一种用于大数据分析的数据预测方法和装置与流程
本发明涉及计算机信息处理技术,更具体地说,涉及一种用于大数据分析的数据预测方法和装置。
背景技术:
从SGI的首席科学家John R.Masey在1998年提出大数据概念,到大数据分析技术广泛应用于社会的各个领域,已经走过了18年的时间。现在再也没有企业怀疑大数据分析的力量,并且都在竞相利用大数据来增强自己企业的业务竞争力。但是,即使18年过去,大数据分析行业仍然处于快速发展的初期,每时每刻都在产生新的变化。从概念到实用、从结构化数据分析到非结构化数据分析,大数据分析技术在不断地进化。大数据分析的研究已经进入到了一个全新的阶段,“预测分析”技术成为最具有代表性的未来技术方向。
技术实现要素:
本发明的目的是提供一种可以有效的进行数据预测的方法和装置,优点是实施方便,并可以方便的根据新增数据对预测规则进行修正改进。
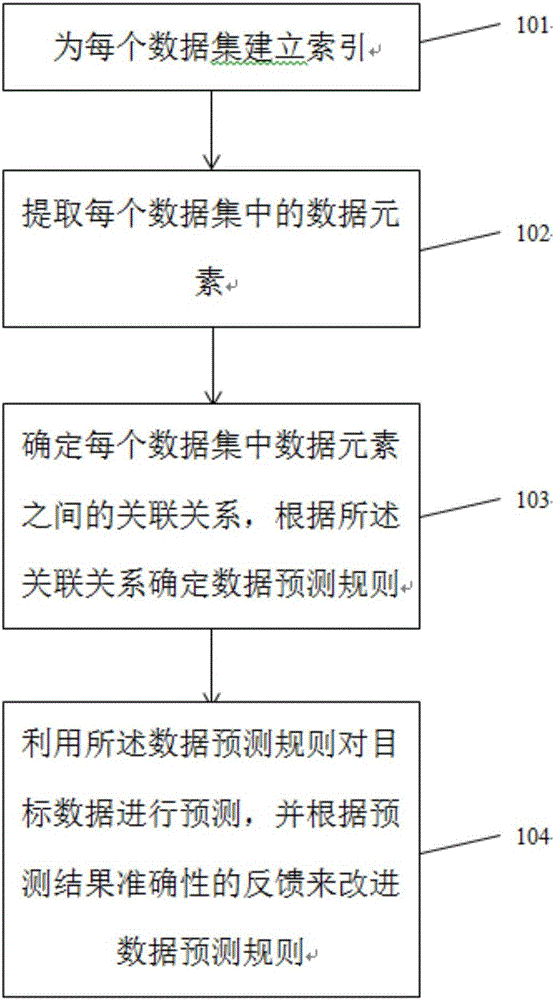
为解决上述技术问题,根据本发明的一个方面,提供了一种用于大数据分析的数据预测方法,包括步骤:为每个数据集建立索引;提取每个数据集中的数据元素;确定每个数据集中数据元素之间的关联关系,根据所述关联关系确定数据预测规则;利用所述数据预测规则对目标数据进行预测,并根据预测结果准确性的反馈来改进数据预测规则。
优选的,所述提取每个数据集中的数据元素,包括:
判断当前数据集的数据是结构化数据还是非结构化数据,如果当前数据集的数据为非结构化数据,则将当前数据集的数据转化为结构化数据,并从当前数据集的结构化数据中提取数据元素,并为每个数据元素设置唯一标识。
优选的,所述确定每个数据集中数据元素之间的关联关系,根据所述关联关系确定数据预测规则,包括:针对每个数据集,按照计算公式计算当前数据集中每两个数据元素同时出现的概率;根据所述当前数据集中每两个数据元素同时出现的概率,确定所述当前数据集的频繁数据元素集,所述频繁数据元素集中包括至少两个数据元素;根据所述当前数据集的频繁数据元素集,确定数据预测规则;
所述计算公式为:
或者,
其中,P(A,B)表示数据元素A和数据元素B在当前数据集中同时出现的概率,C(A∩B)表示数据元素A和数据元素B在当前数据集中同时出现的次数,C(A)表示数据元素A在当前数据集中出现的次数,C(B)表示数据元素B在当前数据集中出现的次数,T为当前数据集中所有数据元素的集合,∑X∈TC(X)为当前数据集中所有数据元素出现的次数,α和β为可调节的修正系数,用于使特殊情况计算得到的P(A,B)所受数据偏差的影响更小,n1和n2为可调节系数,用于更精细的调节,其值大于0。
优选的,根据所述当前数据集中每两个数据元素同时出现的概率,确定所述当前数据集的频繁数据元素集,包括:当两个数据元素同时出现的概率达到预设概率阈值时,确定该两个数据元素构成了一频繁数据元素集;当两个频繁数据元素集具有相同的数据元素时,提取该两个频繁数据元素集中不同的数据元素,计算不同的数据元素在当前数据集中出现的概率;当不同的数据元素在当前数据集中出现的概率达到预设概率阈值时,确定不同的数据元素构成了一频繁数据元素集。
优选的,所述利用所述数据预测规则对目标数据进行预测,包括:根据已被规则引擎解析过的数据预测规则对目标数据进行预测。
优选的,所述方法还可以包括:利用神经网络方法,根据当前大数据及历史数据进行预测。
优选的,所述方法还可以包括:根据预测结果准确性的反馈,对所述数据预测规则及其形成机制进行修正改进。
根据本发明的另一个方面,提供了一种用于大数据分析的数据预测装置,包括:
索引建立模块,用于为每个数据集建立索引;
数据元素提取模块,用于提取每个数据集中的数据元素;
预测规则建立模块,用于确定每个数据集中数据元素之间的关联关系,根据所述关联关系确定数据预测规则;
预测模块,用于利用所述数据预测规则对目标数据进行预测,并根据预测结果准确性的反馈来改进数据预测规则。
