基于声音生成AR内容的方法、存储介质和装置与流程
本发明涉及计算机领域,特别涉及一种基于声音生成ar内容的方法、存储介质和装置。
背景技术
典型的增强现实技术ar(augmentedreality),是一种实时地计算摄影机影像的位置及角度并加上相应图像、视频、3d模型的技术,这种技术的目标是在屏幕上把虚拟世界嵌套在现实世界展示并进行互动。ar系统具有三个突出的特点:真实世界和虚拟的信息集成;具有实时交互性;是在三维尺度空间中增添定位虚拟物体。ar技术可广泛应用于多个领域。
ar实现原理,首先摄像头和传感器采集真实场景的视频或者图像,传入后台的处理单元对其进行分析和重构,并结合头部跟踪设备的数据来分析虚拟场景和真实场景的相对位置,实现坐标系的对齐并进行虚拟场景的融合计算;交互设备采集外部控制信号,实现对虚实结合场景的交互操作。系统融合后的信息会实时地显示在显示器中,展现在用户的视野中。
当前的ar技术主要是基于摄像头和传感器采集的真实场景的视频或图像进行分析,语音进行辅助。在ar场景下的语音辅助作用,主要体现在两处:语音指令检测和语音指令编辑物体。语音指令检测是指,在检测识别上,重点检测图像和视频,语音指令检测用于强调增强辅助信息,如检测到人脸后,语音指令要求显示年龄和性别;语音指令编辑物体,是指在生成ar物体后,语音对ar物体的二维或三维信息进行编辑。
现有技术存在的问题包括:
(1)、缺乏基于声音的ar生成:当前主要是基于现实图像实现增强现实图像,语音只能进行辅助。不能完全基于声音输入生成ar内容,实现听觉信息的ar智能展示。
(2)、被动化的语音触发ar方式:目前ar领域智能语音的应用较为局限,主要在于语音指令检测和语音指令编辑物体。ar生成是被动生成的,需要首先下达语音指令,不能自然而然得主动生成ar内容。
(3)、语音理解范围小:语音指令辅助检测技术只能在视觉检测到图像或视频之后,简单的根据固定名词信息进行调取,不能深入全面进行自然语言理解,并于理解后可视化展示出来。
(4)、声音分析范围局限:除了语音以外,其它人为声音、自然界声音及声源信息,人类凭自己的耳朵无法辨析。目前在ar领域还无法实现对这些声音信息实现展示。
(5)智能化程度低:当前ar设备只能直观处理声音,不能处理后生成机器自己的解析和判断,并把分析结果通过ar展示出来。缺乏运用ai技术帮助人们分析判断声音的智能功能。
(6)、缺少个体差异:目前ar设备针对不同的用户往往生成相同的ar内容,不能实现ar内容的个体差异化。
技术实现要素:
有鉴于此,本发明提供一种基于声音生成ar内容的方法、存储介质和装置,以解决上述至少一个现有ar技术中语音应用的局限问题。
本发明提供一种基于声音生成ar内容的方法,该方法包括
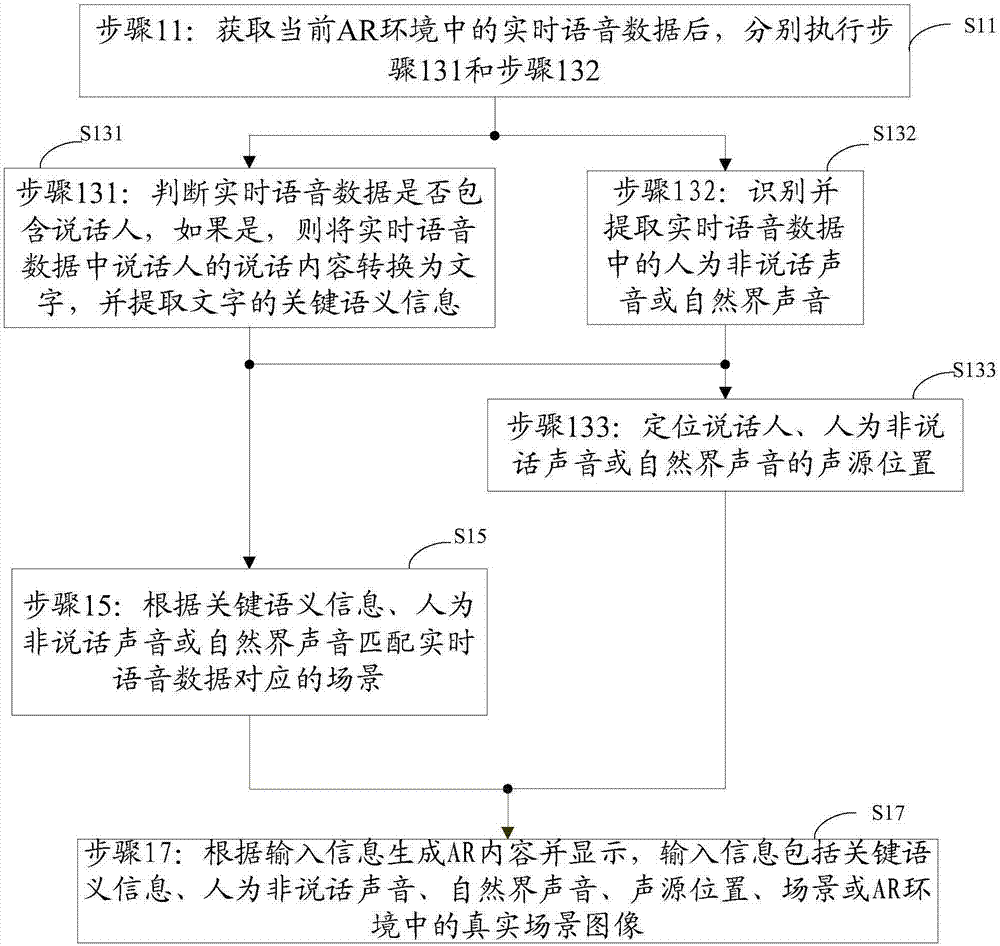
步骤11:获取当前ar环境中的实时语音数据后,分别执行步骤131和步骤132;
步骤131:判断实时语音数据是否包含说话人,如果是,则将实时语音数据中说话人的说话内容转换为文字,并提取文字的关键语义信息;
步骤132:识别并提取实时语音数据中的人为非说话声音或自然界声音;
步骤133:定位说话人、人为非说话声音或自然界声音的声源位置;
步骤15:根据关键语义信息、人为非说话声音或自然界声音匹配实时语音数据对应的场景;
