一种基于双流卷积神经网络的立体匹配方法与流程
本发明涉及计算机视觉的立体匹配与深度学习技术领域,具体讲的是一种基于双流卷积神经网络的双视点图像立体匹配方法。
背景技术:
立体视觉匹配是计算机视觉和非接触测量研究中最基本的关键问题之一,立体匹配的目标是找出不同视角的图像之间的对应点关系,获得视差图,得到了视察图之后,就可以很容易地得到原始图像的深度信息和三维信息。因此,立体匹配问题普遍被视为立体视觉中最关键的问题。
视差图的获取是立体匹配问题的关键,关于计算像素点视差值的算法,根据采用图像表示的基元不同,可以分为:区域立体匹配算法,基于特征的立体匹配算法,基于相位的立体匹配算法。根据采用优化理论的方法不同,又可分为:局部立体匹配和全局立体匹配。
立体匹配问题作为立体视觉中最困难的问题,是因为有以下挑战:遮挡问题,也就是一张图的某些区域因为遮挡原因,在另一个视角的图中没有对应的匹配点。其次是弱纹理的问题,如果只从局部的角度计算,就会出现大量的匹配点。传统的方法通过全局能量代价函数来检测遮挡,利用增大窗口的方法处理弱纹理的问题,但是效果有限[2]。
近几年,深度学习在计算机视觉方面获得了重大进展,在图像分类,物体检测,视觉显著性检测等很多传统计算机图像与视觉方面的问题取得了巨大成功[4]。其中,最为典型的是卷积神经网络cnn,它通过卷积和池化操作提取了目标特征,并降低了特征分辨率,减少了计算量[1]。将池化的结果通过激活函数,将线性的卷积操作与非线性的激活函数结合,使得网络可以模拟出更为复杂多样的映射关系,使网络获得很好的特征提取的能力。
参考文献
[1]krizhevsky,alex,ilyasutskever,andgeoffreye.hinton."imagenetclassificationwithdeepconvolutionalneuralnetworks."advancesinneuralinformationprocessingsystems.2012.
[2]klaus,andreas,mariosormann,andkonradkarner."segment-basedstereomatchingusingbeliefpropagationandaself-adaptingdissimilaritymeasure."patternrecognition,2006.icpr2006.18thinternationalconferenceon.vol.3.ieee,2006.
[3]arewereadyforautonomousdriving?thekittivisionbenchmarksuite,[online].available:
http://www.cvlibs.net/datasets/kitti/eval_stereo_flow.php?benchmark=stereo
[4]lecun,yann,yoshuabengio,andgeoffreyhinton."deeplearning."nature521.7553(2015):436-444.
技术实现要素:
本发明的目的是鉴于立体匹配问题在三维重建,机器人导航,三维场景感知等立体视觉问题中的重要性以及其近几年深度学习方法在计算机视觉领域的巨大成功,提出一种基于双流卷积神经网络的立体匹配方法。
该方法利用一种双流卷积神经网络,学习并计算出左右视图中目标区域的匹配代价,并以交叉聚合算法作为辅助,有效地获得目标图像的视差图。双流网络结构不仅继承了卷积神经网络计算量小,性能稳定等优点,同时拥有较大的接受域,并且更充分地提取了目标点邻近区域的特征,拥有更高的精度。
