身份信息关联系统与方法、计算机存储介质及用户设备与流程
本发明涉及一种大数据分析技术,尤其涉及一种身份信息关联系统及方法、计算机存储介质及用户设备。
背景技术:
:目前多数软件都需要用户进行注册,注册时都需要手动输入用户的个人身份信息,特别是用户名,例如办理会员卡、应聘时,需要手动填写个人身份信息表格,甚至需要照片。这种方式需要预先进行记录,在一些特殊场合,如进行一次性会议时,无法预先记录参与者信息。技术实现要素:鉴于上述状况,有必要提供一种无需预先注册并可基于用户行为分析的身份信息关联系统及方法、计算机存储介质及用户设备。一种身份信息关联方法,应用于一身份信息关联装置中,该方法包括:识别场景内的个体;记录所述场景内的声音信息;识别所述声音信息中的个体声音;判断一目标个体是否对所述个体声音中一触发声音具有应答动作;记录所述触发声音;及关联所述触发声音与所述目标个体。进一步地,在所述关联所述触发声音与所述目标个体之前,所述方法还包括以下步骤:分析多个触发声音的语义;及判断多个触发声音中相同语义的个数是否超过预设个数。进一步地,所述判断一目标个体是否对所述声音信息中一触发声音具有应答动作包括:判断所述触发声音后所述目标个体是否有身体动作;判断所述身体动作幅度是否超过一预定幅度;及判断多个个体是否同时具有所述身体动作。进一步地,所述身体动作包括头部动作、脸部动作及手部动作至少其中之一,所述头部动作包括抬头或转头,所述脸部动作包括特定的嘴部动作或眼部动作,所述手部动作包括举手应答动作。一种身份信息关联系统,包括:视频监测模组,用以识别场景内的个体;声音监测模组,用以记录所述场景内的声音信息;声音识别模组,用以识别所述声音信息中的个体声音;应答判断模组,用以判断一目标个体是否对所述个体信息中一触发声音具有应答动作;触发记录模组,用以记录所述触发声音;及身份关联模组,用以关联所述触发声音与所述目标个体。进一步地,所述身份信息关联系统还包括语义分析模组、声音转换模组及语义判断模组,所述语音分析模组用以分析多个触发语音的语义,所述语义判断模组还用以判断多个触发声音中相同语义的个数是否超过预设个数;所述声音转换模组用以当多个触发声音中相同语义的个数超过预设个数时将所述触发声音转换为文字关联所述目标个体。进一步地,所述应答判断模组还用以判断所述触发声音后所述目标个体是否有身体动作、判断所述身体动作幅度是否超过一预定幅度、及判断多个个体是否同时具有所述身体动作。进一步地,所述身体动作包括头部动作、脸部动作及手部动作至少其中之一,所述头部动作包括抬头或转头,所述脸部动作包括特定的嘴部动作或眼部动作,所述手部动作包括举手应答动作。一种计算机存储介质,该计算机存储介质存储多条指令,所述多条指令适于由处理器加载并执行上述身份信息关联方法。一种用户设备,包括:处理器,用以实现一条或一条以上指令;及计算机存储介质,用以存储多条指令,所述多条指令适于由处理器加载并执行上述身份信息关联方法。上述身份信息关联系统及方法,将目标个体与对应的称呼转换的文字进行关联储存,当需要使用用户名等身份信息时,仅需要识别个体特征,例如体征及体态就可以,无需手动进行填写。附图说明图1为本发明一实施方式中身份信息关联方法的步骤流程图。图2为图1中身份信息关联方法的判断目标环境中是否有应答身体动作的步骤流程图。图3为本发明一实施方式中身份信息关联系统的结构框图。图4为本发明一实施方式中一用户设备的结构框图。