声音处理装置、系统和方法与流程
1.本发明总体上涉及基于人工智能的声音处理,具体而言,本发明涉及一种用于个人声音设备的声音处理装置,还涉及包括该声音处理装置的系统,还涉及一种声音处理方法。
背景技术:
2.近年来,降噪耳机颇受欢迎,因为降噪耳机能够为佩戴者创造舒适的使用场景。例如,戴上耳机启动降噪按钮,就能够在安静的环境下享受自己喜欢的音乐;能够在办公或差旅场景中专注于自己的工作而不受环境噪音干扰。
3.现有技术中应用于耳机的降噪方案主要有被动降噪方案和主动降噪方案两大类别。被动降噪方案基于声音吸收和/或反射材料的被动降噪(pnr)技术来实现声音隔离。主动降噪方案使用基于抗噪声声音输出的主动降噪(anr)技术来中和噪音,从而实现降噪的效果。
4.但是,无论是被动式降噪还是主动式降噪,会将一切噪音都过滤掉,这可能会导致危险。例如,虽然降噪耳机有效过滤掉了地铁上的嘈杂声音,但是有些想被听到的声音也被过滤了,比如报站声,婴儿哭声等。
5.因此,希望提出一种技术方案来解决现有技术中的上述问题。
技术实现要素:
6.鉴于现有技术中的上述问题,本发明旨在提供一种用于个人声音设备的智能声音处理方案,其能够实现基于用户需求的自动化降噪。
7.为此,根据本发明的一个方面,提供了一种用于个人声音设备中的声音处理装置,包括:接收模块,其被配置成接收所述个人声音设备所获取的一个或多个声音的音频信号,所述一个或多个声音至少包括所述个人声音设备周围的环境声音;处理模块,其被配置成采用声音处理模型来执行:分类处理,在所述分类处理中,基于所述音频信号确定出个人声音设备的使用者所处的场景类型;识别处理,在所述识别处理中,基于所确定的场景类型识别出所述一个或多个声音中的各声音为期望声音或不期望声音;以及过滤处理,在所述过滤处理中,基于所述识别处理的结果执行过滤配置,并基于所述过滤平配置来过滤所述音频信号,从而使得所述一个或多个声音中的不期望声音被至少部分地过滤掉,并且使得所述一个或多个声音中的期望声音被通透;以及输出模块,其被配置成输出经过滤的音频信号,以便提供给所述使用者。
8.根据一种可行的实施方式,所述声音处理模型包括一个或多个基于机器学习的模型。
9.根据一种可行的实施方式,所述声音处理模型包括第一经训练的机器学习模型、第二经训练的机器学习模型和第三经训练的机器学习模型;并且所述处理模块被配置成:采用第一经训练的机器学习模型来对所述音频信号执行所述分类处理,以输出所述场景类
型;采用第二经训练的机器学习模型来基于第一经训练的机器学习模型的输出执行所述识别处理,以输出所述一个或多个声音中的各声音为期望声音或不期望声音;并且采用第三经训练的机器学习模型基于第二经训练的机器学习模型的输出执行所述过滤处理,以输出所述经过滤的音频信号。
10.根据一种可行的实施方式,所述第一、第二和第三经训练的机器学习模型被组合成一个或多个混合机器学习模型。
11.根据一种可行的实施方式,所述处理模块通过以下至少一项处理来确定各声音为期望声音或不期望声音:倒频谱分析、声纹识别、关键词和/或关键音检测。。
12.根据一种可行的实施方式,上述各项处理是所述处理模块分别采用与其相关的模型来执行的
13.根据一种可行的实施方式,所述声音处理装置还包括通信模块,其被配置成与位于个人声音设备外部的外部电子设备通信连接,以与设置于所述外部电子设备中的音频应用交互信息。
14.根据一种可行的实施方式,所述通信模块接收来自所述音频应用的指令,所述指令包含所述使用者对所确定的场景类型下的声音过滤的意向;并且所述处理模块根据所述指令来调整所述过滤配置。
15.根据一种可行的实施方式,所述通信模块被配置成:将所述个人声音设备在被使用过程中捕捉到的新声音的音频信号传输给所述音频应用;并且从所述音频应用接收基于所述新声音的音频信号的处理参数,以使得所述新声音能够被识别。
