一种基于有色噪声的语音增强方法与流程
本发明涉及信号处理技术领域,具体而言,涉及一种基于有色噪声的语音增强方法。
背景技术:
随着科技的进步和人民生活水平的提高,用户对居住环境提出了更高的需求,越来越注重家居生活的舒适、安全与便捷。智能家居旨在融合计算机、自动化控制、人工智能和网络通讯各项技术于一体,将家居环境下的各种设备终端,比如照明设备、音视频设备、安防系统、网络家电等家庭网络连接在一起,实现家居环境的智能控制。
语音是人与人之间最便捷的交互方式,智能语音技术对于改变家居环境下对电视、音箱、照明设备等控制方式有着重大革新意义,识赋予人与各终端设备良好沟通的重要桥梁。
发明人研究发现,在真实家居场景下,用户发出语音指令的同时,通过伴随各种各样的噪声,比如电视的声音、音乐等。通常需要进行语音增强。然而在语音增强的过程中,提高信噪比(snr)与提高可懂度通常是相互矛盾的。在滤除噪声的同时或多或少会损伤语音信号。通常,噪声滤除的越多,语音可懂度损害就越多,特别在低snr下这一矛盾更为突出。
传统的谱减法、维纳滤波法是在频域中进行分析的,计算量比较小,降噪效果不理想。而基于信号子空间的语音降噪算法,是将带噪语音信号投影到两个子空间中,一个是语音信号子空间,另一个是噪声子空间,通过去除噪声子空间,由语音信号子空间来重构语音信号,从而达到良好的降噪效果,但该方法属于单通道语音降噪算法,只适用于白噪声环境下的语音降噪,降噪后的语音通常伴有音乐噪声。专利cn1014660055提供了一种麦克风阵列语音增强技术,通过自适应滤波器用一个麦克风接收到的噪声抵消另一个麦克风接收到的信号中的噪声成分,保留语音成分,但是降噪的同时也会损害到语音。
技术实现要素:
有鉴于此,本发明实施例针对语音增强过程中在滤除噪音的同时会损害语音信号,导致语音的可懂度下降的技术问题,提供一种基于有色噪声的语音增强方法。
本发明是这样实施的:
一种基于有色噪声的语音增强方法,包括以下步骤:
步骤1,建立双麦克风阵列,接收得到两个通道的带噪语音信号,带噪语音信号经过时延补偿模块,以使两个通道的带噪语音信号同步;
步骤2,得到带噪语音信号数据的协方差矩阵,并进行特征值分解,将带噪语音信号空间分为信号子空间和噪声子空间;
步骤3,采用子空间法处理得到相对纯净的语音处理信号;
步骤4,在信号子空间内对语音处理信号进行最小均方方差估计,计算最小均方误差。
在步骤1中,
s11,对麦克风接收到的两个通道的带噪语音信号分别进行预处理,预处理包括对带噪语音信号进行采样处理,然后进行分帧处理,将分帧处理后的每帧信号进行加窗处理。
s12,经预处理后的带噪语音信号经过时延补偿模块,使两个麦克风的带噪语音信号准确同步,具体为:
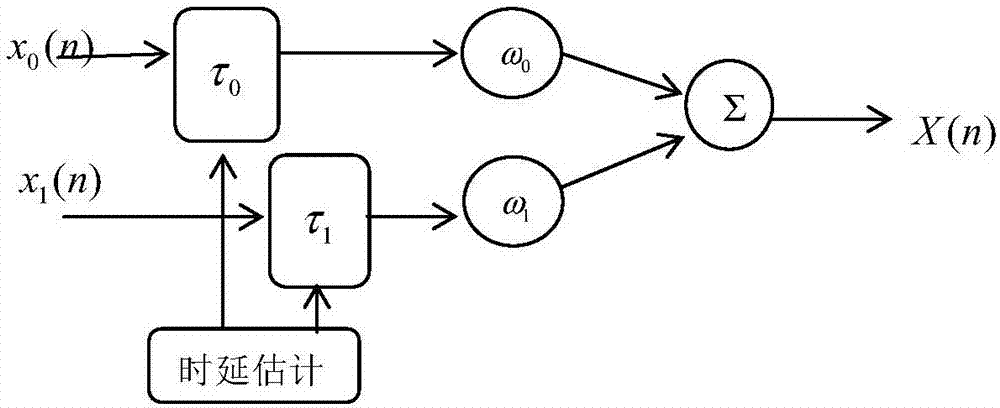
双麦克风阵列采集的两个通道的带噪语音信号分别为x0(n)和x1(n),进行傅立叶变换到频域,然后输入到时延估计单元计算x0(n)和x1(n)的相位差τ0和τ1,根据相位差计算出两个通道信号的相对延时ω0。
然后,进行延时-求和波束形成,表示为:
x(n)=ω0(n)x0(n-τ0)+ω1(n)x1(n-τ1),该过程可在某些程度上消除混响,并初略的对语音进行降噪。
在步骤2中,
s21,双麦克风阵列接收到带噪语音信号为x(n),计算得到带噪语音信号的协方差矩阵为:
其中,x(n)表示带噪语音信号,e[·]表示求矩阵期望,上标h表示共轭转置,rs表示纯净语音信号的协方差矩阵,rn表示噪声信号的协方差矩阵;。
s22,对协方差矩阵rx进行特征值分解,表示为:
rx=uλxut;
其中,λx为rx的k个特征值构成的k维对角阵,λx的所有特征值中有m个较大的特征值,0<m<k,而其余k-m个特征值很小,都等于σn2,σn2表示噪声方差。
令u=[usup」,u是矩阵rx的特征向量矩阵,因而u是正交矩阵,满足:
i=uxuxt+upupt
其中,i为k维单位矩阵;us为信号子空间,包含目标语音信号和噪声;up为噪声子空间,只包含噪声。
在步骤3中,
s31,对带噪语音信号进行kl变换,表示为:
e{utx}=0;
cov{utx}=diag(λx,1+σn2i,σn2i);
cov{uptx}=σn2i;
