文本语音播报方法及系统与流程
本发明涉及人工智能语音领域,尤其涉及文本语音播报方法及系统。
背景技术:
文本语音播报应用于电信、银行、交通运输及智能机器人等,主要是对给定的文本进行语言学分析,逐句进行词汇的、语法的和语义的分析,以确定句子的低层结构和每个字的音素的组成,包括文本的断句、字词切分、多音字的处理、数字的处理、缩略语的处理等,把文本所对应的单字或短语从语音合成库中提取,把语言学描述转化成言语波形。目前市面上有不少类似的功能,但大多效果不佳,主要表现为播出的语音吐字生硬,音色单一。
技术实现要素:
为了克服现有技术的不足,本发明的目的在于提供文本语音播报方法及系统,其能对任意文本进行流畅圆润的播报。
本发明的目的采用以下技术方案实现:
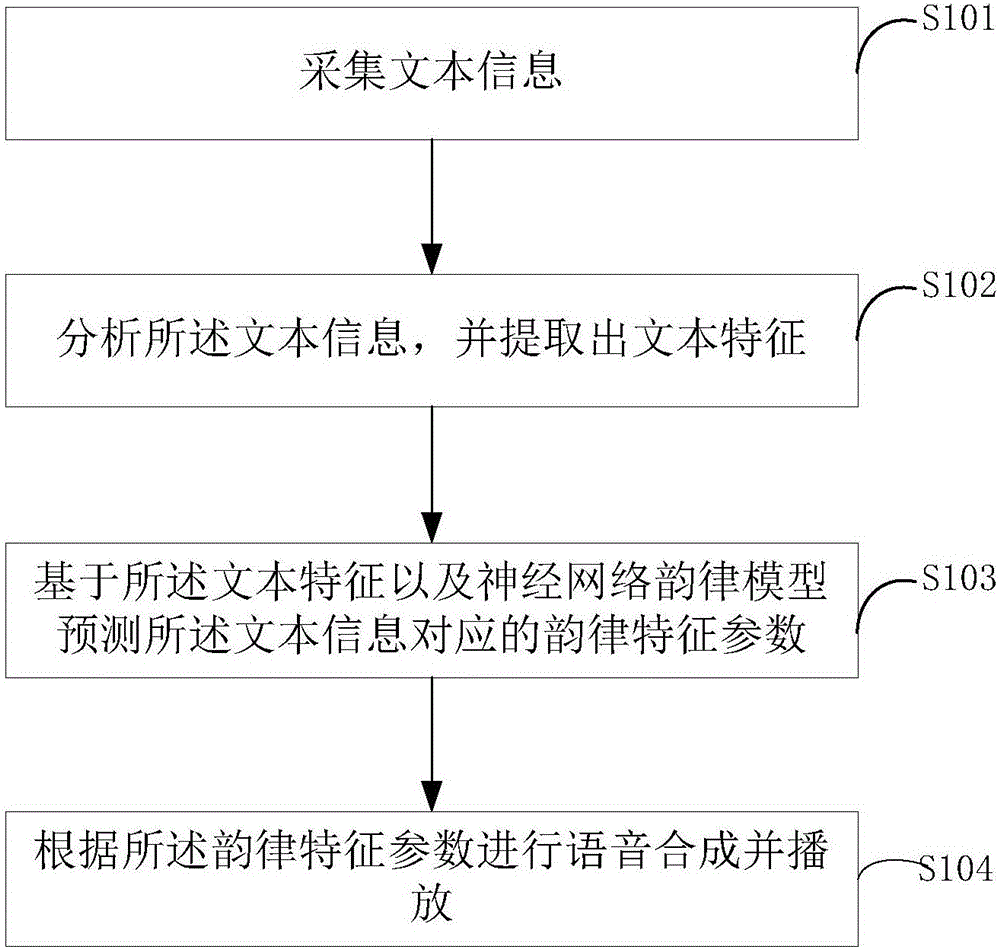
文本语音播报方法,包括:
采集文本信息;
分析所述文本信息,并提取出文本特征;
基于所述文本特征以及神经网络韵律模型预测所述文本信息对应的韵律特征参数;
根据所述韵律特征参数进行语音合成并播放。
优选的,所述分析文本信息,具体为:
根据预先添加的添加语法知识库和语法词典,利用最大匹配算法对文本信息进行切分。
优选的,所述提取出文本特征,具体为:
根据词语的属性计算词语权重,提取出文本关键词;将切分得到的字和/或词对应的词性以及关键词及关键词对应的词性作为文本信息对应的文本特征。
优选的,所述神经网络韵律模型是预先通过对语音材料库基于神经网络模型进行训练得到的。
优选的,所述语音材料库包括:用于语调短语修正的韵律词汇库以及用于参数解码音变规则的编码数据库和音变规则库。
本发明还涉及文本语音播报系统,包括:采集模块、分析模块、预测模块和合成模块;
所述采集模块,用于采集文本信息;
所述分析模块,用于分析所述文本信息,并提取出文本特征;
所述预测模块,用于基于所述文本特征以及神经网络韵律模型预测所述文本信息对应的韵律特征参数;
所述合成模块,用于根据所述韵律特征参数进行语音合成并播放。
优选的,还包括:切分模块;
所述切分模块,根据预先添加的添加语法知识库和语法词典,利用最大匹配算法对文本信息进行切分。
优选的,还包括:提取模块;
所述提取模块,用于根据词语的属性计算词语权重,提取出文本关键词;将切分得到的字和/或词对应的词性以及关键词及关键词对应的词性作为文本信息对应的文本特征。
优选的,所述神经网络韵律模型是预先通过对语音材料库基于神经网络模型进行训练得到的。
优选的,所述语音材料库包括:用于语调短语修正的韵律词汇库以及用于参数解码音变规则的编码数据库和音变规则库。
相比现有技术,本发明的有益效果在于:根据神经网络韵律模型预测所述文本信息对应的韵律特征参数进行语音合成,文本语音播报自然流畅。
附图说明
图1为本发明一实施例提供的文本语音播报方法流程示意图;