16.根据一种可行的实施方式,所述通信模块还被配置成从所述音频应用接收推荐音频内容,所述推荐音频内容基于所确定的场景类型和所述个人声音设备的使用状态。
17.根据一种可行的实施方式,所述声音处理装置的各模块中全部或部分借助于一个或多个ai芯片来实现。
18.根据本发明的另一个方面,提供了一种计算设备,其中,所述计算设备被设置于远程服务器中并且创建用于处理个人声音设备使用过程中获取的一个或多个声音的音频信号的声音处理模型,创建所述声音处理模型包括:执行第一创建过程,在该过程中,使得所述声音处理模型能够基于所述音频信号确定个人声音设备的使用者所处的场景类型;执行第二创建过程,在该过程中,使得所述声音处理模型能够基于所述场景类型确定所述一个或多个声音中的各声音为期望声音或不期望声音;执行第三创建过程,在该过程中,使得所述声音处理模型能够执行过滤配置以及对所述音频信号执行基于所述过程配置的过滤,从而使得所述一个或多个声音中的不期望声音被至少部分地过滤掉,并且使得所述一个或多个声音中的期望声音被通透。
19.根据一种可行的实施方式,创建所述声音处理模型包括在第一至第三创建过程中训练一个或多个基于机器学习的模型。
20.根据一种可行的实施方式,创建所述声音处理模型包括:对基于机器学习的模型执行第一训练以获得第一经训练的机器学习模型,在第一训练过程中,将所述音频信号作为输入,以生成表示所述场景类型的输出;对基于机器学习的模型执行第二训练以获得第二经训练的机器学习模型,在第二训练过程中,将第一经训练的机器学习模型的输出作为输入,以生成表示所述一个或多个声音中的各声音为期望声音或不期望声音的输出;并且
对基于机器学习的模型执行第三训练以获得第三经训练的机器学习模型,在第三训练过程中,将第二经训练的机器学习模型的输出作为输入,以输出所述经过滤的音频信号。
21.根据一种可行的实施方式,所述第一、第二和第三经训练的机器学习模型被组合成一个或多个混合机器学习模型。
22.根据一种可行的实施方式,所述计算设备还被配置成基于述个人声音设备在被使用过程中捕捉到的新声音的音频信号对所述声音处理模型执行再学习过程,以使得所述声音处理模型能够识别所述新声音为期望声音或不期望声音,并生成用于使得所述声音处理模型能够识别所述新声音的处理参数。
23.根据一种可行的实施方式,所述计算设备还被配置成对所述第二经训练的机器学习模型执行再训练,在所述再训练过程中,将所述个人声音设备在被使用过程中捕捉到的新声音的音频信号作为输入,以生成表示所述新声音为期望声音或不期望声音的输出;并且在所述再训练过程中,生成用于使得所述第二经训练的机器学习模型能够识别所述新声音的处理参数。
24.根据本发明的又一个方面,提供了一种声音处理系统,包括:设置于个人声音设备中的、如上所述的声音处理装置;设置于远程服务器中的、如上所述的计算设备,其创建用于处理在个人声音设备处获取的一个或多个声音的音频信号的声音处理模型;以及设置于个人声音设备外部的外部电子设备中音频应用,所述音频应用与所述计算设备和所述声音处理装置分别通信连接;其中,所述声音处理装置采用在远程服务器中的创建的声音处理模型对所述个人声音设备所获取的一个或多个声音的音频信号执行综合处理,以生成经过滤的音频信号,从而使得一个或多个声音中的不期望声音被至少部分地过滤掉,并且使得一个或多个声音中的期望声音被通透。
