一种提高生物雷达语音质量的语音增强方法与流程
本发明属于生命参数探测与获取领域,特别涉及一种基于高阶累积量的雷达语音降噪方法。
背景技术:
传统麦克风获取语音的方法几乎是目前为止唯一的一种语音获取方法,其采用的传统谱减法增强后的语音语和采用小波去噪方法增强后的语音,存在着显而易见的缺点,参照图3、图4所示,方向性差,极易受环境噪声和其它声学噪声的干扰,检测距离近等。
采用毫米波生物雷达,能够在较远距离探测到语音信号,与麦克风语音相比,这种语音探测方法存在着探测距离远,方向性强,抗声学噪声干扰能力强,具有一定的穿透性等诸多优点,由于这种方法能够有效弥补麦克风语音的不足,因此有望作为麦克风的替代产品而具有广阔的应用前景。
采用生物雷达探测语音具有明显的优势,但所探测到的语音存在着新的特点,参照图2所示:雷达语音不受声学干扰的影响,但其语音信号中引入了新的噪声和干扰成分,一是存在雷达波的电磁噪声;二是在语音信号采集过程中引入的电路电子噪声;三是外界环境中由于物体微动,振动和共振所引发的外界环境的微动噪声,这些噪声的引入降低了雷达语音的质量和可懂度,为这种新的语音获取方法走向实际应用带来了新的课题。
生物雷达所获取的语音中的电磁噪声,电路噪声和外界环境噪声大部分是高斯型白噪声,也存在少部分的有色噪声,针对这类噪声的特性,本发明专利提出一种基于高阶累积量的雷达语音降噪新方法。相比二阶统计量,高阶统计量的相位信息量更为丰富,能够有效保留信号的相位信息及非高斯信号的各种特征信息,同时对于阶数大于二的高斯信号的高阶累积量谱均为零,这些优良特性可以用于有针对性地抑制高斯型白噪声和有色噪声,实现对雷达语音的有效增强,使得生物雷达探测语音这一手段能够适用于更复杂的声学背景和更远距离的语音探测。
技术实现要素:
为了克服上述现有技术的不足,本发明的目的在于提供一种提高生物雷达语音质量的语音增强方法,能够有针对性地抑制雷达语音中的高斯型白噪声和有色噪声,实现对雷达语音的有效增强。
为达到上述目的,本发明采用的技术方案是:
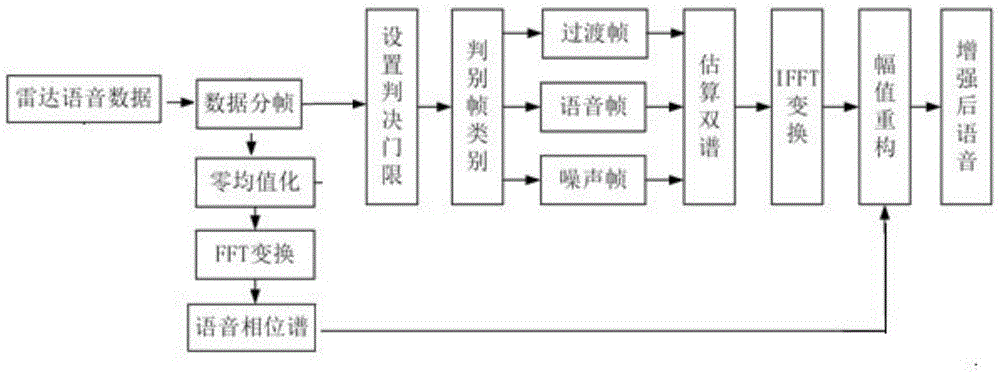
一种提高生物雷达语音质量的语音增强方法,包括以下步骤:
步骤一:获取雷达语音数据:
令{x(1),x(2)……x(n)}为一组雷达语音的观测样本值,将观测样本值分成k帧,每帧含m个样本点;
步骤二:零均值化:
将步骤一中得到第i帧数据xi(n)减去其均值
步骤三:将步骤二得到的零均值信号帧yi(n),进行fft变换,得到带噪语音的相位谱φi(ω);
步骤四:通过设置判决门限将步骤一得到的观测样本值的每帧分为语音帧、噪声帧和过渡帧三类;所述的语音帧对应语音数据的发音段,噪声帧对应静默段,过渡帧则是处于发音段与静默段交界处的分帧;噪声帧的结构性不强,呈现随机波动,其幅值服从高斯分布;
步骤五:根据步骤四中的语音帧、噪声帧和过渡帧,分别估算每帧的双谱;
步骤六:将步骤五中得到的每帧的双谱采用最小二乘法对每帧信号的n点dft系数进行幅值重构;
步骤七:利用步骤六计算所得的每帧信号的重构幅值谱xi(ω)联合步骤三中的相位谱φi(ω)进行fft逆变换,合成语音信号,得到增强后语音。
进一步的,所述的步骤四中的通过设置判决门限对观测样本值的每帧的判别方法为:
1)假设雷达语音的观测样本值的的前十帧均为噪声,根据前十帧对数斜度的均值mγ与标准差sγ设置判决门限:threshold=mγ+ρ·sγ(1)
