用于处理音频信号的方法和装置与流程
本发明涉及用于处理音频信号的方法、装置和系统。
本发明可广泛用于各种音频处理系统,例如音频广播系统、音频通信系统、语音识别系统、音频重建系统和播音系统,还可用于音频处理装置如听力装置。
背景技术:
到达听者耳朵的声信号通常为源自不同声源的几个声音的混合。人类听觉系统利用接收到的声音中的大量同时存在及相继出现的线索以使它们与同时接收到的其它声音分离(Bregman1990)。按时间和频率组合线索的能力还使能正确解释所接收的声音,尤其对于正常听力听者而言,即使在这些声音大幅度降级时,例如因被其它声音掩蔽或因经具有不良传输特性的信道传输而引起。
声音的时域精细结构(TFS)携载线索,其在一些情形下对听者识别和定位声源及理解声音的含义至关重要(Hopkins,Moore and Stone2008)。TFS还携载使声音能与多个声源分离的线索。例如,Andersen和Kristensen已发现正常听力听者在具有3个空间上分隔的讲话者的困难听音情形下在语音识别阈值方面受益于单耳和双耳TFS线索(Andersen et al.2010)。
最近的实验已表明,相比于正常听力听者,听力受损听者对声信号中的TFS线索的敏感性降低(Hopkins and Moore2007;Moore and Sek2009),及在同时有两个讲话者的困难听音情形下不太能够利用TFS线索(Hopkins,Moore and Stone2008;Lunner et al.2011)。TFS1测试(Moore and Sek2009)中的刺激以正感觉级呈现(即高于个人听觉阈),因而可能不会因刺激的可听性有限而引起敏感性降低,尤其是,正常听力听者的表现不会随着感觉级增加而改善(Moore and Sek2009)。此外,有越来越多的证据表明老化也会导致限制使用TFS线索(Hopkins and Moore2011;Ruggles,Bharadwaj and Shinn-Cunningham2011)。
自然发出的声音通常为时变信号,其频谱分量占听得见的频率范围的相当宽的一部分。为有助于从声音解码线索,所有其频谱分量应更适合无失真地传给听者。然而,这并非总是可能。例如,有用声音的声谱的部分被其它声音或噪声掩蔽和/或被频带有限的声音传输信道衰减非常普遍。
不好的信号质量降低人听觉系统正确解码声音中的线索的能力。为补偿该种降低,听者必须利用认知技能及例如利用所讲话语中的冗余以理解说了什么。不好的声音质量因而可明显降低可懂度并可导致误解,而且使听者紧张并降低听者的一般知觉。因此,许多音频系统包括用于减少或防止处理后的声音中的噪声的装置及用于避免频谱分量在窄带传输期间损失的装置。传统用于实现前述声音质量改善的方法包括降噪、使用定向传声器及使用带宽压缩和解压缩算法。
在助听器中,使用降噪和定向传声器使能通过衰减假定听者不感兴趣的音频信号而增加信噪比(SNR)。关于对什么感兴趣的决定可基于假定目标(有用声音的源)在听者前面而掩蔽声源(噪声源)在听者后面,参见(Boldt et al.2008),和/或基于语音和噪声之间的辨别,参见(Elberling,Ekelid and Ludvigsen1991)。在符合这些假定的许多情形下,前述方法对听力受损听者有益。然而,在其它情形下,前述方法仅可提供有限的益处,例如如果所有声音均为语音并出现在听者前面时。此外,如果听者实际上有兴趣注意多个声源,部分声源的衰减可能不利。
频率变换和非线性频率压缩(Neher and Behrens2007)可在不符合上面提及的假定的情形下增强听力受损听者接近多个声源。类似的益处可通过增强与临界频带压缩截然不同的频谱而实现(Yasu et al.2008),其中每一临界频带的频率含量被压缩以减小基膜激励的宽度,因而减小频谱掩蔽效应。然而,前述方法的常见的副作用是声音的分音之间的和声关系被破坏。
应注意,在本说明书中,术语“分音”指基频及其在合成频谱中的和声或泛音。
相较轻声的声源,听者通常趋于更注意大声的声源。因而,众所周知且非常简单的、用于增加语音可懂度的手段是增加其相对于其它声音的响度。同样的手段应用于希望吸引听者注意的其它有用声音。然而,有用声音的声压级的简单增加并非总是可行。例如,其可能导致功耗增加和/或音频系统失真、更早出现听者疲劳、干扰其余的人、伴随有用声音的噪声的放大等。
人通常能够根据声音的响度对其排序,这是感知的声音强度的主观度量。当两个声源位于一样远的地方时,听者通常以与从相应声源接收的声音响度同阶地对声源强度定级。如果到声源的距离不同,听者通常在对声源强度定级时潜意识补偿不同传输通路的效果。因而,听者通常能够正确定级比近处的弱声源更强的远处的大声声源,即使在听者实际上以比来自大声声源的声音更高的声压级从弱声源接收声音时。
上面描述的人补偿不同距离的能力背后的机制尚未完全知道。John M.Chowning提出了称为“听觉透视”的模型作为理解一些机制的基础(Chowning2000)。根据Chowning,听者的听觉系统使用所接收的声音中的各个线索将声音源放在不同距离处并确定声源的响度,类似于视觉系统运行。Chowning提出有用的响度或距离线索可包括频谱包络形状、音色清晰度和回响量。
在本专利申请的上下文中,上面描述的、感知的声源强度的主观度量称为“表观响度”。换言之,声源的表观响度为在(潜意识)补偿声源和听者之间的距离之后感知的声源强度的主观度量。相应地,声音的表观响度等于产生该声音的声源的表观响度。
Moore的响度模型试图提供主观感知的响度的客观度量。其将给定声音的响度预测为每一临界频带的响度的和,其中每一临界频带的响度计算为临界频带中的信号成分的能量总和。该模型包括听觉系统执行的电平压缩(Moore andGlasberg2004)。该模型的简化版本为:
(1)
其中,L为按dB计的响度,C为临界频带的数量,K(c)为每一临界频带内的中心频率组,F为压缩耳蜗函数,及A为相应临界频带内的频谱量值。该模型的应用要求频谱以相对于临界带宽足够的频率分辨率进行采样。Moore的响度模型不包括距离补偿因而不预测表观响度。
在更早的文章中,Chowning公开了一种用于合成乐器的声音的方法,其中声音借助于组合调频(FM)和调幅(AM)产生(Chowning1973)。调制通过一组参数控制,这些参数例如指明声音的持续时间、振幅、载频、调制频率和调频指数(FM指数)。Chowning发现一些合成乐器声音的明亮尤其是合成的铜管乐器声音的明亮可通过随时间变化改变FM指数而得以实质性改善。提出的变化相当简单,例如线性、指数及双曲线偏移,并可通过在由参数集中的几个参数控制的发生器中产生FM指数信号而获得。随时间变化改变FM指数对合成声谱的时间变化具有实质影响,及Chowning假设,相较频率分量的振幅曲线,频率分量随时间变化演变的一般特性对合成声音的主观印象更重要。Chowning还公开了多个参数集,其可用于实现几个不同类型的乐器的逼真合成。时变调制指数的开始和/或结束点通常约为1或更大。随后,Chowning使用同样的方法但不同的调制信号改善话音的合成(Chowning1980)。
Lazzarini和Timoney公开了上面提及的FM合成的变体,称为改进型调频(ModFM)(Lazzarini and Timoney2010)。ModFM基于经典FM原则的改进版并产生已调频的信号,其中,相较经典FM,频谱分量的分布以与调频指数之间更加可预测的关系变化。这使ModFM能提供乐器的更自然发声的合成。
Chowning也指出,FM的原理和FM指数对已调制信号的频谱成分的影响在无线电信号传输领域众所周知。在该领域,具有高于1的调制指数的调频通常称为“宽带调频”。
最简单形式的口头交流涉及讲话人(讲话者)和听话的人(听者)。讲话者将消息变换为语音即声音,并将语音传入空气中。在空气中,语音在到达听者耳朵之前通常与其它声音混合。为理解该消息,听者必须从声音混合导出或解码该消息。解码过程中的差错可明显导致消息的曲解。
