基于渐进式神经网络多维语音信息识别系统及其方法与流程
本发明属于多维语音信息识别技术领域,具体涉及一种基于渐进式神经网络的多维语音信息识别系统及其方法来识别多种语音信息,具体为性别、情感和说话人身份信息。
背景技术
语音信号是人类之间进行信息传递和交流的主要工具,日常情景下一个说话人的语音往往不但传达语义信息同时也携带了说话者的情绪状态,身份,地理位置,性别等信息。这意味着我们收集的语音信号实际上是一个混合了多种信息的信号。但目前语音识别研究主要集中在识别单一信息,不利于理解语音的真实含义。多维说话人信息的同时识别研究是人机交互的一个迫切任务。然而,当前的研究技术中很少有识别系统能够同时识别说话者的身份,年龄,性别和情感等多维信息。在以前的研究工作中,我们创造性地构建了基于性别相关多维信息识别的基线系统作为多维识别的参考模型,证明了多维信息同时识别的可行性和有效性。然而,这项工作没有充分利用单任务语音信息之间的相关性。
技术实现要素:
本发明根据现有基线系统技术的不足,提出了一种基于渐进式神经网络的多维语音信息识别系统及其方法,将来自其他辅助语音信息识别任务的知识,迁移学习到另一个语音信息识别模型中,进而来增强情感、身份模型的识别性能,实现多维语音信息的识别。
本发明公开了一种基于渐进式神经网络的多维语音信息识别系统,在基线系统的基础上,引入渐进式神经网络,所述基线系统以i-vector特征向量作为输入,利用snn模型,进行性别、情感、身份多维信息的识别,在性别识别的基础上,渐进式神经网络将性别相关的情感信息识别和性别相关的身份信息识别结合在一起,信息相互迁移,构建得到识别系统。
给定一个说话人语音序列o={ο1,ο2,l,οn},n表示输入的语音特征帧数,提取的i-vector特征向量用φ来表示为:
其中,l为后验方差:
其中,其中i是单位矩阵,t为从训练集中学习得到的变异矩阵,
nc是通过对整个语音序列上的帧γc(t)求和,得到的第c个高斯计算的零阶统计量,如下所示:
fc是关于ubm的以均值μc为中心,以协方差σc为白化的一阶统计量。
所述渐进式神经网络为单一的多层神经网络模型,第i层隐层的输出为
其中,
本发明还公开了一种基于渐进式神经网络的多维语音信息识别方法,包括以下步骤:
s1:对整个语音数据库提取i-vector特征向量,配置神经网络模型参数,隐含层采用激活函数处理,通过前向传播的方式,对特征向量进行预训练,采用梯度下降法反向传播不断对权重参数进行微调,最后获得性别识别的分类结果;
s2:在训练集中,针对整个男性语音样本,在性别识别的基础上,利用渐进式神经网络完成情感识别和身份识别的相互迁移学习,输出男性情感分类标签;针对整个女性语音样本,在性别识别的基础上,利用渐进式神经网络完成情感识别和身份识别的相互迁移学习,输出女性情感分类标签;
s3:整合多维语音识别的结果;
其中,所述s2中,身份识别信息和情感识别相互迁移学习时,把情感识别作为主任务,身份识别作为辅助任务,构造一个用来训练辅助任务的神经网络,固定上一个任务的神经网络的参数,添加一个随机初始化的新模型,作为第二个多层的神经网络,将训练辅助任务的神经网络的每一层通过横向连接的方式接入到第二个多层的神经网络主任务的每一层作为额外输入,使用反向传播学习第二个多层的神经网络的参数,通过soft-max层进行分类得到识别结果。
