一种高血压病人随访推荐的方法与流程
本发明属于医疗技术领域,涉及一种高血压病人随访推荐的方法。
背景技术:
近几年来,高血压病患者人数在全球范围内不断攀升,根据国际健康组织的不完全统计,在2016年初,全球成年人中高血压患者占据20%以上。目前预估我国高血压患者人数超过2亿且病人对自身疾病的知晓率仅为30%,控制率仅为6%,且高血压病又往往伴随着中风、心力衰竭、眼部损害等诸多并发症,给人民的生活和健康造成极其严重的负面影响。
目前国内针对高血压病人的疾病控制主要由社区、街道卫生院工作人员对高血压病人进行随访,通过药品和医嘱控制病情,并搜集病人生理、病理以及生活习惯等数据。但医疗资源的不均衡分布严重阻碍了高血压病人病情控制,其不平衡性主要体现在(1)时间:工作人员会对上次随访,血压超过阈值的病人在近期再度随访,一般间隔在15天以内,而未超过阈值的随访间隔则长至三个月或以上,随访时发现很大一部分病人的血压已严重超标且伴随其它病症的恶化现象。(2)空间:城乡医疗卫生资源的差距比较大,城市人口平均拥有的医疗卫生资源是农村人口的2.5倍以上,比如,占全国总人口近70%的农村拥有全国医疗卫生资源的30%,而占全国总人口30%的城市却占有全国医疗卫生资源的70%。所以提高基层工作人员的随访效率和医疗资源的利用率是慢性病控制的关键。
准确地预测高血压患者血压的变化情况能够更有针对性地对患者进行随访,目前已有的血压预测技术中,主要通过神经网络模型和深度学习中的循环神经网络模型对高血压的发病进行预测,但这些技术在应用方面存在几点不足。(1)cn201510028877.6一种利用神经网络的高血压预测方法中,忽略了同一个体在不同时间维度下表现的自相关性,因此仅适用于对未确诊为高血压病的人群患高血压概率的预测,并起到预防作用,而不能准确预测高血压患者的血压变化情况。(2)cn201611027689.2基于循环神经网络构建预测模型的方法中涵盖了病人个体差异和测量水平差异两大方面,能够较为准确地监测不同个体的血压随时间变化情况并对下一个时间节点的血压进行预测,然而此种方法大都依靠可穿戴设备对数据进行采集,采集的数据必须是标准的时间序列结构(时间起始、间隔均相同),若数据因病人脱卸设备或设备损坏等原因未能准确及时地上传会影响预测结果,因此具有成本高、灵活性低、不可控性强的缺陷。
技术实现要素:
本发明提出了一种可行性强、可控性强、预测个性化、灵活性强的高血压病人随访推荐的方法。
本发明采用的技术方案是:
一种高血压病人随访推荐的方法,其特征在于:包括:
提取并关联数据库中高血压病人的个人健康档案和随访后产生的潜在性血压影响因子;
将获取的数据进行清洗得到有效数据和现有特征变量;
根据有效数据进行特征构建得到构建特征变量;
采用lmm模型对现有特征变量和构建特征变量进行筛选获得显著特征变量;
将有效数据和显著特征变量代入多层逻辑回归拟合函数进行拟合得到多层逻辑回归模型;
将患者最近一次的测量数据和每日更新的数据作为预测值代入多层逻辑回归模型,计算患者血压超过正常值的概率;
根据获取的数据、血压超过正常值的概率、以及更新的数据,对需要随访的患者进行推荐。
进一步,数据清洗步骤包括:
(1)变量转化:将数据库中的潜在性血压影响因子分别转化成对应的数值型变量、定类变量、定序变量和日期型变量;
(2)错误录入值和极端值过滤:针对类型变量直接移除类别频数小于n的行,针对连续型变量,观察其分布情况后根据高斯概率密度函数:
其中j表示需要对变量进行过滤的数值型变量,xj表示变量的实际值,uj表示各变量的平均值,σj为各变量的方差;移除xu>μj-tσj,和xl<μj+tσj的行,其中xu,xl分别表示计算出的保留的上下区间,t表示方差的倍数,通过t值可计算保留数据的百分比;
(3)缺失值处理:根据获取的数据,直接移除一条数据中同时丢失m个以上变量的行;对于同时缺失在m个以下的行数据,使用knn算法对缺失数据进行填充,根据欧几里得距离,其中xg,yg分别表示两个实例间各个变量的实际值:
选取k个相似的临近单位,针对类型变量用最常出现的值填充,连续型变量则用中位数填充;
(4)时间过滤:过滤不符合预期的时间范围,且为了突出个体间的随机效应,需要选择固定时间范围内随访次数较多(j次)的个体。
进一步,构建特征变量包括:
(1)bmi(身体质量指数)=w/h^2,其中w表示患者的体重,h表示患者身高;
(2)提取随访日期中的月份l作为季节性参考;
(3)计算两次随访的时间间隔,计算方式为:
tp=diff(currentdate-lastdate)
其中currentdate表示此次随访时间,在模型训练时为当前的随访日期,用于预测时为当前的系统时间,lastdate表示上次随访的日期,diff是计算日期间间隔天数的一种表达形式;
(4)将病人编号,按日期从小到大的顺序排列,统计随访次数,每行的随访次数n的计算方式为:
n=lastn+1
其中,lastn等于上次随访的次数,每个病人的第一条数据n=1;
(5)患病天数的计算方式为:
nd=currentdate-firstdate
其中nd表示患病的总天数估计,为当前随访日期减去第一次随访的日期fisrtdate,用于预测时,currentdate为当前的系统时间;
(6)计算血压稳定性因子,选择方差和偏度:
其中,standarddeviation为偏差,skewness为偏度,lastdate血压的实际值,μblood为血压的平均值,σblood为血压的方差,t为实例的个数。
进一步,lmm模型的表达式为:
yblood=xcβ+zcbc+εc
该模型包含了固定效应和随机效应,其中xc表示a*p个固定效应矩阵,a表示实例个数,p表示维度,β表示p维未知的固定效应斜率,同理,zc和bc反映了不同个体层面上带来的随机影响。
进一步,lmm模型结合marginalr-square模型进行变量筛选。
进一步,多层逻辑回归拟合模型拟合步骤包括:
结合逻辑回归模型和多层线性模型推导多层逻辑回归的拟合函数:
水平1:yij=ρ0j+ρ1jxij+εij
水平2:ρ0j=γ00+γ01wj+θ0j
ρ1j=γ10+γ11wj+θ1j
其中水平1为重复测量的表达式,ρ表示水平1即整体水平上的拟合截距与斜率,水平2反应个体差异,yij表示高血压因变量,xij为每个人每次血压测量的预测变量,wj表示第二水平上个体的预测变量,γ的值为拟合的斜率和截距参数,εij为拟合误差,θ0j和θ1j分别表示截距和斜率在水平2上的差异,上述公式组合后得:
yij=γ00+γ01xij+γ01xijwj+θ0j+θ1jxij+εij
再结合逻辑回归的连接表达式,将有效数据和显著特征变量代入拟合。
进一步,需要进行随访推荐的患者包括:
(1)超过a个月未被随访的患者;(2)被确诊为高血压的患者在前期进行定期定次随访;(3)随访阈值在概率c以上且g天内未被随访过的患者。
本发明的有益效果:
(1)可行性强,该随访推荐模型主要基于随访的历史数据对患者血压变化情况进行预测,成本低,速度快。
(2)可控性强,随访推荐系统中有模块分成智能推荐和硬性约束两个模块,保障了病情的可控性。
(3)预测个性化,对每个不同的个体结合自身因素、人口因素和时间轴上的血压变化情况进行预测,能够使预测结果更加精确和个性化。
(4)灵活性强,采集的数据不需要是标准的时间序列,且不同病人的随访次数不需要相同,能够更灵活的对血压进行预测。
附图说明
图1为本发明的流程示意图;
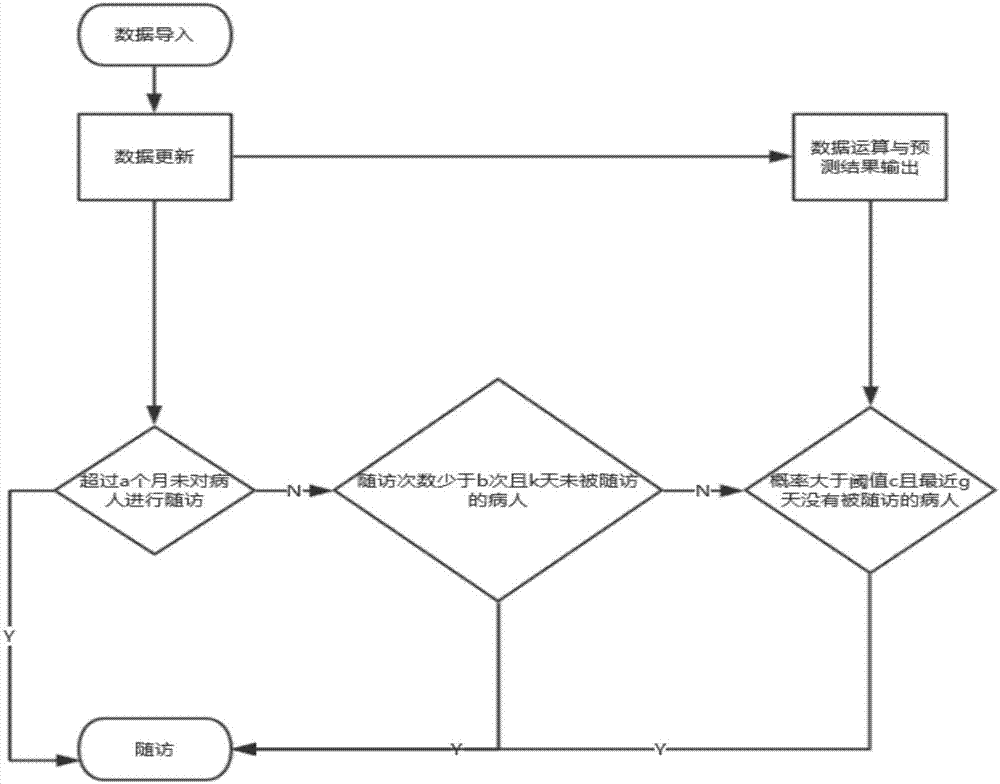
图2为本发明的随访推荐的流程示意图;
图3为本发明实施例的特征变量筛选结果部分示意图。
具体实施方式
下面结合具体实施例来对本发明进行进一步说明,但并不将本发明局限于这些具体实施方式。本领域技术人员应该认识到,本发明涵盖了权利要求书范围内所可能包括的所有备选方案、改进方案和等效方案。
参见图1,一种高血压病人随访推荐的方法,主要包含7个步骤。
步骤一:数据获取,首先提取并关联数据库中高血压病人的个人健康档案和随访后产生的潜在性血压影响因子,其中这些因子包括但不局限于病人编号、随访日期、性别、出生日期、身高、体重、职业、父亲家族史、兄弟姐妹家族史、子女家族史、随访方式、收缩压、舒张压、心率、烟龄、吸烟量、饮酒品种、饮酒量、运动情况、涉盐情况、饮食偏好、心理特征、遵医行为。
步骤二:对数据进行清洗以避免数据质量对预测结果带来负面影响。其中数据清洗的步骤包括以下几个方面:(1)变量转化:将数据库中的变量分别转化成对应的数值型变量、定类变量、定序变量和日期型变量。其中,数值型变量指变量的类型为数值型,定序型变量指根据定性原则区分总体各个案类别的变量,只有属性而无顺序之分,定序变量是在定类的基础上加上顺序对变量的影响的变量类型,另外日期格式的变量必须要转化成‘yyyy-mm-dd’的格式,其中’yyyy’表示年份,‘mm’表示月份,‘dd’表示日。(2)错误录入值和极端值过滤:针对类型变量直接移除类别频数小于n的行,以避免人工录入失误的影响,针对连续型变量如身高、体重、心率等因子,观察其分布情况后根据高斯概率密度函数:
其中j表示需要对变量进行过滤的数值型变量,xj表示变量的实际值,μj表示各变量的平均值,σj为各变量的方差。移除xu>μj-tσj,和xl<μj+tσj的行,其中xu,xl分别表示计算出的保留的上下区间,t表示方差的倍数,通过t值可计算保留数据的百分比。(3)缺失值处理,根据步骤一中采集到的数据,直接移除一条数据中同时丢失m个以上变量的行。对于同时缺失在m个以下的行数据,使用knn算法对缺失数据进行填充。根据欧几里得距离,其中xg,yg分别表示两个实例间各个变量的实际值:
选取k个相似的临近单位,针对类型变量用最常出现的值填充,连续型变量则用中位数填充。而后期的实施例中发现丢失值一般为健康档案中的类型变量,其丢失原因是出于对个人隐私的保护。(4)时间过滤:时间线是患者血压变化的最重要维度,因此需要过滤不符合预期的时间范围,且为了突出个体间的随机效应,需要选择固定时间范围内随访次数较多(j次)的个体。
步骤三:特征构建,通过数据库采集的数据不足以反应影响血压变化的全部特征,故依据现有数据构建以下特征。