25.根据本发明的再一个方面,提供了一种声音处理方法,可选地,所述方法由如上所述的声音处理装置和/或如上所述的声音处理系统执行,所述方法包括:接收个人声音设备所获取的一个或多个声音的音频信号,所述一个或多个声音至少包括所述个人声音设备周围的环境声音;采用声音处理模型来执行分类处理,在所述分类处理中,基于所述音频信号执行确定个人声音设备的使用者所处的场景类型;采用所述声音处理模型来执行识别处理,在所述识别处理中,基于所确定的场景类型确定所述一个或多个声音中的各声音为期望声音或不期望声音;采用所述声音处理模型来执行过滤处理,在所述过滤处理中,基于所述识别处理的结果执行过滤配置,并基于所述过滤平配置来过滤所述音频信号,从而使得所述一个或多个声音中的不期望声音被至少部分地过滤掉,并且使得所述一个或多个声音中的期望声音被通透;以及输出经过滤的音频信号,以便提供给所述使用者。
26.根据本发明的再一个方面,提供了一种用在个人声音设备中的声音处理装置,包括:一个或多个处理器;以及存储计算机可执行指令的存储器,当所述计算机可执行指令被执行时,使得所述一个或多个处理器执行如上所述的方法。
27.根据本发明的再一个方面,提供了一种计算机可读存储介质,其上存储有指令,所述指令在由至少一个处理器执行时,使得所述至少一个处理器执行如上所述的方法。
28.由此可见,根据本发明的技术方案,能够采用机器学习模型来对个人声音设备接收到的声音进行自动化处理,使得用户能够听到符合场景类型和自身意向的声音。而且,根据本发明的技术方案,在针对不同的场景类型以及不同的用户定制声音过滤和通透的组合
方案方面,能够不断提升和扩充声音处理的智能化和自动化水平。
附图说明
29.图1示出了可以在其中实施本发明的一些实现方式的示例性操作环境。
30.图2是根据本发明的一种可行实施方式的声音处理系统的示意性框图,其中包括根据本发明的用在个人声音设备中的声音处理装置。
31.图3示出了根据本发明的一种可行实施方式的声音处理的示例性过程。
32.图4示出了根据本发明的一种可行实施方式的声音再学习的示例性过程。
33.图5示出了根据本发明的一种可行实施方式的音频推送的示例性过程。
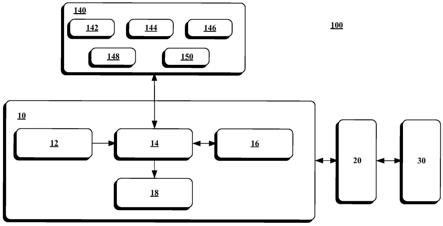
34.图6是根据本发明一种可行实施方式的声音处理方法的流程图。
35.图7示出了根据本发明的另一种声音处理装置的示意性框图。
具体实施方式
36.本发明主要涉及用于自动化地处理个人声音设备所获取的声音信号的技术方案。具体而言,根据本发明的声音处理方案可以基于人工智能(artificial intelligence,ai)技术来实现。
37.在发明中,“个人声音设备”是指被构造成定位在用户的至少一只耳朵里、耳朵上方或耳朵周围的设备,例如,头戴式耳机、耳塞和挂耳式耳机等。
38.下面,结合附图来详细描述本发明的实施例。
39.图1示出了可以在其中实施本发明的一些实现方式的示例性操作环境。图2示意性示出了根据本发明的一种可行实施方式的声音处理系统100。图2中例示的声音处理系统100可以在图1的操作环境中实现。需要注意的是,本发明的声音处理系统100并不限于图1示出的框架。
40.参见图1和图2,声音处理系统100主要包括声音处理装置10、音频应用20和计算设备30。
41.声音处理装置10设置于个人声音设备1中,个人声音设备1例如是耳机。个人声音设备1可以具有多个使用者,例如,图1中示出的user1-user3。不同的使用者在使用设置有声音处理装置10的个人声音设备1时,可以激活适用于各自的定制模式,这将在下文中详细描述。
42.声音处理装置10可以设置于个人声音设备1的处理单元中,该处理单元可以包括任意类型的通用处理单元(包括但不限于cpu、gpu,等等)、专用处理单元(包括但不限于专用集成电路(asic)、可编程逻辑器件(pld)、数字信号处理器(dsp)、现场可编程门阵列(fpga),等等。
