语音对话系统以及语音对话方法与流程
本发明涉及语音对话系统。
背景技术:
语音对话系统期望能够与用户之间进行自然流畅的对话。
专利文献1提出有对用户发声的意图进行解释,判断是否是请求信息的检索的发声。该判断根据文章中是否包含预定的字符串等进行。在用户发声的意图为信息的检索的情况下,利用外部的搜索引擎等检索信息,获取检索结果。另一方面,在用户发声的意图不是信息的检索的情况下,从预先确定的闲聊数据中抽取与发声相应的数据。
专利文献2公开有如下内容:关于用自然语言描述的文档所包含的语句,进行语句彼此、单词彼此以及语句与单词的对应关联,将该信息保存到会话数据库。当从用户受理了用自然语言描述的疑问句的输入时,计算会话数据库中积蓄的语句与输入的疑问句的类似度,将类似度高的语句选择为回答语句。
专利文献1:日本特开2014-98844号公报
专利文献2:日本特开2001-175657号公报
技术实现要素:
专利文献1、2都是确定针对用户发声的应答语句的专利文献,但由于根据用户的1个发声确定应答,所以有时无法确定适当的系统应答。例如,在用户仅回答了“是”或者“否”的情况下,难以继续进行会话。
本发明的目的在于提供一种语音对话系统,该语音对话系统即使在用户的发声为短词的情况下也能够掌握意思并回送应答。
本发明的第一方案为一种语音对话系统(voicedialoguesystem),具备:
语音识别单元(voicerecognizer),获取用户发声(userutterance)的语音识别的结果;
对话脚本存储单元(dialoguescenariostorage),储存有多个对话脚本;以及
对话语句生成单元(dialoguetextgenerator),根据所述语音识别的结果生成对所述用户发声进行应答的对话语句,
所述对话脚本是以3个发声的内容为1个组的脚本,该3个发声内容为第1系统发声的内容、期待为针对该第1系统发声的应答的用户发声的内容以及第2系统发声的内容,该第2系统发声的内容是针对所期待的用户发声的应答,
所述对话语句生成单元判断所述用户发声是否为被期待为前1个系统发声的应答的用户发声,在是期待的用户发声的情况下,将作为针对该期待的用户发声的应答而在对话脚本中定义的第2系统发声生成为对所述用户发声进行应答的对话语句。
根据这样的结构,由于使用了对话脚本(会话模板),所以不论用户发声的长短,都能够回复考虑了前1个系统发声的内容的自然的应答。
在1个对话脚本中,也可以针对第1系统发声定义多个期待的用户发声。在该情况下,根据用户发声的内容分别登记第2系统发声的内容。因而,针对相同的系统发声,能够容易地使系统的第2应答根据用户的应答而不同。
在本发明中,所述对话语句生成单元也可以在所述用户发声不是被期待为前1个系统发声的应答的用户发声的情况下,从储存于所述对话脚本存储单元的多个对话脚本中选择任意的对话脚本,生成选择出的对话脚本中的第1系统发声的内容来作为对所述用户发声进行应答的对话语句。此时,还优选为考虑此前的会话的话题、当前的状况(场景)、用户的情绪中的至少一方来选择对话脚本。为了能够进行这样的选择,可以在对话脚本存储单元中与对话脚本对应关联地存储会话的话题、状况、用户的情绪。
另外,在本发明中,当在选择对话脚本而进行了对话语句的生成以及语音输出之后获取到用户发声的情况下,根据所述用户发声是否为在所选择出的所述对话脚本中被储存为所期待的应答的用户发声来进行所述用户发声是否为被期待为前1个系统发声的应答的用户发声的判断。