为了实现上述目的,本发明通过以下技术方案予以实现,具体包括如下步骤:
步骤(1):构建一种基于交叉熵二值分类问题的训练数据,将训练数据分割出正负样本。
步骤(2):提出一种双流卷积神经网络结构用于计算两张图像的相似度,并利用步骤(1)构建的数据去训练网络的参数。
步骤(3):分段处理双流网络前向计算过程中分流和汇总两个模块,并保存中间数据,节省大量计算量。
步骤(4):将网络输出结果转化为匹配代价,并利用交叉聚合算法将聚合区域内的匹配代价平均化。
步骤(5):基于赢者通吃策略计算每一个像素点的视差,并用插值法对结果进行亚像素增强。
步骤(1)所述的构建训练数据具体如下:
所有数据和对应的标签均从kitti数据库获取[3],本方法只使用灰度图像数据,并对所有灰度值归一化。对于训练用数据,需要为每一个像素点构建一个正样本和负样本便于之后建立基于二分类问题的交叉熵残差。
设
对于一个正样本:q=(x-dt,y)
对于一个负样本:q=(x-dt+oneg,y)
dt为点p对应的视差真值,oneg为一个随机偏移量。由于数据都只有水平方向上的视差,垂直方向是对齐的,因此只需要水平方向的视差。所有靠近图片边界的点,在取窗口时,不够的部分以0值填充。所有正样本对应的标签为1,负样本对应的标签为0。
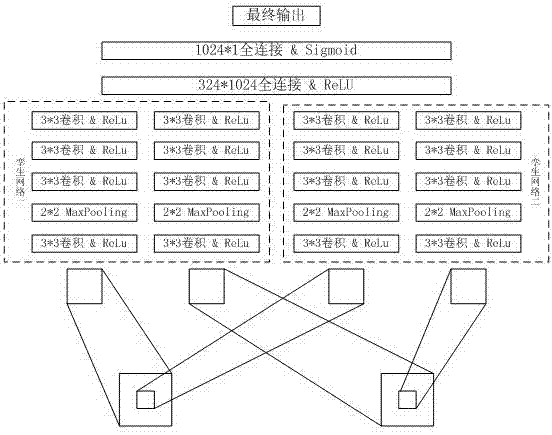
步骤(2)所使用的双流卷积神经网络结构的具体设计:双流网络由两个孪生卷积神经网络组成,再将它们的结果汇总并输出,每一个孪生卷积网络都有左右两个子网络,左右子网络在网络结构上一样,具体如下:
1.以32×32的窗口作为输入
2.后接一个3×3,步长为1的卷积层+relu激活层
3.后接一个2×2,步长为2的下采样层,下采样采用maxpooling
4.后接三个3×3,步长为1的卷积层+relu激活层
孪生网络的两个子网络最后会得到两个9×9的窗口,子网络参数共享。
左右子网络的不同在于:
左侧子网络的输入是左图的窗口,右侧子网络的输入是右图的窗口。
两个孪生卷积神经网络的结构也是一样的,不同在于:
其中一个的输入为原图中解析度为32×32的窗口,另一个的输入是将同一个点为中心的64×64的窗口下采样成32×32的窗口。
两个孪生网络汇总时进入决策层,结构如下:
1.一个324×1024全连接层,输出维度为1024,并经过relu激活
2.一个1024×1的全链接层,输出维度为1,并经过sigmoid激活
网络训练时使用的交叉熵残差定义如下:
θ表示网络的参数,y(i)第i个样本对应的标签值,正样本的y(i)为1,负样本的y(i)为0,x(i)表示样本i,h(x(i))表示第i个样本的网络最终输出结果。
网络的参数更新利用梯度下降法,公式如下:
α表示学习率,
对于参数θ,网络的线性计算部分可表示成:
ak(x(i))表示样本x(i)在第k层网络中,线性部分的输出结果,wk和bk分别表示该层的乘法参数和偏移参数,
梯度
hθ(x(i))表示样本x(i)在参数为θ时,网络的输出结果。
步骤(3)在测试阶段,对于左图中某一点p(x,y),对于所有可能视差值d∈d,右图中所有q(x-d,y)都是可能和p匹配的备选点,令p-d表示点q。则需要计算所有组合<p,p-d>的相似度。
只有在决策阶段才需要计算所有组合,因此在决策层之前先计算并保存所有点对应窗口在孪生网络的结果,保证每个窗口在孪生网络中只计算一次。
最后再在决策层计算将对于p(x,y)的所有备选点的相似度结果,可节省不必要的计算量。