所述s1中,提取i-vector特征向量,具体实施如下:在梅尔频率倒谱系数特征的基础上,结合高斯混合模型,通过最大后验概率标准对通用背景模型进行训练,同时利用通用背景模型调整每个语句以获得相同比例的另一个高斯混合模型,通过投影到总体子空间矩阵中提取固定长度的i-vector语音特征。
有益效果:本发明与现有技术相比,具有以下优点:本发明在基线系统的基础上,引入i-vector特征向量,使用i-vector特征大大提高了分类和回归问题的准确性,并引用了渐进式神经网络技术(prognets),首先通过prognets“冻结”源神经网络训练的任务,并使用它们隐含层的中间表示作为新网络的输入来训练当前主任务,这使得prognets能够克服基线系统中snn传统方法相关的限制,包括一系列关于初始化模型的挑战,通过冻结并保留源任务权重来防止snn方法中存在的遗忘效应;在本发明中,在性别识别的基础上,利用prognets技术将性别相关的情感识别snn模型和性别相关的身份识别snn模型结合在一起,在识别某单一语音信息时,能充分利用了其他语音信息识别的相关信息,进而提高识别效率。
附图说明
图1为基线系统框图;
图2为prognets技术原理框图;
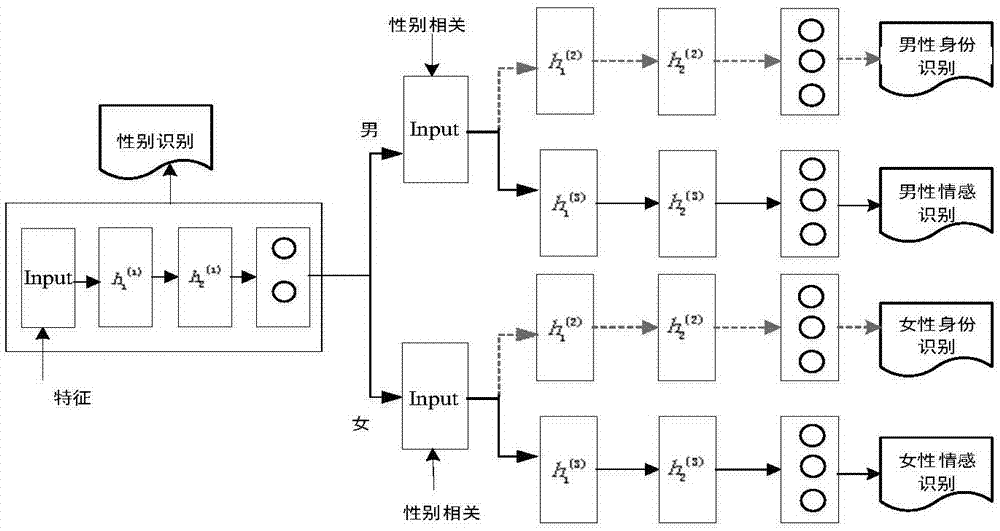
图3为基于prognets多维语音信息识别系统框图;
图4为单维snn模型、基线系统和prognets多维语音信息识别系统比较图;
图5为性别相关的基线系统和prognets系统多维语音信息识别对比图。
具体实施方式
下面结合附图和实施例对本发明提出的基于prognets的多维语音信息识别方法进行详细的说明:
本实施例中使用的语料库是ksu-emotions,语料库有两个阶段,本实施例选择第二个阶段进行研究,该语料库使用14名(7名男性和7名女性)演讲者模拟五种情绪(中性,悲伤,快乐,惊讶和愤怒),每种情绪有336个句子,总共有1680个句子,第二阶段语料的语料大小约为2小时21分。
为更好的估计多维说话人信息的识别效果,本实施例采用基于i-vector的自适应方法来提取特征,在梅尔频率倒谱系数(mfcc)特征的基础上,结合高斯混合模型(gmm),并通过最大后验概率标准对通用背景模型(universalbackgroundmodel,ubm)进行训练,同时利用通用背景模型调整每个语句以获得相同比例的另一个高斯混合模型(gmm),通过投影到总体子空间矩阵中提取固定长度的i-vector语音特征。
给定一个说话人语音序列o={ο1,ο2,l,οn},n表示输入的语音特征帧数,提取的i-vector特征向量用φ来表示为:
式(1)中,l为后验方差:
式(2)中,其中i是单位矩阵,t为从训练集中学习得到的变异矩阵,
{nc,fc}是基于ubm计算的baumwelch统计量,nc是通过对整个序列上的帧γc(t)求和,得到的第c个高斯计算的零阶统计量,如下所示:
fc是关于ubm的以均值μc为中心,以协方差σc为白化的一阶统计量。
图1为基线系统模型示意图,引用i-vector特征向量作为基线系统的输入,包含三种snn模型的soft-max识别器,它们将性别分类器,情感分类器和说话人身份分类器集成并组合到一个系统中,基线系统的具体实现步骤如下:
1-a.通过配置神经网络模型参数,对隐含层采用激活函数处理,通过前向传播的方式,对特征向量进行预训练,采用梯度下降法反向传播不断对权重参数进行微调,最后获得性别识别的分类结果;
1-b.在性别识别的基础上,将语音样本为男性和女性两部分,标签为情感标签和身份标签,选取训练集,通过神经网络模型对性别相关的身份模型进行训练,对性别相关的情感识别模型进行训练;
