基于自注意力机制的语音活动检测方法、装置及存储介质与流程
本发明涉及语音处理技术领域,尤其涉及一种基于自注意力机制的语音活动检测方法、装置及存储介质。
背景技术:
vad(voiceactivitydetection,语音活动检测),又称语音端点检测,是指在噪声环境中检测语音存在与否,通常应用于语音编码、语音活动检测等语音等处理系统中,起到降低语音编码速率、节省通信带宽、减少移动设备能耗、提高识别率和算法性能等作用。vad算法的准确性对语音前端算法十分关键,传统的vad算法通常包括两个部分:特征提取和语音/非语音判决,常用的特征提取分为五类:基于能量、频域、倒普、谐波、和长时信息;语音/非语音判决则根据各自提取的特征的特性进行设计,常用的有根据门限、长时包络、基频等。但是传统vad算法往往对环境和信噪比依赖性较大,准确性也无法得到保证,十分不利应用于实时会议通信设备中。
近年来,由于深度学习的发展,开始出现了利用深度学习进行vad检测的技术。相对于传统算法,深度学习的非线性拟合能力极强,而且较为成熟的深度学习模型如rnn、lstm和gru等也十分适用于音频信号这种序列型输入数据。现有技术深度学习的参数规模和计算开销通常较大,直接使用小模型又使得算法的稳定性和效果得不到保障,因此很难应用于实时会议通信设备。
技术实现要素:
本发明实施例提供的一种基于自注意力机制的语音活动检测方法及装置,能够有效提高语音活动检测的效果,且能够有效提高语音活动检测的稳定性和可靠性。
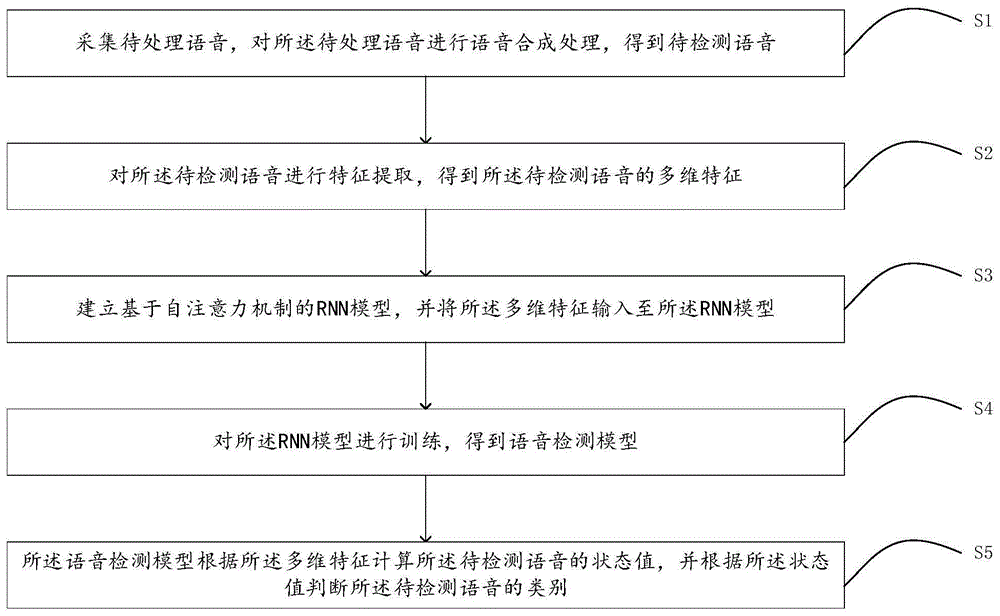
为解决上述问题,一方面,本发明的一个实施例提供了一种基于自注意力机制的语音活动检测方法,包括:
采集待处理语音,对所述待处理语音进行语音合成处理,得到待检测语音;
对所述待检测语音进行特征提取,得到所述待检测语音的多维特征;
建立基于自注意力机制的rnn模型,并将所述多维特征输入至所述rnn模型;
对所述rnn模型进行训练,得到语音检测模型;
所述语音检测模型根据所述多维特征计算所述待检测语音的状态值,并根据所述状态值判断所述待检测语音的类别。
进一步地,所述待处理语音包括纯净语音和原始噪声;所述采集待处理语音,对所述待处理语音进行语音合成处理,得到待检测语音,具体为:
采集纯净语音以及不同场景的原始噪声,根据预设的筛选规则对所述原始噪声进行筛选,得到常规噪声;对所述纯净语音和所述常规噪声进行语音合成处理,得到待检测语音。
进一步地,所述对所述待检测语音进行特征提取,得到所述待检测语音的多维特征,具体为:
对所述待检测语音进行加窗分帧处理并进行快速傅里叶变换,并计算每帧待检测语音的幅度谱;
通过采用巴尔刻度将所述幅度谱平均分为22个子频带,并计算每一所述子频带的对数谱;
分别对所述对数谱进行一阶差分计算和二阶差分计算,得到一阶差分数值和二阶差分数值;
将所述22个子频带、所述一阶差分数值和所述二阶差分数值进行串联得到所述待检测语音的66维特征。
进一步地,所述对所述rnn模型进行训练,得到语音检测模型,具体为:
采用adam训练策略和loss函数对所述rnn模型进行训练,得到语音检测模型。
进一步地,所述语音检测模型根据所述多维特征计算所述待检测语音的状态值,并根据所述状态值判断所述待检测语音的类别,具体为:
所述语音检测模型根据所述多维特征计算所述待检测语音的状态值,并将所述状态值与预设阈值进行比对,若所述状态值小于所述预设阈值,则判断所述待检测语音为非语音信号;若所述状态值大于或等于所述预设阈值,则判断所述待检测语音为语音信号。
另一方面,本发明的另一实施例提供了一种基于自注意力机制的语音活动检测装置,包括语音合成模块、特征提取模块、特征输入模块、训练模块和语音检测模块;
所述语音合成模块,用于采集待处理语音,对所述待处理语音进行语音合成处理,得到待检测语音;
所述特征提取模块,用于对所述待检测语音进行特征提取,得到所述待检测语音的多维特征;