步骤17:根据输入信息生成ar内容并显示,输入信息包括关键语义信息、人为非说话声音、自然界声音、声源位置、场景或ar环境中的真实场景图像。
本发明还提供一种非瞬时计算机可读存储介质,该非瞬时计算机可读存储介质存储指令,指令在由处理器执行时使得处理器执行如上述的基于声音生成ar内容的方法中的步骤。
本发明还提供一种基于声音生成ar内容的装置,包括处理器和上述的非瞬时计算机可读存储介质。
本发明提供了一种更加主动的ar交互方式,可以将语音数据中的内容以ar方式可视化展现出来,智能化地将听觉信息分析判断后转化为ar视觉信息,实现听觉信息的ar智能展示,为用户提供更加便利、智能的服务和体验。
附图说明
图1为本发明方法的流程图;
图2为本发明方法的第1个实施例;
图3为本发明方法的第2个实施例;
图4为本发明方法的第3个实施例;
图5为本发明方法的第4个实施例;
图6为本发明方法的第5个实施例;
图7为本发明方法的第6个实施例;
图8为本发明方法的第7个实施例;
图9为本发明方法的第8个实施例;
图10为本发明方法的第9个实施例;
图11为本发明方法的第10个实施例;
图12为本发明方法的第11个实施例;
图13为本发明方法的第12个实施例;
图14为本发明方法的第13个实施例;
图15为本发明方法的第14个实施例;
图16为本发明方法的第15个实施例;
图17为本发明方法的第16个实施例;
图18为本发明方法的第17个实施例;
图19为本发明方法的第18个实施例;
图20为本发明方法的第19个实施例;
图21为本发明方法的第20个实施例;
图22为本发明方法的第21个实施例;
图23为本发明方法的第22个实施例;
图24为本发明的结构图。
具体实施方式
为了使本发明的目的、技术方案和优点更加清楚,下面结合附图和具体实施例对本发明进行详细描述。
本发明主要涉及到以下技术:
·语音识别技术,也被称为自动语音识别automaticspeechrecognition(asr),其目标是将人类的语音中的词汇内容转换为计算机可读的输入,例如按键、二进制编码或者字符序列。
·自然语言理解,naturallanguageunderstanding俗称人机对话,研究用电子计算机模拟人的语言交际过程,使计算机能理解和运用人类社会的自然语言如汉语、英语等,实现人机之间的自然语言通信,以代替人的部分脑力劳动,包括查询资料、解答问题、摘录文献、汇编资料以及一切有关自然语言信息的加工处理,使计算机具有理解和运用自然语言的功能。
·声纹识别,生物识别技术的一种,也称为说话人识别,包括两类,即说话人辨认和说话人确认。不同的任务和应用会使用不同的声纹识别技术,如缩小刑侦范围时可能需要辨认技术,而银行交易时则需要确认技术。所谓声纹(voiceprint),是用电声学仪器显示的携带言语信息的声波频谱。人类语言的产生是人体语言中枢与发音器官之间一个复杂的生理物理过程,人在讲话时使用的发声器官--舌、牙齿、喉头、肺、鼻腔在尺寸和形态方面每个人的差异很大,所以任何两个人的声纹图谱都有差异。每个人的语音声学特征既有相对稳定性,又有变异性,不是绝对的、一成不变的。这种变异可来自生理、病理、心理、模拟、伪装,也与环境干扰有关。尽管如此,由于每个人的发音器官都不尽相同,因此在一般情况下,人们仍能区别不同的人的声音或判断是否是同一人的声音。
