尖峰域卷积电路的制作方法
相关申请案的交叉参考
本申请案主张2015年2月16日在美国专利商标局申请的第62/116,858号美国临时专利申请案“尖峰域卷积电路(aspikedomainconvolutioncircuit)”的优先权和权益,所述美国临时专利申请案的全部公开内容以引入的方式并入本文中。
关于联邦赞助的研究或开发的声明
本发明是在美国政府支持下作出,由国防高级研究计划局(darpa)资助,批准号为hrl0011-13-c-0052。美国政府享有本发明的某些权利。
本发明的实施例的方面大体上涉及模拟处理领域以及用于使用脉冲域信号执行卷积操作的电路。
背景技术:
计算机视觉技术频繁地用来自动地分析图像以便识别所关注的对象。这些技术可应用于控制自主机器人(例如,无人机和自动驾驶汽车)、半自主机器人(例如,自动地检测危险且警示驾驶员或作为响应自动地减慢汽车的汽车)、军事系统跟踪和目标辨识(例如,来自雷达、红外线相机和可见光相机的图像)以及制造质量控制(例如,对来自组装线的产品进行自动视觉分析以确定是否符合标准)。
图像处理技术常常应用于低级别数据以便识别出特征供较高等级算法进一步分析。例如,图像处理可以用来检测输入图像内的高对比度边缘,改变图像的特定部分的对比度,等。
卷积函数常用于图像处理中用于特征检测。图1是图示通过对大小为14像素乘14像素的输入图像100与大小为5像素乘5像素的内核(kernel)110进行卷积以检测输入图像100的类似于内核110的部分(或“小片(patch)”)102(这些小片102中的一个在图1中以点线示出)来产生大小为10像素乘10像素的输出图像120的实例的示意图。在此实例中,内核110为垂直边缘的检测器,所述垂直边缘在左侧暗且在右侧亮。可以通过对输入图像100与各种不同内核进行卷积来检测不同特征。
输出图像120可以通过将输入图像100分裂成重叠的输入小片102来产生。将输入小片102中的每一个中的像素的值乘以内核110,且将所得乘积相加在一起以产生对应于输入小片的输出图像120的单个像素。
如输出图像120中所见,图像处理图像已识别出沿着垂直线存在高对比度的区。例如,输入图像100中的小黑框的右侧与邻近于其的白色区域(在输入图像100的列10到12中)之间的边缘对应于输出图像120的列8和9中的暗部分,且输入图像100的灰色外部边界与白色中间部分之间的边缘对应于输出图像120的列1中的暗部分。此外,黑色正方形的左边缘在其左侧具有白色区域。此为内核110的“反面”,且因此导致反白(negativewhite)。
然而,实施卷积运算可能是计算密集型的(例如,归因于所需要的大量乘法运算),且因此在通用微处理器上实施时可能具有高功率(能量)要求。因此,对于通用微处理器而言可能难以能够满足特定应用的成本、功率和/或速度要求。
先前已开发脉冲和尖峰域处理器以实施通用神经网络,如例如在第7,822,698号美国专利“尖峰域和脉冲域非线性处理器(spikedomainandpulsedomainnon-linearprocessors)”中所描述,所述美国专利的全部公开内容以引入的方式并入本文中。涉及脉冲和尖峰域处理器的其它工作包含第7,403,144号美国专利“脉冲域编码器和滤波电路(“pulsedomainencoderandfiltercircuits)”以及第8,996,431号美国专利“具有可编程动力学动态、动态平衡可塑性和轴突延迟的尖峰域神经元电路(spikedomainneuroncircuitwithprogrammablekineticdynamic,homeostaticplasticityandaxonaldelays)”,所述两个美国专利的全部公开内容以引入的方式并入本文中。
此外,可以使用吉尔伯特型模拟乘法器(例如,吉尔伯特单元)执行卷积而在模拟域中执行卷积的电路,如在克鲁兹·j.m.(cruz,j.m.)和l.o.·蔡(l.o.chua.)的“16×16蜂窝式神经网络通用芯片:具有分布式存储器和灰阶输入-输出的第一个完整的单芯片动态计算机阵列(a16×16cellularneuralnetworkuniversalchip:thefirstcompletesingle-chipdynamiccomputerarraywithdistributedmemoryandwithgray-scaleinput-output)”(模拟集成电路和信号处理(analogintegratedcircuitsandsignalprocessing)15.3(1998):227-237)中所描述。然而,此论文中的电路使用5v的电力供应器,且通过此设计执行的卷积的准确度预期在缩放到以低电压操作的情况下会显著降低。
技术实现要素:
本发明的实施例的方面是针对用于执行尖峰域卷积处理的专用处理器以及其操作方法。本发明的实施例能够在没有模拟或数字乘法器的情况下执行卷积运算,由此允许具有高准确度的高速且低功率的运算。
