一种基于数据选择性和高斯混合模型的语音活动检测方法与流程
本发明涉及语音信号处理技术领域,特别涉及一种基于数据选择性和gmm(gaussianmixturemodel:高斯混合模型)的vad(voiceactivitydetection:语音活动检测)方法。
背景技术:
语音信号处理是目前一个非常热门的领域。vad作为语音信号处理中的一个方向,其目的是从含噪语音信号中区分出语音段和非语音段。vad在许多领域都发挥着重要的作用:在存储或传输语音的场景下,其可以从连续的语音流中分离出有效语音,能够有效降低存储或传输的数据量;在语音增强领域,其可以在非语音段估计噪声信息,从而进行噪声抑制。
早期的vad算法大多基于如能量,短时过零率,倒谱距离,谱熵等语音特征直接对声音信号作出语音/非语音判决。这些算法的原理比较简单,计算复杂度低,在无噪声或者高信噪比情况下具有较高的正确率。但是一旦信噪比下降,其正确率就会急剧降低。进入21世纪以来,基于统计学模型的vad算法因为更好的性能获得了快速的发展。其中有研究人员使用gmm对含噪语音进行建模,并设计了vad算法。在gmm建模过程中,关键步骤是计算其参数集(均值,方差,权重)。首先需要选取一定的样本数据初始化参数集。之后对新的数据,需要持续地进行参数集的更新。基于gmm的vad算法虽然在低信噪比环境下具有更好的鲁棒性,但是计算复杂度也大大增加。
技术实现要素:
本发明要解决的技术问题是在保证正确率基本不变的情况下,如何降低基于gmm的vad方法的计算复杂度。本发明提供一种基于数据选择性和高斯混合模型的语音活动检测方法,能保证正确率基本不变情况下,大幅降低计算复杂性。
为了上述发明目的,本发明创造采用如下发明构思:
为解决上述问题,本发明提供的技术方案是对基于gmm的vad方法中gmm参数集更新过程做出改进。该技术方案的设计构思是在参数集更新过程中引入数据选择性思想,当数据对方法的正确率提升有限甚至有损的情况下,保持参数不变,从而在保持正确率大体不变的同时,大幅降低计算复杂度。
根据上述发明构思,本发明采用如下技术方案:
一种基于数据选择性和高斯混合模型gmm的语音活动检测vad方法,操作步骤如下:
步骤一:对输入的含噪语音信号进行采样、分帧、加窗处理后,通过fft(fastfouriertransformation,快速傅里叶变换)将信号转换到频域上;
步骤二:计算平滑子带对数能量;
步骤三:选取前m帧信号进行gmm参数集初始化;
步骤四:进行gmm参数集数据选择性更新;
步骤五:根据参数集计算子带语音存在概率,子带语音存在概率通过一个数值反映了当前子带的属性;
步骤六:给出帧单位上vad结果。
优选地,所述步骤二中平滑子带对数能量的计算方法为:
通过频域上信号的幅度谱计算功率谱,并在帧间进行平滑,从而得到平滑信号功率谱。进而将一帧信号分为多个子带计算平滑子带对数能量,作为语音特征用于gmm建模。
优选地,所述步骤三中gmm参数集初始化的方法为:
gmm参数集初始化通过迭代算法实现:首先设置参数集迭代计算开始前的起始值,然后根据公式进行迭代计算,直至参数集收敛完成初始化。
优选地,所述步骤四中gmm参数集数据选择性更新的方法为:
首先根据更新比例pup计算更新阈值,接着根据更新阈值设置不更新条件,然后将当前平滑子带对数能量分别相对于噪声模型和语音模型进行归一化得到位置信息,最后根据位置信息判断是否满足不更新条件,若满足则保持参数集不变,否则更新参数。
优选地,所述步骤六中给出帧单位上vad结果的方法为:
融合一帧中所有子带的语音存在概率,即将一帧信号中的所以子带语音存在概率相加,与判决阈值进行比较,若大于判决阈值,则判定当前帧为语音帧,否则为噪声帧。并且对于后续每一帧,重复步骤四、步骤五和步骤六,从而得到整段音频信号的vad判决结果。
