情绪推断装置、情绪推断方法、及存储介质与流程
本发明涉及情绪推断装置、情绪推断方法、及存储介质。
背景技术:
使用机动车等移动体的乘员发出的语音数据或表示发声内容的文本数据来推断乘员的情绪的技术正在推进研究。另一方面,已知有在使用多个辨别器从图像中辨别人物的服装或辨别人物的轮廓时,使用早期融合(earlyfusion)或晚期融合(latefusion),将各辨别器的输出结果合并的技术(例如,参照专利文献1)。
在先技术文献
专利文献
专利文献1:日本特开2009-140283号公报
技术实现要素:
发明概要
发明要解决的课题
然而,在现有技术中,由于用户的周围的噪音或其他的用户的声音而语音的识别精度有时会下降。其结果是,用户的情绪的推断精度有时会下降。
本发明的形态在于提供能够提高用户的情绪的推断精度的情绪推断装置、情绪推断方法、及存储介质。
用于解决课题的方案
本发明的情绪推断装置、情绪推断方法及存储介质采用了以下的结构。
(1)本发明的一形态涉及一种情绪推断装置,其具备:第一获取部,其获取用户发出的语音数据;第二获取部,其获取对通过所述第一获取部获取到的语音数据进行了文本化的文本数据;第一推断部,其将基于通过所述第一获取部获取到的语音数据的指标值和基于通过所述第二获取部获取到的文本数据的指标值利用第一融合进行合并,基于所述合并后的指标值,来推断所述用户的情绪;及第二推断部,其将表示所述第一推断部的推断结果的指标值与基于通过所述第二获取部获取到的文本数据的指标值利用第二融合进行合并,基于所述合并后的指标值,来推断所述用户的情绪。
(2)的形态以上述(1)的形态的情绪推断装置为基础,所述情绪推断装置还具备:输出部,其输出信息;及输出控制部,其使所述输出部输出基于通过所述第二推断部推断出的所述用户的情绪的信息。
(3)的形态以上述(1)或(2)的形态的情绪推断装置为基础,所述第二推断部基于所述第二融合的结果,来推断所述用户的情绪是正面的第一情绪、还是负面的第二情绪、或者是并非所述第一情绪及所述第二情绪的任一个的中性的第三情绪。
(4)的形态以上述(3)的形态的情绪推断装置为基础,在表示所述第一推断部的推断结果的指标值与基于通过所述第二获取部获取到的文本数据的指标值之和为第一阈值以上的情况下,所述第二推断部推断所述用户的情绪为所述第一情绪,在表示所述第一推断部的推断结果的指标值与基于通过所述第二获取部获取到的文本数据的指标值之和为比所述第一阈值小的第二阈值以下的情况下,所述第二推断部推断所述用户的情绪为所述第二情绪,在表示所述第一推断部的推断结果的指标值与基于通过所述第二获取部获取到的文本数据的指标值之和小于所述第一阈值且超过所述第二阈值的情况下,所述第二推断部推断所述用户的情绪为所述第三情绪。
(5)的形态以上述(1)~(4)中任一形态的情绪推断装置为基础,所述情绪推断装置还具备提取部,该提取部从通过所述第一获取部获取到的语音数据中提取一个以上的特征量,所述第二获取部导出对所述文本数据所表示的文本的整体性的情绪进行了数值化的第一指标值和表示所述文本所包含的情绪性的内容的量的第二指标值,所述第一推断部将通过所述第二获取部导出的所述第一指标值及所述第二指标值与通过所述提取部提取出的一个以上的所述特征量利用所述第一融合进行合并。
(6)的形态以上述(5)的形态的情绪推断装置为基础,所述第一推断部将通过所述第二获取部导出的所述第一指标值及所述第二指标值作为要素追加到分别以通过所述提取部提取出的一个以上的所述特征量为要素的多维数据中,来作为所述第一融合。
(7)的形态以上述(1)~(6)中的任一形态的情绪推断装置为基础,所述第一获取部还获取表示所述用户驾驶的车辆的驾驶操作历史的驾驶操作历史数据和拍摄了所述用户的图像数据,所述第一推断部将基于通过所述第一获取部获取到的语音数据的指标值、基于通过所述第二获取部获取到的文本数据的指标值、基于通过所述第一获取部获取到的驾驶操作历史数据的指标值、基于通过所述第一获取部获取到的图像数据的指标值利用所述第一融合进行合并,基于所述合并后的指标值,来推断所述用户的情绪。
(8)本发明的另一形态涉及一种情绪推断方法,该情绪推断方法使计算机进行如下处理:获取用户发出的语音数据;获取对所述获取到的语音数据进行了文本化的文本数据;将基于所述语音数据的指标值与基于所述文本数据的指标值利用第一融合进行合并,基于所述合并后的指标值,来推断所述用户的情绪;将表示基于通过所述第一融合合并后的指标值的所述用户的情绪的推断结果的指标值与基于所述文本数据的指标值利用第二融合进行合并,基于所述合并后的指标值,来推断所述用户的情绪。
(9)本发明的另一形态涉及一种计算机可读的存储介质,该介质存储有程序,该程序用于使计算机执行如下处理:获取用户发出的语音数据;获取对所述获取到的语音数据进行了文本化的文本数据;将基于所述语音数据的指标值与基于所述文本数据的指标值利用第一融合进行合并,基于所述合并后的指标值,来推断所述用户的情绪;及将表示基于通过所述第一融合合并后的指标值的所述用户的情绪的推断结果的指标值与基于所述文本数据的指标值利用第二融合进行合并,基于所述合并后的指标值,来推断所述用户的情绪。
发明效果
根据(1)~(9)的形态,能够提高用户的情绪的推断精度。
附图说明
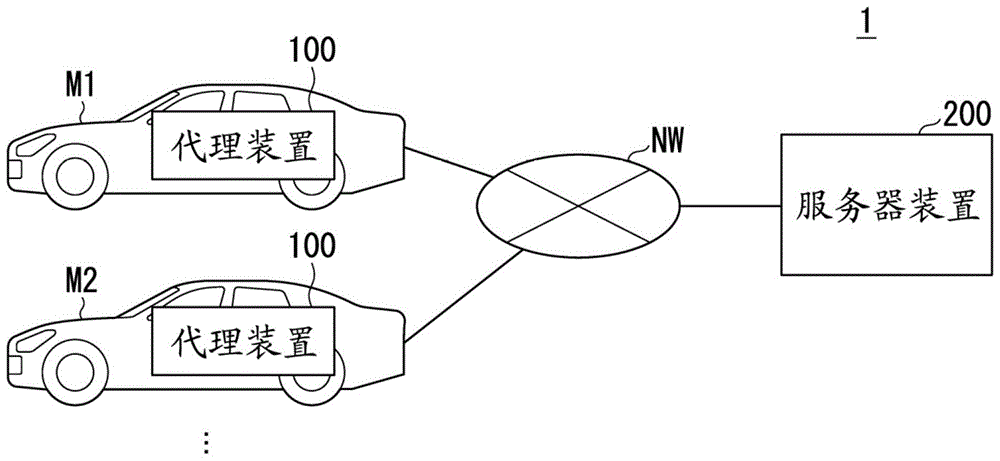
图1是表示第一实施方式的代理系统的结构的一例的图。