根据本发明的一个实施例,一种卷积电路包含:多个输入振荡器,所述输入振荡器中的每一个经配置以:接收多个模拟输入信号中的对应模拟输入信号;以及输出多个尖峰信号中的对应尖峰信号,所述对应尖峰信号具有根据所述对应模拟输入信号的量值的尖峰速率;多个1位dac,所述1位dac中的每一个经配置以:从所述输入振荡器中的一个对应输入振荡器接收所述多个尖峰信号中的所述对应尖峰信号;以及接收包含多个权重的卷积内核的对应权重;根据所述对应尖峰信号和对应权重输出多个经加权输出中的对应经加权输出;以及输出振荡器,其经配置以根据来自所述多个1位dac的所述多个经加权输出产生输出尖峰信号。
所述多个经加权输出可以是电流。
所述卷积电路可以进一步包含在所述多个1位dac与所述输出振荡器之间的求和节点,其中所述多个1位dac经配置以将所述经加权输出输出到所述求和节点,且其中所述输出振荡器经配置以根据所述求和节点处的信号产生所述输出尖峰信号。
所述卷积电路可以进一步包含耦合于所述求和节点与接地之间的电容器。
所述输入振荡器中的每一个可以包含:跨导放大器,其具有经配置以接收所述模拟输入信号的输入端子和耦合到累加节点的输出端子;电容器,其耦合于所述累加节点与接地之间;第一复位开关,其耦合于所述累加节点与接地之间;比较器,其具有耦合到所述累加节点的非反相输入和耦合到所述1位dac中的一个对应1位dac的输出;以及第一延迟器,其包含:输入,其耦合到所述比较器的所述输出;以及输出,其经配置以控制所述第一复位开关。
所述输入振荡器中的每一个可以进一步包含:第二复位开关,其耦合于所述累加节点与所述第一复位开关之间;以及第二延迟器,其包含:输入,其耦合到所述比较器的所述输出;以及输出,其经配置以控制所述第二复位开关。
所述1位dac中的每一个可以包含:增益为1的第一电流镜,其包含第一端子和第二端子;增益为1的第二电流镜,其包含耦合到所述第一电流镜的所述第一端子的第一端子和第二端子;增益大于1的第三电流镜,其包含第一端子和耦合到所述第二电流镜的所述第二端子的第二端子;底部差分对,其耦合到电流源且经配置以接收参考电压和所述对应权重;第一上部差分对,其耦合到所述底部差分对、所述第一电流镜和所述第二电流镜;以及第二上部差分对,其耦合到所述第一上部差分对、所述底部差分对、所述第一电流镜和所述第二电流镜。
所述1位dac中的每一个可以包含:辅助电路,其包含:第一输入端子,其经配置以接收所述对应权重;第二输入端子,其经配置以接收所述对应尖峰信号;第一输出端子,其经配置以输出所述对应权重的绝对值;以及第二输出端子,其经配置以输出多个控制信号;以及dac核心,其包含:第一电流镜;第二电流镜;多个电流受控电流源,其经配置以由所述对应权重的所述绝对值控制;以及多个控制晶体管,其经配置以由所述控制信号控制,所述多个控制晶体管耦合于所述第一和第二电流镜与所述多个电流受控电流源之间。
所述输出振荡器可以包含:输入低通滤波器,其具有耦合到所述1位dac的第一端子;跨导放大器,其具有耦合到所述输入低通滤波器的第二端子的输入端子和耦合到累加节点的输出端子;电容器,其耦合于所述累加节点与接地之间;第一复位开关,其耦合于所述累加节点与复位电压之间;比较器,其具有耦合到所述累加节点的非反相输入和耦合到所述1位dac中的一个对应1位dac的输出;以及第一延迟器,其包含:输入,其耦合到所述比较器的所述输出;以及输出,其经配置以控制所述第一复位开关。
所述卷积电路可以进一步包含耦合到所述输出振荡器的输出的输出低通滤波器。
所述尖峰信号中的每一个可以包含多个脉冲,其中所述尖峰速率对应于所述脉冲中的邻近脉冲之间的时间。
所述经加权输出中的每一个可以是电流。
所述尖峰信号中的每一个可以包含多个脉冲,其中所述尖峰速率对应于所述脉冲中的邻近脉冲之间的时间,且其中所述经加权输出中的每一个在对应尖峰信号的脉冲期间具有正电流,且在所述脉冲中的邻近脉冲之间的所述时间期间具有负电流。
所述模拟输入信号可以对应于图像。
根据本发明的一个实施例,一种用于对多个模拟输入信号与由多个权重表示的内核进行卷积的方法包含:将所述模拟输入信号转换为多个对应尖峰信号,所述尖峰信号中的每一个具有尖峰速率;将所述尖峰信号和所述内核的所述权重供应到1位dac以产生经加权输出;对所述经加权输出求积分以产生积分经加权输出;基于所述积分经加权输出控制输出振荡器;以及从所述输出振荡器产生输出尖峰信号,所述输出尖峰信号具有对应于所述模拟输入信号与所述内核的卷积的输出尖峰速率。
所述方法可以进一步包含将低通滤波器应用于所述输出尖峰信号。
所述尖峰信号中的每一个可以包含多个脉冲,且所述尖峰速率可以对应于所述脉冲中的邻近脉冲之间的时间。
所述经加权输出中的每一个可以是电流。
所述尖峰信号中的每一个可以包含多个脉冲,其中所述尖峰速率对应于所述脉冲中的邻近脉冲之间的时间,且其中所述经加权输出中的每一个在对应尖峰信号的脉冲期间具有正电流,且在所述脉冲中的邻近脉冲之间的所述时间期间具有负电流。
