一种加密语音信号的感知哈希特征提取方法及系统与流程
本发明涉及语音信号处理技术,尤其涉及一种加密语音信号的感知哈希特征提取方法及系统。
背景技术
随着计算机网络和多媒体信息技术的飞速发展,多媒体语音是作为传递信息最为直接和方便的多媒体应用之一。为了保证用户语音数据的安全性,语音数据在上传到云服务器之前需要被加密,由于加密处理会导致语音绝大部分感知内容丢失。因此,如何在密文语音中提取能够满足检索、认证等操作的语音特征成为了人们关注且富有挑战性的课题。
近年来,国内外研究学者对明文域的语音感知哈希特征的提取方法做了大量研究,如焦玉华等人提出的以语音提取线谱作为感知特征,并通过离散余弦变换(dct)对参数矩阵去相关来提取最终的感知特征参数,该算法具有良好的鲁棒性,但是摘要性不强。王宏霞等人提出的基于数字水印和感知哈希的密文域语音搜索算法,通过从明文语音中提取过零率,并将生成的感知哈希序列作为搜索摘要。该算法效率较高,但是鲁棒性和区分性不强。zhao等人提出了一种较为新颖的感知哈希算法用于密文语音检索,利用语音的多重分形特征生成感知哈希摘要,算法具有良好的鲁棒性和区分性,但压缩数据规模之后,算法的鲁棒性和区分性会出现下降,从而导致检索性能的降低。综上所述,现有的用于明文域语音认证、密文语音检索等应用的提取感知哈希特征方法的鲁棒性和区分性不能很好地折中,摘要性也较差,感知特征提取效率也较慢,而且现有研究方法不能直接从加密语音信号中提取感知哈希特征值。
技术实现要素:
本发明的目的是提供一种加密语音信号的感知哈希特征提取方法及系统,以解决现有技术中从加密语音信号中直接提取语音感知特征时的鲁棒性差、区分性差和摘要性差的问题。
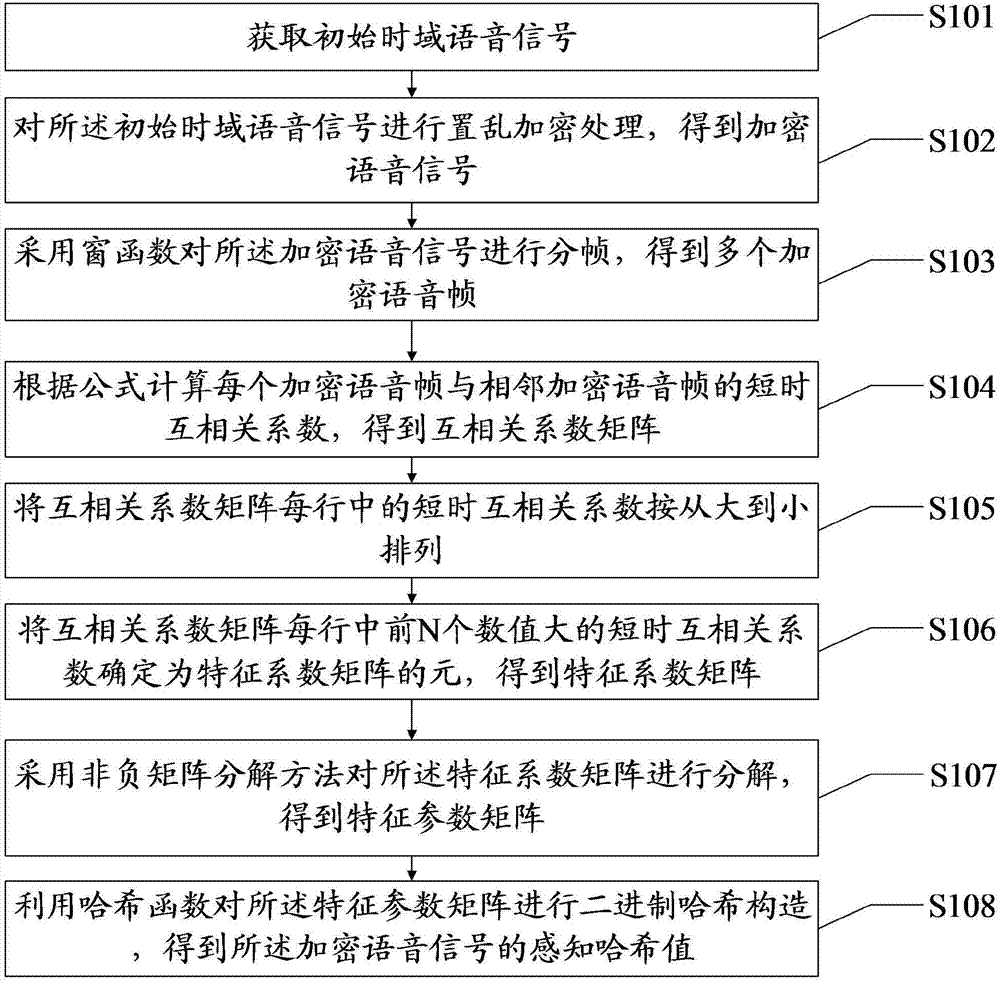
一种加密语音信号的感知哈希特征提取方法,包括:
获取初始时域语音信号;
对所述初始时域语音信号进行置乱加密处理,得到加密语音信号;
采用窗函数对所述加密语音信号进行分帧,得到多个加密语音帧;
根据公式
将互相关系数矩阵每行中的短时互相关系数按从大到小排列;
将互相关系数矩阵每行中前n个数值大的短时互相关系数确定为特征系数矩阵的元,得到特征系数矩阵,其中1≤n≤fn;
采用非负矩阵分解方法对所述特征系数矩阵进行分解,得到特征参数矩阵;
利用哈希函数对所述特征参数矩阵进行二进制哈希构造,得到所述加密语音信号的感知哈希值。
可选的,所述对所述初始时域语音信号进行置乱加密处理,得到加密语音信号,具体包括:
对所述初始时域语音信号进行不重叠分帧处理,得到多个初始时域语音分帧信号;所述初始时域语音分帧信号的长度为256;
分别对每个所述初始时域语音分帧信号进行一维离散余弦变换,得到多个频域语音分帧信号;
利用随机数生成器为每个频域语音分帧信号生成一个唯一的整数,对频域语音分帧信号按随机分配的整数的大小进行排列,得到多个置乱后的频域语音分帧信号,其中1≤所述随机分配的整数的个数≤fn;
对多个置乱后的频域语音分帧信号进行离散余弦反变换,得到多个置乱后的时域语音分帧信号;
将所述多个置乱后的时域语音分帧信号顺序连接,得到所述加密语音信号。
可选的,所述采用窗函数对所述加密语音信号进行分帧,得到多个加密语音帧,具体包括:
采用窗函数对所述加密语音信号进行分帧,得到多个加密语音帧pn(m)=ω(m)×xe((n-1)×inc+m);
其中,pn(m)是第n个加密语音帧,1≤n≤fn,ω(m)为窗函数,inc为后一帧对前一帧的位移量,m为加密语音帧的帧内样点数,xe(.)为加密语音信号。
可选的,所述将互相关系数矩阵每行中前n个数值大的短时互相关系数确定为特征系数矩阵的元,得到特征系数矩阵,具体包括:
将互相关系数矩阵每行中前22个短时互相关系数确定为特征系数矩阵的元,得到特征系数矩阵,本发明中每行选取22个数值,即n=22。
可选的,所述利用哈希函数对所述特征参数矩阵进行二进制哈希构造,得到所述加密语音信号的感知哈希值,具体包括:
利用哈希函数
一种加密语音信号的感知哈希特征提取系统,其特征在于,包括:
初始时域语音信号获取模块,用于获取初始时域语音信号;
加密语音信号生成模块,用于对所述初始时域语音信号进行置乱加密处理,得到加密语音信号;
加密语音帧生成模块,用于采用窗函数对所述加密语音信号进行分帧,得到多个加密语音帧;
互相关系数矩阵生成模块,用于根据公式
排序模块,用于将互相关系数矩阵每行中的短时互相关系数按从大到小排列;
特征系数矩阵生成模块,用于将互相关系数矩阵每行中前n个数值大的短时互相关系数确定为特征系数矩阵的元,得到特征系数矩阵;
特征参数矩阵生成模块,用于采用非负矩阵分解方法对所述特征系数矩阵进行分解,得到特征参数矩阵;
加密语音信号的感知哈希值生成模块,用于利用哈希函数对所述特征参数矩阵进行二进制哈希构造,得到所述加密语音信号的感知哈希值。
可选的,所述加密语音信号生成模块具体包括:
初始时域语音分帧信号生成单元,用于对所述初始时域语音信号进行不重叠分帧处理,得到多个初始时域语音分帧信号;所述初始时域语音分帧信号的长度为256;
频域语音分帧信号生成单元,用于分别对每个所述初始时域语音分帧信号进行一维离散余弦变换,得到多个频域语音分帧信号;
置乱后的频域语音分帧信号生成单元,用于利用随机数生成器为每个频域语音分帧信号生成一个唯一的整数,对频域语音分帧信号按随机分配的整数的大小进行排列,得到多个置乱后的频域语音分帧信号,其中1≤所述随机分配的整数的个数≤fn;
时域语音分帧信号生成单元,用于对多个置乱后的频域语音分帧信号进行离散余弦反变换,得到多个置乱后的时域语音分帧信号;
加密语音信号生成单元,用于将所述多个置乱后的时域语音分帧信号顺序连接,得到所述加密语音信号。
可选的,所述加密语音帧生成模块得到的多个加密语音帧为pn(m)=ω(m)×xe((n-1)×inc+m);
其中,pn(m)是第n个加密语音帧,1≤n≤fn,ω(m)为窗函数,inc为后一帧对前一帧的位移量,m为加密语音帧的帧内样点数,xe(.)为加密语音信号。
可选的,所述特征系数矩阵生成模块生成的特征系数矩阵每行中元的个数为22,即n=22。
可选的,所述加密语音信号的感知哈希值生成模块利用的哈希函数为
根据本发明提供的具体实施例,本发明公开了以下技术效果:
本发明的加密语音信号的感知哈希特征提取方法及系统,采用窗函数对加密语音信号进行分帧,得到多个加密语音帧。根据公式
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本发明所提供的加密语音信号的感知哈希特征提取方法实施例的流程图;
图2为本发明所提供的加密语音信号的感知哈希特征提取系统实施例的结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明的目的是提供一种加密语音信号的感知哈希特征提取方法及系统,以解决现有技术中从加密语音信号中直接提取语音感知特征时的鲁棒性差、区分性差和摘要性差的问题。
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
图1为本发明所提供的加密语音信号的感知哈希特征提取方法实施例的流程图。如图1所示,该方法包括:
步骤s101:获取初始时域语音信号。
步骤s102:对初始时域语音信号进行置乱加密处理,得到加密语音信号。
