一种人工智能语音识别装置的制作方法
本发明涉及智能语音识别技术领域,尤其涉及一种人工智能语音识别装置。
背景技术:
人工智能英文缩写为ai,它是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学,而智能语音技术,是实现人机语言的通信,包括语音识别技术和语音合成技术,随着信息技术的发展,智能语音技术已经成为人们信息获取和沟通最便捷、最有效的手段。
在人工智能语音识别技术应用在机器设备上时,虽然利用识别技术可以将使用者发送的语音指令转化为对应的机器语言并转化、输出进行应答,但是在识别和转化过程中,极容易因语音指令的歧义导致指令错误,影响人工智能语音识别装置的正常工作。
技术实现要素:
本发明的目的是为了解决现有技术中的人工智能语音识别技术应用在机器设备上时,虽然利用识别技术可以将使用者发送的语音指令转化为对应的机器语言并转化、输出进行应答,但是在识别和转化过程中,极容易因语音指令的歧义导致指令错误,影响人工智能语音识别装置的正常工作的缺点,而提出的一种人工智能语音识别装置。
为了实现上述目的,本发明采用了如下技术方案:
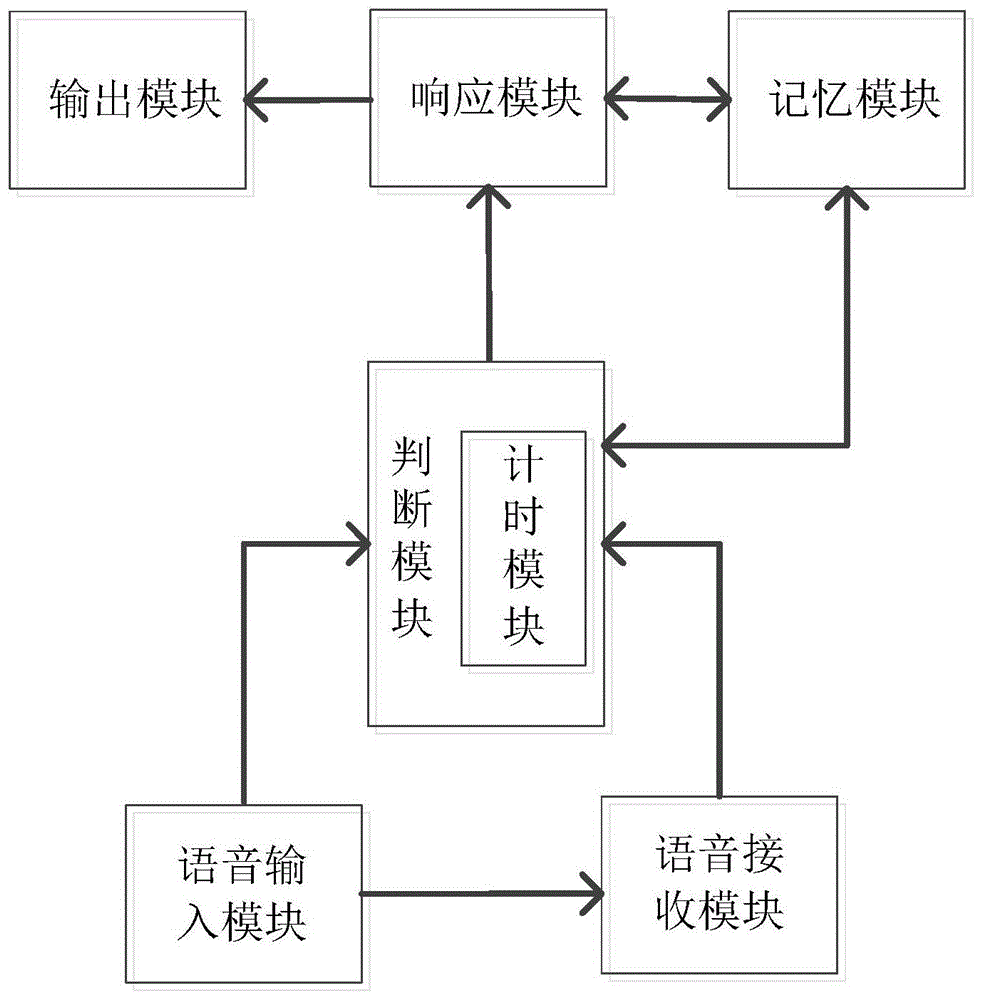
设计一种人工智能语音识别装置,包括依次相连的语音输入模块、语音接收模块、判断模块和响应模块;
输入模块的输出端与语音接收模块的输入端相连,用于接收使用者的语音指令并输送至语音接收模块;
判断模块用于对语音接收模块接收并转化完成的指令进行判断、分析,然后将正确的指令输出至响应模块中,由响应模块对语音指令作出响应。
响应模块的响应数据经输出模块以声或形的形式输出。
优选的,所述响应模块中的过程、结果数据同步输出并储放在记忆模块中,且记忆模块中的数据输出至响应模块和判断模块。
优选的,所述判断模块主要包括计时模块,先进行时间值的预设,在语音输入的过程中,当间隔时间小于或等于预设值,则判定为间歇停顿,当间隔时间大于预设值,则判定为语音指令输入完毕,将接收到的语音指令输出至响应模块中。
优选的,判断模块至少作用于语音输入模块和语音接收模块之一。
优选的,所述响应模块包括回应模块和应答模块,且二者的输出数据均经输出模块输出;
回应模块用于对来自语音接收模块的语音指令再输出和翻译;
应答模块用于对回应模块的指令应答。
本发明提出的一种人工智能语音识别装置,有益效果在于:
在人工智能语音识别系统运行时,通过对语音指令的输入过程进行间隔判断,有效的保证了语音输入指令与接收到的语音指令对应、无误,同时通过应答模块的反馈,进一步保证了该系统运行后输出信息的准确性。
附图说明
图1为本发明的识别系统结构示意图;
图2为本发明的响应模块具体结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。
参照图1-2:
实施例一:
一种人工智能语音识别装置,包括依次相连的语音输入模块、语音接收模块、判断模块和响应模块,输入模块的输出端与语音接收模块的输入端相连,用于接收使用者的语音指令并输送至语音接收模块,判断模块用于对语音接收模块接收并转化完成的指令进行判断、分析,然后将正确的指令输出至响应模块中,由响应模块对语音指令作出响应。
在语音指令经语音输入模块输出至语音接收模块的过程中,判断模块根据语音指令的输入过程进行判断,进一步保证语音指令输出和响应的准确性。
响应模块的响应数据经输出模块以声或形的形式输出,响应模块中的响应结果数据可以语音方式或字幕显示等方式输出,只要保证正常、准确输出即可。
响应模块中的过程、结果数据同步输出并储放在记忆模块中,且记忆模块中的数据输出至响应模块和判断模块,通过将相关数据储放在记忆模块中,便于在后续语音指令输入、输出后进行判断的过程中即时对过往数据进行调用,使记忆模块形成知识库,进一步提高了后续判断模块和响应模块工作的高效性、准确性。