所述特征输入模块,用于建立基于自注意力机制的rnn模型,并将所述多维特征输入至所述rnn模型;
所述训练模块,用于对所述rnn模型进行训练,得到语音检测模型;
所述语音检测模块,用于所述语音检测模型根据所述多维特征计算所述待检测语音的状态值,并根据所述状态值判断所述待检测语音的类别。
又一方面,本发明的又一实施例提供了一种计算机可读存储介质,所述计算机可读存储介质包括存储的计算机程序,其中,在所述计算机程序运行时控制所述计算机可读存储介质所在设备执行如上述的基于自注意力机制的语音活动检测方法。
本发明实施例提供的一种基于自注意力机制的语音活动检测方法、装置及存储介质,通过对待处理语音进行语音合成处理得到待检测语音,并将所述待检测语音进行特征提取得到多维特征,能够有效避免噪声对待检测语音的影响,能够有效提高语音活动检测的效果;通过对rnn模型进行模型训练得到语音检测模型,并将所述多维特征输入到语音检测模型中计算所述待检测语音的状态值,并根据所述状态值判断所述待检测语音的类别。本发明实施例采用较小的模型实现语音活动检测,能够有效解决深度学习模型参数规模和计算开销过大导致的无法应用部署至实时会议通信设备的问题,且采用自注意力机制能够有效提高语音活动检测的稳定性和可靠性。
附图说明
图1是本发明实施例提供的一种基于自注意力机制的语音活动检测方法的流程示意图;
图2是本发明实施例提供的一种基于自注意力机制的语音活动检测方法步骤s2的流程示意图;
图3是本发明实施例提供的一种基于自注意力机制的语音活动检测方法的rnn模型结构示意图;
图4是本发明实施例提供的一种基于自注意力机制的语音活动检测方法的另一流程示意图;
图5是本发明实施例提供的一种基于自注意力机制的语音活动检测装置的结构示例图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参阅图1-4:
本发明的第一实施例。
本发明实施例提供了一种基于自注意力机制的语音活动检测方法,包括:
s1、采集待处理语音,对待处理语音进行语音合成处理,得到待检测语音;
在本发明实施例中,待处理语音包括纯净的语音和原始噪声,其中纯净的语音可以通过声音采集设备在消音室进行采集,噪声可以通过声音采集设备在不同的场景进行采集,不同的场景包括火车站、街道、公园、篮球场、体育场、办公室和铃声等,且在噪声采集完成后对采集到的噪声根据预设的筛选条件进行筛选,得到符合场景的常见噪声数据,能够有效提高语音合成处理的效率,从而能够得到更准确的待检测语音,进而能够有效提高语音活动检测的效果。
s2、对待检测语音进行特征提取,得到待检测语音的多维特征;
s3、建立基于自注意力机制的rnn(recurrentneuralnetworks,循环神经网络)
模型,并将多维特征输入至rnn模型;
s4、对rnn模型进行训练,得到语音检测模型;
s5、语音检测模型根据多维特征计算待检测语音的状态值,并根据状态值判断待检测语音的类别。
在本发明实施例中,可以理解的是,本发明实施例的声音采集设备包括麦克风和信号转换器,麦克风用于采集纯净的语音和原始噪声,信号转换器用于将不同场景环境中的声学信号转换成适合计算的数字信号;采用存储有计算程序的存储器;采用处理器执行程序得到语音活动检测模型和语音活动检测模型的计算;采用可传发数据的网络系统对计算数据进行传输;采用存储器对语音模型参数进行存储;采用终端进行处理后的音频数据播放。本发明实施例通过对待处理语音进行语音合成处理得到待检测语音,并将待检测语音进行特征提取得到多维特征,能够有效避免噪声对待检测语音的影响,能够有效提高语音活动检测的效果;建立基于自注意力机制的rnn模型,通过对rnn模型进行模型训练得到语音检测模型,并将多维特征输入到语音检测模型中计算待检测语音的状态值,并根据状态值判断待检测语音的类别。本发明实施例采用较小的模型实现语音活动检测,能够有效解决深度学习模型参数规模和计算开销过大导致的无法应用部署至实时会议通信设备的问题,且采用自注意力机制能够有效提高语音活动检测的稳定性和可靠性。