43.声音处理装置10主要包括接收模块12、处理模块14、通信模块16和输出模块18。在一个实施例中,声音处理装置10可以借助人工智能技术来实现,即,声音处理装置10的全部或部分模块可以借助于一个或多个ai芯片来是实现。例如,声音处理装置10的一部分功能模块设置于一个ai芯片上,另一部分功能模块设置于另一个ai芯片上。
44.可以理解的是,声音处理装置10的各模块的命名应当被理解为逻辑上的描述,而不是物理形态或设置方式的限定。换言之,接收模块12、处理模块14、通信模块16和输出模
块18中的一个或多个可以实现在同一芯片或电路中,它们也可以分别设置于不同的芯片或电路中,本发明对此不进行限定。对于声音处理装置10的各模块,只要声音处理装置10具备一模块的功能,就应当理解为车载设备10包含该模块。
45.处理模块14可以采用声音处理模型140执行声音处理。该声音处理模块140是预先在远程服务器3(例如,计算设备30)处预先创建的。该声音处理模块140可以包括多个子模型。该声音处理模块140可以包括一个或多个基于机器学习的模型。
46.在一个实施例中声音处理模型140实现为基于机器学习的模型,该基于机器学习的模型是在远程服务器3(例如,计算设备30)处被预先训练的,并且还具备再学习的能力(功能)。经训练的机器学习模型140可以包括一个或多个混合机器学习模型。例如,经训练的机器学习模型140可以包括声纹识别模型142、数据分析/挖掘模型144、语音处理模型146、音频知识图谱148、关于处理音频流的模型150(例如,语速统计模型、关键词检测模型、特征音检测模型等)等。
47.声音处理装置10可以在个人声音设备1上电(例如,耳机的电源键处于on状态)时开启,即,其声音处理功能在个人声音设备1上电时被激活。声音处理装置10可以在个人声音设备1断电(例如,耳机的电源键处于off状态)时关闭。
48.音频应用20设置于位于个人声音设备1外部的外部电子设备2中,外部电子设备2例如是智能手机、台式计算机、平板电脑、多媒体播放器等。外部电子设备2与个人声音设备1之间可以以有线和/或无线的方式通信连接,以使得声音处理装置10与音频应用20之间能够交互数据。例如,外部电子设备2与个人声音设备1之间可以采用usb连接线传输数据。外部电子设备2与个人声音设备1之间也可以通过网络来传输数据,该网络包括但不限于无线局域网(wlan)、红外(ir)网络、蓝牙(bluetooth)网络、近场通信(nfc)网络、zigbee网络,等等。
49.计算设备30设置于远程服务器3中。远程服务器3可以与外部电子设备2通信地耦合,以使得在音频应用20与计算设备30之间能够交互数据。远程服务器3可以通过网络来与外部电子设备2通信连接,该网络可以基于任何无线电通信技术和/或标准。例如,该网络可以包括由电信运营商提供的任何制式的电信网络。该网络还可以包括物联网(iot)。在一个实施中,远程服务器3可以被部署在分布式计算环境中,并且也可以使用云计算技术来实现,本发明不限于此。
50.可以理解的是,个人声音设备1与远程服务器3之间的数据交互是通过外部电子设备2来执行的。例如,在下文将介绍的再学习过程中,声音处理装置10将新声音(例如,不同用户使用个人声音设备1的过程中被采集到的、未被声音处理装置10识别出的声音)的音频信号传输给音频应用20,再由音频应用20将带有标签的新声音的音频信号上传至远程服务器3。
51.图3示出了根据本发明的一种可行实施方式的声音处理的示例性过程300。以下以声音处理装置10执行过程300为例进行介绍。
52.在框302,接收模块12接收一个或多个声音的音频信号。该一个或多个声音可以包括个人声音设备1的麦克风捕捉(采集)的其周围的环境声音。该一个或多个声音也可以包括来自外部电子设备2的声音,例如,诸如通话之类的语音事件、诸如播放音乐、视频之类的音频输入事件。
