融合深度语言生成模型的语言表达能力评价方法和系统与流程
本发明涉及,尤其是一种融合深度语言生成模型的语言内容表达能力评价方法,以及融合深度语言生成模型的语言内容表达能力评价系统。
背景技术:
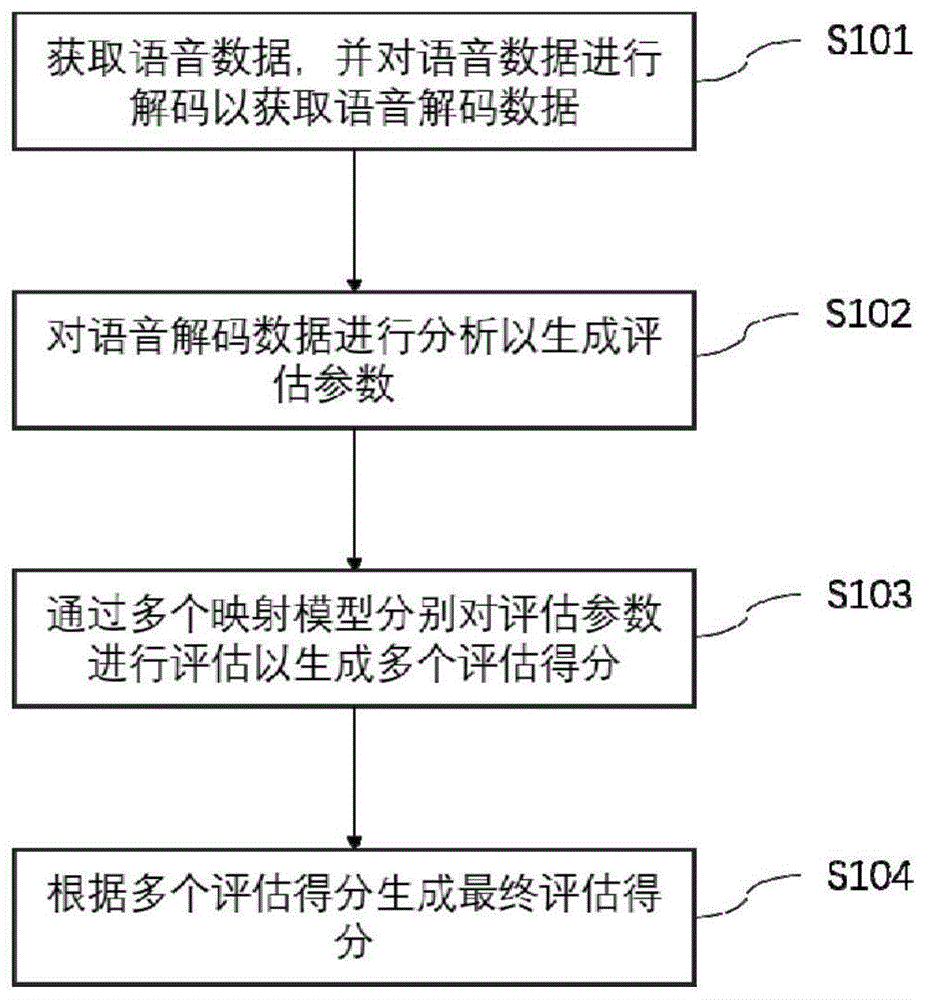
:语言内容评价是语言学习中的一个重要的过程,其不仅针对学习者的发音进行评价,还对学习者的内容表述进行评价。在传统的评价方式中,语言内容评价由语言专家对学习者的发音及表达的内容做出人工的评价。但是,这种方式效率较低,对评价专家要求较高,评价成本也随之提高。此外,评价过程主要依赖于专家个人,导致评价标准难以统一,评价结果也缺乏客观性。目前,市场中许多语言培训机构使用语言内容评价来评估学习者的语言能力。这使得语言培训机构需要聘请大量语言专家,来对学习者的语言能力进行评价。但是,目前市场中没有通用可行的评估标准,语言专家的数量不足等因素,导致了市场中的语言内容评价既昂贵又不足够客观、准确。随着深度学习和语音识别技术的快速发展,一些研究已经可以有效的进行语言识别,可以准确的识别不同的讲话人,并且可以对不同讲话人发音进行打分。使用人工智能的技术降低语言能力评价的人工成本并提高评估的客观性成为了当前市场中的重要需求。现有技术方案的构造:目前,大多数语音评测方法是基于传统的映射模型以确定用户的语音内容,并依据此内容计算声学、语言学特征,然后使用某一通用模型,运用上述信息和特征计算最终评测结果。中国专利文献cn104464757a公开了一种语音评测方法和语音评测装置。其方法流程如图1所示。语音评测方法包括获取语音数据,并对语音数据进行解码以获取语音解码数据、对语音解码数据进行分析以生成评估参数、通过多个映射模型分别对评估参数进行评估以生成多个评估得分、根据多个评估得分生成最终评估得分四个步骤来评估用户的发音好坏。该方法存在以下缺陷:语言评估的成本较高,评分不够客观不够准确。不能模拟语言专家对各类语言进行评价。中国专利文献cn1835076b公开了一种综合运用语音识别,语音学知识及汉语方言分析的语音评测方法。该方法针对地方语言进行了特别处理,建立了针对语音评测的标准数据库(包括单词的标准发音、连续语流的标准发音),在此标准数据库上使用隐马尔科夫模型的语音识别器。该方法针对汉语特点进行分析,并引入了对不同语种的分析,普适性较强,但仍然存在以下缺陷:系统构造成本高,语音评测的标准数据库构造具有较大的人工成本,在评价技术上进行了有针对性的改进,但评价模式依然以打分为主,在语言学习教育的意义上没有进行改进提升。中国专利文献cn105632488a公开了一种语音评测方法,该方法旨在减少在语音评测的评分中出现失误的问题。该方法提高了评分的准确度和可信度,最终可生成所述分数对应的雷达图,但仍需要测评人员进行人工分析给出最终的评分,不能解决目前市场中由于语言专家缺失带来的语言学习困难的问题。技术实现要素:本发明的发明目的在于:针对上述存在的问题,提供一种融合深度语言生成模型的语言内容表达能力评价方法。以及一种融合深度语言生成模型的语言内容表达能力评价系统。以通过低成本的系统构造,在无人工干预的情况下,准确、客观地对学习者的语言表达能力进行评价。