基于区域卷积神经网络的第一视角手势识别与交互方法与流程
本发明属于计算机视觉与机器学习的技术领域,具体涉及一种基于区域卷积神经网络的第一视角手势识别与交互方法。
背景技术:
随着许多虚拟现实(virtualreality,vr)和增强现实(augmentingreality,ar)设备产品的推出,给人机交互方面研究的热度又增加了不少。纵观人体全身,手已经被认为是最重要和普遍的交互工具了。同时,在人机交互领域,手势识别已经是一个很重要的研究方向。而由于ar与vr的兴起,第一视角(egocentricvision)手势交互技术逐渐受到大家的关注,越来越多的学者及企业也纷纷投入人力物力去做相应的研究与开发。
第一视角的手势交互主要涉及两个方面,手势识别与骨架关键点定位。本发明将结合手势识别与骨架点定位形成一个综合应用。假设如下场景:用户在佩戴ar/vr设备的情况下,需要与设备中内容做相应交互,可以直接举起手进行特定的手势动作,完成特定的交互操作而无需借助其他外接设备,大大提高了产品的用户体验。
目前,由于数字摄像头的广泛普及,基于图像和视频的手势识别研究已经成为计算机视觉领域的一个重要研究方向之一。各种各样的手势识别的传统方法也早已经被提出来,例如隐马尔科夫模型(hmm)、有限状态机(fsm)、动态贝叶斯网络(dbn)、动态时间规划(dtw)和人工神经网络(ann)。这些传统方法模型通常是需要人工预定义特征,如尺度不变特征转换(sift)、陈特征(surf)、方向梯度直方图(hog)、傅里叶描述子等手形特征描述和基于光流、运动跟踪方法的手势运动信息描述,人工选择特征的方法有很大的局限性,通常需要先验知识、经验和大量的手工调整,而且算法模型的识别率容易因为手势操作速度、方向、手形大小的差异产生很大的影响。近年来新起的深度学习技术在特征选择方面可以很好的解决上述问题。深度学习善于处理视觉信息,深度卷积神经网络(cnn)能将图像浅层特征通过层层非线性变化强化为高级深层特征,在各种视觉分类,回归问题均能有极佳的表现。
技术实现要素:
为了克服现有技术存在的上述不足,本发明提出基于区域卷积神经网络的第一视角手势识别与交互方法,以解决第一视角下,动态视频流中手势识别与关键骨节点精准定位问题,并根据手势识别结果及利用骨节点位置信息,实现一套手势交互方案。
为了实现上述的目的,本发明提供如下的技术方案:基于区域卷积神经网络的第一视角手势识别与交互方法,包括以下步骤:
s1、获取包括多种不同第一视角下的手势的训练数据,人工标定训练数据的标签,所述训练数据的标签包括手势区域的外接矩阵左上角坐标和右下角坐标、人工标定的手势类别、人工标定的关键骨架的坐标点;
s2、设计一个基于区域卷积的神经网络,使得神经网络输入为三通道rgb图像,输出为手势区域的外接矩阵左上角坐标和右下角坐标,以及手势类别、手势骨架关键点;
s3、判断手势类别,根据不同需求输出相应的交互结果;
s4、利用手势判别结果进行指令判别,作出相应指令。
优选地,步骤s2所述基于区域卷积的神经网络包括两部分,第一部分为包括卷积层-池化层-卷积层-池化层-卷积层-池化层-全连接层的卷积神经网络cnn模型,用于训练手部检测,第一部分的输入为rgb图像,训练输出为手势区域外接矩阵左上角坐标和右下角坐标;第二部分为包括roi池化层-卷积层-池化层-卷积层-池化层-全连接层的卷积神经网络cnn模型,输入为第一部分的最后一个池化层图像,并通过第一部分输出手势区域外接矩阵左上角坐标和右下角坐标,在roi池化层作一致化处理,训练输出为手势类别及关键骨架的坐标位置。
从以上技术方案可知,本发明通过单模型训练与部分网络共享,提高了第一视角下手势识别的识别速度与准确性。与现有技术相比,本发明的有益效果是:
1、将数据格式转为rgb图像,不同于rbgd图像,该数据采集范围大,距离远,可同时使用于室内与室外,在第一视角下的手势识别场景下有很好的表现。
