模拟信息特征提取的基于时间的频率调谐的制作方法
不适用。
关于联邦政府资助研究或开发的声明
不适用。
技术领域
本发明属于音频输入的主动感测(active sensing)领域。实施例针对感测音频中的具体特征的检测。
背景技术:
半导体制造和传感器技术的最新进展已经使对传感器和控制器的低功率网络的使用的新能力能够监测环境以及控制过程。预期这些网络来进行广泛应用(包括运输、制造、生物医学、环境管理、安全以及保密)的部署。这些低功率网络中的许多低功率网络涉及广域网上的机器对机器(“M2M”)通信,现在这种网络通常被称为“物联网”(“IoT”)。
被设想作为这些网络中的传感器的输入的特定的环境属性或事件也是广范围的,包括如温度、湿度、地震活动、压力、机械应变或振动等条件。在这些网络化系统中还设想感测音频属性或事件。例如,在安全性背景中,可以部署传感器来检测特定声音,如枪声、玻璃打破声、人声、脚步声、附近的汽车声、动物咀嚼电力电缆声、天气状况等。
音频信号或输入的感测还由这种用户设备(如移动电话、个人电脑、平板电脑、汽车音响系统、家庭娱乐或照明系统等)实施。例如,在现代移动电话手机中,软件“app”的语音激活通常是可用的。典型地,通过检测感测到的音频中的特定特征或“签名”以及调用相应的应用或行动作为响应来运行常规的语音激活。能够由这些用户设备感测的其他类型的音频输入包括背景声音(如用户是否为办公环境、餐厅、移动的汽车或其他运输工具中),设备响应于这些音频输入而对其响应或操作进行修改。
在低功率网络设备和电池供电移动设备中,对考虑到最大灵活性和电池寿命以及最小形状系数来说,低功率操作是关键的。例如,已经观察到的是,在等待预期的事件发生同时,一些类型的传感器(如在IoT背景环境中部署的无线环境传感器)能够在环境或信道监测上使用其可用功率的一大部分。考虑通常在语音或声音识别中需要的大量的功率,对声学传感器来说是尤其如此。这种类型的常规传感器通常根据低功率或“睡眠”运行模式来运行,在该运行模式中,传感器组件(例如,信号发送器电路系统)的后端被有效地断电直到接收到指示预期事件发生的信号。而此方法能够显著地减少传感器组件的功率消耗,许多小功率循环系统在空闲周期期间仍然消耗大量功率,以便构成总功率预算的主要部分,在这些小功率循环系统中,每个传感器组件花费非常小量的时间执行数据传输。
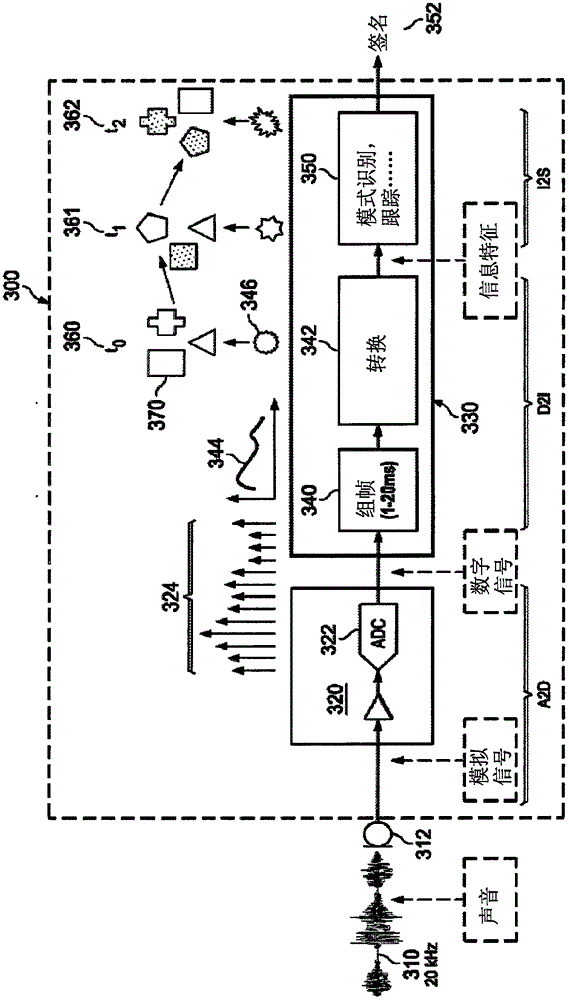
图1示出了典型的常规声音识别系统300,例如应用于人类语言的检测。识别系统300的麦克风312接收来自周围环境的声音310,并且将其转换为模拟信号。系统300的模拟前端(AFE)级320中的模数转换器(ADC)322将此模拟输入信号转换为数字信号,具体地,以数字采样324的序列的形式。作为本领域的基本原理,ADC 322的采样率超过两倍的感兴趣的最大频率的尼奎斯特率(Nyquist rate)。对典型的人类语言识别系统来说高达大约20kHz的声音信号是感兴趣的,并且对典型的人类语言识别系统来说采样率将为至少40kHz。
在此常规系统300中,系统300的数字逻辑330将数字采样324转换为声音信息(D2I)。数字逻辑330通常由通用微控制器单元(MCU)、专用数字信号处理器(DSP)、专用集成电路(ASIC)或其他类型的可编程逻辑实现,并且在此布置中将采样划分为帧340以及然后使用定义的转换函数344将组帧(frame)的采样转换342为信息特征。然后,通过模式识别和跟踪逻辑350将这些信息特征映射到声音签名(I2S)。
