一种口语考试的多维度评估方法及装置与流程
本发明涉及计算机技术领域,特别是涉及一种口语考试的多维度评估方法及装置。
背景技术:
作为人际交流的重要媒介,口语语言在实际生活中占有极其重要的地位。随着社会经济的不断发展和经济全球化趋势的进行,人们对语言学习的效率以及语言评估的客观性、公正性和规模化测试提出了越来越高的要求。口语考试中的开放题型如口头作文、故事复述和看图说话等是反映考生口语的表达能力的一个重要题型。会考察考生的表达内容的完整性,流畅程度,发音准确性及语法的正确性等方面。
传统的口语考试评分系统是直接根据老师打分的总分标注数据学习评分模型,给出一个总分输出。而学生在口语表达上的哪些方面有欠缺没有给出,如发音是否准确,语法是否有问题,内容是否完整等,因此,单独的总分不能全部呈现考生的综合水平。
技术实现要素:
基于此,有必要针对传统方案评分反馈不明确问题,提供一种口语考试的多维度评估方法及装置.
一种口语考试的多维度评估方法,所述方法包括:
获取考生的口语回答结果;
确定对所述口语回答结果的评分维度,所述评分维度至少包括内容维度、发音维度、语法维度和流利度;
基于所述评分维度,获取与所述评分维度相对应的维度评分值;
基于各个所述维度评分值,确定所述口语回答结果的综合评分值;
基于所述综合评分值和各个所述维度评分值,确定对所述考生的评估结果。
优选的,如果所述评分维度包括内容维度,则所述基于所述评分维度,获取与所述评分维度相对应的维度评分值,包括:
获取所述口语回答结果的文本内容;
确定所述文本内容与预设参考答案之间的完整度系数;
基于所述完整度系数确定对应的内容维度评分值。
优选的,如果所述评分维度包括发音维度,则所述基于所述评分维度,获取与所述评分维度相对应的维度评分值,包括:
基于标准发音形成的声学模型提取所述口语回答结果中的发音特征;
基于所述标准发音,确定所述发音特征相对于所述标准发音的正确率;
基于所述正确率确定对应的发音维度评分值。
优选的,如果所述评分维度包括语法维度,则所述基于所述评分维度,获取与所述评分维度相对应的维度评分值,包括:
获取所述口语回答结果的文本内容;
对所述文本内容进行断句获取目标句子文本;
获取所述目标句子文本中的语法特征;
将对每个所述语法特征作为参数输入至预设的预测模型,并由所述预测模型输出对应的语法维度评分值。
优选的,如果所述评分维度包括流利度,则所述基于所述评分维度,获取与所述评分维度相对应的维度评分值,包括:
获取所述口语回答结果的文本内容;
确定所述文本内容中相应单词的时间序列信息;
基于所述时间序列信息生成与每个所述时间序列信息相对应的特征值;
将与每个所述时间序列信息相对应的特征值输入至预设的流利度模型,并由所述流利度模型输出对应的流利度评分值。
一种口语考试的多维度评估装置,所述装置包括:
第一获取模块,用于获取考生的口语回答结果;
第一确定模块,用于确定对所述口语回答结果的评分维度,所述评分维度至少包括内容维度、发音维度、语法维度和流利度;
第二获取模块,用于基于所述评分维度,获取与所述评分维度相对应的维度评分值;
第二确定模块,用于基于各个所述维度评分值,确定所述口语回答结果的综合评分值;
第三确定模块,用于基于所述综合评分值和各个所述维度评分值,确定对所述考生的评估结果。
优选的,如果所述评分维度包括内容维度,则所述第二获取模块用于:
获取所述口语回答结果的文本内容;
确定所述文本内容与预设参考答案之间的完整度系数;
基于所述完整度系数确定对应的内容维度评分值。
优选的,如果所述评分维度包括发音维度,则所述第二获取模块用于:
基于标准发音形成的声学模型提取所述口语回答结果中的发音特征;
基于所述标准发音,确定所述发音特征相对于所述标准发音的正确率;
基于所述正确率确定对应的发音维度评分值。
优选的,如果所述评分维度包括语法维度,则所述第二获取模块用于:
获取所述口语回答结果的文本内容;
对所述文本内容进行断句获取目标句子文本;
获取所述目标句子文本中的语法特征;
将对每个所述语法特征作为参数输入至预设的预测模型,并由所述预测模型输出对应的语法维度评分值。
优选的,如果所述评分维度包括流利度,则所述第二获取模块用于:
获取所述口语回答结果的文本内容;
确定所述文本内容中相应单词的时间序列信息;
基于所述时间序列信息生成与每个所述时间序列信息相对应的特征值;
将与每个所述时间序列信息相对应的特征值输入至预设的流利度模型,并由所述流利度模型输出对应的流利度评分值。
本发明中,获取考生的口语回答结果;确定对所述口语回答结果的评分维度,所述评分维度至少包括内容维度、发音维度、语法维度和流利度;基于所述评分维度,获取与所述评分维度相对应的维度评分值;基于各个所述维度评分值,确定所述口语回答结果的综合评分值;基于所述综合评分值和各个所述维度评分值,确定对所述考生的评估结果。由此,本发明可以基于多个不同的维度同时对考生的口语回答作评估,还可以进一步形成综合评分值从整体上评估;这样,每个学生可以直接知道自己的优点和不足,及时的改进自己的学习计划;相对直接给出总分的方案,评分解释性更强、相对更客观。
附图说明
图1为一实施例的口语考试的多维度评估方法的流程图;
图2为一实施例的口语考试的多维度评估装置的结构图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
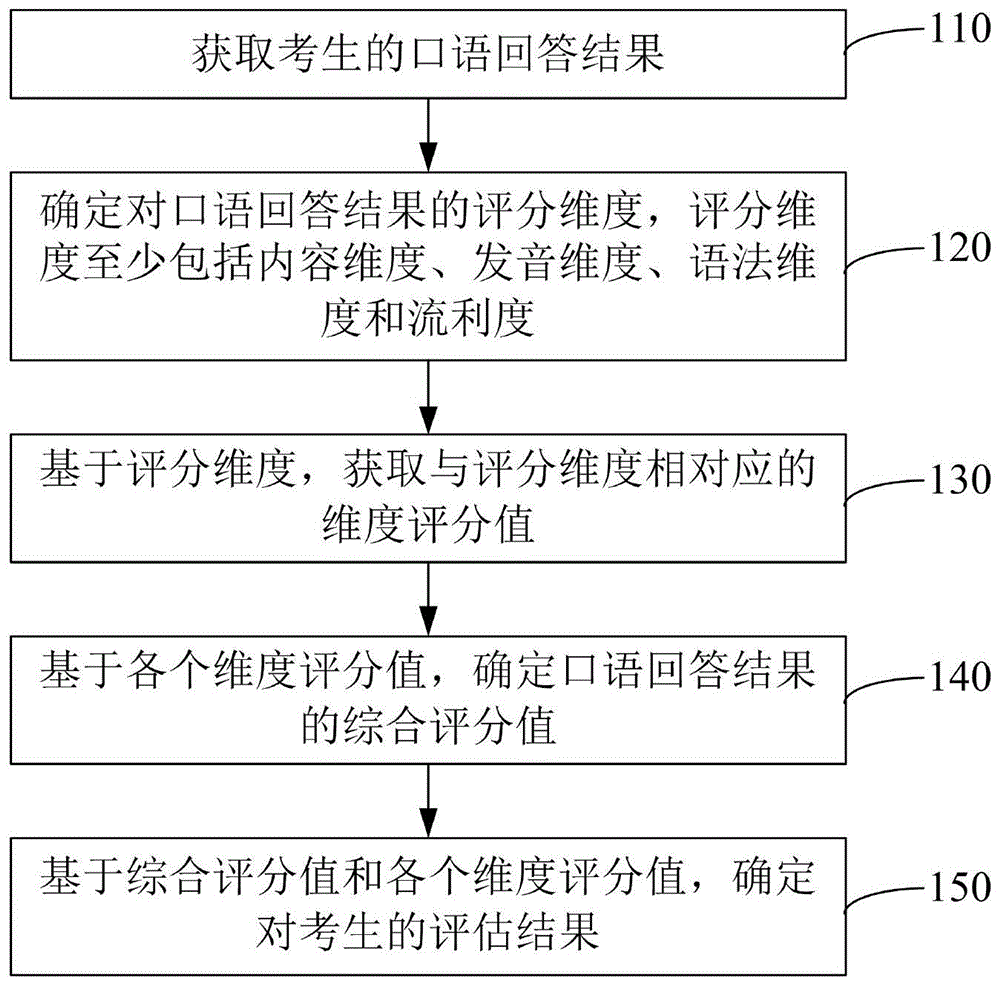
图1为一实施例的口语考试的多维度评估方法的流程图。如图1所示,该方法包括:
步骤110,获取考生的口语回答结果;
步骤120,确定对口语回答结果的评分维度,评分维度至少包括内容维度、发音维度、语法维度和流利度;
步骤130,基于评分维度,获取与评分维度相对应的维度评分值;
步骤140,基于各个维度评分值,确定口语回答结果的综合评分值;
步骤150,基于综合评分值和各个维度评分值,确定对考生的评估结果。
本发明中,获取考生的口语回答结果;确定对所述口语回答结果的评分维度,所述评分维度至少包括内容维度、发音维度、语法维度和流利度;基于所述评分维度,获取与所述评分维度相对应的维度评分值;基于各个所述维度评分值,确定所述口语回答结果的综合评分值;基于所述综合评分值和各个所述维度评分值,确定对所述考生的评估结果。由此,本发明可以基于多个不同的维度同时对考生的口语回答作评估,还可以进一步形成综合评分值从整体上评估;这样,每个学生可以直接知道自己的优点和不足,及时的改进自己的学习计划;相对直接给出总分的方案,评分解释性更强、相对更客观。
本实施例中,在考生口语回答时,可以采用语音存储系统记录考生的口语回答结果,可以以音频等方式存储起来。
