一种端到端的骨气导语音联合增强方法
本发明属于电子信息技术领域,具体涉及一种语音联合增强方法。
背景技术:
语音增强旨在改善带噪语音的质量和可懂度,被广泛应用于各类语音系统的前端。近年来,由于深度学习的兴起,基于深度学习的语音增强日益受到关注,包括谱映射方法,时频掩膜方法和近一两年的端到端的时域增强方法。然而目前这些基于深度学习的语音增强方法均只使用了气导语音。
骨导麦克风通过拾取头骨等人体部位的振动信号来获得音频信号。与传统的气导语音相比,骨传导语音不会拾取环境中的噪声,因而可以从声源处屏蔽噪声,实现低信噪比下的语音通信。然而,骨导语音自身也存在许多缺点。首先,由于人体组织的低通性,骨传导语音的高频部分衰减严重,甚至缺失。通常大于800hz的频率成分就已经十分微弱,大于2khz的部分基本完全丢失,使得骨导语音听起来十分沉闷,可懂度降低。其次,骨导语音会引入一定的非声学干扰,说话时麦克风与皮肤的摩擦,人体运动等,进一步影响了骨导语音。最后,由于骨传导的特性,语音中的清音,摩擦音等辅音严重丢失。
骨传导语音的用法可以分为两类。一类就是用骨传导麦克风直接替换到原来系统中的气导麦克风,然后对骨传导的语音进行带宽扩展,这也被称为骨导语音的盲增强。这类方法主要设计一个模型,实现从骨导语音到气导语音的映射,包括线性表示,重构滤波器,高斯混合模型和深度神经网络。然而,这类工作大多侧重于扩展骨传导语音的带宽,而忽略了骨导自身的各类噪声。另一类方法则将骨导语音作为一个辅助的信号用来提升语音增强的性能。2004年,微软研究院首先提出同时使用骨传导和气导语音进行联合语音增强。在随后的几年里,有不少类似的工作,但是这些方法都是基于传统的信号处理方法。目前为止,还没有基于端到端深度学习的骨气导语音增强的工作。
技术实现要素:
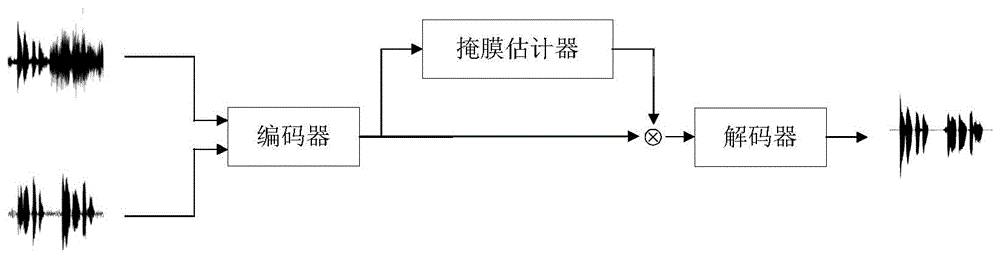
为了克服现有技术的不足,本发明提供了一种端到端的骨气导语音联合增强方法,首先同步录制气导语音和骨导语音,添加环境噪声后构造数据集;接下来构建端到端的神经网络模型,包括编码器、掩膜估计器和解码器;通过神经网络模型将带噪声的气导语音和骨导语音转化为一个单通道的语音信号;使用训练集和验证集的数据用adam优化器对端到端的神经网络模型进行训练,直到si-snr的值不再增大时,停止训练,得到最终端到端的神经网络模型。本方法相比传统的只利用气导的语音信号或者单纯骨导语音进行增强,联合增强的语音质量和可懂度都有大幅的提升,同时语音识别的错误率也显著下降。
本发明解决其技术问题所采用的技术方案包括以下步骤:
步骤1:在无噪声环境下同步录制气导语音xa和骨导语音xb;给气导语音xa添加环境噪声,得到
步骤2:将训练集的语音数据按固定长度切割为多个小段语音;
步骤3:构建端到端的神经网络模型,所述神经网络模型包括编码器e、掩膜估计器m和解码器;
步骤3-1:所述编码器e由一维卷积构成,编码器e的输入为经过步骤2切割的数据
步骤3-2:所述掩膜估计器m为一个时域卷积网络,包括多个串行堆叠的卷积块,每个卷积块包括串行排列的一个1x1的卷积和一个深度可分离卷积,每个1x1的卷积后跟随一个prelu非线性激活函数和归一化操作,每个深度可分离卷积后跟随一个prelu非线性激活函数和归一化操作;每经过一个卷积块,1x1的卷积的扩张因子的值乘以2;
掩膜估计器m的输入为特征图z,输出为和特征图z尺寸相同的掩膜m,即m=m(z);
步骤3-3:将特征图z和掩膜估计器输出的掩膜m进行点乘,得到一个新的特征图c=z·m;
步骤3-4:所述解码器d由一维反卷积构成;将新的特征图c送入解码器d中,解码器d将新的特征图c转化为一个单通道的语音信号y=d(c);
步骤4:对端到端的神经网络模型进行训练,训练目标为最大化尺度无关的信噪比,具体表示为:
其中,<·>代表内积,si-snr为尺度无关的信噪比;
使用训练集和验证集的数据用adam优化器对端到端的神经网络模型进行训练,如果用验证集验证时si-snr的值不再增大,则停止训练,得到最终端到端的神经网络模型;
步骤5:模型测试;
将测试集数据送入步骤4得到的最终端到端的神经网络模型,输出得到联合增强的语音信号。
优选地,所述将数据集划分为训练集、验证集和测试集的方法为将数据集的70%设置为训练集,20%设置为验证集,剩下的10%设置为测试集。
优选地,所述将训练集的语音数据按固定长度切割为多个小段语音分割中的固定长度为1s。
优选地,所述编码器e的一维卷积的卷积核大小为20,个数为256,stride设置为8,输出通道数等于256。