53.在框304,处理模块14对接收到的音频信号进行分析,以确定出个人声音设备1的使用者所处的场景类型。例如,处理模块14采用声音处理模型140执行分类处理,在该分类处理中,基于接收到的音频信号确定出个人声音设备的使用者所处的场景类型。声音处理模型140的、用于执行该分类处理的部分可以由计算设备30通过第一创建过程来实现。例如,在该第一创建过程中,实现了声音处理模型140的用于分类处理的子模型。
54.场景类型可以包括办公、家庭、公共交通等。在一个实施例中,处理模块14还可以确定出场景类别下的子类别(即,大类别下的小类别)。例如,公共交通场景类型下可以包括地铁、火车、飞机等。办公场景类型下可以包括基于工作任务和/或组织结构划分的小类别,例如,项目组1、项目组2、人事部门、研发部门等。
55.在一个实施例中,处理模块14可以采用第一经训练的机器学习模型来输出场景类型。该第一经训练的机器学习模型例如是适于分类的模型。该第一经训练的机器学习模型在计算设备30上对基于机器学习的模型执行第一训练而获得。在第一训练过程中,各种类别的声音的音频信号作为模型输入,并生成场景类别作为模型输出。在第一训练过程中,可以首先针对大类别的分类进行训练,再针对各大类别下的小类别进行训练。在针对小类别的训练过程中,将各种小类别的声音的音频信号作为模型输出,并生成表示小类别的模型输出。
56.在框306,处理模块14执行识别过程,以识别出在所确定的场景类别下,一个或多个声音中的哪些声音是期望声音(即,个人声音设备1的使用者在该场景类型下所期望听到的声音),哪些声音是不期望声音(即,个人声音设备1的使用者在该场景类型下不期望听到的声音)。例如,处理模块14采用声音处理模型140执行识别处理,在该识别处理中,基于所确定的场景类型确定所述一个或多个声音中的各声音为期望声音或不期望声音。声音处理模型140的、用于执行该识别处理的部分可以是由计算设备30通过第二创建过程来实现。例如,在该第二创建过程中,实现了声音处理模型140的用于识别处理的子模型。
57.在一个实施例中,处理模块14可以采用第二经训练的机器学习模型来输出对所述一个或多个声音中的各声音的识别结果。该第二经训练的机器学习模型例如是适于声音识别的模型。该第二经训练的机器学习模型在计算设备30上对基于机器学习的模型执行第二训练而获得。在第二训练过程中,将第一经训练的机器学习模型的输出作为输入,以生成表示一个或多个声音中的各声音为期望声音或不期望声音的输出。
58.可以理解的是,不同场景类别下的声音特性是不同的,第二经训练的机器学习模型可以采用适合于各类声音的特性的模型来执行该类声音的识别过程。相应地,计算设备30在执行第二训练的过程中采用表示各类声音的特性的参数来进行训练。
59.以下,以示例的方式描述一些声音识别过程的实例。
60.在框3061中,采用与倒频谱相关的模型对音频信号的倒频谱进行分析,以确定各声音的声音源,从而确定该声音为期望声音或不期望声音。该分析方式尤其适合于分析和识别交通工具场景中的频率或带宽特征明显的声音信号,例如,汽车鸣笛声、激烈碰撞声、机舱内发动机的嗡鸣声等。
61.在框3062中,采用与声纹识别相关的模型对音频信号进行分析和识别,以确定各声音的声音源(例如,发声者),从而确定该声音为期望声音或不期望声音。该分析方式尤其适合于分辨不同人的声音,例如,在确定出场景类别下,确定某人发出声音是应当作为噪音
被过滤掉,还是作为有用信息被通透给带耳机的人。例如,采用这样的识别处理方式,可是使得带着耳机的人在公办场景下能够听到自己所属的项目组的同事的讨论声,而屏蔽其他项目组的同事的讨论声。