与现有技术相比,本发明具有如下显而易见的突出实质性特点和显著的技术进步:
1.本发明在计算量最大的参数集更新过程中引入了数据选择性思想,不同于以往的参数集更新方式,在数据对算法的正确率提升有限甚至有损的情况下,保持参数不变,以此来降低计算复杂度,同时保证了正确率基本不变;
2.本发明整个方法的实施过程较为清晰简单,在正确率基本不变的同时能够大幅降低计算复杂度;在实际应用过程中,尤其是对实时性要求较高的场景中,具有较好的应用前景。
本领域的技术人员阅读了下面的附图以及具体实施方式后,将能更进一步理解本发明的实施方法、优越的特征和其它重要方面。
附图说明
图1是本发明方法的总体流程图。
图2是本发明方法的信号分帧示意图。
图3是本发明方法的gmm参数初始化流程图。
图4是本发明方法的gmm参数集数据选择性更新流程图。
图5是本发明方法在不同噪声环境中与现有技术方法在正确率和计算时间的对比图。
图6是本发明方法与现有技术在低信噪比下vad结果对比图。
具体实施方式
下面将对本发明的优选实施例结合附图进行详细地说明,其中表示了本发明的优选实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
实施例一:
参见图1~图6,一种基于数据选择性和高斯混合模型的语音活动检测方法,包括以下操作步骤:
步骤一:对输入的含噪语音信号进行分帧、加窗处理后,通过快速傅里叶变换fft将信号转换到频域上;
步骤二:计算平滑子带对数能量;
步骤三:选取前m帧信号进行高斯混合模型gmm参数集初始化;
步骤四:进行gmm参数集数据选择性更新;
步骤五:根据参数集计算子带语音存在概率,子带语音存在概率通过一个数值反映了当前子带的属性;
步骤六:给出帧单位上语音活动检测vad结果。
本实施例方法是基于gmm的vad方法中gmm参数集更新过程做出改进,在参数集更新过程中引入数据选择性思想,当数据对方法的正确率提升有限甚至有损的情况下,保持参数不变,从而在保持正确率大体不变的同时,大幅降低计算复杂度。
实施例二:
本实施例与实施例一基本相同,特别之处如下:
一种基于数据选择性和高斯混合模型的语音活动检测方法,包括以下操作步骤:
步骤一:对输入的含噪语音信号进行分帧、加窗处理后,通过快速傅里叶变换fft将信号转换到频域上;
步骤二:计算平滑子带对数能量,平滑子带对数能量计算方法为:通过频域上信号的幅度谱计算功率谱,并在帧间进行平滑,从而得到平滑信号功率谱;进而将一帧信号分为多个子带计算平滑子带对数能量,作为语音特征用于gmm建模;
步骤三:选取前m帧信号进行高斯混合模型gmm参数集初始化,gmm参数集初始化方法为:gmm参数集初始化通过迭代算法实现:首先设置参数集迭代计算开始前的起始值,然后根据公式进行迭代计算,直至参数集收敛完成初始化;
步骤四:进行gmm参数集数据选择性更新,gmm参数集数据选择性更新方法为:首先根据更新比例pup计算更新阈值,接着根据更新阈值设置不更新条件,然后将当前平滑子带对数能量分别相对于噪声模型和语音模型进行归一化得到位置信息,最后根据位置信息判断是否满足不更新条件,若满足则保持参数集不变,否则更新参数集;
步骤五:根据参数集计算子带语音存在概率,子带语音存在概率通过一个数值反映了当前子带的属性;
步骤六:给出帧单位上语音活动检测vad结果,帧单位上vad结果给出方法为:融合一帧中所有子带的语音存在概率,即将一帧信号中的所以子带语音存在概率相加,与判决阈值进行比较,若大于判决阈值,则判定当前帧为语音帧,否则为噪声帧;并且对于后续每一帧;
重复步骤四、步骤五和步骤六的帧单位上vad结果给出方法,从而得到整段音频信号的vad判决结果。