·声源定位,利用环境中的声音确定声源方向和距离。取决于到达麦克风阵列的声音的物理特性变化,包括频率、强度和持续时间上的差别。
基于上述技术,提出本发明的基于声音生成ar内容的方法,如图1所示,包括:
步骤11:获取当前ar环境中的实时语音数据后,分别执行步骤131和步骤132。
需要说明的是,步骤11中的实时语音数据仅针对录音设备(如麦克风)而言,即实时语音数据为录音设备获取的当前语音数据,但是该语音的来源可能是当前ar环境中说话人的说话内容,也可能是ar环境中视频播放设备播放(或回放)的声音。
ar环境中的麦克风可实时记录语音数据,并把记录的语音数据发送给步骤131和步骤132分析。可选地,在ar环境中检测到非静音特征时,自动启动录音,在录音过程再次出现静音特征时,停止录音,停止录音后将录取的最新语音数据发送给步骤131和步骤132分析。
步骤131:判断实时语音数据是否包含说话人,如果是,则将实时语音数据中说话人的说话内容转换为文字,并提取文字的关键语义信息。
需要说明的是,实时语音数据中可能包含多个说话人的信息,则将每个说话人的对应的语音数据均转换为对应的文字,文字与说话人一一对应。
在上述步骤131中,提取文字的关键语义信息包括:
步骤1311:将文字分词;
步骤1312:对分词进行词性和语义角色标注后,提取文字中的关键语义信息,关键语义信息包括关键词和命名实体。
常用的将语音数据转换为文字的工具为隐马尔科夫模型hmm、神经网络模型等。
分词可以采用隐马尔科夫模型hmm或条件随机场crf(conditionalrandomfield),将语音数据转换的文字序列切分为一个个单独的词(也称为单位词),将文字序列转换为的词序列。
词性分类主要包括:基本词性分类:名词n、时间词t、处所词s、方位词f、数词m、量词q、区别词b、代词r、动词v、形容词a、状态词z、副词d、介词p、连词c、助词u、语气词y、叹词e、拟声词o、成语i、习惯用语l、简称j、前接成分h、后接成分k、语素g、非语素字x、标点符号w等一共26类,此外还可以包括了专有名词分类:人名nr、地名ns、机构名称nt、其他专有名词nz等4类;或其他词性分类。
语义角色标注(semanticrolelabeling,srl)是一种浅层的语义分析技术,标注句子中某些短语为给定谓词的论元(语义角色),如施事、受事、时间和地点等,以更好的理解文本。语义角色主要为a0-5六种,a0通常表示动作的施事,a1通常表示动作的影响等,a2-5根据谓语动词不同会有不同的语义含义。其余的15个语义角色为附加语义角色,如loc表示地点,tmp表示时间等。
例如,可以采用hmm或crf对词序列中的词进行词性和语义角色标注,或采用机器学习模型进行词性和语义角色标注,机器学习模型包括循环神经网络语言模型rnnlm(recurrentneuralnetworkbasedlanguagemodel)、连续词袋模型cbow(continuousbag-of-words)、上下文word采样skip-grammodel等。
可以通过关键字提取算法textrank或信息检索与数据挖掘的加权技术tf-idf提取词性和语义角色标注后文字的关键词。
