可加载个性化特征模型的语音识别系统及方法与流程
本发明涉及嵌入式语音识别技术领域,具体地,涉及一种可加载个性化特征模型的语音识别系统及方法。
背景技术:
基于按键及触摸屏的人机接口技术已经非常成熟,并且大大提高了人们操作设备便利性,而语音作为人类的自然界面,利用语音识别来控制操作设备的技术才开始起步,一方面是因为语音识别技术非常复杂,另一方面是嵌入式计算能力不足,即使在pc机上验证的算法很难移植到嵌入式系统中。
技术实现要素:
针对现有技术中的缺陷,本发明的目的是提供一种可加载个性化特征模型的语音识别系统及方法,其可以用于语音控制ui的技术,且可以加载个性化特征模型,大大提高识别率及识别的可靠性。
根据本发明的一个方面,提供一种可加载个性化特征模型的语音识别系统,所述可加载个性化特征模型的语音识别系统包括:
语音编解码芯片,用于将接收到的模拟语音信号进行a/d转换得到数字音频信号,及将数字信号处理器后的数字音频信号进行d/a转换为模拟语音信号;
数字信号处理器,用于对输入的数字音频信号进行语音识别算法处理,识别完成后将识别的结果语音合成为输出数字音频信号,发送给语音编解码芯片进行语音输出;
flash芯片,用于存储数字信号处理器的语音识别程序及通用语音模型数据,上电启动后,程序及通用语音模型数据从flash芯片加载到ddrram芯片中;
ddrram芯片,用于运行语音识别程序,存储通用语音模型数据及个性化特征模型数据;
串口芯片,数字信号处理器通过串口芯片和外部通信,数字信号处理器通过串口芯片和外部通信,通过串口给出识别出的词汇对应的汉字码;
网络芯片,当某人口音特别严重时,利用通用语音模型识别时识别率小于95%,用于加载个性化特征模型数据,以提高其识别率。
优选地,所述数字信号处理器选用高性能低功耗的浮点型tms320c6748数字信号处理器。
优选地,所述语音编解码芯片需要支持多种采样率。
优选地,所述网络芯片选择lan8710a型芯片。
优选地,所述数字信号处理器的通信和语音编解码芯片的通信都采取dma方式通信。
本发明提供一种可加载个性化特征模型的语音识别方法,其包括如下步骤:
步骤一,系统上电后,首先将语音识别程序从flash芯片加载到ddrram芯片中,然后将通用语音模型数据加载到ddrram芯片中,开始运行准备语音识别;
步骤二,语音识别模块上电程序运行后,系统进行识别按键检测,检测到识别按键按下后,开始控制音频编解码芯片,进行ad转换接收语音信号,然后通过语音识别算法进行语音识别,同时系统检测到识别按键抬起后,通过串口给出识别出的词汇对应的汉字码,同时将识别的词汇进行语音合成,控制音频编解码芯片将合成的结果da转换为模拟语音信号进行输出;
步骤三,语音识别模块运行中,如果检测到模型切换按键按下,加载下一条个性化语音模型数据到ddrram芯片,如果没有下一条个性化语音模型数据,加载通用语音模型数据到ddrram芯片中,后续语音识别将会使用新加载的模型进行语音识别;
步骤四,语音识别模块运行中,如果接收到网络加载的个性化语音模型数据,则将收到的个性化语音模型数据存储到flash芯片中及ddrram芯片中,后续语音识别将会使用新加载的模型进行语音识别。
与现有技术相比,本发明具有如下的有益效果:本发明可以用于语音控制ui的技术,且可以加载个性化特征模型,大大提高识别率及识别的可靠 性。
附图说明
通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:
图1为本发明可加载个性化特征模型的语音识别系统的原理框图。
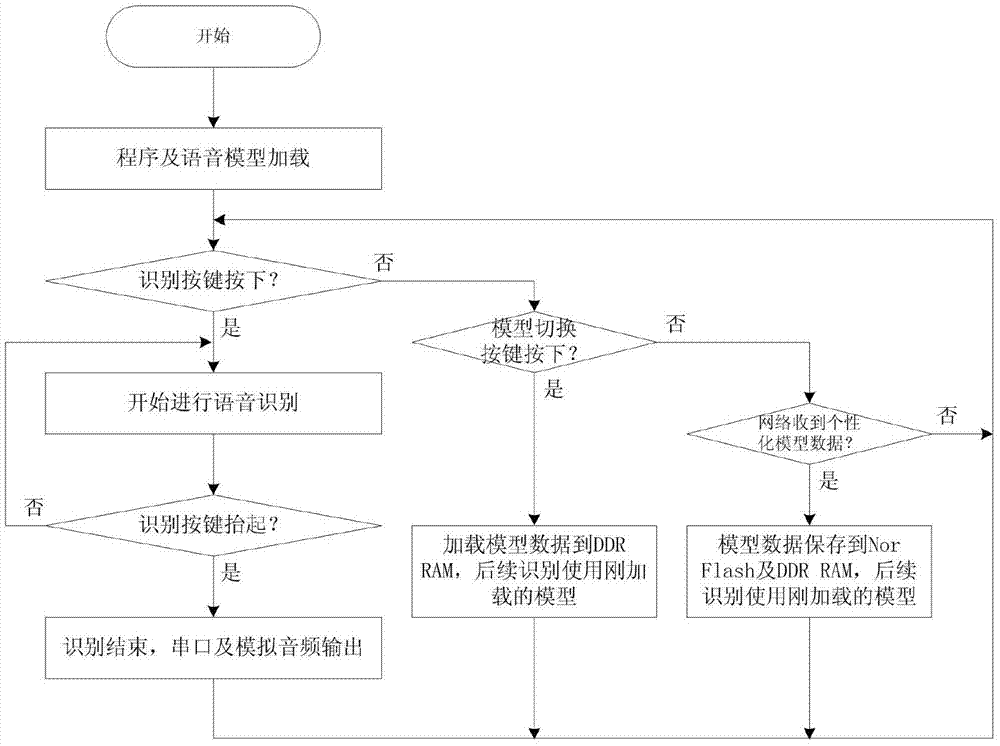
图2为本发明可加载个性化特征模型的语音识别方法的流程图。
具体实施方式
