声音内容控制装置、声音内容控制方法以及存储介质与流程
本发明涉及声音内容控制装置、声音内容控制方法以及存储介质。
背景技术:
例如,如专利文献1所示,提出了分析检测出的用户的声音并进行与用户的意图对应的处理的声音控制装置。另外,还提出了以下的声音控制装置:通过声音输出进行了用户希望的处理,或者通过声音输出用户的询问内容。
【在先技术文献】
专利文献
专利文献1:日本特公平7-109560号公报。
技术实现要素:
但是,在使用输出声音的声音处理装置的情况下,存在位于用户以外的周围的人也能听到该声音的情况。例如,在周围的人睡觉时,该声音有可能成为麻烦。在这样的情况下,也可以减小要输出的声音本身,但如果过小,则用户自身也难以听到该声音,有可能无法理解内容。因此,在向用户输出声音的情况下,要求在抑制对用户以外的影响的同时,能够适当地理解向用户输出的声音的内容。
本发明鉴于上述课题,目的在于提供一种以下的声音内容控制装置、声音内容控制方法以及存储介质:在向用户输出声音的情况下,抑制对用户以外的人的影响的同时,能够适当地理解向用户输出的声音的内容。
本发明的一个方式涉及的声音内容控制装置,包括:声音获取部,获取用户发出的声音;声音分类部,对由所述声音获取部获取的声音进行分析,将所述声音分类为第一声音和第二声音中的某一个;处理执行部,对由所述声音获取部获取的声音进行分析,并执行所述用户请求的处理;以及声音内容生成部,基于所述处理执行部执行的处理内容来生成输出文章,所述输出文章是向所述用户输出的声音用的文章数据,当被分类为所述第一声音时,所述声音内容生成部生成第一输出文章作为所述输出文章,当被分类为所述第二声音时,所述声音内容生成部生成第二输出文章作为所述输出文章,所述第二输出文章与所述第一输出文章相比省略了信息。
本发明的一实施方式涉及的声音内容控制方法,包括:声音获取步骤,获取用户发出的声音;声音分类步骤,对在所述声音获取步骤中获取的声音进行分析,将所述声音分类为第一声音和第二声音中的某一个;处理执行步骤,对在所述声音获取步骤中获取的声音进行分析,并执行所述用户希望的处理;以及声音内容生成步骤,基于在所述处理执行步骤中执行的处理内容,来生成输出文章,所述输出文章是向所述用户输出的声音用的文章数据,在所述声音内容生成步骤中,当被分类为所述第一声音时,生成第一输出文章作为所述输出文章,当被分类为所述第二声音时,生成第二输出文章作为所述输出文章,所述第二输出文章省略了包含在所述第一输出文章中的信息的一部分。
本发明的一个方式涉及的存储介质存储有声音内容控制程序,该声音内容控制程序使计算机执行以下步骤:声音获取步骤,获取用户发出的声音;声音分类步骤,对在所述声音获取步骤中获取的声音进行分析,将所述声音分类为第一声音和第二声音中的某一个;处理执行步骤,对在所述声音获取步骤中获取的声音进行分析,并执行所述用户希望的处理;以及声音内容生成步骤,基于在所述处理执行步骤中执行的处理内容,来生成输出文章,所述输出文章是向所述用户输出的声音用的文章数据,在所述声音内容生成步骤中,当被分类为所述第一声音时,生成第一输出文章作为所述输出文章,当被分类为所述第二声音时,生成第二输出文章作为所述输出文章,所述第二输出文章省略了包含在所述第一输出文章中的信息的一部分。
根据本发明,在向用户输出声音的情况下,能够抑制对用户以外的人的影响,并且能够适当地理解向用户输出的声音的内容。
附图说明
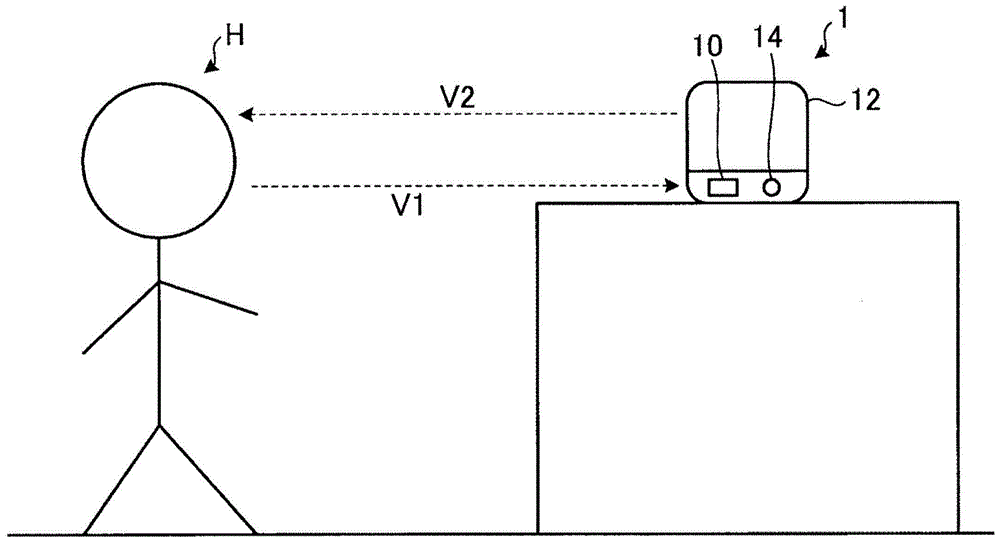
图1是第一实施方式涉及的声音内容控制装置的示意图。
图2是第一实施方式涉及的声音内容控制装置的示意框图。
图3是说明属性信息的一例的表。
图4是用于说明获取信息的表。
图5是表示第一实施方式的输出文章的输出处理的流程的流程图。
图6是表示输出文章的输出处理的流程的另一例的流程图。
图7是第二实施方式涉及的声音处理系统的示意性框图。
具体实施方式
以下,基于附图对本发明的实施方式进行详细说明。另外,本发明并不是通过以下说明的实施方式来限定本发明。
(第一实施方式)
首先,对第一实施方式进行说明。图1是第一实施方式涉及的声音内容控制装置的示意图。如图1所示,第一实施方式涉及的声音内容控制装置1通过声音检测部10检测用户h发出的声音v1,对检测出的声音v1进行分析并进行规定的处理,通过声音输出部12输出声音v2。这里,声音v2向用户h输出,但在声音内容控制装置1的周围有其他人的情况下,也存在到达其他人的情况。在该人睡觉时等,声音v2有可能打扰其他人。本实施方式涉及的声音内容控制装置1分析声音v1,调整作为声音v2输出的文章,由此,能够抑制声音v2对用户h以外的人的影响,用户h能够适当地理解声音v2的内容。
图2是第一实施方式涉及的声音内容控制装置的示意框图。如图2所示,声音内容控制装置1具有声音检测部10、声音输出部12、点亮部14、控制部16、通信部18和存储部20。声音内容控制装置1是所谓的智能扬声器(ai扬声器),但只要是发挥后述的功能的装置,就不限于此。声音内容控制装置1例如也可以是智能手机或平板电脑等。