步骤s103:采用窗函数对加密语音信号进行分帧,得到多个加密语音帧。
步骤s104:根据公式
步骤s105:将互相关系数矩阵每行中的短时互相关系数按从大到小排列。
步骤s106:将互相关系数矩阵每行中前n个数值大的短时互相关系数确定为特征系数矩阵的元,得到特征系数矩阵,其中1≤n≤fn。
步骤s107:采用非负矩阵分解方法对特征系数矩阵进行分解,得到特征参数矩阵。
步骤s108:利用哈希函数对特征参数矩阵进行二进制哈希构造,得到加密语音信号的感知哈希值。
本实施例提供的加密语音信号的感知哈希特征提取方法,计算每个加密语音帧与相邻加密语音帧的短时互相关系数,选取数值大的短时互相关系数生成特征系数矩阵。采用非负矩阵分解方法对特征系数矩阵进行分解,得到特征参数矩阵;利用哈希函数对特征参数矩阵进行二进制哈希构造,得到加密语音信号的感知哈希值。本实施例可以将从加密语音信号中提取的短时互相关系数作为加密语音信号的感知特征,并通过哈希构造生成加密语音信号的感知哈希值,提高了从加密语音信号中直接提取语音感知特征时的鲁棒性、区分性和摘要性。能够有效用于密文语音的检索、认证等。
在实际应用中,对初始时域语音信号进行置乱加密处理,得到加密语音信号,具体包括:
对初始时域语音信号进行不重叠分帧处理,得到多个初始时域语音分帧信号;初始时域语音分帧信号的长度为256。
分别对每个初始时域语音分帧信号进行一维离散余弦变换,得到多个频域语音分帧信号。
利用随机数生成器为每个频域语音分帧信号生成一个唯一的整数,对频域语音分帧信号按随机分配的整数的大小进行排列,得到多个置乱后的频域语音分帧信号,其中1≤所述随机分配的整数的个数≤fn。
对多个置乱后的频域语音分帧信号进行离散余弦反变换,得到多个置乱后的时域语音分帧信号。
将多个置乱后的时域语音分帧信号顺序连接,得到加密语音信号。
在实际应用中,采用窗函数对加密语音信号进行分帧,得到多个加密语音帧,具体包括:
采用窗函数对加密语音信号进行分帧,得到多个加密语音帧pn(m)=ω(m)×xe((n-1)×inc+m)。
其中,pn(m)是第n个加密语音帧,1≤n≤fn,ω(m)为窗函数,inc为帧移长度,m为加密语音帧的帧内样点数,xe(.)为加密语音信号。设置帧移的原因是:语音信号是时变的,在短时范围内特征变化较小,所以作稳态处理;但超出这短时范围语音信号就有变化了,如相邻两帧之间的基音发生了变化,正好是两个音节之间,或正好是声母向韵母过渡,等等,这时,其特征参数可能变化较大,故为了使特征参数平滑的变化,在两个不重叠分帧之间插入一些帧来提取特征参数,inc即为后一帧对前一帧的位移量(简称帧移长度)。
在实际应用中,将互相关系数矩阵每行中前n个数值大的短时互相关系数确定为特征系数矩阵的元,得到特征系数矩阵,具体包括:
将互相关系数矩阵每行中前22个短时互相关系数确定为特征系数矩阵的元,得到特征系数矩阵,本发明中每行选取22个数值,即n=22。
本实施例综合考虑算法的效率和感知哈希的性质,将特征系数矩阵每行元的个数确定为22,从而提高了加密语音信号的感知哈希特征提取方法的计算效率和可区分性。
在实际应用中,利用哈希函数对特征参数矩阵进行二进制哈希构造,得到加密语音信号的感知哈希值,具体包括:
利用哈希函数
图2为本发明所提供的加密语音信号的感知哈希值的提取系统实施例的结构示意图。如图2所示,该系统包括:
初始时域语音信号获取模块1,用于获取初始时域语音信号。
加密语音信号生成模块2,用于对初始时域语音信号进行置乱加密处理,得到加密语音信号。
加密语音帧生成模块3,用于采用窗函数对加密语音信号进行分帧,得到多个加密语音帧。
互相关系数矩阵生成模块4,用于根据公式