其中:
ρ为常数,此处设ρ=2.3;
2)提取每一帧数据yi(n)的对数斜度10·log10|γi|,其中
γi=c3(0,0)=e{yi*(n)y(n)y(n)}(4)
3)根据上述计算出的门限threshold,进行帧类型的判别:
a若该帧的对数斜度10·log10|γi|<threshold,则为噪声帧;
b若10·log10|γi|≥threshold,但前或后一帧有一个满足10·log10|γk|<threshold,k=i-1,i+1,则为过度帧;
c若10·log10|γi|≥threshold,10·log10|γi+1|≥threshold,10·log10|γi-1|≥threshold同时满足,则为语音帧。
进一步的,所述的步骤五中的估算每帧信号双谱的方法如下:
(1)设{x(i)(k),k=0,1,2...,m-1}为第{i}帧语音数据,计算第{i}帧的dft系数:
(2)通过dft系数估算第{i}帧信号的双谱:
(3)根据第{i}帧的特点,判别帧的类型,分别估算双谱:
a语音帧:
其双谱估计可通过与前后帧的加权平均计算:
其中,加权系数满足2a+b=1,b≥a。
b过渡帧:
过渡帧不需要进行平均计算,直接取该帧的估算值
c噪声帧:
其中,系数c为常数,且c<0.01。
进一步的,所述的步骤六中采用最小二乘法对每帧信号的n点dft系数进行幅值重构的方法如下:
设x(k)和b(k,l)=b((2π/n)k,(2π/n)l),分别为x(n)的n点dft系数及双
谱,由双谱的定义可知:
|b(k,l)|=|x(k)||x(l)||x(k+l)|(10)
因此
可表示为
其中
是所有频率点对应的双谱样本值形成的(n2/16)×1维向量,
是一个(n/2)×1维向量,
为一个(n2/16)×(n/2)维矩阵,该矩阵是满秩可逆的,因此可得
在解出
和
求出。
本发明的有益效果是:
本发明针对雷达语音中的噪声特性,利用高阶累积量对于阶数大于二的高斯信号的高阶累积量谱均为零,且能够有效保留信号的相位信息及非高斯信号的各种特征信息这些优良特性,有针对性地抑制高斯型白噪声和有色噪声,实现对雷达语音的有效增强,从而不仅为雷达语音的增强提供一种有针对性的新方法,同时也能够在较大程度上拓展雷达语音获取方法的应用领域和前景。
本发明具有的低频分量感知能量不足,且易受环境噪声干扰,方向性弱等缺陷,利用生物雷达所具有的低频分量感知能力强,高灵敏度,高方向性,高抗声学干扰能力等特性,能够提升获取语音信号的质量,拓展传统语音信号检测能力,从而在更复杂的声学背景和更远的距离条件下获得更高质量的语音信号。
附图说明
图1是本发明的算法框图。
图2是原始语音语谱图。
图3是采用传统普减法增强后的语音语谱图
图4是采用小波去噪方法增强后的语音语谱图。
图5是采用高阶累积量方法增强后的语音语谱图。
具体实施方式
下面结合附图对本发明作进一步详细说明。
参见图1所示,本发明基于高阶累积量的雷达语音增强方法的基本原理为:将零均值化的雷达语音信号通过设置判决门限将其分为过渡帧帧、语音帧和噪声帧三类,针对不同的语音帧类型估算其双谱,再通过采用最小二乘法对各帧信号的dft系数进行幅值重构,再联合原始信号的相位谱对语音信号进行重构。
一种提高生物雷达语音质量的语音增强方法,包括以下步骤:
步骤一:获取雷达语音数据:
令{x(1),x(2)……x(n)}为一组雷达语音的观测样本值,将观测样本值分成k帧,每帧含m个样本点;