语音的物理发生是一个复杂的过程,其涉及讲话者的具有声带和声道的喉。目前技术发展水平表明,慢的、关联的FM和AM在自然语音中产生(Teager1980;Teager and Teager1990;Bovik,Maragos and Quatieri1993;Maragos,Kaiser and Quatieri1993A;Maragos,Kaiser and Quatieri1993B;Zhou,Hansen and Kaiser2001),及FM线索对于使正常听力听者能在具有负SNR的情形下解码语音很重要,而FM提取对于耳蜗受损的人员可能被削弱(Moore and Skrodzka2002;Heinz et al.2010)。然而,听力受损听者可利用AM线索(Hopkins,Moore and Stone2008)。
在具有竞争声音的情形下,讲话者趋于修改他们的话音以增加其话音的清晰度。这通常称为发音努力,清晰语音(Lindblom1996)或在1909年发现Lombard效应之后称为Lombard效应。Lindblom报告了在短持续时间元音中,第二共振峰的中心频率偏离其目标值(Lindblom1996)。Folk报告了基频(f0)的平均和动态范围随噪声级增加而增加,与平均强度和该强度的动态范围一样,同时讲话速率降低(Folk and Schiel2011)。对于许多自然声音,强度增加也伴随带宽增加(Chowning2000)。讲话者的话音与噪声级之间的这种关系是自动语音识别(ASR)的主要难题。例如,ASR系统不能通过向其馈送从纯语音库和噪声库混合的声音而简单地进行可靠的测试(Winkler2011)。
Potamianos或Maragos公开了语音分析和合成方法,其中语音通过AM-FM调制的信号的和建模,每一信号表示语音共振峰(Potamianos and Maragos1999)。
还从耳蜗植入(CI)型助听器知道,音频信号可通过提取FM信息并在具有相对窄带宽的FM调制的载波信号中呈现该信息而使得可用于助听器用户(Nie,Stickney and Zeng2005;Zeng et al.2005;Zeng and Nie2007)。
技术实现要素:
本发明的目标在于提供没有上面提及的缺点的、用于处理音频信号的方法。
本发明的另一目标在于提供没有上面提及的缺点的、用于处理音频信号的装置和系统。
本发明的这些及其它目标由独立权利要求中限定的及下面描述的发明实现。本发明的另外的目标由从属权利要求中限定的及下面详细描述的实施方式实现。
本发明基于发明人发现的一些令人惊讶的发现,即:
-人发音系统产生具有快速FM调制的语音(通常除慢速及可能关联的FM和AM调制之外),其中快速FM调制的FM指数与发音努力关联变化,即与讲话者希望将要传输的消息怎样鲁棒和清楚相关联;
-FM指数因而发音努力与语音的表观响度关联;
-宽范围的自然出现的声音的表观响度可通过改变这些声音的快速FM调制的FM指数进行改变;及
-人听觉系统好像直接从声音的快速FM调制的FM指数解码表观响度和发音努力的线索。
换言之,改变声音的快速FM调制的FM指数影响声音的频谱成分,即听者直接解释为改变声音的表观响度及在声音为语音的情形下解释为改变发音努力。
此外,增加FM指数使得快速FM调制中的重要边带的数量增加,因而导致信号信息跨更宽频率范围扩展,然而并未增加声音强度。
在本说明书中,“快速FM调制”指调制速率高于60Hz的FM调制。遇到自然出现的声音如语音的快速FM调制速率通常位于60Hz和几千Hz之间的频率范围内。
这些新的发现使能解释多种不同的新的音频信号处理方法、装置和系统,这些方法、装置和系统没有上面提及的缺点且相较于现有技术还提供其他重要优点。这些方法、装置和系统可使听力受损听者和/或正常听力听者受益。
这些方法、装置和系统对其起作用的音频信号通常可由一组时变信号表示,包括调幅信号、载频信号、基音信号及调频指数信号(或缩写为“FM指数信号”)。在下面,前述的一组记为“扩展的FM表示”或缩写为“XFMR”。在包括声音的XFMR中,调幅信号通常表示声音包络,及基音信号通常表示基频和/或声音的基音。
对应地,术语“XFM解调”和“XFM分析”或缩写“XFMA”指从音频信号的单一波形表示确定音频信号的XFMR的过程,及术语“XFM调制”和“XFM合成”或缩写“XFMS”指从音频信号的XFMR产生或合成音频信号的单一波形表示。此外,术语“XFMR信号”指XFMR中的四个时变信号中的任何一个。
还应注意,载频信号、基音信号和FM指数信号一起表示音频信号的TFS。
在本说明书中,术语“音频信号”指声音的任何可处理的表示,例如模拟电信号或数字信号。应注意,XFMR因而也是音频信号。
此外,“听力装置”指适于改善或增加个人的听觉能力的装置如助听器或有源耳朵保护装置,其通过从个人的环境接收声信号、产生对应的音频信号、修改音频信号并将修改后的音频信号作为听得见的信号提供给个人耳朵的至少一只耳朵而实现。前述听得见的信号可以下述形式提供:辐射到个人外耳内的声信号、作为机械振动通过个人头部的骨结构传到个人内耳的声信号、和/或直接或间接传到个人耳蜗神经的电信号。听力装置可构造成以任何已知的方式进行佩戴,如安排在耳后的单元,具有将辐射的声信号导入耳道的管或具有安排成靠近耳道或位于耳道中的扬声器;或整个或部分安排在耳廓和/或耳道中的单元;连到植入颅骨的固定装置的单元等。更一般地,听力装置包括用于从个人的环境接收声信号并提供对应的输入音频信号的输入变换器、用于处理输入音频信号的信号处理电路、及用于根据处理后的音频信号将听得见的信号提供给个人的输出变换器。
“听力系统”指包括一个或两个听力装置的系统,及“双耳听力系统”指包括一个或两个听力装置并适于以一定关联和/或协作度向个人的两只耳朵提供听得见的信号的系统。听力系统或双耳听力系统还可包括“辅助装置”,其与听力装置通信并影响和/或受益于听力装置的功能。辅助装置可以是遥控器、音频网关设备、移动电话、播音系统、汽车音频系统或音乐播放器。听力装置、听力系统或双耳听力系统可用于补偿听力受损人员的听觉能力损失、增强正常听力人员的听觉能力和/或保护人的听觉系统。
除非明确指出,在此所用的单数形式的含义均包括复数形式(即具有“至少一”的意思)。应当进一步理解,说明书中使用的术语“具有”、“包括”和/或“包含”表明存在所述的特征、整数、步骤、操作、元件和/或部件,但不排除存在或增加一个或多个其他特征、整数、步骤、操作、元件、部件和/或其组合。应当理解,除非明确指出,当元件被称为“连接”或“耦合”到另一元件时,可以是直接连接或耦合到其他元件,也可以存在中间插入元件。如在此所用的术语“和/或”包括一个或多个列举的相关项目的任何及所有组合。除非明确指出,在此公开的任何方法的步骤不必须精确按所公开的顺序执行。
附图说明
本发明将在下面参考附图、结合优选实施方式进行更详细地说明。
图1A和图1B示出了已知的基本FM调制器的例子。
图2示出了根据本发明第一实施例的扩展的FM调制器。
图3示出了根据本发明第二实施例的XFMR修改器。
图4和图5示出了本发明另外的实施例的细节。
图6示出了本发明的另外的实施例中包括的FM解调器的第一实施例。
图7示出了图6的FM解调器的第二实施例。
图8示出了本发明的另外的实施例中包括的FM分析器的第一实施例。
图9示出了图8的FM分析器的第二实施例。
图10示出了根据本发明实施例的XFM处理器。
图11示出了根据本发明实施例的语音合成器。
图12示出了根据本发明实施例的音频处理装置。
图13示出了本发明另外的实施例中包括的另外的解调。
图14示出了本发明另外的实施例中包括的语音增强的实施例。
图15示出了本发明另外的实施例中包括的语音增强的另外的实施例。
为清晰起见,这些附图均为示意性及简化的图,它们只给出了对于理解本发明所必要的细节,而省略其他细节。在所有附图中,同样的附图标记用于同样或对应的部分。
