一种立体声音频的带宽扩展方法与装置与流程
本发明涉及网络技术应用领域,特别涉及一种立体声音频的带宽扩展方法与装置。
背景技术:
在数字音频信号处理技术中,通常将覆盖人耳可感知的20hz~20khz全部频率范围内的音频信号称作全带音频,这类信号主要应用于音乐信号的高保真重现。现阶段的音频即时通信系统无法提供足够的网络传输速率和终端处理能力,不可避免地会限制重建信号的有效带宽,优先量化编码音频信号的低频成分,进而提升音频通信系统的编码效率。
传统电话语音通信系统通常传输的是窄带信号,其频率分布在300~3400hz范围内,采样率为8khz。相关主观听力测试结果表明,窄带语音中保留了91%的音节可懂度以及99%的语句可理解性。但是相比于真实语音,在实际通话中所传输窄带信号的自然度和主观质量均有明显下降。由于高频成分的缺失,窄带语音无法良好地区分部分的清音或爆破音,并削弱了其描述说话人特性的能力。为了有效地克服窄带音频的不足,宽带音频被广泛应用到了电话语音通信领域中,其有效带宽扩展到50hz~7khz,较好地覆盖了表征语音信号重要特性的大部分频谱,实现了接近调幅广播的音质水平。然而受到历史、经济、技术等诸多问题的限制,传统固定和移动通信完全实现从窄带向宽带音频的迈进还需要相当长的一段过渡期。
作为一种有效的音频增强方法,频带扩展方法可以在不改变窄带信号信源编码和网络传输的前提下,通过分析原始音频信号的时频特性,在接收端从重建的宽带音频中人为地恢复出编码端所截去的高频成分,进而达到增强重建音频听觉质量的目的。对于听力有损人士,频带扩展方法能够进一步改善其音素和语义的分辨能力。近十几年来,许多研究机构与科研人员针对单声道语音信号的频带扩展相继提出了众多解决方案。这些方法通常分别从频谱包络扩展和频谱细节扩展两个方面出发,进而合成信号高频成分,其原理如图1所示。首先根据人耳听觉感知原理对窄带信号进行时频特征提取;接下来,借助边信息或者先验知识所描述高低频特征之间的映射关系来对高频成分的频谱包络和能量进行估计;同时,选择适当的频谱修补方法来扩展频谱细节;最终,结合扩展后的频谱包络和频谱细节,实现宽带音频信号高频成分的有效重建。
对于立体声音频,传统频带扩展方法多针对两个声道进行高频成分独立重建,这类方法仅根据单个声道重建信号的主观质量实现对信号带宽的扩展,没有考虑到两个声道中信号能量和相位的相关性,其重建立体声信号严重影响了听者对声源位置和距离的判定。
技术实现要素:
鉴于上述问题,本发明提供了一种立体声音频的带宽扩展方法与装置。
本发明提供的立体声音频的带宽扩展方法,包括以下步骤:
将立体声信号分解为直达声和扩散声;
按照预设的频带扩展方法对所述扩散声进行带宽扩展;
将所述直达声分离成多个不同方位的点声源,对多个点声源分别进行带宽扩展,得到带宽扩展后的多个点声源;
将所述带宽扩展后的多个点声源按照预先估计的方位信息进行重新混合,得到带宽扩展后的直达声;
根据所述带宽扩展后的直达声结合带宽扩展后的扩散声重建出宽带立体声音频信号。
本发明还提供了一种立体声音频的带宽扩展装置,包括:分解模块、扩散声扩展模块、直达声分离与扩展模块、重构模块;
所述分解模块,用于将立体声信号分解为直达声和扩散声;
所述扩散声扩展模块,用于按照预设的频带扩展方法对所述扩散声进行带宽扩展;
所述直达声分离与扩展模块,用于将所述直达声分离成多个不同方位的点声源,对多个点声源分别进行带宽扩展,得到带宽扩展后的多个点声源;