声音检测部10是麦克风,检测用户h发出的声音v1。用户h向声音检测部10发出声音v1,以包含希望声音内容控制装置1执行的处理内容的信息。另外,声音检测部10也可以说是接受来自外部的信息的输入部,输入部也可以设置在声音检测部10以外,例如,也可以设置通过用户h的操作来调整声音v2的音量的开关等。声音输出部12是扬声器,将控制部16生成的文章(后述的输出文章)作为声音v2输出。点亮部14例如是led(发光二极管)等光源,通过控制部16的控制而点亮。通信部18是例如wi-fi(注册商标)模块、天线等与外部服务器等进行通信的机构,通过控制部16的控制,与未图示外部服务器进行信息的发送接收。通信部18通过wi-fi等无线通信与外部服务器进行信息的发送接收,但也可以通过与电缆等连接来通过有线通信与外部服务器进行信息的发送接收。存储部20是存储控制部16的运算内容、程序的信息等的存储器,并且例如包括ram(随机存取存储器)、rom(只读存储器)和闪存(闪速存储器)等外部存储装置中的至少一个。
控制部16是运算装置、即cpu(中央处理单元)。控制部16具有声音获取部30、声音分析部32、处理执行部34、声音内容生成部36、声音分类部38和输出控制部40。声音获取部30、声音分析部32、处理执行部34、声音内容生成部36、声音分类部38、输出控制部40通过读出存储在存储部20中的软件(程序),来执行后述的处理。
声音获取部30获取声音检测部10检测出的声音v1。声音分析部32执行声音获取部30获取的声音v1的声音分析,将声音v1变换为文本数据。文本数据是包含作为声音v1发出的文章的文字数据(文本数据)。声音分析部32例如从声音v1中检测基于每个时间的振幅或波长等的声音波形。然后,声音分析部32根据存储了声音波形和字符之间的关系的表,将每个时间的声音波形分别置换为字符,由此,将声音v1变换为文本数据。但是,声音分析部32只要能够将声音v1变换为文本数据,则变换的方法是任意的。
处理执行部34基于声音分析部32生成的文本数据,检测声音v1中包含的、希望声音内容控制装置1执行的处理内容的信息,并执行该处理。处理执行部34包括意图分析部50和处理部52。
意图分析部50获取由声音分析部32生成的文本数据,基于文本数据提取意图信息i,并基于意图信息i提取属性信息e。意图信息i是表示用户h的意图的信息,即意向。属性信息e是与意图信息i相关联的信息,并且是表示在执行用户h希望的处理时所需的条件的信息。也就是说,属性信息e是实体。
首先,对意图信息i的提取处理进行说明。意图信息i即意向,换言之,是表示用户h希望在声音内容控制装置1进行怎样的处理的信息。换言之,意图信息i是用户h对声音内容控制装置1请求进行怎样的处理的信息。意图分析部50例如使用自然语言处理,从文本数据中提取意图信息i。在本实施方式中,意图分析部50根据存储在存储部20中的多个训练数据,从文本数据中提取意图信息i。这里的训练数据是对文本数据预先设定了意图信息i的数据。即,意图分析部50提取与声音分析部32生成的文本数据类似的训练数据,将该训练数据的意图信息i设为声音分析部32生成的文本数据的意图信息i。另外,训练数据也可以不存储在存储部20中,意图分析部50也可以控制通信部18从外部服务器提取训练数据。另外,只要意图分析部50从文本数据中提取意图信息i即可,意图信息i的提取方法是任意的。例如,意图分析部50也可以读出存储在存储部20中关键字和意图信息i间的关系表,在文本数据中包含关系表中的关键字的情况下,提取与该关键字关联的意图信息i。
例如,如果文本数据是文章“今天的天气是”,则意图分析部50执行如上所述的分析,并识别为向用户h通知天气的信息是用户h请求的处理的信息、即意图信息i。另外,意图分析部50例如在文本数据是“点亮照明灯”这样的文章的情况下,进行上述那样的分析,并识别为接通照明灯的电源这样的处理识别是用户h请求的处理的信息、即意图信息i。这样,意图信息i被分类为通知所请求的信息的意思的信息和如请求那样控制设备的意思的信息。
另外,基于文本数据的意图信息i的提取方法不限于此,可以是任意的。例如,声音内容控制装置1也可以预先将关键字和意图信息i的关系表存储在存储部20中,在用户h发出的声音v1的文本数据包含该关键字的情况下,检测与该关键字相关联的意图信息i。这种情况的示例包括将关键字“您好”与天气信息和新闻信息相关联。在这种情况下,当用户h发出“您好”的声音v1时,意图分析部50检测天气信息和新闻信息作为意图信息i。
