不须计算取样频率误差的盲源分离方法以及音频处理系统与流程
1.本揭露是有关于非同步录音,特别的是不需要计算取样频率误差,也不需要对声音信号重新取样。
背景技术:
2.在音频信号处理领域中,自组(ad-hoc)麦克风阵列的使用变得越来越有用。对于盲源分离(blind source separation)的技术来说,自组麦克风阵列提供了价格合理,灵活且便携式的音频采集系统。但是,自组麦克风阵列获取的信号通常具有不同的开始时间。此外,由于录音设备之间的模拟数字转换器(analog-to-digital,adc)彼此独立,因此每个设备上真实的取样频率与号称的取样频率略有不同。这些变异会导致信号处理演算法(例如盲源分离)明显的效能降低,因此需要进行校正。尽管存在录音前的校正方法,但在大多数录音设备上这些方法并不总是可行或方便的。因此,在实际应用中,通常是在不知道关于设置或不匹配的信息前提下,在录音后进行取样频率不匹配和起始偏移的补偿。
技术实现要素:
3.本揭露的实施例提出一种盲源分离方法,适用于一音频处理系统。此音频处理系统包括多个装置,每一个装置包括多个麦克风。盲源分离方法包括:取得每一个装置的每一个麦克风所感测的声音信号,将每一个声音信号分为多个讯框,并对每一个讯框执行时间至频率域转换以产生在时间频率域的向量xd[τ,k;fd],其中d表示第d个装置,fd表示第d个装置的取样频率,τ表示第τ个讯框,k表示第k个频率系数索引;设定一混和矩阵a[k]=[a1[k;f1]
t
,
…
,ad[k;fd]
t
]
t
,其中d表示装置的个数,矩阵ad[k;f1]对应至第d个装置,混和矩阵ad的大小为cd×
n,cd为第d个装置的麦克风的个数,n为多个信号源的个数;对于每一个信号源、每一个装置及每一个讯框,计算向量xd[τ,k;fd]与向量a
n,d
[k;fd]之间的差异,其中向量a
n,d
[k;fd]表示矩阵ad[k;f1]中的第n个行,n为小于等于n的正整数;根据差异建立目标函数,并根据目标函数执行最佳化演算法以计算混和矩阵;以及根据混和矩阵与向量xd[τ,k;fd]计算信号源所对应的多个原始信号,而不计算装置之间的取样频率误差。
[0004]
在一些实施例中,上述的差异为向量xd[τ,k;fd]与向量a
n,d
[k;fd]之间的余弦相似度。
[0005]
在一些实施例中,上述的盲源分离方法,还包括:根据差异计算一判别项,判别项如以下数学式所示,其中r为一实数,为向量a
n,d
[k;fd]的共轭转置。
[0006][0007]
在一些实施例中,目标函数表示为以下数学式,其中t为讯框的个数。
[0008][0009]
在一些实施例中,执行最佳化演算法的步骤包括:根据以下数学式计算目标函数的一次导数;将混和矩阵减去次导数与学习率的乘积再加上选择性的动量项以更新混和矩阵,或者将混和矩阵减去次导数与黑赛矩阵(hessian matrix)的近似值的乘积以更新混和矩阵。
[0010][0011][0012][0013][0014][0015]
在一些实施例中,目标函数表示为以下数学式。
[0016][0017]
在一些实施例中,执行最佳化演算法的步骤包括:根据以下数学式计算目标函数的一次导数;将混和矩阵减去次导数与学习率的乘积再加上选择性的动量项以更新混和矩阵,或者将混和矩阵减去次导数与黑赛矩阵(hessian matrix)的近似值的乘积以更新混和矩阵。
[0018][0019]
[0020][0021][0022][0023]
在一些实施例中,根据混和矩阵与装置所对应的向量xd[τ,k;fd]计算信号源所对应的原始信号的步骤包括:组成一向量其中c=∑cd,d为装置的个数;以及将混和矩阵的反矩阵乘上向量x[τ,k]以得到原始信号,或者根据混和矩阵与向量x[τ,k]取得频率域遮罩,将频率域遮罩乘上向量x[τ,k]以得到原始信号。
[0024]
以另一个角度来说,本揭露的实施例提出一种音频处理系统,包括:多个装置,每一个装置包括多个麦克风,每一个装置的每一个麦克风用以感测一声音信号;以及一服务器,上述的装置与服务器用以执行多个步骤:(a)将每一个声音信号分为多个讯框,并对每一个讯框执行一时间至频率域转换以产生在一时间频率域的向量xd[τ,k;fd],其中d表示第d个装置,fd表示第d个装置的取样频率,τ表示第τ个讯框,k表示第k个频率系数索引;(b)设定一混和矩阵a[k]=[a1[k;f1]
t
,...,ad[k;fd]
t
]
t