主要元件符号说明视频监测模组31声音监测模组32声音识别模组33应答判断模组34触发记录模组35身份关联模组36声音转换模组37语义分析模组38语音判断模组39处理器71计算机存储介质73如下具体实施方式将结合上述附图进一步说明本发明。具体实施方式下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。需要说明的是,当一个元件被认为是“连接”另一个元件,它可以是直接连接到另一个元件或者可能同时存在居中设置的元件。当一个元件被认为是“设置于”另一个元件,它可以是直接设置在另一个元件上或者可能同时存在居中设置的元件。除非另有定义,本文所使用的所有的技术和科学术语与属于本发明的
技术领域:
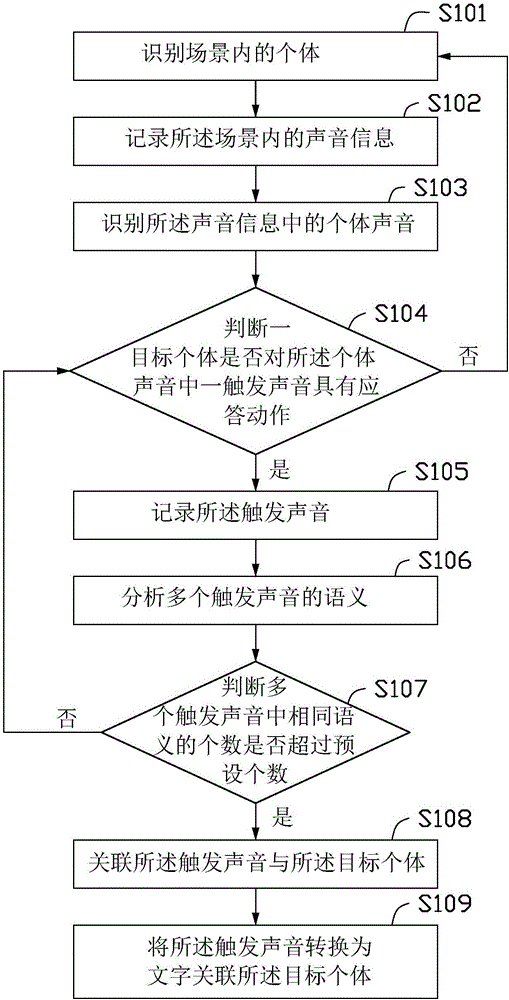
的技术人员通常理解的含义相同。本文中在本发明的说明书中所使用的术语只是为了描述具体的实施例的目的,不是旨在于限制本发明。本文所使用的术语“及/或”包括一个或多个相关的所列项目的任意的和所有的组合。请参阅图1,本发明一实施方式中提供一种身份信息关联方法,可通过对个体的行为分析获取并记录其身份信息。该方法包括以下步骤:步骤s101:识别场景内的个体。所述场景是固定区活动空间,例如会议室、超市、实验室、教室、餐厅、商场等,通过视频监测装置监测。所述个体可为人体、动物或人造物,如人工智能机器人等。所述视频监测装置为摄像头。视频监测装置可通过体征识别(如脸部识别)及体态识别等方式确定并跟踪每个个体。步骤s102:记录所述场景内的声音信息。通过声音监测装置来收录目标场景中的声音;在一实施方式中,所述声音监测装置为麦克风。场景中的声音可包括个体所发出的声音及其他声音。步骤s103:识别所述声音信息中的个体声音。可通过声音频率、结合视频中个体的体态变化如张嘴的动作,或识别语义的方式来识别声音信息中的个体声音。步骤s104:判断一目标个体是否对所述个体声音中一触发声音具有应答动作,如果是,执行步骤s105,如果否,返回步骤s101。所述应答动作包括头部动作、脸部动作及手部动作至少其中之一,头部动作包括抬头、转头,脸部动作包括特定的嘴部动作、眼部动作,手部动作包括举手应答;所述触发声音包括目标个体的称呼,例如姓名、外号、昵称等。步骤s105:记录所述触发声音。步骤s106:分析多个触发声音的语义。步骤s107:判断多个触发声音中相同语义的个数是否超过预设个数,如果是,执行步骤s108,如果否,返回步骤s104。步骤s108:关联所述触发声音与所述目标个体。步骤s109:将所述触发声音转换为文字关联所述目标个体。将所述触发声音转换为文字与所述目标个体关联后,在需要注册的时候,就可以直接通过体征识别(如脸部识别)或体态识别来注册,不需要手动注册。利用目标个体与关联的文字,数据库中还可以通过大数据分析关联与文字对应的其他个人资料,例如职涯经历、求诊数据、健康情况等。当经过体征识别或体态识别后,就可以知道对应的称呼及相关的个人资料。请同时参阅图2,步骤s103包括:步骤s201:判断所述触发声音后所述目标个体是否有身体动作,如果是,执行步骤s202,如果否,仅需执行步骤s201。步骤s202,判断所述身体动作幅度是否超过一预定幅度,如果是,执行步骤s203,如果否,返回步骤s201。