识别逻辑350通常由一种或更多种类型的已知模式识别技术(如神经网络、分级树、隐马尔科夫模型、条件随机域、支持向量机等)实现,并且以由时间点t0360,t1361,t2362等表示的周期的方式运行。例如,由转换342产生的每个信息特征(例如,特征346)与预先识别的特征的数据库370比较。在每个时间步骤,识别逻辑350企图找到由转换逻辑342产生的信息特征的序列和存储在数据库370中的声音签名的序列之间的匹配。被识别的每个候选签名352被分配指示其与数据库370中的特征之间的匹配程度的分数值。那些具有超过阈值的分数的签名352被识别器300识别为与已知签名匹配。
由于复杂的信号分段,因此在识别系统300中是信号转换和最终模式识别操作在数字域执行,需要ADC 322的高性能和高精度实现以及其余的模拟前端(AFE)320来为接下来复杂的数字处理提供足够的数字信号。例如,由典型的常规声音识别系统进行的具有8kHz带宽的声音信号的语音识别将需要以16KSps(每秒采样)或更高采样率运行的具有16比特精度的ADC。此外,由于原始输入信号310本质上由系统300记录,因此信号能够从存储的数据、提高隐私和安全问题方面被重建。
另外,为了缓解电池供电应用中的高功率消耗问题,在一些工作周期,系统300可以在正常检测和备用操作模式之间切换。例如,有时,整个系统可以被开启并且运行在全功率模式用于检测,然后是低功率备用模式中的间隔。然而,这种周期性工作操作增加了在备用模式期间丢失事件的可能性。
借助于进一步的背景,2015年3月5日公开的通常由此参考指定在此并结合于此的美国专利申请公开号US 2015/0066498,描述了配置成接收可能包括签名声音的模拟信号的低功率声音识别传感器。在此传感器中,使用模拟部分的检测部分评估接收到的模拟信号以确定何时超过模拟信号上的背景噪声。当超过背景噪声时,触发模拟部分的特征提取部分以从模拟信号中提取稀疏的声音参数信息。当期望的声音可能以模拟信号的形式被接收时,声音参数信息的初始截断部分与随着声音识别传感器本地存储的截断声音参数数据库比较以进行检测。当期望的声音可能以超过阈值的形式被接收时,产生触发信号以触发分类逻辑。
借助于进一步的背景,2015年3月5日公开的通常由此参考指定在此并结合于此的美国专利申请公开号US 2015/0066495,描述了配置成接收可能包括签名声音的模拟信号的低功率声音识别传感器。在此传感器中,当在模拟信号中接收签名声音时,从模拟信号中提取稀疏的声音参数信息,并且将该稀疏的声音参数信息与随着声音识别传感器本地存储的声音参数参考比较以进行检测。稀疏的声音参数信息的部分为微分零交叉(ZC)计数。通过测量在时间帧的每个序列期间模拟信号交叉阈值的次数以形成ZC计数的序列以及通过ZC计数的选择对之间的区别来形成微分ZC计数的序列,可以确定微分ZC率。
技术实现要素:
所公开的实施例提供了以减少的功率消耗有效识别具体音频事件的音频识别系统和方法。
所公开的实施例提供了以改进的精度识别具体音频事件的这种系统和方法。
所公开的实施例提供了实现提高的硬件效率(具体结合模拟电路系统和功能电路)的这种系统和方法。
所公开的实施例提供了能够以更高的频带分辨率而不增加检测信道复杂度执行这种音频识别的这种系统和方法。
所公开的实施例提供了这种系统和在音频识别系统中降低模拟滤波器失配的方法。
通过参照以下说明连同其附图,所公开的实施例的其他目标和优点对本领域普通技术人员将是明显的。
根据特定的实施例,通过将信号持续时间划分成多个间隔(例如,划分为多个帧),在接收的音频信号上执行模拟音频检测。从在信号中的不同时间以不同频率特性滤波的信号中识别模拟信号特征,因此在输入信号中的具体时间点识别具体频率的信号特征。根据识别的模拟信号特征构造输出特征序列,并且针对检测的事件,将输出特征序列与预定义的特征序列比较。
附图说明
图1为框图形式的常规音频识别系统的电路图。
图2为框图形式的根据公开的实施例的音频识别系统的电路图。
图3为框图形式的根据实施例的具有模拟特征提取能力的模拟前端的电路图。
图4为框图形式的根据实施例的图3的模拟前端的模拟特征提取功能电路的功能图。
图5示出了滤波的信号的曲线图,该曲线图将多信道滤波方法与实施例的操作进行比较。