图2是表示第一实施方式的代理系统的一系列的处理的流程的时序图。
图3是表示第一实施方式的代理装置的结构的一例的图。
图4是表示从驾驶位观察的车辆的车室内的一例的图。
图5是表示从上方观察的车辆的车室内的一例的图。
图6是表示第一实施方式的代理装置的一系列的处理的流程的流程图。
图7是表示显示部显示的图像的一例的图。
图8是表示显示部显示的图像的一例的图。
图9是表示第一实施方式的服务器装置的结构的一例的图。
图10是用于说明第一实施方式的早期融合的图。
图11是用于说明第一实施方式的晚期融合的图。
图12是表示第一实施方式的服务器装置的一系列的处理的流程的流程图。
图13是表示第一实施方式的代理装置的另一例的图。
图14是表示第二实施方式的代理装置的结构的一例的图。
图15是用于说明第二实施方式的早期融合的图。
图16是表示第三实施方式的代理系统的结构的一例的图。
图17是表示终端装置的结构的一例的图。
图18是表示终端侧控制部的功能结构的一例的图。
附图标记说明
1…代理系统,100…代理装置,102…代理侧通信部,104…麦克风,106…扬声器,108…显示部,110…输入部,112…驾驶操作检测部,114…驾驶员监视相机,116…车辆传感器,120…代理侧存储部,130…代理侧控制部,132…第一获取部,134…语音合成部,136…输出控制部,138…通信控制部,200…服务器装置,202…服务器侧通信部,210…服务器侧存储部,230…服务器侧控制部,232…第一获取部,234…发声期间提取部,236…语音识别部,238…特征量提取部,240…第一推断部,242…第二推断部,244…通信控制部,246…学习部,300…终端装置,302…终端侧通信接口,304…终端侧扬声器,306…终端侧麦克风,308…终端侧显示部,310…终端侧输入部,320…终端侧控制部,330…终端侧存储部。
具体实施方式
以下,参照附图来说明本发明的情绪推断装置、情绪推断方法、及存储介质的实施方式。
<第一实施方式>
[系统结构]
图1是表示第一实施方式的代理系统1的结构的一例的图。第一实施方式的代理系统1例如具备多个代理装置100、服务器装置200。如图示的例子那样,各代理装置100搭载于车辆m。车辆m例如是二轮或三轮、四轮等的车辆。这些车辆的驱动源可以是柴油发动机或汽油发动机等内燃机、电动机、或它们的组合。电动机使用与内燃机连结的发电机产生的发电电力、或者二次电池或燃料电池的放电电力进行动作。
代理装置100与服务器装置200经由网络nw连接成能够通信。网络nw包括lan(localareanetwork:局域网)或wan(wideareanetwork:广域网)等。网络nw可以包括例如wi-fi或bluetooth(注册商标,以下省略)等利用了无线通信的网络。
代理装置100是具有与车辆m的乘员进行语音对话或对乘员彼此的对话进行支援的功能(以下,称为代理功能)的装置。代理功能通过某种具有人工智能的功能的软件代理(智能代理)来实现。
服务器装置200与搭载于各车辆m的代理装置100通信,从代理装置100收集各种数据。服务器装置200通过对收集到的数据进行解析来推断各车辆m的乘员的情绪,并将其推断结果向代理装置100发送。服务器装置200是“情绪推断装置”的一例。
需要说明的是,搭载有代理装置100的移动体并不局限于车辆m,例如,可以是客机或飞艇、直升机等飞行器、或客轮等船舶这样的其他移动体。
[代理系统的时序]
图2是表示第一实施方式的代理系统1的一系列的处理的流程的时序图。首先,代理装置100在乘员发出的语音由麦克风104收集的情况下,从麦克风104获取该收集了的语音的数据(以下,称为语音数据)(步骤s100)。
接下来,代理装置100将获取到的语音数据向服务器装置200发送(步骤s102)。
服务器装置200当从代理装置100接收到语音数据时,基于接收到的语音数据,推断搭载有代理装置100的车辆m的乘员的情绪(步骤s104)。
接下来,服务器装置200将推断了乘员的情绪的推断结果向代理装置100发送(步骤s106)。
接下来,代理装置100当从服务器装置200接收到推断结果时,基于该推断结果,来决定对话的支援形态(步骤s108)。例如,代理装置100根据乘员的情绪的推断结果,来变更对话语音的声压等级或抑扬等,或变更车室内的音乐的选曲,或变更车室内显示的影像或图像。
[代理装置的结构]
图3是表示第一实施方式的代理装置100的结构的一例的图。第一实施方式的代理装置100例如具备代理侧通信部102、麦克风104、扬声器106、显示部108、输入部110、代理侧存储部120、代理侧控制部130。
这些装置或设备可以通过can(controllerareanetwork:控制器局域网络)通信线等多重通信线或串行通信线、无线通信网等相互连接。需要说明的是,图3所示的代理装置100的结构只不过为一例,可以省略结构的一部分,也可以还追加其他的结构。
代理侧通信部102包括nic(networkinterfacecard:网卡)等通信接口。代理侧通信部102经由网络nw而与服务器装置200等通信。
麦克风104是对车室内的语音进行收集的语音输入装置。麦克风104将收集的语音数据向代理侧控制部130输出。例如,麦克风104设置在乘员就座于车室内的座椅时的前方附近。例如,麦克风104可以设置在脚垫灯、方向盘、仪表板或座椅的附近。而且,麦克风104可以在车室内设置多个。