通过下面给出的详细描述,本发明进一步的适用范围将显而易见。然而,应当理解,在详细描述和具体例子表明本发明优选实施例的同时,它们仅为说明目的给出。对于本领域的技术人员来说,从下面的详细描述可显而易见地在本发明范围内进行各种变化和修改。
具体实施方式
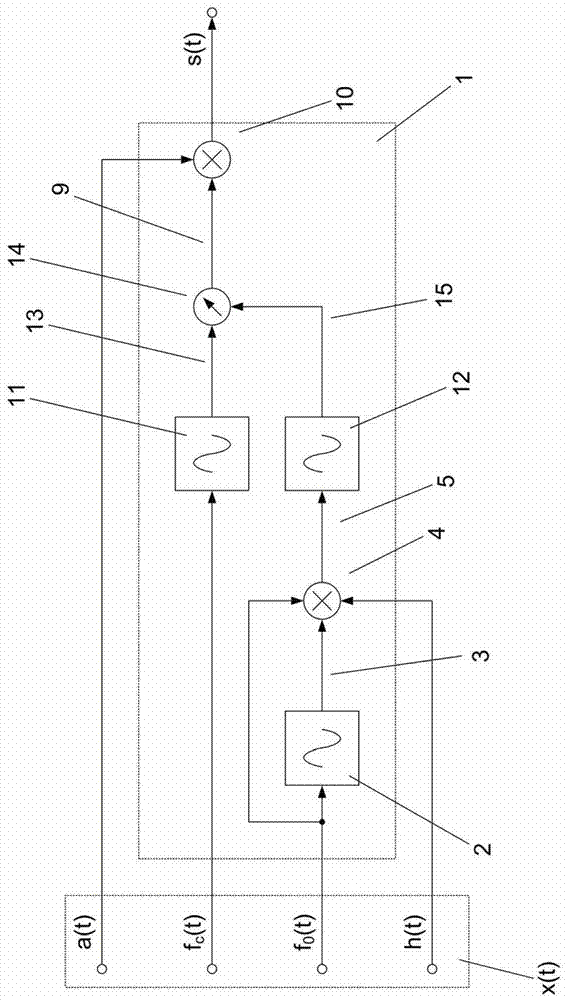
图1A示出了现有技术中已知的例如从Chowning1973知道的基本FM解调器1的功能框图。基本FM调制器1把将要合成的音频信号的XFMR x(t)取为输入并将频率和振幅调制的波形音频信号s(t)提供为输出。XFMR x(t)包括调幅信号a(t)、载频信号fc(t)、基音信号f0(t)和FM指数信号h(t)。基音信号f0(t)控制振荡器2,其提供对应于基音信号f0(t)的具有恒定振幅和频率的输出信号3。振荡器2的输出信号3在乘法器4中与基音信号f0(t)和FM指数信号h(t)相乘,从而在调频信号5中提供所得的积。调频信号5在加法器6中与载频信号fc(t)相加,从而在频率信号7中提供所得的和。频率信号7控制振荡器8,其提供对应于频率信号7的、具有恒定振幅和频率的输出信号9。振荡器8的输出信号9在乘法器10中与调幅信号a(t)相乘,将所得的积提供在已调制音频信号s(t)中。
作为备选,图1B中所示的基本FM调制器1的已知实施,载频信号fc(t)和调频信号5中的每一个控制相应的振荡器11、12,及由载频信号fc(t)控制的振荡器11的输出13在移频器中移频等于由调频信号5控制的振荡器12的输出15的量。移频后的信号9近似对应于图1A中的振荡器8的输出信号9。
在两个实施例子中,调幅信号a(t)控制已调制音频信号s(t)的时变振幅。载频信号fc(t)控制已调制音频信号s(t)的时变中心频率,基音信号f0(t)控制已调制音频信号s(t)调频中边带之间的时变频谱距离,及FM指数信号h(t)控制已调制音频信号s(t)中能量的时变频谱分布。
图2的功能框图示出了根据本发明第一实施例的扩展的FM调制器20(XFM调制器)。除了图1A的基本FM调制器1的功能模块之外,XFM调制器20还包括乘法器21,其使所接收的XFMR x(t)的FM指数信号h(t)与第一增益信号g1(t)相乘并将所得的积提供在馈给乘法器4的修改后的FM指数信号h’(t)中。FM指数信号h(t)的振幅因而可通过将第一增益信号g1(t)设置为不同于1的值而进行修改,即放大或衰减。由于修改后的FM指数信号h’(t)控制已调制音频信号s(t)中能量的频谱分布,第一增益信号g1(t)可用于改变该频谱分布。
由XFM调制器20接收的输入优选为已从输入波形音频信号i(t)解调的XFMR x(t)(参见图6-9)。因而,XFM调制器20可用于提供对应于输入音频信号i(t)的已调制音频信号s(t),然而,具有不同的信号能量频谱分布。
放大FM指数信号h(t)的直接效果是已调制音频信号s(t)的信号功率跨更大频率范围扩展,然而并未改变总信号功率及未改变信号中携载的信息量。另一效果是不同频率范围之间的信息冗余增加,因而已调制音频信号s(t)在随后增加频带有限的噪声或频带有限的信号衰减时更鲁棒。信息冗余的增加主要涉及TFS和TFS携载的线索。另一效果是已调制音频信号s(t)的表观响度增加。正常听力听者及听力受损听者均可受益于这些效果。在随后的音频信号处理中,如果已调制音频信号s(t)与频带有限的噪声或其频谱被衰减的部分混合,信号功率的扩频增加通常将增加两组听者从处理后的信号解码TFS线索的能力。如果受损频带与初始输入音频信i(t)号的频带重叠,具有频带有限的听力受损的听者显然也可受益于扩频增加。表观响度增加也使听者更容易将其注意力集中在声音和/或其来源上。
在音频处理方法和系统中用于改善声音质量的传统解决方案通常追求的目标为增加预期将出现重要线索的那些频区中的SNR。这也是助听器中的情形,其中通常一个或多个频带被放大以增加声音相比竞争噪声的可听性。然而,放大输入音频信号i(t)的FM指数信号h(t)通常起相反作用。如果保持竞争宽带噪声的频谱功率密度,FM指数信号h(t)的放大通常减小包含输入音频信号i(t)的基频的频带内的SNR。
因而,放大FM指数信号h(t)使能增加语音可懂度非常出乎意料。本发明方法通常使能增加TFS传送的线索的可达性、增加声音的可听性、及补偿宽范围的听力受损。
相反地,衰减FM指数信号h(t)的直接效果是已调制音频信号s(t)的信号功率集中在更小的频率范围内,但并未改变总信号功率及未改变该信号中携载的信息量。该更小频率范围内的SNR通常增加。由于带宽更小,已调制音频信号s(t)可由具有比初始输入音频信号i(t)小的带宽的方法或装置处理。处理后的信号随后可遭遇FM指数信号h(t)的放大以恢复更宽的带宽。此外,音频信号的表观响度降低,这通常导致听者不太注意音频信号,因而发现其不太明显或烦扰。然而,对于一些听力受损听者,已调制音频信号s(t)的带宽更小至少可部分补偿听觉系统的降低的频率选择性,因而帮助他们解码TFS。
个体听者是否和/或在哪些情形下可受益于FM指数信号h(t)的放大或衰减的估计例如可基于适当的临床测试进行。
作为备选,XFM调制器20中包括的基本FM调制器1可按图1B中所示实施,或实施为本领域已知的任何其它适当的FM调制器。ModFM调制器(Lazzarini and Timoney2010)为前述适当的FM调制器的例子。
图3示出了根据本发明第二实施例的XFMR修改器30的功能框图。XFMR修改器30接收XFMR x(t)并提供具有调幅信号a(t)、载频信号fc(t)、基音信号f0(t)和修改后的FM指数信号h’(t)的、修改后的XFMR x’(t)。修改后的XFMR x’(t)中的前三个XFM信号a(t)、fc(t)、f0(t)等于所接收的XFMR x(t)中的对应XFM信号,而修改后的FM指数信号h’(t)等于所接收的XFMR x(t)的FM指数信号h(t)与第一增益信号g1(t)的积。与图2中的XFM调制器20类似,XFMR修改器30包括乘法器21,其使FM指数信号h(t)与第一增益信号g1(t)相乘因而提供修改后的FM指数信号h’(t)。
修改后的XFMR x’(t)可提供给基本FM调制器1或XFM调制器20以提供已调制音频信号s(t)。因此,FM指数信号h(t)的振幅的修改和修改后的XFMRx’(t)的产生可在第一装置中进行,其后修改后的XFMR x’(t)借助于适当的测试装置如有线或无线传输电路例如光学或射频发射器和接收器电路(未示出)传给第二装置。在第二装置中,(X)FM调制器1、20(即基本FM调制器1或XFM调制器20)则可从所接收的修改后的XFMR x’(t)提供已调制音频信号s(t)。
另外或作为备选,FM指数信号h(t)的振幅的修改和修改后的XFMR x’(t)的产生可在第一时刻进行,其后修改后的XFMR x’(t)借助于适当的存储装置如光学、电子或磁性存储装置(未示出)例如在第一或第二或第三中间装置中保存一段时间。在第二时刻,修改后的XFMR x’(t)可从存储装置取回并提供给(X)FM调制器1、20以从所取回的修改后的XFMR x’(t)提供已调制音频信号s(t)。
另外或作为备选,在FM指数信号h(t)的振幅的修改和修改后的XFMR x’(t)的产生之前,输入XFMR x(t)可能已以类似的方式从临时存储器取回和/或从另一装置取回。
根据本发明的具体应用,可以任何顺序级联任何数量的XFMR修改器30、传输装置和/或存储装置。
在不同装置和/或位置中和/或在不同时刻执行FM指数信号h(t)的振幅的修改及提供已调制音频信号s(t)显然在许多类型的音频处理方法和装置中均有益处。此外,相较传输和/或保存输入音频信号i(t),传输和/或保存XFMR x(t)和/或修改后的XFMR x’(t)通常需要较少的传输带宽或存储容量,取决于XFMRx(t)和/或修改后的XFMR x’(t)表示输入音频信号i(t)的多少频谱分量。
