基于深度学习的辅助诊断方法及系统与流程
本发明涉及大数据分析领域,具体涉及一种基于深度学习的辅助诊断方法及系统。
背景技术:
通常,大型公立医院的医生每天需要接诊大量具有相似症状的病人,其中包括经验不足的年轻医生,当接诊人数过多时,容易出现医生工作效率低、甚至误诊率变高等问题。
随着我国健康医疗大数据规划的推进,医院的病历系统已进入信息时代,在医院内部积攒了海量的电子病历数据。这些电子病历数据中包含了患者在医院诊断中的详细记录,包括症状表现、病情及治疗措施等,对于医生做出诊断具有很高的参考价值。
近年来深度学习发展迅速,在语音识别、图像识别、自然语言处理等领域都取得了巨大的成就。由此,我们考虑用深度学习来对电子病历数据进行处理,生成辅助诊断应用,帮助没有经验的医生做出诊断。考虑到电子病历在数据上具有特殊字段(如,现病史、体格检查结果),对于辅助诊断具有很高的参考价值,对此,传统辅助诊断方法或系统依赖于极度标准化的数据,在标准化过程中开销巨大,而且由于数据过于标准化,面对实际应用中不同医生输入的“咳一周”与“咳嗽一周”(二者均为常规记法)无法识别是否是相同属性;同时,传统辅助诊断方法或系统在提取病历特征时,其所提取的是一个一个的词,而不是整个句子的特征,当样本多时,特征太多,完全提取不切实际,不适用于大规模数据。
技术实现要素:
本发明的目的在于提供一种基于深度学习的辅助诊断方法及系统,其具有优异的响应速度与准确率。
为实现上述目的,本发明采用以下技术方案:
基于深度学习的辅助诊断方法,包括以下步骤:
s1、由语料库导入原始语料数据,对原始语料数据进行分词处理,并建立词嵌入查询表;
s2、提取电子病历数据中的关键特征字段,并生成训练样本,使用所述词嵌入查询表对训练样本进行数字化转换,将数字化训练样本输入卷积神经网络进行训练,生成辅助诊断模型;
s3、对新输入的电子病历提取关键特征字段,并生成待预测集,使用所述词嵌入查询表对待预测集进行数字化转换,将数字化待预测集输入所述辅助诊断模型进行匹配,输出匹配的诊断结果。
进一步地,所述步骤s1具体包括:
s11、从语料库导入原始语料数据,对原始语料数据进行数据清洗;
s12、对原始语料数据进行中文分词,将得到的分词结果输入到词向量模型训练,建立词嵌入查询表。
进一步地,所述步骤s2具体包括:
s21、由电子病历数据库中提取已经确认无误诊的原始电子病历数据集,从原始电子病历数据集中提取出原始病历数据,对提取出的原始病历数据进行数据清洗;
s22、对清洗后的病历数据进行特征提取,提取医生在诊断中的关键特征字段;
s23、对s22提取出来的关键特征字段进行分词处理,生成训练样本;
s24、使用所述词嵌入查询表将训练样本中的每个词转换为对应的词向量;
s25、统一各特征字段的向量维度,最终拼接成整条诊断记录的向量表示形式,完成训练样本的数字化;
s26、将数字化的训练样本输入到卷积神经网络进行训练,生成辅助诊断模型。
进一步地,步骤s26中的卷积神经网络中,通过卷积核与数字化训练样本中的逐条向量按照某一方向进行卷积,并加上一个偏置项,通过激活函数输出一个特征;
则有,ci=f(w×xi:i+h-1+b);
式中,ci代表新的特征;w代表一个卷积核,以k代表空间维度,一个窗口中包含h个诊断记录特征单元,则卷积核为w∈rhk;xi:i+h-1表示从第i个关键特征字段到第i+h-1个关键字特征字段之间的向量值;b代表一个偏置项;f为非线性函数。
进一步地,步骤s3具体包括:
s31、对新输入的电子病历提取关键特征字段;
s32、对提取出的关键特征字段进行分词处理,获得待预测集;