扬声器106例如设置在车室内的座椅附近或显示部108附近。扬声器106基于通过代理侧控制部130输出的信息来输出语音。
显示部108包括lcd(liquidcrystaldisplay:液晶显示器)或有机el(electroluminescence:场致发光)显示器等显示装置。显示部108基于由代理侧控制部130输出的信息来显示图像。
输入部110例如是按钮、键盘或鼠标等用户接口。输入部110受理乘员的操作,将与受理的操作相应的信号向代理侧控制部130输出。输入部110也可以是与显示部108一体构成的触摸面板。
图4是表示从驾驶位观察的车辆m的车室内的一例的图。而且,图5是表示从上方观察的车辆m的车室内的一例的图。在图示的例子的车室内设置有麦克风104、扬声器106、显示部108a~108c。麦克风104例如设置于方向盘,主要对驾驶者发出的语音进行收集。扬声器106例如设置在显示部108b的附近,即,仪表板ip的中央附近。
显示部108a例如是在驾驶者观察车外时的视线的前方显示虚像的hud(head-updisplay:抬头显示器)装置。hud装置例如是通过将光向车辆m的称为前风档玻璃或组合器的具有透光性的透明构件投射而使乘员观察虚像的装置。乘员主要是驾驶者,但也可以是驾驶者以外的乘员。
显示部108b设置于驾驶位(距方向盘最近的座位)的正面附近的仪表板ip,并设置在乘员从方向盘的间隙或越过方向盘能够视觉辨识到的位置。显示部108b例如是lcd或有机el显示装置等。在显示部108b例如显示车辆m的速度、发动机转速、燃料剩余量、散热器水温、行驶距离、其他的信息的图像。
显示部108c设置在仪表板ip的中央附近。显示部108c例如与显示部108b同样是lcd或有机el显示装置等。显示部108c显示电视节目或电影等的内容。
返回图3的说明,代理侧存储部120通过hdd、闪存器、eeprom(electricallyerasableprogrammablereadonlymemory:带电可擦可编程只读存储器)、rom(readonlymemory:只读存储器)或ram(randomaccessmemory:随机存储器)等实现。在代理侧存储部120储存有例如由处理器参照的程序等。
代理侧控制部130例如具备第一获取部132、语音合成部134、输出控制部136、通信控制部138。
这些构成要素例如通过cpu(centralprocessingunit:中央处理器)或gpu(graphicsprocessingunit:图形处理器)等处理器执行程序(软件)来实现。而且,这些构成要素中的一部分或全部可以通过lsi(largescaleintegration:大规模集成电路)或asic(applicationspecificintegratedcircuit:专用集成电路)、fpga(field-programmablegatearray:现场可编程门阵列)等硬件(包括电路部;circuitry:电路)实现,也可以通过软件与硬件的协作实现。程序可以预先储存于代理侧存储部120,也可以储存于dvd或cd-rom等能够拆装的存储介质并通过将存储介质装配于驱动装置而安装于代理侧存储部120。
第一获取部132从麦克风104获取语音数据。
语音合成部134基于代理侧通信部102从服务器装置200接收到的数据,生成人工性的合成语音(以下,称为代理语音)。
当通过语音合成部134生成代理语音或从外部装置获取该代理语音时,输出控制部136使扬声器106输出该代理语音。而且,输出控制部136可以将成为代理语音的源头的句子(文本数据)做成图像而在显示部108显示。
通信控制部138经由代理侧通信部102,将通过第一获取部132获取的语音数据向服务器装置200发送。
[代理装置的处理流程]
以下,使用流程图说明第一实施方式的代理装置100的一系列的处理的流程。图6是表示第一实施方式的代理装置100的一系列的处理的流程的流程图。本流程图的处理可以按照规定的周期反复进行。
首先,第一获取部132判定通过代理侧通信部102是否接收到包含乘员的情绪的推断结果和该情绪推断所利用的表示乘员的语音的发声内容的文本数据在内的情绪推断数据(步骤s200),在判定为通过代理侧通信部102接收到情绪推断数据的情况下,第一获取部132从代理侧通信部102获取情绪推断数据。
语音合成部134当通过第一获取部132获取情绪推断数据时,基于该情绪推断数据所包含的文本数据和情绪推断结果,生成代理语音(步骤s202)。
例如,语音合成部134进行波形连接型语音合成(concatenativesynthesis)和共振峰合成(formantsynthesis),生成读取文本数据所包含的发音记号的代理语音。而且,语音合成部134在文本数据不包含发音记号而包含表示句子的文字列的情况下,可以将该文字列转换成发音记号,生成读取转换后的发音记号的代理语音。在生成代理语音时,语音合成部134根据情绪推断结果,变更代理语音的音程或抑扬、声压等级、读取速度等。例如,在推断乘员的情绪为“愤怒”等负面情绪的情况下,语音合成部134为了使乘员的心情平静,可以减小代理语音的声压等级或延缓读取速度。
接下来,输出控制部136使扬声器106输出由语音合成部134生成的代理语音(步骤s204)。此时,输出控制部136可以使显示部108显示与情绪推断结果相应的图像或影像,也可以选择与情绪推断结果相应的乐曲作为向车室内播放的音乐。
