降低语音失真的自适应波束形成方法与流程
本发明涉及人机语音识别领域,尤指一种降低语音失真的自适应波束形成方法
背景技术:
基于麦克风阵列的语音增强技术已经广泛应用于通信、人机交互、语音识别系统等中,其中广义旁瓣消除(GSC,Generailized Sidelobe Canceller)方法应用最广,这种方法易于实现且性能很好。其中GSC分成上下两个通路,上通路是固定波束模块(FBF,Fixed Beamformer)用于估计目标语音的参考信号,下通路是阻塞矩阵模块(BM,Adaptive Blocking Matrix)和自适应消除模块(MC,Multiple input Canceller),用于消除固定波束中的残留的噪声,其中阻塞矩阵模块用于消除目标语音信号而得到噪声信号。但是出消除噪声的处理过程不可避免地会对目标语音造成失真,所以,失真和降噪是一对不可调和的矛盾体,只能通过技术手段在稳定降噪的情况下,减小失真。
技术实现要素:
本发明的目的在于克服现有技术的缺陷,提出一种降低语音失真的自适应波束形成方法,所述方法包括如下步骤:
录制环境声音形成输入信号;利用固定波束形成器通过波束形成从所述输入信号中获取含噪语音信号;利用阻塞矩阵模块对所述输入信号进行滤波以形成相干噪声信号;利用自适应消除模块从所述含噪语音信号中消除所述相干噪声信号形成输出信号并予以输出;从所述输出信号中获取残余噪声信号,并将所获取的残余噪声信号反馈至所述自适应消除模块以更新所述自适应消除模块的滤波系数,从而实现在输出信号中使残余噪声信号变小的自适应滤波。
本发明的有益效果为:通过获取输出信号中的残余噪声,并将其反馈至自适应消除模块以更新自适应消除模块中的滤波系数,从而将输出信号中残余噪声信号变小,而保持目标信号不变,在达到降噪目的的同时也保证了目标信号的失真更小。
本发明的进一步改进为:还包括:从所述含噪语音信号中获取噪声信号,包括:
(1)含噪语音信号的双态假设:
H0:X=N
H1:X=S+N (式一)
H0状态表示只存在噪声,N表示噪声信号,H1状态表示含噪语音的状态,S为含噪语音信号中的目标信号;
(2)假定含噪语音信号中语音存在的先验概率:
P(H1)=0.5
P(H0)=1-P(H1) (式二)
(3)求解含噪语音信号的后验信噪比:
式三中,M是麦克风数目w是固定波束形成权重(可用延迟求和或者最小旁瓣类的方法求出权重),xi是第i个麦克风输入信号,FBF是固定波束形成器输出的含噪语音信号,|FBF|2表示波束形成器中含噪语音信号的功率,表示FBF中的噪声信号估计值的功率的估计值;
(4)利用判决引导方法求解含噪语音信号的先验信噪比ε
式四中,η为平滑系数,较佳取值为0.85,γold为含噪语音信号的上一帧的后验信噪比,GH1old表示语音信号上一帧的H1状态时的语音谱增益;
(5)求解含噪语音信号中语音存在似然度GLR
其中
(6)求解含噪语音信号中语音存在的条件先验概率P(H1|FBF)
(7)计算含噪语音信号中当前帧的H1状态语音谱增益GH1
(8)计算含噪语音信号中当前帧的噪声信号的估计值
其中为动态时域一阶平滑系数,其中,α取值0.85,E(N|FBF)是当前帧中FBF条件下中噪声信号的期望估计值,其计算如下:其中,P(H0|FBF)是语音不存在的条件概率,计算方法如下:
P(H0|FBF)=1-P(H1|FBF)
(9)计算FBF中的语音增益
其中,表示H1状态下的语音增益,表示H0状态下的语音增益,在这里Gmin=0.01(-20dB),其中Gmin是H0状态时的下限约束,取值计算公式为10*lg0.01=-20dB;
(10)估计含噪语音信号中的噪声信号
NFBF=FBF*(1-Gain) (式十)
其中,NFBF为FBF中的噪声信号的估计值。
本发明的进一步改进为:从所述目标信号中获取残余噪声信号,包括:利用从所述含噪语音信号中估计出的噪声信号估计值和所述阻塞矩阵模块形成的相干噪声信号计算出所述残余噪声信号:
R=NFBF-wHZ (式十一)