所述模拟输入信号可以对应于图像。
附图说明
附图连同本说明书一起说明本发明的示范性实施例,并连同描述一起用以阐释本发明的原理。
图1是图示来自对输入图像与内核进行卷积以检测输入图像中的垂直边缘的输出的示意图。
图2是图示本发明的实施例的示意图,其中两个尖峰振荡器层执行图像卷积。
图3是根据本发明的一个实施例的用于产生单个输出像素的卷积模块的示意图。
图4a图示根据本发明的一个实施例的由输入振荡器产生的尖峰信号的波形。
图4b图示根据本发明的一个实施例的由1位dac产生的电流脉冲的波形。
图5a和5b示意性地说明根据本发明的一个实施例的输入振荡器、1位dac与输入图像的当前小片的像素值之间的连接。
图6a是根据本发明的一个实施例的输入振荡器的电路图。
图6b是根据本发明的一个实施例的输入振荡器的跨导放大器的电路图。
图6c是根据本发明的一个实施例的延迟器的电路图。
图6d是根据本发明的一个实施例的包含两个开关和两个延迟器的输入振荡器的电路图。
图6e是根据本发明的一个实施例的第二延迟器的电路图。
图7是根据本发明的一个实施例的1位dac的电路图。
图8a是根据本发明的一个实施例的1位dac的示意图。
图8b是根据本发明的一个实施例的dac核心的电路图。
图9a是根据本发明的一个实施例的输出振荡器电路的电路图。
图9b是图示根据本发明的一个实施例的在求和节点处的典型波形的波形图。
图9c是图示根据本发明的一个实施例的来自输出振荡器的输出波形的波形图。
图10是图示根据本发明的一个实施例的在模拟电路时,在三个输入振荡器的输出处、在求和节点处、在输出振荡器的内部电容器处以及在输出振荡器的输出处的波形的一组波形图。
图11是图示根据本发明的一个实施例的电路的模拟输出的示意图。
图12是图示由根据本发明的一个实施例的芯片产生的实验测量波形的示意图。
图13a是在实验过程期间供应到根据本发明的一个实施例的芯片的测试输入图像。
图13b是在实验过程期间供应到根据本发明的一个实施例的芯片的卷积内核。
图13c是图13a的测试输入图像与13b的卷积内核之间的理想卷积输出。
图13d是由根据本发明的一个实施例的芯片在实验过程期间产生的卷积输出,所述芯片供应有图13a的测试输入图像和图13b的卷积内核。
图13e是根据本发明的一个实施例的误差图像,其表示图13c中所示的理想输出与图13d中所示的实验输出之间的差异。
图13f是根据本发明的一个实施例的用于第二实验输出图像的所有像素的误差的直方图。
具体实施方式
在以下详细描述中,仅借助于说明展示和描述了本发明的某些示范性实施例。如所属领域的技术人员将认识到,本发明可以许多不同形式体现且不应将其理解为限于本文中所阐述的实施例。在本说明书通篇中,相同的图式元件符号表示相同的元件。
如上文所论述,图1是图示通过对大小为14像素乘14像素的输入图像100与大小为5像素乘5像素的内核110进行卷积来产生大小为10像素乘10像素的输出图像120的实例的示意图。输出图像120可以通过将输入图像100分裂成重叠的输入小片102来产生。将输入小片102中的每一个中的像素的值乘以内核110的对应值,且将所得乘积相加在一起以计算对应于输入小片102的输出图像120的像素的值。由此,产生输出图像120的每个像素需要对于内核110的每个像素的一个乘法运算(在具有5像素乘5像素内核的此实例中,需要5×5=25个乘法运算)连同对结果求和的加法运算(在此实例中,存在25个乘积,且因此执行25-1=24个加法运算以对这些值进行求和)。在实际系统中,输入图像、输出图像和内核可能比此处示出的实例大得多,且运算的数目随着输入图像、输出图像的大小和内核大小大于线性地增大。通用微处理器在设计时未考虑这些类型的工作流程,且因此通常经配置而以功率低效方式一次一个地(例如,连续地)执行这些运算,进而使得难以缩放此类系统用于与较大输入和输出一起使用。
由此,本发明的实施例是针对经配置以使用减小的功率量执行卷积运算的电路。明确地说,本发明的实施例可以用于利用小电力供应器的技术,且使用比数字电路小的电路,比对等模拟电路的准确度高。在一个实验性实施例中,核心电路每像素使用260pj且在1mhz下操作,产生了正确的卷积结果,误差小于2%。更详细地,本发明的实施例基于连接到输出尖峰振荡器层(或输出振荡器)的输入尖峰振荡器层(或输入振荡器)来使用电路计算卷积,其中连接230包含一组1位数/模转换器(dac)。
根据本发明的实施例的电路可以用作图像处理管线的构建基块。在组件之间发射的信号为尖峰脉冲信号,所述尖峰脉冲信号仅具有两个电压电平且对于具有低电压供应的当前cmos过程是有效的。可以使用比发射数字信号时小的布线来发射这些尖峰脉冲信号。对于模拟尖峰信号,使用仅一根电线来发射具有多位分辨率的信息。
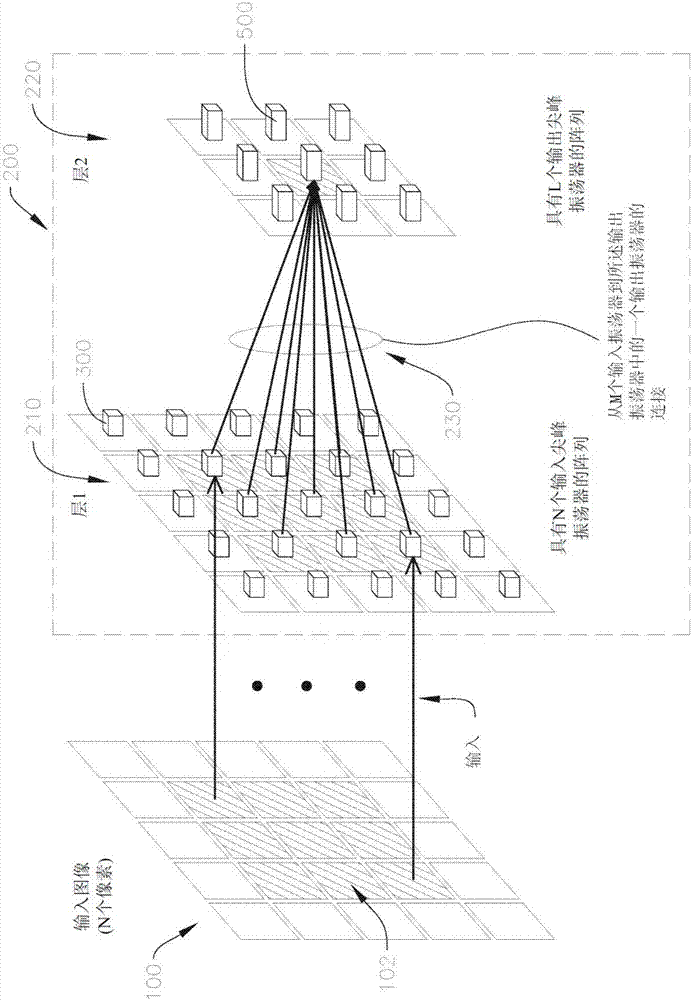