1-c.在训练阶段,保存性别相关的神经网络情感模型,性别相关的神经网络身份模型;
1-d.在识别阶段,针对测试集中的语音样本,提取特征,输入神经网络中,最后和保存的模型进行比较,根据神经网络最后一层soft-max函数进行语音不同信息的分类,分类结果和情感标签、身份标签进行对比,最终获得识别的结果。最后整理性别识别、情感识别均值、身份识别均值的结果,实现多维语音信息的识别。
图2为prognets技术原理框图,prognets是由单一的神经网络模型开始的,一个具有l层snn模型,第i层隐层的输出为
其中,
f(x)=1/(1+e-x)(6)
简而言之,为了能使用前一个网络训练的经验,将之前网络的每一层的输出,与当前任务的网络每一层的输出一起输入到下一层。具体实现步骤如下:
2-a.构造一个神经网络,用来训练辅助任务;
2-b.固定上一个任务的神经网络的参数,添加一个随机初始化的新模型,作为第二个多层的神经网络;
2-c.将辅助任务神经网络的每一层都连接到第二个的神经网络主任务的每一层作为额外输入,神经网络主任务每一层除了原始的输入,还加上辅助任务对应层的输入;
2-d.使用反向传播学习第二个神经网络的参数,最后通过soft-max层进行分类得到识别结果。
总的来说,就是把前一个的神经网络的信息融合到当前神经网络的输入信息中,然后训练,训练的结果与没有加源神经网络的方法对比,如果效果改进了,说明前面的神经网络对当前神经网络有用,知识有迁移。这种技术的优势是保留之前的训练,不至于像snn模型中微调那样更改原来的网络,而且每一层的特征信息都能得到迁移,缺点就是随着神经网络任务增加,参数的数量也急剧增加。
本实施例在上述基线系统的基础上,引入prognets技术,将性别相关的情感识别snn模型和性别相关的身份识别snn模型结合在一起,信息相互迁移,构建得到基于prognets的多维说话人识别系统,如图3所示。系统模型实现的具体步骤如下:
3-a.对整个语料库提取i-vector特征向量,配置神经网络模型参数,跟基线系统第一步一样,通过预训练和微调,实现性别识别的分类结果,输出性别分类标签。
3-b.在训练集中选择整个男性语音样本,在性别识别的基础上,利用prognets完成情感识别和身份识别的相互迁移学习。当把身份识别信息迁移到情感识别时,把男性相关的情感识别作为主识别任务,男性相关的身份识别模型作为辅助任务,利用prognets将两个snn模型结合起来,最后情感识别的结果就是目标任务的识别结果,不但利用到了性别相关的影响,同时利用到身份识别的相关信息,这种渐进式神经网络具有记忆功能,避免了身份识别模型训练中的信息的丢失,可以让神经网络学习到更多的语音原始特征的信息,从而提高语音识别的效果,最终输出男性情感分类标签。
3-c.针对整个女性语音样本,利用prognets完成女性相关的身份识别到情感识别的迁移学习,输出女性情感分类标签,女性相关的身份识别到情感识别的迁移学习,输出女性身份分类标签。
3-d.整合多维语音识别的结果,分别将男性和女性语音识别结果整合起来,三个不同的输出标签代表该系统中的分类结果。
本实施例采用ksu语音数据库,分别针对单维的snn语音识别模型、性别相关的基线系统和性别相关的prognets系统进行实验,比较三种系统的优略,同时分析不同性别下,情感识别、身份识别的差异性。