图7及图8是表示显示部108显示的图像的一例的图。例如,输出控制部136可以使乘员发声的发声内容(在图示的例子中为“到目的地还剩多少公里啊”这样的文字列)重叠显示于与乘员的情绪的推断结果相应的背景图像。在推断乘员的情绪为“愤怒”等负面情绪的情况下,输出控制部136如图7所例示那样在表示天气为暴风雨天气的背景图像上重叠显示乘员的发声内容。另一方面,在推断乘员的情绪为“喜悦”等正面情绪的情况下,输出控制部136如图8所例示那样在表示天气为晴好的背景图像上重叠显示乘员的发声内容。而且,输出控制部136可以根据乘员的情绪的推断结果来变更表示乘员的发声内容的文字列的颜色或大小、字体等。
另一方面,第一获取部132在s200的处理中判定为通过代理侧通信部102未接收到情绪推断数据的情况下,判定是否通过麦克风104收集到乘员发出的语音,即,判定乘员是否发声(步骤s206)。
在判定为乘员发声的情况下,通信控制部138经由代理侧通信部102,将通过麦克风104收集的语音数据向服务器装置200发送(步骤s208)。由此本流程图的处理结束。
[服务器装置的结构]
图9是表示第一实施方式的服务器装置200的结构的一例的图。第一实施方式的服务器装置200例如具备服务器侧通信部202、服务器侧存储部210、服务器侧控制部230。
服务器侧通信部202包括nic等通信接口。服务器侧通信部202经由网络nw与搭载于各车辆m的代理装置100等通信。服务器侧通信部202是“输出部”的一例。
服务器侧存储部210通过hdd、闪存器、eeprom、rom或ram等实现。在服务器侧存储部210中,例如除了储存有由处理器参照的程序之外,还储存有情绪辨别模型信息212等。
情绪辨别模型信息212是定义了用于辨别用户情绪的情绪辨别模型mdl的信息(程序或数据结构)。情绪辨别模型mdl是一种当被输入至少包含用户的声音的特征量在内的数据时,进行学习以辨别用户发声时的情绪的模型。
情绪辨别模型mdl例如可以利用dnn(deepneuralnetwork(s):深度神经网络)实现。而且,情绪辨别模型mdl并不局限于dnn,可以通过逻辑回归或svm(supportvectormachine:支持向量机)、k-nn(k-nearestneighboralgorithm:k-最近邻算法)、决策树、朴素贝叶斯分类器、随机森林这样其他的模型来实现。
在情绪辨别模型mdl由dnn实现的情况下,在情绪辨别模型信息212中例如包括:构成情绪辨别模型mdl所包含的各dnn的输入层、一个以上的隐藏层(中间层)、输出层所分别包含的神经元(也称为单元或节点)相互如何耦合这样的耦合信息;向在耦合的神经元间输入输出的数据赋予的耦合系数为多少个这样的加权信息等。耦合信息例如包括:各层所包含的神经元数、指定各神经元的耦合目的地的神经元的种类的信息、实现各神经元的激活函数、在隐藏层的神经元间设置的门等信息。实现神经元的激活函数例如可以是根据输入符号而切换动作的函数(relu(rectifiedlinearunit:修正线性单元)函数或elu(exponentiallinearunits:指数线性单元)函数等),也可以是s型函数、阶跃函数、双曲正切函数,还可以是恒等函数。门例如根据由激活函数返回的值(例如1或0)而使在神经元间传递的数据选择性地通过或加权。耦合系数例如包括:在神经网络的隐藏层中,在从某层的神经元向更深层的神经元输出数据时,对输出数据赋予的加权。而且,耦合系数可以包含各层的固有的偏置分量等。
服务器侧控制部230例如具备第一获取部232、发声期间提取部234、语音识别部236、特征量提取部238、第一推断部240、第二推断部242、通信控制部244、学习部246。语音识别部236是“第二获取部”的一例,通信控制部244是“使输出部输出基于用户的情绪的信息的输出控制部”的一例。
这些构成要素例如通过cpu或gpu等处理器执行程序(软件)来实现。而且,这些构成要素中的一部分或全部可以通过lsi或asic、fpga等硬件(包括电路部;circuitry)实现,也可以通过软件与硬件的协作实现。程序可以预先储存于服务器侧存储部210,也可以储存于dvd或cd-rom等能够拆装的存储介质并通过将存储介质装配于驱动装置(盘式驱动器)而安装于服务器侧存储部210。
第一获取部232经由服务器侧通信部202从代理装置100获取语音数据。
发声期间提取部234从通过第一获取部132获取到的语音数据中,提取乘员发声的期间(以下,称为发声期间)。例如,发声期间提取部234可以利用零交叉法,基于语音数据所包含的语音信号的振幅来提取发声期间。而且,发声期间提取部234可以基于混合高斯分布模型(gmm;gaussianmixturemodel:高斯混合模型),从语音数据中提取发声期间,也可以通过对发声期间特有的语音信号进行模板化的数据库和模板匹配处理,从语音数据中提取发声期间。
语音识别部236按照通过发声期间提取部234提取出的各发声期间来识别语音,通过对识别的语音进行文本化而生成表示发声的内容的文本数据。
例如,语音识别部236将发声期间的语音信号向包含bilstm(bi-directionallongshort-termmemory:双向长短期记忆)或提示机构等在内的循环神经网络输入,由此将语音信号分离成低频率、高频率等多个频率带,得到将该各频率带的语音信号进行了傅里叶变换的频谱(梅尔频谱)。循环神经网络例如可以通过利用教师数据来预先学习,该教师数据为对由学习用的语音生成的频谱,将该学习用的语音信号作为教师标签而建立了对应的数据。