2、通过训练神经网络结构,让神经网络自动去学习对于手势分类有用的时空特征,使得手势识别方法更加鲁棒,手势识别率更加稳定。此外,本发明所使用神经网络模型由于有部分网络共享,相对于目前已有神经网络模型在计算上更加快速。
附图说明
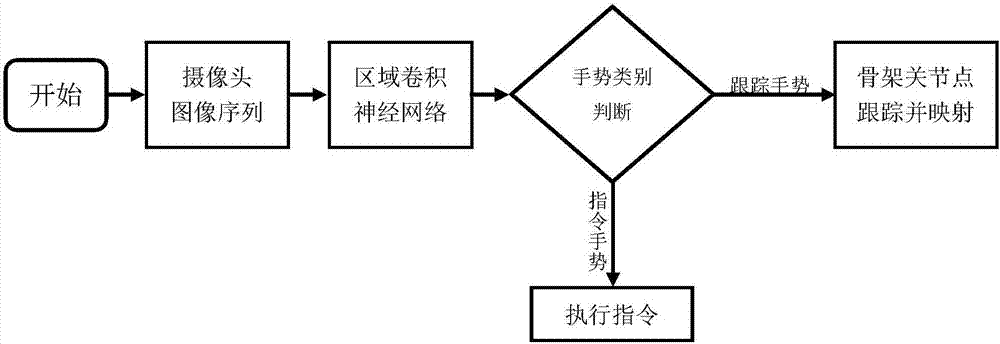
图1为本发明第一视角下手势识别与交互算法流程图;
图2中a、b、c、d、e及f为本发明第一视角下手势类别样本示意图;
图3为本发明中区域卷积神经网络的结构图。
具体实施方式
下面将结合实施例及附图,对本发明的技术方案进行清楚、完整的描述,但本发明的实施方式不限于此。
实施例
如图1所示,本发明基于区域卷积神经网络的第一视角手势识别与交互方法,包括如下步骤:
s1、获取训练数据,人工标定训练数据的标签,标签包括手部区域的前景趋于的左上角点和右下角点,不同手势的骨架节点坐标,以及人工标记的不同手势类别。
获取数据时,将摄像头处于人眼位置,视觉方向与眼睛直视方向一致,持续采集视频流信息并转化为rgb图像,图像包括多种不同手势(如图2的a-f所示)。其中,摄像头为普通2d摄像头,采集图像为普通rgb图像,大小为640*480。训练数据包括多种不同手势,手势均为第一视角下的,其中训练数据的标签包括手势区域的外接矩阵左上角坐标和右下角坐标、人工标定的手势类别、人工标定的关键骨架的坐标点。
s2、设计一个基于区域卷积的神经网络(如图3所示),包括卷积层、池化层的多级组合,以及最后作为输出的全连接层,还有特定的roi池化层,用于提取池化层中手部的前景区域,使得网络输入为三通道rgb图像,输出为手势区域的外接矩阵左上角坐标和右下角坐标,以及手势类别、手势骨架关键点。
基于区域卷积的神经网络在用于手部检测的同时,也用于手势分类与指尖检测,其在结构上主要包括两部分:
第一部分为一个7层卷积神经网络(cnn模型),用于训练手部检测,输入为三通道rgb图像,训练输出为手势区域外接矩阵左上角坐标和右下角坐标;这一部分7层分别为卷积层-池化层-卷积层-池化层-卷积层-池化层-全连接层,卷积层的作用是用它来对图像进行特征提取;池化层的作用是对卷积层输出的特征图进行压缩,一方面使特征图变小,简化网络计算复杂度,一方面进行特征压缩,提取主要特征;全连接层作用是连接所有的特征,将输出值送给最后分类器,得出最后分类结果,由于第一部分是回归问题,所以无需用到分类器。
第二部分从第一部分cnn模型中的池化层(pool层)取出图层,并通过网络输出的前景外接矩形左上角坐标和右下角坐标,切割出感兴趣区域,从而获得包含手部的前景区域,将该前景区域接入roi池化层,作用为做一致性处理,使得不同大小的前景图像均能变换成相同大小的前景图像,作为后续网络的输入;后续网络为一个6层的卷积神经网络(cnn模型)用于骨节点检测与手势识别,分别为roi池化层-卷积层-池化层-卷积层-池化层-全连接层。这里和第一部分不同,由于第二部分是分类问题,所以加上分类器做最后的输出。也就是说,第二部分cnn模型的输入为第一部分cnn模型的最后一个池化层图像,通过第一部分输出手势区域外接矩阵左上角坐标和右下角坐标切割出感兴趣区域,并在roi池化层作一致化处理,训练输出为手势类别及关键骨节点的坐标位置。
需说明的是,神经网络的两部分模型为一体化模型,共同构成一个网络,一同训练,第一部分模型优化欧氏范数损失函数,第二部分模型优化分段损失函数,通过监督竞争学习的方式得到各层的权值,最后训练得到整个网络的参数权值,用于识别检测手势类别及关键骨节点的坐标位置。
s3、判断手势类别,根据不同需求输出相应的交互结果,若为跟踪需求,则对手势骨架关键点进行双指数滤波与坐标映射,若为判定需求,则对不同手势类别做出相应的判别结果,例如确定、取消等。
s4、利用手势判别结果进行指令判别,作出相应指令。
手势识别方法可适用于增强现实(ar),虚拟现实(vr)等需要第一视角下手势交互场景中。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!