一种使用QR-RLS算法对多通道语音信号去混响方法与流程
本发明属于信号处理技术领域,涉及一种使用QR-RLS算法对多通道语音信号去混响方法。
背景技术:
房间的混响问题严重的影响了语音的质量和识别系统的识别率。近年来,发展出很多的去混响算法来解决这一问题,比如波束形成技术(beamforming)和房间传输函数的逆滤波技术等。然而这些方法需要精确的DOA(direction of arrival)估计或者房间的声学参数等,因此,这些算法性能有限。
去混响技术可以根据是否需要对声学冲激响应进行估计来分类。于是把去混响技术分为混响抑制和混响消除,前者不需要估计冲激响应,而后者需要冲激响应的估计。混响抑制技术是基于以下假设:①混响是一个加性过程,②目标信号与混响信号不相关,③混响信号模型服从正态分布。混响抑制可以继续分为五大类,分别为:语音建模技术、线性预测残留增强技术、时域包络滤波技术、谱增强技术和空间处理技术。混响消除技术可以看作是冲激响应逆滤波问题。而该技术又可以继续分为:盲反卷积技术,同态解卷积技术和基于调和的去混响技术等。
现阶段使用比较广泛的去混响技术就是WPE(weighted prediction error)技术。在WPE中,MCLP(multi-channel linear predictor)被用在STFT域通过混响语音的前几帧来估计晚期混响成分。然后将混响语音与晚期混响作差,即可得到增强后的语音信号。该方法认为STFT参数独立同服从高斯分布,预测滤波器的系数在每一帧中通过最大似然估计的方法计算。
另一种基于MCLP去混响的算法是利用语音的稀疏性来实现的,使期望信号在STFT域的最大稀疏性达到去混响的目的。在此基础上产生了使用RLS算法自适应去混响的方法,但是由于RLS计算复杂度高,数值不稳定等特性,当房间的冲激响应或者声源发生移动时,去混响的效果往往不是很理想。因此,需要一种使用QR-RLS算法对语音信号去混响方法。
技术实现要素:
有鉴于此,本发明的目的在于提供一种使用QR-RLS算法对多通道语音信号去混响方法,采用QR-RLS算法来代替基于MCLP方法中的RLS算法,改善自适应去混响算法在收敛速度不变的基础上提高数值的稳定性,并且避免RLS算法中的求逆运算,使得当房间冲激响应或者声源发生移动时,可以有效的提高去混响系统的稳定性。
为达到上述目的,本发明提供如下技术方案,具体包括以下步骤:
步骤1:使用多个全指向性麦克风在封闭房间内采集带混响的语音信号;
步骤2:使用赛宾公式估计房间的混响时间T60,即直达声声压级下降60dB对应的时间,计算公式如下:
其中,α为房间吸声系数,V和S分别为房间的体积和表面积;
步骤3:将采集得到的带混响语音信号进行短时傅里叶变换,把信号由时域转化为频域,并在频域对带混响语音信号进行延迟处理得到延迟信号,延迟信号延迟的阶数由预测滤波器的长度决定;
步骤4:通过混响时间T60计算混响语音信号的衰减常数Δ,从而估计出晚期混响信号和期望信号的功率谱密度,Δ的计算公式如下:
其中,Td为语音早期反射成分的时间;
步骤5:根据步骤4得到的期望信号功率谱密度的估计值计算期望信号2范数的加权系数;
步骤6:将延迟信号和带混响语音信号作为QR-RLS算法的输入数据,对其进行迭代更新,最后输出预测滤波器系数;
步骤7:将延迟信号与预测滤波器系数相乘得到晚期混响信号,带混响语音信号减去晚期混响信号等于去混响后的期望信号,对去混响后的期望信号进行逆傅里叶变换,得到时域上的去混响后的期望信号。
进一步,所述步骤4中,采用多个间隔一定距离的麦克风对混响语音进行采集,产生多通道的带混响语音数据,采用多通道线性预测(MCLP)模型对晚期混响信号进行建模,晚期混响信号成分u(n)即为延迟麦克风信号的和,即:
其中G(n)=[g1(n),…,gM(n)]代表多输入多输出预测滤波器的预测系数,gM(n)为第M个麦克风的预测系数,为延迟后的带混响数据。
进一步,所述步骤4中,晚期混响信号和期望信号的功率谱密度的估计:
假设晚期混响信号的功率谱密度是基于指数衰减的模型,首先计算衰减系数Δ,估计房间的混响时间T60、语音早期反射成分的时间Td;然后估计晚期混响信号和带混响语音信号的PSD,两者相减得到期望信号的PSD;在期望信号PSD的计算中需要对其平滑处理。
进一步,所述步骤5中,计算期望信号2范数的加权系数;