本实施例是对实施例一的进一步具体,采用更加优选的平滑子带对数能量计算方法、gmm参数集初始化方法、gmm参数集数据选择性更新方法和帧单位上vad结果给出方法,本实施例方法在计算量最大的参数集更新过程中引入了数据选择性思想,不同于以往的参数集更新方式,在数据对算法的正确率提升有限甚至有损的情况下,保持参数不变,以此来降低计算复杂度,同时保证了正确率基本不变;本实施例整个方法的实施过程较为清晰简单,在正确率基本不变的同时能够大幅降低计算复杂度。
实施例三:
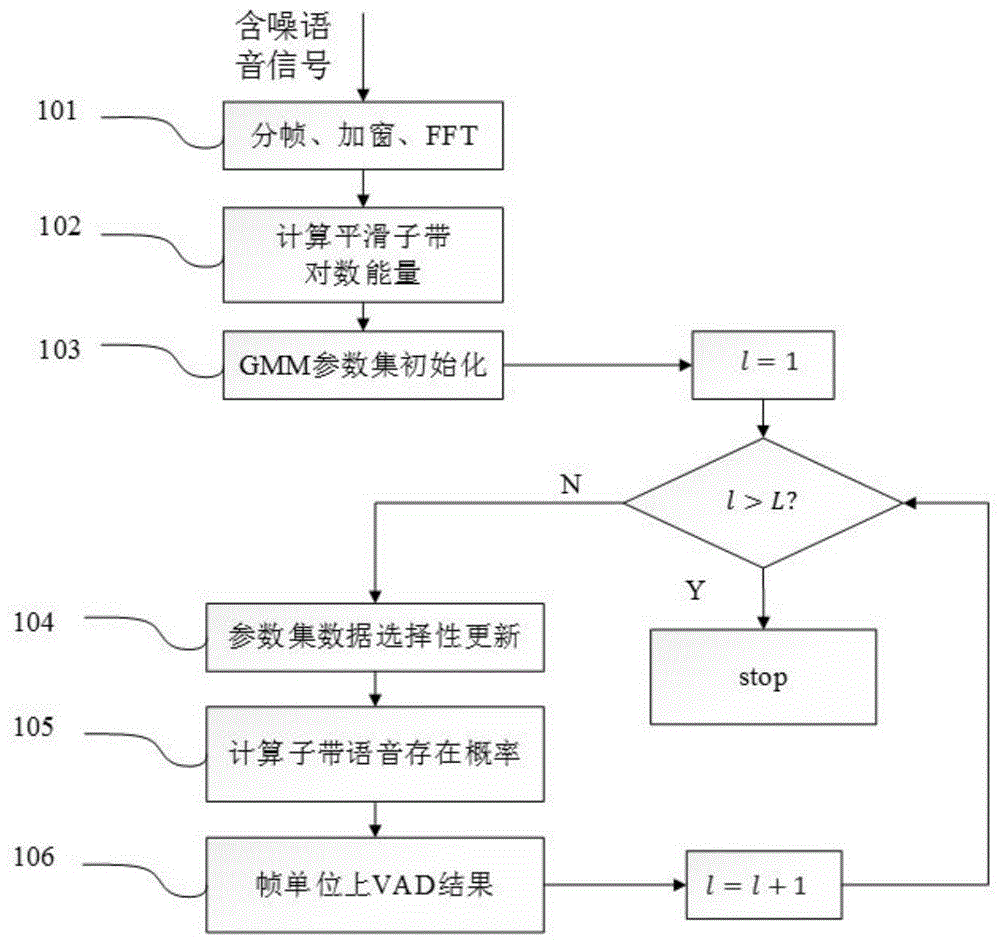
在本实施例中,图1是本实施例的总体流程图,本实施例方法包括对输入含噪语音信号进行采样、分帧、加窗及fft的预处理操作;计算平滑子带对数能量;进行gmm参数集初始化;进行gmm参数集数据选择性更新;计算子带语音存在概率;输出每帧的vad结果。该方法从步骤101开始:
步骤101:对输入含噪语音信号进行采样、分帧、加窗及fft的预处理操作。
输入一段时长为t秒的含噪语音信号,本实施例中t优选取值为100以上。采样率为fs,本实施例fs取值为16khz,则总采样点数为nx=fs*t。对输入的含噪语音信号进行采样,采样后信号表示为{x(n)|n取从0到nx-1的整数值}。然后进行分帧,分帧示意图如图2所示。一帧信号的长度称为帧长nw,例如可优选取值为320。帧移ni表示前后两帧信号的偏移量,例如可优选取值为帧长的50%,则ni=50%*nw。l表示整段语音信号的总帧数。
分帧完成后进行加窗处理,即将一帧信号与窗函数相乘。加窗的目的是为了抑制频谱泄露,分帧加窗对应公式如下:
x(n,l)=x(n+(l-1)ni)ω(n)(1)
其中x(n,l)代表第l帧内的第n个采样值,n可取从0到nw-1的整数值,l表示帧索引,l可取从1到l的整数值。ω(n)表示窗函数的第n个采样值,窗函数的长度等于帧长,应选用频谱旁瓣衰减较快的窗函数,例如可优选为hamming窗。
将经过采样、分帧、加窗的信号通过fft转换到频域上。对应的公式如下:
其中j代表单位虚数,n表示傅里叶变换点数(例如n可优选取值为512),x(k,l)表示频域中第l帧第k个频点的含噪语音信号,k表示频点索引(k可取从0到n-1的整数值)。
步骤102:计算语音特征平滑子带对数能量。
首先计算平滑信号功率谱,对应公示如下:
p(k,l)=αp(k,l-1)+(1-α)|x(k,l)|2(3)
其中p(k,l)表示第l帧第k个频点的平滑信号功率谱,p(k,l-1)表示前一帧即第l-1帧第k个频点的平滑信号功率谱。α表示平滑常数,例如α可优选取值为0.98。x(k,l)表示第l帧第k个频点的含噪语音信号幅度。特别的,对于第一帧信号有p(k,1)=|x(k,1)|2。
然后通过平滑信号功率谱计算平滑子带对数能量。平滑子带对数能量的计算公式如下:
其中b是子带索引,b取从0到b-1的整数,b取正整数,表示子带总数,mb=b(n/b)。ys(b,l)是第l帧中第b个子带的平滑子带对数能量,子带总数可以根据实际情况进行选择,在对实时性要求较高的场景下一个较小的子带总数比较合适,本实施例b取值为8,在对正确率要求更高的场景下选择一个大的子带总数比较合适,本实施例b取值为16。
步骤103:使用输入语音信号前m,m为偶数,本实施例的m取值为60,帧对应的语音特征数据即平滑子带对数能量,进行gmm参数集初始化。
图3是本实施例gmm参数集初始化的流程图。图3展示的是对第b个子带的初始化。注意本发明提出的方法需要对所有子带都进行初始化,即b依次从0到b-1取值,对于b的每个取值都要执行图3展示的流程图。对第b个子带的初始化流程从步骤301开始。
步骤301:设置权重起始值。令