62.在该方式中,可以考虑不同方面的声学特征作为模型处理参数,这些处理参数可以包括以下一种或多种:(1)词法特征(例如,说话人对某个音的发声方式);(2)韵律特征(例如,说话人的基音和能量“姿势”);(3)方言和习惯(即,说话人容易重复使用的词);(4)其他定制的声学特征。
63.在框3063中,可以采用与语音识别相关的模型对音频信号执行关键词和/或关键音检测。该关键词和/或关键音可以是易于确定声音源并由此确定该声音被过滤掉还是被通透的一些词或音,例如,火车站的报站声、公共设施播报的紧急信息、救护车的警示音等。
64.在框3064中,通信模块16接收到来自音频应用20的指令,该指令指示所确定的场景类别下的声音处理方案(过滤或通透)。处理模块14根据该指令将所指示的声音设定为期望声音或不期望声音。
65.在一个实施例中,音频应用20通过通信模块16获知所确定的场景类型,并在其操作界面上显示该场景类型下的各声音源的选项菜单。个人声音设备1的使用者可以在该选项菜单上选定哪些声音是要被过滤掉的,哪些声音是要被通透的。表示用户对声音过滤的意向的指令经由通信模块16传输给处理模块14,处理模块14根据该指令对接收到的声音进行相应的设定。
66.需要注意的是,在根据来自音频应用20的指令的声音设定与处理模块根据预定的分析识别策略确定的声音设定相矛盾的情况下,优先执行根据指令的声音设定,因为该指令能够体现使用者的当前意向。例如,在根据声音处理模型已识别出哪些声音为期望声音,哪些声音为不期望声音,并基于这样的识别执行了过滤配置的情况下,可以基于表示用户对声音过滤的意向的指令来调整该过滤配置。
67.在框308,处理模块14根据所确定期望声音和不期望声音来执行过滤配置,以基于该配置来过滤所述音频信号,从而使得接收到的一个或多个声音中的不期望声音被至少部分地过滤掉,并且使得接收到的一个或多个声音中的期望声音被通透。例如,处理模块14采用声音处理模型140执行过滤处理,在该过滤处理中,基于识别处理的结果执行过滤配置,并基于所述过滤平配置来过滤所述音频信号,从而使得不期望声音被至少部分地过滤掉,并且使得期望声音被通透。声音处理模型140的、用于执行该过滤处理的部分可以由计算设备30通过第三创建过程来实现。例如,在该第三创建过程中,实现了声音处理模型140的用于过滤处理的子模型。
68.可以理解的是,“过滤配置以及基于该过滤配置的过滤”可以通过硬件或者软件或者软件与硬件相结合的方式来实现。例如,对于硬件实现的方式,可以借助于一个或多个用作过滤器的专用集成电路(asic)来实现。
69.在一个实施例中,处理模块14采用第三经训练的机器学习模型来实现过滤配置和过滤操作。该第三经训练的机器学习模型在计算设备30上对基于机器学习的模型执行第三训练而获得。在第三训练过程中,将第二经训练的机器学习模型的输出作为输入,以输出经过滤的音频信号,从而使得所述一个或多个声音中的不期望声音被至少部分地过滤掉,并且使得所述一个或多个声音中的期望声音被通透。
70.可以理解的是,虽然以上描述了多种基于机器学习的模型,这些基于机器学习的模型可以实现为一个或多个混合模型。例如,上述第一、第二和第三经训练的机器学习模型被组合成一个或多个混合机器学习模型。计算设备在采用训练数据训练模型的过程中,可以将上述基于机器学习的模型训练成一个或多个混合机器学习模型。
71.在框310,输出经过滤的音频信号,以使得个人声音设备1的使用者听到被智能过滤并且符合自身意向的声音。
72.图4示出了根据本发明的一种可行实施方式的声音再学习的示例性过程400。以下以声音处理系统100执行声音再学习的过程400为例进行说明。