本发明采用的技术方案如下:一种融合深度语言生成模型的语言内容表达能力评价方法,包括以下步骤:a.第一模型的训练步骤:对音频数据样本进行特征提取,得到音频特征;对音频数据对应的评语进行分词,并对分词结果进行词向量化处理,得到词向量;将音频特征和对应的词向量输入lstm模型进行训练;b.第二模型的训练步骤:将步骤a中得到的词向量和对应的评语输入lstm模型进行训练;c.将待测评的音频数据依次经过步骤a、b所训练的模型,得到评价结果。进一步的,所述步骤a中对音频数据样本进行特征提取的步骤包括:采用mfcc特征提取技术或隐马尔科夫模型对音频数据进行特征提取。进一步的,采用mfcc特征提取技术对音频数据进行特征提取的方法包括:使用mfcc特征提取技术提取所述音频数据每一步长的mfcc特征参数;将若干mfcc特征参数进行合并,得到mfcc特征即为所求。进一步的,所述mfcc特征由18个mfcc特征参数合并而成。进一步的,所述采用mfcc特征提取技术对音频数据进行特征提取的方法还包括:使用三层lstmp对所述mfcc特征进行分析,其中,分析过程使用mse损失函数。一种融合深度语言生成模型的语言内容表达能力评价系统,包括第一模型和第二模型,第一学习模型的输出层连接第二学习模型的输入层;所述第一模型的训练过程包括:对音频数据样本进行特征提取,得到音频特征;对音频数据对应的评语进行分词,并对分词结果进行词向量化处理,得到词向量;将音频特征和对应的词向量输入lstm模型进行训练;所述第二模型的训练过程包括:将第一模型训练过程中得到的词向量和对应的评语输入lstm模型进行训练。进一步的,所述第一模型训练过程中,对音频数据样本进行特征提取的方法为:采用mfcc特征提取技术或隐马尔科夫模型对音频数据进行特征提取。进一步的,采用mfcc特征提取技术对音频数据进行特征提取的方法包括:使用mfcc特征提取技术提取所述音频数据每一步长的mfcc特征参数;将若干mfcc特征参数进行合并,得到mfcc特征即为所求。进一步的,所述mfcc特征由18个mfcc特征参数合并而成。进一步的,所述采用mfcc特征提取技术对音频数据进行特征提取的方法还包括:使用三层lstmp对所述mfcc特征进行分析,其中,分析过程使用mse损失函数。综上所述,由于采用了上述技术方案,本发明的有益效果是:1、本发明的方案构造简单,构建成本低。训练时间与样本数量大致成线性关系,因此具有较强的可扩展性。2、本发明的方法能够对学习者的语言表达进行客观、准确地评价。3、本发明方案的整体响应时间在500ms左右,响应快速。附图说明本发明将通过例子并参照附图的方式说明,其中:图1是现有技术中的语音评测方法流程图。图2是本发明的语言表达能力评价方法流程图。图3是图2流程所对应的任务处理流程图。图4是音频特征提取过程流程图。图5是预测模型训练模型。图6是响应时间与训练样本量间关系的折线图。具体实施方式本说明书中公开的所有特征,或公开的所有方法或过程中的步骤,除了互相排斥的特征和/或步骤以外,均可以以任何方式组合。本说明书(包括任何附加权利要求、摘要)中公开的任一特征,除非特别叙述,均可被其他等效或具有类似目的的替代特征加以替换。