如图4中所示,另外的乘法器42、43、44可用于在如图2和3中所示的FM调制、传输和/或存储之前使XFM信号a(t)、fc(t)、f0(t)与相应增益信号g2(t)、g3(t)、g4(t)相乘。除了乘法器21之外,XFM调制器20或XFMR修改器30因而可包括乘法器42、乘法器43、乘法器44、乘法器42和43、乘法器42和44、乘法器43和44、或所有乘法器42、43和44。
此外,任何前述乘法器42、43、44或其任何组合可以类似的方式包括在基本FM调制器1中或用于修改XFMR x(t)的电路中,然而没有乘法器21,例如用在包括XFM调制器20或XFMR修改器30的音频处理系统中。
调幅信号a(t)例如借助于乘法器42进行的放大和衰减对应于相应放大和衰减声音。因而,这可用作放大和/或衰减信号链的其它部分中的声音的备选方案。
载频信号fc(t)例如借助于乘法器43进行的放大和衰减对应于置换声音,分别为频率向上和向下。这可用于将声音移到听力受损听者更好感知、不易干扰、在传输时较少衰减和/或与其它有用声音占用的频率范围无重叠的频率范围。
基音信号f0(t)例如借助于乘法器44进行的放大和衰减对应于分别放大和衰减声音的基音的频率变化。这使能控制语音的颤音和语调水平,其对帮助听力受损听者正确感知和解码语音有帮助。
基音信号f0(t)放大2以上的整数值G4导致声音分音之间的距离相应增加,然而并不破坏声音内的和声关系。分音之间的距离增加可使那些相较正常听力听者遭受更宽听觉带宽的听力受损听者能分辨更多的分量,因而更好地解码语音及其它声音。为保留所得声音的带宽,FM指数信号h(t)可被衰减值G1,例如通过将第一增益信号g1(t)设置为等于G1。所需衰减G1可从卡森(Carson)规则计算:
(2)BW=(Δf+fm),
其中BW为带宽,Δf为峰值频率偏差,及fm为调制信号中的最高频率。在本说明书中,等式(2)可被重写以获得XFMR x(t)的带宽BW:
(3)BW=2(M·F+F)=2(M+1)F,
其中M为FM指数信号h(t)的最大值,及F为基音信号f0(t)的最大值。对应地,修改后的XFMR x’(t)的带宽BW’为:
(4)BW′=2(G1M+1)G4F,
将修改后的XFMR x’(t)的带宽BW’设置为等于XFMR x(t)的带宽BW,得出:
(5)2(G1M+1)G4F=2(M+1)F,
对G1求解等式(5),得出:
(6)G1=((M+1)/G4-1)/M,
载频信号fc(t)和/或基音信号f0(t)的放大和衰减不改变各个声音的频率分量之间的和声关系,因而相较现有技术方法可导致修改后的音频信号中的非自然信号更少。
如图5中所示,多个音频信号s1(t),s2(t)...sN(t)可在加法器50中组合以提供合成音频信号c(t),其表示来自一个以上声源的声音和/或来自一个声源的多个声音。前述音频信号s1(t),s2(t)...sN(t)中的每一个可以是来自基本FM调制器1的已调制音频信号s(t)、来自XFM调制器20的已调制音频信号s(t)或任何其它类型的音频信号。音频信号s1(t),s2(t)...sN(t)中的至少一个的FM指数信号h(t)的振幅在使信号相加之前按上述进行修改。这使能相对于合成音频信号c(t)中来自其它声源的声音强调或削弱来自个别声源的声音,和/或相对于彼此强调或削弱来自单一声源的多个声音。如果音频信号s1(t),s2(t)...sN(t)中的多个的FM指数信号h(t)的振幅按上述修改,前述修改可个别地进行,这使在“设计”所得声画时具有更大的自由度。
临界频带压缩可这样实现:为源自一个以上声源的两个以上声音中的每一个提供XFMR x(t)并包括在输入音频信号i(t)中、对一个以上XFMR x(t)衰减FM指数信号h(t)、从修改后的XFMR x’(t)提供相应的已调制音频信号s(t)并将已调制音频信号s(t)组合为合成音频信号c(t)。衰减FM指数信号h(t)将减少每一声音和/或声源使用的带宽,但并不破坏每一声音内所得分音之间的和声关系。该临界频带压缩方法因而相较现有技术解决方案具有较少副作用。尽管他们的兴趣不在临界频带压缩及临界频带压缩未被直接测试,Oxenham等最近的实验(Micheyl,Keebler and Oxenham2010)表明听力受损听者可受益于上面公开的临界频带压缩。
如果部分或所有已调制音频信号s(t)具有一样的调幅信号a(t),作为备选,前述信号的已调频部分可在图2中的振荡器8和乘法器10之间的信号通路中的加法器(未示出)中加在一起或组合,使得前述信号的XFM调制器20在与共同的调幅信号a(t)相乘时共享乘法器10。所得的已调制音频信号随后可在图2的加法器50中与其他已调制音频信号s(t)相加。
图6示出了可包括在本发明的另外的实施例中的XFM解调器60的功能框图。XFM解调器60将输入波形音频信号i(t)取为输入并将输入音频信号i(t)的XFMR x(t)提供为输出。输入音频信号i(t)例如可以是模拟电信号或采样的数字信号的形式。
第一AM解调器61接收输入音频信号i(t)并将其分解为调幅信号a(t)和第一相位信号62,调幅信号表示输入音频信号i(t)的瞬时振幅,第一相位信号表示输入音频信号i(t)的瞬时相位。
第一相位信号62提供为第一锁相环(PLL)63的输入,其具有足够低的时间常数以使其能跟随输入音频信号i(t)中的最快预期频率变化。对于语音,前述频率变化通常位于高达基音的约10或20倍的范围内。第一PLL63以已知方式运行并提供频率信号64,其表示第一相位信号62因而输入音频信号i(t)的瞬时频率。低通滤波器65接收频率信号64并通过急剧低通滤波确定载频信号fc(t),例如12dB/倍频程或24dB/倍频程,对频率信号64具有相当低的截止频率如约10Hz、约20Hz或约50Hz。减法器66将调频信号67确定为频率信号64和载频信号fc(t)之间的差。积分器68将调频信号67积分为规格化的调频信号69。积分器68进行的积分对应于图2的乘法器4中修改后的FM指数信号h’(t)与基音信号f0(t)相乘的反运算。
第二AM解调器70将规格化的调频信号69分解为表示规格化的调频信号69的AM部分的FM指数信号h(t)和表示规格化的调频信号69的FM部分的第二相位信号71。第二相位信号71提供为第二PLL72的输入,其具有适于使其能跟随规格化调频信号69中的最快预期频率变化的时间常数,如基音变化。对于语音,基音变化通常位于高达约500Hz或约1000Hz的范围内。第二PLL72以已知方式运行并提供基音信号f0(t),其表示第二相位信号71的瞬时频率。第二PLL72的唯一功能是将第二相位信号71转换为频率信号。因而如果XFMR x(t)将被保存以随后进行处理和/或将被传给另一装置以在那里进行处理,则其可省略。在该情形下,XFMR x(t)的基音信号f0(t)为时变相位信号的形式。如果XFMR x(t)的进一步处理需要,例如PLL中的相位到频率的转换可在从存储器取回之后和/或在XFMR x(t)被传给其的装置中进行。
在图7中所示的备选实施例中,积分器68已被省略,来自第二PLL72的AM部分输出73在除法器74中除以基音信号f0(t)以获得FM指数信号h(t)。
在两实施例中,第一和第二AM解调器61、70中的每一个可应用任何已知的用于将相应信号分解为AM部分和FM部分的方法,不必须是相同的方法。许多前述方法在本领域众所周知(例如参见Kubo et al.2011for a summary)。一些已知方法基于经希尔伯特变换(Hilbert Transformation)获得的分析信号。另外的已知AM-FM分解方法为分立能量分离算法(Discrete Energy Separation Algorithm(DESA))(Bovik,Maragos and Quatieri1993;Maragos,Kaiser and Quatieri1993A;Maragos,Kaiser and Quatieri1993B),其基于假设信号x(t)由简单弹性体系统产生,这使DESA能根据与动能和势能分离类似的原理将信号分离为AM和FM调制器。同样,基于PLL的AM-FM分解方法也已知(Wang and Kumaresan2006;Smith2006)。使用PLL的分解对应于在控制理论中应用正弦信号模型(Ljung2000)。作为备选,可应用更复杂的信号模型。此外,控制理论可由备选学习模型代替(参见Jordan1998)。
