电力系统的语音导航系统、语音识别方法和语音交互方法与流程
本发明涉及语音交互系统领域,特别涉及电力系统的语音导航系统、语音识别方法和语音交互方法。
背景技术:
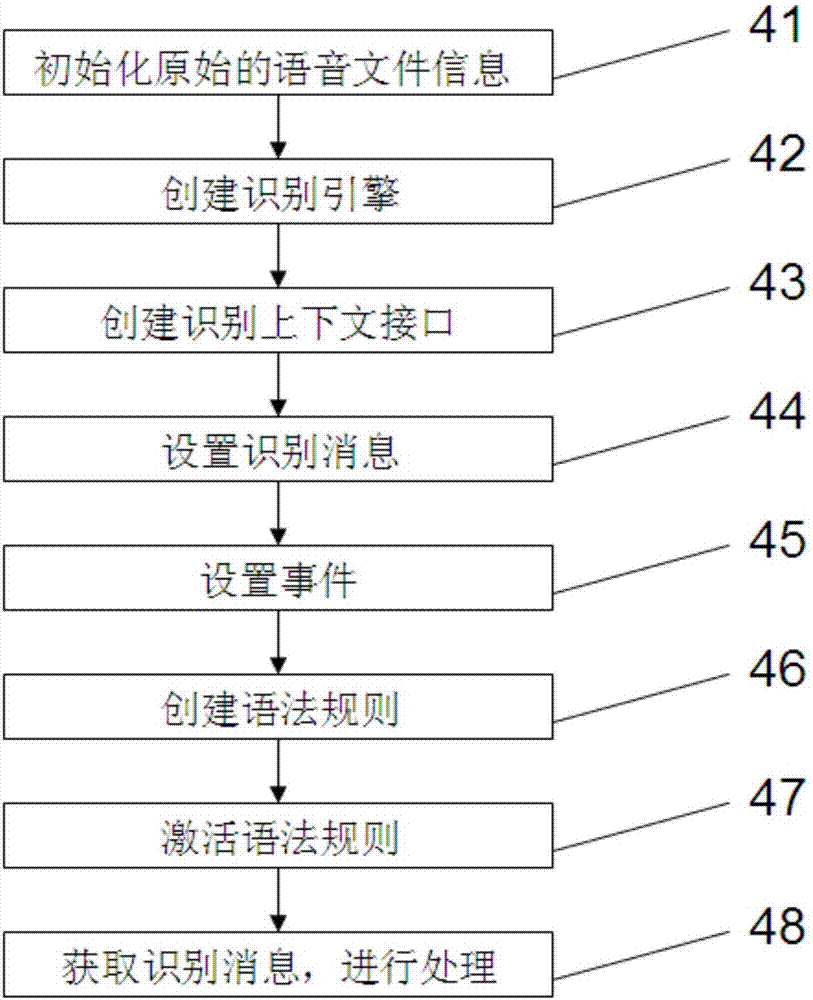
:在传统的语音导航系统中,用户与系统交互的方式是通过电话的键盘。通常,用户在进入语音导航系统后,会听到相关的语音提示选单,根据自己的需要可以按下键盘上相关的按键。系统通过dtmf信号传送用户按下的键,同时也将用户的请求传送给系统,从而触发相关的语音信息。然而,传统的电话仅能通过dtmf信号,传送有限的几个数字及符号按键。这使得用户与系统的交互界面受到很大的限制,同时也就使得语音导航系统的信息查询范围变得相当狭窄,用户在实际使用时会感到诸多不便。随着计算机技术和人工智能总体技术的发展,自然语言理解不断取得进展。语音识别系统已成为一个越来越广泛的应用方向。基于传统声学模型的语音识别技术的语音导航系统,被应用自动语音服务系统(即ivr服务)中,解决了菜单层级过深和业务无法拓展的问题,随着服务内容日趋增多,训练人工投入大、语音识别率低和系统的鲁棒性差等固有的缺点和难点也日益凸显,影响客户对自助服务的使用,从而求助人工导致人工话务压力增加。随着深度学习技术的发展,在传统的语音技术的基础上引入深度学习技术应经成为了必然趋势和解决当下问题的有效途径。技术实现要素:针对上述现有技术存在的问题,提供了电力系统的语音导航系统、语音识别方法和语音交互方法。为了实现上述目的,一种电力系统的语音导航系统,其特征在于:包括语音输入模块:客户通过手机或者固话,利用排队机接入呼叫中心系统,在cti和ivr的控制下,当用户需要语音导航业务时,通过呼叫平台实现话务接入,平台记录下的原始语音信息,并进行播报用户确认无误后,将该文件作为原始的语音文件信息输入;语音识别模块包括语音识别单元和语音文本处理单元;语音识别单元:语音识别引擎输入的原始的语音文件信息经过语音识别预处理;将经过语音识别预处理的语音文件进行离线解码或在线解码、置信度处理后转成自然语言文本信息;并将原始语音信息、原始的语音文件信息、语音特征信息存入文本/语音语库中;语音文本处理单元:将自然语言文本信息经过模式匹配处理、语法分析处理、语义解析处理、语义搜索处理、上下文管理处理以及语义预测处理后,将自然语言文本信息转换成计算机识别的语音信息作为输出物;进行业务需求分析,为自然语言处理引擎提供数据输入;作为上述方案的进一步优化,在语音识别单元中进行的语音识别预处理包括特征提取处理、端点检测处理和去燥处理。作为上述方案的进一步优化,还包括语音反馈模块,用于反馈噪音或非普通话输入的原始语音信息。作为上述方案的进一步优化,其特征在于:语音识别模块中,语音识别处理的步骤为:(41)初始化原始的语音文件信息;(42)创建识别引擎;语音识别引擎用于输入的原始的语音文件;(43)创建识别上下文接口;(44)设置识别消息;(45)设置事件;(46)创建语法规则;(47)激活语法规则:(48)获取识别消息,进行处理:本发明还公开了电力系统的语音导航系统的语音识别方法,其特征在于,语音识别单元采用深度神经网络和隐马尔科夫(dnn-hmm)混合模型,使用hmm来描述语音信号的动态变化,再使用dnn的每个输出节点来估计连续密度hmm的某个状态的后验概率。作为上述方案的进一步优化,离线解码或在线解码中:(61)首先将后验概率转为似然度p(xt/qt):p(xt/qt=s)=p(qt=s/xt)p(xt)/p(s)(1)其中,是从训练集中统计的每个状态的先验概率,ts是标记属于状态s的帧数,t是总帧数,(62)p(xt)与字词序列无关,计算时可以忽略,忽略后得到缩放的似然度(63)在dnn-hmm模型中,解码出的字词序列由以下公式确定:其中p(ω)是语言模型(lm)概率,以及上式是声学模型(am)概率,其中,p(qt/xt)由dnn模型计算得出,p(qt)是状态的先验概率,π(q0)和分别是初始状态概率和状态转移概率,(64)语言模型权重系数λ通常被用于平衡声学和语言模型得分,最终的解码路径由以下公式决定:本发明还公开了一种电力系统的语音导航系统的语音交互方法,包括如下步骤:(101)用户接通电话,语音导航系统接收到请求;(102)语音导航系统将请求发送给mcp(mediacontrolplatform)单元;(103)mcp单元返回给对应的语音文件、提示音给语音导航系统;(104)语音导航系统播报提示音给用户;(105)用户语音输入,进行识别请求;(106)语音导航系统将识别请求通过mcp单元转发至语音识别引擎;引入反馈,将用户语音识别的结果反馈给用户,得到用户的确认后,进行下一步;(107)语音识别引擎进行语音识别,并将转写文本发送给语义理解引擎;(108)语义理解引擎获取语义上下文信息,给出语义识别结果,并将结果返回给语音识别引擎;(109)语音识别引擎将语义结果返回给语音导航系统;(110)语音导航系统将语义结果发送至mcp单元,进行流程跳转控制;(111)mcp单元返回最终结果给语音导航系统;(112)语音导航系统将结果通过语音播报给用户。