所述重构模块,用于将所述带宽扩展后的多个点声源按照预先估计的方位信息进行重新混合,得到带宽扩展后的直达声,根据所述带宽扩展后的直达声结合带宽扩展后的扩散声重建出宽带立体声音频信号。
本发明有益效果如下:
本发明实施例首先利用声道间的频谱相关性将输入立体声信号分解为直达声和扩散声两种成分,然后扩散声成分直接利用传统频带扩展方法进行扩展;直达声则依据不同声源在时频结构上的稀疏性分离成多个不同方位的点声源,并分别进行带宽扩展,最终扩展后的点声源依照其在原始立体声中方位信息进行重新混合,并结合带宽扩展后的扩散声成分,重建出宽带立体声音频信号。本发明解决了现有技术中仅根据单个声道重建信号的主观质量实现对信号带宽的扩展,没有考虑到两个声道中信号能量和相位的相关性,其重建立体声信号严重影响了听者对声源位置和距离的判定的问题。
附图说明
图1为现有技术中单声道语音信号频带扩展方法的基本流程图;
图2是本发明方法实施例的立体声音频的带宽扩展方法的流程图;
图3是本发明装置实施例的立体声音频的带宽扩展装置的结构示意图;
图4是本发明实例1的立体声音频的带宽扩展方法的原理框图;
图5是本发明实例1中基于深度神经网络的状态空间模型的原理框图。
具体实施方式
下面将参照附图更详细地描述本公开的示例性实施例。虽然附图中显示了本公开的示例性实施例,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。
为了解决现有技术中仅根据单个声道重建信号的主观质量实现对信号带宽的扩展,没有考虑到两个声道中信号能量和相位的相关性,其重建立体声信号严重影响了听者对声源位置和距离的判定的问题,本发明提供了一种立体声音频的带宽扩展方法与装置,以下结合附图以及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不限定本发明。
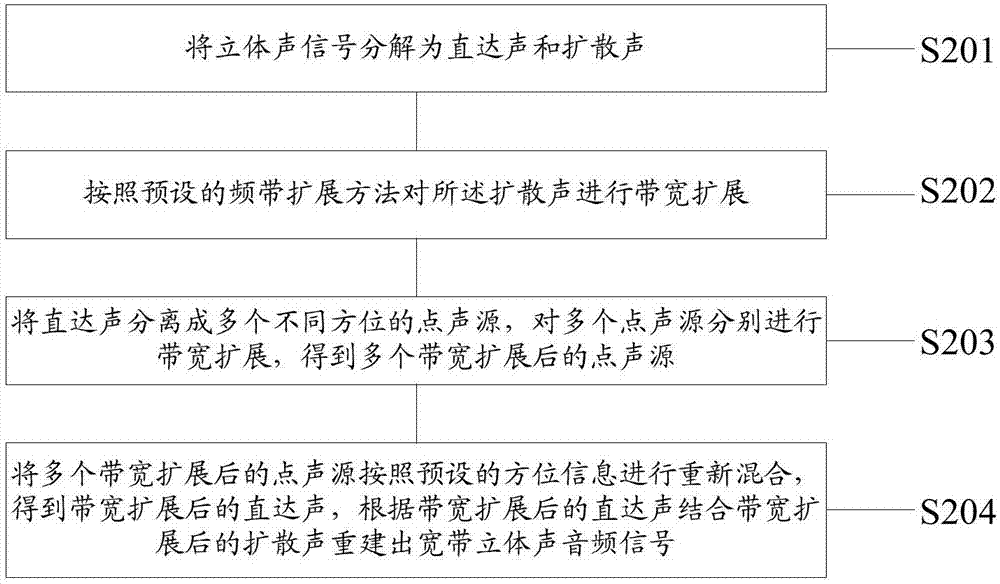
根据本发明的方法实施例,提供了一种立体声音频的带宽扩展方法,图1是本发明方法实施例的立体声音频的带宽扩展方法的流程图,如图1所示,根据本发明方法实施例的立体声音频的带宽扩展方法包括如下处理:
步骤201,将立体声信号分解为直达声和扩散声。
具体的,步骤201包括以下步骤:
将所述立体声信号分解为左声道和右声道;
分别将分帧处理后的左声道和右声道进行时频变换,得到立体声信号的左声道短时频谱成分和右声道短时频谱成分;
分别根据所述左声道短时频谱成分和右声道短时频谱成分,得到左右声道信号能量谱之间的和psum、左右声道信号能量谱之间的差pdiff、左右声道信号能量谱之间的互相关pcc;
利用所述psum、pdiff、及pcc通过最小二乘法得到直达声矩阵;
利用所述直达声矩阵从所述立体声信号中分离出直达声;
利用所述立体声信号减去所述直达声得到扩散声。
更加具体的,所述分别根据所述左声道短时频谱成分和右声道短时频谱成分,得到左右声道信号能量谱之间的和psum、左右声道信号能量谱之间的差pdiff、左右声道信号能量谱之间的互相关pcc、包括:
利用所述左声道短时频谱成分sl(t,f)和所述右声道短时频谱成分sr(t,f)根据公式psum=|sl(t,f)|2+|sr(t,f)|2计算左右声道信号能量谱之间的和psum;
利用所述左声道短时频谱成分sl(t,f)和所述右声道短时频谱成分sr(t,f)根据公式pdiff=|sl(t,f)|2-|sr(t,f)|2计算左右声道信号能量谱之间的差pdiff;