73.在框402,声音处理装置10经由通信模块16将使用者在使用个人声音设备1的过程中采集到的新声音的声音数据(音频信号)传输给音频应用20。新声音例如是个人声音设备的当前使用用户感兴趣或认为需要包含在识别范围内的声音,并且该声音在之前未被包含在任一环境类别的声音中,即,未被包含在任何大类别或小类别的声音中。
74.可以理解的是,被传输的声音数据可以包括来自不同用户在使用过程中的声音数据,例如,来自user1的声音数据data1,来自user2的声音数据data2,来自user3的声音数据data3等。
75.在框404,使用者借助音频应用20为该声音数据设置标签,以便对新声音进行标识。该标签例如是朋友a的声音、同事b的声音、客户c的声音等。接着,音频应用20将带有标签的新声音的数据传输给远程服务器3上的计算设备30。
76.在框406,在远程服务器3处,计算设备30在接收到新声音的数据之后,基于新声音的数据对已创建的声音处理模型进行再学习,以使得声音处理模型能够识别新声音为期望声音或不期望声音,并生成用于使得所述声音处理模型能够识别所述新声音的处理参数。
77.在一个实施例中,计算设备30将接收到的新声音的数据作为训练样本,对基于机器学习的模型进行再训练。例如,计算设备30对第二经训练的机器学习模型执行再训练。在再训练过程中,将新声音的数据作为模型输入,以生成由其标签表示的类别,作为模型输出。通过这样的再训练,可以生成用于更新第二经训练的机器学习模型的模型参数(处理参数),即,位于处理模块14中的第二经训练的机器学习模型可以通过导入模型参数(处理参数)而能够识别出新声音为期望声音或不期望声音。
78.可以理解的是,用作再训练的新声音的数据可以来自个人声音设备1的多个使用者,因此,可以针对不同的用户定制适合于各自意向的声音过滤和通透的定制化组合。
79.在框408,计算设备30将用于更新的模型参数传输给音频应用20,接着由音频应用20推送至个人声音设备1的声音处理装置10中,以使得声音处理装置10能够识别出新声音,由此声音处理装置10具备提升声音识别能力的功能。
80.图5示出了根据本发明的一种可行实施方式的音频推送的示例性过程500。以下以声音处理系统100执行音频推送的过程500为例进行说明。
81.在框502,音频应用20通过声音处理装置10和/或自身的定位系统获知个人声音设备1的使用者当前所处的环境(位置)。并且,音频应用20可以获知使用者当前是否处于语音事件(通话)中。
82.在框504,在使用者没有处于语音事件的情况下,音频应用20可以从音频云4获取适合的音频内容,然后在音频应用20的界面上向使用者显示是否允许播放该推荐内容。
83.在框506,在使用者在音频应用20的界面上选择“允许播放”的情况下,声音处理装置10通过通信模块从音频应用20接收推送音频内容,例如,适合于当前场景的音乐、相声、童话故事等。
84.在一个实施例中,外部电子设备2与音频云4(例如,网易云音乐)通信连接。音频应用20在确定了使用者的环境以及没有处于语音事件的情况下,从音频云4获取适合的音频内容,然后在音频应用20的界面上向使用者显示是否播放该推荐内容,如果使用者选择“是”,则可以向使用者播放推送的音频内容。
85.图6示出了根据本发明的一个实施方式的声音处理方法600。声音处理方法600可以由上述声音处理装置10来执行,也可以由上述声音处理系统100来执行,因此,以上相关描述同样适用于此。
86.在步骤s610中,接收个人声音设备所获取的一个或多个声音的音频信号,所述一个或多个声音至少包括所述个人声音设备周围的环境声音。
87.在步骤s612中,采用声音处理模型来执行分类处理,在所述分类处理中,基于所述音频信号执行确定个人声音设备的使用者所处的场景类型。