排序模块5,用于将互相关系数矩阵每行中的短时互相关系数按从大到小排列。
特征系数矩阵生成模块6,用于将互相关系数矩阵每行中前n个数值大的短时互相关系数确定为特征系数矩阵的元,得到特征系数矩阵。
特征参数矩阵生成模块7,用于采用非负矩阵分解方法对特征系数矩阵进行分解,得到特征参数矩阵。
加密语音信号的感知哈希值生成模块8,用于利用哈希函数对特征参数矩阵进行二进制哈希构造,得到加密语音信号的感知哈希值。
本实施例提供的加密语音信号的感知哈希特征的提取系统,通过互相关系数矩阵生成模块4计算每个加密语音帧与相邻加密语音帧的短时互相关系数,通过特征系数矩阵生成模块6选取数值大的短时互相关系数生成特征系数矩阵。通过特征参数矩阵生成模块7采用非负矩阵分解方法对特征系数矩阵进行分解,得到特征参数矩阵;最后通过加密语音信号的感知哈希值生成模块8利用哈希函数对特征参数矩阵进行二进制哈希构造,得到加密语音信号的感知哈希值。本实施例通过使用互相关系数矩阵生成模块4、特征系数矩阵生成模块6、特征参数矩阵生成模块7及加密语音信号的感知哈希值生成模块8生成加密语音信号的感知哈希值,提高了从加密语音信号中直接提取语音感知特征时的鲁棒性、区分性和摘要性。
在实际应用中,加密语音信号生成模块具体包括:
初始时域语音分帧信号生成单元,用于对初始时域语音信号进行不重叠分帧处理,得到多个初始时域语音分帧信号;初始时域语音分帧信号的长度为256。
频域语音分帧信号生成单元,用于分别对每个初始时域语音分帧信号进行一维离散余弦变换,得到多个频域语音分帧信号。
置乱后的频域语音分帧信号生成单元,用于利用随机数生成器为每个频域语音分帧信号生成一个唯一的整数,对频域语音分帧信号按随机分配的整数的大小进行排列,得到多个置乱后的频域语音分帧信号,其中1≤所述随机分配的整数的个数≤fn;
时域语音分帧信号生成单元,用于对多个置乱后的频域语音分帧信号进行离散余弦反变换,得到多个置乱后的时域语音分帧信号。
加密语音信号生成单元,用于将多个置乱后的时域语音分帧信号顺序连接,得到加密语音信号。
在实际应用中,加密语音帧生成模块得到的多个加密语音帧为pn(m)=ω(m)×xe((n-1)×inc+m)。
其中,pn(m)是第n个加密语音帧,1≤n≤fn,ω(m)为窗函数,inc为后一帧对前一帧的位移量,m为加密语音帧的帧内样点数,xe(.)为加密语音信号。
在实际应用中,特征系数矩阵生成模块生成的特征系数矩阵每行中元的个数为22。
本实施例中特征系数矩阵生成模块综合考虑算法的效率和感知哈希的性质,将特征系数矩阵每行元的个数确定为22,从而提高了加密语音信号的感知哈希特征提取方法的计算效率和可区分性。
在实际应用中,加密语音信号的感知哈希值生成模块利用的哈希函数为
在此提供本发明的加密语音信号的感知哈希特征提取方法的具体实施例。
本具体实施例中所用语音数据来自于timit语音库和tts语音库,由中文男女、英文男女录制的不同内容的语音组成,采样频率为16khz,采样精度为16bit的4秒wav语音1280段,声道数为单声道。其中英文640段,中文640段。实验环境为:
(1)硬件环境为:intel(r)core(tm)i5-3337ucpu,1.80ghz,内存4g。
(2)软件环境为:windows7操作系统下的matlabr2014a。
以从timit和tts语音库中随机选取的1280段中的1000条语音片段作为测试语音,首先根据步骤s102对测试语音进行加密得到加密语音信号。然后根据步骤s103将每段加密语音按长度512进行分帧,帧重叠为分帧长度的一半,得到多个加密语音帧。根据步骤s104-步骤s107生成特征参数矩阵。最后利用步骤s108提取加密语音信号的感知哈希值。