并且,语音识别部236通过向包含多个隐藏层的卷积神经网络输入频谱而从频谱得到文字列。卷积神经网络例如通过利用教师数据来预先学习,该教师数据为对学习用的频谱,将与为了生成该学习用的频谱所使用的语音信号对应的文字列作为教师标签而建立了对应的数据。语音识别部236将从卷积神经网络得到的文字列的数据作为文本数据。
当由语音数据生成文本数据时,语音识别部236将该生成的文本数据向为了分析乘员的情绪而预先学习的dnn输入,由此导出将乘员的情绪进行了数值化的指数(以下,称为情感分析指数ins)。情感分析指数ins是“基于文本数据的指标值”的一例。
情感分析指数ins例如包含:表示作为分析对象的文本的整体性的情绪的得分s、表示文本的整体性的情绪的深度(大小或振幅)的重要性m。例如,文本整体的“愉快”或“高兴”那样的正面的言行越多,则得分s越获取接近+1.0的值,“悲伤”或“烦躁”那样的负面的言行越多,则得分s越获取接近-1.0的值,中性的言行越多,则得分s越获取接近0.0的数值。重要性m通过从-1.0至+1.0的数值范围来表示文本之中叙述情绪性的意见的文字列(串)的数量。在得分s接近0.0的情况下,该文本为中性的言行或者正面的言行与负面的言行为相同程度,表示相互抵消极性的情况。文本之中叙述情绪性的意见的文字列是“内容”的一例。
通常已知在真正中性的文本中,重要性m小,在正面的言行与负面的言行混杂的文本中,重要性m大。因此,即使得分s为接近0.0的值,根据重要性m的值,也能够区分分析对象的文本是真正中性的文本还是正面的言行与负面的言行混杂的文本。得分s是“第一指标值”的一例,重要性m是“第二指标值”的一例。
特征量提取部238从通过发声期间提取部234提取出的各发声期间的语音中,提取乘员的声音的特征量(以下,称为语音特征量f)。语音特征量f是“基于语音数据的指标值”的一例。
语音特征量f例如是zcr(zero-crossingrate:过零率)、rms(rootmeansquare:均方根)、声音的音调的基本频率f0、hnr(harmonics-to-noiseratio:谐波噪声比)、梅尔频率倒谱系数mfcc。而且,语音特征量f可以包括上述的各种指标值的最小值、最大值、标准偏差、平均值、峰度、偏度、相对位置、范围、线性回归系数、均方差等统计值。语音特征量f可以由以上述各种特征量分别为要素的多维向量表示。表示语音特征量f的多维向量是“多维数据”的一例。
第一推断部240将通过特征量提取部238提取出的语音特征量f与通过语音识别部236导出的情感分析指数ins融合为一个,并将其融合结果向情绪辨别模型mdl输入,由此暂时地推断乘员的情绪。以下,将作为情绪辨别模型mdl的输入数据的语音特征量f及情感分析指数ins融合为一个的情况称为“早期融合”进行说明。早期融合是“第一融合”的一例。
图10是用于说明第一实施方式的早期融合的图。例如,第一推断部240作为早期融合,在zcr、rms、f0这样的表示语音特征量f的多维向量中追加情感分析指数ins的得分s和重要性m作为新的要素。由此,向情绪辨别模型mdl输入的输入数据的维数被扩张。
并且,第一推断部240将分别包含作为要素的语音特征量f所包含的各特征量、得分s、重要性m的多维向量(维数增加的多维向量)向通过逻辑回归或dnn等而实现的情绪辨别模型mdl输入。
情绪辨别模型mdl例如当被输入向量时,输出辨别用户的情绪是正面的情绪(第一情绪的一例)、还是负面的情绪(第二情绪的一例)、或者是中性的情绪(第三情绪的一例)的值(以下,称为一次情绪辨别值e)。例如,如果用户的情绪为正面的情绪,则一次情绪辨别值e成为接近+1.0的值,如果用户的情绪为负面的情绪,则一次情绪辨别值e成为接近-1.0的值,如果用户的情绪为中性的情绪,则一次情绪辨别值e成为接近0.0的值。
例如,第一推断部240将与通过情绪辨别模型mdl输出的一次情绪辨别值e对应的情绪暂时推断为发出了作为语音特征量f的提取源的语音的乘员的情绪。
第二推断部242将第一推断部240的推断结果即一次情绪辨别值e与通过语音识别部236导出的情感分析指数ins融合为一个,基于其融合结果,来推断乘员的情绪。以下,将一次情绪辨别值e与情感分析指数ins融合的情况称为“晚期融合”进行说明。晚期融合是“第二融合”的一例。
图11是用于说明第一实施方式的晚期融合的图。例如,第二推断部242求出一次情绪辨别值e与情感分析指数ins的合计值,根据该合计值,将辨别乘员的情绪是正面的情绪、还是负面的情绪、或者是中性的情绪的值(以下,称为二次情绪辨别值c)导出作为乘员的情绪的推断结果。具体而言,第二推断部242基于数学式(1),导出二次情绪辨别值c。
【数学式1】
例如,第二推断部242按照数学式(1),将一次情绪辨别值e与情感分析指数ins所包含的得分s相加时(合并时),在其合计值(e+s)为+1.0以上的情况下,将二次情绪辨别值c设为表示正面的情绪的+1.0,在合计值(e+s)为-1.0以下的情况下,将二次情绪辨别值c设为表示负面的情绪的-1.0,在合计值(e+s)小于+1.0且超过-1.0的情况下,将二次情绪辨别值c设为表示中性的情绪的0.0。+1.0是“第一阈值”的一例,-1.0是“第二阈值”的一例。
