一种收集、分析猪的发声行为的方法和系统与流程
本发明属于畜禽养殖智能化工艺及设备、声音信号处理技术领域,特别涉及一种收集、分析猪的发声行为的方法和系统。
背景技术:
目前,我国的养猪业正朝着规模化、集约化方向发展,传统的农民散养模式已逐渐淡出历史舞台,规模化养猪能够降低养殖成本,增加养猪企业的利润空间,提高其竞争力,同时又为养殖各个环节的管理、疾病预防等带来挑战。随着传感器、人工智能、大数据、机器学习等现代科学技术的发展,将人工智能技术赋能养猪业,实现所谓的智能养猪,已成为养猪业发展的一种趋势。
目前,已有一些研究人员将人工智能技术应用于养猪的研究,例如,利用机器视觉识别猪的行为、估重、目标跟踪,利用猪的发声来判断其健康状况、打架等行为。
猪床是生猪养殖过程中使用的一个重要设备,猪的生长过程中,有大部分时间将在猪床上度过,猪对温度、湿度等环境指标具有一定的敏感性,因此,一些研究人员提出了能够测量猪床温度,并通过加热、湿帘冷却等方式控制温度的方法,提高了养猪的福利化水平。
由于猪有许多时间在猪床上度过,因此,如果能够收集猪在猪床上的行为数据,就能够为猪行为的智能识别提供数据支撑。而目前的猪床一般仅限于对温度的感知与控制,缺乏对猪行为的感知能力。
发声是猪的一种重要行为,能反映猪的不同行为状态。例如通过声音,能判断猪的生病、求偶、打架等行为。如果能够收集猪在猪床上的发声数据,将能够对基于声音的猪行为智能识别提供数据支持。因此,本发明提出一种收集、分析猪的发声行为的方法和系统。
技术实现要素:
本发明目的是提供一种收集、分析猪的发声行为的方法和系统,通过猪床来收集猪床本体内猪发出的声音数据,进而对猪的行为特征进行智能分析,为猪行为的智能识别和智能养猪技术提供技术支撑。
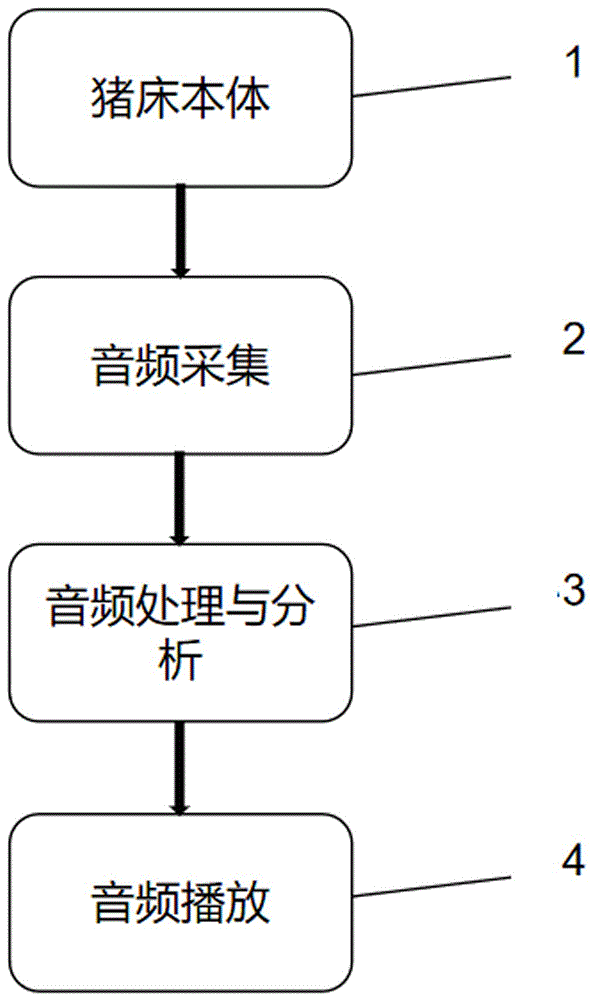
为解决上述技术问题本发明提供了一种收集、分析猪的发声行为的系统,包括依次连接的:猪床本体模块,用于猪在休息时进行躺卧,以及对猪监测的场所;音频采集模块,用于对猪床本体内猪发出的声音数据的采集;音频处理与分析模块,用于对音频数据进行收集储存,并对音频数据进行处理分析;音频播放模块,对收集到的音频文件进行播放。
所述的猪床本体模块由底板、顶板、侧板、床帘构成,底板左右侧以及后侧设置有侧板,侧板上端连接有顶板,顶板的前端设置有吊帘,猪可通过吊帘进出猪床本体。
所述的音频采集模块由话筒构成,话筒采集猪床本体内猪发出的声音,并将音频文件传送给音频处理与分析模块。
所述的音频处理与分析模块由计算机硬件及软件系统构成,计算机硬件包括信号接收模块、储存硬盘,软件系统由音频保存、行为标注、时间规整、加窗滤波、频域变换、模型训练和评价功能模块构成。
所述的音频播放模块由音箱构成,音箱用来播放接收到的音频文件。
所述的软件部分中的音频保存模块将信号接收模块接收到的音频文件保存至本地硬盘;行为标注模块提供对猪发声行为标注的人机接口,供领域专家对保存的猪发声音频所表示的猪的行为类别进行标注;时间规整模块从已标注的音频中提取预设帧数的音频片段;加窗滤波模块将时间规整模块提取的每个时域音频片段,按照预设的窗口和步长进行卷积处理;频域变换模块使用离散序列快速傅里叶变换将每个音频片段的卷积结果变换至频域,得到与卷积结果等长的频谱序列,每个频谱序列的类别即为与其对应的时域音频片段类别;模型训练和评价模块将所有的频谱序列及其类标签组成的频域数据集按照一定的比例随机拆分为互斥的训练集和测试集,选择分类模型,使用训练集训练分类模型,使用测试集对训练的模型进行测试,根据测试结果评价训练的分类模型的性能。