图6a和图6b为框图形式的根据替代实施例的时间相关的模拟滤波特征提取和排序(sequencing)功能电路的电路图。
图7为框图形式的根据公开的实施例的利用A2I稀疏声音特征进行声音识别的系统的电路图。
具体实施方式
将此说明中描述的一个或更多个实施例实现为(例如移动电话手机中的)语音识别功能,如设想在其上下文中这种实现是特别有利的。然而,还设想本发明的概念可以在其他应用中有益地应用和实现,例如,在如可以由远程传感器、安全以及其他环境传感器等实施的声音检测中实现。因此,将理解的是,以下描述仅以示例的方式提供且不旨在限制如要求保护的本发明的真实范围。
图2功能性地示出模拟信息(analog-to-information)(A2I)声音识别系统5的架构和操作,本发明的实施例可以在该系统中实现。在此布置中,如上述结合的美国专利申请公开号US 2015/0066495和US 2015/0066498中大体描述的,系统5作用于从模拟输入信号中直接提取的稀疏信息,其中模拟输入信号在该实例中由麦克风M接收。根据此布置,模拟前端(AFE)10还执行各种形式的模拟信号处理,如具有期望的频率特性的模拟滤波器的应用、滤波信号的组帧(frame)等。
如结合这些实施例在下面将进一步描述的,AFE 10还执行模拟域处理来提取接收的输入信号中的具体特征。将这些典型地“稀疏的”提取模拟特征分类(例如,通过比较存储在签名/冒名(imposter)数据库17中的签名特征),然后将其数字化并且转发至数字微控制器单元(MCU)20(该数字微控制器单元可以由通用微处理器单元、专用数字信号处理器(DSP)、专用集成电路(ASIC)等实现)。MCU 20应用一种或更多种类型的已知模式识别技术(如神经网络、分级树、隐马尔科夫模型、条件随机域、支持向量机等)来对由此布置中的AFE 10提取的数字化特征执行数字域模式识别。一旦MCU 20从那些特征中检测声音签名,相应的信息以常规的方式从声音识别系统5转发至系统5在其中实施的系统中合适的目标功能电路。根据此布置,声音识别系统5仅数字化提取的特征(即,包括有用的和可识别的信息的那些特征)而不是全部输入信号,并且基于那些特征而不是全部输入信号的数字化版本执行数字模式识别。根据此布置,由于输入声音在模拟域中被处理和组帧,因此可能出现在声音信号中的许多噪声和干扰在数字化之前被移除,这继而降低了AFE 10中需要的精度,具体地,降低了AFE 10中模拟数字转换(ADC)功能的速度和性能需求。所产生的对AFE 10的性能需求的放宽使声音识别系统5能够在非常低的功率水平上运行,这在现代电池供电系统中是关键的。
如图2所示,AFE 10(特别是其模拟特征提取功能电路)能够与签名/冒名数据库17的在线实施通信以执行其特征识别功能。在此布置中,声音识别系统5功能性地包括网络链路15,系统5通过该网络链路能够与服务器16通信,在针对接收的输入信号的识别过程中其反过来实时的访问签名/冒名数据库17。替代性的,本地存储器资源可以存储系统5中的本地特征识别的必要数据,该本地存储器资源在声音识别系统5中或在系统5在其中实施的终端用户系统(例如,移动电话手机)中的其他地方。在此示例中,如图2所示,设想通过“基于云端的”在线训练18可以开发应用在信号特征的识别中的数据,如在上述结合的美国专利申请公开号US 2015/0066495和US 2015/0066498中描述的,或在本领域已知的其他常规方式中描述的。
图3示出了根据这些实施例的AFE 10的功能化布置。在此实现中,由麦克风M接收的模拟信号被放大器22放大,并且应用于在模拟前端10中的模拟信号处理电路系统24。信号处理电路系统24执行各种形式的模拟域信号处理和调节,如适合于下游功能;设想参考此说明书的本领域技术人员将能够容易地实现如适合具体的实现而不进行过度实验的模拟信号处理功能电路24。在此实施例中,模拟特征提取在逐帧(frame-by-frame)基础上实施,模拟组帧功能电路26将处理过的模拟信号分成时域帧。每个帧的长度可以根据具体的应用而变化,例如,从大约1毫秒到大约20毫秒的典型的帧值范围。然后,将处理过的模拟信号帧转发至模拟特征提取功能电路28。