作为上述方案的进一步优化,对于查询类问题,语音导航系统调用webservice接口,进行信息的查询获取;且webservice接口返回给语音导航系统对应的客户的信息。与现有技术相比,本发明的电力系统的语音导航系统、语音识别方法和语音交互方法的有益效果如下:1、本发明的一种电力系统的语音导航系统,在识别率、鲁棒性方面比基于传统模型的语音导航有很大的改善和提高。本发明的一种电力系统的语音导航系统,即使在有一定噪音的环境下,系统的识别率达也能达到95%以上。2、本发明的一种电力系统的语音导航系统的语音识别方法,采用dnn-hmm模型的语音识别引擎,具有识别率高,识别速度快,可移植性好等优点。3、本发明的一种电力系统的语音导航系统的语音识别方法,,应用电力系统的语音导航系统中,在模型的训练、识别率、鲁棒性方面有显著的改善,有效提高语音识别率,为语音导航系统识别提供了新的手段。附图说明图1为本发明的电力系统的语音导航系统的结构框图;图2为本发明的语音识别处理的流程图。具体实施方式为使本发明的目的、技术方案和优点更加清楚明了,下面通过附图及实施例,对本发明进行进一步详细说明。但是应该理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限制本发明的范围。参见图1,图1为本发明的电力系统的语音导航系统的结构框图;一种电力系统的语音导航系统,包括语音输入模块、语音识别模块和数据交互模块和语音反馈模块:其中,语音输入模块:客户通过手机或者固话,利用排队机接入呼叫中心系统,在cti和ivr的控制下,当用户需要语音导航业务时,通过呼叫平台实现话务接入,平台记录下的原始语音信息,并进行播报用户确认无误后,将该文件作为原始的语音文件信息输入。语音识别模块包括语音识别单元和语音文本处理单元。语音识别单元:语音识别引擎输入的原始的语音文件信息经过语音识别预处理;将经过语音识别预处理的语音文件进行离线解码或在线解码、置信度处理后转成自然语言文本信息;并将原始语音信息、原始的语音文件信息、语音特征信息存入文本/语音语库中。在语音识别单元中进行的语音识别预处理包括特征提取处理、端点检测处理和去燥处理。其中,在语音识别单元中进行的语音识别预处理包括特征提取处理、端点检测处理和去燥处理。语音文本处理单元:将自然语言文本信息经过模式匹配处理、语法分析处理、语义解析处理、语义搜索处理、上下文管理处理以及语义预测处理后,将自然语言文本信息转换成计算机识别的语音信息作为输出物;进行业务需求分析,为自然语言处理引擎提供数据输入;数据交互模块,为用户输入的数据、系统识别的数据和反馈客户输出的数据提供交互。语音反馈模块,用于反馈噪音或非普通话输入的原始语音信息。一种电力系统的语音导航系统的语音识方法,首先调用coinitialize(null)初始化com对象,然后创建基于dnn+hmm的语音识别引擎、语法规则上下文和识别语法,并调用函数loadcmdfromfile装载文法识别规则。本发明的一种电力系统的语音导航系统调用setinterest来注册需要的事件。本发明的一种电力系统的语音导航系统的语音数据是从gvp取得的实时语音数据,将其存入内存,然后通过调用ispaudioplug的setdata方法将其送入识别引擎,调用语音识别引擎的处理模块。参见图2,语音识别处理的步骤为:(41)初始化原始的语音文件信息;本发明的优选实施例中,speechapi5.1+vc6为例:在cwinapp的子类中,调用coinitializeex函数进行com初始化,代码如下:coinitializeex(null,coinit_apartmentthreaded);//初始化com(42)创建识别引擎;语音识别引擎用于输入的原始的语音文件:本发明的优选实施例中,使用共享型,大的服务型程序使用inproc;如下:hr=m_cprecognizer.cocreateinstance(clsid_spsharedrecognizer);//sharehr=m_cprecognizer.cocreateinstance(clsid_spinprocrecognizer);//inproc如果是share型,可直接进到步骤3;如果是inproc型,必须使用isprecognizer::setinput设置语音输入。