88.在步骤s614,采用所述声音处理模型来执行识别处理,在所述识别处理中,基于所确定的场景类型确定所述一个或多个声音中的各声音为期望声音或不期望声音。
89.在步骤s616,采用所述声音处理模型来执行过滤处理,在所述过滤处理中,基于所述识别处理的结果执行过滤配置,并基于所述过滤平配置来过滤所述音频信号,从而使得所述一个或多个声音中的不期望声音被至少部分地过滤掉,并且使得所述一个或多个声音中的期望声音被通透。
90.在步骤s618,输出经过滤的音频信号,以便提供给所述使用者。
91.图7示出了根据发明的用在个人声音设备10中的另一种示例性声音处理装置700。装置700可以包括一个或多个处理器710和存储计算机可执行指令的存储器720,当执行所述计算机可执行指令时,所述一个或多个处理器710可以执行上述方法600。
92.本发明还提供一种计算机可读存储介质。该计算机可读存储介质可以包括指令,当所述指令被执行时,使得一个或多个处理器根据如上面所述的本公开内容的实施例,执行用于智能声音处理的操作,例如,上述方法600。
93.由此可见,根据本发明的技术方案,能够借助于人工智能技术对个人声音设备接收到的声音进行自动化处理,使得用户能够听到符合场景类型和自身意向的声音。
94.而且,根据本发明的技术方案,无需在个人声音设备中设置包含大量样本声音数据的本地数据库,因为大量的样本声音作为训练数据在远程服务器中完成了相应的分类、识别和匹配的过程。
95.而且,根据本发明的技术方案,能够针对不同的场景类型以及不同的用户定制声音过滤和通透组合方案,而无需在每次使用过程中对各声音一一设置。
96.而且,根据本发明的技术方案,采用擅长针对声音数据的分类、识别和过滤的机器学习模型来实现声音数据处理,能够快速地充分挖掘出多种类声音数据的不同特性和/或依赖关系,从而提升声音数据处理的效率和准确性。
97.应当理解,以上描述的装置中的所有模块都可以通过各种方式来实施。这些模块可以被实施为硬件、软件、或其组合。此外,这些模块中的任何模块可以在功能上被进一步
划分成子模块或组合在一起。
98.已经结合各种装置和方法描述了处理器。这些处理器可以使用电子硬件、计算机软件或其任意组合来实施。这些处理器是实施为硬件还是软件将取决于具体的应用以及施加在系统上的总体设计约束。作为示例,本发明中给出的处理器、处理器的任意部分、或者处理器的任意组合可以实施为微处理器、微控制器、数字信号处理器(dsp)、现场可编程门阵列(fpga)、可编程逻辑器件(pld)、状态机、门逻辑、分立硬件电路、以及配置用于执行在本公开中描述的各种功能的其它适合的处理部件。本发明给出的处理器、处理器的任意部分、或者处理器的任意组合的功能可以实施为由微处理器、微控制器、dsp或其它适合的平台所执行的软件。
99.软件应当被广泛地视为表示指令、指令集、代码、代码段、程序代码、程序、子程序、软件模块、应用、软件应用、软件包、例程、子例程、对象、运行线程、过程、函数等。软件可以驻留在计算机可读介质中。计算机可读介质可以包括例如存储器,存储器可以例如为磁性存储设备(如,硬盘、软盘、磁条)、光盘、智能卡、闪存设备、随机存取存储器(ram)、只读存储器(rom)、可编程rom(prom)、可擦除prom(eprom)、电可擦除prom(eeprom)、寄存器或者可移动盘。尽管在本公开给出的多个方面中将存储器示出为是与处理器分离的,但是存储器也可以位于处理器内部(如,缓存或寄存器)。
100.虽然前面描述了一些实施方式,这些实施方式仅以示例的方式给出,而不意于限制本发明的范围。所附的权利要求及其等同替换意在涵盖本发明范围和主旨内做出的所有修改、替代和改变。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1