接下来,对属性信息e进行说明。图3是说明属性信息的一例的表。属性信息e,即实体是在执行被提取为意图信息i的、用户h所请求的处理时所需要的条件,即参数。例如,当意图信息i是天气信息时,属性信息e包括指示是哪里的天气预报的位置的信息和指示是什么时候的天气预报的日期和时间的信息。进一步说,如图3所示,属性信息e包含属性参数e0和属性内容e1的信息。属性参数e0是表示参数的种类、即是怎样的条件的信息,属性内容e1是指该属性参数e0的内容。即,在属性信息e是场所的信息的情况下,属性参数e0是表示条件是场所的信息,属性内容e1是表示场所是东京的信息。另外,在属性信息e是日期时间的信息的情况下,属性参数e0是表示条件是日期时间的信息,属性内容e1是表示日期时间是x年y月z日的信息。
在本实施例中,意图分析部50基于提取的意图信息i提取属性信息e。更具体地,意图分析部50从提取的意图信息i中选择并提取属性参数e0。意图分析部50读出存储在存储部20中意图信息i与属性参数e0间的关系表,并从关系表中检测与提取出的意图信息i一致的意图信息i。然后,意图分析部50提取与一致的意图信息i相关联的属性参数e0。但是,意图分析部50也可以经由通信部18与外部服务器进行通信,从外部服务器获取关系表。
意图分析部50在提取出属性参数e0后,对每个属性参数e0设定属性内容e1。意图分析部50例如从由声音分析部32生成的文本数据中提取属性内容e1。即,如果文本数据中包含“今天”这样的关键词,则将日期时间的属性参数e0的属性内容e1设定为今日。另外,意图分析部50也可以预先设定针对属性参数e0的属性内容e1。例如,如果意图信息i是天气信息,则在存储部20预先存储表示场所的属性内容e1是“东京”这样的设置数据。这样,即使在文本数据中不包含表示场所的关键字的情况下,意图分析部50也能够将场所的属性内容e1设定为“东京”。另外,意图分析部50也可以通过通信部18与外部服务器进行通信来设定属性内容e1。此时,例如,意图分析部50通过gps(位置信息定位系统)等的通信获取当前的场所,将其设定为属性内容e1。
意图分析部50如上所述提取意图信息i和属性信息e,但是意图信息i和属性信息e的提取方法不限于上述,可以是任意方法。另外,图3是天气信息为意图信息i的情况,但在其他情况下也同样能够提取意图信息i和属性信息e。例如,在接通照明的电源的信息是意图信息i的情况下,属性信息e包含照明的场所的信息和何时接通电源这样的日期时间的信息。
返回图2,处理部52基于意图信息i的内容,执行用户请求的处理。处理部52在意图信息i是控制设备的意思的情况下,执行意图信息i的内容的处理。例如,处理部52接通由属性信息e示出的场所的照明的电源。
图4是用于说明获取信息的表。处理部52在意图信息i是通知被请求的信息的意思的情况下,获取被请求的信息、即获取信息a。获取信息a是用于通知用户h的信息,换言之,如果是用户h正在请求通知的信息,则是由处理执行部34判断了的信息。处理部52基于由意图分析部50提取的意图信息i对获取信息a进行获取。更详细地说,处理部52从提取出的意图信息i中选择并提取获取参数a0。处理部52读出存储在存储部20中意图信息i与获取参数a0间的关系表,从关系表中检测出与提取出的意图信息i一致的意图信息i。然后,处理部52提取与一致的意图信息i相关联的获取参数a0。这里,处理部52也可以经由通信部18与外部服务器进行通信,从外部服务器获取关系表。
处理部52在提取了获取参数a0后,根据属性信息e,按照每个获取参数a0来对获取内容信息a1进行获取。具体而言,处理部52按照每个获取参数a0获取成为属性参数e0设定的属性内容e1时的获取内容信息a1。处理部52通过通信部18与外部服务器(外部设备)进行通信,按照每个获取参数a0,从外部服务器对获取内容信息a1进行获取。这里,处理部52在存储部20中存储有获取内容信息a1的情况下,也可以从存储部20对获取内容信息a1进行获取。即,所谓获取内容信息a1,可以说是处理部52从外部服务器或存储部20等数据库获取的数据。
这样,获取内容信息a1是处理部52通过与外部服务器的通信或从存储部20的读出而获取的信息。在图4的示例中,意图信息i是天气,而获取参数a0是天气、气温和降水概率。在该情况下,处理部52获取针对x年y月z日的东京的天气、气温以及降水概率的各获取参数a0的获取内容信息a1。在图4的例子中,关于天气的获取内容信息a1是“晴间多云”,关于气温的获取内容信息a1是“最高气温25度,最低气温15度”,关于降水概率的获取内容信息a1是“20%”。
如上所述,处理部52基于属性信息e获取每个获取参数a0的获取内容信息a1。另外,在本实施方式中,意图信息i与多个获取参数a0相关联。然而,一个获取参数a0可以与意图信息i相关联。在这种情况下,可以说意图信息i本身是获取参数a0。
返回图2,声音内容生成部36根据处理部52获取的获取内容信息a1生成输出文章。输出文章是使声音输出部12输出的声音v2用的文章的数据,即文本数据。输出文章也可以是对话数据。声音内容生成部36具有生成第一输出文章作为输出文章的第一输出文章生成部60,以及生成第二输出文章作为输出文章的第二输出文章生成部62。在说明第一输出文章生成部60和第二输出文章生成部62之前,对声音分类部38进行说明。