图4示出了根据此实施例的模拟特征提取功能电路28的功能化布置。信号触发器30被实现为评估组帧的模拟信号相对背景噪声以确定之后的信号链中的功能是否将从备用状态被唤醒的模拟电路系统,这允许AFE 10中的电路系统的许多电路多次断电。在信号触发器30检测具体数量的信号能量的事件中(例如,比较信号的放大版本与模拟阈值),将组帧的模拟信号传递到时间相关的模拟滤波特征提取和排序功能电路35。
上述结合的美国专利申请公开号US 2015/0066495和US 2015/0066498描述了模拟特征提取的方法,其中多个模拟信道作用于模拟信号上以提取不同的模拟特征。如那些公开中描述的,使用选择的带通、低通、高通或其他类型的滤波器,一个或更多个信道可以从模拟输入信号各自的滤波版本中提取这种属性(如零交叉信息和总能量)。提取的特征可以基于微分(differential)零交叉(ZC)计数,例如相邻声音帧(即在时域中)之间的ZC率中的差,通过使用不同的阈值电压代替仅一个参考阈值(即在振幅域中)来确定ZC率的差;通过使用不同的采样时钟频率(即在频域中)来确定ZC率的差,通过单独或结合使用的这些或其他微分ZC措施来识别具体的特征。能够分析从模拟信号中提取的总能量值和该信号的各种滤波版本来检测具体频带内的能量值,该总能量值和各种滤波版本还能够指示具体的特征。
根据上述结合的美国专利申请公开号US 2015/0066495和US 2015/0066498中的方法,在接收信号的持续时间内应用模拟特征提取信道。图5示出了被这些不同的模拟信道应用的滤波的说明性示例。在此示例中,模拟信号i(t)为在一段时间内(如在第二事件的持续时间内或在一些数量的帧内)接收的输入信号。例如,如果期望的声音事件通常在一秒钟内发生,并且由组帧功能电路26产生的帧的长度为20毫秒,那么模拟信号i(t)将具有大约五十帧的持续时间。在一个模拟特征提取信道中,低通滤波器LPF1使用具有0.5kHz的截止频率fCO的低通滤波器滤波此接收的模拟信号i(t),以产生如所示的滤波的模拟信号i(t)LPE1。类似地,在另一个特征提取信道中,低通滤波器LPF2将具有2.5kHz的截止频率fCO的滤波器应用于输入信号i(t)以产生如所示的滤波的模拟信号i(t)LPF2。根据上述结合的美国专利申请公开号US 2015/0066495和US 2015/0066498中描述的实现,然后通过特征提取电路(如零交叉(ZC)计数器、微分ZC分析器、导出总能量的积分器等)分析这些信号i(t)LPF1和i(t)LPF2中的每个信号,该特征提取电路确定在相应的滤波信号i(t)LPF1和i(t)LPF2中的具体模拟信号特征的振幅。
结合本发明已经发现,在信号内的具体时间间隔的具体频带内的信号特征对签名识别来说能够比在该间隔期间的其他频带内的特征更重要,并且比在该信号内的其他时间的相同的具体频带内的特征更重要。根据这些实施例,提供时间相关的模拟滤波特征提取和排序功能电路35(图4)以使得信号中的特征的提取能够在音频信号事件持续时间内的不同时间以不同频率敏感度来执行。
设想在输入信号持续时间内应用的滤波频率特性的具体序列将通常在签名/冒名数据库17的发展中由在线训练功能电路18确定。通常,此训练将运行以识别待检测的声音事件的最独特的特征(如上述结合的美国专利申请公开号US 2015/0066495和US 2015/0066498中描述的),附加必要的训练来识别具体频带和帧间隔,那些特征在帧间隔处出现在该信号内。根据这些实施例,在该信号持续时间内(视情况而定),此训练导致滤波频带序列以及待应用或检测的相应信号特征的确定。