即,除非特别叙述,每个特征只是一系列等效或类似特征中的一个例子而已。实施例一本实施例公开了一种融合深度语言生成模型的语言内容表达能力评价方法,其包括:a.学习模型的训练步骤:对音频数据样本进行特征提取,得到音频特征;对音频数据对应的评语进行分词,并对分词结果进行词向量化处理,得到词向量;将音频特征和对应的词向量输入lstm模型进行训练。b.评估模型的训练步骤:将步骤a中得到的词向量和对应的评语输入lstm模型进行训练。c.将待测评的音频数据依次经过步骤a、b所训练的模型。如图2所示,上述流程可概括为步骤s201-s204:通过学习模型对待测音频数据进行特征提取并生成对应的评估参数,评估模型对评估参数进行评估,以生成语言内容评价(评语),即得到最终的评价结果。实施例二本实施例公开了一种融合深度语言生成模型的语言内容表达能力评价方法。如图3所示,该方法利用两个独立的循环人工神经网络完成评价,其一是音频数据与评价内容的映射关系的学习模型,另一个为评价内容与自然语言评价的映射关系的学习模型。1、音频数据与评语词向量的映射关系的学习模型的设计本模型以lstm模型作为基础,将音频数据的音频特征,以及对应于该音频数据的评价内容的词向量作为样本进行训练。其中,就需要先获取到样本数据,包括音频数据的音频特征,以及对应的词向量。对于音频数据的音频特征的提取,如图4所示,本实施例利用mfcc特征提取技术和lstmp相结合的方法对学习者音频数据的音频特征进行提取。mfcc为一种在自动语音和说话人识别中广泛使用的特征。为了减小计算量,提高音频特征准确率,本实施例中将多个时间步长的mfcc特征参数合并,得到更具代表性的mfcc特征。如果在合并时间步长时出现阙值不足的情况,使用0进行补足。具体而言,首先获取学习者音频数据,输入的音频在mel频谱上进行倒频谱分析,提取每个时间步长的特征。该过程还包括对声谱图的每帧进行短时fft计算、语音频谱图的倒频谱分析、mel频率分析、mel频率倒谱系数计算,得到mfcc特征参数。在此基础上,将多个时间步长的mfcc特征参数的合并,得到mfcc特征。在一个实施例中,将18个时间步长的mfcc特征参数合并为1个mcff特征。通过三层lstmp对提取的mfcc特征进一步分析,提高音频特征的识别率,最终得出更有效的音频特征向量。在这一阶段,本实施例使用了mse(均方误差)损失函数,对音频分类进行评分,提高音频分类的准确性。针对mfcc在噪声情况下的识别效果急剧下降的情况,本发明采用了深度神经网络自适应技术中批量梯度下降算法,在低维固定长度中压缩表示了说话人特征最重要的信息。为了减少矩阵的参数量,引用了三层lstmp进行音频特征的提取。当然,上述对语音数据的音频特征提取也可采用隐马尔科夫模型或其它音频特征提取工具进行。对于音频数据所对应的评语,首先进行分词处理,再对分词后的结果进行词向量化处理,得到音频内容评论所对应的词向量。如图5所示,最后将音频特征和对应的词向量利用lstm模型进行训练,完成音频数据与评价内容的映射关系的构建。训练后的分类模型在输入音频数据后,会映射出相关词向量形成评语词汇表。此过程完成了评语词汇的输出。