,其中d表示装置的个数,矩阵ad[k;f1]对应至第d个装置,矩阵ad的大小为cd×
n,cd为第d个装置的麦克风的个数,n为多个信号源的个数;(c)对于每一个信号源、每一个装置及每一个讯框,计算向量xd[τ,k;fd]与一向量a
n,d
[k;fd]之间的一差异,其中向量a
n,d
[k;fd]表示矩阵ad[k;f1]中的第n个行,n为小于等于n的正整数;(d)根据差异建立一目标函数,并根据目标函数执行一最佳化演算法以计算混和矩阵;以及(e)根据混和矩阵与装置所对应的向量xd[τ,k;fd]计算信号源所对应的多个原始信号,而不计算装置之间的取样频率误差。
[0025]
在一些实施例中,装置将声音信号传送至服务器,由服务器执行步骤(a)~(e)。
[0026]
在一些实施例中,装置执行步骤(a)~(c)以计算出多个判别项,并且将这些判别项传送至服务器。服务器根据判别项计算至少一讯框索引,并将至少一讯框索引传送至装置以更新混和矩阵。
附图说明
[0027]
为让本发明的上述特征和优点能更明显易懂,下文特举实施例,并配合所附附图作详细说明如下。
[0028]
图1是根据一些实施例绘示音频处理系统的示意图;
[0029]
图2是根据一些实施例绘示集中式机制的流程图;
[0030]
图3是根据一些实施例绘示分散式机制的流程图;
[0031]
图4是根据一些实施例绘示在分散式机制下装置与服务器之间传输数据的示意图。
[0032]
【符号说明】
[0033]
100:音频处理系统
[0034]
101~103:装置
[0035]
111~113:信号源
[0036]
120:服务器
[0037]
201~215,301~303:步骤
[0038]
230:缓冲器
具体实施方式
[0039]
为了使本揭示内容的叙述更加详尽与完备,下文针对了本发明的实施态样与具体实施例提出了说明性的描述;但这并非实施或运用本发明具体实施例的唯一形式。实施方式中涵盖了多个具体实施例的特征以及用以建构与操作这些具体实施例的方法步骤与其顺序。然而,亦可利用其他具体实施例来达成相同或均等的功能与步骤顺序。
[0040]
关于本文中所使用的“第一”、“第二”等,并非特别指次序或顺位的意思,其仅为了区别以相同技术用语描述的元件或操作。
[0041]
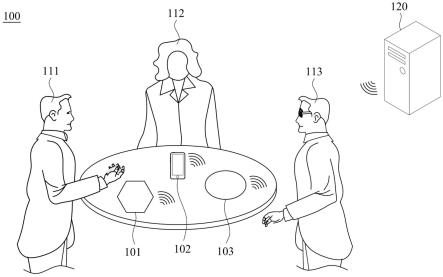
图1是根据一些实施例绘示音频处理系统的示意图。请参照图1,音频处理系统100包括多个装置101~103与服务器120。装置101~103可以是智能手机、平板、笔记型计算机、或任意具有录音功能的电子设备。每个装置101~103包括多个麦克风,每个麦克风也代表一个通道,每个使用者111~113代表一个信号源。在此,共有d个装置,其中第d个装置所量测到的信号向量表示为xd=[x
d,1
[n],...,x
d,c
[n]]
t
,其中x
d,c
[n]表示第d个装置在第c个通道在离散时间的第n个取样,其中d、d、c、n为正整数。如果第1个装置的取样频率表示为f1,则第1个装置连续至离散的取样可以表示为以下数学式(1),而第1个装置与第d个装置之间的取样频率不匹配(即取样频率误差)可以表示为以下数学式(2)。
[0042][0043][0044]
其中x1()表示第1个装置在连续时间的信号,而x1[]表示第1个装置在离散时间的信号。∈d是第d个装置相对于第1个装置的取样频率误差,δd是第d个装置录音的起始时间与第1个装置录音的起始时间之间的离散时间误差。在此,这个起始时间误差δd可以透过任意合适的已知演算法来求得,例如以下数学式(3)可计算出δd。
[0045][0046]
其中
★
为互相关(cross-correlation)运算子,在计算出起始时间误差δd以后则可以根据以下数学式(4)来对声音信号做补偿。
[0047]
xd[n]
←
xd[n-δd]
ꢀꢀꢀꢀ
(4)
[0048]
在已知技术中会计算取样频率误差∈d,然后对信号重新取样,但这样的做法需要很大的计算量。在此揭露中并不需要计算取样频率误差∈d也不需要重新取样。我们假设每个装置101~103包括至少两个通道,并且在同一个装置中的通道是以相同的频率来取样,在这样的假设下,可以分别对每个装置个别推导出一个判别项。透过这个判别项可以整合装置之间的信息,并学习所有装置的混和矩阵(mixing matrix),一旦计算出混和矩阵便可以计算出信号源的原始信号。
[0049]