本发明还提供了一种收集、分析猪的发声行为的方法,包括:
S1:在猪床本体内安装话筒,话筒安装在猪不能触碰到且能够采集猪床本体内全部区域猪的声音的位置,通过话筒完成对猪声音信息的采集,并将话筒采集到的声音信息传递给计算机硬件;
S2:信号接收模块将音频文件进行接收,同时使用音箱进行播放音频文件,音频保存模块将音频文件存放在储存硬盘中,通过软件部分中的行为标注模块对猪发声行为进行标注,时间规整模块从已标注的音频中提取预设帧数的音频片段,将音频文件截取为相同时长的音频片段,由加窗滤波模块将时间规整模块提取的每个时域音频片段,按照预设的窗口和步长进行卷积处理;
S3:通过频域变换模块使用离散序列快速傅里叶变换将每个音频片段的卷积结果变换至频域,得到与卷积结果等长的频谱序列,每个频谱序列的类别即为与其对应的时域音频片段类别,将每个频谱序列和与之对应的音频文件的标注一起,建立猪发声行为的频域数据库;
S4:由模型训练和评价模块将频域数据库按照一定的比例随机拆分为互斥的训练集和测试集,使用训练集训练分类模型,然后再使用训练好的分类模型预测测试集的音频样本类别,将预测结果与真实结果对比,评价分类模型的性能;
S5:改变分类模型的类型、结构、参数,重复步骤S4,直至模型性能满足要求。
所述的步骤S4包括:
S41:模型训练和评价模块将频域数据库按照一定的比例随机拆分为互斥的训练集和测试集;
S42:使用训练集训练分类模型,使用训练好的分类模型预测测试集的样本类别,获得一组预测结果序列;
S43:将预测结果与真实结果对比,考察分类准确率、召回率、f1分数,评价分类模型的性能。
本发明的一种收集、分析猪的发声行为的方法和系统,采用猪床本体内设置的话筒采集猪在猪床本体内的发声数据,并将采集到的音频存放到储存硬盘中,再将音频文件传送给软件系统,由软件系统对音频文件进行处理分析,并根据猪发声的音频数据建立分类模型,该分类模型可以根据提供的音频数据对猪的行为进行标注识别(例如:通过声音,能判断猪的生病、求偶、打架等行为),为基于声音的猪行为智能识别提供数据支持。
附图说明
图1为本发明的一种收集、分析猪的发声行为的系统模块组成示意图。
图2为本发明的一种收集、分析猪的发声行为的系统结构示意图。
图3为本发明的一种收集、分析猪的发声行为的方法中的音频采集模块、音频处理与分析模块、音频播放模块之间工作流程示意图。
图4为本发明的一种收集、分析猪的发声行为的方法中一个猪叫声的时域波形图。
图5为本发明的一种收集、分析猪的发声行为的方法中将图4的一维卷积(即滤波)结果图。
图6为本发明的一种收集、分析猪的发声行为的方法中将图5的卷积结果加窗分帧和快速傅里叶变换得到的频谱图。
图7为本发明的一种收集、分析猪的发声行为的方法中截取的图4的2秒时长音频片段时域波形图。