图2为本发明一实施例提供的文本语音播报系统结构示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
如图1所示,本发明一实施例提供的文本语音播报方法,包括以下步骤:
步骤S101:采集文本信息。
具体的,智能设备上的应用程序与文本播放模块接口连接,应用程序采集文本信息通过文本播放模块接口将采集到的文本信息发送给对应的文本播放模块。文本播放模块对文本进行分析处理、特征提取已经合成。
步骤S102:分析所述文本信息,并提取出文本特征。
具体的,文本播放模块预先添加语法知识库和语法词典,本发明实施例中根据最大匹配算法确定分词,并滤除不能反映主题的功能词。
对采集到的文本信息,按照正向最大匹配算法,从左边开始取出等于预设最大词长数量的词语,查找语法知识库和语法词典中是否有所述词语,若没有查找到,则去掉右边第一个字继续查找,依次循环,直到从语法知识库和语法词典中查找到相应的词语,则输出词语,完成分词过程。
能标识文本特性的一般为文本中的名词、动词、形容词等,文本中的虚词如感叹词、介词、连词等对标识文本特性往往没有贡献,不能反映主题,在提取文本特征前去掉不能反映主题的功能词,提高文本特征提取的效率和准确率。完成文本切分后,得到对应的字和/或词,将对应的字和/或词与其词性关联。
同时,本发明实施例还根据词语的属性计算词语权重,提取出文本关键词。
词语的词性、词语的长度、词语在文中出现的位置和频率等多个因素影响词语的权重,根据文本特征提取算法,将多种词语影响因素引入评价函数计算词语的权重提取出文本关键词。
将得到的字和/或词对应的词性以及关键词及关键词对应的词性作为文本信息对应的文本特征。
步骤S103:基于所述文本特征以及神经网络韵律模型预测所述文本信息对应的韵律特征参数。
具体的,本发明实施例中文本播放模块包括预先建立的神经网络韵律模型。该神经网络韵律模型是通过对语音材料库基于神经网络模型训练得到的,可以是基于现有的深度神经网络和双向LSTM神经网络进行训练得到。语音材料库中的语句涵盖了汉语中常见的句型、汉语中所有的语音、文字上下文的特性、声调、重音等信息,使用语音材料库中的句子对神经网络模型进行训练和测试,合成的语音能体现不同的韵律特征,增加了系统的灵活性和风格的多样性。当然具体的韵律模型也可以采用其他模型,比如隐马克科夫韵律模型等。
在分析得到文本特征后,将对应的文本特征输入到神经网络韵律模型进行预测,得到对应的字、词的韵律特征参数。韵律特征参数包括谱参数以及基频参数等。
优选的,所述语音材料库还包括:用于语调短语修正的韵律词汇库以及用于参数解码音变规则的编码数据库和音变规则库。用户可以根据需要设置不同的音色,语音播报更多样化。
步骤S104:根据所述韵律特征参数进行语音合成并播放。
具体的,本发明实施例中,文本播报模块的语音合成模块,将韵律特征参数发送到声码器进行语音合成,输出音频文件并发送到文本播报模块的音频播放器,完成语音播报的过程。