命名实体识别ner(namedentityrecognition),又称作“专名识别”,是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等。可以基于训练好的人工智能模型或神经网络模式识别命名实体。
步骤132:识别并提取实时语音数据中的人为非说话声音或自然界声音。
通过机器学习、监督式学习大量的人为非说话声音和自然界声音样本,训练好的模型用于识别和提取“实时语音数据中的人为非说话声音或自然界声音”。
人为非说话声音包括:人的呼喊声、呼吸声、歌声等,自然界的声音包括:自然界动物的声音和自然气象的声音(如风暴、雷电等)。
步骤133:定位说话人、人为非说话声音或自然界声音的声源位置。
声源定位可采用:基于可控波束的声源定位技术、基于高分辨率谱估计的声源定位技术或基于时延差估计的声源定位技术。
步骤15:根据关键语义信息、人为非说话声音或自然界声音匹配实时语音数据对应的场景。
具体地,步骤15包括:
步骤151:建立场景库,场景库至少包含一个场景;
步骤152:通过聚类算法将场景库中的场景进行分类,分类依据为场景库中的每个场景的关键词信息、所包含的人为非说话声音和自然界声音;
步骤153:将实时语音数据相关的关键语义信息、人为非说话声音或自然界声音与场景库进行匹配,其中匹配度最高的场景为实时语音数据对应的场景。
可选地,步骤153中的匹配算法可采用k最近邻分类算法。
场景库包含的场景举例如下,但不仅限于此,其中表1为说话人对应的场景,表2为人为非说话声音或自然界声音对应的场景。
表1说话人对应的场景
表2人为非说话声音或自然界声音对应的场景
表1中,视频商务会议场景的匹配信息包括:产品名称,商务数据,时间,日期,缩写,讨论阶段性结果;旅游解说场景的匹配信息包括:文物古迹名称,文物古迹年代,文物古迹特征,人民活动;体育赛事场景的匹配信息包括:球员名称,球员号码,球员战绩,进攻路线;运动教学场景的匹配信息包括:身体部位,身体动作,姿势名称;远程教学场景的匹配信息包括:几何形状,几何关系,公式定理,教学结论,文章名称,诗词短语;远程社交聊天场景的匹配信息包括:人物、物体名称,人物、物体运动,感叹词,形容词,拟声词,形象化短语,地点;儿童教育场景的匹配信息包括:故事人物,故事人物活动,故事人物语言,对方对话内容;实战游戏场景的匹配信息包括:人物,地点,任务。
步骤17:根据输入信息生成ar内容并显示,输入信息包括关键语义信息、人为非说话声音、自然界声音、声源位置、场景或ar环境中的真实场景图像。
例如,视频商务会议场景的ar内容包括:产品图片,电子图表,倒数计时时间,缩写全称,百科知识,讨论总结;旅游解说场景的ar内容包括:文物古迹图像,人民生活工作的景象;现场体育解说场景的ar内容包括:放大的目标球员图像,球员信息,进攻情况;远程教学场景的ar内容包括:高亮显示的几何图像,差异化的解析步骤;远程社交聊天场景的ar内容包括:人物或物体的动态图像,卡通趣味贴图,对方的地理位置,距离自己的距离,交通用时,导航指引;实战游戏场景的ar内容包括:虚拟立体地图,用户及队友的定位、距离、相对位置;儿童教育场景的ar内容包括:儿童读物相关的动态图像,百科知识,社交指导;运动教学场景的ar内容包括:高亮显示的身体部位,百科知识,形体标注;声乐教育场景的ar内容包括:身体发声部位标注;紧急救援场景的ar内容包括:被困者与当前位置的距离和角度,以及被困人基本信息;野外生存场景的ar内容包括:自然声源的名称,百科介绍,运动情况,距离用户的位置,应急建议以及导航路线。