判断模块主要包括计时模块,先进行时间值的预设,在语音输入的过程中,当间隔时间小于或等于预设值,则判定为间歇停顿,当间隔时间大于预设值,则判定为语音指令输入完毕,将接收到的语音指令输出至响应模块中。
通过先进行预设时间的输入,假设预设时间为n,在语音指令输入的过程中,输入间隙小于或等于n继续输入时,判断为同一个语音指令且前后指令之间分隔,当输入间隙大于n时,判断为此语音指令输入完成,直接将数据输出,有效的防止在语音指令输入的过程中连词连句产生歧义,影响系统分析判断的准确性。
判断模块至少作用于语音输入模块和语音接收模块之一,在语音指令输入至运营输入模块的过程中或在语音指令经语音输入模块注入至语音接收模块的过程中,判断模块都可工作,独立工作过程可以保证判断模块的正常进行,同步工作过程近一半保证判断模块判断的准确性。
实施例二,本实施例与实施例一的区别在于:
响应模块包括回应模块和应答模块,且二者的输出数据均经输出模块输出,回应模块用于对来自语音接收模块的语音指令再输出和翻译,应答模块用于对回应模块的指令应答。
在语音指令数据输出至响应模块,响应模块响应的过程中,响应模块中的回应模块首先对接收到的指令翻译后输出,同样的输出形式可以声或形的形式,让使用者对此数据进行再判断,然后将判断无误后数据输出至应答模块,应答模块对接收到的数据进行应答,当使用者判定数据错误时,可直接终止后续应答传输并重新输入更改后的语音指令,从而进一步保证了人工智能语音识别过程的准确性。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
技术特征:
1.一种人工智能语音识别装置,其特征在于,包括依次相连的语音输入模块、语音接收模块、判断模块和响应模块;
输入模块的输出端与语音接收模块的输入端相连,用于接收使用者的语音指令并输送至语音接收模块;
判断模块用于对语音接收模块接收并转化完成的指令进行判断、分析,然后将正确的指令输出至响应模块中,由响应模块对语音指令作出响应。
响应模块的响应数据经输出模块以声或形的形式输出。
2.根据权利要求1所述的一种人工智能语音识别装置,其特征在于:所述响应模块中的过程、结果数据同步输出并储放在记忆模块中,且记忆模块中的数据输出至响应模块和判断模块。
3.根据权利要求1所述的一种人工智能语音识别装置,其特征在于:所述判断模块主要包括计时模块,先进行时间值的预设,在语音输入的过程中,当间隔时间小于或等于预设值,则判定为间歇停顿,当间隔时间大于预设值,则判定为语音指令输入完毕,将接收到的语音指令输出至响应模块中。
4.根据权利要求1至3任一所述的一种人工智能语音识别装置,其特征在于:判断模块至少作用于语音输入模块和语音接收模块之一。
5.根据权利要求1所述的一种人工智能语音识别装置,其特征在于:所述响应模块包括回应模块和应答模块,且二者的输出数据均经输出模块输出;
回应模块用于对来自语音接收模块的语音指令再输出和翻译;
应答模块用于对回应模块的指令应答。
技术总结
本发明涉及智能语音识别技术领域,尤其是一种人工智能语音识别装置,包括依次相连的语音输入模块、语音接收模块、判断模块和响应模块,输入模块的输出端与语音接收模块的输入端相连,用于接收使用者的语音指令并输送至语音接收模块,判断模块用于对语音接收模块接收并转化完成的指令进行判断、分析,然后将正确的指令输出至响应模块中,由响应模块对语音指令作出响应。在人工智能语音识别系统运行时,通过对语音指令的输入过程进行间隔判断,有效的保证了语音输入指令与接收到的语音指令对应、无误,同时通过应答模块的反馈,进一步保证了该系统运行后输出信息的准确性。
技术研发人员:张国发
受保护的技术使用者:安徽仁昊智能科技有限公司
技术研发日:2019.12.27
技术公布日:2020.04.28
- 还没有人留言评论。精彩留言会获得点赞!