另外,在本发明中,也可以在所述对话脚本存储单元中储存有其它对话脚本,该其它对话脚本中作为第1系统发声的内容而具有至少一部分对话脚本中的第2系统发声的内容。还考虑在1个对话脚本中定义比3个发声长的对话,只要准备多个包括3个发声的脚本并将它们衔接起来进行对话,则对话脚本的管理就变容易了。
此外,本发明能够理解为具备上述单元的至少一部分的语音对话系统。另外,本发明还能够理解为构成语音对话系统的语音对话装置或者对话服务器。另外,本发明还能够理解为执行上述处理的至少一部分的语音对话方法。另外,本发明还能够理解为用于使计算机执行该方法的计算机程序、或者非临时地存储该计算机程序的计算机可读存储介质。能够最大限地相互组合上述单元以及处理的每一个来构成本发明。
根据本发明,在语音对话系统中,即使在用户的发声为短词的情况下也能够掌握意思并返回应答。
附图说明
图1是示出实施方式的语音对话系统的结构的图。
图2是示出变形例的语音对话系统的结构的图。
图3的(a)以及图3的(b)是示出对话脚本的例子的图。
图4是示出实施方式的语音对话系统中的处理的流程的例子的图。
图5是实施方式中的用户与系统之间的对话的例子。
具体实施方式
以下,参照附图,举例来详细说明本发明的一个实施方式。以下说明的实施方式是将语音对话机器人用作语音对话终端的系统,但语音对话终端并不是非机器人不可,能够使用任意的信息处理装置、语音对话接口等。
<系统结构>
图1是示出本实施方式的语音对话系统(语音对话机器人)的结构的图。本实施方式的语音对话机器人100是包括麦克风101、传感器103、扬声器108、微型处理器等运算装置、存储器以及通信装置等的计算机。利用微型处理器执行程序,从而语音对话机器人100作为语音识别部(voicerecognizer)102、场景推测部(sceneestimator)104、对话语句生成部(dialoguetextgenerator)105、对话脚本存储部(dialoguescenariostorage)106、语音合成部(voicesynthesizer)107发挥功能。虽未图示,但语音对话机器人100也可以具备图像获取装置(照相机)、可动关节部、移动单元等。
语音识别部102对从麦克风101输入的用户发声的语音数据进行噪音去除、声源分离、特征量抽取等处理,使用户发声的内容文本化。语音识别部102根据用户发声的内容推测话题,或者根据用户发声的内容或语音特征量推测用户的情绪。
场景推测部104根据从传感器103得到的传感器信息推测当前的场景。传感器103可以是任意的传感器,只要能够获取周围的信息即可。例如,能够使用获取位置信息的gps传感器,判断当前的场景是呆在家中、在工作单位工作中、还是逗留在旅游景点等。除此以外,还可以将时钟(时刻获取)、照度传感器、降雨传感器、速度传感器、加速度传感器等用作传感器103来推测当前的场景。
对话语句生成部105确定要向用户发出的系统发声的内容。典型地,对话语句生成部105根据用户发声的内容或当前会话的话题、用户的情绪、当前的场景等生成对话语句。
对话语句生成部105参照存储于对话脚本存储部106的会话模板(对话脚本)确定对话语句。会话模板是(1)系统发声、(2)期待为系统发声的应答的用户发声、(3)对所期待的用户发声进行应答的系统发声这3个发声为1组的模板。如果在依照会话模板发声之后从用户得到的应答是被期待为最初的系统发声的应答的应答,则对话语句生成部105将会话模板中定义的系统应答确定为用于对用户发声进行应答的对话语句。详情如后所述。
语音合成部107从对话语句生成部105接收发声内容的文本,进行语音合成而生成应答语音数据。从扬声器108再生由语音合成部107生成的应答语音数据。
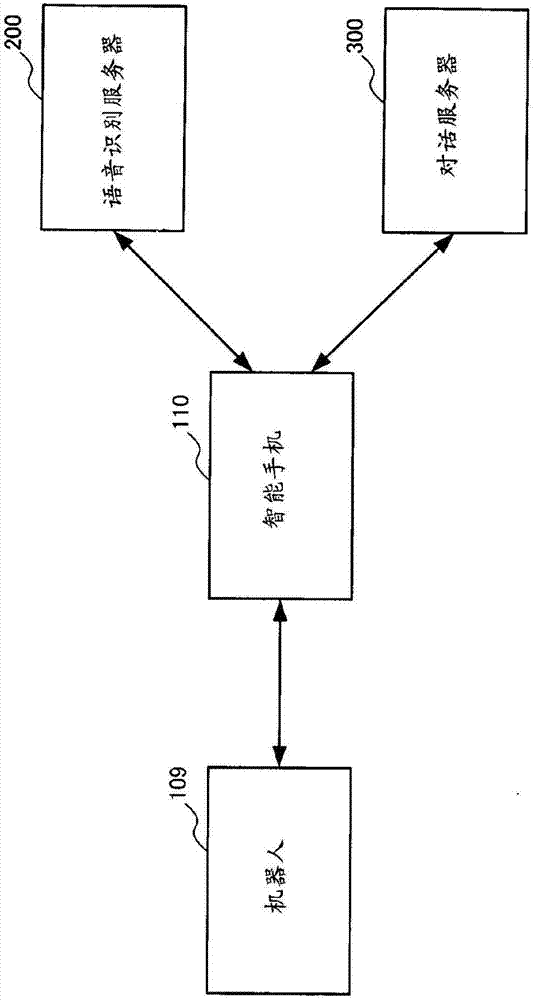