步骤17中的输入信息还包括:ar环境中用户的个人数据、ar环境中除麦克风和摄像头之外其他设备获取的数据。例如:ar环境中除麦克风和摄像头之外的设备主要包括:信息储存设备,其它设备获取的数据包括:多种模式下用户的定位信息、实战游戏模式下的战区地图、社交模式下用户平时的生活情况和经验记载、社交模式下用户对话对象信息及对话内容记载、紧急救援模式下事发地住户登记情况(包括住户信息和住户位置)等。
具体地,步骤17包括:
步骤171:根据输入信息匹配ar内容模板,输入信息包括关键语义信息、声源位置、场景或ar环境中的真实场景图像,ar内容模板包括:文字、图表、图像、3d模型或视频。
例如:例如通过声源位置,结合当前采集到的真实场景图像、ar环境中其他设备获取的数据,得到精确的所在位置。每个ar内容模板都对应了一种情境并与多个位置相关联,匹配时首先考虑场景对应的多个ar内容模板,再根据位置选择最为接近的ar内容模板。
步骤172:将输入信息输入最匹配的ar内容模板,生成ar内容并显示。
ar内容模板类似预先制作的模块,将关键信息(输入信息)留空,将输入信息输入最匹配的ar内容模板后,就能生成与实时语音数据相关的ar内容。
可选地,步骤171还包括:如果最匹配的ar内容模板与输入信息的匹配度低于预设值,则在ar内容模板之外根据输入信息搜索匹配内容,将匹配内容反馈给用户。
例如:在搜索引擎上搜索与输入信息相关的内容,将相关内容反馈用户后,用户会选择最相关的内容和关键语义信息一起加入当前场景对应的ar内容模板中。
如果实时语音数据中包含多项关键信息,则按照识别顺序先后显示相应的ar内容。
可选地,在步骤17之后还包括:
步骤19:根据用户指令对显示的ar内容进行修改、调整。
例如,用户可以通过手势,控制器,语音控制等方式对显示的ar内容进行修改,如修改ar内容显示的位置,大小等。同时,若生成的内容为图像,视频,还可以对图像进行缩放,旋转等几何操作,或通过手势,语音指令等方式修改显示的内容,若显示的内容为3d模型,则还可以播放模型对应的骨骼动画等。
下面给出本申请方法的应用举例。
实施例一:视频商务会议
场景的识别结果为视频会议,获取视频会议中输入的语音,运用自然语言理解技术,分析名词、图表、时间、缩写及其它语义信息,然后运用匹配ar内容,采用智能运算、电子图表自动生成、文本摘要等技术进一步处理,最后生成如图2-图5所示的ar内容,展示给用户。
图2中主要涉及图表:视频会议中语音谈及数据及总量,如总销售量是多少,a\b\c各销售量是多少。运用nlp技术分析语音,智能运算后,运用电子图表自动生成技术,以ar方式智能生成电子图表,用户发出保存指令后还可以保存该电子图表。
图3主要涉及时间:当视频会议中用户谈及某月某日是截止日期。运用nlp技术分析日期相关语音信息,智能运算,计算截至日期到现在的剩余时间,以ar内容方式展示剩余时间。
图4主要涉及缩写注解:当视频会议中用户谈及某些较为偏僻的缩写,运用nlp技术分析语音信息,运用智能搜索技术搜索全称注解,并以ar内容方式进行展示。