步骤二:零均值化:
将步骤一中得到第i帧数据xi(n)减去其均值
步骤三:将步骤二得到的零均值信号帧yi(n),进行fft变换,得到带噪语音的相位谱φi(ω);
步骤四:通过设置判决门限将步骤一得到的观测样本值的每帧分为语音帧、噪声帧和过渡帧三类;所述的语音帧对应语音数据的发音段,噪声帧对应静默段,过渡帧则是处于发音段与静默段交界处的分帧;噪声帧的结构性不强,呈现随机波动,其幅值服从高斯分布;
所述通过设置判决门限对观测样本值的每帧的判别方法为:
1)假设雷达语音的观测样本值的的前十帧均为噪声,根据前十帧对数斜度的均值mγ与标准差sγ设置判决门限:threshold=mγ+ρ·sγ(1)
其中:
ρ为常数,此处设ρ=2.3;
2)提取每一帧数据yi(n)的对数斜度10·log10|γi|,其中
3)根据上述计算出的门限threshold,进行帧类型的判别:
a若该帧的对数斜度10·log10|γi|<threshold,则为噪声帧;
b若10·log10|γi|≥threshold,但前或后一帧有一个满足10·log10|γk|<threshold,k=i-1,i+1,则为过度帧;
c若10·log10|γi|≥threshold,10·log10|γi+1|≥threshold,10·log10|γi-1|≥threshold同时满足,则为语音帧。
步骤五:根据步骤四中的语音帧、噪声帧和过渡帧,分别估算每帧的双谱;
所述的步骤五中的估算每帧信号双谱的方法如下:
(1)设{x(i)(k),k=0,1,2...,m-1}为第{i}帧语音数据,计算第{i}帧的dft系数:
(2)通过dft系数估算第{i}帧信号的双谱:
(3)根据第{i}帧的特点,判别帧的类型,分别估算双谱:
a语音帧:
其双谱估计可通过与前后帧的加权平均计算:
其中,加权系数满足2a+b=1,b≥a。
b过渡帧:
过渡帧不需要进行平均计算,直接取该帧的估算值
c噪声帧:
其中,系数c为常数,且c<0.01。
步骤六:将步骤五中得到的每帧的双谱采用最小二乘法对每帧信号的n点dft系数进行幅值重构;
所述的步骤六中采用最小二乘法对每帧信号的n点dft系数进行幅值重构的方法如下:
设x(k)和b(k,l)=b((2π/n)k,(2π/n)l),分别为x(n)的n点dft系数及双
谱,由双谱的定义可知:
|b(k,l)|=|x(k)||x(l)||x(k+l)|(10)
因此
可表示为
其中
是所有频率点对应的双谱样本值形成的(n2/16)×1维向量,
是一个(n/2)×1维向量,
为一个(n2/16)×(n/2)维矩阵,该矩阵是满秩可逆的,因此可得
在解出
和
求出。
步骤七:利用步骤六计算所得的每帧信号的重构幅值谱xi(ω)联合步骤三中的相位谱φi(ω)进行fft逆变换,合成语音信号,得到增强后语音,参照图5所示,弥漫于原始语音信号中的噪音信号已经被有效去除,而原始雷达语音中的有效分量则仍然保留完好。这主要是由于本算法利用了高阶累积量对于阶数大于二的高斯信号的高阶累积量谱均为零这样的优良特性,在基于双谱对每帧信号进行幅值重构时能够有针对性地抑制高斯型白噪声和有色噪声,本算法还能够在语音增强的同时有效保留信号的相位信息及非高斯信号的各种特征信息,从而达到有针对性地对雷达语音实施有效增强的目的,从而大大提高了雷达语音的可懂度。
- 还没有人留言评论。精彩留言会获得点赞!