其中,u是矩阵rx的特征向量矩阵,up为噪声子空间,λx,1为rx的特征值构成的对角阵;
向量uptx中的语音信号能量为零,即便是噪声,在估计纯净语音信号时,此向量可以被直接去除,得到相对纯净的所述语音处理信号。
s32,将信号子空间的特征值减去噪声子空间的特征值,得到相对纯净的语音处理信号,表示为:λs=λx-λn;其中,λs为相对纯净的语音处理信号的特征值,λx为信号子空间的特征值,λn为噪声子空间的特征值。
在步骤4中,
s41,将噪声子空间up的kl分量置零,表示为:
e{utx}=0;
cov{utx}=diag(λx,1+σn2i,σn2i);
cov{uptx}=σn2i;
s42,在信号子空间us内对先相对纯净的语音处理信号的kl分量进行最小均方误差估计,具体为:
先验信噪比ξk表示为:
后验信噪比γk表示为:
其中,xk为带噪语音信号x的傅里叶变换,λs(k)为第k个频率分量下的语音方差,λn(k)为第k个频率分量下的噪声方差,sk为纯净语音的傅里叶变化,nk为噪声的傅里叶变换;
得到ξk和γk后,定义νk为:
s43,mmse增益:
s44,通过kl逆变换,输出增强语音信号。
本发明的有益效果是:该方法利用双麦阵列获得两个通道的带噪语音信号,两个麦克风的带噪语音信号通过时延补偿准备同步。然后通过子空间算法和最小均方误差估计法的结合,能够有效解决信号子空间单通道算法所产生的音乐噪声,在实现降噪的同时,有效保证语音信号的可懂度。方法简单,容易实现,且不仅对合成的带噪语音具有良好的降噪效果,对实际场景中的带噪语音也具有良好的降噪效果。此外,该语音增强方法不仅对白噪声有良好的降噪效果,且对noise92库里的其他噪声,如babble噪声、pink噪声、leopard噪声、volvo噪声等,也具有良好的降噪效果。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,应当理解,以下附图仅示出了本发明的某些实施例,因此不应被看作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图。
图1为本发明实施例的原理示意图;
图2为本发明实施例的步骤1的原理示意图;
图3为babble+white噪声经过最小均方误差算法、子空间算法和本实施例改进算法后的分段信噪比;
图4为leopard+white噪声经过最小均方误差算法、子空间算法和本实施例改进算法后的分段信噪比;
图5为pink+white噪声经过最小均方误差算法、子空间算法和本实施例改进算法后的分段信噪比;
图6为volvo+white噪声经过最小均方误差算法、子空间算法和本实施例改进算法后的分段信噪比;
图7为空调噪声下的带噪语音在不同算法下的增强语音谱图。
具体实施方式
下面将结合本发明实施例中附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。通常在此处附图中描述和示出的本发明实施例的组件可以以各种不同的配置来布置和设计。因此,以下对在附图中提供的本发明的实施例的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的选定实施例。基于本发明的实施例,本领域技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
步骤1:建立双麦克风阵列,接收得到两个通道的带噪语音信号,带噪语音信号经过时延补偿模块,以使两个通道的带噪语音信号同步;
s11,对麦克风接收到的两个通道的带噪语音信号分别进行预处理,预处理包括对带噪语音信号进行采样处理,然后进行分帧处理,将分帧处理后的每帧信号进行加窗处理,步骤如下:
采样得到带噪语音信号xi,然后进行分帧处理(i=1,2),每帧n个采样点,或帧长12ms~30ms,设m帧信号是di(m,n),其中0≤n<n,0≤m;相邻两帧有m个采样点的混叠,即当前帧的前m个采样点时前一帧的最后m个采样点,每帧有l=n-m个采样点的新数据,每m帧数据为di(m,n)=xi(m*l+n)。将分帧处理后的每帧信号进行加窗处理,采用窗函数win(n),加窗后的信号为gi(m,n)=win(n)*di(m,n)。窗函数可以选择汉明窗、汉宁窗等窗函数。