图5主要涉及讨论结论:视频会议中多方共同探讨,运用nlp技术语音分析多人讨论内容,然后运用文本摘要技术,生成本次会议的讨论结论,并以ar内容方式进行展示。
实施例二:旅游解说
场景为旅游解说,获取导游解说时输入的不同语音,运用自然语言理解技术分析语义信息,然后运用图像识别技术,实时生成旅游景点导游的语音内容相关的ar图像。
图6主要涉及文物介绍:当导游语音谈及历史文物随时代变迁的演变时,运用nlp技术智能分析语音内容,然后运用图像识别技术,以ar内容方式在原文物图像上叠加文物变换的图像。
图7主要涉及古迹介绍:当导游语音介绍古迹及古时此地劳动人民的生活劳作时,运用nlp技术智能分析语音,然后运用图像识别技术,在原古迹图像上叠加古代人民生活及劳作的画面,并以ar内容方式展现出来。
实施例三:体育解说
场景识别结果为现场体育比赛,解说员语音解说比赛情况,如拿球者名称、号码、战绩、进攻路线等。运用nlp技术智能分析解说员语音,并结合人脸识别技术和智能搜索技术,对目标球员放大画面,如图8所示,ar显示解说内容及球员百科信息。
实施例四:远程教学及培训
图9主要涉及几何图像注释:场景识别结果为远程教学,老师语音讲解几何习题,提及某些特定的几何形状。运用nlp技术智能分析语音,再根据图像识别技术,以ar内容方式在原几何图像上高亮显示几何边或几何形状,并显示标注,帮助同学快速理解老师的几何讲解。
图10和图11主要涉及差异化解析:场景识别结果为远程教学,老师语音谈及某教学结论。运用nlp技术智能分析语音,再根据图像识别技术、智能搜索技术和用户识别技术,基于用户个人数据,例如成绩或错题情况,针对不同资质的学生,和知识点掌握的差异,ar生成详略不同、或侧重点不同的解析步骤。
实施例五:远程社交聊天
语音实时操控ar物体:场景识别结果为远程社交聊天,当语音提及某物体及其动态情况,运用nlp技术智能分析语音,实时生成语音中的ar物体,然后运用语音操控技术,根据语音实时操控ar图像动态展示。如图12所示,场景识别结果为客服,客服远程视频通过语音向用户解释设备如何安装设置,并且通过语音实时操控ar内容演示设备组装。
图13主要涉及动态ar贴图:场景识别结果为远程社交聊天,当语音谈及某感叹词(啊!哈哈哈!我的天啊!)、形容词(好可爱)、拟声词(汪汪)形象化短词(走开啦)等,运用nlp技术智能解析语音,再结合图像识别技术,以卡通可爱的方式图像化语言内容,实时生成动态的ar趣味贴图内容,增加视频聊天的趣味性和生动性。
图14主要涉及车内ar地图展示:场景识别为车内远程社交聊天,当对方语音说出自己的地理位置,运用nlp技术智能解析语音,结合用户自身定位信息,运用智能导航和图像识别技术,在车内的ar设备上文字显示对方语音提及的地理位置,距自己的距离、交通用时,并且ar图像化显示路面导航指引。
实施例六:实战游戏
图15主要涉及游戏增强助手:场景识别结果为多人实战游戏,当队友语音说出自己的位置,运用nlp技术智能解析语音,结合用户自身的定位信息和战区地图信息,运用智能导航技术和虚拟三维技术,在ar设备上智能生成虚拟立体地图及两人定位,可视化用户和队友的距离和相对位置,丰富ar应用中人与游戏的交互性。
实施例七:儿童教育
图16主要涉及ar儿童故事:场景识别结果为儿童读物模式,父母给孩子语音讲故事,运用nlp技术智能分析语音,根据语义分析在ar设备上生成生动的故事图像。使儿童在父母讲故事时,配合父母的声音,获得丰富而又有乐趣的视觉体验,对听觉体验进行补充。