2、词向量与评语的映射关系的学习模型的设计该模型将模型1中产生的词向量和对应的完整的评语作为样本输入到lstm模型进行训练,完成词向量与自然语言评语的映射关系的构建。词向量由模型1中产生,对应的自然语言评语为采集的样本数据。训练完成的模型可通过词向量生成对应的自然语言组成的评语。例如模型1中输出的词向量传递给本模型,本模型根据训练阶段形成的映射关系,找出每个词向量对应的自然语言组成评论并输出。在本模型的训练过程中,将输入的词向量对应生成评论的数字向量,然后根据对应的词汇表,找出每个数字所对应的自然语言词汇组成评语并输出。本模型基于多层传统lstm单元的累积,根据模型1生成的词汇表,找出数字向量对应的自然语言组成评语输出。为了能够输出准确度高、语句通顺的评语,本发明通过预训练的模型获得特征训练自然语言生成模型。该模型借鉴了图片标记问题的解决方法,选用长短期记忆模型作为预训练模型,其具有存储记忆功能,它的记忆指的是在一个序列中,记忆在不同的时间步中传播。长短期记忆模型解决了在传统的rnn中,当训练时间比较长时,需要回传的残差会使指数下降,网络权重更新缓慢的问题。本模型采用word层级生成文本,输入足够评语数据进行训练,lstm具有存储记忆功能,可以预测下一个单词。模型定义了每个句子的开头和结尾的词语<开始>和<结束>,在lstm发出<结束>词语时就形成了一个完整的句子例如,源序列是包含[<开始>]、‘语言’、‘标准’、‘感情’、‘饱满’、‘表述’、‘流畅’]而目标序列是一个包含[‘语言’、‘标准’、‘感情’、‘饱满’、‘表述’、‘流畅’、‘<结束>’]的序列,比如“您的语言较为标准,感情丰富,但表述不够流畅,需要多加练习”,这就是最终得到的符合预定规则的最终评语。实施例三本实施例公开了上述模型中所使用的样本数据的采集方法。模型的训练需要一定规模的音频数据,在真实的社交媒体上找到高匹配性的各类语言音频有一定难度,因此,本发明采用人工的方式进行音频数据收集,并进行模型的训练与不同程度的测试。本实施例中,可以设计评测用卷让不同的志愿者朗读,同步采集朗读者的音频数据,并将对应的专家评语一起作为训练样本。所收集的音频数据可以为通用的mp3压缩格式。本发明所能用到的数据集较多,各类语言不可枚举。考虑到语音收录进程中可能遇到的地点不确定、环境不确定等问题,本实施例使用高保真的移动音频收录设备进行收集。如下表为本实施例训练和测试音频数据的统计表:训练集测试集普通话15926方言214情感丰富577情感欠缺12323表述流畅10316表述不够流畅7714为了训练上述两个模型,本实施例中收集了不同人的音频数据,同时,将收集的音频数据交予专业的语言专家进行测评,从音频的语言的标准程度、感情饱满程度和流畅程度等方面分别进行评价,并分别针对各方面给出评语。训练样本的收集对于训练效果有着很大的影响,本发明通过统一的格式收集专家评语,其具有客观性,且从原始端规避了样本格式的差异,因此,所采集的样本具有较强的有效性。实施例四本实施例对本发明方法的响应时间进行多次测试,以验证本发明响应的及时性。