一种基于机器学习的光学显微镜自动聚焦方法与流程
本发明属于医学图像处理技术领域,涉及一种基于机器学习的光学显微镜自动聚焦方法。
技术背景
传统的人工阅片方法给病理医生带来了繁重的劳动,而且长时间高注意力地阅片易产生视觉疲劳,大大增加了误诊的概率。近年来,随着显微镜的自动化、智能化发展,自动阅片技术开始出现并迅速发展。显微镜的自动阅片技术由自动聚焦算法拍摄清晰的镜下图像,然后进行后续病理分析,显微镜自动聚焦算法作为自动阅片技术的第一步,极大的影响了后续的病理分析过程,其速度和精度显得尤为重要。
显微视觉存在视场小、景深短、聚焦精度要求高等特点,这使得显微镜自动聚焦面临着很多亟待解决的难题。基于图像处理的自动聚焦法由于具有速度快、精度高、成本低和体积小等优点,成为了现代自动聚焦技术发展的主流。现有的基于图像处理的自动聚焦方法可以分为离焦深度法(dfd)和聚焦深度法(dff)两类:离焦深度法(dfd)首先要对光学显微镜的成像系统进行建模,在此基础上采集模糊的图像,利用模糊图像和模型推导出该图像与焦平面的偏移量,然后驱动步进电机补偿偏移量达到聚焦平面,这种方法主要依据建模的精度,只需要采集2-3幅图像即可完成聚焦,聚焦时间比较短,但是,该方法依赖于成像系统的数学模型,不同的成像系统数学模型差异较大,数学模型建立的不准确则会导致聚焦误差,没有很好的泛化性能。聚焦深度法(dff)是一种建立在搜索算法上的自动对焦方法,如专利文献cn105652429a公开了一种基于机器学习的显微镜细胞载玻片扫描自动聚焦方法,首先在扫描路径规划阶段,根据细胞载玻片情况确定选择扫描路径;然后在学习阶段,得到变步爬山法的步长、门限值以及低灰度值统计法的阈值;在聚焦阶段,首先使用灰度零值法判断当前位置以确定使用哪种聚焦策略,如果当前位置处于距离焦点较远处时,使用灰度零值法并使用大步长,经过试探判断焦点方向后进行移动,当位置处于焦点附近时选用较小步长,使用低灰度值统计法,经过试探判断焦点方向后进行移动,最后到达焦点位置聚焦完成。聚焦深度法(dff)主要涉及聚焦评价函数的选择与设计、聚焦窗口的选择以及聚焦搜索策略的制定。在聚焦评价函数和聚焦窗口确定的情况下,聚焦搜索策略对聚焦性能的优劣起着决定性的作用。大量的诸如爬山法、二分法、斐波纳契搜索法、模糊控制搜索法、自适应步长法、函数曲线拟合法、离散差分方程预测法等搜索策略被用来自动聚焦,在一定程度上改善了调焦的速度和精度,但存在通用性较差,速率较慢的缺点,不适用于精度较高的显微镜自动聚焦。
技术实现要素:
本发明针对现有技术的不足,提供一种基于机器学习的光学显微镜自动聚焦方法,将自动聚焦的调焦过程视为回归问题,通过设计特征和构造回归器,来同时获取显微镜调焦过程需要移动的步长和方向,避免了调焦过程中反复移动带来的回程误差。在保证显微镜聚焦精度的同时,大大的提高了聚焦的速度。
本发明的具体技术方案如下:
一种基于机器学习的光学显微镜自动聚焦方法,所述方法包括以下步骤:
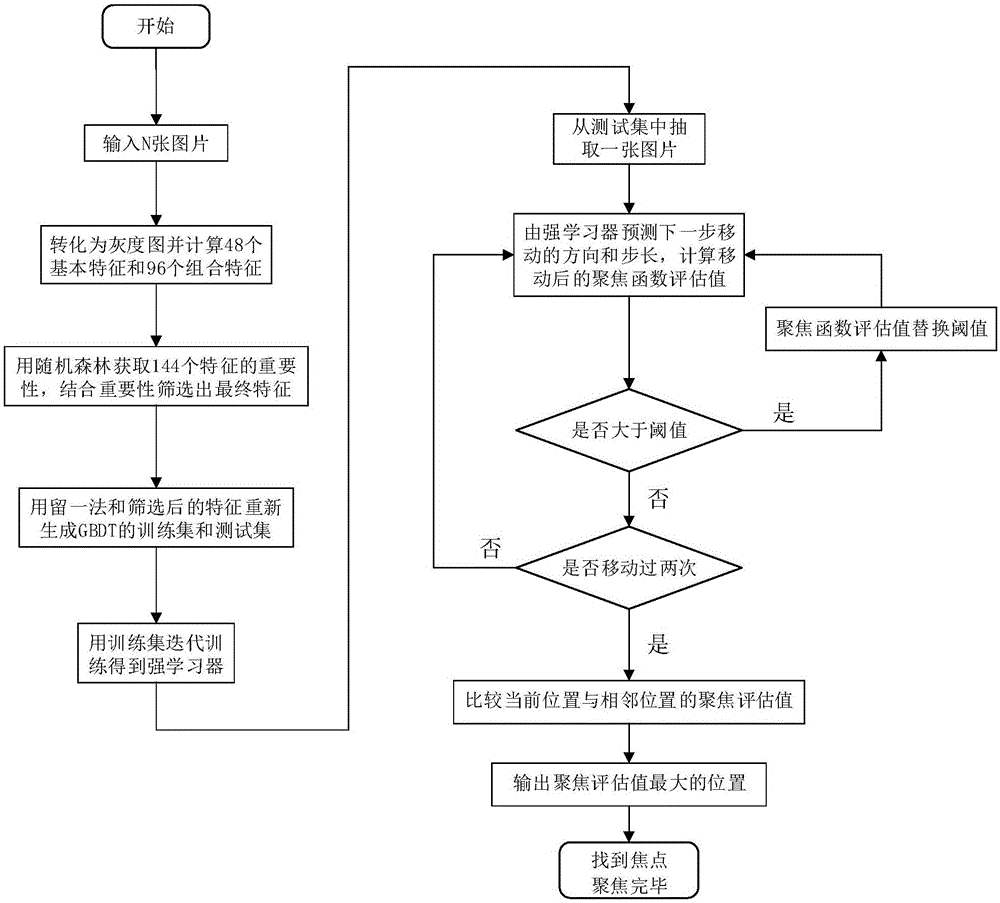
步骤1:沿着光学显微镜的z轴采集p张原始图片ii(x,y),并转化为灰度图fi(x,y),其中i={1,2,…,p},p=100~300;
步骤2:重复步骤1,每次记为1组,采集q组数据共n张图片,q=20~40;
步骤3:计算每张图片的48个原始特征
步骤4:采用自助法(bootstrapping)将所有数据d分为n个数据子集{d1,d2,…,dn},其中未抽到的样本构成袋外数据集
步骤5:对于每个数据子集di,从所有特征中随机抽取w个特征(w<m)做为回归树ti的训练集,训练生成回归树ti,其中i={1,2,…,n},w=1~143;
步骤6:重复步骤5,训练得到n颗回归树,用袋外数据计算均方误差,记为