图17主要涉及社交障碍指导:基于用户的个人数据,针对自闭或有社交障碍的孩子,场景识别结果为社交障碍指导模式,对方语音和用户沟通,运用nlp技术智能分析对方的语音,结合平时机器学习到的用户自身生活情况以及对方的身份信息,运用智能搜索、机器学习、知识图谱、人脸识别等技术,生成一些特定的提供给该用户的社交指导,并以ar方式展示出来。
实施例七:远程运动教学
图18主要涉及形体标注:场景识别结果为运动教学,健身教练语音解释身体发力部位或身体姿势技巧,运用nlp技术智能解析语音,然后运用图像识别、人体识别、智能搜索技术,在教练语音中提及的身体部位实现高亮,或者ar内容展示其它语音提及的运动相关信息。辅助教练语音教学,使用户对教练的语音有更好的视觉补充理解。
实施例八:声乐教育
图19主要涉及发声部位分析:场景为声乐教育,ar设备获取歌唱老师的唱歌声音,运用声源识别技术智能解析声音,得出声音是从人身体的哪个部位发出,是胸腔发音还是鼻腔发音等等,并通过ar图像展示出来,便于用户更好地体验学习歌唱的发声技巧。
实施例十:紧急救援
图20主要涉及被困者声源分析:场景为紧急救援,地震废墟下面被压者发出喊叫声、心跳声、呼吸声、挪动声,智能分析声音来源及声源定位。同时结合事发地住户登记情况和用户位置,运用声纹分析技术、智能导航技术,智能生成废墟下被困者与当前位置的距离和角度,以及被困人基本信息。
实施例十一:野外生存
图21主要涉及大自然非生物声源分析:场景为野外生存,ar设备接收到大自然的非生物自然声,如水流、飓风、雷鸣、雪崩、泥石流等声音,ar设备智能解析声源及生源定位。结合用户自身定位,运用智能搜索、智能导航技术,以ar内容方式生成自然声源的名称、百科介绍、距离用户的位置、应急建议以及导航路线。
图22和图23主要涉及大自然生物声源分析:场景为野外生存,ar设备接收到生物发出的声音,如生物叫声、生物运动发出的声音等,智能解析声源物及声源定位。结合用户自身定位,运用智能搜索、智能导航技术,以ar内容方式生成生物的名称、百科介绍、运动情况、距离用户的位置、应急建议以及导航路线。
以上为本发明方法的应用举例
本发明基于声音生成ar内容的方法公开了一种通过输入声音,ar设备智能解析声音并主动创建可编辑ar内容的交互方法。将声音信息中的内容以ar方式可视化展现出来,智能化地将听觉信息分析判断后转化为ar视觉信息,在ar领域实现了听觉信息的智能化展示。
具体实现的效果包括:
(1)、基于声音输入的崭新ar交互方式:ar的生成激发物完全为输入的声音信息,不再局限在摄像头和传感器采集真实场景的视频或者图像。在ar领域实现了机器听觉,即听觉信息的ar智能展示。
(2)、自然主动的ar生成:无需人下达语音指令,无需语音之前输入固定唤醒词,自然而然得生成ar内容,ar生成变被动为主动,交互更加自然。
(3)、全面的语义分析:不是简单的语音指令辅助检测或语音指令编辑物体,而是深入全面解析用户说话的语义内容,并将其可视化ar展现出来,使用户对语音信息实现视觉的补充理解,帮助人们更直观自然地理解语音,更精确,更有趣味。
(4)、全面的声音分析:不仅可以分析语音,还可以分析其它人为声音、自然界声音及声源信息,帮助用户掌握自身耳朵无法辨析的声音信息。