线性预测滤波器系数估计基于期望信号在时域的最大稀疏性,即期望信号的混合p范数;预测滤波器系数的最优化问题使用QR-RLS算法来解决,使用加权2范数来近似表示p范数,加权2范数的权系数依赖于期望信号PSD,则期望信号2范数的加权系数计算公式如下:
其中,M是麦克风的数量,ε是非常小的正数,p是范数,是期望信号的PSD估计值。
进一步,所述步骤6中,QR-RLS算法自适应计算预测滤波器的系数:
首先对QR-RLS算法中的参数进行初始化,对输入数据的矩阵进行对角化,通过基本的Givens旋转矩阵得到所有的三角化矩阵;计算Givens旋转元素,将旋转元素分别用于信息矩阵和期望的信息向量,应用Givens旋转余弦元素计算误差信号,最后通过迭代更新的方式得到预测滤波器的预测系数。
本发明的有益效果在于:在收敛速度不变的基础上,充分利用QR-RLS算法的数值稳定性特性,有效避免了当输入信号不具有一致性激励性时,自相关矩阵及其对应的求逆问题是病态的问题;而且QR-RLS算法采用的QR分解方法避免了RLS问题不准确求解问题,在病态环境下可以很容易的随时检查变换信息矩阵的正定性,从而有效提升了去混响系统中自适应模块的稳定性。
附图说明
为了使本发明的目的、技术方案和有益效果更加清楚,本发明提供如下附图进行说明:
图1为多通道线性预测模型图;
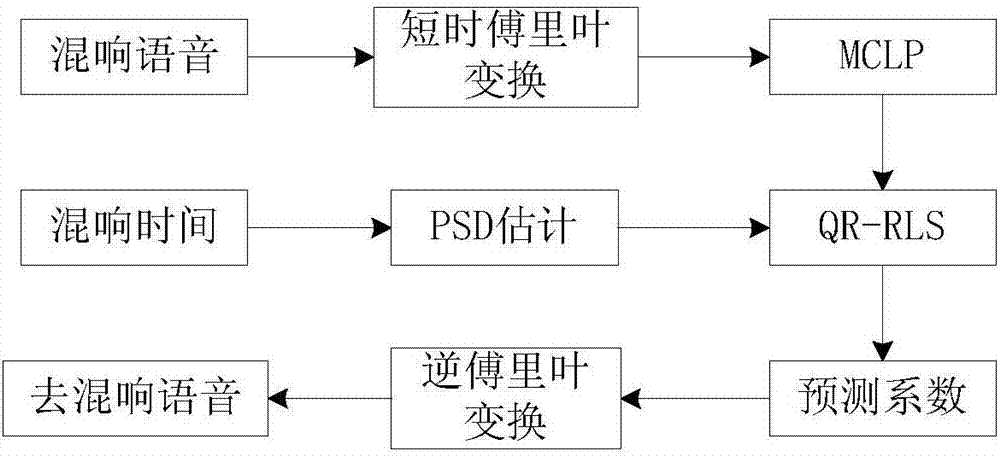
图2为使用QR-RLS算法去语音混响的流程图。
具体实施方式
下面将结合附图,对本发明的优选实施例进行详细的描述。
图2为使用QR-RLS算法去语音混响的流程图,一种使用QR-RLS算法对多通道语音信号去混响方法的具体实施步骤包括:
步骤1:使用两个全指向性麦克风在封闭房间内采集带混响的语音信号;
步骤2:使用赛宾公式估计房间的混响时间T60,即直达声声压级下降60dB对应的时间,计算公式如下:
其中,α为房间吸声系数,V和S分别为房间的体积和表面积;
步骤3:将采集得到的带混响语音信号进行短时傅里叶变换,把信号由时域转化为频域,并在频域对带混响语音信号进行延迟处理得到延迟信号,延迟信号延迟的阶数由预测滤波器的长度决定;
步骤4:通过混响时间T60计算混响语音信号的衰减常数Δ,从而估计出晚期混响信号和期望信号的功率谱密度,Δ的计算公式如下:
其中,Td为语音早期反射成分的时间。
采用两个间隔一定距离的麦克风对混响语音进行采集,产生两通道的带混响语音数据,采用多通道线性预测(MCLP)模型对晚期混响信号进行建模,晚期混响信号成分u(n)即为延迟麦克风信号的和,即:
其中G(n)=[g1(n),…,gM(n)]代表多输入多输出预测滤波器的预测系数,gM(n)为第M个麦克风的预测系数,为延迟后的带混响数据,原理图如图1,使用过去的信号来估计当前信号。
晚期混响信号和期望信号的功率谱密度的估计:假设晚期混响信号的功率谱密度是基于指数衰减的模型,首先计算衰减系数Δ,估计房间的混响时间T60、语音早期反射成分的时间Td;然后估计晚期混响信号和带混响语音信号的PSD,两者相减得到期望信号的PSD;在期望信号PSD的计算中需要对其平滑处理。
步骤5:根据步骤4得到的期望信号功率谱密度的估计值计算期望信号2范数的加权系数:线性预测滤波器系数估计基于期望信号在时域的最大稀疏性,即期望信号的混合p范数;预测滤波器系数的最优化问题使用QR-RLS算法来解决,使用加权2范数来近似表示p范数,加权2范数的权系数依赖于期望信号PSD,则期望信号2范数的加权系数计算公式如下:
其中,M是麦克风的数量,ε是非常小的正数,p是范数,是期望信号的PSD估计值。
步骤6:将延迟信号和带混响语音信号作为QR-RLS算法的输入数据,对输入数据的矩阵进行对角化,通过基本的Givens旋转矩阵得到所有的三角化矩阵;计算Givens旋转元素,将旋转元素分别用于信息矩阵和期望的信息向量,应用Givens旋转余弦元素计算误差信号,最后通过迭代更新的方式得到预测滤波器的预测系数。
步骤7:将延迟的带混响信号与预测滤波器系数相乘得到晚期混响信号,带混响语音信号减去晚期混响信号等于去混响后的期望信号,对去混响后的期望信号进行逆傅里叶变换,得到时域上的去混响后的期望信号。
最后说明的是,以上优选实施例仅用以说明本发明的技术方案而非限制,尽管通过上述优选实施例已经对本发明进行了详细的描述,但本领域技术人员应当理解,可以在形式上和细节上对其作出各种各样的改变,而不偏离本发明权利要求书所限定的范围。
- 还没有人留言评论。精彩留言会获得点赞!