本实施例的一实现方式中,如果评分维度包括内容维度,则基于评分维度,获取与评分维度相对应的维度评分值,包括:
获取口语回答结果的文本内容;
确定文本内容与预设参考答案之间的完整度系数;
基于完整度系数确定对应的内容维度评分值。
通过语音识别系统可以获取口语回答结果的文本内容。确定文本内容与预设参考答案之间的完整度系数时,可以从参考答案中提取出关键字,这些关键字可以是考生必须要口语回答的内容。然后对这些关键字作同义词扩展,并取其并集。然后将该并集从文本内容中搜索文本内容是否包括有其中的关键字,如果有,则记录,相同或者同义词的关键字只保留一个。然后基于文本内容中包括的关键字的数量与从参考答案中提取出的关键字的数量,二者相除,可以得到一个完整度系数。可以理解,该完整度系数越大,对应的内容维度评分值越高。
本实施例的一实现方式中,如果评分维度包括发音维度,则基于评分维度,获取与评分维度相对应的维度评分值,包括:
基于标准发音形成的声学模型提取口语回答结果中的发音特征;
基于标准发音,确定发音特征相对于标准发音的正确率;
基于正确率确定对应的发音维度评分值。
本实施例中,可以用标准发音训练出的声学模型,按识别结果提取gop打分相关特征。以标准发音为参考依据,训练单词级的发音评价0-1模型。最后整个维度的打分按正确率来给出。声学模型可以通过大数据训练的方式得到。
发音特征可以是每口语回答结果中每一个单词的发音。然后,基于每一个单词的发音,可以将其与每个单词的标准发音对比,判断该单词的发音是否正确。基于所有的单词,从中确定发音正确的单词,将发音正确的单词的数量与所有的单词的数量相除,即可得到正确率。正确率越大,则发音维度评分值越高。
本实施例的一实现方式中,如果评分维度包括语法维度,则基于评分维度,获取与评分维度相对应的维度评分值,包括:
获取所述口语回答结果的文本内容;
对所述文本内容进行断句获取目标句子文本;
获取所述目标句子文本中的语法特征;
将对每个所述语法特征作为参数输入至预设的预测模型,并由所述预测模型输出对应的语法维度评分值。
本发明可,可以先对文本内容进行分句;然后按句对文本内容进行语法对错判断,依靠链语法方案来对句子进语法对错判断;最后,根据考生回答错误的相关特征,及对应的语法错误打分标注,基于预测模型。通过这样一个预测模型给出语法维度打分。预测模型可以基于以往所有考生的口语回答结果通过大数据训练的方式生成。
可以理解,预测模型可以对输入的语法特征判断是否存在错误,并进行打分标注,以最终输出语法维度打分。
本实施例的一实现方式中,如果评分维度包括流利度,则基于评分维度,获取与评分维度相对应的维度评分值,包括:
获取口语回答结果的文本内容;
确定文本内容中相应单词的时间序列信息;
基于时间序列信息生成与每个时间序列信息相对应的特征值;
将与每个时间序列信息相对应的特征值输入至预设的流利度模型,并由流利度模型输出对应的流利度评分值。
本实施例中,时间序列信息重点包括长短sil的时间个数的分布信息。特征值可以是时间信息本身,如时间长度、间隔时间长度、停顿时间长度等。
对于时间序列信息,其本身可以理解为对应单词发音的时间点。可以理解,如果口语比较流程,两个单词之间的时间间隔必然较小,相反,则会比较大。因此,如果两个时间序列信息之间的时间间隔较小,即特征值越小,则打分值较高,相反,打分值则较小。