其中,R为残余噪声信号,w为自适应消除模块中自适应算法的权重,H是共轭转置操作,Z为阻塞矩阵模块输出的相干噪声信号,NFBF表示FBF中的噪声信号的估计值。
本发明的进一步改进为:式十一由以下方程推导出,
自适应消除模块的输出Y中包含了目标信号T和残余噪声信号R:
Y=T+R (方程一)
而固定波束形成器中输出的含噪语音信号包含了目标信号T和噪声信号NFBF:
FBF=T+NFBF (方程二)
而自适应消除模块的输出Y是由固定波束形成器和阻塞矩阵模块输出的相干噪声信号Z在自适应消除模块中做自适应谱减而得到:
Y=FBF-wHZ (方程三)
由上述方程一至方程三推导得出式十一。
本发明的进一步改进为:更新所述消除模块的滤波系数包括:利用归一化最小均方计算滤波系数:
式十二中,其中w是自适应消除模块中自适应算法的权重,μ是步长,Z是阻塞矩阵模块的输出的相干噪声信号,R是残余噪声信号,k是帧的索引。
附图说明
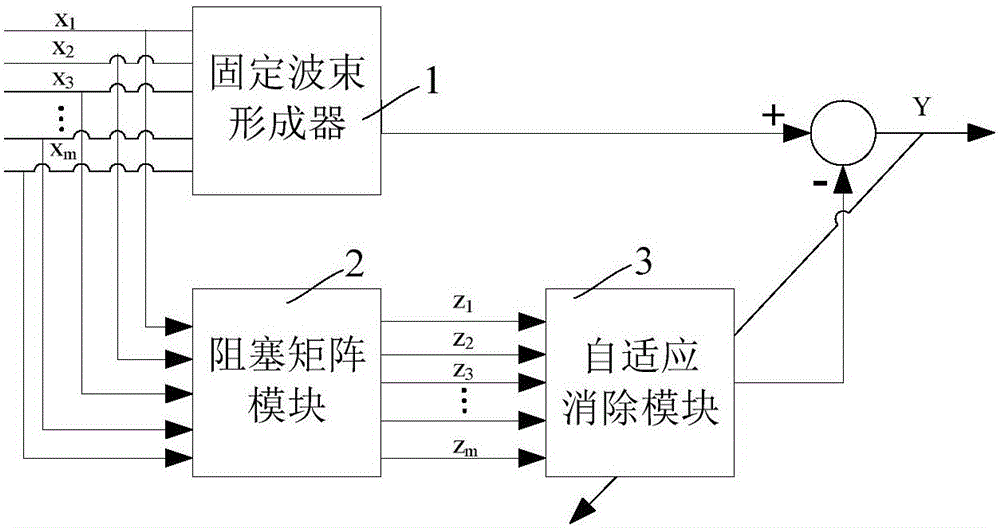
图1为降低语音失真的自适应波束形成方法的示意图。
具体实施方式
下面结合附图,对本发明作进一步详细说明。语音增强技术已经广泛应用于通信、人机交互、语音识别系统等中,该技术通过将输入的含噪信号中的噪声信号最小化以提高语音通信的质量,而在降噪的过程中,不可避免地造成了目标信号的失真。本发明通过获取输出信号中的残余噪声,并将其反馈至自适应消除模块以更新自适应消除模块中的滤波系数,从而将输出信号中的残余噪声信号变小,而保持目标信号不变,在达到降噪目的的同时也保证了目标信号的失真更小。下面,结合附图对本发明降低语音失真的自适应波束形成方法进行说明。
如图1所示,本发明公开了一种降低语音失真的自适应波束形成方法,该方法首先录制环境中的声音并经过处理形成声音的输入信号;然后将该输入信号输入到固定波束形成器1(FBF,Fixed Beamformer)内,固定波束形成器通过波束形成从输入信号中获取含噪语音信号;接着利用阻塞矩阵模块2(BM,Blocking Matrix)对输入信号进行滤波以形成相干噪声信号;利用自适应消除模块3(MC,Multiple input Canceller)从含噪语音信号中消除相干噪声信号,并形成输出信号输出,最后在输出信号内提取残余噪声信号,并将残余噪声信号反馈至自适应消除模块3以更新自适应消除模块的滤波系数,从而实现在输出信号中的残余噪声信号变小的自适应滤波。即实现了利用当前的输出信号中的残余噪声信号更新自适应消除模块的下一帧滤波系数,以使得下一帧的输出信号中的残余噪声信号变小,从而保证输出信号中的目标信号不变,使得该目标信号的失真大幅减小。
具体地,使用麦克风录制环境中的声音,并进行数字化处理形成输入信号,该麦克风可采用麦克风阵列。固定波束形成器与麦克风通信连接,接收麦克风输入的输入信号通过波束形成获取包括噪声信号和目标信号的含噪语音信号;阻塞矩阵模块2与麦克风通信连接,接收麦克风输入的输入信号,并将目标信号从输入信号中滤除以形成相干噪声信号;自适应消除模块3与固定波束形成器1和阻塞矩阵模块2通信连接,接收固定波束形成器1形成的含噪语音信号以及阻塞矩阵模块中过滤形成的相干噪声信号,并将相干噪声信号从含噪语音信号中滤除形成输出信号并输出,而该输出信号中仍存在残余噪声信号,通过一系列算法计算出输出信号中的残余噪声信号,然后将残余噪声信号反馈至自适应消除模块3,自适应消除模块在进行下一帧自适应滤波时,根据接收到的残余噪声信号更新自适应消除模块的滤波系数,从而将输出信号中的残余噪声信号进一步消除,使得输出信号中的残余信号越来越小,而保持目标信号不变,从而在进一步减小噪声信号的同时达到减小失真的目的。
进一步地,残余噪声信号是通过固定波束形成器中的噪声信号与阻塞矩阵模块中形成的相干噪声信号对比得到的,所以计算残余噪声信号之前首先计算出固定波束形成器1中的噪声信号,计算方法如下:
(1)含噪语音信号的双态假设:
H0:X=N
H1:X=S+N (式一)
H0状态表示只存在噪声,N表示噪声信号,H1状态表示含噪语音的状态,S为含噪语音信号中的目标信号;
(2)假定含噪语音信号中语音存在的先验概率:
P(H1)=0.5
P(H0)=1-P(H1) (式二)
(3)求解含噪语音信号的后验信噪比:
式三中,M是麦克风数目w是固定波束形成器中波束形成权重(可用延迟求和或者最小旁瓣类的方法求出权重),xi是第i个麦克风输入信号,FBF是固定波束形成器输出的含噪语音信号,|FBF|2表示波束形成器中含噪语音信号的功率,表示噪声信号的功率的估计值;
(4)利用判决引导方法求解含噪语音信号的先验信噪比ε
式四中,η为平滑系数,较佳取值为0.85,γold为含噪语音信号的上一帧的后验信噪比,GH1old表示语音信号上一帧的H1状态时的语音谱增益;
(5)求解含噪语音信号中语音存在似然度GLR
其中
(6)求解含噪语音信号中语音存在的条件先验概率P(H1|FBF)
(7)计算含噪语音信号中当前帧的H1状态语音谱增益GH1
(8)计算含噪语音信号中当前帧的噪声信号估计值
其中为动态时域一阶平滑系数,其中,α取值0.85,E(N|FBF)是当前帧中FBF条件下中噪声期望估计值,其计算如下:其中,
P(H0|FBF)是语音不存在的条件概率,计算方法如下:
P(H0|FBF)=1-P(H1|FBF)
(9)计算FBF中的语音增益
其中,表示H1状态下的语音增益,表示H0状态下的语音增益,但是防止H0状态语音衰减过多,通常将GH0改为Gmin,在这里Gmin=0.01(-20dB),其中Gmin是H0状态即语音不存在时的下限约束,这里设置下限为-20dB,取值计算公式为10*lg0.01=-20dB;
(10)估计含噪语音信号中的噪声信号
NFBF=FBF*(1-Gain) (式十)
其中,NFBF为FBF中的噪声信号的估计值。
进一步地,当计算出固定波束形成器输出的含噪语音信号中的噪声信号,由于自适应消除模块的输出Y中包含了目标信号T和残余噪声信号R,即,Y=T+R;而波束形成器中包含了目标信号T和噪声信号N,即FBF=T+N,而输出Y是由FBF和阻塞矩阵模块的输出Z在自适应消除模块中做自适应谱减而得到Y=FBF-wHZ。
由上述三个方程式进行推导计算,即:
Y=T+R (方程一)
FBF=T+NFBF (方程二)
Y=FBF-wHZ (方程三)
通过如下的推导过程得到式十一:
R=Y-T=(FBF-wHZ)-T=(FBF-wHZ)-(FBF-NFBF)=NFBF-wHZ
所以,推导出残余噪声信号的计算公式:
R=NFBF-wHZ (式十一)
根据式十一计算得出参与噪声信号。在计算出噪声残余信号后,将残余噪声信号反馈到自适应消除模块,自适应消除模块在进行下一帧自适应滤波时,根据接收到的残余噪声信号更新自适应消除模块的滤波系数,从而将含噪语音信号中的残余噪声信号进一步消除,使得输出信号中的残余信号越来越小,而保持目标信号不变,从而在进一步减小噪声信号的同时达到减小失真的目的。
式十二中,其中w是MC中自适应算法的权重,μ是步长,Z是阻塞矩阵模块的输出的相干噪声信号,R是残余噪声信号,k是帧的索引。
值得注意的是,在式十中计算出固定波束形成器中的噪声信号后,现有技术中有做法直接利用该噪声信号计算得到目标信号并输出,而本发明是利用该噪声信号计算输出信号中的残余噪声信号,其相比于上述做法得到的输出信号效果更加稳定,且目标信号的失真更小。理由是在利用噪声信号直接计算目标信号并输出时,该噪声信号的值为估计值,存在一定的不稳定性,从而导致利用噪声信号直接输出的目标信号也存在不稳定的情形。而本发明将残余噪声信号通过自适应滤波后不断减小,能够使得目标信号的质量不断提高。
本发明通过获取输出的目标信号中的残余噪声,并将其反馈至自适应消除模块以更新自适应消除模块中的滤波系数,从而将输出信号中残余噪声信号变小,而保持目标信号不变,在达到降噪目的的同时也保证了目标信号的失真更小。
以上结合附图及实施例对本发明进行了详细说明,本领域中普通技术人员可根据上述说明对本发明做出种种变化例。因而,实施例中的某些细节不应构成对本发明的限定,本发明将以所附权利要求书界定的范围作为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!