一种文字直播方法及平台与流程
本发明涉及语音识别和声纹识别技术领域,尤其涉及一种文字直播方法及平台。
背景技术:
目前,对直播过程一般以人工的方式将语音转换为文字,即相关工作人员将听到的发言人的语音转换为文字,例如:有主持人、嘉宾、采访者和被访者,将各自说话的语音转为文字,并直播每句话是某个人说的。这种方式需要耗费大量的人力成本,并且受限于速度,很大可能出现转换前一句话时,没有办法集中精力听下一句话,造成漏播、错播,使文字直播效率低下。
技术实现要素:
有鉴于此,本发明实施例期望提供一种文字直播方法及平台,能将直播过程中发言者的语音转换为有序的文字,并识别出文字的归属者,提高文字直播效率,节省人力物力。
为达到上述目的,本发明实施例提供了一种文字直播方法:
将直播的语音音频进行语音识别,生成有序文字;
根据预先设置的声纹特征确定所生成的有序文字的归属;
生成有序的包含归属者的文字作为直播文字。
其中,所述将直播的语音音频进行语音识别,生成有序文字包括:将语音音频转换为文字,并根据直播的语音音频中发言者的对话顺序确定转换后的文字顺序,将按对话顺序排序的文字作为有序文字。
其中,所述根据预先设置的声纹特征确定所生成的有序文字的归属之前,所述方法还包括:
对直播的语音音频中的各个发言者进行声纹特征提取,所述声纹特征包括:声学特征、词法特征、韵律特征、语种、方言和口音特征。
其中,所述根据预先设置的声纹特征确定所生成有序文字的归属,包括:
将所述提取的声纹特征与语音音频中的发言者形成对应关系,确定直播的语音音频中当前语音音频的归属,确定所述有序文字的归属。
本发明实施例还提供了一种文字直播平台,包括:
语音识别模块,用于将直播的语音音频进行语音识别,生成有序文字;
声纹识别模块,用于根据预先设置的声纹特征确定所生成的有序文字的归属;
处理模块,用于生成有序的包含归属者的文字作为直播文字。
其中,所述语音识别模块具体用于:将语音音频转换为文字,并根据直播的语音音频中发言者的对话顺序确定转换后的文字顺序,将按对话顺序排序的文字作为有序文字。
其中,所述声纹识别模块,还用于对直播的语音音频中的各个发言者进行声纹特征提取。
其中,所述声纹识别模块具体用于:将所述提取的声纹特征与语音音频中的发言者形成对应关系,确定直播的语音音频中语音音频的归属,确定所述有序文字的归属。
本发明实施例提供的文字直播方法及平台,将直播的语音音频进行语音识别,生成有序文字;根据预先设置的声纹特征确定所生成的有序文字的归属,生成有序的包含归属者的文字作为直播文字。如此,能够实时将直播中发言者的语音音频转换为文字,并确定所述文字的归属者,再将生成的直播文字进行展示,能提高文字直播效率,节省人力物力。
附图说明
图1为本发明实施例文字直播方法实现流程示意图;
图2为本发明实施例文字直播平台的组成结构示意图;
图3为本发明实施例文字直播方法完整流程示意图。
具体实施方式
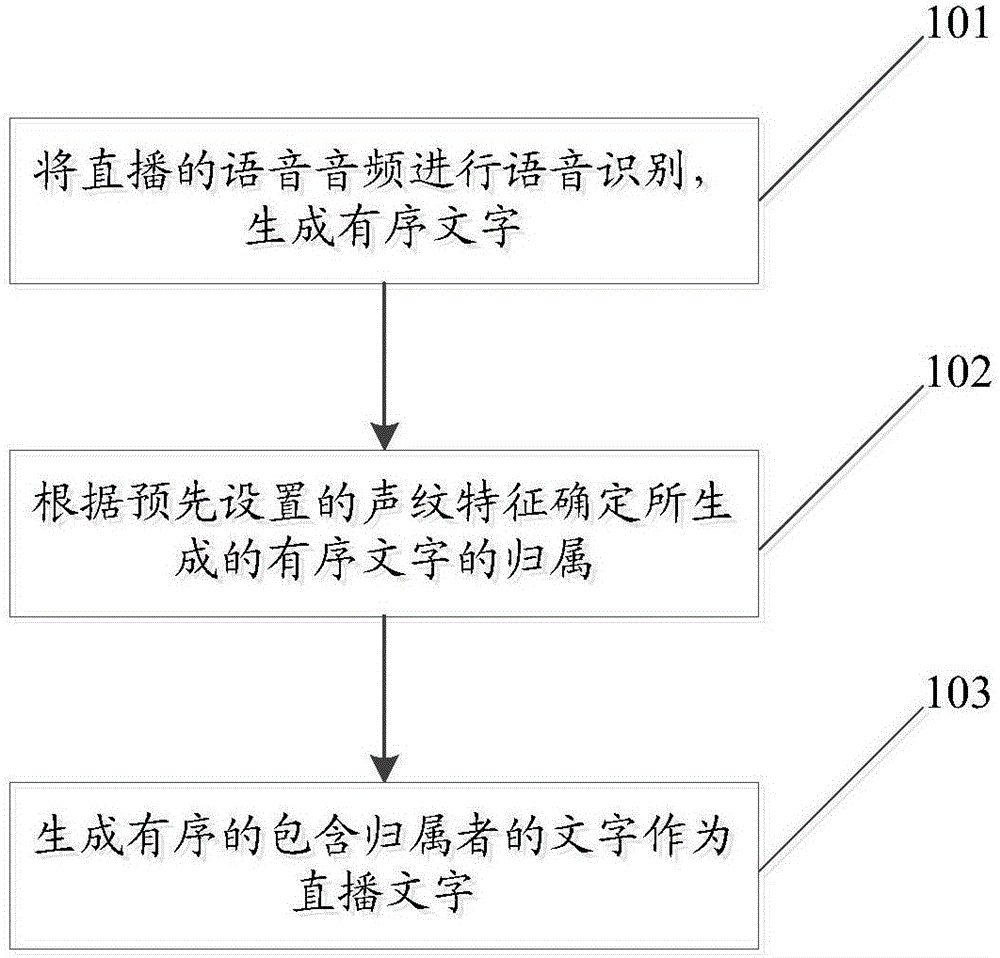
图1为本发明实施例文字直播方法实现流程示意图,如图1所示,本发明实施例文字直播方法包括以下步骤:
步骤101:将直播的语音音频进行语音识别,生成有序文字;