步骤7:随机对
步骤8:计算特征j的重要性i(j),其中
步骤9:重复步骤7-8,计算出所有特征的重要性,筛选出r个重要性较高的特征,记为s=(s1,s2,…,sr};
步骤10:用步骤9中的特征s和留一法将数据集d划分为训练集dtrain和测试集dtest;
步骤11:在训练集dtrain上采用基于梯度提升的回归树(gradientboostingregressiontree)方法训练得到强回归树fm(x),其中
步骤12:采用迭代强回归树fm(x)进行聚焦,直到不符合迭代条件。
更进一步地,步骤3中,采用聚焦评估函数fj作为图片原始特征,采用显微镜当前视野图片的聚焦评估函数计算值
聚焦评估函数fj可以为以下24种:
原始特征f1为autocorrelation,计算方法为
其中μ,σ2是灰度图片f(x,y)均值和方差,m,n表示为灰度图片f(x,y)长宽的像素点数量,k是常数,这里设置为2;
原始特征f2为brenner,计算方法为
原始特征f3为entropyhistogram,计算方法为
其中p(k)表示图片中像素值为k的像素点的相对频率;
原始特征f4为firstderivgaussian,计算方法为
其中⊙表示相关运算,
原始特征f5为3×3laplacian,计算方法为
其中⊙表示相关运算,
原始特征f6为5×5laplacian,计算方法为
其中
原始特征f7为log,计算方法为
其中
其中i,j为整数,取值范围如下
原始特征f8为m&ghistogram计算方法为
其中h(k)表示图片中像素值为k的数量,μ为θmg+1,这里θmg为阈值,计算方法如下
δ=2(f(x,y-1)-f(x,y+1))2+2(f(x-1,y)-f(x+1,y))2
+(f(x-1,y-1)-f(x+1,y+1))2+(f(x-1,y+1)-f(x+1,y-1))2
原始特征f9为m&mhistogram,计算方法为
其中h(k)表示图片中像素值为k的像素点的数量,μ表示图片像素值的均值,这里设置为128;
原始特征f10为normalizedvariance,计算方法为
其中μ是灰度图片f(x,y)均值;
原始特征f11为3×3prewitt,计算方法为
其中
原始特征f12为rangehistogram,计算方法为
max{h(k)}-min{h(k)}
其中h(k)表示图片中像素值为k的像素点的数量;
原始特征f13为3×3roberts,计算方法为
其中
原始特征f14为3×3scharr,计算方法为
其中
原始特征f15为3×3sobel,计算方法为
其中
原始特征f16为3×3crosssobel,计算方法为
其中
原始特征f17为5×5sobel,计算方法为
其中
原始特征f18为5×5crosssobel,计算方法为
其中
原始特征f19为squaredgradient,计算方法为
原始特征f20为thresholdgradient,计算方法为
只有f(x,y+1)-f(x,y)的绝对值大于等于设定的阈值才累加,这里阈值为0;
原始特征f21为thresholdcontent,计算方法为
只有f(x,y)大于等于设定的阈值才累加,这里阈值为0;
原始特征f22为variance,计算方法为
其中μ是灰度图片f(x,y)均值;
原始特征f23为vollath’sf4,计算方法为
原始特征f24为vollath’sf5,计算方法为
其中μ表示图片像素值的均值;
采用如下4种组合方式作为图片的组合特征:
更进一步地,步骤3中,采用当前图片到聚焦最清晰图片的序列差值作为训练集的标签。
更进一步地,步骤9中,采用随机森立计算特征重要性,结合设定的阈值迭代多次进行特征的筛选。
更进一步地,步骤10中,采用留一法和随机森林计算出来的特征重要性把数据划分训练集dtrain和测试集dtest。