本发明从收集的样本库中随机选取(例如使用rand函数选取)了5个编号的音频数据,利用本发明的方法(模型)进行测试,相应的响应时间如下表所示:音频编号192329228学习模型(ms)512343455399497预测模型(ms)2020221922总时长(ms)534364478419520由上表可以看出,模型1的响应时间在300~600ms范围内;模型2的响应时间在20ms左右,总时长约在500ms。同时,本实施例还在可扩展性方面进行了分析。如图6所示,为模型训练时间复杂度随着训练集数量的增多而随之变化的折线图。由图6可以看出,随着训练集样本数量的线性增长,响应时间增长趋势基本呈线性,由此可以验证本发明方法在真实环境下具有通用性,可扩展性强。实施例五参见附图2、3,本实施例公开了一种融合深度语言生成模型的语言内容表达能力评价方法。该方法包括学习模型训练过程、预测模型训练过程和目标音频评价过程。1、学习模型训练过程对音频数据样本进行音频特征提取。在一个实施例中,使用mfcc技术提取学习者音频数据的音频特征。对音频数据对应的评语样本进行分词处理,并对分词结果进行向量化处理,得到对应的词向量。此时,模型接收的学习者音频数据、评语数据对已转化为音频特征、评语词向量数据对。将音频特征和对应的词向量输入到lstm模型进行训练。从而完成学习模型的训练过程。在学习模型训练完成后,学习模型接收一段学习者的音频数据,首先提取语音的音频特征,经过训练的lstm将该音频特征映射到对应的评语词向量。在本实施例中,音频特征提取更关注输入音频的声学特征,对语言学特征不做分析。声学特征可包括音高、音长、音强和音色;语言学特征信息可包括但不仅限于语言、语法、词汇、语义等。在接收学习者音频数据后,可以使用现有的音频分析技术对语音进行分析以获得不同音频对应的特征。例如,先获取学习者音频数据,首先进行音频特征的提取,换句话说音频特征提取是指把音频信号中具有辨识性的成分提取出来然后把其他无用信息去掉,例如背景噪声,情绪等等。对于音频数据和对应评语的收集,参见实施例三。2、预测模型训练过程将学习模型训练过程中得到的评语的词向量和对应的评语输入到lstm模型进行训练。完成预测模型训练过程。训练完成的预测模型可通过词向量生成对应的自然语言评语。例如将学习模型输出的词向量传递给预测模型,即可得到对应的评语。预测模型采用单词层级生成文本,输入足够评语进行训练,预测模型中使用的lstm模型具有存储记忆功能,可以预测下一个单词。模型定义了每个句子的开头和结尾的词语<开始>和<结束>,在lstm发出<结束>词语时就形成了一个完整的句子例如,源序列是包含[<开始>]、‘语言’、‘标准’、‘感情’、‘饱满’、‘表述’、‘流畅’]而目标序列是一个包含[‘语言’、‘标准’、‘感情’、‘饱满’、‘表述’、‘流畅’、‘<结束>’]的序列,比如“您的语言较为标准,感情丰富,但表述不够流畅,需要多加练习”,这就是最终得到的符合预定规则的最终评价。3、将待测音频数据依次经过学习模型和预测模型,得到对应的评语。最终生成的评语的评价指标如下表所示:评价指标评论语言标准xxxxxxxx标书流畅xxxxxxx情感表达xxxxxxx……xxxxxxx……xxxxxxx实施例六本实施例公开了一种融合深度语言生成模型的语言内容表达能力评价系统,其包括学习模型和预测模型,学习模型的输出层连接预测膜层的输入层(即学习模型的输出作为预测模型的输入)。