所述身体动作包括头部动作、脸部动作及手部动作至少其中之一,头部动作包括抬头、转头,脸部动作包括特定的嘴部动作、眼部动作,手部动作包括举手应答。步骤s203:判断多个个体是否同时具有所述身体动作,如果否,执行步骤s204,如果是,返回步骤s201。步骤s204:记录该身体动作为应答动作。请参阅图3,本发明一实施方式中的身份信息关联系统包括:视频监测模组31,用以识别场景内的个体。所述场景是固定区活动空间,例如会议室、超市、实验室、教室、餐厅、商场等。所述个体可为人体、动物或人造物,如人工智能机器人等。所述视频监测装置为摄像头。视频监测模组31可通过体征识别(如脸部识别)及体态识别等方式确定并跟踪每个个体。声音监测模组32,用以记录所述场景内的声音信息。通过在所述目标场景中装设声音监测装置来收录目标场景中的声音;在一实施方式中,所述声音监测装置为麦克风。场景中的声音可包括个体所发出的声音及其他声音。声音识别模组33,用以识别所述声音信息中的个体声音。可通过的声音频率、结合视频中个体的体态变化或识别语义的方式,如张嘴的动作来识别声音信息中的个体声音。应答判断模组34,用以判断一目标个体是否对所述个体声音中一触发声音具有应答动作。所述应答动作包括头部动作、脸部动作及手部动作至少其中之一,头部动作包括抬头、转头,脸部动作包括特定的嘴部动作、眼部动作,手部动作包括举手应答。所述应答判断模组34通过判断目标场景中是否有身体动作和判断身体动作幅度是否超过一预定幅度及判断多个个体是否同时具有所述身体动作来判断是否应答动作。身体动作包括头部动作、脸部动作及手部动作,头部动作包括抬头、转头,脸部动作包括特定的嘴部动作、眼部动作,手部动作包括举手应答。当身体动作幅度太小或多人都有身体动作时,不被认为是应答动作。触发记录模组35,用以记录触发应答动作的触发语音。语义分析模组38,用以分析多个触发声音的语义。语义判断模组39,用以判断多个触发声音中相同语义的个数是否超过预设个数。所述预设个数大于或等于两个。身份关联模组36,用以在多个触发声音中相同语义的个数超过预设个数时关联所述触发声音与所述目标个体。声音转换模组37,用以将触发声音转换为文字关联所述目标个体。将所述触发声音转换为文字与所述目标个体关联后,在需要注册的时候,就可以直接通过体征识别(如脸部识别)或体态识别来注册,不需要手动注册。利用目标个体与关联的文字,数据库中还可以通过大数据分析关联与文字对应的其他个人资料,例如职涯经历、求诊数据、健康情况等。当经过体征识别或体态识别后,就可以知道对应的称呼及相关的个人资料。请同时参阅图4,本发明还揭示一种用户设备,该用户设备可包括至少一个处理器(processor)71(图中以一个处理器71为例)以及计算机存储介质(memory)73。处理器71可以调用计算机存储介质73中的逻辑指令,以执行上述实施例中的方法。在一实施方式中,所述用户设备为服务器。此外,上述的计算机存储介质73中的逻辑指令可以通过软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机存储介质中。计算机存储介质73可设置为存储软件程序、计算机可执行程序,如本公开实施例中的方法对应的程序指令或模块。处理器71通过运行存储在计算机存储介质73中的软件程序、指令或模块,从而执行功能应用以及数据处理,即实现上述实施例中的方法。