步骤302:先将l从1到m取值所对应的m个ys(b,l)从小到大排序;然后计算前m/2个的均值,记为mean0(b);最后计算后m/2个的均值,记为mean1(b)。
步骤303:对输入样本进行分类。令l依次取从1到m的整数,对于每个对应的ys(b,l),如果:
|ys(b,l)-mean0(b)|<|ys(b,l)-mean1(b)|(5)
则此时的ys(b,l)属于第0类,否则属于第1类。
步骤304:使用步骤303所得数据的分类信息,对属于第0类的数据求平均,设为噪声模型的均值起始值
步骤305:使用步骤303所得数据的分类信息。对属于第0类的数据求方差,设为噪声模型的方差起始值
步骤306:对参数集进行迭代计算直到收敛,完成参数集初始化。首先做以下定义:w0(b)’、μ0(b)’、κ0(b)’分别代表噪声模型的权重、均值、方差在每次迭代计算时被更新前取值;w1(b)’、μ1(b)’、κ1(b)’分别代表语音模型的权重、均值、方差在每次迭代计算时被更新前取值;λ(b)’={w0(b)’,μ0(b)’,κ0(b)’,w1(b)’,μ1(b)’,κ1(b)’}代表在每次迭代计算时被更新前参数集的取值。w0(b)、μ0(b)、κ0(b)分别代表噪声模型的权重、均值、方差经过每次迭代计算被更新后的取值;w1(b)、μ1(b)、κ1(b)分别代表语音模型的权重、均值、方差经过每次迭代计算被更新后的取值;λ(b)={w0(b),μ0(b),κ0(b),w1(b),μ1(b),κ1(b)}代表经过每次迭代计算时被更新后参数集的取值。每次迭代计算使用以下公式:
其中z可取0或1,取0代表噪声模型,取1代表语音模型。在(6)-(8)中,对于使用z作为下标的变量,需要分别计算下标z=0和下标z=1对应的变量值。在第一次迭代时
其中p[ys(b,l)|z,λ(b)']表示概率密度函数,其计算公式如下:
最后,计算模型似然度的当前值l(b)和上一轮值l(b)’:
为计算l(b)中的p[ys(b,l)|z,λ(b)],可将公式(10)中的λ(b)’、μz(b)’、κz(b)’分别替换为λ(b)、μz(b)、κz(b)后进行计算。如果|l(b)-l(b)’|<ε则表示参数集已收敛,停止迭代,否则继续使用公式(6)(7)(8)进行迭代。ε是一个很小的数,例如可优选取值为0.1。
步骤104:对每帧信号进行gmm参数集数据选择性更新。
图4是本实施例gmm参数集数据选择性更新流程图。图4展示的是对第b个子带的参数集的数据选择性更新。注意本实施例方法需要对所有子带都进行数据选择性更新,即b依次从0到b-1取值,对于b的每个取值都要执行图4展示的流程图。对第b个子带的数据选择性更新流程从步骤401开始。
步骤401:预先设定一个更新比例pup,根据pup在标准正态分布模型上求得两个更新阈值。pup具体取值根据实际情况变化,最终选取值的原则为:使用当前pup值所做的数据选择性vad的正确率大体不变而计算时间减小最大化,例如pup可优选取值为0.92。
步骤402:根据所设pup计算更新阈值,更新阈值的计算公式如下:
其中tleft表示更新左阈值,更新右阈值tright与之关系为tright=-tleft。
步骤403:设定不更新条件如下:
其中
步骤404:将当前平滑子带对数能量ys(b,l),分别相对于语音模型和噪声模型的参数进行归一化,得到位置信息,计算公式如下:
其中对于使用z作为下标的变量,需要分别计算下标z=0和下标z=1对应的变量值。
步骤405:选择性更新参数集。为方便后文描述,定义:w0(b,l)、μ0(b,l)、κ0(b,l)分别代表噪声模型在第l帧的第b个子带的权重、均值、方差的取值;w1(b,l)、μ1(b,l)、κ1(b,l)分别代表语音模型在第l帧的第b个子带的权重、均值、方差的取值;λ(b,l)={w0(b,l),μ0(b,l),κ0(b,l),w1(b,l),μ1(b,l),κ1(b,l)}代表第l帧的第b个子带的参数集。