声音分类部38对声音获取部30获取的声音v1进行分析,将声音v1分类为第一声音v1a和第二声音v1b中的任一个。在本实施方式中,声音分类部38分析声音v1,在声音v1是耳语的情况下,将该声音v1分类为第二声音v1b。然后,声音分类部38在声音v1不是耳语的情况下,将该声音v1分类为第一声音v1a。耳语是指不使声带振动而无声化时的声音,例如只要是在后述的方法中被分类为第二声音v1b的声音,这并不局限于不使声带振动而使声带无声化时的声音。
例如,声音分类部38获取声音v1的强度的时间波形,通过对该时间波形进行傅立叶变换,获取表示每个频率声音v1的强度的频谱。然后,声音分类部38将频谱所具有的规定强度以上的峰值的频率作为特征量,对声音v1是第一声音v1a还是第二声音v1b进行分类。例如,声音分类部38在峰值频率为阈值以下的情况下作为耳语,分类为第二声音v1b,在峰值的频率大于阈值的情况下,设为不是耳语而分类为第一声音vb。这里,声音分类部38也可以通过任意的方法对第一声音v1a和第二声音v1b进行分类。例如,声音分类部38也可以将频谱的峰值的斜率作为特征量,对第一声音v1a和第二声音v1b进行分类。另外,声音分类部38也可以将声音v1音量、声音v1中包含的用户h的发音的速度、以及声音v1中的人的发音与风声的音量比中的任意一个作为特征量,对第一声音v1a和第二声音v1b进行分类。另外,在声音内容控制装置1中也可以设置接近传感器,根据接近传感器检测结果计算用户h与声音内容控制装置1间的距离,将该距离作为特征量,对第一声音v1a和第二声音v1b进行分类。另外,声音分类部38还可以从声音v1导出梅尔频率倒谱系数作为特征量,并基于梅尔频率倒谱系数对第一声音v1a和第二声音v1b进行分类。在这些情况下,声音分类部38预先对特征量设定阈值,根据特征量是否超过阈值,来分类为第一声音v1a和第二声音v1b中的某一个。
这样,声音分类部38使用声音获取部30获取的声音v1,对声音v1进行分类。即,即使声音v1意义相同,在声音v1是耳语的情况下,声音分类部38将其分类为第二声音v1b,在声音v1不是耳语的情况下,声音分类部38将其分类为第一声音v1a。
另外,声音分类部38不限于根据声音v1对是第一声音v1a还是第二声音v1b进行分类的方法。也可以通过对声音获取部30获取的声音v1进行文字分析来生成声音v1的文本数据,使用声音v1的文本数据进行分类。例如,声音分类部38也可以不是根据是否是耳语的判定、而是根据例如声音v1中包含的关键字对声音v1进行分类。即,可以是:在声音v1中包含存储部20存储的关键字的情况下,声音分类部38将其分类为第二声音v1b,在声音v1中不包含存储部20存储的关键字的情况下,声音分类部38将其分类为第一声音v1a。
声音分类部38可以使用以上说明的分类方法中的任意一种,也可以组合以上说明的分类方法来进行分类。
声音内容生成部36在通过声音分类部38将声音v1分类为第一声音v1a的情况下,使第一输出文章生成部60生成第一输出文章。即,声音内容生成部36在声音v1被分类为第一声音v1a的情况下,不生成第二输出文章而生成第一输出文章。第一输出文章生成部60将由处理执行部34获取的包含意图信息i、属性信息e(更详细地说是属性内容e1)和获取信息a的全部信息的文章作为第一输出文章生成。即,第一输出文章是包括由处理执行部34获取的所有意图信息i、属性内容e1和获取信息a的文本数据。
在图3和图4的例子中,意图信息i是“天气”,属性内容e1是“x年y月z日”、“东京”。然后,在获取信息a中,获取参数a0是“天气”、“气温”、“降水概率”,获取内容信息a1是“晴间多云”、“最高气温25度、最低气温15度”、“20%”。此时,第一输出文章生成部60例如将“x年y月z日的东京的天气是晴间多云,降水概率为20%,最高气温25度,最低气温15度”这样的文章,作为第一输出文章生成。意图信息i、属性内容e1和获取信息a分别是单独的信息。第一输出文章生成部60为了使第一输出文章成为包含意图信息i、属性内容e1和获取信息a的文章,在第一输出文章中加入信息。即,第一输出文章生成部60将意图信息i、属性内容e1、以及获取信息a以外的信息(单词)添加到第一输出文章中。作为添加的信息(单词),如果是日语的话,就是“です”等礼貌词或者是“は”等助词等,如果是英语的话则是冠词等。以下,将该信息设为文章用信息。