本步骤可采用现有的语音识别(Speech Recognize)技术识别语音音频,所谓语音识别技术,是让机器通过识别和理解过程,使其能听懂人类语言的技术;语音识别技术是信息技术中人机交互的关键技术,目前已经在呼叫中心、电信增值业务、企业信息化系统中有着广泛的应用。
随着语音识别在语音搜索、语音控制等全新应用领域的深入应用,语音识别技术被业界权威人士誉为有可能引发人机界面领域革命的关键技术。目前,语音识别技术已经可以进行针对长时间音频进行语音转换文字,再通过文字的信息服务特定的应用。
具体语音识别工具,可以采用隐性马尔科夫(HMM,Hidden Markov Model)模型,HMM模型是语音识别领域广泛采用的统计学模型,能表示出语音信号的时变特征和随机特征,能适应各种变化的发音,进而适合非特定人的大词汇量连续语音的识别工作。
本步骤中,具体的,所述将直播的语音音频进行语音识别,生成有序文字包括:通过语音识别模块将语音音频转换为文字,并根据直播的语音音频中发言者的对话顺序确定转换后的文字顺序,将按对话顺序排好序的文字作为有序文字。
步骤102:根据预先设置的声纹特征确定所生成的有序文字的归属;
本步骤之前,所述方法还包括:对直播的语音音频中的各个发言者进行声纹特征提取,所述声纹特征包括:声学特征、词法特征、韵律特征、语种、方言和口音特征;
特征提取的目的是:提取并选择对发言者的声纹具有可分性强、稳定性高等特性的声学或语言特征。与语音识别不同,声纹识别的特征必须是个性化特征,而发言者语音识别的特征,对发言者来讲必须是共性特征。
虽然,目前大部分声纹识别系统用的都是声学层面的特征,但是表征一个人特点的特征应该是多层面的,包括:(1)与人类的发音机制的解剖学结构有关的声学特征(如频谱、倒频谱、共振峰、基音、反射系数等)、鼻音、带深呼吸音、沙哑音、笑声等;(2)受社会经济状况、受教育水平、出生地等影响的语义、修辞、发音、言语习惯等;(3)个人特点或受父母影响的韵律、节奏、速度、语调、音量等特征。
从利用数学方法可以建模的角度出发,声纹自动识别模型目前可以使用的特征包括:(1)声学特征;(2)词法特征;(3)韵律特征;(4)语种、方言和口音信息。因此,采集声纹特征,应该能够有效地区分不同的发言者。
所述根据预先设置的声纹特征确定所生成的有序文字的归属,包括:将所述提取的声纹特征与语音音频中的发言者形成对应关系,确定直播的语音音频中当前语音音频的归属,进一步确定所述有序文字的归属。
在实际应用中,声纹识别可以有以下几类方法:
模板匹配方法:利用动态时间弯折以对准训练和测试特征序列,主要用于固定词组的应用;
最近邻方法:训练时保留所有特征矢量,识别时对每个矢量都找到训练矢量中最近的K个,据此进行识别,通常模型存储和相似计算的量都很大;
神经网络方法:有很多种形式,如多层感知、径向基函数等,可以显式训练以区分发言者和其背景发言者,其训练量很大,且模型的可推广性不好;
HMM方法:通常使用单状态的HMM,或高斯混合模型,是比较流行的方法,效果比较好;
VQ聚类方法:效果比较好,算法复杂度也不高,和HMM方法配合起来更可以收到更好的效果;
多项式分类器方法:有较高的精度,但模型存储和计算量都比较大。
步骤103:生成有序的包含归属者的文字作为直播文字;
