双通道智能音频信号处理方法、系统及音频设备与流程
本发明涉及音频信号处理领域,具体为一种双通道智能音频信号处理方法、系统及音频设备。
背景技术:
在实际环境中,麦克风在拾取语音信号时,不可避免地会受到来自嘈杂环境下的环境噪声、传输媒介噪声、通信设备内部电噪声、房间混响以及其它说话人的话音干扰,因此拾取语音的质量受到影响。语音增强技术是语音处理领域的核心技术之一,能够实现从带噪语音中提取干净的目标语音,以改善接收端语音质量,提高语音的清晰度、可懂度和舒适度,使人易于接受或提高语音处理系统的性能。
基于单个麦克风的语音增强技术的研究已经有四十多年的历史。但是实际情况中,噪声总是来自于四面八方,且其与语音信号在时间和频谱上常常是相互交叠的,再加上回波和混响的影响,利用单麦克风增强感兴趣的声音并有效抑制背景噪声和方向性强干扰是相当困难的。引入麦克风阵列技术后,语音增强技术取得了很大突破。相比传统的单一麦克风语音增强技术,麦克风阵列语音增强技术可以利用语音信号的空间信息来形成波束,实现对干扰噪声的消除,能够保证在语音信息损失最小的条件下实现噪声抑制。因此近十多年来,麦克风阵列语音增强技术已成为了语音增强技术的研究热点和关键技术。然而,目前大多数的麦克风阵列语音增强技术的性能都是正比于阵列所用麦克风数目的,因此该种技术的研究往往采用较多麦克风的阵列,有的麦克风阵列甚至使用数百个麦克风,而较多的麦克风数目造成麦克风阵列的体积也较大,最典型的案例是mit搭建的用于噪声消除和语音增强的麦克风阵列使用了1020个麦克风,其阵列孔径有几米长。因此麦克风阵列技术噪声抑制性能虽好,但由于其设备体积大,算法运算复杂度高,故在实际应用时受到了许多限制。
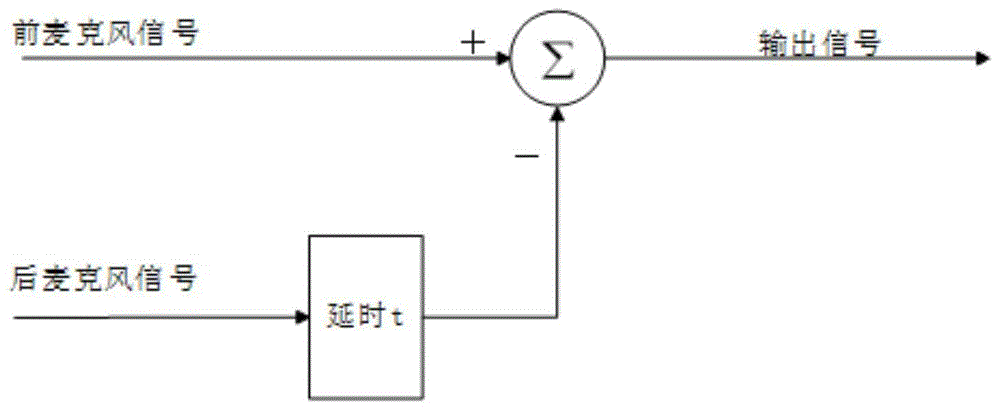
现有双通道智能音频信号处理方法中,为了提升在嘈杂环境中的判断准确率,一般对比前向波束能量和后向波束能量(见图5),这种方法不能防止大的噪声环境对方向判别的影响。且常规的波束形成算法需要加入一个声源定位模块,在切换过程中容易出现杂音。因而现有方法稳定性较低,波束切换的渐变性不平滑。
技术实现要素:
本发明旨在提供一种双通道智能音频信号处理方法、系统及音频设备,防止大的噪声环境影响到方向判别的结果,提高声音判断的稳定性和波束切换的平滑性。
为解决上述技术问题,本发明所采用的技术方案是:一种双通道智能音频信号处理方法,其包括:
形成前向波束和后向波束;
计算所述前向波束的信噪比和后向波束的信噪比;
根据所述前向波束的信噪比和后向波束的信噪比实现前向声音和后向声音的判别和切换。
借由上述方法,将“前向波束能量与后向波束能量”之比改成前向波束信噪比与后向波束信噪比的大小对比,从而能够防止大的噪声环境影响到方向判别的结果。
根据所述前向波束的信噪比和后向波束的信噪比实现前向声音和后向声音的判别的具体实现过程为:若前向波束的信噪比大于后向波束的信噪比,则判定为前向声音;若前向波束的信噪比小于后向波束的信噪比,则判定为后向声音。
为了使得前向后向波束的切换更加平滑,可以考虑根据信噪比的能量大小,采用加权的方式,对波束进行叠加:对前向波束和后向波束进行加权叠加,得到最终的目标语音信号为out=a1*a1+a2*a2;其中,a1=snr1/(snr1+snr2);a2=snr2/(snr1+snr2);snr1为前向波束a1的信噪比;snr2为后向波束a2的信噪比。
所述前向波束形成过程包括:定义靠近0度角度的麦克风信号为前麦克风信号,靠近180度角度方向的麦克风信号为后麦克风信号,用前麦克风信号减去后麦克风信号延时t的信号,则形成一个指向前麦克风的心形波束,即前向波束。
所述后向波束形成过程包括:定义靠近0度角度的麦克风信号为前麦克风信号,靠近180度角度方向的麦克风信号为后麦克风信号,用后麦克风信号减去前麦克风信号延时t的信号,则形成一个指向后麦克风的心形波束,即后向波束。