作为本发明实施例的一种具体实施方式,待处理语音包括纯净语音和原始噪声;采集待处理语音,对待处理语音进行语音合成处理,得到待检测语音,具体为:
采集纯净语音以及不同场景的原始噪声,根据预设的筛选规则对原始噪声进行筛选,得到常规噪声;对纯净语音和常规噪声进行语音合成处理,得到待检测语音。
在本发明实施例中,待处理语音包括纯净的语音和原始噪声,其中纯净的语音可以通过声音采集设备在消音室进行采集,噪声可以通过声音采集设备在不同的场景进行采集,不同的场景包括火车站、街道、公园、篮球场、体育场、办公室和铃声等,且在噪声采集完成后对采集到的噪声根据预设的筛选条件进行筛选,得到符合场景的常见噪声数据,能够有效提高语音合成处理的效率,从而能够得到更准确的待检测语音,进而能够有效提高语音活动检测的效果。
本发明实施例语音合成公式如下:
smix=α×sclean+β×n
其中,smix为合成的待检测语音,sclean为纯净语音,n为噪声,α为纯净语音的衰减系数,0.3≤α≤1;β为噪声的衰减系数,0.3≤β≤1;优选地,本实施例中α=0.5,β=0.6。
请参阅图2,在本发明实施例中,对待检测语音进行特征提取,得到待检测语音的多维特征,具体为:
s21、对待检测语音进行加窗分帧处理并进行快速傅里叶变换,并计算每帧待检测语音的幅度谱;
s22、通过采用巴尔刻度将幅度谱平均分为22个子频带,并计算每一子频带的对数谱;
s23、分别对对数谱进行一阶差分计算和二阶差分计算,得到一阶差分数值和二阶差分数值;
s24、将22个子频带、一阶差分数值和二阶差分数值进行串联得到待检测语音的66维特征。
请参阅图4,为本发明实施例提供的一种基于自注意力机制的语音检测方法的另一流程示意图。
作为本发明实施例的一种具体实施方式,对rnn模型进行训练,得到语音检测模型,具体为:
采用adam训练策略和loss函数对rnn模型进行训练,得到语音检测模型。
在本发明实施例中,请参阅图3,为本发明实施例提供的rnn模型结构图。其中,atttention层的计算公式如下:
其中hk和hq分别为gru(hk)以及gru(hq)的输出,score(.)为相关性得分,表达式如下:
score(hk,hq)=hktwhq
其中,w为hk和hq的权重。
本发明实施例通过将66维特征输入至基于自注意力机制的rnn模型,再采用adam训练策略和loss函数进行训练得到语音检测模型;其中,模型学习率为0.0001。本发明实施例中的loss函数的公式如下:
k2=k1×log(thread)/log(1-thread)
其中,wbcmin(x)i为加权二值交叉熵,k1和k2为加权系数,thread为阈值,在本发明实施例中thread取0.5,k1取30。
本发明实施例adam训练策略公式如下:
mt=μ×mt-1+(1-μ)×gt
其中,gt为梯度,mt为梯度的一阶动量,mt-1为在t-1时刻梯度的一阶动量,nt为梯度的二阶动量,nt-1为在t-1时刻梯度的二阶动量,
本发明的语音检测模型的参数包括input层(输入层)与dense(全连接层)层的权重和偏置、dense层与gru(gatedrecurrentunit,门控循环单元)层的权重和偏置,gru层和attention层(注意力层)的权重和偏置,attention联合gru层和output层(输出层)的权重和偏置;根据模型结构设计并优化前向算法,具体为根据权重数量与各个层之间的连接情况定义同等大小的数组,并根据dense层、gru层和attention层的神经元的输入输出设计对应数据结构储存参数,从而可以存储至存储器中,进而可以部署在实时会议通信设备中。本发明实施例通过语音检测模型对待检测语音进行计算并检测,能够有效提高语音活动检测的检测率,且本发明实施例的语音检测模型鲁棒性高,在同等效果小,能够有效降低参数的规模,从而能够有效提高语音检测的稳定性和可靠性。