通过对1000个加密语音段进行感知哈希值的两两匹配,得到了499500个比特误码率(ber)数据,匹配结果表示不同内容加密语音信号的感知哈希值的ber值的概率分布与标准正态分布的概率曲线几乎重叠,即使用本发明方法提取到的哈希距离值近似服从正态分布,因此,本发明方法具有很好的区分性。
为了进一步验证本发明方法的区分性能,采用了误识率(far)来衡量,误识率可由下式计算;
其中,τ为感知认证阈值,μ为ber均值,δ为ber方差,x为误识率。
感知哈希算法的误识率的值越低,说明感知哈希算法的区分越好。本发明通过表格形式与wang方法(“wangh,zhoul,zhangw,etal.watermarking-basedperceptualhashingsearchoverencryptedspeech[c]//internationalworkshopondigitalwatermarking.springer,berlin,heidelberg,2013:423-434.”)、hao方法(“haogy,wanghx.perceptualspeechhashingalgorithmbasedontimeandfrequencydomainchangecharacteristics[c]//symposiumoninformation,electronics,andcontroltechnologies.2015.”)、zhao方法(“zhaoh,hes.aretrievalalgorithmforencryptedspeechbasedonperceptualhashing[c]//naturalcomputation,fuzzysystemsandknowledgediscovery(icnc-fskd),201612thinternationalconferenceon.ieee,2016:1840-1845.”)、he方法(“hes,zhaoh.aretrievalalgorithmofencryptedspeechbasedonsyllable-levelperceptualhashing[j].computerscienceandinformationsystems,2017,14(3):703–718.”)等方法进行对比,使用相同数量的1000条语音片段,对不同阈值τ下的误识率far值进行了比较,对比结果如表1所示。
表1不同阈值下不同方法的误识率far值
从表1可以看出,本发明所提出的加密语音信号的感知哈希特征提取方法的误识率far值好于wang、hao和zhao方法,与目前最新he方法性能几乎相当。本发明提出的加密语音信号的感知哈希特征提取方法应用于明文域时,误识率far值好于he方法。当设置匹配阈值τ=0.16时,每1020个语音片段大约有5个被误识,表明本发明方法具有较强的抗碰撞能力,即具有良好的区分性,能够满足密文语音的检索、认证等要求。
对来自于timit语音库和tts语音库中的语音文件进行了如下表2所示的各种内容保持操作。
表2内容保持操作
通常,语音信号经过mp3压缩,重采样、增加减小音量和添加噪音等内容保持操作处理后,其在语音信号中的数字表示所产生的特定改变并不影响内容表达。感知哈希的鲁棒性是指原始语音信号与其通过内容保持操作处理后的语音信号之间的ber小于预设阈值τ。换句话说,原始语音信号在一些内容保存操作之后,语音信号的感知哈希特征值应当与原始语音信号的感知哈希特征值一致。