相应的,本发明还提供了一种双通道智能音频信号处理系统,包括:
波束形成模块,用于形成前向波束和后向波束;
计算模块,用于计算所述前向波束的信噪比和后向波束的信噪比;
执行模块,用于根据所述前向波束的信噪比和后向波束的信噪比实现前向声音和后向声音的判别和切换。
上述系统还包括叠加模块,用于对前向波束和后向波束进行加权叠加,得到最终的目标语音信号为out=a1*a1+a2*a2;其中,a1=snr1/(snr1+snr2);a2=snr2/(snr1+snr2);snr1为前向波束a1的信噪比;snr2为后向波束a2的信噪比。
作为一个发明构思,本发明还提供了一种音频设备,其包括:
前麦克风,靠近0°角度方向,输出前麦克风信号;
后麦克风,靠近180°角度方向,输出后麦克风信号;
处理模块,用于利用所述前麦克风信号和后麦克风信号形成前向波束和后向波束,并计算所述前向波束的信噪比和后向波束的信噪比,最后根据所述前向波束的信噪比和后向波束的信噪比实现前向声音和后向声音的判别和切换。
所述处理模块还执行如下操作:对前向波束和后向波束进行加权叠加,得到最终的目标语音信号为out=a1*a1+a2*a2;其中,a1=snr1/(snr1+snr2);a2=snr2/(snr1+snr2);snr1为前向波束a1的信噪比;snr2为后向波束a2的信噪比。
当采用麦克风组合形成波束时,如果麦克风的灵敏度存在差异,对形成波束的效果会有很大的影响,为了形成指向性比较稳定的波束,需要使得两路麦克风的相位,灵敏度一致性比较高。但是生产中,很难保证麦克风在焊接和长时间使用以后,还有比较高的一致性,那么,需要在算法上自适应校准。因此,本发明在形成前向波束和后向波束之前,所述处理模块还执行如下操作:计算前麦克风和后麦克风在各个频段内的能量,统计前麦克风和后麦克风长时间的稳定性,并进行补偿,使得前麦克风和后麦克风的频率响应特性一致。
为了防止使用时间太长以后,出现产品失效,若有一路麦克风失效,则选择正常工作的一路麦克风作为输出。
与现有技术相比,本发明所具有的有益效果为:
1、本发明将现有技术中的“前向波束能量与后向波束能量”之比改成前向波束信噪比与后向波束信噪比的大小对比,从而能够防止大的噪声环境影响到方向判别的结果;
2、本发明采用加权的方式对波束进行叠加,因此使得前后向波束的切换更加平滑;
3、采用加权方法,当目标说话人的方向出现变化的时候,该方法能够快速地跟踪说话人的声音方位的变化,而且能够相对快速地跟踪说话人方位的变化,不会出现由于说话人方向变化时由于波束切换导致出现的杂音现象;而且不需要像常规的波束形成算法一样,需要加入一个声源定位模块,因而更加稳定,波束切换的渐变性也更加平滑;
4、对两路麦克风各频段内的能量进行补偿,使得各路麦克风的频率响应特性一致,从而可以形成指向性比较稳定的波束,保证产品的性能;
5、在一路麦克风失效后,选择正常工作的一路麦克风作为输出,从而防止产品使用时间太长以后失效。
附图说明
图1是前向波束形成原理图;
图2是前向心形波束示意图;
图3是后向波束形成原理图;
图4是后向心形波束示意图。
图5是现有的双通道智能音频信号处理原理框图。
具体实施方式
如图1,定义靠近0度角度的麦克风为前麦克风信号,靠近180度角度方向的麦克风为后麦克风信号。当延时t=d/c(例如0.1s)时,用前麦克延时t后的信号减去后麦克延时t后的信号,则刚好形成一个指向前麦克风的心形波束。
前麦克风信号减去后麦克风信号延时t之后的信号,得到一个指向前麦克风的心形波束(如图2所示),该波束即本发明所指的前向波束。
如图3和图4所示,当延时t=d/c时,用后麦克延时t后的信号减去前麦克延时t后的信号,则刚好形成一个指向前麦克风的心形波束,即后麦克风信号减去前麦克风信号延时t之后的信号,得到一个指向后麦克风的心形波束(如图2所示),该波束即本发明所指的后向波束。