图2是图示根据本发明的实施例的电路200的示意图,其中两个尖峰振荡器层并行地执行输入图像100的多个小片102的图像卷积。在图2中所示的实例中,输入层210包含n个输入振荡器300(在此实例中,25个输入振荡器,且因此n为25),所述输入振荡器接收对应于输入图像100的n个像素的强度的外部输入in且输出电压尖峰。在图2中,输入图像100的一个小片102示出为阴影绘示的像素,其中小片102具有m个像素(在此实例中,小片102为3像素乘3像素部分,且因此m为9)。这些外部输入in控制输入振荡器300的尖峰速率,其中尖峰为具有二元振幅的电压信号。与小片102相关联的九个输入振荡器300在图2中以阴影绘示。为清楚起见,图2略去用于将输入数据供应到输入层210和用于从输出层220读出结果的额外电路。
由n个输入振荡器300产生的尖峰供应到输出层220的输出振荡器500(或多个输出振荡器)。l个输出振荡器中的每一个从m个连接230接收输入(在图2中所示的实例中,l为9),其中m个连接230中的每一个包含将对应权重w应用于尖峰以产生经加权电流脉冲的1位dac,其中m个权重对应于内核110(在图2中所示的实例中,使用3乘3内核,且因此存在9个权重)。
更详细地,dac中的每一个对应于内核的像素中的一个,且每一dac编程有对应于内核的对应像素的强度的权重(w)。由此,dac中的每一个基于从输入振荡器300接收的尖峰和其权重(w)而输出响应。根据本发明的实施例的1位dac比对等模拟乘法器(例如吉尔伯特单元)或数字乘法器(例如通用微处理器)实施起来更简单且更节能。
对经加权电流脉冲进行求和以控制输出层220的输出振荡器(或输出尖峰振荡器)500。由输出尖峰振荡器500产生的信号对应于对输入小片102与内核110进行卷积的结果。如图2中所见,来自与小片102相关联的阴影绘示的输入振荡器的m个连接全部连接到相同输出振荡器(例如,阴影绘示的中心输出振荡器)。
在一个实施例中,l稍微小于或等于n。在一个实施例中,m小于l和n中的每一个。在一个实施例中,电路中的连接230的总数目为m×l。
为方便起见,图2中未示出层1的输入振荡器300与层2的输出振荡器500之间的额外连接230。例如,层1的一组九个输入振荡器300(包含前两行阴影绘示的振荡器和在正上方的具有三个振荡器的行)可以经由额外连接230(具有对应权重)连接到在图2中所示的阴影绘示中心输出振荡器正上方的输出振荡器500。在一些实施例中,这些连接230大体上独立于图2中所示的连接,且电路可以同时将信号并行地供应到所有输出振荡器500。
为方便起见,下文将相对于包含一个输出振荡器500(例如,其中l为1)以及接收对应权重w1-m(权重w1到wm)的一组m个1位dac600(如图3中所示,在下文更详细地论述)的卷积模块400来更详细地描述本发明的实施例。图2中所示的电路具有规则空间结构,且可以例如使用具有n个相同输入振荡器300的阵列、具有l个相同卷积模块的阵列、相关联布线以及相关联输入和输出电路来加以实施。
然而,本发明的实施例不限于此,且在本发明的一些实施例中,下文更详细描述的结构可以适于并行地控制多个输出振荡器500。例如,可以并联地使用多组m个1位dac600,且所述组的1位dac可以耦合到输出振荡器中的不同输出振荡器。
图3是根据本发明的一个实施例的用于产生单个输出像素的卷积模块400的示意图。如图3中所示,输入振荡器300接收对应于输入图像100的值的输入信号in且将尖峰信号x供应到1位dac600中的对应1位dac。
图4a图示根据本发明的一个实施例的由第j个输入振荡器300j响应于第j个输入inj而产生的尖峰信号x的第j个尖峰信号xj的波形。如图4a中所见,波形为具有电压vl或vh的二元值。第j个尖峰信号xj的尖峰10中的每一个具有电压vh和脉冲宽度pw(脉冲宽度可以基于例如电路的噪声特性而设定为特定值)。供应到输入振荡器300j的信号in控制邻近脉冲之间的周期t的长度(下文将更详细地论述用于实施输入振荡器300j的实例电路)。较高输入信号in导致较短周期t。在图4a中所示的实例中,输入信号in随时间t推移而增大,且因此稍后周期ti+1短于较早周期ti。
作为响应,1位dac600将经加权电流脉冲i供应到求和节点410,所述求和节点控制其相应输出振荡器500的尖峰速率。图3示出(来自总共n个输入振荡器300当中的)m个输入振荡器,经由m个连接230耦合到单个输出振荡器500。由此,输入信号in标注为in1、in2、...、inm,由输入振荡器产生的尖峰信号x标注为x1、x2、...、xm,且经加权电流脉冲(或经加权输出)标注为i1、i2、...、im。
更详细地,1位dac600中的每一个从输入振荡器300中的一个对应输入振荡器接收尖峰信号x以及对应于内核的m个权重w当中的权重w。m个1位dac600中的每一个产生对应电流脉冲信号i(例如,m个电流脉冲信号i1、i2、...、im),其中电流脉冲的尖峰速率由尖峰信号x的速率(例如,尖峰10到达的速率)控制,且电流脉冲的振幅由权重w的值控制。