根据这些实施例的通过低通滤波器LPF(t)的时间相关的模拟滤波特征提取和排序功能电路35的操作的一个示例在图5中示出,该功能电路将具有时间相关的截止频率fCO(t)的滤波器应用到输入信号i(t)以产生滤波的输入信号i(t)LPF(t)。在此示例中,低通滤波器LPF(t)在输入信号序列中的第一帧期间以及在靠近该输入信号序列的中间的两个独立的帧期间应用具有2.5kHz的截止频率fCO的低通滤波器LPF2,并且在输入信号i(t)持续时间内的其他帧期间应用具有0.5kHz的截止频率fCO的低通滤波器LPF1。如果待测的期望的声音签名在声音事件早期(即在第一帧期间)以及还在靠近选择低通滤波器LPF2时的声音事件的中间的两个独立的帧内在高频处具有高能量,以及在该事件中的其他时间在较低频处具有特征,那么该模式是有用的。通过时间相关的模拟滤波特征提取和排序功能电路35,在那些间隔内将模拟特征提取应用到这些各自的滤波信号中,以在输入信号i(t)持续时间内产生信号特征序列。以此方式,时间相关的模拟滤波特征提取和排序功能电路35实现信号间隔内的不同时间的不同频率处的信号特征的识别,并且因此实现签名检测的精度改进。
参照图6a,现在将进一步详细描述根据一个实施例的时间相关的模拟滤波特征提取和排序功能电路35的构建与操作。在此实施例中,可调谐滤波器40接收模拟输入信号i(t),并且根据在该信号持续时间内能够随时间变化的频率特性来滤波该信号。例如,可以将可调谐滤波器40构造为模拟滤波器,在该模拟滤波器中响应于数字控制信号可以将选择的部件(例如,电阻器、电容器)切换到或切换出滤波器电路。在这种实施例中,时基控制器42包括用于生成数字控制信号的合适的逻辑电路系统,该数字控制信号选择可调谐滤波器40应用的滤波器特性。在图4的此实施例中,针对表示为m个帧的序列的模拟输入信号i(t)的示例,时基控制器42向可调谐滤波器40发出合适的控制信号以使得其将具体的滤波器特性应用到m个帧的序列的每个帧内的输入信号i(t)。这些滤波器特性的示例包括具有不同的截止频率的低通滤波器、带通滤波器、高通滤波器、陷波滤波器等,如图5的简单示例中的LPF1和LPF2的情况。例如,时基控制器42能够针对m个帧的每个,控制从可用滤波器特性的集合F={F1,F2,F3,...,FX}的可调谐滤波器40的可适用滤波器特性的选择,以使得应用于给定帧n的选择滤波器特性为该集合(例如,F(n)∈F)的成员。当然,成功的帧可以应用相同的滤波器特性,例如,如图5所示通过更长的间隔,在该间隔内应用低通滤波器LPF1。
如以上所指出的,基于在线训练功能电路18的结果或者以其他方式对应于待测的声音签名的签名/冒名数据库17中的预先知道的特征序列能够预定义在m个帧的序列内由时基控制器42选择的滤波器特性序列。
因此,根据此实施例,组帧滤波模拟信号F(n)的序列由可调谐滤波器40提供给特征提取功能电路45,根据可以在m个帧的序列的帧之间变化的滤波器特性滤波该组帧滤波模拟信号的每个信号。构造特征提取功能电路45以从每个帧中的滤波信号中提取一个或更多个特征。例如,如上述结合的美国专利申请公开号US 2015/0066495和US 2015/0066498中描述的,可以构造特征提取功能电路45来提取特征如ZC计数、ZC微分、总能量等。设想通过参考此说明连同上述结合的美国专利申请公开号US 2015/0066495和US 2015/0066498,本领域技术人员将能够容易的实现零交叉电路系统、积分器电路系统等,以根据此实施例从可调谐滤波器40产生的信号F(n)中提取期望的特征而不进行过度实验。因此,特征提取功能电路45产生所提取的特征的逐帧序列E(F(n))/ZC(F(n)),其中,在信号的持续时间内的各时间处从输入信号的具体频率中提取那些特征。