更进一步地,步骤11中,采用梯度提升回归树的方法对显微镜下一步要移动的步长和方向同时做出预测,采用回归的方法,拟合出来的结果正负表示显微镜下一步需要移动的方向,数值大小表示显微镜下一步需要移动的步长。
本发明能够得到以下有益效果:
本发明将自动聚焦的调焦过程视为回归问题,通过设计特征和构造回归器,来同时获取显微镜调焦过程需要移动的步长和方向,避免了调焦过程中反复移动带来的回程误差。在保证显微镜聚焦精度的同时,大大的提高了聚焦的速度。在自己采集的数据集中,设置初始位置为每组第一张图片时,平均只需要移动7.6次;精度达到了100%,任意初始化位置时最佳精度达到了99.9%,平均只需要移动6.9次。
附图说明
图1是本发明的流程图;
图2是采集的一组数据集中的部分图片以及其聚焦评估函数的曲线;
图3-图26是24种原始特征在20组数据集上的计算结果,每组中节选出100张图片;
图27是随机森林构建的过程;
图28是梯度提升树的迭代过程。
具体实施方式
为了使本发明的发明目的、技术方案和有益技术效果更加清晰,以下结合实施例,对本发明进行进一步详细说明。应当理解的是,本说明书中描述的实施例仅仅是为了解释本发明,并非为了限定本发明,实施例的具体参数设置等可因地制宜做出选择而对结果并无实质性影响。
步骤1:如图2所示,沿着光学显微镜的z轴采集200张原始图片ii(x,y),并转化为灰度图fi(x,y),其中i={1,2,…,p};
步骤2:重复步骤1,每次记为1组(如图2所示),采集20组数据共n张图片;
步骤3:计算每张图片的48个原始特征
原始特征f1为autocorrelation(如图3所示),横轴表示图片编号,纵轴表示每张图片对应的特征值,每种线型代表一组图片,计算方法为
其中μ,σ2是灰度图片f(x,y)均值和方差,m,n表示为灰度图片f(x,y)长宽的像素点数量,k是常数,这里设置为2;
原始特征f2为brenner(如图4所示),计算方法为
原始特征f3为entropyhistogram(如图5所示),计算方法为
其中p(k)表示图片中像素值为k的像素点的相对频率;
原始特征f4为firstderivgaussian(如图6所示),计算方法为
其中⊙表示相关运算,
原始特征f5为3×3laplacian(如图7所示),计算方法为
其中⊙表示相关运算,
原始特征f6为5×5laplacian(如图8所示),计算方法为
其中
原始特征f7为log(如图9所示),计算方法为
其中
其中i,j为整数,取值范围如下
原始特征f8为m&ghistogram(如图10所示)计算方法为
其中h(k)表示图片中像素值为k的数量,μ为θmg+1,这里θmg为阈值,计算方法如下
δ=2(f(x,y-1)-f(x,y+1))2+2(f(x-1,y)-f(x+1,y))2
+(f(x-1,y-1)-f(x+1,y+1))2+(f(x-1,y+1)-f(x+1,y-1))2
原始特征f9为m&mhistogram(如图11所示),计算方法为
其中h(k)表示图片中像素值为k的像素点的数量,μ表示图片像素值的均值,这里设置为128;
原始特征f10为normalizedvariance(如图12所示),计算方法为
其中μ是灰度图片f(x,y)均值;
原始特征f11为3×3prewitt(如图13所示),计算方法为
其中
原始特征f12为rangehistogram(如图14所示),计算方法为
max{h(k)}-min{h(k)}
其中h(k)表示图片中像素值为k的像素点的数量;
原始特征f13为3×3roberts(如图15所示),计算方法为
其中
原始特征f14为3×3scharr(如图16所示),计算方法为
其中