作为备选或另外,载频信号c(t)和/或基音信号f0(t)可使用现有技术中已知的基音跟踪器从输入音频信号i(t)估计,例如YIN(de Cheveignéand Kawahara2002)。前述估计可用于估计其余XFMR信号,即调幅信号a(t)和FM指数信号h(t),在该情形下,XFM解调器60可部分或完全省略。作为备选,前述估计量可与XFM解调器60的对应输出比较,即载频信号fc(t)和/或基音信号f0(t),及比较结果可用于自适应调节滤波器参数,如XFM解调器60的滤波器61、65、70和PLL63、72的截止频率和时间常数,以提高XFM解调的准确度。
在XFMR x(t)或修改后的XFMR x’(t)将在ModFM调制器中进行调制的情形下(Lazzarini and Timoney2010),输入音频信号i(t)也应优选根据ModFM的原理进行解调,其可产生与上面公开的XFM解调器60稍微不同的载频信号fc(t)、基音信号f0(t)和FM指数信号h(t)值。因而,ModFM解调需要对XFM解调器60进行相应修改。
当输入音频信号i(t)仅包括一个声音时,其也不是太复杂,XFM解调器60,如在图6或7所示的实施例中可用于直接得到声音的XFMR x(t)。这同样应用于比输入音频信号i(t)中的其他声音更大声的声音。
然而,如果输入音频信号i(t)包括多个同阶响度的声音,确定一个或多个声音的XFMR x(t)将更困难。复杂声音如语音自身可由多个“部分”声音组成,如共振峰,因而解调同样更困难。应注意,在本说明书中,术语“部分声音”与术语“分音”意思不一样。部分声音如共振峰可包括任何数量的分音。
图8示出了能够解调多个声音如共振峰的XFM分析器80。XFM分析器80包括连接到声音检测器81的多个如两个、三个或以上XFM解调器60。声音检测器81接收输入音频信号i(t)、确定所接收的信号i(t)中声音、部分声音和/或共振峰的存在和/或性质、及经相应控制信号82控制每一XFM解调器60以解调检测到的声音、部分声音和/或共振峰中的相应声音、部分声音和/或共振峰。每一XFM解调器60提供分开的XFMR x1(t)…xN(t),及XFM分析器80因而提供包括两个、三个及以上XFMR x1(t)…xN(t)的XFMR集83。声音检测器81可通过设置XFM解调器60的一个或多个功能模块的限制和/或参数选择而控制XFM解调器60,例如通过设置低通滤波器65的截止频率和/或设置PLL63、72的时间常数。
如图9中所示,一个或多个XFM解调器60之前有带通滤波器90。声音检测器81可确定每一检测到的声音、部分声音和/或共振峰占用的频率范围,并可经相应控制信号91控制每一带通滤波器90以在将输入音频信号i(t)传到相应XFM解调器60之前在相应频率范围外衰减频率。带通滤波器90因而可去除可能干扰XFM解调器60中的解调的频率。
语音中频率分量的产生主要在喉中发生,而声道对具有最大发音的分量即共振峰应用频率滤波。在每一音素期间,讲话者通常单独改变产生的频率分量和共振峰频率。声道应用的频率滤波改变频率分量的相对振幅,使得从信号波形确定XFMR x(t)尤其是FM指数信号h(t)变得更困难。
声道应用的频率滤波可至少部分由削弱滤波器抵消。削弱滤波器因而可减弱声道所发音的信号频率,反之亦然。前述削弱滤波器可放在相应XFM解调器60前面的信号通路中,及优选集成在带通滤波器90中。每一削弱滤波器的滤波器曲线可由声音检测器81个别控制,声道滤波器曲线实质上为相应声道滤波器曲线的反向曲线,至少在对应于带通滤波器90的通带的频带内。削弱滤波器因而可提高XFM解调器60确定相应共振峰的XFMR x1(t)…xN(t)的能力。声音检测器81可确定共振峰频率和/或检测到的共振峰的频谱分布并根据其设定削弱滤波器的滤波器曲线的形状,或作为备选,设定这些形状与基于语音统计数据的典型共振峰曲线一致。在两种情形下,声音检测器81可根据相应确定的共振峰频率调整每一曲线形状如宽度。
源自单一声源的部分声音通常共享一个或多个性质。例如,在来自单一讲话者的语音的部分或所有共振峰中基音通常一样。同样,在构成复杂声音的部分或所有部分声音中调幅通常一样。在一些情形下,甚至载频和/或FM指数也可被部分声音共享。当导出部分声音的XFMR x1(t)…xN(t)时可利用共享性质。因而,声音检测器81可分析输入音频信i(t)号存在具有共享或推测共享性质的部分声音的复杂声音;确定共享性质的值;及限制一个或多个XFM解调器60使得在它们的XFMR输出x1(t)…xN(t)中保持确定的共享性质值。在XFMR集83中可省略冗余XFMR信号a(t)、fc(t)、f0(t)、h(t)。
基于在输入音频信号i(t)中检测到语音,声音检测器81可假设共振峰共享基音性质并因而不实际测试该假设地继续下去。
如本领域已经众所周知的,声音检测器81可借助于信号分析确定共享性质的存在和/或值。作为备选,声音检测器81可借助于一个或多个XFM解调器60确定共享性质的存在和/或值。这可能要求声音检测器81从一个或多个XFM解调器60接收对应于共享性质的XFMR信号a(t)、fc(t)、f0(t)、h(t),如连接92所示。
声音检测器81可通过设置XFM解调器60的一个或多个功能模块的限制,例如通过设置低通滤波器65的截止频率和/或设置PLL63、72的时间常数而限制XFM解调器60。
在输入音频信号i(t)包括来自一个以上声源的复杂声音的情形下,例如来自一个以上讲话者的语音,声音检测器81可根据共享性质对部分声音分组因而区分各个声音的来源。例如,共振峰可通过基音进行分组以区分各个讲话者。声音检测器81可取得声音的另外的性质说明该分组,如到达方向。前述另外的性质可由声音检测器81基于来自多个传声器的输入音频信号i(t)确定。分组信息可增加到XFMR集83以使能随后对声音进行随来源而变的处理,如语音识别、或相对于来自其它声源的声音强调或削弱来自个别声源的声音。此外,讲话者的身份可通过将XFMR集83中的XFMR输出x1(t)…xN(t)或识别出的一组XFMR输出x1(t)…xN(t)与对同一讲话者记录的、先前保存的XFMR集83进行比较而确定。
图10中所示的XFM处理器100包括XFM分析器80和一个、两个、三个或以上(X)FM调制器1、20。XFM处理器100接收输入音频信号i(t)并提供合成音频信号c(t),其中至少一声音已通过修改对应的FM指数信号h(t)而被改变。在XFM处理器100中,包括在由XFM分析器80提供的XFMR集83中的部分或所有XFMR x1(t)…xN(t)随后借助于(X)FM调制器1、20调制为相应已调制音频信号s1(t)…sN(t)。XFMR x1(t)…xN(t)中的一个或多个XFM信号a(t)、fc(t)、f0(t)、h(t)的振幅例如按结合图2、3和4所示实施例描述的进行修改。
为更好地调制表示共振峰的XFMR x1(t)…xN(t),(X)FM调制器1、20中的一个或多个之后有相应的共振峰滤波器101,其至少部分模拟声道应用的频率滤波。每一共振峰滤波器101的滤波器曲线可根据包括在一个或多个XFMRx1(t)…xN(t)中和/或XFMR集83中的信息由控制单元102经相应控制线路103进行控制。前述信息例如可由XFM分析器80中的声音检测器81在解调共振峰时提供。之后,每一共振峰滤波器曲线优选设定为在解调之前应用的相应削弱滤波器90的滤波器曲线的反向曲线。作为备选,共振峰滤波器曲线的形状设定为与基于语音统计数据的典型共振峰曲线一致。在未检测到语音时或者如果相应(X)FM调制器1、20将调制非共振峰音频信号,控制单元102可将共振峰滤波器101的滤波器曲线设定为平坦曲线。作为备选,一个或多个共振峰滤波器101可被回避或省略。