本实施例中,当评分维度包括内容维度、发音维度、语法维度和流利度等4个维度时,可以采用如下公式计算口语回答结果的综合评分值。具体公式如下:
r=scontent*0.05
x1=scontent;scontent∈[0,10]
x2=sfluency/3*10;sfluency∈[0,3]
x3=sgrummar;sgrammar∈[0,3]
x4=spronunciationspronunciation∈[0,4]
overall=(1-r)*x1+r*(0.25*x2+0.25*x3+0.5*x4)
overall∈[0,10]
其中,x1表示内容维度打分值,x2表示流利度打分值,x3表示语法维度打分值,x4表示发音维度打分值,r表示与口语回答结果相关联的系数。
图2为一实施例的口语考试的多维度评估装置的结构图。如图2所示,该装置包括:
第一获取模块210,用于获取考生的口语回答结果;
第一确定模块220,用于确定对口语回答结果的评分维度,评分维度至少包括内容维度、发音维度、语法维度和流利度;
第二获取模块230,用于基于评分维度,获取与评分维度相对应的维度评分值;
第二确定模块240,用于基于各个维度评分值,确定口语回答结果的综合评分值;
第三确定模块250,用于基于综合评分值和各个维度评分值,确定对考生的评估结果。
本发明中,获取考生的口语回答结果;确定对所述口语回答结果的评分维度,所述评分维度至少包括内容维度、发音维度、语法维度和流利度;基于所述评分维度,获取与所述评分维度相对应的维度评分值;基于各个所述维度评分值,确定所述口语回答结果的综合评分值;基于所述综合评分值和各个所述维度评分值,确定对所述考生的评估结果。由此,本发明可以基于多个不同的维度同时对考生的口语回答作评估,还可以进一步形成综合评分值从整体上评估;这样,每个学生可以直接知道自己的优点和不足,及时的改进自己的学习计划;相对直接给出总分的方案,评分解释性更强、相对更客观。
本实施例一实现方式中,如果评分维度包括内容维度,则第二获取模块用于:
获取口语回答结果的文本内容;
确定文本内容与预设参考答案之间的完整度系数;
基于完整度系数确定对应的内容维度评分值。
本实施例一实现方式中,如果评分维度包括发音维度,则第二获取模块用于:
基于标准发音形成的声学模型提取口语回答结果中的发音特征;
基于标准发音,确定发音特征相对于标准发音的正确率;
基于正确率确定对应的发音维度评分值。
本实施例一实现方式中,如果评分维度包括语法维度,则第二获取模块用于:
获取所述口语回答结果的文本内容;
对所述文本内容进行断句获取目标句子文本;
获取所述目标句子文本中的语法特征;
将对每个所述语法特征作为参数输入至预设的预测模型,并由所述预测模型输出对应的语法维度评分值。
本实施例一实现方式中,如果评分维度包括流利度,则第二获取模块用于:
获取口语回答结果的文本内容;
确定文本内容中相应单词的时间序列信息;
基于时间序列信息生成与每个时间序列信息相对应的特征值;
将与每个时间序列信息相对应的特征值输入至预设的流利度模型,并由流利度模型输出对应的流利度评分值。
本实施例中,以上装置的实现过程与以上方法的内容相同,具体可以参照以上方法中的实施例的内容,本实施例不再对于装置具体详述。
以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!