在此假设自组(ad-hoc)麦克风阵列共有d个装置,其中第d个装置具有cd≥2个通道(即麦克风)。我们假设每一个装置内的通道之间并没有取样频率误差,因此取样频率误差只发生在装置之间。c=∑cd表示所有通道的数目。基于交混回响(reverberation),每个装置上所录制的声音信号是可卷积(convolutive)的。
[0050]
首先取得每一个装置的每一个麦克风所感测的声音信号,将每个声音信号分为多个讯框,在此并不限制讯框的长度,并对每一个讯框执行一时间至频率域转换以产生在一时间频率域(time frequency domain,tf-domain)的向量xd[τ,k;fd]。上述的时间至频率域转换例如为短时傅立叶转换(short term fourier transform,stft)。向量xd[τ,k;fd]包括了第d个装置的cd个通道所取样的声音信号,其中为第d个装置的第c个通道所感测的声音信号经过短时傅立叶转换后第τ个讯框中的第k个频率系数索引(frequency bin index),fd为第d个装置的取样频率。在此,我们假设所有装置中的第τ个讯框都约略的对应至相同的连续时间区间,这在声音信号的长度较短或是取样频率误差较小时成立,如此一来在所有装置中第τ个讯框中的原始信号是大致上相同的。向量xd[τ,k;fd]是经由信号源的原始信号与混和矩阵在时间频率域下的相乘所产生,如以下数学式(5)所示。
[0051]
xd[τ,k;fd]=ad[k;fd]sd[τ,k;fd]
ꢀꢀꢀ
(5)
[0052]
其中混和矩阵ad[k;fd]的大小为cd×
n,n为所有信号源111~113的个数。向量sd[τ,k;fd]是n个信号源所发出的原始信号被第d个装置所取样后在时间频率域下的表示(不同的装置可采用不同的取样频率),此向量的大小为n。上述数学式(5)只考虑一个装置,如果同时考虑所有的装置,则可根据以下数学式(6)~(8)将多个向量/矩阵组合起来。
[0053][0054][0055][0056]
因此,上述数学式(5)可改写为以下数学式(9)。
[0057]
x[τ,k]=a[k]s[τ,k]
ꢀꢀꢀꢀ
(9)
[0058]
其中向量x[τ,k]的长度为c,矩阵a[k]的大小为c
×
nd。向量s[τ,k]的长度为nd。在此是要先计算出混和矩阵a[k],然后根据混和矩阵a[k]与向量x[τ,k]计算原始信号s[τ,k],例如将将混和矩阵a[k]的反矩阵乘上向量x[τ,k]以计算出原始信号s[τ,k],或者根据混和矩阵a[k]与向量x[τ,k]取得一频率域遮罩,将此频率域遮罩乘上向量x[τ,k]以得到原
始信号,本领域通常知识者当可理解如何根据数学式(9)计算出向量s[τ,k]。如此一来便不需要计算取样频率误差。
[0059]
在此实施例中,对于每一个信号源n、每一个装置d及每一个讯框k,都会计算向量xd[τ,k;fd]与向量a
n,d
[k;fd]之间的差异,此差异例如为余弦相似度,但在其他实施例中也可以采用尤拉距离或任意合适的差异度/相似度。其中向量a
n,d
[k;fd]表示矩阵ad[k;f1]中的第n个行,n为小于等于n的正整数。根据此差异可以计算一判别项,如以下数学式(10)所示。
[0060][0061]
其中r为实数,可经由实验设定。为向量a
n,d
[k;fd]的共轭转置(conjugate transpose)。接着根据此判别项可建立一目标函数,根据目标函数可执行最佳化演算法来计算出混和矩阵a[k]。以下举两个实施例详细说明。
[0062]
在第一个实施例中,可取d个装置中所有判别项的最小值来建立目标函数j
(asyndsf-min)
,如以下数学式(11)所示。
[0063][0064]
其中t为讯框的个数。在另一个实施例中,可取d个装置中判别项的最大值来建立目标函数j
(asyndsf-max)
,如以下数学式(12)所示。
[0065][0066]
在其他实施例中,也可以取d个装置中所有判别项的平均值来建立目标函数,为了简化起见并不列出目标函数。值得注意的是,不论是目标函数j
(asyndsf-min)
或是j
(asyndsf-min)
,都只需要一个装置上的区域信息,这些信息预设已经被同步,这是因为同一个装置上的模拟数字转换器使用相同的时脉信号,但不同的装置之间则没有。物理上来说,当混和矩阵a[k]正确的计算时,判别项zd[τ,k]会变成0,也就是说当混和矩阵a[k]不正确时判别项zd[τ,k]会是一个大的数值。直觉上,我们希望在所有的讯框与频率系数索引下都产生小的判别项zd[τ,k]。当要求解上述的数学式(11)、(12)时,可先计算次导数(sub-gradient),分别如以下数学式(13)、(14)。