(1)bmi=w/h^2,其中w表示患者的体重,h表示患者身高。
(2)经大量数据分析发现,很多病人高血压病发作存在季节性影响,尤其是气温差异较大时,患者更容易发病,因此提取随访日期中的月份l作为季节性参考。
(3)为反应高血压患者的血压在时间线上变化的情况,计算两次随访的时间间隔。计算方式为:
tp=diff(currentdate-lastdate)
其中currentdate表示此次随访时间,在模型训练时为当前的随访日期,用于预测时为当前的系统时间,lastdate表示上次随访的日期,diff是计算日期间间隔天数的一种表达形式。
(4)随访次数标识是计算稳定性因素所需的变量值,也可以从侧面反映出高血压患者病情的严重程度,例如相同时间间隔内,随访次数高意味着病情相对偏重。将病人编号,按日期从小到大的顺序排列,统计随访次数,每行的随访次数n的计算方式为:
n=lastn+1
其中,lastn等于上次随访的次数,每个病人的第一条数据n=1。
(5)患病天数的计算方式为:
nd=currentdate-firstdate
其中nd表示患病的总天数估计,为当前随访日期减去第一次随访的日期firstdate。用于预测时,currentdate为当前的系统时间。
(6)根据测量次数计算血压稳定性因子,这里选择方差和偏度:
其中xk血压的实际值,μblood为血压的平均值,σblood为血压的方差,t为实例的个数。
步骤四:特征筛选,为了使步骤三中采集的因子和步骤四创建的因子能够更好的预测患者血压的变化情况用lmm(线性最小模型)结合marginalr-square(边际模型)的方法对变量进行筛选。与传统的方法相比,lmm更适用于反映多次测量中个体的自相关性带来的影响,其表达方式如下:
yblood=xcβ+zcbc+εc
该模型包含了固定效应和随机效应,其中xc表示a*p个固定效应矩阵,a表示实例个数,p表示维度,β表示p维未知的固定效应斜率,同理,zc和bc反映了不同个体层面上带来的随机影响。通过对大量数据的观察和相关性计算发现收缩压更能左右工作人员决定下次随访的时间,因此使用收缩压作为拟合的目标函数,然后使用边际r-square来筛选变量。
步骤五:本发明更关注于预测病人血压超标的概率,而不在于精准预测高血压的值,且在预测概率时希望集合病人自身因素生成个性化定制的预测模型,并结合时间线对血压变化产生的影响,因此使用多层逻辑回归作为预测模型。首先对目标变量进行转化,通过判断病人的收缩压是否大于140,若小于140,标记为0,大于则标记为1。其次结合逻辑回归模型和多层线性模型推导多层逻辑回归的拟合函数:
水平1:yij=ρ0j+ρ1jxij+εij
水平2:ρ0j=γ00+γ01wj+θ0j
ρ1j=γ10+γ11wj+θ1j
其中水平1为重复测量的表达式,ρ表示水平1即整体水平上的拟合截距与斜率,水平2反应个体差异,yij表示高血压因变量,xij为每个人每次血压测量的预测变量,wj表示第二水平上个体的预测变量,γ的值为拟合的斜率和截距参数,εij为拟合误差,θ0j和θ1j分别表示截距和斜率在水平2上的差异,上述公式组合后得:
yij=γ00+γ01xij+γ01xijwj+θ0j+θ1jxij+εij
结合逻辑回归的
步骤六:根据患者最近一次的测量数据结合每日更新的数据(如时间相关的因子)作为预测值代入步骤五中的模型,计算病人血压超过正常值的概率。