然后,如图4所示,在模拟特征提取功能电路28中将提取的特征的此序列E(F(n))/ZC(F(n))提供给事件触发器36。如以上讨论的,类似于上述结合的美国专利申请公开号US 2015/0066495和US 2015/0066498中描述的,事件触发器36被实现为将提取的特征的序列E(F(n))/ZC(F(n))与预定义的特征序列比较并基于该比较决定是否唤醒MCU 20中的数字分类器功能电路来运行完整的签名检测的逻辑。根据此实施例,事件触发器36可以依赖于序列E(F(n))/ZC(F(n))中的一个或更多个模拟信号特征来发送开始点以与已知特征比较,例如那些由在线训练18确定的已知特征或以其他方式存储在签名/冒名数据库17中的已知特征。可以将由此具体系统5识别的具体特征(例如,用户具体特征)存储在事件触发器36内部的存储器或以其他方式由事件触发器可访问的存储器中的一个或更多个声音签名的数据库中,用于在此比较中使用,从而使得提取的特征的序列E(F(n))/ZC(F(n))可以与预定义的特征序列比较,例如在每个时间间隔内(例如,一个或更多个帧)具体频率特征由可调谐模拟滤波器40应用。一旦事件触发器36检测到根据匹配准则可能匹配(例如由识别的特征序列E(F(n))/ZC(F(n))与预定义的已知特征的比较超过阈值的一些测量),事件触发器36断言启动由数字处理电路系统执行的行动的信号,如,引起MCU 20唤醒以及引起其数字分类逻辑在模拟特征提取功能电路28提取的稀疏的声音特征上执行严格的声音识别过程的触发信号。在此实施例中,特征序列E(F(n))/ZC(F(n))自身转发至ADC 29以进行数字化以及转发至MCU 20用于此严格的数字声音识别任务;替代地,接收的模拟信号自身(即不根据可调谐模拟滤波器40的时间相关的滤波而被滤波)反而可以转发至ADC 29以使得数字声音识别在完整的信号上执行。
参照图6b,现在将进一步详细描述根据另一个实施例的时间相关的模拟滤波特征提取和排序功能电路35’的构建与操作。在此布置中,提取和排序功能电路35’而不是可调谐模拟滤波器包括一组模拟滤波器50a,50b,...,50k,每个滤波器在输入信号i(t)的整个持续时间内接收和滤波所述输入信号。然而,根据此实施例,模拟滤波器50a至50k彼此应用不同滤波器特性到输入信号i(t);而图6b通过低通滤波指示示出了模拟滤波器50a至50k的每个,由这些滤波器应用的滤波特性当然不限于低通滤波器。可以由模拟滤波器50a至50k的单独的一个应用的滤波器特性的示例包括低通滤波器、带通滤波器、高通滤波器、陷波滤波器等,它们具有不同的截止频率,如图5的简单的低通滤波器示例中的LPF1和LPF2的情况。
然后,将由模拟滤波器50a至50k产生的滤波信号应用到相应的特征提取功能电路55a,55b,...,55k,这些特征提取功能电路经构造以从相应的滤波信号中提取一个或更多个特征。设想可以相似于特征提取功能电路45构造特征提取功能电路55a至55k,其中每个实例提取特征(如ZC计数器、ZC微分、总能量等),该特征提取功能电路45在上述结合的美国专利申请公开号US 2015/0066495和US 2015/0066498中描述。设想通过参考此说明连同上述结合的美国专利申请公开号US 2015/0066495和US 2015/0066498,本领域技术人员将能够容易地以零交叉电路系统、积分器电路系统等形式实现特征提取功能电路55a至55k,适合于从来自相应的模拟滤波器50a至50k的滤波信号中提取期望的特征而不进行过度实验。设想来自一个或更多个模拟滤波器50a至50k的滤波输出可以被提供至多于一个相应的特征提取功能电路55a至55k。例如,如图6b所示,将来自模拟滤波器50c的滤波信号应用于两个特征提取功能电路55c1、55c2;这些功能电路55c1、55c2可以被布置以从滤波信号中提取不同的特征,例如,用功能电路55c1提取总能量以及功能电路55c2提取ZC计数或微分等。