优选的,数据元素提取模块,用于判断当前数据集的数据是结构化数据还是非结构化数据,如果当前数据集的数据为非结构化数据,则将当前数据集的数据转化为结构化数据,并从当前数据集的结构化数据中提取数据元素,并为每个数据元素设置唯一标识。
优选的,预测规则建立模块,用于针对每个数据集:按照计算公式计算当前数据集中每两个数据元素同时出现的概率;根据所述当前数据集中每两个数据元素同时出现的概率,确定所述当前数据集的频繁数据元素集,所述频繁数据元素集中包括至少两个数据元素;根据所述当前数据集的频繁数据元素集,确定数据预测规则;
所述计算公式为:
或者,
其中,P(A,B)表示数据元素A和数据元素B在当前数据集中同时出现的概率,C(A∩B)表示数据元素A和数据元素B在当前数据集中同时出现的次数,C(A)表示数据元素A在当前数据集中出现的次数,C(B)表示数据元素B在当前数据集中出现的次数,T为当前数据集中所有数据元素的集合,∑X∈TC(X)为当前数据集中所有数据元素出现的次数,α和β为可调节的修正系数,用于使特殊情况计算得到的P(A,B)所受数据偏差的影响更小,n1和n2为可调节系数,用于更精细的调节,其值大于0。
优选的,还可以包括:修正模块,用于根据预测结果准确性的反馈,对所述数据预测规则及其形成机制进行修正改进。
附图说明
图1是根据本发明实施例的一种用于大数据分析的数据预测方法的流程图;
图2是根据本发明实施例的一种用于大数据分析的数据预测装置的示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
图1是根据本发明实施例的一种用于大数据分析的数据预测方法的流程图。
在步骤101,为每个数据集建立索引。
在步骤102,提取每个数据集中的数据元素。
在一个实施例中,判断当前数据集的数据是结构化数据还是非结构化数据,如果当前数据集的数据为非结构化数据,则将当前数据集的数据转化为结构化数据,并从当前数据集的结构化数据中提取数据元素,并为每个数据元素设置唯一标识。在本发明的一个实施例中,提取出的数据元素的标识分别为A1,A2,A3,A4,A5。
在步骤103,确定每个数据集中数据元素之间的关联关系,根据所述关联关系确定数据预测规则。
在一个实施例中,数据元素之间的关联关系可用数据元素在数据集中同时出现的概率来表征。此时,步骤103中,针对每个数据集可实施为如下步骤B1-B3:
步骤B1、按照计算公式计算当前数据集中每两个数据元素同时出现的概率。
步骤B2、根据所述当前数据集中每两个数据元素同时出现的概率,确定所述当前数据集的频繁数据元素集,所述频繁数据元素集中包括至少两个数据元素。
在一个实施例中,当两个数据元素同时出现的概率达到预设概率阈值时,确定该两个数据元素构成了一频繁数据元素集;
当两个频繁数据元素集具有相同的数据元素时,提取该两个频繁数据元素集中不同的数据元素,计算不同的数据元素在当前数据集中出现的概率;当不同的数据元素在当前数据集中出现的概率达到预设概率阈值时,确定不同的数据元素构成了一频繁数据元素集。
步骤B3、根据所述当前数据集的频繁数据元素集,确定数据预测规则。
上述步骤B1中的计算公式为:
或者,
其中,P(A,B)表示数据元素A和数据元素B在当前数据集中同时出现的概率,C(A∩B)表示数据元素A和数据元素B在当前数据集中同时出现的次数,C(A)表示数据元素A在当前数据集中出现的次数,C(B)表示数据元素B在当前数据集中出现的次数,T为当前数据集中所有数据元素的集合,ΣX∈TC(X)为当前数据集中所有数据元素出现的次数,α和β为可调节的修正系数,用于使特殊情况计算得到的P(A,B)所受数据偏差的影响更小,n1和n2为可调节系数,用于更精细的调节,其值大于0。在本发明的一个实施例中,使用前一个公式,其中,0≤α≤3,0≤β≤0.1。
在本发明的一个实施例中,给定在一个数据集中,A1出现11次,A2出现9次,A3-A5均出现10次,A1和A2同时出现的次数有8次,此处给定α=1,β=0.05,则按照前述计算公式可以计算出:
在本实施例中,设定预设概率阈值为0.5,由于P(A1,A2)大于0.5,所以将A1和A2归入同一个频繁数据元素集{A1,A2},可得到一个数据预测规则为A1:—A2,表示当A1出现的时候,可预测A2也会出现。
如果在当前数据集中,P(A1,A3)也大于0.5,则将A1和A3归入同一个频繁数据元素集{A1,A3},可得到一个数据预测规则为A1:—A3,表示当A1出现的时候,可预测A3也会出现。
进一步可推测A2,A3有可能也是两个频繁同时出现的数据元素,接下来可根据前述计算公式计算P(A2,A3),如果计算得出P(A2,A3)也大于0.5,则可将A1、A2和A3归入同一个频繁数据元素集{A1,A2,A3},可得到一个数据预测规则为A1:—(A2,A3),表示当A1出现的时候,可预测A2和A3也会出现。
根据频繁数据元素集中元素的出现,可以预期同一个频繁数据元素集中其他的元素也有较高的概率出现。
在步骤104,利用所述数据预测规则对目标数据进行预测,并根据预测结果准确性的反馈来改进数据预测规则。在本发明的一个实施例中,将一批新的数据被提交至智能分析引擎,新的数据包含(A1,A6,A7……)。判断当中是否包含已有预测规则中的数据元素,发现A1包含在已有的预测规则中。由于新提交的数据当中存在A1,根据已有的预测规则:A1:—A2,则预测A2也会出现。
通过数据预测规则进行预测后,进行预测准确性的比较,当添加新数据后的预测准确性较差时(如A1和A2同时出现的概率低于0.3,已经小于预设概率阈值0.5),则删除该规则。
确定新数据中的数据元素之间的关联关系,再根据新数据元素间的关联关系确定新的数据预测规则,并将新的数据预测规则加入原有的数据预测规则中。
本发明通过优点是实施方便,可以实时添加数据并根据新的数据内容对预测规则进行修改。
图2是根据本发明实施例的一种用于大数据分析的数据预测装置的示意图;
根据本发明的另一个方面,提供了一种用于大数据分析的数据预测装置,包括:
索引建立模块,用于为每个数据集建立索引;
数据元素提取模块,用于提取每个数据集中的数据元素;
预测规则建立模块,用于确定每个数据集中数据元素之间的关联关系,根据所述关联关系确定数据预测规则;
预测模块,用于利用所述数据预测规则对目标数据进行预测,并根据预测结果准确性的反馈来改进数据预测规则。
优选的,数据元素提取模块,用于判断当前数据集的数据是结构化数据还是非结构化数据,如果当前数据集的数据为非结构化数据,则将当前数据集的数据转化为结构化数据,并从当前数据集的结构化数据中提取数据元素,并为每个数据元素设置唯一标识。
优选的,预测规则建立模块,用于针对每个数据集:按照计算公式计算当前数据集中每两个数据元素同时出现的概率;根据所述当前数据集中每两个数据元素同时出现的概率,确定所述当前数据集的频繁数据元素集,所述频繁数据元素集中包括至少两个数据元素;根据所述当前数据集的频繁数据元素集,确定数据预测规则;
所述计算公式为:
或者,
其中,P(A,B)表示数据元素A和数据元素B在当前数据集中同时出现的概率,C(A∩B)表示数据元素A和数据元素B在当前数据集中同时出现的次数,C(A)表示数据元素A在当前数据集中出现的次数,C(B)表示数据元素B在当前数据集中出现的次数,T为当前数据集中所有数据元素的集合,∑X∈TC(X)为当前数据集中所有数据元素出现的次数,α和β为可调节的修正系数,用于使特殊情况计算得到的P(A,B)所受数据偏差的影响更小,n1和n2为可调节系数,用于更精细的调节,其值大于0。
优选的,还可以包括:修正模块,用于根据预测结果准确性的反馈,对所述数据预测规则及其形成机制进行修正改进。
以上述依据本发明的理想实施例为启示,通过上述的说明内容,本领域普通技术人员完全可以在不偏离本项发明技术思想的范围内,进行多样的变更以及修改。本项发明的技术性范围并不局限于说明书上的内容,必须要根据权利要求范围来确定其技术性范围。
- 还没有人留言评论。精彩留言会获得点赞!