步骤七:参见图2,首先获取数据并更新一部分数据例如当前的系统时间、随访次数等,再根据前六个步骤计算出血压超标概率结合更新的数据,对工作人员进行随访推荐,随访推荐包括三个判断模块:(1)第一个模块是对超过a个月未被随访的病人进行随访,这一模块是对患者安全性的约束,其意义是不论预测结果如何,工作人员必须对a个月以上未被随访过得病人进行随访。(2)第二个模块中,工作人员需要对被确诊为高血压的病人在前期进行定期定次,比如对随访次数少于b的患者每隔k天进行一次随访,一是在前期对患者的疾病起到强制的监控,二是保证有足够的数据来定制个性化的血压超标概率预测模型。(3)第三个模块通过更新时间和随访次数,结合患者上次随访的数据预测血压超标概率并按降序排序,根据预测概率的分布决定阈值,随访阈值在概率c以上且g天内未被随访过的病人。经大量数据总结发现,病人若在某次随访后发现其血压超过正常水平,工作人员会对其开具降压药品,且在较短的时间内进行再次随访,而短时间内病人的血压未出现过保持在超标水平的情况,所以参数g的设置是为了避免医疗资源的浪费。
具体应用实施例如下:
步骤一:从数据库获取数据,提取上一次随访的测量数据和人口相关数据,并更新相关的时间和随访次数信息为预测作准备。
步骤二:数据清洗
(1)在编程建模语言中分别将预测因子转化成适当的连续型数值变量,类型变量和日期型变量等。
(2)错误值和极端值过滤:针对数值型变量,移除x>μ-1.96σ,和x<μ+1.96σ的行以避免极端值和录入错误的值对模型造成的负面影响,其中±1.96倍方差截取中间95%的数据。例如心率在58-95之间的患者会被保留下来。
(3)缺失值处理,首先过滤掉每条数据同时丢失在m个以下的行,此处经对实施例数据的观察与分析,令m=3,即同时缺失在三个以上变量的行视为数据质量差被直接移除,剩余的变量用knn算法进行填充,经观察发现,丢失变量均为健康档案的类型数据变量,丢失原因是出于对个人隐私的保护,针对类型变量,使用k临近条数据中的众数进行填充,此处为平衡准确率和运算效率,使k值=10。
(4)时间维度过滤,取2016年-2017年6月份随访次数j在10次以上的病人。步骤三:按照规定对数据进行特征构建。
通过步骤一、二、三得到有效数据188494条和变量38个。
步骤四:通过lmm模型对变量进行筛选,其运行结果的部分截图如图3,其中第一列表示变量名称,第二列表示估计的参数值,第三列表示估计的方差,四五列分别表示tvalue和pvalue。
通过变量筛选发现,患者的性别、年龄、运动情况、心理特征、bmi、随访月份、职业、吸烟情况、遵医行为、血压偏度和服药次数等变量均显著,应该保留并用其构建多层逻辑回归模型。
步骤五:用步骤四中筛选的变量拟合多层逻辑回归模型。
步骤六:根据患者最近一次的测量数据结合步骤一中更新的数据(如时间相关的因子)作为预测值代入步骤五中的模型,计算病人血压超过正常值的概率。
步骤七:经过专家咨询、对实施例数据和步骤六中输出结果的分析得出,工作人员需要对以下三种患者进行随访:(1)超过三个月未被随访的病人。(2)随访次数不到10次的病人需要在随访间隔k达到30天时进行一次随访。(3)工作人员需要对当日预测的血压超标概率c超过70%且最近随访天数g超过15天的病人进行随访。
步骤七中的部分且具有代表先的结果呈现如下:
- 还没有人留言评论。精彩留言会获得点赞!