原始特征f15为3×3sobel(如图17所示),计算方法为
其中
原始特征f16为3×3crosssobel(如图18所示),计算方法为
其中
原始特征f17为5×5sobel(如图19所示),计算方法为
其中
原始特征f18为5×5crosssobel(如图20所示),计算方法为
其中
原始特征f19为squaredgradient(如图21所示),计算方法为
原始特征f20为thresholdgradient(如图22所示),计算方法为
只有f(x,y+1)-f(x,y)的绝对值大于等于设定的阈值才累加,这里阈值为0;
原始特征f21为thresholdcontent(如图23所示),计算方法为
只有f(x,y)大于等于设定的阈值才累加,这里阈值为0;
原始特征f22为variance(如图24所示),计算方法为
其中μ是灰度图片f(x,y)均值;
原始特征f23为vollath’sf4(如图25所示),计算方法为
原始特征f24为vollath’sf5(如图26所示),计算方法为
其中μ表示图片像素值的均值;
组合特征
组合特征
组合特征
组合特征
将所有图片用特征的形式表示,记为d={(x1,y1),(x2,y2),…,(xn,yn)},其中y表示当前图片到聚焦最清晰图片的序列差值(如图2所示聚焦评估的曲线中x轴的差值);
步骤4:如图27所示,采用自助法(bootstrapping)将所有数据d分为n个数据子集{d1,d2,…,dn},其中未抽到的样本构成袋外数据集
步骤5:如图27所示,对于每个数据子集di,从样本中随机抽取w个特征(w<m)做为回归树ti的训练集,训练生成回归树ti,每棵决策树生长不受限制,也不要做剪裁,其中i={1,2,…,n},m为基础特征和组合特征的总和,这里设置为144;
步骤6:重复步骤5,训练得到n颗回归树,用袋外数据计算均方误差,记为
步骤7:随机对
步骤8:计算特征j的重要性i(j),计算方法如下
步骤9:重复步骤7-8,计算出所有特征的重要性,每一次将i(j)大于阈值的特征j加入集合s当中,最终集合s即为随机森林特征选择后的结果,记为s={s1,s2,…,sk},si表示选择后的特征,这里阈值设置为5%;
步骤10:用步骤9中的特征s和留一法将数据集d划分为训练集dtrain和测试集dtest,这里留一法表示将19组数据做为训练集dtrain,余下的一组数据做为测试集dtest;
步骤11:如图28所示,用dtrain={(x1,y1),(x1,y1),…,(xn,yn)}做为训练集,采用基于梯度提升回归树(gradientboostingregressiontree)方法训练得到强回归树fm(x),具体过程如下
1)使用常量值γ初始化模型,
2)迭代训练模型,对于第m次迭代,其中m={1,2,…,m}
a)计算损失函数的负梯度在当前模型的值,将它作为残差的估计
其中l(yi,f(xi))为损失函数,这里设置为最小二乘(least-square),i=1,2,…,n;
b)将{(xi,rim)}作为训练集,其中i=1,2,…,n,拟合得到第m颗回归树,叶节点区域记为rjm,j=1,2,…,jm,其中jm为迭代第m次时叶子节点的个数;
c)对叶子区域j=1,2,…,jm计算最佳拟合值
d)如图28所示更新模型
其中ν是学习率,i(x∈rjm)表示第m次迭代当样本归结为第j个叶结点时值为1,否者为0;
3)更新模型,得到强学习器
步骤12:迭代强回归树fm(x)进行聚焦(如图1右边所示),直到不符合迭代条件。
上面对本专利的较佳实施方式作了详细说明,但是本专利并不限于上述实施方式,在本领域的普通技术人员所具备的知识范围内,还可以在不脱离本专利宗旨的前提下做出各种变化。
- 还没有人留言评论。精彩留言会获得点赞!