另一方面,声音内容生成部36在通过声音分类部38将声音v1分类为第二声音v1b的情况下,使第二输出文章生成部62生成第二输出文章。即,声音内容生成部36在声音v1被分类为第二声音v1b的情况下,不生成第一输出文章而生成第二输出文章。第二输出文章生成部62与第一输出文章相比,以省略信息的一部分的方式生成文章,由此生成第二输出文章。因此,第二输出文章的文章量比第一输出文章少。进一步说,在假定根据相同的意图信息i、属性信息e和获取信息a生成了第一输出文章和第二输出文章的情况下,第二输出文章由于与第一输出文章相比所包含的信息被省略,因此文章量比第一输出文章少。
具体而言,第二输出文章生成部62生成第二输出文章,使得不包含处理执行部34获取的意图信息i、属性内容e1、以及获取信息a以及在生成第一输出文章的情况下添加的文章用信息中的至少一者。换言之,在假定根据相同意图信息i、属性信息e和获取信息a生成了第一输出文章的情况下,第二输出文章生成部62通过省略包含在第一输出文章中的意图信息i、属性内容e1、获取信息a和文章用信息中的至少一者来生成第二输出文章。
在不包括意图信息i的情况下,即,在省略意图信息i的情况下,例如,在第二输出文章中,省略作为意图信息i的“天气”,而成为“x年y月z日的东京晴间多云,降水概率为20%,最高气温25度,最低气温15度”。由于意图信息i是想要询问的信息的种类,因此即使省略该意图信息i,用户h也能够掌握内容。
另外,在不包含属性内容e1、即省略属性内容e1的情况下,例如,第二输出文章省略作为属性内容e1的“x年y月z日”和“东京”,而成为“天气晴间多云,降水概率为20%,最高气温25度,最低气温15度”。通常将属性内容e1包含在声音v1中,因此即使省略属性内容e1,用户h也能够掌握内容。换言之,第二输出文章生成部62可以选择包含在声音v1中的信息作为省略的信息、即不包含在第二输出文章中的信息。即,第二输出文章生成部62将包含在用户h发出的声音v1中的信息作为被省略的信息的一部分。另外,例如即使属性内容e1不包含在声音v1中,也存在属性内容e1作为设定数据存储在存储部20中的情况。在该情况下,识别出属性内容e1被设定为设定数据、即默认的数据,因此即使不包含属性内容e1,用户h也能够理解内容。另外,在属性内容e1有多个的情况下,第二输出文章生成部62可以省略全部的属性内容e1,也可以仅省略一部分的属性内容e1。
另外,在不包含文章用信息、即省略文章用信息的情况下,例如,第二输出文章省略作为文章用信息的单词,而成为“x年y月z日东京的天气晴间多云,降水概率为20%,最高气温25度,最低气温15度”。即,例如在日语的情况下,例如作为文章用信息而省略礼貌词,例如在英语的情况下省略冠词。
另一方面,由于获取信息a是用户h想要询问的信息,因此与意图信息i、属性内容e1和文章用信息相比,优选不省略。特别是,由于获取内容信息a1是提供给用户h的数据本身,因此优选不省略。即,优选第二输出文章生成部62从获取内容信息a1以外的信息中选择省略的信息来生成第二输出文章。进一步而言,优选第二输出文章生成部62不选择获取内容信息a1作为省略的信息,而使获取内容信息a1包含在第二输出文章中。这样,通过从获取内容信息a1以外信息中选择不包含在第二输出文章中的信息,不选择获取内容信息a1作为不包含在第二输出文章中的信息,能够使用户h掌握内容的同时,适当地减少文章量。
这里,第二输出文章生成部62有时也省略获取信息a,以下对该情况进行说明。例如,第二输出文章生成部62也可以选择获取信息a中的获取参数a0作为省略的信息。此时,第二输出文章省略了作为获取参数a0的“天气”、“降水概率”、“气温(最高气温、最低气温)”,而成为“x年y月z日的东京晴间多云,20%,15度到25度”。由于获取参数a0是与用户h想要询问的获取内容信息a1关联的信息,因此如果被通知了获取内容信息a1,则用户h能够识别是针对哪个获取参数a0的获取内容信息a1。
更具体地,在获取内容信息a1是包括单位的数值信息的情况下,第二输出文章生成部62选择与获取内容信息a1关联的获取参数a0、即选择表示数值信息的种类的信息作为省略的信息。在获取内容信息a1包含单位的情况下,用户h能够根据该单位识别获取参数a0。
另外,在获取内容信息a1是表示数值范围信息的情况下,第二输出文章生成部62选择与该获取内容信息a1关联的获取参数a0作为省略的信息。该情况下的要被省略的获取参数a0是表示是数值范围中的最大值的信息(在该例中为“最高气温”)和表示是数值范围中的最小值的信息(在该例中为“最低气温”)。
另外,在获取内容信息a1是指示开始和结束的信息的情况下,第二输出文章生成部62选择与该获取内容信息a1关联的获取参数a0作为省略信息。表示开始和结束的信息例如是乘车站为东京站、到达站为横滨站时的信息。在这种情况下,东京站是表示开始的信息,横滨站是表示结束的信息。该情况下,例如第一输出文章为“上车站是东京站,下车站是横滨站”,但第二输出文章省略了作为获取参数a0的“上车站”和“下车站”,而成为“从东京站到横滨站”。即,在该情况下,作为获取参数a0的“上车站”是表示相当于开始的获取内容信息a1为开始的信息,作为获取参数a0的“下车站”可以说是表示相当于结束的获取内容信息a1是结束的信息。即使在以上的情况下,由于第二输出文章包含有“从a到b”这样的获取内容信息a1,因此即使省略获取参数a0,用户h也能够掌握内容。