多个(X)FM解调器1、20和/或可选共振峰滤波器101的输出可在加法器50中组合。这样,XFM处理器100可提供包括来自一个以上声源的大约复杂的声音如来自一个以上个体讲话者的语音的合成音频信号c(t)。通过修改一个或多个XFMR x1(t)…xN(t)中的一个或多个XFM信号a(t)、fc(t)、f0(t)、h(t),XFM处理器100可修改各个声音和/或声源的性质,例如它们的表观响度,因而改变声画。
就XFM分析器80设法正确解调XFMR x1(t)…xN(t)来说,输入音频信号i(t)中缺失的频谱分量将自动在合成音频信号c(t)中再现。这是XFM处理器100中的XFM处理的另一副作用,其可能特别有益于听力受损听者。XFM处理因而通常使能增加声画的清晰性。
图11中所示的语音合成器110与图10的XFM处理器100相似;然而,代替XFM分析器80,其包括形成共振峰库的非易失性存储器111。表示共振峰的多个XFMR x1(t)…xN(t)预先保存在共振峰库111中。预先保存的XFMRx1(t)…xN(t)例如可能已借助于XFM分析器80、XFM解调器60和/或任何其它适当的语音解调或语音分析装置从一个或多个输入音频信号i(t)导出,和/或它们可被合成。
语音合成器104从共振峰库111取回表示一个或多个共振峰的一个或多个XFMR x1(t)..xN(t);在一个或多个XFM调制器20中修改取回的XFMRx1(t)…xN(t)中的至少一个的FM指数信号h(t)的振幅;非必须地,在相应共振峰滤波器101中对已调制音频信号s(t)滤波;及随后在加法器50中将所得的共振峰信号组合为合成信号c(t)。语音合成器104因而从预先保存的共振峰XFMRx1(t)…xN(t)产生合成语音。修改至少一FM指数信号h(t)的振幅导致合成语音中的发音努力的相应修改。类似地,修改一个或多个其它XFM信号a(t)、fc(t)、f0(t)的振幅可用于改变合成语音的其它特性,如基音、颤音、语调和共振峰频率。控制单元102可控制共振峰滤波器101以为每一合成共振峰设置共振峰频率和共振峰形状。因而可产生一个或多个讲话者的合成语音。前述合成语音例如可与噪声信号混合以测试ASR系统。
来自一个或多个XFM处理器100和/或一个或多个语音合成器110的输出可被组合以产生具有复杂声画的合成音频信号c(t)。在该情形下,共用加法器50可用于从已调制音频信号si(t)产生合成音频信号c(t)。
一个或多个XFM处理器100和/或一个或多个语音合成器110可组合在音频处理系统中,如音频广播系统、音频通信系统、话音无线电系统、移动电话或移动电话系统、电话或电话系统、电视或电视系统、自动语音识别系统、音频再现系统、播音系统或听力系统,或组合在音频处理装置中,如听力装置。在前述系统或装置中,一个或多个输入音频信号i(t)可从一个或多个输入变换器导出,及所得的已调制音频信号si(t)和/或合成音频信号c(t)可馈给一个或多个输出变换器。
图12示出了音频处理装置120,如听力装置,如助听器或有源耳朵保护装置,包括如上所述的XFM处理器100,及非必须地包括如上所述的语音合成器110及包括加法器50。音频处理装置120还可包括连接成形成输入信号通路的传声器121、前置放大器122和数字转换器123。传声器121可安排成接收声输入信号,如从个人环境接收,并将对应的传声器信号提供给前置放大器122。前置放大器122适于放大传声器信号并将放大的传声器信号提供给数字转换器123。数字转换器123适于使放大的传声器信号数字化并将数字化输入音频信号i(t)提供给XFM处理器100。
XFM处理器100按如上所述及根据音频处理装置120的目的修改数字化音频信号,例如以改善或增强个人的听觉能力。XFM处理器100可包括另外的信号处理电路(未示出),如电平压缩电路、反馈抑制电路、降噪电路等,如音频处理领域和/或听力装置领域已知的那样。
XFM处理器100和语音合成器110的输出在加法器50中组合以形成合成音频信号c(t)。音频处理装置120还可包括连接成形成输出信号通路的脉宽调制器或另一类型的放大器124和扬声器125。加法器50适于将合成音频信号c(t)提供给脉宽调制器或放大器124,其适于将相应的脉宽调制的或放大的信号提供给扬声器125。音频处理装置120可适于安排在个人耳朵之处或之中,及扬声器125安排成将对应于脉宽调制信号的声输出信号传给个人或一群人。音频处理装置120还可包括用于对音频处理装置120的各个电子电路供电的电池126。
音频处理装置120还可包括信号处理器127,其适于接收输入音频信号i(t)并将其修改为提供给加法器50的输出信号。信号处理器127可进行前述对输入音频信号i(t)的修改,这些修改在本领域已众所周知,例如以改善或增强个人的听觉能力。信号处理器127还可包括滤波器(未示出)或适于对输入音频信号i(t)滤波以从其去除对应于在XFM处理器100的XFM分析器80中解调的声音或部分声音的信号部分。XFM处理器100可从输入音频信号i(t)和/或从已解调信号x(t)确定对应的信息如频谱分布,并将该信息经控制线路128提供给信号处理器127。因此,合成音频信号c(t)可包括主要在XFM处理器100中进行处理的第一组声音及主要在信号处理器127中进行处理的第二组声音。例如,截然不同的声音如语音、引擎声音、乐器声音等可主要在XFM处理器100中进行处理,而不容易或一点也不能在XFM分析器80中解调的声音如四散的噪声或风噪声可主要在信号处理器127中进行处理。
在不希望在合成音频信号c(t)中再现已解调声音或部分声音的情形下,XFM处理器100可不调制对应的已解调信号x(t)。此外,代替实际上调制已解调及可能修改后的XFMR x(t)、x’(t)、x1(t)…xN(t),XFM处理器100可确定和/或预测相应波形音频信号s1(t)…sN(t)的频谱成分并将这些频谱成分的信息提供给信号处理器127,其进而可使用该信息以将相应频谱成分增加到输入音频信号i(t)。根据解调质量,这可减少合成音频信号c(t)中不合需要的非自然信号。
语音合成器110具有用于控制其的控制线路129,例如以在电池电压低时发出合成语音形式的、听得见的警告,以向用户通知状态变化、在播音系统中提供标准消息等。语音合成器110及音频处理装置120中其它功能单元的控制可由控制单元(未示出)执行,其可以是单独的单元或包括在信号处理器127或XFM处理器100中的单元。
音频处理装置120可以是作为双耳听力系统的一部分的听力装置,在该情形下,可包括无线电收发器(未示出),XFM处理器100、信号处理器127和/或控制单元可经其与第二听力装置120交换数据,如设置、音频信号和用户命令。听力受损听者的解码两耳时间差(ITD)的能力可通过对双耳听力系统的左耳和右耳听力装置中处理的声音的FM指数信号h(t)同样放大而得以改善。
图13示出了可包括在本发明的另外的实施例中的基音解调器130的功能框图。基音解调器130取XFMR x(t)的波形基音信号f0(t)为输入,如通过XFM解调器60解调的,并将平滑后的基音信号f0,S(t)、基音偏差速率信号f0,D(t)和基音偏差范围信号f0,I(t)提供为输出。基音解调器130与XFM解调器60类似地运行,然而,没有初始的AM/FM分解,因而仅提供基音信号f0(t)的频率解调。平滑后的基音信号f0,S(t)、基音偏差速率信号f0,D(t)和基音偏差范围信号f0,I(t)以与XFMR x(t)的载频信号fc(t)、基音信号f0(t)和FM指数信号h(t)与音频输入信号i(t)有关一样的方式与基音信号f0(t)有关,因而它们可借助于(X)FM调制器1、20调制为已调制基音信号f0,M(t),调幅信号a(t)设定为恒定值如1。作为备选,(X)FM调制器1、20中的AM乘法器10可省略。