根据此实施例,多个模拟滤波器50a至50k的每个模拟滤波器可以被使能以在输入信号i(t)的整个持续时间内滤波输入信号i(t),特征提取功能电路55a至55k的每个特征提取功能电路的输出应用到多路复用器60的相应输入。多路复用器60的输出将特征序列E(F(n))/ZC(F(n))提供给以上描述的触发器逻辑36和ADC 29(图4)。在此实施例中,多路复用器60经构造以响应于来自时基控制器42的控制信号,从特征提取功能电路55a至55k中选择一个或更多个提取特征。类似于以上关于图6a的描述,时基控制器42包括用于产生控制信号的合适的逻辑电路系统,这些控制信号引起多路复用器60在输入信号i(t)的持续时间内的期望的帧或时间间隔处选择合适的提取特征。在模拟输入信号i(t)被呈现为m个帧的序列的图4的实施例中,时基控制器42向多路复用器60发出合适的控制信号,从而使得其在m个帧的序列中的每一个帧中的特征提取功能电路55a至55k选择所提取的特征中的一个或更多个特征。以此方式,多路复用器60的输出产生所提取的特征的逐帧序列E(F(n))/ZC(F(n)),其中,在信号的持续时间内的各时间处从输入信号的具体频率中提取那些特征。
如在图6a的实施例中,然后由时间相关的模拟滤波特征提取和排序功能电路35’的多路复用器60将所提取的特征的序列E(F(n))/ZC(F(n))提供至模拟特征提取功能电路28(图4)中的事件触发器36。如以上所描述的,事件触发器36将所提取的特征的序列E(F(n))/ZC(F(n))与预定义的特征序列比较,并且如以上相对于图6a描述的,基于该比较以及适用的匹配准则决定是否唤醒在MCU 20中的数字分类器功能以进行完整的签名检测。如果是,则触发器逻辑130断言启动对下游电路系统部分的行动的信号,例如,使MCU 20唤醒并且使其数字分类逻辑对模拟特征提取功能28所提取的稀疏声音特征执行严密的声音识别过程的信号。或者特征序列E(F(n))/ZC(F(n))自身转发至ADC 29用于数字化并且转发至MCU 20用于此严密的数字声音识别任务,或者所接收的模拟信号(由时间相关的模拟滤波特征提取和排序功能电路35’从该模拟信号中提取特征)自身转发至ADC 29用于数字化以及由MCU 20进行数字声音识别。
图7是根据这些实施例的利用A2I稀疏声音特征的示例性移动蜂窝电话1000的框图,比如用于命令识别。数字基带(DBB)单元1002可以包括数字处理处理器系统(DSP),该数字处理处理器系统包括嵌入式存储器和安全特征。激励处理(SP)单元1004从手机麦克风1013a接收语音数据流并将语音数据流发送至手机单声道扬声器1013b。SP单元1004还从麦克风1014a接收语音数据流并将语音数据流发送至单声道耳机1014b。通常,SP和DBB是单独的IC。在多数实施例中,SP并不嵌入可编程处理器芯片,但是基于由在DBB上运行的软件设置的音频路径、滤波、增益等的配置来执行处理。在可替代的实施例中,在执行DBB处理的相同的处理器上执行SP处理。在另一个实施例中,单独的DSP或者其他类型的处理器执行SP处理。
在此实施方式中,SP单元1004包括采用以上所描述的声音识别系统5的形式的A2I声音提取模块,其允许移动电话1000以超低功率消耗模式运行同时持续监测可以被配置成唤醒移动电话1000的口头字命令或者其他声音。可以提取并向数字基带模块1002提供鲁棒的声音特征用于分类和识别命令字的词汇表,该命令字然后调用移动电话1000的各种运行特征的中使用。例如,可以执行至地址簿中的联系人的语音拨号。如以上更加详细地描述的,可以经由RF收发器1006将鲁棒的声音特征发送至基于云的训练服务器。