图8为本发明的一种收集、分析猪的发声行为的方法中将图7一维卷积(即滤波)的结果。
图9为本发明的一种收集、分析猪的发声行为的方法中将图8的卷积结果加窗分帧和快速傅里叶变换得到的频谱图。
具体实施方式
实施例1,如图1、图2所示,一种收集、分析猪的发声行为的系统,包括依次连接的:猪床本体模块1,用于猪在休息时进行躺卧,以及对猪监测的场所,猪床本体模块1由底板、顶板、侧板、床帘构成,底板采用20mm厚密度板,左、右、后3个侧板采用12mm厚密度板,顶板采用12mm厚度中空塑料板,底板左右侧以及后侧设置有侧板,侧板上端连接有顶板,顶板的前端设置有吊帘,吊帘优选为PVC条形吊帘,猪床本体的长、宽、高尺寸可根据实际需要定制,猪可通过吊帘进出猪床本体。音频采集模块2,用于对猪床本体内猪发出的声音数据的采集,采集的音频文件格式为wav,采样率为22050帧/秒,音频采集模块2由话筒构成,话筒可以设置有多个,以保证能够完全采集到猪床本体内猪发出的声音,话筒安装位置优选为顶板下表面,话筒与计算机相连接,实时采集猪床本体内的声音,并将音频文件传送给音频处理与分析模块3;音频处理与分析模块3,用于对音频数据进行收集储存,并对音频数据进行处理分析,音频处理与分析模块3由计算机硬件及软件系统构成,计算机硬件包括信号接收模块、储存硬盘,软件系统使用Python编程语言和TensorFlow,Wave,Numpy,Struct,SciPy,Matplotlib等API开发,由音频保存、行为标注、时间规整、加窗滤波、频域变换、模型训练和评价功能模块构成;软件系统中的音频保存模块将信号接收模块接收到的音频文件保存至本地硬盘,并通过音频播放模块4,对收集到的音频文件进行播放;行为标注模块提供对猪发声行为标注的人机接口,供领域专家对保存的猪发声音频所表示的猪的行为类别进行标注;时间规整模块从已标注的音频中提取预设帧数的音频片段(采样率不变时即为等长时间的音频片段);加窗滤波模块将时间规整模块提取的每个时域音频片段,按照预设的窗口和步长进行卷积(即滑动滤波)处理;频域变换模块使用离散序列快速傅里叶变换将每个音频片段的卷积结果变换至频域,得到与卷积结果等长的频谱序列,每个频谱序列的类别即为与其对应的时域音频片段类别,所有的频谱序列和与之对应的音频文件的标注组成频域数据库;模型训练和评价模块将所有的频谱序列和与之对应的音频文件的标注一起组成的频域数据库按照一定的比例随机拆分为互斥的训练集和测试集,选择分类模型,使用训练集训练分类模型,使用测试集对训练的模型进行测试,根据测试结果评价训练的分类模型的性能;音频播放模块4,对收集到的音频文件进行播放,音频播放模块4由音箱构成,音箱用来播放接收到的音频文件。
实施例2,如图3—9所示一种收集、分析猪的发声行为的方法,包括:
S1:在猪床本体内安装话筒,话筒安装在猪不能触碰到的位置,话筒可以设置多个以保证能够采集猪床本体内全部区域猪的声音,话筒安装位置优选为猪床本体的顶板上,这样可以保证猪床本体内猪发出的声音能够清晰地被采集到,通过话筒完成24小时对猪声音信息的采集,采集的音频文件格式为wav,采样率为22050帧/秒,并实时将话筒采集到的音频文件传递给计算机硬件;