另外,第二输出文章生成部62在获取了多个意图信息i、多个获取内容信息a1情况下,也可以选择一部分获取内容信息a1作为省略的信息。例如,在提取了多个意图信息i的情况下,第二输出文章生成部62省略属于某一个意图信息i的获取内容信息a1。例如,第二输出文章生成部62省略在设为文章的情况下文章量变多的、属于意图信息i的获取内容信息a1来作为优先级低的信息。例如,说明在声音v1为“早上好”的情况下设定为提取天气和新闻作为意图信息i的情况。在该情况下,在与新闻相关的输出文章比与天气相关的输出文章长的情况下,第二输出文章生成部62省略与新闻相关的获取内容信息a1,留下与天气相关的获取内容信息a1。
另外,在针对一个意图信息i获取了多个获取内容信息a1的情况下,第二输出文章生成部62也可以省略某一个获取内容信息a1。例如,在意图信息i是通知拥堵的信息的情况下,第二输出文章生成部62对获取内容信息a1进行获取而成为每个场所的拥堵信息。在该情况下,第二输出文章生成部62将例如远离当前位置场所的拥堵信息、拥堵的规模小的场所的拥堵信息等重要度低的拥堵信息(获取内容信息a1)作为优先级低信息而省略。
这样,在有多个获取内容信息a1、省略多个获取内容信息a1中一部分的情况下,第二输出文章生成部62选择优先级低的获取内容信息a1作为省略的信息。第二输出文章生成部62预先设定优先级并存储在存储部20中,根据该优先级,选择优先级低的获取内容信息a1。即,例如,将文章量少作为优先级高的信息,或者将距当前位置近的拥堵信息作为优先级高的信息来存储。
如上所述,第二输出文章生成部62通过省略意图信息i、属性内容e1、获取信息a和文章用信息中的至少某一个来生成第二输出文章。即,意图信息i、属性内容e1、获取信息a和文章用信息可以说是可省略的信息。第二输出文章生成部62可以选择以上说明的可省略的信息作为全部省略的信息,也可以仅省略可省略的信息中的一部分。例如,声音内容控制装置1预先设定可省略的信息中的、实际省略的信息。例如,在将意图信息i和属性内容e1设定为省略的信息的情况下,第二输出文章生成部62在生成第二输出文章时,不管意图信息i和属性内容e1的种类,总是省略意图信息i和属性内容e1。另外,声音内容控制装置1也可以将表示实际省略的信息的种类的表存储在存储部20中。在这种情况下,例如,由于被省略的意图信息i(例如天气等)和未被省略的信息(例如时间等)被区分,因此根据信息的种类能够适当地选择省略的信息。
声音内容生成部36如上所述生成输出文章。以上的说明是意图信息i是通知信息的意思的内容的情况下的输出文章的生成方法。在意图信息i是控制设备的意思的内容的情况下,声音内容生成部36也同样地以比第一输出文章更省略信息的方式生成第二输出文章。在该情况下,声音内容生成部36在执行了基于处理部52的控制(例如接通照明的电源的控制)之后,将说明该控制的执行状况的文章作为输出文章生成。更详细地说,在被分类为第一声音v1a的情况下,声音内容生成部36作为第一输出文章生成“是,接受了处理”这样的文本数据。即,第一输出文章包含“是”等回答的信息和“接受了处理”等接在回答的信息之后的文章的信息。另一方面,在被分类为第二声音v1b的情况下,声音内容生成部36作为第二输出文章生成“是”这样的文本数据。即,在该情况下,第二输出文章包含回答的信息,省略接在回答的信息之后的文章的信息。因此,即使在该情况下,也可以说在被分类为第二声音v1b的情况下,声音内容生成部36省略了生成了第一输出文章的情况下所包含的一部分信息。
返回图2,输出控制部40获取声音内容生成部36生成的输出文章,即第一输出文章或第二输出文章。输出控制部40将作为该文本数据的输出文章变换为声音数据,并将该声音数据作为声音v2输出到声音输出部12。输出控制部40在通过调整音量开关设定为相同音量的情况下,将读取第一输出文章的声音v2的音量和读取第二输出文章的声音v2的音量设为相同音量。即,输出控制部40在第一输出文章和第二输出文章中不改变声音v2的音量。但是,输出控制部40也可以在第一输出文章和第二输出文章中改变声音v2的音量。另外,输出控制部40也可以在输出声音v2时、处理部52的处理结束时、检测出声音v1时等,控制点亮部14使其点亮。