作为本发明实施例的一种具体实施方式,语音检测模型根据多维特征计算待检测语音的状态值,并根据状态值判断待检测语音的类别,具体为:
语音检测模型根据多维特征计算待检测语音的状态值,并将状态值与预设阈值进行比对,若状态值小于预设阈值,则判断待检测语音为非语音信号;若状态值大于或等于预设阈值,则判断待检测语音为语音信号。
在本发明实施例中,计算得到的待检测语音的状态值在[0,1]范围,本发明实施例预设阈值设定为0.5,若状态值小于0.5,则判断待检测语音为非语音信号,若状态值大于等于0.5,则判断待检测语音为语音信号。
实施本发明实施例,具有以下有益效果。
在本发明实施例中,可以理解的是,本发明实施例的声音采集设备包括麦克风和信号转换器,麦克风用于采集纯净的语音和原始噪声,信号转换器用于将不同场景环境中的声学信号转换成适合计算的数字信号;采用存储有计算程序的存储器;采用处理器执行程序得到语音活动检测模型和语音活动检测模型的计算;采用可传发数据的网络系统对计算数据进行传输;采用存储器对语音模型参数进行存储;采用终端进行处理后的音频数据播放。本发明实施例通过对待处理语音进行语音合成处理得到待检测语音,并将待检测语音进行特征提取得到多维特征,能够有效避免噪声对待检测语音的影响,能够有效提高语音活动检测的效果;建立基于自注意力机制的rnn模型,通过对rnn模型进行模型训练得到语音检测模型,并将多维特征输入到语音检测模型中计算待检测语音的状态值,并根据状态值判断待检测语音的类别。本发明实施例采用较小的模型实现语音活动检测,能够有效解决深度学习模型参数规模和计算开销过大导致的无法应用部署至实时会议通信设备的问题,且采用自注意力机制能够有效提高语音活动检测的稳定性和可靠性。
请参阅图5:
本发明的第二实施例。
本发明实施例提供了一种基于自注意力机制的语音检测装置,包括语音合成模块10、特征提取模块20、特征输入模块30、训练模块40和语音检测模块50;
语音合成模块10,用于采集待处理语音,对待处理语音进行语音合成处理,得到待检测语音;
特征提取模块20,用于对待检测语音进行特征提取,得到待检测语音的多维特征;
特征输入模块30,用于建立基于自注意力机制的rnn模型,并将多维特征输入至rnn模型;
训练模块40,用于对rnn模型进行训练,得到语音检测模型;
语音检测模块50,用于语音检测模型根据多维特征计算待检测语音的状态值,并根据状态值判断待检测语音的类别。
实施本发明实施例,具有以下有益效果:
在本发明实施例中,可以理解的是,本发明实施例的声音采集设备包括麦克风和信号转换器,麦克风用于采集纯净的语音和原始噪声,信号转换器用于将不同场景环境中的声学信号转换成适合计算的数字信号;采用存储有计算程序的存储器;采用处理器执行程序得到语音活动检测模型和语音活动检测模型的计算;采用可传发数据的网络系统对计算数据进行传输;采用存储器对语音模型参数进行存储;采用终端进行处理后的音频数据播放。本发明实施例通过语音合成模块10对待处理语音进行语音合成处理得到待检测语音,并通过特征提取模块20将待检测语音进行特征提取得到多维特征,能够有效避免噪声对待检测语音的影响,能够有效提高语音活动检测的效果;通过训练模块40建立基于自注意力机制的rnn模型,通过对rnn模型进行模型训练得到语音检测模型,并将多维特征输入到语音检测模型中通过语音检测模块50计算待检测语音的状态值,并根据状态值判断待检测语音的类别。本发明实施例采用较小的模型实现语音活动检测,能够有效解决深度学习模型参数规模和计算开销过大导致的无法应用部署至实时会议通信设备的问题,且采用自注意力机制能够有效提高语音活动检测的稳定性和可靠性。
本发明的第三实施例提供了一种计算机可读存储介质,计算机可读存储介质包括存储的计算机程序,其中,在计算机程序运行时控制计算机可读存储介质所在设备执行如上述的基于自注意力机制的语音活动检测方法。
以上是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!