通信控制部244将包含第二推断部242的推断结果即二次情绪辨别值c和通过语音识别部236生成的文本数据在内的情绪推断数据经由服务器侧通信部202向代理装置100发送。情绪推断数据是“基于用户的情绪的信息”的一例。
学习部246基于预先准备的教师数据,来学习情绪辨别模型mdl。教师数据是对于从某学习用的语音数据提取出的语音特征量f和从由相同学习用的语音数据生成的文本数据得到的情感分析指数ins,将成为正确答案的一次情绪辨别值e作为教师标签建立了对应的数据。例如,对于使愤怒的用户发声时的语音数据的语音特征量f及情感分析指数ins,与-1.0的值的一次情绪辨别值e建立对应。
例如,学习部246将教师数据的语音特征量f及情感分析指数ins进行早期融合,并将其融合结果向情绪辨别模型mdl输入。并且,学习部246学习情绪辨别模型mdl,以使情绪辨别模型mdl的输出结果即一次情绪辨别值e接近对于向情绪辨别模型mdl输入的语音特征量f及情感分析指数ins作为教师标签建立了对应的正确答案的一次情绪辨别值e。
例如,在情绪辨别模型mdl为神经网络的情况下,学习部246利用sgd(stochasticgradientdescent:随机梯度下降)、momentumsgd、adagrad、rmsprop、adadelta、adam(adaptivemomentestimation:自适应力矩估计)等的概率斜度法来学习情绪辨别模型mdl的参数,以使通过情绪辨别模型mdl输出的一次情绪辨别值e与教师标签的一次情绪辨别值e的差值变小。
[服务器装置的处理流程]
以下,使用流程图说明第一实施方式的服务器装置200的处理。图12是表示第一实施方式的服务器装置200的一系列的处理的流程的流程图。本流程图的处理可以按照规定的周期反复进行。
首先,第一获取部232经由服务器侧通信部202从代理装置100获取语音数据(步骤s300)。
接下来,发声期间提取部234从通过第一获取部232获取到的语音数据中提取乘员发声的发声期间(步骤s302)。
接下来,语音识别部236按照通过发声期间提取部234提取出的各发声期间来识别语音,通过对识别出的语音进行文本化而生成表示发声的内容的文本数据(步骤s304)。
接下来,语音识别部236将生成的文本数据向为了分析乘员的情绪而预先学习的dnn输入,由此导出情感分析指数ins(步骤s306)。
接下来,特征量提取部238从通过发声期间提取部234提取出的各发声期间的语音中提取语音特征量f(步骤s308)。
接下来,第一推断部240将通过特征量提取部238提取出的语音特征量f与通过语音识别部236导出的情感分析指数ins利用早期融合而合并为一个(步骤s310)。
接下来,第一推断部240将早期融合的结果向情绪辨别模型mdl输入,由此暂时性推断乘员的情绪(步骤s312)。
接下来,第二推断部242将第一推断部240的推断结果即一次情绪辨别值e与通过语音识别部236导出的情感分析指数ins利用晚期融合而合并为一个(步骤s314)。
接下来,第二推断部242基于晚期融合的结果来导出二次情绪辨别值c,推断乘员的情绪(步骤s316)。
接下来,通信控制部244将包含第二推断部242的推断结果即二次情绪辨别值c和通过语音识别部236生成的文本数据在内的情绪推断数据经由服务器侧通信部202向代理装置100发送(步骤s318)。此时,文本数据可以包含与表示发声内容的文字列的各文字一一对应的发音记号(也称为语音字母或音标文字)。由此,代理装置100根据二次情绪辨别值c的值是+1.0、还是-1.0、或者是0.0,来变更对话的支援形态。由此,本流程图的处理结束。
根据以上说明的第一实施方式,服务器装置200具备:获取搭载有代理装置100的车辆m的乘员发出的语音数据的第一获取部232;生成将通过第一获取部232获取到的语音数据进行了文本化的文本数据的语音识别部236;将基于语音数据的语音特征量f与基于文本数据的情感分析指数ins通过早期融合而合并为一个,基于该早期融合的合并结果,来推断乘员的情绪的第一推断部240;将第一推断部240的推断结果即一次情绪辨别值e与情感分析指数ins通过晚期融合而合并为一个,基于该晚期融合的合并结果,来推断乘员的情绪的第二推断部242,由此,例如能够做到:在基于语音数据的情绪推断和基于文本数据的情绪推断的结果如“正面”和“正面”、或“负面”和“负面”那样为相互相同的推断结果的情况下,维持上述的推断结果,在如“正面”和“负面”、或“负面”和“正面”那样双方的情绪推断的结果为互不相同的推断结果的情况下,由于产生推断错误的盖然性高,因此变更为中性的推断结果。其结果是,能够抑制将心情低落的乘员的情绪误推断为“正面的情绪”,或者将心情高扬的乘员的情绪误推断为“负面的情绪”的情况,能够提高乘员(用户的一例)的情绪的推断精度。
<第一实施方式的变形例>
以下,说明第一实施方式的变形例。在上述的第一实施方式中,说明了搭载于各车辆m的代理装置100与服务器装置200为互不相同的装置的情况,但是并不局限于此。例如,服务器装置200可以是通过代理装置100的代理侧控制部130假想性地实现的假想机器。在该情况下,代理装置100是“情绪推断装置”的另一例。