由此,1位dac600有效地计算输入信号(如已以尖峰信号x的尖峰速率编码)与权重w的乘积,且因此实施输入图像与内核之间的卷积的乘法运算。
此外,因为1位dac的经加权输出为电流,因此将这些输出电流供应到共用求和节点410具有对输出电流求和的效果(归因于基尔霍夫电流定律)。由此,本发明的实施例可以对由内核加权的输入信号的经加权贡献进行总和,而无需在对等系统中将使用的m-1个加法运算。
图4b图示根据本发明的一个实施例的由1位dac600产生的电流脉冲信号中的一个的波形。明确地说,图4b图示由第j个1位dacgj响应于第j个尖峰信号xj而产生的电流脉冲信号ij。如图4b中所见,电流脉冲信号ij的脉冲20具有与尖峰信号xj相同的脉冲宽度pw,且在脉冲之间具有相同周期ti和ti+1。在电流脉冲信号i的脉冲20期间(例如,在i为非零时),电流的量值为ia,且在脉冲之间(例如,在i为0时),电流的量值为ib(如图4b中所见,ia为正电流,且ib为负电流,但本发明的实施例不限于此),其中ia和ib定义为:
ia=α·wj
ib=β·wj
其中α和β为常数,且其中,在一个实施例中,β=-0.25α。脉冲中的阴影绘示的区域对应于与脉冲相关联的总电荷或与脉冲之间的周期相关联的总电荷。
电流脉冲信号i在求和节点410处求和在一起,所述求和节点可以是1位dac600的输出的简单电线连接(例如,归因于基尔霍夫电流定律)。如下文更详细地描述,求和节点410可以耦合到电容器,其对来自1位dac600的经加权脉冲信号i的电荷进行求和。由此,来自经加权脉冲信号i的电荷的累加对应于卷积函数中乘积的求和。求和节点410处求和的电压用来控制产生输出尖峰信号z的输出振荡器500的尖峰速率。输出尖峰信号z的尖峰速率(或尖峰频率)对应于卷积运算的结果。输出低通滤波器420可以用来利用尖峰信号z的平均值(例如,尖峰信号z在时间窗内的平均值)计算模拟信号。
在本发明的一些实施例中,异步数字缓存器430(例如,一连串的反相器)可以用来输出尖峰信号z。在本发明的一些实施例中,模拟输出缓存器440(例如,运算放大器)可以用来输出来自输出低通滤波器420的模拟信号。
如上文所指出,图3图示基于输入图像的像素小片计算输出图像的一个输出像素的卷积的卷积模块400。根据本发明的一个实施例,电路200包含单个卷积模块400,且其中计算输入图像与内核的卷积包含一次一个小片地将输入图像的小片的像素的值供应到卷积模块400以产生输出图像的值(一次一个输出图像像素)。
图5a和5b示意性地图示根据本发明的一个实施例的输入振荡器300、1位dac600与输入图像100的两个不同小片的像素值的连接。在图5a中所示的实例中,输入图像100、内核图像和输出图像的大小分别为14像素乘14像素(14×14)、5像素乘5像素(5×5)与10像素乘10像素(10×10)(与图1的实例的彼等图像大小相同)。然而,本发明的实施例不限于此。如图5a中所见,14×14输入图像的196个像素“展开”成单个值列(或向量或列向量),按行进行分组。此外,如图5a中所见,包含输入像素(如由以黑色突出显示的像素来表示)的行1到5的像素1到5的第一小片供应到1位dac(经由输入振荡器),以便计算第一小片与内核(由权重w1-25表示)的卷积。
图5b大体类似于图5a,差异为其图示输入图像100的第二小片供应到1位dac600。明确地说,所述第二小片包含行1到5的像素2到6(如由以黑色突出显示的像素来表示),其经由输入振荡器300供应到1位dac600以计算第二小片与内核的卷积。
根据本发明的另一实施例,多个卷积模块400可以并行地操作以并行地计算输入图像的不同小片的卷积。例如,如果存在两个卷积模块,那么一个卷积模块可以用来处理来自图像上半部的小片,且另一卷积模块可以用来处理来自图像下半部的小片。类似地,如果存在三个或四个卷积模块,那么每一卷积模块可以用来处理来自图像的单独部分的小片。此外,在一些实施例中,存在足够卷积模块,使得可以从输入图像的对应小片并行地计算每一输出像素。
图6a是根据本发明的一个实施例的输入振荡器300(例如,第j个输入振荡器300j)的示意图。如图6a中所示,输入振荡器300包含跨导放大器(gin)310、电容器330、开关340、比较器350和延迟元件360。跨导放大器310从输入图像接收输入信号inj(例如,对应于输入图像的像素的值的模拟值),且具有耦合到累加节点332的输出端子。累加节点332耦合到比较器350的非反相输入。此外,电容器330耦合于累加节点332与接地之间,且开关340耦合于累加节点332与接地之间,与电容器330并联。比较器350的反相输入供应有阈值电压vth(例如,高于接地的恒定电压),且比较器350的输出耦合到延迟器360,所述延迟器控制开关340的运作。开关340维持在断开状态(“断”状态),直到被来自延迟器360的信号触发。