带阻滤波器131接收基音信号f0(t)并通过从基音信号f0(t)至少部分去除调制信号而确定平滑后的基音信号f0,S(t)。带阻滤波器131具有如1、2或3Hz的下转折频率和如10、20或50Hz的上转折频率。带阻滤波器131优选具有其衰变如为6dB/倍频程、12dB/倍频程或24dB/倍频程的下和上斜率。减法器132将基音偏差信号133确定为基音信号f0(t)和平滑后的基音信号f0,S(t)之间的差。基音偏差信号133因而主要包括带阻滤波器131的阻带内的信号频率,而平滑后的基音信号f0,S(t)通常慢速变化,即具有低于阻带的频率,但可包括具有高于阻带频率的调制和/或突然的电平转变,例如在讲话者突然改变基音时。
积分器134将基音偏差信号133积分为规格化基音偏差信号135。AM解调器136将规格化基音偏差信号135分解为表示规格化基音偏差信号135的AM部分的基音偏差范围信号f0,I(t)和表示规格化基音偏差信号135的FM部分的相位信号137。相位信号137提供为PLL138的输入,其具有适于使其跟随规格化基音偏差信号135的最快预期频率变化的时间常数,如约60Hz、约80Hz、约100Hz或高于100Hz。PLL138以已知方式运行并提供基音偏差速率信号f0,D(t),其表示相位信号137的瞬时频率。
Vatti的结果表明,听力受损听者需要更大的基音偏差以实现与正常听力听者一样的语音“正常”感知(Vatti2010)。此外,在1980年的声音论证中,Chowning表明正常听力听者可使用来自平滑后的基音的偏差分离同时发生的声音。更大的基音偏差可通过在调制为修改后的基音信号f’0(t)之前放大基音偏差范围信号f0,I(t)而实现。前述修改可借助于与上面公开的用于修改和调制XFMRx(t)的装置、系统和方法一样或几乎一样的装置、系统和方法实施。所得的与平滑后的基音信号f0,S(t)具有更大偏差的修改后的基音信号f’0(t)因而可用于至少部分补偿听力受损听者的不同感知并提高其在具有多个讲话者的情形下利用基音偏差作为分组线索的能力。使用上面提及的带阻滤波器131的下和上转折频率使基音偏差信号133能包括对感知语音和识别讲话者很重要的基音变化。
修改后的基音信号f’0(t)可进一步处理为XFMR x(t)或修改后的XFMR x’(t)的一部分,如上所述。基音偏差范围信号f0,I(t)的放大因而可在任何上面公开的方法、装置和/或系统中实施,然而,在听力装置和听力系统中特别相关。
图14示出了可包括在本发明的另外的实施例中的语音增强实施例的功能框图。在上面公开的任何方法、装置和系统中,语音增强可通过确定包括语音的XFMR x(t)中的基音偏差并与所确定的语音偏差同步修改XFMR x(t)的FM指数信号h(t)而实现。基音偏差可由基音解调器130确定,如上面公开的基音解调器,其接收XFMR x(t)的基音信号f0(t)并提供对应的基音偏差速率信号f0,D(t)。振荡器140可向XFMR修改器30提供第一增益信号g1(t),作为具有对应于基音偏差速率信号f0,D(t)的恒定振幅和频率的振荡信号。振荡器140的振幅可被改变以控制语音增强的量。
上面公开的语音增强使能增加基音变化的可听性,因为它们将被表示为频谱自身的调制,因而可对听力受损听者特别有益。Lunner和Pontoppidan描述了对语音信号应用调幅的类似效果,其中调幅为语音信号中的调频的函数(Lunner and Pontoppidan2008)。
图15示出了语音增强的另一实施例的功能框图,其可包括在本发明的另外的实施例中。在语音增强的该实施例中,类似的频谱调制通过输入音频信号i(t)和与基音偏差同步的已调制音频信号s(t)之间的交叉增益调节实现,其中已调制信号s(t)从输入音频信号i(t)的修改后的XFMR x’(t)调制。XFM解调器60接收输入音频信号i(t)并提供对应的XFMR x(t),如上面别处所述。XFMR修改器30修改XFMR x(t)的FM指数信号h(t)并提供具有修改后的FM指数信号h’(t)的修改后的XFMR x’(t),如上所述。(X)FM调制器1、20接收修改后的XFMRx’(t)并提供对应的已调制音频信号s(t),如上所述。例如如上所述的基音解调器130接收FM指数信号h(t)并提供对应的基音偏差速率信号f0,D(t)。交叉增益调节器150接收输入音频信号i(t)、已调制音频信号s(t)和基音偏差速率信号f0,D(t),并根据下述等式提供增强的音频信号e(t):
(7)e(t)=αi(t)+(1-α)s(t),
其中增益调节因子α定义为:
(8)α=1/2+cos2πf0,D(t)/2,
增强的音频信号e(t)因而在输入音频信号i(t)和已调制音频信号s(t)之间来回变化,具有与XFMR x(t)的基音信号f0(t)在平滑后的基音信号f0,S(t)附近变化一样的频率。实际增加基音变化的可听性所需要的FM指数信号h(t)的放大或衰减量取决于个体的听力受损。等式(7)和(8)中的常数可被修改以获得其它交叉增益调节比。
在上面公开的任何方法、装置和系统中,图15中所示的语音增强可代替图14中所示的语音增强或增加到其中。
本发明的实施例优选主要实施为在离散时域运行的数字电路,但其任何或所有部分也可实施为在连续时域运行的模拟电路。因而,输入音频信号i(t)、XFMR信号a(t)、fc(t)、f0(t)、h(t)、修改后的XFMR信号a’(t)、fc‘(t)、f0‘(t)、h’(t)、基音已解调的信号f0,S(t)、f0,D(t)、f0,I(t)、已调制音频信号s(t),s1(t)..sN(t)、合成音频信号c(t)和增强信号e(t)中的任何一个可按需在例如包括多个装置的音频处理系统中在任何多个时间及信号链中的任何地方在数字和模拟表示之间转换,反之亦然。在模拟电路中,乘法器4、10、21、42、43、44、74例如可实施为增益可控的放大器。
实施例的数字功能模块可以硬件、固件和软件的任何适当组合和/或以任何适当数量和组合的硬件单元实施。此外,任何单一硬件单元可并行、顺序、交叉顺序和/或以其任何适当组合执行几个功能模块的操作。具体地,单一XFM解调器60可从单一重复的输入音频信号i(t)迭代地解调多个XFMR x(t),及单一(X)FM调制器1、20可将多个XFMR x(t)顺序调制为多个已调制音频信号s(t),其随后可在时延单元中时间对准并相加。
实施例的功能模块可实施在音频处理系统包括的不同装置中,在该情形下,相应功能模块应借助于适当的传输装置进行连接。作为备选,实施例可实施在单一音频处理装置中。
一些优选实施例已经在前面进行了说明,但是应当强调的是,本发明不受这些实施例的限制,而是可以权利要求限定的主题内的其它方式实现。例如,为使根据本发明的系统、装置和/或方法适应特定需要,所述实施例的特征可任意组合。
当由相应过程适当替代时,上面描述的、“具体实施方式”中详细描述的及权利要求中限定的系统和/或装置的结构特征可与方法组合。方法的实施例具有与对应系统和/或装置一样的优点。
在不背离本发明范围的情形下,本领域技术人员可显而易见地对所公开的方法、系统和/或装置进行另外的修改。在本说明书内,任何前述修改以非限制性的方式提及。
权利要求中的任何附图标记和名称不意于限制其范围。
参考文献
Andersen MR.,Kristensen MS.,Neher T.and Lunner T.2010.Effect of Binaural Tone Vocoding on Recognising Target Speech Presented Against Spatially Separated Speech Maskers(IHCON Poster).