当已经形成了前向后向两路波束以后,设计切换策略,从而使得助听器佩戴者能够实现对于前向声音和后向声音的自然切换。
为了提升在嘈杂环境中的判断准确率,本发明将“前向波束能量与后向波束能量”之比改成前向波束信噪比(即信号与噪声的比例)与后向波束信噪比的大小对比,从而能够防止大的噪声环境影响到方向判别的结果。
信噪比的计量单位是db,其计算方法是10lg(ps/pn),其中ps和pn分别代表信号和噪声的有效功率,也可以换算成电压幅值的比率关系:20lg(vs/vn),vs和vn分别代表信号和噪声电压的“有效值”。在音频放大器中,我们希望的是该放大器除了放大信号外,不应该添加任何其它额外的东西。因此,信噪比应该越高越好。本实施例中,可以采用cn103813227a中的方法提高麦克风的信噪比,本发明的麦克风也可以采用cn103813227a公开的麦克风。实际使用过程中,一般可以用94dbspl(音压电平位准)减去内部噪声强度来计算麦克风的信噪比。
本实施例中,若前向波束的信噪比大于后向波束的信噪比,则判定为前向声音;若前向波束的信噪比小于后向波束的信噪比,则判定为后向声音。
为了使得前向后向波束的切换更加平滑,可以考虑根据信噪比的能量大小,采用加权的方式,对波束进行叠加。定义第一路波束(例如前向波束)a1的信噪比为snr1,第二路波束(例如后向波束)a2信噪比为snr2。那么,加权因子计算公式如下:
a1=snr1/(snr1+snr2);
a2=snr2/(snr1+snr2)。
得到上述信息以后,可以根据得到的加权因子,对形成的两路波束进行加权叠加,输出最终的目标语音信号。
最终输出的信号为out=a1*a1+a2*a2。
例如,若第一路波束的信噪比为80db,第二路波束的信噪比为75db,则判定为前向声音。a1=80/(80+75)≈0.52;a2=75/(80+75)≈0.48,则最终输出的信号为out=0.52*a1+0.48*a2。
采用该加权方法的优点在于,当目标说话人的方向出现变化的时候,该方法能够快速地跟踪说话人的声音方位的变化,而且能够相对快速地跟踪说话人方位的变化,不会出现由于说话人方向变化时,常规波束方法中由于波束切换导致出现的杂音现象。而且不像常规的波束形成算法,需要加入一个声源定位模块,因而本发明的方法更加稳定,波束切换的渐变性也更加平滑。
当采用麦克风组合形成波束时,如果麦克风的灵敏度存在差异,对形成波束的效果会有很大的影响,为了形成指向性比较稳定的波束,需要使得两路麦克风的相位,灵敏度(代表麦克风将声音能量转换成电压后所产生的输出信号强度,是在麦克风声压激励下输出电压与输入声压的比值。当输入信号固定时,例如为1khz时,输出信号越强,代表麦克风灵敏度越高)一致性比较高。但是生产中,很难保证麦克风在焊接和长时间使用以后,还有比较高的一致性,那么,需要在算法上自适应校准。基本思路是,自适应计算两路麦克在各个频段内的能量,统计其长时间(例如24小时以上)的稳定性,并且进行补偿,使得各路麦克风的频率响应特性一致。然后再做延时相减和延时相加算法。
通过实际测量得到麦克风的频率响应曲线(频率响应又称带宽,是指麦克风感应声波频率的范围,并将声波能量真实地转换为电子讯号的能力,麦克风接收到不同频率声音时,输出信号会随着频率的变化而发生放大或衰减),在算法中针对测量得到的麦克风频率响应曲线进行修订,使得两路麦克风频率响应相同。从而能够更好的保证产品的性能。
同时,为了防止使用时间太长以后,出现产品失效,加入保护模块,当算法监测到在使用过程中有其中一路麦克风确认失效,那么退回到单麦克风的算法。选择正常工作的那一路麦克风作为输出。例如,当判断出前向麦克风失效时,则选择后向麦克风的信号作为输出。
- 还没有人留言评论。精彩留言会获得点赞!