在跨导放大器310接收到输入信号inj时,其将电流iinput,j输出到累加节点332。跨导放大器310产生正电流,所述正电流的值取决于输入信号inj的电压。在输入信号inj的电压较高时,产生较大电流iinput,j。
电流iinput,j累加在电容器330中,所述电容器具有电容cin且充当积分器。随着电荷在电容器330中累加,累加节点332处的电压增大(例如,单调地),其中增大速率取决于输入信号inj的振幅。在累加节点332处的电压超过阈值电压vth时,比较器350被触发,且开始输出具有高电压vh的正脉冲。比较器350的高电压vh输出触发延迟器360。在延迟器360的输出变高时,其使得开关340闭合,进而使电容器330复位且将累加节点332的电压拉到接地。将累加节点332的电压拉到接地具有结束正脉冲的效果,因为非反相输入处的电压已下降到阈值电压vth以下,使得比较器350实际上开始输出低电压vl,直到累加节点332处的电压再次超过阈值电压vth。由此,延迟器360控制信号的脉冲宽度pw(参见图4a),且输入信号inj的量值控制输出xj的尖峰10之间的周期t。在一些实施例中,脉冲速率在10mhz到40mhz的范围内。
图6b是根据本发明的一个实施例的输入振荡器300(例如,第j个输入振荡器300j)的跨导放大器310的示意图。如图6b中所见,根据本发明的一个实施例,跨导放大器310包含三个晶体管。跨导放大器310的第一电晶体m3为n型(或n通道)mosfet,其第一电极耦合到节点312,第二电极耦合到接地,且栅电极耦合到输入314以接收输入信号inj。跨导放大器310的第二电晶体m4为p型(或p通道)mosfet,其第一电极耦合到电压源316,第二电极耦合到节点312,且栅电极耦合到节点312。跨导放大器310的第三电晶体m5为p型mosfet,其第一电极耦合到电压源316,第二电极耦合到累加节点332,且栅电极耦合到节点312。
图6c为根据本发明的一个实施例的延迟器360的示意图。如图6c中所示,延迟器360包含构成两个反相器362和364的四个晶体管。第一反相器的第一p型晶体管m9a具有耦合到电压源316的第一电极、耦合到内部节点366的第二电极和耦合到比较器350的输出的栅电极。第一反相器的第一n型晶体管m10a具有耦合到内部节点366的第一电极、耦合到接地的第二电极和耦合到比较器350的输出的栅电极。第一p型晶体管m9a和第一n型晶体管m10a一起形成第一反相器362。延迟器的第二p型晶体管m9b具有耦合到电压源316的第一电极、经由输出节点369耦合到开关340的第二电极,和耦合到内部节点366的栅电极。延迟器的第二n型晶体管m10b具有经由输出节点369耦合到开关340的第一电极、耦合到接地的第二电极和耦合到内部节点366的栅电极。第二p型晶体管m9b和第二n型晶体管m10b一起构成第二反相器364。
图6d是根据本发明的一个实施例的输入振荡器300j’的示意图,所述输入振荡器包含两个开关和两个延迟器360和380(例如,分别为第一延迟器和第二延迟器)。图6d大体类似于图6a的输入振荡器300j,只是添加了第二延迟器380和第二开关342。第二延迟器380可以用来调谐输入振荡器300j’的脉冲宽度pw,因为脉冲宽度是由第一延迟元件360和第二延迟元件380产生的两个延迟中的最大值确定。
图6e是根据本发明的一个实施例的第二延迟器380的示意图。如图6e中所示,第二延迟器380包含构成第一反相器382和第二反相器384的五个晶体管。第二延迟器380的第二反相器384包含第二延迟器的五个晶体管中的两个(晶体管m9c和m10c),且与图6c中所示的第一延迟器360的第二反相器364大体相同,且因此本文中将不重复对第二延迟器380的第二反相器384的论述。
第二延迟器380的第一反相器382包含第二延迟器380的其余三个晶体管。第一反相器的p型晶体管m6具有耦合到电压源316的第一电极、耦合到内部节点386的第二电极和耦合到比较器350的输出的栅电极。第一反相器的第一n型晶体管m7具有第一电极和栅电极,两者皆耦合到内部节点。第一反相器的第二n型晶体管m8具有耦合到第一n型晶体管的第二电极的第一电极、耦合到接地的第二电极和耦合到供应偏电压vb的线的栅电极。偏电压vb可以用来调谐反相器的运算速度,进而控制反相器的定时,且允许控制由输入振荡器300j’产生的脉冲的脉冲宽度。
图7是根据本发明的一个实施例的1位dac600的电路图。如图7中所示,1位dac600包含电流源602、三个晶体管差分对,和三个电流镜612、614和616,其中第一电流镜612和第二电流镜614具有电流增益1,且第三电流镜616具有电流增益a。第一电流镜612耦合到第二电流镜614,且第三电流镜616耦合到第二电流镜614。顶部两个差分对622和624中的晶体管用作开关,第一参考电压vref1供应到顶部两个差分对之间的栅电极,且脉冲输入xj供应到顶部两个差分对622和624的其它栅电极。顶部差分对622和624两者皆耦合到第一电流镜612和第三电流镜616。底部差分对626耦合于顶部两个差分对622和624与电流源602的底部之间。第二参考电压vref2供应到底部差分对626的栅电极中的一个,且权重wj供应到底部差分对626的另一栅电极。在第三电流镜616与第二电流镜614之间获得对应于ij的输出。