如下:ccomptr<ispobjecttoken>cpaudiotoken;//定义一个tokenhr=spgetdefaulttokenfromcategoryid(spcat_audioin,&cpaudiotoken);//建立默认的音频输入对象if(succeeded(hr)){hr=m_cprecognizer->setinput(cpaudiotoken,true);}或者:ccomptr<ispaudio>cpaudio;//定义一个音频对象hr=spcreatedefaultobjectfromcategoryid(spcat_audioin,&cpaudio);//建立默认的音频输入对象hr=m_cprecoengine->setinput(cpaudio,true);//设置识别引擎输入源。(43)创建识别上下文接口;本发明的优选实施例中,调用isprecognizer::createrecocontext创建识别上下文接口(isprecocontext),如下:hr=m_cprecoengine->createrecocontext(&m_cprecoctxt);(44)设置识别消息;本发明的优选实施例中,调用setnotifywindowmessage告诉windows哪个是识别消息,需要进行处理。如下:hr=m_cprecoctxt->setnotifywindowmessage(m_hwnd,wm_recoevent,0,0);setnotifywindowmessage定义在ispnotifysource中。(45)设置事件;本发明的优选实施例中,其中最重要的事件是”spei_recognition“。参照speventenum。代码如下:constulonglongullinterest=spfei(spei_sound_start)|spfei(spei_sound_end)|spfei(spei_recognition);hr=m_cprecoctxt->setinterest(ullinterest,ullinterest);(46)创建语法规则;本发明的优选实施例中,语法规则两种,一种是听说式(dictation),一种是命令式(commandandcontrol---c&c)。首先利用isprecocontext::creategrammar创建语法对象,然后加载不同的语法规则,如下://dictationhr=m_cprecoctxt->creategrammar(giddictation,&m_cpdictationgrammar);if(succeeded(hr)){hr=m_cpdictationgrammar->loaddictation(null,splo_static);//加载词典}//c&chr=m_cprecoctxt->creategrammar(gidcmdctrl,&m_cpcmdgrammar);然后利用isprecogrammar::loadcmdxxx加载语法(47)激活语法规则:本发明的优选实施例中,hr=m_cpdictationgrammar->setdictationstate(sprs_active);//dictationhr=m_cpcmdgrammar->setrulestate(null,null,sprs_active);//c&c(48)获取识别消息,进行处理:截获识别消息(wm_recoevent),然后处理。识别的结果放在cspevent的isprecoresult中。如下:uses_conversion;cspeventevent;switch(event.eeventid){casespei_recognition:{//识别出了语音输入m_bgotreco=true;staticconstwcharwszunrecognized[]=l"<unrecognized>";cspdynamicstringdstrtext;//取得识别结果if(failed(event.recoresult()->gettext(sp_getwholephrase,sp_getwholephrase,true,&dstrtext,null))){dstrtext=wszunrecognized;}bstrsrout;dstrtext.copytobstr(&srout);cstringrecstring;recstring.empty();recstring=srout;//进一步处理......