RF收发器1006是数字无线电处理器并且包括用于经由天线1007从蜂窝基站接收编码的数据帧流的接收器,以及用于经由天线1007将编码的数据帧流发送至蜂窝基站的发送器。RF收发器1006被耦合至DBB 1002,该DBB提供对移动电话1000接收并发送的编码的数据帧的处理。
DBB单元1002可以向连接至通用串行总线(USB)端口1026的各种设备发送或者接收数据。能够将DBB 1002连接至用户识别模块(SIM)卡1010,并且该DBB能够存储并检索用于经由蜂窝系统来做出呼叫的信息。还能够将DBB 1002连接至存储器1012,该存储器增加板载内存并且用于各种处理需要。能够将DBB 1002连接至蓝牙基带单元1030用于与发送和接收语音数据的麦克风1032a和耳机1032b的无线连接。还能够将DBB 1002连接至显示器1020,该DBB能够向该显示器发送信息以在呼叫过程中与移动UE 1000进行交互。可以将触摸屏1021连接至DBB 1002用于触觉反馈。显示器1020还可以显示从网络、从本地摄像机1028或者从如USB 1026的其他源接收的图片。DBB 1002还可以经由RF收发器1006或者摄像机1028将从如蜂窝网络的各种源接收的视频流发送至显示器1020。DBB 1002还可以经由在复合输出终端1024之上的编码器1022将视频流发送至外部视频显示单元。编码器单元1022能够根据PAL/SECAM/NTSC视频标准提供编码。在一些实施例中,音频编解码器1009从FM无线电调谐器1008接收音频流并将音频流发送至立体声耳机1016和/或立体声扬声器1018。在其他实施例中,可能存在音频流的其他源,比如光盘(CD)播放器、固态存储器模块等。
根据本实施例的模拟滤波特征提取和排序功能在音频事件、命令等的识别中提供重要益处。由根据这些实施例的模拟特征提取产生的一个这种益处是减少下游数字声音识别过程的复杂性。这些实施例能够呈现所提取的特征的单个序列,而不是接收并处理由多个模拟信道处理的多个模拟特征序列,这允许数字分类器的复杂性显著减小。这些实施例还改进了通过固定频带实施方式的声音识别过程的潜在频带分辨率,在固定频带实施方式中,频带分辨率与信道数目成比例。在这些实施例中,能够向输入信号的某些时间间隔分配不同的频带,使单个信道在多个频率上达到良好的分辨率。这些实施例的这种属性还通过使训练过程提取待检测的音频事件的在时间和频率上都孤立的最独特的特征来改进声音识别过程的整体精确度和效率,这在改进识别的精确度的同时减少了识别签名的计算工作。
以上所描述的一些实施例提供硬件效率和改进的硬件性能。更具体地,与多信道方法相比,在信号持续时间内的不同时间应用不同频率特性的可调谐模拟滤波器的使用减少了模拟滤波器的数量以及在模拟前端中的特征提取功能电路的数量。此外,使用可调谐模拟滤波器的实施例消除了在多个并行运行的滤波器之间的滤波器不匹配的可能性;反而,许多相同的电路元件被用于在不同的时间应用多个滤波器特性。
设想参考本说明书的本领域的技术人员将认识到所描述的实施例的变型形式和替代形式,并且要理解的是,这种变型形式和替代形式旨在落入权利要求的范围内。例如,当这些实施例在对输入模拟信号进行组帧之后执行模拟滤波和特征提取的同时,设想可以在特征提取和识别之后可替代地执行组帧。此外,其他实施例可以包括其他类型的模拟信号处理电路,这些模拟信号处理电路可以被裁剪成提取可以用于检测如马达或引擎运行声音、电弧声音、汽车碰撞声音、刹车声音、动物咀嚼电力电缆的声音、雨声、风声等特定类型的声音的声音信息。设想参照本说明书的本领域的技术人员能够容易地实施并实现这种替代形式,而没有过度实验。
已经在本说明书中描述了一个或更多个实施例的同时,当然设想这些实施例的修改形式和替代形式,这种修改形式和替代形式能够获得本发明的一个或更多个优点和益处,这对参照本说明书以及其附图的本领域的普通技术人员而言将是明显的。设想这种修改形式和替代形式在如随后在本文中所要求保护的本发明的范围内。
- 还没有人留言评论。精彩留言会获得点赞!