S2:信号接收模块将音频文件进行接收,同时使用音箱进行播放音频文件,音频保存模块将音频文件存放在储存硬盘中,一个猪叫声时域波形如图4所示;通过软件部分中的行为标注模块对猪的行为(例如:咳嗽、饥饿、求偶等)进行标注,时间规整模块从已标注的音频中提取预设帧数的音频片段,将所有音频文件截取为2s时长的音频片段,一个截取的声音片段如图7所示;由加窗滤波模块将时间规整模块提取的每个时域音频片段,按照预设的窗口和步长进行卷积处理,对每个音频片段,以20ms时长所对应的帧数(220帧)作为窗口大小,窗函数选择平均值,以0.5窗口大小(110帧)作为步长,对音频片段进行滑动滤波,得到一个离散数值序列,如图8所示;
S3:通过频域变换模块使用离散序列快速傅里叶变换将每个音频片段的卷积结果变换至频域,得到一个元素数量与其相同的频谱序列,对图8的滤波结果的快速傅里叶变换结果如图9所示;每个频谱序列的类别即为与其对应的时域音频片段类别,将每个频谱序列和与之对应的音频文件的标注(例如:0代表咳嗽、1代表饥饿、2代表求偶)一起,建立猪发声行为的频域数据库;
S4:由模型训练和评价模块将频域数据库按照8:2的比例随机拆分为互斥的训练集和测试集,使用训练集训练分类模型,获得一组预测结果序列,分类模型优选为朴素贝叶斯分类模型,然后再使用训练好的分类模型预测测试集的音频样本类别,将预测结果与真实结果对比,评价分类模型的性能;
S5:改变分类模型的类型、结构、参数,重复步骤S4,直至模型性能满足要求。如果f1分数不小于0.9,则接受该分类模型,否则,调整分类模型的类型、参数,返回步骤S4,重复上述操作,直至f1分数大于等于0.9。
所述的步骤S4包括:
S41:模型训练和评价模块将频域数据库按照8:2的比例随机拆分为互斥的训练集和测试集;
S42:使用训练集训练分类模型,分类模型优选为朴素贝叶斯分类模型,使用训练好的分类模型预测测试集的样本类别,获得一组预测结果序列;
S43:将预测结果与真实结果对比,考察分类准确率、召回率、f1分数,评价分类模型的性能。
本发明的一种收集、分析猪的发声行为的方法和系统,通过猪床本体内设置的话筒采集猪在猪床本体内发出的音频信号,并将采集到的音频文件存放到储存硬盘中,再将音频文件传送给软件系统内的行为标注模块,对猪发声行为进行标注,时间规整模块从已标注的音频中提取预设帧数的音频片段,将音频文件截取为相同时长的音频片段,由加窗滤波模块将时间规整模块提取的每个时域音频片段,按照预设的窗口和步长进行卷积处理;通过频域变换模块建立猪行为的频域数据库,由模型训练和评价模块对音频文件进行处理分析,并根据猪的行为训练分类模型,该发明通过收集大量的猪床本体内猪的行为数据,用以对猪发出的各种声音进行行为分析标注,使分类模型能够更加迅速准确地识别猪的行为,该分类模型可以根据猪发出的声音对猪的行为进行标注识别,以便养殖人员及时发现猪的典型行为、各种异常,从而及时、自动、针对性地采取相应的措施,提高养猪的效率,降低养殖成本,提高养猪企业的竞争力,为基于声音的猪行为智能识别提供数据支持。
以上所述仅为本发明的优选实施例而已,并不用以限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!