计算机存储介质73可包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需的应用程序;存储数据区可存储根据终端设备的使用所创建的数据等。此外,计算机存储介质73可以包括高速随机存取计算机存储介质,还可以包括非易失性计算机存储介质。例如,u盘、移动硬盘、只读计算机存储介质(read-onlymemory,rom)、随机存取计算机存储介质(randomaccessmemory,ram)、磁碟或者光盘等多种可以存储程序代码的介质,也可以是暂态存储介质。所述处理器71加载并执行计算机存储介质73中存放的一条或一条以上指令,以实现上述图1-图2所示方法流程的相应步骤;具体实现中,计算机存储介质中的一条或一条以上指令由处理器加载并执行如下步骤:步骤s101:识别场景内的个体。所述场景是固定区活动空间,例如会议室、超市、实验室、教室、餐厅、商场等,通过视频监测装置监测。所述个体可为人体、动物或人造物,如人工智能机器人等。所述视频监测装置为摄像头。视频监测装置可通过体征识别(如脸部识别)及体态识别等方式确定并跟踪每个个体。步骤s102:记录所述场景内的声音信息。通过声音监测装置来收录目标场景中的声音;在一实施方式中,所述声音监测装置为麦克风。场景中的声音可包括个体所发出的声音及其他声音。步骤s103:识别所述声音信息中的个体声音。可通过的声音频率、结合视频中个体的体态变化或识别语义的方式,如张嘴的动作来识别声音信息中的个体声音。步骤s104:判断一目标个体是否对所述个体声音中一触发声音具有应答动作,如果是,执行步骤s105,如果否,返回步骤s101。所述应答动作包括头部动作、脸部动作及手部动作至少其中之一,头部动作包括抬头、转头,脸部动作包括特定的嘴部动作、眼部动作,手部动作包括举手应答;所述触发声音包括目标个体的称呼,例如姓名、外号、昵称等。步骤s105:记录所述触发声音。步骤s106:分析多个触发声音的语义。步骤s107:判断多个触发声音中相同语义的个数是否超过预设个数,如果是,执行步骤s108,如果否,返回步骤s104。步骤s108:关联所述触发声音与所述目标个体。步骤s109:将所述触发声音转换为文字关联所述目标个体。将所述触发声音转换为文字与所述目标个体关联后,在需要注册的时候,就可以直接通过体征识别(如脸部识别)或体态识别来注册,不需要手动注册。利用目标个体与关联的文字,数据库中还可以通过大数据分析关联与文字对应的其他个人资料,例如职涯经历、求诊数据、健康情况等。当经过体征识别或体态识别后,就可以知道对应的称呼及相关的个人资料。步骤s201:判断所述触发声音后所述目标个体是否有身体动作,如果是,执行步骤s202,如果否,仅需执行步骤s201。步骤s202,判断所述身体动作幅度是否超过一预定幅度,如果是,执行步骤s203,如果否,返回步骤s201。所述身体动作包括头部动作、脸部动作及手部动作至少其中之一,头部动作包括抬头、转头,脸部动作包括特定的嘴部动作、眼部动作,手部动作包括举手应答。步骤s203:判断多个个体是否同时具有所述身体动作,如果否,执行步骤s204,如果是,返回步骤s201。步骤s204:记录该身体动作为应答动作。另外,本领域技术人员还可在本发明精神内做其它变化,当然,这些依据本发明精神所做的变化,都应包含在本发明所要求保护的范围内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1