}break;}此外,本发明还公开了一种电力系统的语音导航系统的语音识别方法,语音识别单元采用深度神经网络和隐马尔科夫(dnn-hmm)混合模型,使用hmm来描述语音信号的动态变化,再使用dnn的每个输出节点来估计连续密度hmm的某个状态的后验概率。语音识别过程中,离线解码或在线解码的步骤如下:离线解码或在线解码中:(61)首先将后验概率转为似然度p(xt/qt):p(xt/qt=s)=p(qt=s/xt)p(xt)/p(s)(1)其中,是从训练集中统计的每个状态的先验概率,ts是标记属于状态s的帧数,t是总帧数,(62)p(xt)与字词序列无关,计算时可以忽略,忽略后得到缩放的似然度对于训练语句中包含很长静音时段效果时,除以先验概率p(s),获取缩放的似然度,对于缓解标注不平衡问题很有效。(63)在dnn-hmm模型中,解码出的字词序列由以下公式确定:其中p(ω)是语言模型(lm)概率,以及上式是声学模型(am)概率,其中,p(qt/xt)由dnn模型计算得出,p(qt)是状态的先验概率,π(q0)和分别是初始状态概率和状态转移概率,各自都由hmm模型决定。(64)语言模型权重系数λ通常被用于平衡声学和语言模型得分,最终的解码路径由以下公式决定:本发明的电力系统的语音导航系统的语音交互方法,包括如下步骤:(101)用户接通电话,语音导航系统接收到请求;(102)语音导航系统将请求发送给mcp(mediacontrolplatform)单元;(103)mcp单元返回给对应的语音文件、提示音给语音导航系统;(104)语音导航系统播报提示音给用户;(105)用户语音输入,进行识别请求;(106)语音导航系统将识别请求通过mcp单元转发至语音识别引擎;引入反馈,将用户语音识别的结果反馈给用户,得到用户的确认后,进行下一步;(107)语音识别引擎进行语音识别,并将转写文本发送给语义理解引擎;(108)语义理解引擎获取语义上下文信息,给出语义识别结果,并将结果返回给语音识别引擎;(109)语音识别引擎将语义结果返回给语音导航系统;(110)语音导航系统将语义结果发送至mcp单元,进行流程跳转控制;(111)mcp单元返回最终结果给语音导航系统;(112)语音导航系统将结果通过语音播报给用户。对于查询类问题,语音导航系统调用webservice接口,进行信息的查询获取;且webservice接口返回给语音导航系统对应的客户的信息,如:电费具体是多少。与现有的语音导航系统相比,通过实验测试本发明提供的语音导航系统的语音识别模块的性能,进行了孤立单词识别、连续语音识别(连续单词识别、连续言语识别与理解)、特定人语音识别(客服)、非特定人语音识别、有限词汇识别和无限词汇识别(全音节语音识别)等各种语音的输入,结果参见表1.本发明提供的语音导航系统综合识别率达到90%,其中孤立单词识别和特定人语音识别的识别率达到100%。识别对象传统模型的语音导航系统本发明的语音导航系统孤立单词识别80%100%连续语音识别73%85%特定人语音识别(客服)89%100%非特定人语音识别82.10%94.00%有限词汇识别85%97%无限词汇识别80.20%89%综合80%90%表1基于传统模型的语音导航系统和本发明的语音导航系统效果对比图本发明的一种电力系统的语音导航系统,在识别率、鲁棒性方面比基于传统模型的语音导航有很大的改善和提高。本发明的一种电力系统的语音导航系统,即使在有一定噪音的环境下,系统的识别率达也能达到95%以上。本发明的一种电力系统的语音导航系统的语音识别方法,采用dnn-hmm模型的语音识别引擎,具有识别率高,识别速度快,可移植性好等优点。本发明的一种电力系统的语音导航系统的语音识别方法,,应用电力系统的语音导航系统中,在模型的训练、识别率、鲁棒性方面有显著的改善,有效提高语音识别率,为语音导航系统识别提供了新的手段。以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换或改进等,均应包含在本发明的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1