s12,经预处理后的带噪语音信号经过时延补偿模块,使两个麦克风的带噪语音信号准确同步:
如图2所示,双麦克风阵列采集的两个通道的带噪语音信号分别为x0(n)和x1(n),进行傅立叶变换到频域,然后输入到时延估计单元计算x0(n)和x1(n)的相位差τ0和τ1,根据相位差τ0计算出两个通道信号的相对延时ω0,使x0(n)和x1(n)准确同步。
进行延时-求和波束形成,表示为:
x(n)=ω0(n)x0(n-τ0)+ω1(n)x1(n-τ1)。
该过程可在某些程度上消除混响,并初略的对语音进行降噪。
步骤2,得到带噪语音信号数据的协方差矩阵,并进行特征值分解,将带噪语音信号空间分为信号子空间和噪声子空间;
s21,双麦克风阵列接收到带噪语音信号为x(n),计算得到带噪语音信号的协方差矩阵为:
其中,x(n)表示带噪语音信号,e[·]表示求矩阵期望,上标h表示共轭转置,rs表示纯净语音信号的协方差矩阵,rn表示噪声信号的协方差矩阵;。
s22,对协方差矩阵rx进行特征值分解,表示为:
rx=uλxut;
其中,λx为rx的k个特征值构成的k维对角阵,λx的所有特征值中有m个较大的特征值,0<m<k,而其余k-m个特征值很小,都等于σn2,σn2表示噪声方差。
令u=[usup」,u是矩阵rx的特征向量矩阵,因而u是正交矩阵,满足:
i=uxuxt+upupt
其中,i为k维单位矩阵;us为信号子空间,包含目标语音信号和噪声;up为噪声子空间,只包含噪声。
步骤3,采用子空间法处理得到相对纯净的语音处理信号;
s31,对带噪语音信号进行kl变换,表示为:
e{utx}=0;
cov{utx}=diag(λx,1+σn2i,σn2i);
cov{uptx}=σn2i;
其中,u是矩阵rx的特征向量矩阵,up为噪声子空间,λx,1为rx的特征值构成的对角阵;即向量uptx中的语音信号能量为零,即便是噪声,在估计纯净语音信号时,此向量可以被直接去除。
s32,将信号子空间的特征值减去噪声子空间的特征值,得到相对纯净的语音处理信号,表示为:λs=λx-λn。
其中,λs为相对纯净的语音处理信号的特征值,λx为信号子空间的特征值,λn为噪声子空间的特征值。
步骤4,在信号子空间内对语音处理信号进行最小均方方差估计,计算最小均方误差。
s41,在信号子空间us内对先相对纯净的语音处理信号的kl分量进行最小均方误差估计,具体为:
先验信噪比ξk表示为:
后验信噪比γk表示为:
其中,xk为带噪语音信号x的傅里叶变换,λs(k)为第k个频率分量下的语音方差,λn(k)为第k个频率分量下的噪声方差,sk为纯净语音的傅里叶变化,nk为噪声的傅里叶变换;
得到ξk和γk后,定义νk为:
s42,经过mmse(最小均方误差算法)增益:
s43,通过kl逆变换,输出增强语音信号。
本发明的效果可通过以下仿真说明:
通过matlab仿真,仿真条件为:采样频率fs=32000hz,信号传播速度c=340m/s,帧长为256ms,步长为帧长的一半,第k个频率分量的语音存在概率假设为0.2,取前2000采样点用于噪声估计,麦克风数量m=2,阵元间距离采用信号波长的一半。仿真结果得到原始带噪语音、最小均方误差算法、子空间算法和本设计的改进算法的分段信噪比(snrseg)。snrseg建立在度量均方误差基础上,是基于帧的信噪比,是每一帧语音信号信噪比的均值。仿真结构如图3~6所示。如图3~6所示,相比于最小均方误差算法(mmse)和子空间算法,本实施例提供的改进算法在四种噪声环境(babble+white噪声、leopard+white噪声、pink+white噪声、volvo+white噪声)均具有良好的信噪比值。
图7给出了空调噪声下的带噪语音经过不同算法去噪后的语音谱图。从图7可以看出,子空间算法对语音本身的损伤较大,mmse算法虽然对有用语音失真较小,但是对低频段的噪声的降噪效果并不如意。而本实施例的改进算法不仅对噪声具有较好的降噪效果而且对语音的损伤也做到了最小失真,最大限度保证了纯净语音的可懂度。
综上,本本发明实施例提供的语音增强方法不仅对合成的带噪语音具有良好降噪效果,且对实际的带噪语音也有较好降噪效果。
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!