控制部16具有如上所述的结构。以下,基于流程图说明控制部16的输出文章的输出处理的流程。图5是表示第一实施方式的输出文章的输出处理的流程的流程图。如图5所示,控制部16通过声音获取部30获取输入声音、即声音v1的声音数据(步骤s10)。控制部16通过声音分析部32对声音获取部30获取的声音v1的声音数据进行分析来生成文本数据(步骤s12)。然后,控制部16通过意图分析部50从文本数据中提取意图信息i和属性信息e(步骤s14)。在提取了意图信息i和属性信息e之后,控制部16通过处理部52进行执行基于意图信息i的处理或者获取基于意图信息i的获取信息中的某一个(步骤s16)。即,在意图信息i是控制设备的意思的内容的情况下,处理部52执行由意图信息i和属性信息e规定的内容的处理(例如接通照明的电源)。另一方面,在意图信息i是通知信息的意思的内容的情况下,处理部52基于意图信息i和属性信息e对获取信息a进行获取。具体而言,处理部52根据意图信息i和属性信息e提取获取参数a0,并按照每个获取参数a0对获取内容信息a1进行获取。另外,如果在步骤s10中获取了输入声音、即声音v1,则控制部16通过声音分类部38将声音v1分类为第一声音v1a、第二声音v1b中的某一个(步骤s18)。
控制部16判定声音v1是否是第一声音v1a(步骤s20),在是第一声音v1a情况下(步骤s20;是),由第一输出文章生成部60生成第一输出文章(步骤s22)。另一方面,在不是第一声音v1a情况下(步骤s20;否)、即是第二声音v1b的情况下,控制部16通过第二输出文章生成部62生成第二输出文章(步骤s24)。控制部16在生成了输出文章、即第一输出文章或第二输出文章后,通过输出控制部40使该输出文章利用声音输出部12作为声音v2输出(步骤s26),并结束处理。即,在生成第一输出文章后,输出控制部40将该第一输出文章变换为声音数据,由声音输出部12作为声音v2输出。然后,在生成了第二输出文章的情况下,输出控制部40将该第二输出文章变换为声音数据,由声音输出部12作为声音v2输出。
本实施方式的声音内容控制装置1具有声音分类部38、处理执行部34、声音内容生成部36。声音分类部38对声音获取部30获取的、用户h发出的声音v1进行分析,并将声音v1分类为第一声音v1a和第二声音v1b中的某一个。处理执行部34对声音获取部30获取的声音v1进行分析,并执行用户请求的处理。声音内容生成部36根据处理执行部34执行的处理内容,生成输出文章,该输出文章是向用户h输出的声音v2用的文章数据(文本数据)。在被分类为第一声音v1a的情况下,声音内容生成部36生成第一输出文章作为输出文章。在分类为第二声音v1b的情况下,声音内容生成部36生成与第一输出文章相比省略了一部分信息的第二输出文章,作为输出文章。进而,在本实施方式中,在被分类为第二声音v1b情况下,声音内容生成部36以与第一输出文章相比省略一部分信息的方式生成文章,由此,生成与第一输出文章相比文章量少的第二输出文章作为输出文章。
作为输出文章的声音数据输出的声音v2被向用户h输出,如上所述,有时也会到达位于声音内容控制装置1周围的用户h以外的人。在判断为不想对周围人产生声音v2的影响的情况下,用户h通过耳语发出声音v1等,相对于判断为可以产生声音v2的影响的情况,即使在传递相同内容的情况下,也使声音v1变化。声音内容控制装置1分析用户声音v1,在检测出被分类为第一声音v1a的声音v1的情况下,判断为可以不考虑对用户h以外的人的影响,生成用于声音v2的第一输出文章。另一方面,声音内容控制装置1在检测出被分类为第二声音v1b声音v1的情况下,判断为需要考虑对用户h以外的人的影响,生成文章量比第一输出文章少第二输出文章。由此,声音内容控制装置1在需要考虑对用户h以外的人的影响的情况下,能够减少作为声音v2发出的文章量,缩短输出声音v2的长度,抑制对用户h以外的人的影响。进而,声音内容控制装置1为了省略一部分信息而生成第二输出文章,通过调整省略的信息,用户h能够适当地理解声音v2的内容、即第二输出文章的内容。
此外,处理执行部34具有基于声音v1提取指示用户h的意图的意图信息i的意图分析部50,以及基于意图信息i获取通知给用户h的获取内容信息a1的处理部52。声音内容生成部36将包含获取内容信息a1的文章数据作为输出文章。该声音内容控制装置1由于使基于意图信息i获取的获取内容信息a1包含在输出文章中,因此能够将用户h希望的信息适当地传递给用户h。
另外,在被分类为第二声音v1b的情况下,声音内容生成部36从获取内容信息a1以外的信息中选择省略的信息来生成第二输出文章。获取内容信息a1有时指用户h请求的信息本身。声音内容生成部36由于从获取内容信息a1以外选择省略的信息,因此能够不省略获取内容信息a1地通知信息,能够使用户h适当地理解声音v2的内容。
另外,声音内容生成部36不选择获取内容信息a1作为省略的信息,而使获取内容信息a1包含在第二输出文章中。声音内容生成部36能够不省略获取内容信息a1地通知信息,能够使用户h适当地理解声音v2的内容。
另外,声音内容生成部36从预先设定的表中选择省略的信息。声音内容控制装置1由于从存储在存储部20中的表中选择省略的信息,因此能够适当地选择省略的信息,使用户h能够适当地理解声音v2内容。