此外,语音对话机器人100并不是非要构成为1个装置不可。例如,如图2所示,能够由包括麦克风101、传感器103、扬声器108、照相机、可动关节部等的机器人装置109(前端装置)和执行各种处理的智能手机110(或者其它计算机)这两个装置构成。在该情况下,机器人装置与计算机利用蓝牙(注册商标)等无线通信连接,机器人装置所获取到的数据被送到计算机,根据由计算机得到的处理结果,由机器人装置进行应答语句等的再生。
另外,并不是非要利用语音对话机器人100进行语音识别处理、对话语句生成处理,如图2所示,也可以在语音识别服务器200和对话服务器300中进行这些处理。另外,这些处理也可以由1个服务器进行。在这样使用外部服务器进行处理的情况下,智能手机110(或者机器人装置109)控制与服务器之间的协作。
<对话脚本(会话模板)>
图3的(a)是示出本实施方式的对话脚本的一个例子的图。例如,栏301定义有如下对话脚本:在系统进行了“你好吗?”这样的发声时,如果用户回复为“挺好呀”,则系统进一步应答为“那很好”,如果用户回复为“不太好”,则系统进一步应答为“哦,那太遗憾了”。
栏302为如下对话脚本:针对“你去哪里了?”这样的系统发声,如果用户回复为“京都呀”,则系统进一步应答为“京都呀。去了清水寺吗?”,如果用户回复为“东京呀”,则系统进一步应答为“东京呀。去了东京塔吗?”。栏303为如下对话脚本:针对“今天你吃了什么?”这样的系统发声,如果用户回复为“拉面呀”,则系统进一步应答为“真好呀。我也想吃”,如果用户回复为“切面呀”,则系统进一步应答为“哦。喜欢吃切面吗?”。
单独定义这样的对话脚本很费事,所以在本实施方式中,由使用单词或者语句的属性信息的会话模板表现对话脚本,储存于对话脚本存储部106。
图3的(b)示出使用会话模板的对话脚本的例子。栏311为与栏301的对话脚本对应的会话模板,定义有如下内容:对于“你好吗?”这样的系统发声,如果用户回复肯定的应答则系统应答为“那很好”,如果用户回复否定的应答,则系统应答为“哦,那太遗憾了”。在此,<肯定>或者<否定>是意味着用户的应答语句作为整体表现肯定或者否定的属性信息。肯定的语句包括“挺好”、“状态绝佳”、“是的”、“嗯”等,否定的语句包括“不太好”、“不舒服”、“不”等。
栏312为与栏302的对话脚本对应的会话模板。在针对“你去哪里了”这样的系统发声而用户进行了与地点或设施名称有关的应答的情况下,系统重复用户说出的地点或设施名称,进而询问是否去了与该地点或设施关联的地点。关联的地点能够通过对话语句生成部105参照数据库而获取。
栏313为针对栏303的对话脚本的会话模板。针对“今天你吃了什么?”这样的系统发声,在回复为吃了用户爱吃的东西的情况下,系统应答为“真好呀。我也想吃”,在回复为吃了系统未掌握用户是否喜欢的食物的情况下,向用户询问是否喜欢该食物。在此,能够通过参照储存有用户信息的数据库来判断用户的发声所包含的食物是否为用户爱吃的东西。
图4是示出本实施方式的对话语句生成处理的流程的流程图。在此,说明语音对话系统生成从用户接受发声之后的应答时的处理。
在步骤s11中,对话语句生成部105从语音识别部102获取用户发声的识别结果,判断用户的发声是否为期待的应答。
用户发声为期待的应答(s11-是)相当于语音对话系统进行依照某个对话脚本的发声、用户回复了在该对话脚本中被定义为期待的应答的应答的情况。例如,在语音对话系统依照图3的(b)的栏312的对话脚本向用户询问“你去哪里了?”时,用户回答了地点或设施名称的情况与此相当。