在提取i-vector特征向量时,首先提取出18维的mfcc,包括其一阶和二阶导数的能量,一共54维特征向量,训练ubm模型,执行10次em算法迭代,对于所有训练集和测试集的语音信号,提取固定维度的200维i-vector特征向量。
由于ksu-emotion数据库中的数据量较小,针对低资源多维语音信息识别,本实施例采用四层浅层神经网络系统,分别是输入层,两个隐层和最后输出层,为了让三种识别模型在相同的平台进行比较,把前三层网络分别设置为200,50,200个神经元节点。在单维snn语音识别模型和基线系统中,最后一层的节点根据不同单个任务的类别确定,2个节点用于性别识别任务;5个节点用于情感识别任务;14个节点分别用于说话人识别任务。不同的是基线系统中的情感、身份识别是在性别相关的基础上。
在prognets系统中,当把性别相关身份识别迁移到性别相关情感识别时,网络配置分别为说话人识别200-50-200-14,情绪识别200-100-400-5。当把性别相关情感识别迁移到性别相关身份识别时,网络配置分别为说话人识别200-50-200-5,情绪识别200-100-400-14。这里在基线系统和prognets系统中,性别识别任务的输入特征是基于整个语料库提取的i-vector,情感识别任务和身份识别任务,是基于性别相关的语料库提取出的i-vector。在训练过程中,将l2正则化中的惩罚因子设置为0.0001,最小批量大小设置为100。为了使网络系统更加优化,使用指数衰减法获得学习率,初始值设置为0.03,总共执行了500次迭代。这些参数配置都用于单维snn语音识别模型、基线系统和prognets系统。
本实施例在tensorflow下进行仿真实验,在三种语音信息识别系统下,对比语音性别、情感、身份的识别结果,识别结果如图4所示。
从图4中,可以看到,基线和prognets两种多维语音信息识别系统明显优于单维的snn语音识别模型,进一步验证了多维语音信息识别技术研究的实用性,在以往的研究中,性别识别技术基本已经成熟,在三种语音识别系统实验中,性别识别的结果都接近100%。对性别识别的研究没有多少意义。因此,本发明研究的重点是,针对两种多维识别系统,比较性别相关的情感识别和身份识别的识别性能,实验数据记录在表1中。
表1:单维snn模型、基线系统和prognets多维语音信息识别系统比较
从表1中,可以看到,当利用prognets技术,把身份识别信息迁移学习到情感识别模型时,针对说话人情感识别,prognets系统明显优于基线系统,平均提升了1.9%(prognets79.31%vs基线77.41%),这表明,说话人身份识别的模型知识,对情感识别是有很大帮助。当把情感识别信息迁移到身份识别中时,平均提升了0.92%(prognets87.82%vs基线86.9%),情感识别的模型对说话人身份识别有帮助,但是并不是特别显著,这说明身份识别的结果对情感识别的帮助大于情感识别对身份识别的帮助,prognets技术相比身份识别,对提高情感识别更加有效。
图5分析了在不同性别下的语音信息识别,prognets系统和相比基线系统改进的程度。图中可以看出,在进行性别相关的情感识别时,关于男性语音和女性语音,prognets系统相比于基线系统得到显著的提升(男1.39%vs女2.41%)。在进行性别相关的身份识别时,prognets系统相比于基线系统也提升了(男0.61%vs女1.22%)。prognets技术对女性语音信号的识别性能的提升明显优于男性语音信号。
- 还没有人留言评论。精彩留言会获得点赞!