另外,声音内容生成部36选择用户h发出的声音v1中包含的信息作为省略的信息。用户h发出的声音v1中包含的信息即使省略,用户h也容易理解意思。声音内容控制装置1通过省略这样的声音v1中包含的信息,能够在适当地理解声音v2的内容的同时,抑制对用户h以外的人的影响。
另外,声音内容生成部36在获取内容信息a1中包含有包含单位的数值信息的情况下,选择表示数值信息的种类的信息(获取参数a0)作为省略信息。声音内容控制装置1通过省略与包含单位的获取内容信息a1关联的获取参数a0,能够适当地理解声音v2的内容,并抑制对用户h以外的人的影响。
在从处理执行部34获取了多种获取内容信息a1的情况下,声音内容生成部36选择优先级低的获取内容信息a1作为省略的信息。声音内容控制装置1通过省略优先级低的获取内容信息a1,能够适当地理解声音v2的内容,并抑制对用户h以外的人的影响。
声音内容生成部36从多种获取内容信息a1中选择作为输出文章时文章量变多的上述获取内容信息a1,作为省略的信息。声音内容控制装置1通过省略文章量变多的获取内容信息a1,能够抑制对用户h以外的人的影响。
声音内容生成部36预先决定优先级,根据预先决定的优先级,选择省略的信息。声音内容控制装置1通过预先确定优先级,能够在适当地理解声音v2的内容的同时,抑制对用户h以外的人的影响。
声音分类部38在用户发出的声音v1是耳语的情况下,将声音v1分类为第二声音v2b。该声音内容控制装置1检测出耳语并在该情况下生成第二输出文章,由此适当地检测是否为对用户h以外人造成影响的状况,并能够适当地抑制其影响。
图6是表示输出文章的输出处理的流程的另一例的流程图。另外,在是第二声音v1b的情况下,本实施方式的声音内容生成部36不生成第一输出文章,而生成第二输出文章。不过,声音内容生成部36也可以在生成了第一输出文章之后,通过省略生成的第一输出文章的信息的一部分来生成第二输出文章。即,在该情况下,如图6所示,在步骤s16中进行了处理部52的处理之后,声音内容生成部36不参照声音v1的分类结果、即不管分类结果如何都生成第一输出文章(步骤s17)。声音内容生成部36在生成第一输出文章之后,在判断为是第一声音v1a情况下(步骤s20a;是)转移到步骤s26,并将该第一输出文章作为输出文章。另一方面,声音内容生成部36在生成第一输出文章之后,在判断为不是第一声音v1a(步骤s20a;否)、即判断为是第二声音v1b的情况下,通过省略生成的第一输出文章的一部分信息来生成第二输出文章(步骤s24a),将第二输出文章作为输出文章。该情况下的第二输出文章中的信息的省略方法可以是已述的方法。
(第二实施方式)
接着,对第二实施方式进行说明。第一实施方式涉及的声音内容控制装置1具有声音检测部10和声音输出部12,但第二实施方式涉及的声音内容控制装置1a不具有声音检测部10和声音输出部12。在第二实施方式中,对结构与第一实施方式相同的部分省略说明。
图7是根据第二实施例的音频处理系统的示意性框图。如图7所示,第二实施方式涉及的声音处理系统100具有声音内容控制装置1a和响应装置2a。响应装置2a例如是智能扬声器,具有声音检测部10、声音输出部12、点亮部14和通信部15a。声音内容控制装置1a是位于远离响应装置2a的地方的装置(服务器),具有控制部16、通信部18a和存储部20。声音内容控制装置1a和响应装置2a通过无线通信连接,但也可以通过有线通信连接。
声音内容控制装置1a通过经由通信部15a和通信部18a的信息通信,获取声音检测部10检测出的声音v1。然后,声音内容控制装置1a执行与第一实施方式相同的处理,生成输出文章,将该输出文章输出到响应装置2a。响应装置2a通过声音输出部12将输出文章变换为声音数据,并作为声音v2输出。这里,声音内容控制装置1a也可以生成输出文章的声音数据,并发送到响应装置2a。在这种情况下,声音输出部12将获取的声音数据作为声音v2输出。这样,声音处理系统100具有声音内容控制装置1a、检测用户h发出声音v1的声音检测部10、以及将声音内容生成部36生成的输出文章作为声音(v2)输出的声音输出部(12)。这样,声音内容控制装置1a即使与响应装置2a分体,也能够起到与第一实施方式同样的效果。
以上,对本发明的实施方式进行了说明,但实施方式并不限定于这些实施方式的内容。另外,上述构成要素包括本领域技术人员能够容易想到的要素、实质上相同的要素、所谓等同范围的要素。进而,上述的构成要素可以适当组合。进而,在不脱离上述实施方式的主旨的范围内,能够进行构成要素的各种省略、置换或变更。
符号说明
1声音内容控制装置、10声音检测部、12声音输出部、16控制部、30声音获取部、32声音分析部、34处理执行部、36声音内容生成部、38声音分类部、40输出控制部、50意图分析部、52处理部、a获取信息、e属性信息、h用户、i意图信息、v1、v2声音、v1a第一声音、v1b第二声音。
- 还没有人留言评论。精彩留言会获得点赞!