(5)智能分析判断:基于声音处理的结果和情境识别的结果,运用ai技术,结合摄像头和传感器采集的真实场景图像、用户的个人数据和第三方设备数据等场景信息,生成对用户有用的智能分析结果,帮助用户进行理解和思考,在ar领域使声音实现了智能化。
(6)、实现了个体差异:本发明可以针对个体差异,差别化解析声音。
本发明还提供一种非瞬时计算机可读存储介质,该非瞬时计算机可读存储介质存储指令,指令在由处理器执行时使得处理器执行如上述的基于声音生成ar内容的方法中的步骤。
本发明还提供一种基于声音生成ar内容的装置,包括处理器和上述的非瞬时计算机可读存储介质。
如图24所示,本发明的基于声音生成ar内容的装置,包括:
语音获取模块:获取当前ar环境中的实时语音数据后,分别执行语音处理模块1和语音处理模块2;
语音处理模块1:判断实时语音数据是否包含说话人,如果是,则将实时语音数据中说话人的说话内容转换为文字,并提取文字的关键语义信息;
语音处理模块2:识别并提取实时语音数据中的人为非说话声音或自然界声音;
语音处理模块3:定位说话人、人为非说话声音或自然界声音的声源位置;
场景识别模块:根据关键语义信息、人为非说话声音或自然界声音匹配实时语音数据对应的场景;
ar内容生成模块:根据输入信息生成ar内容并显示,输入信息包括关键语义信息、声源位置、场景或ar环境中的真实场景图像。
可选地,场景识别模块包括:
场景库构建模块:建立场景库,场景库至少包含一个场景;
场景分类模块:通过聚类算法将场景库中的场景进行分类,分类依据为场景库中的每个场景的关键词信息、所包含的人为非说话声音和自然界声音;
场景匹配模块:将实时语音数据相关的关键语义信息、人为非说话声音或自然界声音与场景库进行匹配,其中匹配度最高的场景为实时语音数据对应的场景。
可选地,在场景匹配模块中,匹配算法为k最近邻分类算法。
可选地,ar内容生成模块中,输入信息还包括:ar环境中用户的个人数据、ar环境中除麦克风和摄像头之外其他设备获取的数据。
可选地,ar内容生成模块包括:
ar内容模板定位模块:根据输入信息匹配ar内容模板,输入信息包括关键语义信息、人为非说话声音、自然界声音、声源位置、场景或ar环境中的真实场景图像,ar内容模板包括:文字、图表、图像、3d模型或视频;
ar内容更新模块:将输入信息输入最匹配的ar内容模板,生成ar内容并显示。
可选地,ar内容模板定位模块还包括:如果最匹配的ar内容模板与输入信息的匹配度低于预设值,则在ar内容模板之外根据输入信息搜索匹配内容,将匹配内容反馈给用户。
可选地,语音处理模块1中,提取文字的关键语义信息包括:
分词模块:将文字分词;
关键信息提取模块:对分词进行词性和语义角色标注后,提取文字中的关键语义信息,关键语义信息包括关键词和命名实体。
可选地:ar内容生成模块之后还包括:
步骤19:根据用户指令对显示的ar内容进行修改、调整。
需要说明的是,本发明的基于声音生成ar内容的装置的实施例,与基于声音生成ar内容的方法的实施例原理相同,相关之处可以互相参照。
以上所述仅为本发明的较佳实施例而已,并不用以限定本发明的包含范围,凡在本发明技术方案的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!