利用所述左声道短时频谱成分sl(t,f)和所述右声道短时频谱成分sr(t,f)根据公式pcc=r{sl(t,f)sr*(t,f)}计算左右声道信号能量谱之间的互相关pcc,其中r{}为取实部操作。
更加具体的,所述利用所述直达声矩阵从立体声信号中分离出直达声,包括:
利用所述直达声矩阵md(t,f)根据公式1从立体声信号s(t,f)中分离出直达声s'(t,f);
s′(t,f)=md(t,f)[sl(t,f)sr(t,f)]t公式1。
步骤202,按照预设的频带扩展方法对所述扩散声进行带宽扩展。
具体的,步骤202直接利用传统的频带扩展方法对所述扩散声进行带宽扩展,本发明不作赘述。
步骤203,将所述直达声分离成多个不同方位的点声源,对多个点声源分别进行带宽扩展,得到带宽扩展后的多个点声源。
具体的,步骤203中将所述直达声分离成多个不同方位的点声源,包括:
计算每一个时频点上直达声的方向信息,对全部时频点的方向信息进行聚类,得到方向信息的聚类中心,所述聚类中心分别对应各个点声源的方向信息;
根据某一时频点上直达声的方向信息和所述方向信息的聚类中心,得到掩蔽矩阵;
利用所述掩蔽矩阵对直达声进行分离,得到多个不同方位的点声源。
具体的,所述对多个点声源分别进行带宽扩展,包括:
将多个点声源分别输入到预设的状态空间模型中拟合窄带信号的短时频谱和宽带信号的短时频谱之间的映射关系,并根据预设的误差准则对宽带信号短时频谱高频成分的频谱包络进行估计,结合低频频谱包络和采用适当频谱修补方法扩展后的频谱细节,得到带宽扩展后的多个点声源。
更加具体的,所述在所述状态空间模型中拟合窄带信号的短时频谱和宽带信号的短时频谱之间的映射关系,并根据预设的误差准则对高频成分的频谱包络进行估计,包括:
利用前一时刻隐藏状态矢量和前一时刻窄带信号的短时频谱,得到状态空间模型中隐藏状态矢量;
利用所述状态空间模型中隐藏状态矢量和当前时刻窄带信号的短时频谱,得到宽带信号的短时频谱。
步骤204,将所述多个带宽扩展后的点声源按照预设的方位信息进行重新混合,得到带宽扩展后的直达声,根据所述带宽扩展后的直达声结合带宽扩展后的扩散声重建出宽带立体声音频信号。
具体的,所述预先估计的方位信息根据所述方向信息的聚类中心估计得到,所述估计的方法为本领域的常规技术手段,本发明对此不作赘述。
具体的,利用公式2根据所述带宽扩展后的直达声结合带宽扩展后的扩散声重建出宽带立体声音频信号;
在公式2中,
与本发明的方法实施例相对应,提供了一种立体声音频的带宽扩展装置,图3是本发明装置实施例的立体声音频的带宽扩展装置的结构示意图,如图3所示,根据本发明装置实施例的立体声音频的带宽扩展装置包括:分解模块30、扩散声扩展模块32、直达声分离与扩展模块34、重构模块36,以下对本发明实施例的各个模块进行详细的说明。
具体地,所述分解模块30,用于将立体声信号分解为直达声和扩散声;
所述扩散声扩展模块32,用于按照预设的频带扩展方法对所述扩散声进行带宽扩展;
所述直达声分离与扩展模块34,用于将所述直达声分离成多个不同方位的点声源,对多个点声源分别进行带宽扩展,得到带宽扩展后的多个点声源;
所述重构模块36,用于将所述带宽扩展后的多个点声源按照预先估计的方位信息进行重新混合,得到带宽扩展后的直达声,用于根据所述带宽扩展后的直达声结合带宽扩展后的扩散声重建出宽带立体声音频信号。
所述分解模块30具体用于:
将所述立体声信号分解为左声道和右声道;
分别将分帧处理后的左声道和右声道进行时频变换,得到立体声信号的左声道短时频谱成分和右声道短时频谱成分;