[0067][0068][0069]
其中
[0070][0071]
[0072][0073][0074][0075]
在此会重复更新混和矩阵a[k]多次,每次的更新是把混和矩阵减去次导数与一学习率的乘积再加上一选择性的动量项,此动量项是指上一次更新的混和矩阵a[k]乘上小于1的实数,而学习率可经由实验设定。或者在每次更新中,可该混和矩阵减去次导数与黑赛矩阵(hessian matrix)的近似值的乘积。值得注意的是最小函数min与最大函数max的次导数是0或是1,这隐含了在每次更新时只有次导数不是0的讯框会用来更新矩阵ad[k;fd]。当采用数学式(11)、(13)时,混和矩阵a[k]是用有最小判别项的讯框来更新;当采用数学式(12)、(14)时,混和矩阵a[k]是用有最大判别项的讯框来更新。在一些实验中,采用数学式(12)、(14)的效果会比较好。
[0076]
简单来说,上述提出的方法可以区域性的在每个装置上计算判别项,因此不需要计算取样频率误差。此外,在更新混和矩阵时只需要一部分的讯框,因此需要较少的计算量与传输频宽,这可达成即时处理。
[0077]
以下提供两个机制来实作上述的方法,分别是集中式机制与分散式机制。在集中式的机制中,每个装置101~103必须要把声音信号传送至服务器120,由服务器120来执行盲源分离方法。举例来说,图2是根据一实施例绘示集中式机制的流程图。请参照图2,首先从装置101~103收集声音信号,步骤201~215则是由服务器120执行。在步骤201,计算并补偿起始时间误差,接着在步骤202执行短时傅立叶转换,转换后的数据暂存在缓冲器230。在步骤203中则更新混和矩阵,步骤203可再包括步骤204~213。
[0078]
在步骤204中,对声音信号执行白化(whitening),例如执行主成分分析(principle component analyze,pca)。在步骤205中,执行正规化,例如l2正规化。在步骤206中,初始化混和矩阵。步骤207可包括步骤208~211。在步骤208中,执行平坦化,把混和矩阵转换为向量。在步骤209中,设定成本函数(即目标函数)。在步骤210中,采用基于梯度的优化器(gradient-based optimizer)来更新向量。在步骤211中,执行反平坦化,把更新后的向量转换为矩阵。在步骤212中,执行软遮罩(soft mask)。具体来说,步骤212可表示为以下数学式(15)、(16)。
[0079]
[0080][0081]
其中运算子表示哈达玛德(hadamard)元素乘法。β为实数,例如为12.5。在步骤213中,进行排列组合以对齐矩阵。在步骤214中,执行盲源分离,也就是根据声音信号与混和矩阵来计算出对应于信号源的原始信号。在步骤215,执行逆短时傅立叶转换,最后得到时间域的原始信号。
[0082]
图3是根据一实施例绘示分散式机制的流程图。请参照图3,步骤201~206、301、212~215是由装置101~103所执行。图3与图2的差异在于步骤301,其包括了步骤302、303。请参照图3与图4,在步骤302中,由装置101~103计算出各自的判别项,并把判别项传送至服务器120。服务器根据判别项来建立成本函数(目标函数),执行最佳化演算法以后得到所要更新的讯框,借此可以产生至少一个讯框索引。接下来在步骤303装置101~103接收来自服务器120的讯框索引,并根据这些讯框索引来更新混和矩阵。值得注意的是,集中式机制所需要的数据频宽是正比于装置上的通道数,但在分散式机制可以减少数据频宽。举例来说,如果每个装置上有6个麦克风(通道),则分散式机制可以减少6倍的数据频宽。
[0083]
上述提出的盲源分离方法可以应用在任意的技术领域,例如声音增强、语音辨识、自然语言处理、文字产生或言语分析,本揭露并不限制上述的盲源分离方法被应用在什么领域或应用。
[0084]
虽然本发明已以实施例揭露如上,然其并非用以限定本发明,任何所属技术领域中具有通常知识者,在不脱离本发明的精神和范围内,当可作些许的更动与润饰,故本发明的保护范围当视所附的权利要求书所界定的范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1