首先,将步骤103最后输出的λ(b)赋值给第1帧的参数集λ(b,1)。
然后,对后续各帧依次判断是否满足不更新条件。
若满足(13)或(14),则保持参数集不变,将λ(b,l)赋值给λ(b,l+1)。
若既不满足(13)也不满足(14),则更新参数集,
根据第l帧的参数集更新计算第l+1帧参数集的具体公式如下:
wz(b,l+1)=βwz(b,l)+(1-β)p[z|ys(b,l+1),λ(b,l)](16)
其中对于使用z作为下标的变量,需要分别计算下标z=0和下标z=1对应的变量值。β为参数集更新平滑常数,可优选取值为0.98。ys(b,l+1)表示第l+1帧第b个子带中的平滑子带对数能量。p[z|ys(b,l+1),λ(b,l)]表示第l+1帧第b个子带的后验概率,可将公式(9)中的ys(b,l)、λ(b)’分别替换为ys(b,l+1)、λ(b,l)后进行计算。
步骤105:根据当前的gmm参数集,计算子带的语音存在概率。
子带语音存在概率通过一个大于0小于1的具体数值来反映当前子带属性,其计算公式如下:
其中spp(b,l)表示第l帧中第b个子带上的语音存在概率。计算p[ys(b,l)|z,λ(b,l)]时可将公式(10)中的λ(b)’替换为λ(b,l)后进行计算。
步骤106:将一帧中所有子带的语音存在概率相加,与判决阈值η进行比较,给出每一帧的vad判决结果,相应公式如下:
其中vad(l)表示第l帧的vad结果,h1表示存在语音,h0表示只有噪声。判决阈值η可以根据经验值设定。若希望shr(speechhitrate:语音命中率)尽可能高,可以将判决阈值η设为一个较小值,取值为3;若同时需要兼顾nhr(nonspeechhitrate:非语音命中率),则可以将判决阈值η设为一个较大的值,取值为6。
基于上述实施例,从timit语料库中随机选择200个语音句子,和noisex-92噪声数据库中的white、pink、buccaneercockpit1、hfchannel噪声按照-5、0、5、10db的信噪比混合,对本发明的性能进行评价。图5展示了本实施例在不同噪声环境中与现有技术在正确率和计算时间的对比图。图6是本实施例与现有技术在white噪声环境(0db)下vad结果对比图。可见本发明相比现有技术,在正确率性能大致不变的情况下,具有更快的计算速度。
综合上述实施例可知,上述实施例基于数据选择性和高斯混合模型的语音活动检测方法,属于语音信号处理领域,其中方法的实现包括以下步骤:对输入的含噪语音信号进行分帧、加窗处理后,通过fft(fastfouriertransformation,快速傅里叶变换)将信号转换到频域上;根据频域上的信号计算平滑信号功率谱,进而通过平滑信号功率谱计算平滑子带对数能量,平滑子带对数能量作为语音特征用于gmm建模;选取前m帧信号进行gmm参数集初始化;对每帧信号进行gmm参数集数据选择性更新;根据参数集计算子带语音存在概率;将一帧信号中所有子带的语音存在概率相加与判决阈值进行比较,若大于判决阈值,则判定当前帧为语音帧,否则为噪声帧,输出每一帧的vad结果。本发明方法在基于gmm的vad算法中引入了数据选择性,在保证正确率基本不变情况下,能够大幅降低计算复杂度。
以上对本发明基于数据选择性和gmm的vad方法进行了详细介绍,本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处,综上,本说明书内容不应理解为本发明的限制。
- 还没有人留言评论。精彩留言会获得点赞!