不同方法鲁棒性比较:分别按照本发明提出的加密语音信号的感知哈希特征提取方法、wang方法、hao方法、zhao方法与he方法,将经过表2所列出的内容保持操作后的1000条语音片段的感知哈希值与原始语音的感知哈希值进行两两匹配,在执行每个内容保持操作后计算平均比特误码率,对比结果如表3所示。
表3不同方法平均比特误码率
从表3可以看出,本发明方法鲁棒性优于wang方法。与hao方法和zhao方法相比,除了mp3压缩操作之外,本发明方法的其他的内容操作手段的鲁棒性表现的均较好。与最新he的方法相比,本发明方法在mp3压缩和重采样操作鲁棒性表现一般,但是在同样的数量级,其余内容保持操作的鲁棒性均好于he方法,这是因为加密导致了语音信号的部分特征丢失,表明了本发明方法的鲁棒性较好,能够满足对密文语音的认证、检索等需求。此外,本发明方法应用于明文域语音时,除了mp3压缩操作平均比特误码率比he方法稍差之外,其余内容保持操作的平均比特误码率均好于表2所列其他方法,说明本发明提出的加密语音信号的感知哈希特征提取方法应用于明文语音时也具有较强的鲁棒性。
继续对来自于timit语音库和tts语音库中的原始语音采取用步骤s102中的方法进行加密,然后按步骤s104到步骤s107提取特征参数矩阵。原始语音片段采样频率为16khz、采样精度为16bit、长度为4s的wav格式语音片段,采样点数为64000。根据加密后的语音信号波形图,可知,加密后的语音波形变化平缓且均匀分布,表明加密性能良好,加密后的语音在听觉上表现为一段嘈杂的噪音,听不出任何信息来。使用密钥对加密语音信号进行解密,解密后的语音信号与原始语音信号几乎没有区别。当改变一位密钥后对语音信号进行解密,加密语音信号不能被解密,表明本发明步骤s102中提出的加密算法的密钥敏感性良好。当加密语音信号分帧长度为256,对于长度为4s的语音,密钥长度为125位,故密钥空间为125!,具有较大的密钥空间,能够满足实际使用中对语音的加密算法的要求。
继续对步骤s102得到的加密语音信号和相应的解密语音信号的感知语音质量评估(perceptualevaluationofspeechquality,pesq)进行了分析,pesq是国际电信联盟电信标准化部p.862建议的客观平均意见得分(meanopinionscore,mos)值从1.0(最差)到4.5(最好)的pesq-mos范围。对于密文语音,通常希望其pesq-mos能降低到1.0左右甚至更低(语音质量极差,静音或完全听不清楚,并且杂音很大),对于解密后所得明文语音,则希望其pesq-mos能达到2.5(语音质量还可以,听不太清楚,有一定延迟,有杂音)上甚至更高。本发明任意选取了密文语音库中的20条语音,分别测试了加密语音信号和解密语音信号的pesq-mos,如表4所示:
表4加密和解密后语音信号的pesq-mos
从表4可以看出,加密语音信号的pesq-mos几乎为1,表明加密语音信号质量极差,加密效果良好,不会泄露语音内容,而解密后的语音信号的pesq-mos大于2.5,说明本发明步骤s102提出的置乱加密算法的解密语音质量良好。
综上所述,本发明提出的密文语音感知哈希算法能够直接从加密语音中提取感知哈希值,并且对密文语音信号具有良好鲁棒性、区分性和摘要性。此外,本发明提出的加密语音信号的感知哈希特征提取方法应用于明文域语音时也表现出了比较好的区分性、鲁棒性和摘要性。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的系统而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处。综上,本说明书内容不应理解为对本发明的限制。
- 还没有人留言评论。精彩留言会获得点赞!