图13是表示第一实施方式的代理装置100的另一例的图。如图13所示,代理装置100的代理侧控制部130可以除了具备上述的第一获取部132、语音合成部134、输出控制部136及通信控制部138之外,还可以具备发声期间提取部234、语音识别部236、特征量提取部238、第一推断部240、第二推断部242、学习部246。在该情况下,代理装置100的扬声器106或显示部108是“输出部”的另一例,代理装置100的输出控制部136是“使输出部输出基于用户的情绪的信息的输出控制部”的另一例。
另外,在代理装置100的代理侧存储部120可以储存情绪辨别模型信息212。
通过这样的结构,通过代理装置100单体,能够根据乘员发出的语音来推断该乘员的情绪,因此能够减少情绪的推断错误,提高乘员的情绪的推断精度。
另外,在上述的第一实施方式中,说明了代理装置100基于通过服务器装置200推断的乘员的情绪来变更代理语音的声压等级或抑扬等,或变更向车室内播放的音乐的选曲,或变更车室内显示的影像或图像的情况,但是并不局限于此。例如,代理装置100可以基于乘员的情绪的推断结果,来变更速度、加速度、转弯角这样的车辆m的行为。
另外,在上述的第一实施方式中,说明了服务器装置200具备语音识别部236,该语音识别部236按照通过发声期间提取部234提取出的各发声期间来识别语音,通过对识别的语音进行文本化来生成表示发声的内容的文本数据的情况,但是并不局限于此。例如,服务器装置200的通信控制部244可以将通过发声期间提取部234提取出的发声期间的语音数据经由服务器侧通信部202向某特定的外部装置发送,委托该外部装置由语音数据生成文本数据。外部装置具有与语音识别部236同样的结构,当从其他的装置接收到语音数据时,由该接收到的语音数据来生成文本数据。并且,外部装置将生成的文本数据向委托源的装置发送。当通过服务器侧通信部202从外部装置接收到文本数据时,服务器装置200的语音识别部236从通过服务器侧通信部202接收到的文本数据中导出情感分析指数ins。在该情况下,服务器侧通信部202或语音识别部236是“第二获取部”的另一例。
<第二实施方式>
以下,说明第二实施方式。在上述的第一实施方式中,作为早期融合,说明了向zcr、rms、f0这样的表示语音特征量f的多维向量追加情感分析指数ins的得分s和重要性m作为新的要素的情况。
相对于此,在第二实施方式中,作为早期融合,对于表示语音特征量f的多维向量,追加情感分析指数ins的得分s和重要性m作为新的要素,并追加表示乘员的驾驶操作的倾向的特征量、乘员的外观的特征量、表示车辆m的状态的特征量等作为新的要素,这一点与上述的第一实施方式不同。以下,以与
第一实施方式的不同点为中心进行说明,关于与第一实施方式相同的点省略说明。需要说明的是,在第二实施方式的说明中,对于与第一实施方式相同的部分,标注同一符号进行说明。
图14是表示第二实施方式的代理装置100的结构的一例的图。第二实施方式的代理装置100除了上述的结构之外,还具备驾驶操作检测部112、驾驶员监视相机114、车辆传感器116。
驾驶操作检测部112检测表示方向盘、加速踏板、制动踏板等驾驶操作件由乘员操作了何种程度这样的情况的操作量,或者检测有无对驾驶操作件的操作。即,驾驶操作检测部112检测乘员对驾驶操作件的驾驶操作。例如,驾驶操作检测部112将检测到的操作量或检测到的表示操作的有无的信息(以下,称为用户驾驶操作数据)向代理侧控制部130输出。
驾驶员监视相机114例如设置在搭载有代理装置100的车辆m的车室内,拍摄就座在车室内的座椅上的各乘员的脸部等。驾驶员监视相机114例如是利用了ccd(chargecoupleddevice:电荷耦合器件)或cmos(complementarymetaloxidesemiconductor:互补金属氧化物半导体)等固体拍摄元件的数码相机。驾驶员监视相机114例如以规定的定时反复拍摄各乘员。驾驶员监视相机114生成拍摄了乘员的图像的数据(以下,称为图像数据),将生成的图像数据向代理侧控制部130输出。
车辆传感器116包括:检测车辆m的朝向的方位传感器、检测车辆m的速度的车速传感器、检测车辆m的加速度的加速度传感器、检测车辆m的绕铅垂轴的角速度的偏航率传感器、检测转向扭矩的扭矩传感器等。车辆传感器116将检测到的包含方位、速度、加速度等的数据(以下,称为车辆状态数据)向代理侧控制部130输出。
第二实施方式的通信控制部138经由代理侧通信部102,将语音数据、用户驾驶操作数据、图像数据、车辆状态数据向服务器装置200发送。
第二实施方式的服务器装置200的特征量提取部238当通过服务器侧通信部202接收到图像数据时,从该图像数据中提取眼、口、鼻这样的脸部的部位的特征点作为乘员的脸部的特征量。
第二实施方式的服务器装置200的第一推断部240将下述的(i)~(iii)通过早期融合而合并为一个,将该早期融合的合并结果向情绪辨别模型mdl输入,由此暂时性地推断乘员的情绪。
(i):通过特征量提取部238提取出的语音特征量f。
(ii):通过语音识别部236导出的情感分析指数ins。
(iii):用户驾驶操作数据所表示的对驾驶操作件的操作量、从图像数据中提取出的乘员的脸部的特征量、及车辆状态数据所表示的车辆m的状态量中的一部分或全部。
图15是用于说明第二实施方式的早期融合的图。例如,第一推断部240作为早期融合,对于zcr、rms、f0这样的表示语音特征量f的多维向量,追加情感分析指数ins的得分s及重要性m、方向盘的操作量(例如转向扭矩或转向角)、加速踏板或制动踏板的操作量(例如踏入量)、乘员的脸部的特征量、车辆m的速度、加速度、角速度等状态量作为新的要素。