优选地,所述掩膜估计器m包括8个串行堆叠的卷积块。
优选地,所述解码器d的一维卷积的卷积核的大小为20,卷积核个数为1。
优选地,所述步骤4中对端到端的神经网络模型进行训练的最大训练次数设置为30个epoch,初始学习率设置为0.001。
本发明的有益效果如下:
本发明的有益效果在于同时利用带噪的气导语音和骨导语音,实现端到端的联合语音增强。相比传统的只利用气导的语音信号或者单纯骨导语音进行增强,联合增强的语音质量和可懂度都有大幅的提升,同时语音识别的错误率也显著下降。另外,由于带噪的气导语音和骨导语音的相位均有不足,因而传统的时频域的方法也面临相位估计的问题,而本发明设计的端到端的系统能有效避免相位估计问题。
附图说明
图1是本发明方法的系统框图。
具体实施方式
下面结合附图和实施例对本发明进一步说明。
如图1所示,一种端到端的骨气导语音联合增强方法,包括以下步骤:
步骤1:在无噪声环境下同步录制气导语音xa和骨导语音xb;给气导语音xa添加环境噪声,得到
步骤2:将训练集的语音数据按固定长度切割为多个小段语音;
步骤3:构建端到端的神经网络模型,所述神经网络模型包括编码器e、掩膜估计器m和解码器;
步骤3-1:所述编码器e由一维卷积构成,编码器e的输入为经过步骤2切割的数据
步骤3-2:所述掩膜估计器m为一个时域卷积网络,包括多个串行堆叠的卷积块,每个卷积块包括串行排列的一个1x1的卷积和一个深度可分离卷积,每个1x1的卷积后跟随一个prelu非线性激活函数和归一化操作,每个深度可分离卷积后跟随一个prelu非线性激活函数和归一化操作;每经过一个卷积块,1x1的卷积的扩张因子的值乘以2;
掩膜估计器m的输入为特征图z,输出为和特征图z尺寸相同的掩膜m,即m=m(z);
步骤3-3:将特征图z和掩膜估计器输出的掩膜m进行点乘,得到一个新的特征图c=z·m;
步骤3-4:所述解码器d由一维反卷积构成;将新的特征图c送入解码器d中,解码器d将新的特征图c转化为一个单通道的语音信号y=d(c);
步骤4:对端到端的神经网络模型进行训练,训练目标为最大化尺度无关的信噪比,具体表示为:
其中,<·>代表内积,si-snr为尺度无关的信噪比;
使用训练集和验证集的数据用adam优化器对端到端的神经网络模型进行训练,如果用验证集验证时si-snr的值不再增大,则停止训练,得到最终端到端的神经网络模型;
步骤5:模型测试;
将测试集数据送入步骤4得到的最终端到端的神经网络模型,输出得到联合增强的语音信号。
具体实施例:
1、获取同步的骨导和气导语音数据(xa,xb)构建数据集,其中xa为在消声实验室或者较为安静的环境下录制的纯净语音,xb为同步录制的骨导语音。将所有的语音降采样到16khz,16bit量化。模型的输入数据为带噪的气导和骨导语音。因为骨导语音自身可以抵制环境噪声,因而,只给气导的语音按照一定的信噪比添加噪声,即为
2、为了方便训练,将训练的语音数据按固定长度进行切割,本实施例中,分割的长度为1s,每1s包含16000点。
3、搭建端到端的神经网络模型。所提出的模型由三个模块构成,即编码器,掩膜估计器和解码器。
3.1编码器e由一维卷积构成,将带噪的气导语音和骨导语音转化到同一个特征空间中,得到特征图z,即
3.2掩掩膜估计器m是一个时域卷积网络,由8个堆叠的卷积块构成,每个卷积块包含了1x1的卷积和深度可分离卷积,每个卷积后跟随着一个prelu非线性激活函数和归一化操作,每一个卷积块的扩张因子呈指数增长。每个卷积块包含512个卷积核。膜估计器的输入为编码器得到的特征图,输出为和特征图同尺寸的掩膜m,即m=m(z)。
3.3先将编码器输出的特征图和掩膜估计器输出的掩膜进行点乘,得到一个新的特征图c=z·m,被认为是纯净的气导语音在该空间的分量。
3.4解码器d由一维卷积构成。将新的特征图送入解码器中,解码器将其转化为一个单通道的语音信号y,即y=d(c)。卷积核的大小为20,卷积核个数为1。
4、优化神经网络。网络的训练目标为最大化尺度无关的信噪比(si-snr),用adam优化器对网络进行优化。最大训练次数设置为30个epoch。初始学习率设置为0.001.如果模型在验证集的指标在连续的2个epoch内没有提升,则学习率减半。如果模型在验证集上的指标在连续的5个epoch都没有提升,则停止训练,得到最佳的模型。
5、模型测试。将测试数据送入第4步得到的训练好的网络,得到联合增强的语音信号。
- 还没有人留言评论。精彩留言会获得点赞!