优选的,步骤S104之前即在韵律特征参数发送给声码器进行语音合成之前,还可以对神经网络韵律模型预测的韵律特征参数进行优化,比如对基频参数进行基频重构,或者对谱参数以及重构后的基频参数进行平滑处理。然后再将优化后的韵律特征参数发送给声码器进行语音合成。
本实施例提供的语音播报方法,克服了市面上类似产品播报语音生硬不自然,音色单一的不足,让文本的语音播报自然流畅,有更多不同的音色选择,更大程度上接近于人的语言沟通。
本发明实施例还提供文本语音播报系统,如图2所示,包括:采集模块11、分析模块14、预测模块15和合成模块16;
所述采集模块11,用于采集文本信息;
所述分析模块14,用于分析所述文本信息,并提取出文本特征;
所述预测模块15,用于基于所述文本特征以及神经网络韵律模型预测所述文本信息对应的韵律特征参数;
所述合成模块16,用于根据所述韵律特征参数进行语音合成并播放。
优选的,还包括:切分模块12;
所述切分模块12,根据预先添加的添加语法知识库和语法词典,利用最大匹配算法对文本信息进行切分。
优选的,还包括:提取模块13;
所述提取模块13,用于根据词语的属性计算词语权重,提取出文本关键词;将切分得到的字和/或词对应的词性以及关键词及关键词对应的词性作为文本信息对应的文本特征。
优选的,所述神经网络韵律模型是预先通过对语音材料库进行训练得到的。
优选的,所述语音材料库包括:用于语调短语修正的韵律词汇库以及用于参数解码音变规则的编码数据库和音变规则库。
本实施例中的系统与前述实施例中的方法是基于同一发明构思下的两个方面,在前面已经对方法实施过程作了详细的描述,所以本领域技术人员可根据前述描述清楚地了解本实施例中的系统的结构及实施过程,为了说明书的简洁,在此就不再赘述。
为了描述的方便,描述以上系统时以功能分为各种模块分别描述。当然,在实施本发明时可以把各模块的功能在同一个或多个软件和/或硬件中实现。
通过以上的实施方式的描述可知,本领域的技术人员可以清楚地了解到本发明可借助软件加必需的通用硬件平台的方式来实现。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品可以存储在存储介质中,如ROM/RAM、磁碟、光盘等,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例或者实施例的某些部分所述的方法。
本发明提供的语音播报方法及系统,克服了市面上类似产品播报语音生硬不自然,音色单一的不足,让文本的语音播报自然流畅,有更多不同的音色选择,更大程度上接近于人的语言沟通。
对本领域的技术人员来说,可根据以上描述的技术方案以及构思,做出其它各种相应的改变以及形变,而所有的这些改变以及形变都应该属于本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!