分别根据所述左声道短时频谱成分和右声道短时频谱成分,得到左右声道信号能量谱之间的和psum、左右声道信号能量谱之间的差pdiff、左右声道信号能量谱之间的互相关pcc;
利用所述psum、pdiff、及pcc通过最小二乘法得到直达声矩阵;
利用所述直达声矩阵从所述立体声信号中分离出直达声;
利用所述立体声信号减去所述直达声得到扩散声。
所述直达声分离与扩展模块34具体用于:
计算每一个时频点上直达声的方向信息,对全部时频点的方向信息进行聚类,得到方向信息的聚类中心,所述聚类中心分别对应各个点声源的方向信息;
根据某一时频点上直达声的方向信息和所述方向信息的聚类中心,得到掩蔽矩阵;
利用所述掩蔽矩阵对直达声进行分离,得到多个不同方位的点声源。
所述直达声分离与扩展模块34具体用于:
将多个点声源分别输入到预设的状态空间模型中拟合窄带信号的短时频谱和宽带信号的短时频谱之间的映射关系,并根据预设的误差准则对宽带信号短时频谱高频成分的频谱包络进行估计,结合低频频谱包络和采用适当频谱修补方法扩展后的频谱细节,最终得到带宽扩展后的直达声。
为了更加详细的说明本发明的技术方案,给出实例1,图4是本发明实例1的立体声音频的带宽扩展方法的原理框图,如图4所示,一种立体声音频的带宽扩展方法包括以下步骤:
1.直达声/扩散声分离
本文所提出的立体声扩展系统采用离散傅里叶变换或者正交镜像滤波器组将分帧后的左右声道音频信号各自转换到频域,并根据人耳听觉感知原理划分为多个均匀子带或临界频带。那么,输入立体声信号的短时频谱s(t,f)可以表示为s(t,f)=[sl(t,f)sr(t,f)]t
其中,t和f分别表示信号的时间帧和子带序号;sl(t,f)和sr(t,f)则分别表示立体声信号的左右声道短时频谱成分。
为了有效地分离直达声和扩散声,系统还需要分别计算左右声道信号能量谱之间的和psum和差pdiff以及两个声道的互相关pcc。
psum=|sl(t,f)|2+|sr(t,f)|2
pdiff=|sl(t,f)|2-|sr(t,f)|2
pcc=r{sl(t,f)sr*(t,f)}
其中,r{}为取实部操作。为了改善分离算法的稳定性,分别对计算得到的psum、pdiff和pcc进行时间平滑。
立体声左右声道中的直达声成分之间高度相关,并可表示为由某一方向传播来的点声源信号。据此,本文所提系统利用一个直达声矩阵从原始立体声双声道信号s(t,f)中直接分离出直达声成分s'(t,f),如下式所示,
s'(t,f)=[sl'(t,f)sr'(t,f)]t=md(t,f)[sl(t,f)sr(t,f)]t=md(t,f)s(t,f)
其中,sl'(t,f)和sr'(t,f)分别表示直达声的左右声道短时频谱成分,md(t,f)为直达声矩阵。根据文献【mvinton,dmcgrath,crobinson,pbrown,nextgenerationsurrounddecodingandupmixingforconsumeradprofessionalapplications.aes57thinternationalconference,usa,2015】所述,直达声矩阵md(t,f)可以利用最小二乘方法获得,从而使得估计得到的直达声成分和真实成分之间的期望平方误差最小,即
则直达声矩阵md(t,f)可以由下式计算得到,
而扩散声成分s”(t,f)则可以表示为原始立体声信号和直达声成分之差,
s”(t,f)=s(t,f)-s'(t,f)
2.直达声成分的声源分离