s32、使用所述词嵌入查询表将待预测集中的每个词转换为对应的词向量;
s33、统一各特征字段的向量维度,最终拼接成整条诊断记录的向量表示形式,完成待预测集的数字化;
s34、将数字化的待预测集输入到所述辅助诊断模型,得出匹配的诊断结果。
进一步地,步骤s2及s3中提取的关键特征字段均包括主诉、现病史及体格检查结果。
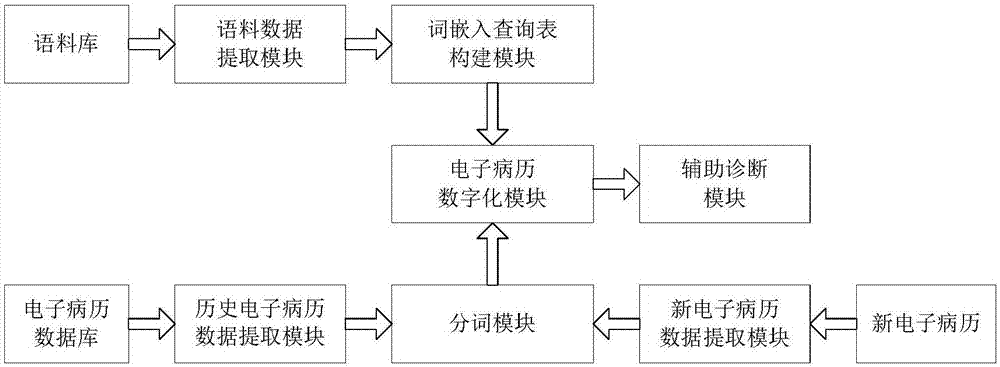
本发明还提供一种基于深度学习的辅助诊断系统,包括:
语料数据提取模块,所述语料数据提取模块从语料库中导入原始语料数据,对原始语料数据进行清洗后进行中文分词;
词嵌入查询表构建模块,其与所述语料数据提取模块相连,其设有词向量模型以对所述语料数据提取模块的分词结果进行训练,建立词嵌入查询表;
历史电子病历数据提取模块,其从电子病历数据库中提取原始病历数据,对提取出的原始病历数据进行数据清洗,并提取医生在诊断中的关键特征字段;
新电子病历数据提取模块,其从新输入的电子病历中提取关键特征字段;
分词模块,其分别与所述历史电子病历数据提取模块及新电子病历数据提取模块相连;其对所述历史电子病历数据提取模块所提取的关键特征进行分词处理,获得训练样本;其对所述新电子病历数据提取模块提取的关键特征字段进行分词处理,获得待预测集;
电子病历数字化模块,其分别与所述词嵌入查询表构建模块及分词模块相连,其调用所述词嵌入查询表分别对所述训练样本及所述待预测集进行数字化转换;
辅助诊断模块,其与所述电子病历数字化模块相连,其设有卷积神经网络以对数字化后的训练样本进行训练而生成辅助诊断模型;其应用所述辅助诊断模型,以数字化后的待预测集为输入,得出匹配的诊断结果并输出。
进一步地,所述历史电子病历数据提取模块及所述新电子病历数据提取模块提取的关键特征字段均包括主诉、现病史及体格检查结果。
采用上述技术方案后,本发明与背景技术相比,具有如下优点:
本发明并不依赖于极度的标准化数据,而是通过深度学习自动提取自然语言中的潜在特征。其自动提取医生常规书写电子病历与诊断之间的联系,构建智能辅助诊断模型,实现辅助诊断的功能。
本发明提取的是整个句子的特征,适用于临床大规模数据的提取,同时本发明所使用的卷积神经网络的分类,由于卷积神经网络采用了权值共享的网络结构,减少了权值的数量,降低了网络的复杂度,分类速度和分类的准确率都得到了很大的提高,以达到“辅助诊断”的目的;
本发明尤其适用于儿科等疾病的辅助诊断。由于我国儿科医生的配比率低,造成儿科医生的接诊任务繁重,同时由于儿童的体质的特殊性,诊断时需慎之又慎,造成儿科医生的工作压力极大。本发明具有高效的诊断速率与精确的匹配度,能为医生提供有效的辅助诊断,极大程度避免误诊,减轻医生的工作压力。
附图说明
图1为本发明所揭示的辅助诊断方法流程图;
图2为本发明所揭示的辅助诊断系统结构框图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
实施例
如图1所示,本发明公开了一种基于深度学习的辅助诊断方法,其包括以下步骤:
s1、由语料库导入原始语料数据,对原始语料数据进行分词处理,并建立词嵌入查询表;
s2、提取电子病历数据中的关键特征字段,并生成训练样本,使用所述词嵌入查询表对训练样本进行数字化转换,将数字化训练样本输入卷积神经网络进行训练,生成辅助诊断模型;
s3、对新输入的电子病历提取关键特征字段,并生成待预测集,使用所述词嵌入查询表对待预测集进行数字化转换,将数字化待预测集输入所述辅助诊断模型进行匹配,输出匹配的诊断结果。
其中,所述步骤s1具体包括:
s11、从语料库导入原始语料数据,对原始语料数据进行数据清洗;
s12、对原始语料数据进行中文分词,将得到的分词结果输入到词向量模型(word2vec中的cbow模型)训练,用以训练维度为200的词向量的词嵌入查询表。
其中,所述步骤s2具体包括:
s21、由电子病历数据库中提取已经确认无误诊的原始电子病历数据集,从原始电子病历数据集中提取出原始病历数据,对提取出的原始病历数据进行数据清洗;
s22、对清洗后的病历数据进行特征提取,提取医生在诊断中的关键特征字段(所述关键特征字段包括主诉、现病史及体格检查结果);
s23、对s22提取出来的关键特征字段进行分词处理,生成训练样本;
s24、使用所述词嵌入查询表对训练样本中的词进行词向量转换,将训练样本中的每个词转换为对应的词向量;
s25、统一各特征字段的向量维度,生成主诉、现病史及体格检查结果的向量表示,最终拼接成整条诊断记录的向量表示形式,即完成训练样本的数字化;
s26、将数字化的训练样本输入到卷积神经网络中进行训练,不断回传调整参数进行权值更新,以减小误差,提取特征,生成辅助诊断模型。
步骤s26中的卷积神经网络中,通过卷积核与数字化训练样本中的逐条向量按照某一方向进行卷积,并加上一个偏置项,通过激活函数输出一个特征。
则有,ci=f(w×xi:i+h-1+b);式中,ci代表新的特征;w∈rhk代表一个卷积核,以k代表空间维度,一个窗口中包含h个关键特征字段;关键特征字段的数目为n,则关键特征字段可被表达为
步骤s3具体包括:
s31、对新输入的电子病历提取关键特征字段;
s32、对提取出的关键特征字段进行分词处理,获得待预测集;
s32、使用所述词嵌入查询表对待预测集中的词进行词向量转换,将每个词转换为对应的词向量;
s33、通过句向量相关算法统一各特征字段的维度,生成主诉、现病史以及体格检查结果的向量表示,最终拼接成整条诊断记录的向量表示形式;
s34、将数字化的待预测集输入到所述辅助诊断模型,得出匹配的诊断结果。
本发明还提供一种基于深度学习的辅助诊断系统,用于实现前述的辅助诊断方法,其包括语料数据提取模块、词嵌入查询表构建模块、历史电子病历数据提取模块、新电子病历数据提取模块、分词模块、电子病历数字化模块以及辅助诊断模块。
所述语料数据提取模块从语料库中导入原始语料数据,对原始语料数据进行清洗后进行中文分词。
所述词嵌入查询表构建模块与所述语料数据提取模块相连,其设有词向量模型以对所述语料数据提取模块的分词结果进行训练,建立词嵌入查询表。
所述历史电子病历数据提取模块从电子病历数据集中提取已确认无误诊的原始病历数据,对提取出的原始病历数据进行数据清洗,并提取医生在诊断中的关键特征字段(包括主诉、现病史及体格检查结果)。
所述新电子病历数据提取模块从新输入的电子病历中提取关键特征字段(包括主诉、现病史及体格检查结果)。
所述分词模块分别与所述历史电子病历数据提取模块及新电子病历数据提取模块相连。其对所述历史电子病历数据提取模块所提取的关键特征进行分词处理,获得训练样本;其对所述新电子病历数据提取模块提取的关键特征字段进行分词处理,获得待预测集。
所述电子病历数字化模块分别与所述词嵌入查询表构建模块及分词模块相连,其调用所述词嵌入查询表分别对所述训练样本及所述待预测集进行数字化转换。
所述辅助诊断模块与所述电子病历数字化模块相连,其设有卷积神经网络以对数字化后的训练样本进行训练而生成辅助诊断模型;其应用所述辅助诊断模型,以数字化后的待预测集为输入,得出匹配的诊断结果并输出。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!