步骤(4)中,由于弱纹理现象和视差图平滑化的需要,有必要利用交叉聚合的方法均值化同一物体上点的视差值,方法具体如下:
对于某一个像素点p,根据一定的规则进行扩散,可获得区域u(p),扩散规则如下:
|i(p)-i(pl)|<intensity(1)
||p-pl||<distance(2)
式1表示备选点pl与p的值的差距要小于阈值intensity,式2表示pl与p的距离要小于阈值distance。
根据以上规则,首先基于p点分别从上下方向延伸,得到一组垂直的像素点v(p),对于
得到u(p)后,匹配代价均值化计算如下:
步骤(5)的赢者通吃策略就是,设c(p,d)为交叉聚合的最终结果,对于左图中某点p,选取所有c(p,d)中最小的结果作为匹配结果,那么d就是像素p的视差。
最后再对结果进行亚像素增强,公式如下:
dp为亚像素增强后结果,d为赢者通吃策略的结果,c为赢者通吃策略结果中对应的c(p,d),c+为c(p,d+1),c-为c(p,d-1)。
本发明的有益效果如下:本发明利用一种双流网络结构,学习并计算出左右视图中目标区域的匹配代价,并以一些后处理算法作为辅助,有效地获得目标图像的视差图。该方法有效地将深度学习中的卷积神经网络应用到了立体匹配中,不仅继承了卷积神经网络计算量小,性能稳定等优点,同时拥有较大的接受域,并且更充分地提取了目标点邻近区域的特征,拥有更高的精度。
附图说明
图1是本发明基于双流卷积神经网络进行立体匹配的算法流程图。
图2是双流卷积神经网络的结构。
图3是交叉聚合范围示意图。
图4是交叉聚合范围选取流程图。
具体实施方式
下面结合附图对本发明作进一步说明。
如图1所示,一种基于双流卷积神经网络的立体匹配方法,具体步骤如下:
步骤(1):构建一种基于交叉熵二值分类问题的训练数据,将训练数据分割成正负样本。
步骤(2):提出一种双流卷积神经网络结构用于计算两张图像的相似度,并利用步骤(1)构建的数据去训练网络的参数。
步骤(3):分段处理双流网络前向计算过程中分流和汇总两个模块,并保存中间数据,节省大量计算量。
步骤(4):将网络输出结果转化为匹配代价,并利用交叉聚合算法将聚合区域内的匹配代价平均化。
步骤(5):基于赢者通吃策略计算每一个像素点的视差,并插值法对结果进行亚像素增强。
步骤(1)所述的构建训练数据具体如下:
所有数据和对应的标签均从kitti数据库获取,本方法只使用灰度图像数据,并对所有灰度值归一化。对于训练用数据,需要为每一个像素点构建一个正样本和负样本便于之后建立基于二分类问题的交叉熵残差。
设
对于一个正样本:q=(x-dt,y)
对于一个负样本:q=(x-dt+oneg,y)
dt为点p对应的视差真值,oneg为一个随机偏移量。由于数据都只有水平方向上的视差,垂直方向是对齐的,因此只需要水平方向的视差d。所有靠近图片边界的点,在取窗口时,不够的部分以0值填充。所有正样本对应的标签为1,负样本对应的标签为0
步骤(2)所使用的双流卷积神经网络结构的具体设计如图2所示,以下是具体说明:
双流网络由两个孪生卷积神经网络组成,再将它们的结果汇总并输出,每一个孪生卷积网络都有左右两个子网络,左右子网络在网络结构上一样,具体如下:
5.以32×32的窗口作为输入
6.后接一个3×3,步长为1的卷积层+relu激活层
7.后接一个2×2,步长为2的下采样层,下采样采用maxpooling
8.后接三个3×3,步长为1的卷积层+relu激活层
孪生网络的两个子网络最后会得到两个9×9的窗口,子网络参数共享。
左右子网络的不同在于:
左侧子网络的输入是左图的窗口,右侧子网络的输入是右图的窗口。
两个孪生卷积神经网络的结构也是一样的,不同在于:
其中一个的输入为原图中解析度为32×32的窗口,另一个的输入是将同一个点为中心的64×64的窗口下采样成32×32的窗口。
由此可以使网络拥有较大的接收域,同时又强化了靠近中点部分信息的特征提取能力。
两个孪生网络汇总时会得到4个9×9窗口,将他们拉平并连接成1×324的向量,进入汇总的决策层,结构如下:
3.一个324×1024全连接层,输出维度为1024,并经过relu激活
4.一个1024×1的全链接层,输出维度为1,并经过sigmoid激活
最后经过sigmoid层的结果作为网络的最终结果。
整个网络非线性计算部分由relu和sigmoid组成。
relu定义如下:
sigmoid定义如下:
h(x)表示激活层(非线性运算)的输出,x表示激活层之前的线性计算输出,网络中线性计算部分可以表示成:
ak(x(i))表示样本x(i)在第k层网络中,线性部分的输出结果,wk和bk分别表示该层的乘法参数和偏移参数,
网络训练时使用的交叉熵残差定义如下:
l(θ)=y(i)logh(x(i))+(1-y(i))log(1-h(x(i)))
θ表示网络的参数,y(i)第i个样本对应的标签值,正样本的y(i)为1,负样本的y(i)为0,x(i)表示样本i,h(x(i))表示第i个样本的网络最终输出结果。
网络的参数更新利用梯度下降法,公式如下:
α表示学习率,
梯度
hθ(x(i))表示样本x(i)在参数为θ时,网络的输出结果。
步骤(3)在测试阶段,对于左图中某一点p(x,y),对于所有可能视差值d∈d,右图中所有q(x-d,y)都是可能和p匹配的备选点,令p-d表示点q。则需要计算所有组合<p,p-d>的相似度。
只有在决策阶段才需要计算所有组合,因此在决策层之前先计算并保存所有点对应窗口在孪生网络的结果,保证每个窗口在孪生网络中只计算一次。
最后再在决策层计算将对于p(x,y)的所有备选点的相似度结果,可节省不必要的计算量。
步骤(4)中,由于弱纹理现象和视差图平滑化的需要,有必要进行交叉聚合均值化同一物体上点的视差值,方法具体如下:
对于某一个像素点p,根据一定的规则进行扩散,可获得区域u(p),扩散规则如下:
|i(p)-i(pl)|<intensity(1)
||p-pl||<distance(2)
式1表示备选点pl与p的值的差距要小于阈值intensity,式2表示pl与p的距离要小于阈值distance。
具体选取流程如图4所示。根据以上规则,首先基于p点分别从上下方向延伸,得到一组垂直的像素点v(p),对于
u(p)范围如图3所示,得到u(p)后,匹配代价均值化计算如下:
c0(p,d)=-s(<pl(p),pr(p-d)>)
步骤(5)的赢者通吃策略就是,设c(p,d)为交叉聚合的最终结果,对于左图中某点p,选取所有c(p,d)中最小的结果作为匹配结果,那么d就是像素p的视差。
最后再对结果进行亚像素增强,公式如下:
dp为亚像素增强后结果,d为赢者通吃策略的结果,c为赢者通吃策略结果中对应的c(p,d),c+为c(p,d+1),c-为c(p,d-1)。
综上所述,本发明利用双流卷积神经网络学习不同视点图片中匹配点之间的相似度,并利用交叉聚合的方法辅助,优化了弱纹理区域的结果,通过实验证明本方法确实可以准确地进行立体匹配。不仅继承了卷积神经网络计算量小,性能稳定等优点,同时拥有较大的接受域,并且更充分地提取了目标点邻近区域的特征,拥有更高的精度。
- 还没有人留言评论。精彩留言会获得点赞!