图8a是根据本发明的一个实施例的1位dac600’的示意图。如图8a中所示,在一个实施例中,1位dac600’包含dac核心800和辅助模块802。辅助模块802获得来自输入振荡器的脉冲输入xj和权重wj以产生一组信号804,包含|wi|(权重wi的绝对值)和控制信号va、vb、vc和vd(图8a中表示为va、...、vd)。控制信号va、vb、vc和vd为二元信号,其值对应于输入xj的逻辑值(高vh或低vl)与权重wj的正负号(正或负)的四个组合中的一个。对于给定输入和权重,四个信号va、vb、vc和vd中的仅一个将处于开状态。所述四个控制信号可以由辅助模块802中的逻辑电路产生。
由辅助模块802产生的控制信号供应到dac核心电路800,所述dac核心电路作为响应而产生电流脉冲输出ij。
图8b是根据本发明的一个实施例的dac核心800的电路图。如图8b中所示,dac核心800包含由晶体管m11、m12、m13和m14实施的四个电压受控电流源以及由权重信号|wi|控制的电流镜cm1和cm2。控制晶体管m15、m16、m17和m18用来在四个电流源的输出处实施开关且由信号va、vb、vc和vd控制,使得在任何给定时间,开关中的仅一个接通。
图9a是根据本发明的一个实施例的输出振荡器电路500的电路图。输出振荡器电路500大体类似于输入振荡器电路300j,只是求和节点410和输入低通滤波器510位于跨导放大器310前方。因此,本文中将不重复对大体类似组件的描述。求和节点410耦合到耦合到此输出振荡器电路500的m个1位dac600,且可以使用简单的电线合并来加以实施。低通滤波器510包含积分电容器512,所述积分电容器具有电容cint且耦合于求和节点410与接地之间。在一些实施例中,低通滤波器包含电阻器514,所述电阻器具有电阻rint且耦合于求和节点410与偏电压源vsum,b之间。
图9b是图示根据本发明的一个实施例的求和节点410处的典型波形的波形图。如图9b中所见,求和节点410处的波形为振幅取决于传入电流i1、i2、...、im中的脉冲的区域的模拟信号。在输入电流具有大的正值(与负值相反)时,则求和节点处的电压增大。电阻器514可以用来提供“泄漏”以便消耗电容器512,以使得累加的值不会变为过大。在本发明的另一个实施例中,以开关与电容器并联而非(或连同)电阻器514。在此类实施例中,开关充当复位开关,其方式类似于与耦合到在振荡器内部的累加节点332的电容器330并联耦合的开关340。
图9c是图示根据本发明的一个实施例的来自输出振荡器500的输出波形的波形图。如图9c中所见,输出波形z为与输入振荡器300具有相同振幅(vh)和脉冲宽度(pw)的脉冲型信号。循环时间(to1、to2、...)对求和节点410处的信号(例如,电压)的值进行编码。求和节点410处的较大电压导致较短循环时间to,且求和节点410处的较小电压导致较长循环时间to。
如上文关于图3所论述,所得输出脉冲z可以供应到异步数字缓存器430以输出尖峰信号z。或者(或另外),所得输出脉冲z可以供应到输出低通滤波器420以对脉冲求积分以产生模拟信号,所述模拟信号可以接着由模拟输出缓存器440(例如,由运算放大器)缓存。
模拟结果
图10是图示根据本发明的一个实施例的在模拟电路时,在三个输入振荡器3001、3002和3003的输出处、在求和节点410处、在输出振荡器500的内部电容器332处以及在输出振荡器500的输出(z)处的波形的一组波形图。所述波形示出1μs的运算。标注为x1、x2和x3的迹线示出由三个输入振荡器3001、3002和3003(分别处于高、低和中等尖峰速率)产生的信号,且标注为vint的迹线示出在求和节点410(其在时间0复位到固定值)处产生的信号,标注为vosc的迹线示出在输出振荡器500的内部节点处(例如,在比较器350的非反相输入处)产生的信号,且标注为outz的迹线示出输出振荡器500的输出尖峰信号。outz迹线含有卷积值。
电路消耗的模拟功率为1.86mw,且主要子组件的模拟功率包含:用于单个卷积模块的0.26mw,用于具有二十五个输入振荡器的阵列的1.03mw,和用于输出缓存器的0.57mw。
图11是图示根据本发明的一个实施例的电路的模拟输出的示意图。图11大体类似于图1,但进一步包含电路200的最终输出图像130的图像。如可看出,最终输出130紧密地匹配理想输出120,进而确认电路设计按既定执行。
实验结果