下面结合具体实施例对本发明进行详细说明。以下实施例将有助于本领域的技术人员进一步理解本发明,但不以任何形式限制本发明。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进。这些都属于本发明的保护范围。
如图1所示,本发明可加载个性化特征模型的语音识别系统包括:
语音编解码芯片104,用于将接收到的模拟语音信号进行a/d转换得到数字音频信号,及将数字信号处理器后的数字音频信号进行d/a转换为模拟语音信号;
数字信号处理器(digitalsignalprocessor,dsp)101,用于对输入的数字音频信号进行语音识别算法处理,识别完成后将识别的结果语音合成为输出数字音频信号,发送给语音编解码芯片进行语音输出;
flash芯片102,用于存储数字信号处理器的语音识别程序及通用语音模型数据,上电启动后,程序及通用语音模型数据从flash芯片加载到ddrram芯片中;
ddrram芯片103,用于运行语音识别程序,存储通用语音模型数据及个性化特征模型数据;
串口芯片105,dsp通过串口芯片和外部通信,,数字信号处理器通过串口芯片和外部通信,通过串口给出识别出的词汇对应的汉字码;
网络芯片106,当某人口音特别严重时,利用通用语音模型识别时识别率小于95%,用于加载个性化特征模型数据,以提高其识别率。
本发明可加载个性化特征模型的语音识别系统还可以包括锂电池107,锂电池用于给本发明可加载个性化特征模型的语音识别系统供电。
作为一种实施方式,数字信号处理器101可以选用高性能低功耗的浮点型tms320c6748dsp,同时,为了降低功耗,尽量减少处理器各接口的使用,在满足算法处理的情况下,尽量降低处理器工作频率。flash芯片102及ddrram芯片103选用市场上通用的并且本款数字信号处理器能够支持的芯片即可。串口芯片105可以选择rs232、rs422、rs485任意一种标准的芯片。语音编解码芯片104需要支持多种采样率,如8khz、16khz、44.1khz等,采样精度支持16bit、24bit。网络芯片106可以选择lan8710a型芯片。
作为一种实施方式,语音编解码芯片被配置为16khz的采样率,采样精度为24bit。数字信号处理器和语音编解码芯片之间可以采用iis方式通信,每秒传输字节数位48k字节,为了降低数字信号处理器的负担,使数字信号处理器主要运行识别程序,数字信号处理器的通信和语音编解码芯片的通信都采取dma(directmemoryaccess,直接内存存取)方式通信。
如图2所示,本发明可加载个性化特征模型的语音识别方法,包括如下步骤:
步骤一,系统上电后,首先将语音识别程序从flash芯片加载到ddrram芯片中,然后将通用语音模型数据加载到ddrram芯片中(如果有个性化语音模型数据,将个性化语音模型数据加载到ddrram芯片中),开始运行准备语音识别;
步骤二,语音识别模块上电程序运行后,系统进行识别按键检测,检测到识别按键按下后,开始控制音频编解码芯片,进行ad转换接收语音信号,然后通过语音识别算法进行语音识别,同时系统检测到识别按键抬起后,通过串口给出识别出的词汇对应的汉字码,同时将识别的词汇进行语音合成,控制音频编解码芯片将合成的结果da转换为模拟语音信号进行输出;
步骤三,语音识别模块运行中,如果检测到模型切换按键按下,加载下一条个性化语音模型数据到ddrram芯片,如果没有下一条个性化语音模型数据,加载通用语音模型数据到ddrram芯片中,后续语音识别将会使用新加载的模型进行语音识别;
步骤四,语音识别模块运行中,如果接收到网络加载的个性化语音模型数据,则将收到的个性化语音模型数据存储到flash芯片中及ddrram芯片中,后续语音识别将会使用新加载的模型进行语音识别。
以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变形或修改,这并不影响本发明的实质内容。
- 还没有人留言评论。精彩留言会获得点赞!