学习模型的训练过程包括:对音频数据样本进行特征提取,得到音频特征。对于音频数据的音频特征的提取,如图4所示,本实施例利用mfcc特征提取技术和lstmp相结合的方法对学习者音频数据的音频特征进行提取。mfcc为一种在自动语音和说话人识别中广泛使用的特征。为了减小计算量,提高音频特征准确率,本实施例中将多个时间步长的mfcc特征参数合并,得到更具代表性的mfcc特征。如果在合并时间步长时出现阙值不足的情况,使用0进行补足。具体而言,首先获取学习者音频数据,输入的音频在mel频谱上进行倒频谱分析,提取每个时间步长的特征。该过程还包括对声谱图的每帧进行短时fft计算、语音频谱图的倒频谱分析、mel频率分析、mel频率倒谱系数计算,得到mfcc特征参数。在此基础上,将多个时间步长的mfcc特征参数的合并,得到mfcc特征。在一个实施例中,将18个时间步长的mfcc特征参数合并为1个mcff特征。通过三层lstmp对提取的mfcc特征进一步分析,提高音频特征的识别率,最终得出更有效的音频特征向量。在这一阶段,本实施例使用了mse(均方误差)损失函数,对音频分类进行评分,提高音频分类的准确性。针对mfcc在噪声情况下的识别效果急剧下降的情况,本发明采用了深度神经网络自适应技术中批量梯度下降算法,在低维固定长度中压缩表示了说话人特征最重要的信息。为了减少矩阵的参数量,引用了三层lstmp进行音频特征的提取。当然,上述对语音数据的音频特征提取也可采用隐马尔科夫模型或其它音频特征提取工具进行。然后,对音频数据对应的评语进行分词,并对分词结果进行词向量化处理,得到词向量。最后,将音频特征和对应的词向量输入lstm模型进行训练。预测模型的训练过程包括:将学习模型训练过程中得到的词向量和对应的评语输入lstm模型进行训练。为了能够输出准确度高、语句通顺的评语,本发明通过预训练的模型获得特征训练自然语言生成模型。该模型借鉴了图片标记问题的解决方法,选用长短期记忆模型作为预训练模型,其具有存储记忆功能,它的记忆指的是在一个序列中,记忆在不同的时间步中传播。长短期记忆模型解决了在传统的rnn中,当训练时间比较长时,需要回传的残差会使指数下降,网络权重更新缓慢的问题。本模型采用word层级生成文本,输入足够评语数据进行训练,lstm具有存储记忆功能,可以预测下一个单词。模型定义了每个句子的开头和结尾的词语<开始>和<结束>,在lstm发出<结束>词语时就形成了一个完整的句子例如,源序列是包含[<开始>]、‘语言’、‘标准’、‘感情’、‘饱满’、‘表述’、‘流畅’]而目标序列是一个包含[‘语言’、‘标准’、‘感情’、‘饱满’、‘表述’、‘流畅’、‘<结束>’]的序列,比如“您的语言较为标准,感情丰富,但表述不够流畅,需要多加练习”,这就是最终得到的符合预定规则的最终评语。本发明并不局限于前述的具体实施方式。本发明扩展到任何在本说明书中披露的新特征或任何新的组合,以及披露的任一新的方法或过程的步骤或任何新的组合。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1