依据90nm工艺制造基于上文所描述的电路设计的芯片。所制造的芯片包含二十五个输入振荡器、二十五个1位dac和一个输出振荡器。二十五个输入振荡器将二十五个模拟输入信号转换为二十五个脉冲信号。所制造芯片占用2.3mm×2.3mm,且具有七十二个焊垫:对应于二十五个模拟输入的二十五个焊垫以及用以将模拟权重w供应到1位dac的额外二十五个焊垫。
在一个实验中,将大小为14×14像素的输入图像供应到芯片用于处理。将输入图像的一个大小为5×5像素的小片的强度值经由二十五个模拟输入焊垫提供到芯片。同时,经由二十五个模拟权重焊垫将内核5×5像素内核的权重w供应到芯片。每一输入小片施加到芯片1μs,且记录所得输出。为处理整个图像,跨越输入图像依序移位所述小片(例如,在每一行中从左到右一次移位一个像素,且对于所有行从上到下重复)。对于此图像实例,一百个小片依序供应到芯片以处理整个输入图像。
图12是图示由根据本发明的一个实施例的芯片产生的实验测量波形的示意图。如图12中所见,输入图像106具有被白色边界围绕着的大小为5×5像素的小黑色正方形,且5×5像素内核112包含在左侧的两列白色像素,在中心的一列灰色像素,和在右侧的两列黑色像素。图12的上部部分图示处理在黑色正方形左侧上的第一输入小片102a。所述第一输入小片102a极类似于内核112。由于第一输入小片102a与内核112之间的类似性,芯片以高速率输出信号,所述信号映射到芯片的输出图像132中的亮(例如,白色)像素。相比之下,图12的下部部分图示处理在黑色正方形的右侧上的第二输入小片102b。因为第二输入小片102b与内核112差异很大,因此芯片以高速率输出信号,所述信号映射到芯片的输出图像132中的暗(例如,黑色)像素。(注意,此情形为例如图1和11的反转,在图1和11中,类似于内核的输入图像部分映射到输出区中的暗或黑色像素,且不同于内核的输入图像部分映射到输出图像中的亮或白色像素。进行输出的此反转以实现与图像处理文献中使用的惯例的一致性。然而,本发明的实施例不限于此。)
图12中的实验输出图像132示出由芯片响应于一百个输入小片而建置的图像。对于每一输入小片,芯片复位,且如上文所描述,每一输入小片输入到芯片1μs。outz信号的尖峰速率通过使用由计算机控制的数字示波器测量每次复位和图像小片更新之后0.8μs的脉冲信号的瞬时循环时间来加以测量。实验输出图像132的大小为10×10像素,且100个像素中的每一个处于灰阶。亮像素指示低尖峰速率,且暗像素指示高尖峰速率。
再次在较大图像上测试所述电路。图13a示出输入图像104,其大小为512×512像素。图13b示出在测试期间应用的大小为5×5像素的卷积内核114。
图13c示出具有图13a的输入图像104与图13b的内核114的理想输出卷积122的图像的曲线图,其中理想输出卷积122是使用理想等式产生。
图13d示出在向芯片依序供应来自图13a的输入图像104的小片和图13b的内核114时,以实验方式从芯片测量的卷积输出134。图13d中所示的卷积输出图像134的大小为508×508像素,且是通过将输入图像104的小片一次一个小片地供应到芯片而产生,其方式类似于上文相对于图12所描述的方式。每个像素的灰阶值表示在芯片复位且被供应输入图像小片之后约0.8μs由芯片产生的脉冲信号的尖峰速率。类似于在图12中,图13c和13d中的输出图像与图1和11中相比被反转:具有较高类似性(例如,较低输出尖峰速率)的区映射到较亮的输出像素,且具有较低类似性(例如,较高输出尖峰速率)的区映射到较暗输出像素。
图13e示出根据本发明的一个实施例的误差图像136,其表示图13c中所示的理想输出122与图13d中所示的实验输出134之间的差异。图13f是根据本发明的一个实施例的用于卷积输出图像134的所有像素的误差的直方图138。如图13e和13f中所见,实验输出134极为接近于理想输出122。此外,误差的标准差为全范围的1.72%,其为理想计算的晶体管级模拟的预期误差。
芯片的实验测量功率消耗为1.62mw,其稍微好于(约降低13%)模拟值。
由此,本发明的实施例提供用于执行尖峰域卷积的电路和方法。与相关电路相比,可以在不使用模拟或数字乘法器而使用具有可变增益的1位dac来执行乘法运算的情况下执行本发明的实施例。1位dac比模拟和数字乘法器使用的功率显著较小。由此,本发明的实施例可以按比通用微处理器小约3个数量级的能量执行准确的卷积。此外,本发明的实施例比对等的全模拟卷积电路实现更好地准确度,且使用比数字实施方案小的物理区域,进而提供每次计算的低能量使用以及高运算速度。
本发明的实施例可以实施为例如专用集成电路(asic)或数字信号处理器(dsp)的组件。
虽然已经关于某些示范性实施例来描述本发明,但应理解,本发明不限于所公开的实施例,而相反地,本发明旨在涵盖包含于所附权利要求和其等效物的精神和范围内的各种修改和等效布置。
- 还没有人留言评论。精彩留言会获得点赞!