根据s'(t,f)=[sl'(t,f)sr'(t,f)]t利用公式3得到某一时频点上直达声s'(t,f)的方向信息θ(t,f),所述某一时频点上直达声s'(t,f)的方向信息θ(t,f)与点声源的方向信息θi相同;
对全部时频点的方向信息θ(t,f)进行聚类,得到方向信息的聚类中心ci,i=1、2…n;这些聚类中心分别对应各个点声源s1(t,f)、s2(t,f)、s3(t,f)…sn(t,f)的方向信息θ1、θ2、θ3…θn;
根据某一时频点上直达声s'(t,f)的方向信息θ(t,f)和聚类中心ci得到掩蔽矩阵mi(t,f);
利用所述掩蔽矩阵mi(t,f)根据公式4对直达声s'(t,f)进行分离,得到直达点声源
3.带宽扩展
根据上文所述方法,分别从立体声信号中分离出扩散声成分s”(t,f)和直达声成分s'(t,f),并利用时频稀疏性进一步将直达声成分s'(t,f)分离成多个点声源
本文采用状态空间模型来直接拟合窄宽带频谱参数之间的映射关系,并在实际扩展中根据一定的误差准则对高频成分的频谱包络进行估计,
sy(t,f)=f[sx(t,f)]
式中,sx(t,f)和sy(t,f)分别表示窄带和宽带信号的短时频谱,f[]表示映射(或估计)函数。
根据状态空间模型,映射函数f[]可以由状态演变函数fstate[]和观察函数fobs[]两个过程来描述,如下式所示,
shidden(t,f)=fstate[shidden(t-1,f),sx(t-1,f),n1(t,f)]
sy(t,f)=fobs[shidden(t,f),sx(t,f),n2(t,f)]
其中,shidden(t,f)为模型中隐藏状态矢量,n1(t,f)和n2(t,f)分别描述状态演变函数fstate和观测函数fobs的误差。上述模型中,当前时刻的隐藏状态矢量shidden(t,f)由前一时刻隐藏状态矢量shidden(t-1,f)和前一时刻窄带信号的短时频谱sx(t-1,f)所决定,而当前时刻宽带信号短时频谱sy(t,f)则进一步由当前时刻隐藏状态矢量shidden(t,f)和当前时刻窄带信号的短时频谱sx(t,f)决定。利用状态空间模型中蕴含的隐藏状态递归结构能够更加精确地拟合窄宽带频谱参数之间的复杂映射关系,该模型可以采用广义卡尔曼滤波方法实现,也可以采用两个相互独立的深度神经网络来实现。基于深度神经网络的状态空间模型基本原理如图5所示。此处,状态演变函数fstate和观测函数fobs可以采用堆栈自编码器、多层感知器、延时递归网络、长短时记忆网络等各种前向和递归深度神经网络实现。
4.立体声信号合成
采用单声道频带扩展方法可以分别对扩散声s”(t,f)和直达点声源
其中,
本发明实施例首先利用声道间的频谱相关性将输入立体声信号分解为直达声和扩散声两种成分,然后扩散声成分直接利用传统频带扩展方法进行扩展;直达声则依据不同声源在时频结构上的稀疏性分离成多个不同方位的点声源,并分别进行带宽扩展,最终扩展后的点声源依照其在原始立体声中方位信息进行重新混合,并结合带宽扩展后的扩散声成分,重建出宽带立体声音频信号。本发明解决了现有技术中仅根据单个声道重建信号的主观质量实现对信号带宽的扩展,没有考虑到两个声道中信号能量和相位的相关性,其重建立体声信号严重影响了听者对声源位置和距离的判定的问题。
以上所述仅为本发明的实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的权利要求范围之内。
- 还没有人留言评论。精彩留言会获得点赞!