并且,第一推断部240将扩张了维数的多维向量向通过逻辑回归或dnn等实现的情绪辨别模型mdl输入。由此,能够导出更接近于当前的乘员的情绪的一次情绪辨别值e。
第二实施方式的学习部246使用下述这样的教师数据,来学习情绪辨别模型mdl,即,对于从学习用的语音数据中提取出的语音特征量f、根据相同学习用的语音数据生成的文本数据的情感分析指数ins、驾驶操作件的操作量、乘员的脸部的特征量、车辆m的状态量的组合,将成为正确答案的一次情绪辨别值e作为教师标签而建立了对应的教师数据。
根据以上说明的第二实施方式,将(i)语音特征量f、(ii)情感分析指数ins、(iii)对驾驶操作件的操作量、乘员的脸部的特征量、及车辆m的状态量中的一部分或全部通过早期融合而合并为一个,基于该早期融合的合并结果来导出一次情绪辨别值e,因此与第一实施方式相比,能够进一步减少情绪的推断错误。其结果是,能够进一步提高乘员的情绪的推断精度。
<第三实施方式>
以下,说明第三实施方式。在上述的第一实施方式及第二实施方式中,说明了代理装置100搭载于车辆m的情况。相对于此,在第三实施方式中,智能手机或便携电话等终端装置具备代理装置100的功能,这一点与上述的第一或第二实施方式不同。以下,以与第一或第二实施方式的不同点为中心进行说明,关于与第一或第二实施方式相同的点省略说明。需要说明的是,在第三实施方式的说明中,对于与第一或第二实施方式相同的部分,标注同一符号进行说明。
图16是表示第三实施方式的代理系统1的结构的一例的图。第三实施方式的代理系统1例如具备多个终端装置300、服务器装置200。
终端装置300是用户能够利用的装置,例如是智能手机等便携电话、平板电脑终端、各种个人计算机等具备输入装置、显示装置、通信装置、存储装置及运算装置的终端装置。通信装置包括nic等网卡、无线通信模块等。在终端装置300中,网络浏览器或应用程序等ua(useragent:用户代理)起动,接受用户的各种输入操作。
[终端装置的结构]
图17是表示终端装置300的结构的一例的图。如图所示,终端装置300例如具备终端侧通信接口302、终端侧扬声器304、终端侧麦克风306、终端侧显示部308、终端侧输入部310、终端侧控制部320、终端侧存储部330。
终端侧通信接口302包括与网络nw连接用的硬件。例如,终端侧通信接口302可以包含天线及收发装置、或nic等。例如,终端侧通信接口302经由网络nw而与服务器装置200通信,从服务器装置200接收情绪推断数据。
终端侧扬声器304基于通过终端侧控制部320输出的信息而输出语音。
终端侧麦克风306是对周围的语音进行收集的语音输入装置。终端侧麦克风306将收集到的语音数据向终端侧控制部320输出。
终端侧显示部308例如包括lcd或有机el显示器等显示装置。终端侧显示部308基于通过终端侧控制部320输出的信息来显示图像。
终端侧输入部310例如包括按钮、键盘或鼠标等用户接口。终端侧输入部310受理乘员的操作,将与受理的操作相应的信号向终端侧控制部320输出。终端侧输入部310也可以是与终端侧显示部308一体构成的触摸面板。
终端侧控制部320例如通过cpu等处理器执行终端侧存储部330储存的程序或应用来实现。而且,终端侧控制部320可以通过lsi、asic或fpga等硬件实现。程序或应用可以预先储存于终端侧存储部330,也可以储存于dvd或cd-rom等能够拆装的存储介质并通过将存储介质装配于驱动装置而安装于终端侧存储部330。
终端侧存储部330例如通过hdd、闪存器、eeprom、rom或ram等实现。在终端侧存储部330例如储存有实现终端侧控制部320的处理器参照的程序或应用。应用例如包含对用户发出的语音进行解析或分析并用于推断该用户的情绪的应用(以下,称为语音识别应用332)。
以下,说明实现终端侧控制部320的处理器执行语音识别应用332时的终端侧控制部320的功能。图18是表示终端侧控制部320的功能结构的一例的图。例如,终端侧控制部320具备第一获取部322、语音合成部324、输出控制部326、通信控制部328。
第一获取部322从终端侧麦克风306获取语音数据。
语音合成部324基于终端侧通信接口302从服务器装置200接收到的情绪推断数据,来生成代理语音。例如,语音合成部324基于情绪推断数据所包含的用户的情绪的推断结果和文本数据,来生成代理语音。
输出控制部326当通过语音合成部324生成代理语音时,使终端侧扬声器304输出该代理语音。此时,输出控制部326可以使终端侧显示部308显示与情绪推断结果相应的图像。
通信控制部328经由终端侧通信接口302将通过第一获取部322获取到的语音数据向服务器装置200发送。由此,在服务器装置200中,基于从终端装置300接收的语音数据,进行利用该终端装置300的用户的情绪推断。
根据以上说明的第三实施方式,智能手机等终端装置300具备代理装置100的功能,因此不仅是搭载于移动体的乘员,而且能够提高利用终端装置300的用户的情绪的推断精度。
以上,使用实施方式说明了用于实施本发明的方式,但是本发明丝毫不受这样的实施方式限定,在不脱离本发明的主旨的范围内能够施加各种变形及置换。
- 还没有人留言评论。精彩留言会获得点赞!