Boldt JB.,Kjems U.,Pedersen MS.,Lunner T.and Wang D.2008.Estimation of the ideal binary mask using directional systems.Paper presented at IWAENC2008.
Bovik AC.,Maragos P.and Quatieri TF.1993.AM-FM Energy Detection and Spearation in Noise using Multiband Energy Operators.IEEE transactions on Signal Processing41(12),pages3245-3265.
Bregman AS.1990.Auditory Scene Analysis.Cambridge,Massachusetts:MITPress.
Chowning J.1973.The synthesis of complex audio spectra by means of frequency modulation.Journal of the Audio Engineering Society21(7),pages526-534.
Chowning JM.2000.Digital sound synthesis,acoustics and perception:A rich intersection.Paper presented at COST G-6Conference on Digital Audio Effects(DAFX-00),at Verona,Italy.
Chowning JM.1980.Computer synthesis of the singing voice.Paper presented at Sound generation in Winds,Strings and Computers,Kungl.Musikaliska Akademien,Stockholm Sweden.
de CheveignéA.and Kawahara H.2002.YIN,a fundamental frequency estimator for speech and music.The Journal of the Acoustical Society of America111(4),pages1917-1030.
Elberling C.,Ekelid M.and Ludvigsen C.1991.A method and an apparatus for classification of a mixed speech and noise signal.Patent application WO91/03042A1.
Folk L.and Schiel F.2011.The Lombard Effect in Spontaneous Dialog Speech.Paper presented at Interspeech2011.
Heinz MG.,Swaminathan J.,Boley JD.and Kale S.2010.Across-fiber coding of temporal fine-structure:Effects of noise-induced hearing loss on auditory-nerve responses.The Neurophysiological Bases of Auditory Perception,pages621-630.
Hopkins K.and Moore BCJ.2011.The effects of age and cochlear hearing loss on temporal fine structure sensitivity,frequency selectivity and speech reception in noise.The Journal of the Acoustical Society of America130(1),pages334-349.
Hopkins K.and Moore BCJ.2007.Moderate cochlear hearing loss leads to a reduced ability to use temporal fine structure information.J.Acoust.Soc.Am.122(2),pages1055-1068.
Hopkins K.,Moore BCJ.and Stone MA.2008.Effects of moderate cochlear hearing loss on the ability to benefit from temporal fine structure information in speech.Journal of the Acoustical Society of America123(2),pages1140-1153.
Jordan MI.1998.Learning in graphical models.Kluwer Academic Publishers.
Kubo Y.,Okawa S.,Kurematsu A.and Shirai K.2011.Temporal AM-FMcombination for robust speech recognition.Speech Communication53(5),pages716-725.
Lazzarini V.and Timoney J.2010.Theory and Practice of Modified Frequency Modulation Synthesis.Journal of the Audio Engineering Society58(6),pages459-471.
Lindblom B.1996.Role of articulation in speech perception:Clues from production.Journal of the Acoustical Society of America99(3),pages1683-1692.
Ljung L.1999.System identification.Wiley Encyclopedia of Electrical and Electronics Engineering.
Lunner T.,Hietkamp RK.,Andersen MR.,Hopkins K.and Moore BCJ.2011.Effect of speech material on the benefit of temporal fine structure information in speech for normal-hearing and hearing-impaired subjects.Submitted to Ear&Hearing.
Lunner T.and Pontoppidan NH.2008.N band FM demodulation to aid cochlear hearing impaired persons.Patent application EP 2 184 929 A1.
Maragos P.,Kaiser JF.and Quatieri TF.1993A.Energy separation in signal modulations with application to speech analysis.IEEE transactions on Signal Processing41(10),pages3024-3051.
Maragos P.,Kaiser JF.and Quatieri TF.1993B.On Amplitude and Frequency Demodulation Using Energy Operators.IEEE transactions on Signal Processing41(4),pages1532-1550.
Micheyl C.,Keebler MV.and Oxenham AJ.2010.Pitch perception for mixtures of spectrally overlapping harmonic complex tones.Journal of the Acoustical Society of America128(1),pages257-269.
Moore BCJ.and Sek A.2009.Development of a fast method for determining sensitivity to temporal fine structure.International Journal of Audiology48(4),pages161-171.
Moore BCJ.and Glasberg BR.2004.A revised model of loudness perception applied to cochlear hearing loss.Hearing Research188,pages70-88.
Moore BCJ.and Skrodzka E.2002.Detection of frequency modulation by hearing-impaired listeners:Effects of carrier frequency,modulation rate and added amplitude modulation.The Journal of the Acoustical Society of America111(1),pages327-335.
Neher T.and Behrens T.2007.Frequency transposition applications for improving spatial hearing abilities for subjects with high-frequency hearing loss.Patent application EP2026601A1.
Neher T.2008.Hearing device,hearing aid system,method of operating a hearing aid system and use of a hearing device.Patent application EP 2 091 266 A1.
Nie K.,Stickney G.and Zeng F-G.2005.Encoding Frequency Modulation to Improve Cochlear Implant Performance in Noise.IEEE Transaction on Biomedical Engineering52(1),pages64-73.
Potamianos A.and Maragos P.1999.Speech analysis and synthesis using an AM-FM modulation model.Speech Communication28(1999),pages195-209.
Ruggles D.,Bharadwaj H.and Shinn-Cunningham BG.2011.Normal hearing is not enough to guarantee robust encoding of suprathreshold features important in everyday communication.Proc.Natl.Acad.Sci.U.S.A108(37),pages15516-15521.
Schimmel SM.2007.Theory of Modulation Frequency Analysis and Modulation Filtering with Applications to Hearing Devices.PhD Theory of Modulation Frequency Analysis and Modulation Filtering with Applications to Hearing Devices,University of Washington.
Smith JSR.2006.Apparatus for and method of signal processing.Patent application WO2006/032917.
Teager HM.1980.Some Observations on Oral Air Flow During Phonation.IEEE transactions on acoustics,speech and signal processing28(5),pages599-601.
Teager HM.and Teager SM.1990.Evidence for nonlinear sound production mechanisms in the vocal tract.In Speech production and speech modelling,eds WJ Hardcastle and A Marchal,pages241-261.Kluwer.
Vatti M.2010.Consequences of hearing impairment in auditory scene analysis.Master’s thesis.Technical University of Denmark.
Wang Y.and Kumaresan R.2006.Real Time Decomposition of Speech into Modulated Components.Journal of the Acoustical Society of America119(6),pagesEL68-EL73.
Winkler T.2011.How realistic is Artificially Added Noise?Paper presented at Interspeech2012.
Yasu K.,Ishida K.,Takahashi R.,Arai T.,Kobayashi T.and Shindo M.2008.Critical-band compression method of speech enhancement for elderly people:Investigation of syllable and word intelligibility.
Zeng FG.,Nie K.,Stickney GS.,Kong YY.,Vongphoe M.,Bhargave A.,Wei C.and Cao K.2005.Speech recognition with amplitude and frequency modulations.Proceedings of the National Academy of Sciences102(7),pages2293-2298.
Zeng F-G.and Nie K-B.2007.Cochlear implants and apparatus/methods for improving audio signals by use of frequency-amplitude-modulation-encoding(FAME)strategies.Patent US7,225,027.
Zhou G.,Hansen JHL.and Kaiser JF.2001.Nonlinear Feature Based Classification of Speech Under Stress.IEEE Transactions on Speech and Audio Processing9(3),pages201-216.
- 还没有人留言评论。精彩留言会获得点赞!