根据步骤101和步骤102分别确定出了有序文字、以及文字的归属者,本步骤通过将上述内容进行编辑并进行展示,如:主持人(这里显示的是发言人的姓名):XXXXX(这里显示的是发言内容),将步骤103中语音识别出的有序文字之前加入步骤102中识别出的发言人的姓名,使用户尽量真实的感受到直播过程。
图2为本发明实施例文字直播平台的组成结构示意图,如图2所示,本发明实施例文字直播平台包括:语音识别模块201、声纹识别模块、处理模块203;其中,
语音识别模块201,用于将直播的语音音频进行语音识别,生成有序文字;
声纹识别模块202,用于根据预先设置的声纹特征确定所生成的有序文字的归属;
处理模块203,用于生成有序的包含归属者的文字作为直播文字;
其中,语音识别模块201具体用于:将语音音频转换为文字,并根据直播的语音音频中发言者的对话顺序确定转换后的文字顺序,将按对话顺序排好序的文字称为有序文字;
所述声纹识别模块202,还用于对直播的语音音频中的各个发言者进行声纹特征提取。
声纹识别模块202具体用于:将所述提取的声纹特征与语音音频中的发言者形成对应关系,确定直播的语音音频中语音音频的归属,进一步确定所述有序文字的归属。
图3为本发明实施例文字直播方法完整流程示意图,如图3所示,本发明实施例文字直播方法完整流程包括以下步骤:
步骤301:输入直播语音音频;
这里,可将直播语音音频输入到本发明实施例文字所述的直播平台中;
步骤302:进行语音识别;
其中,语音识别过程包括:将直播的语音音频进行语音识别,生成有序文字;
在实际应用中,对语音音频进行语音识别过程可以使用了数据准备、模型训练、识别测试等方法进行识别;其中,
数据准备是用来将采集的语音文件转换成可以被系统处理的用于训练的数据文件,包含:语音特征参数提取过程,主要提取语音的梅尔倒谱系数(MFCC,Mel-scale Frequency Cepstral Coefficients),其中,MFCC充分考虑的人耳的听觉特性,不仅能提高抗噪性能,而且能突出包含语音大部分信息的低频部分,有利于提高语音识别性能,对于动态性比较强的辅音,MFCC也可以能够进行很好的识别;
训练模型主要是基于Baum-Welch算法,在模型训练之前先确定隐马尔科夫模型(HMM,Hidden Markov Model)的拓扑结构,并以文本的形式进行保存,然后对语音识别模块建立HMM模型;
识别测试主要应用Viterbi算法在语音识别单元中队语音进行识别;
整个语音识别过程就是在语音数据转化之后,使用模型训练根据这些数据和相关的文本文件估计出HMM模型的参数,根据这些训练产生的模型利用语音识别模块将直播语音转换成相应的文字;
步骤303:进行声纹识别;
其中,声纹识别过程包括:先对直播的语音音频中的发言者进行声纹特征提取,将所述提取的声纹特征与语音音频中的发言者形成对应关系,确定直播的语音音频中语音音频的归属,进一步确定所述有序文字的归属。
步骤304:生成直播文字;
将步骤302和303确定出的有序文字以及文字的归属,生成直播文字进行展示。
通过上述步骤,将直播的语音音频进行语音识别,生成有序文字;根据预先设置的声纹特征确定所生成的有序文字的归属;生成有序的包含归属者的直播文字。如此,可以提高语音转换文字直播的效率,同时还可以使收看者感受真实的直播过程。
以上所述,仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!