在用户发声为所期待的应答的情况下(s11-是),在步骤s12中,对话语句生成部105将对话脚本中定义的应答确定为系统应答。在上述例子中,将是否去了与用户所应答的地点或设施名称关联的地点的询问(“<地点或设施名称>呀。去了<关联地点>吗?”)确定为系统应答。
另一方面,用户发声不是所期待的应答(s11-否)相当于上述以外的情况。也就是说,相当于语音对话系统进行了依照某个对话脚本的系统发声而用户却回复了在该对话脚本中被定义为期待的应答以外的应答的情况。另外,虽然用户发声了但不是对系统发声进行应答,而是用户自发地对系统搭话的情况也与此相当。
在用户发声不是期待的应答的情况(s11-否)下,在步骤s13中,对话语句生成部105根据用户发声的内容、推测场景等重新选择要采用的对话脚本。在步骤s14中,对话语句生成部105将选择出的对话脚本中的发声内容确定为系统应答。此外,选择出哪个对话脚本的情况被存储在存储部中。
图5示出依照本实施方式进行的系统与用户之间的对话的例子。首先,在步骤s21中,用户对系统搭话说“今天去旅行了”。会话因用户的该发声而开始,在该时间点,系统并未开始基于对话脚本的对话。因而,步骤s21的用户发声并不符合系统期待的应答(s11-否)。
因此,在步骤s22中,对话语句生成部105考虑用户发声的内容而选择适当的对话脚本(图3(b)的栏312)来作为其应答,进行“你去哪里了?”这样的发声(s13~s14)。
对此,用户在步骤s23中回答为“京都呀”。该应答符合对话脚本中期待的应答(<地点或设施名称>)(s11-是)。因而,对话语句生成部105将当前的对话脚本中定义的应答(<地点或设施名称>呀。去了<关联地点>吗?)作为应答。此时,将用户发声所包含的“京都”直接代入到<地点或设施名称>,将被确定为与“京都”关联的地点的“清水寺”代入到<关联地点>。然后,在步骤s24中,回复“京都呀。去了清水寺吗?”这样的系统应答(s12)。
此外,如果步骤s23中的用户发声是“是晚上回来的”这样的发声,则这不是在对话脚本中期待的应答(s11-否)。在该情况下,对话语句生成部105不采用在当前的对话脚本中定义的“<地点或设施名称>呀。去了<关联地点>吗?”这样的应答,再次从所有的对话脚本(会话模板)之中进行选择,进行所选择出的对话脚本中定义的发声(s13~s14)。
<本实施方式的有利的效果>
根据本实施方式,因为进行按照对话脚本的对话,所以即使针对系统发声的用户的应答短,也能够回复考虑了最初的系统发声的内容的自然的应答。
另外,将3个发声作为1组来管理对话脚本,所以具有对话脚本数据库的生成以及管理容易的优点。
另外,只要准备有将某个对话脚本中的第3个发声作为第1个发声的其它对话脚本,就能够实现衔接了多个对话脚本的长的对话。当得到了在某个对话脚本中期待用户返回的应答时,对话语句生成部105将在该对话脚本中定义的应答确定为发声语句,并且选择将该发声语句定义为第1发声的其它对话脚本,将该其它对话脚本重新存储为当前利用中的对话脚本即可。
<变形例>
上述说明的对话脚本仅仅是一个例子,能够采用各种变形。例如,在上述说明中,仅考虑用户发声的文语(文本)而定义了对话脚本,但也可以根据用户的情绪而使回复何种应答不同。例如,即使在针对“你去哪里了?”、“你吃了什么?”这样的发问而用户进行了相同的应答的情况下,也能够以根据用户是高兴还是悲伤等回复不同的系统应答的方式定义对话脚本。同样,还能够以根据用户所处的状况(场景)回复系统应答的方式定义对话脚本。
<其它>
上述实施方式以及变形例的结构能够在不脱离本发明的技术的思想的范围内适当地组合使用。另外,本发明也可以在不脱离其技术思想的范围施加适当的变更来实现。
- 还没有人留言评论。精彩留言会获得点赞!