有机化合物的制造方法及棒状细菌与流程
本发明涉及一种有机化合物的制造方法及棒状细菌。
背景技术:
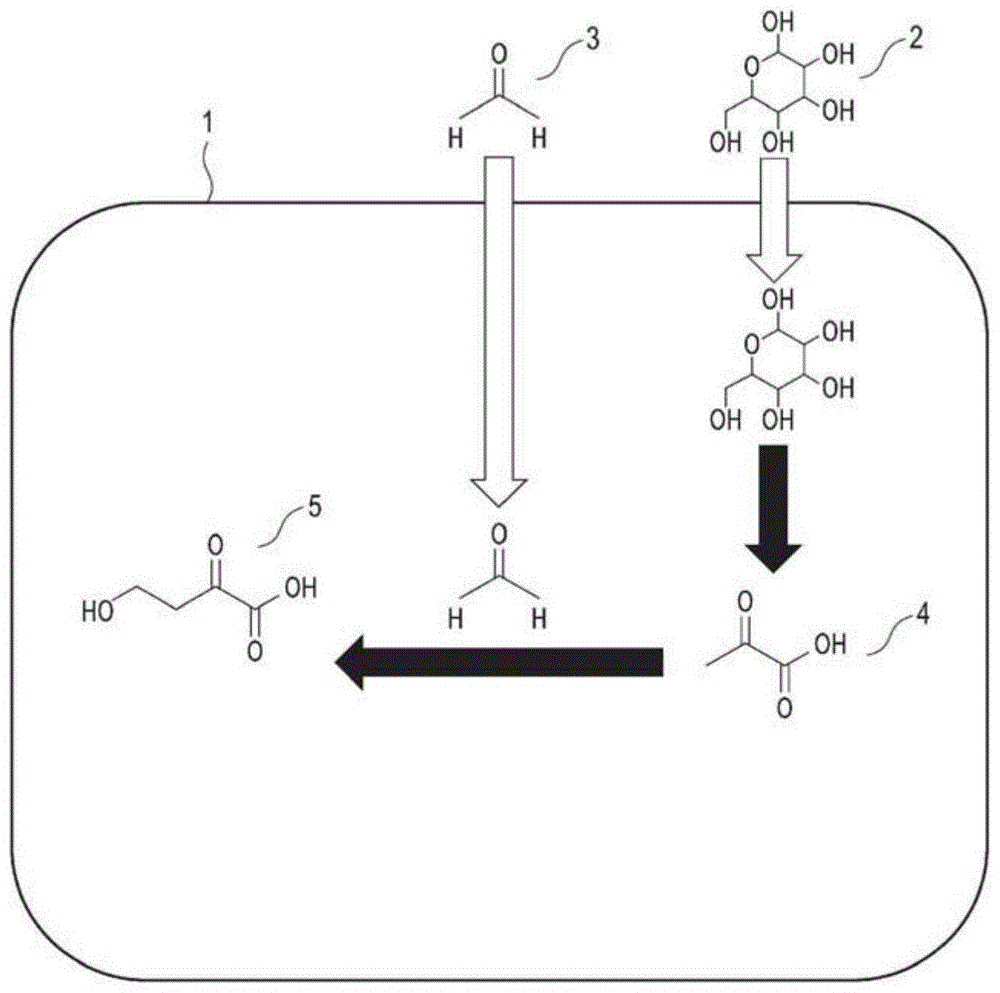
:现在,强烈希望将作为可再生资源的生物资源用作原料,代替被认为是全球变暖元凶的石油资源来生产化成品。因此,出于由糖类等来源于生物的原料生产化成品的目的,正在积极地进行研究,以便使用微生物及其转化体来生产用于工业原料、燃料、饲料、食品添加物等的化成品。例如,报告有使用酵母或大肠杆菌的转化体,由糖类来制造醇或氨基酸等有机化合物的情况(参照美国专利第9926577号、美国专利第8647847号)。技术实现要素:发明所要解决的问题本发明的目的在于提供一种制造有机化合物的新颖方法及可用于所述制造方法的棒状细菌。使用微生物生产化成品时,作为其生产对象,通常限定于微生物代谢物。另外,即使是微生物代谢物,也存在很多因微生物代谢系统中的能量不足或氧化还原平衡的不均衡而难以生产的微生物代谢物。作为用以解决此种课题的一个有效方法(approach),可列举制作转化体。但本发明人等人认为,若仅通过该方法来解决课题,则开发能够生产对象化合物的菌体有时会花费大量时间。另一方面,考虑今后会要求微生物代谢物以外的多种化合物也由来源于生物的原料来生产。因此,本发明人等人研究开发一种新颖的工艺,所述工艺对于有用物质的生产,并非仅依赖于制作微生物的转化体。解决问题的技术手段本发明人等人进行了努力研究,结果发现了通过在羰基化合物的存在下对具有特定的基因的微生物进行培养来获得氨基酸等作为有用物质合成的关键的中间体的生产工艺,从而完成了本发明。根据本发明的第一方面,提供一种α-酮酸的制造方法,包括:在丙酮酸供给化合物以及羰基化合物的存在下对微生物进行培养以生产α-酮酸的工序,其中,所述微生物包含对催化丙酮酸与羰基化合物的羟醛反应的酶进行编码的基因,所述丙酮酸供给化合物选自丙酮酸及糖类中,所述羰基化合物由下述通式(1)表示:r101c(o)r102(此处,r101及r102相互独立地为氢、或具有1个~5个碳原子的烷基),所述α-酮酸由下述通式(2)表示:r101c(r102)(oh)ch2cocooh(所述通式(2)中的r101及r102分别为与所述通式(1)中的r101及r102相同的基)。根据本发明的第二方面,提供一种1,3-二醇的制造方法,包括:在丙酮酸供给化合物以及羰基化合物的存在下对微生物进行培养以生产1,3-二醇的工序,其中,所述微生物包含以下基因:(a)第一基因,对催化丙酮酸与羰基化合物的羟醛反应的酶进行编码,(b)第二基因,对催化α-酮酸的脱羧反应的酶进行编码,及(c)第三基因,对催化醛的还原反应的酶进行编码,所述丙酮酸供给化合物选自丙酮酸及糖类中,所述羰基化合物由下述通式(3)表示:r103c(o)r104(此处,r103及r104相互独立地为氢、或具有1个~5个碳原子的烷基。其中,当r103为氢时,r104不为氢),所述1,3-二醇由下述通式(4)表示:r103c(r104)(oh)ch2ch2oh(所述通式(4)中的r103及r104分别为与所述通式(3)中的r103及r104相同的基)。根据本发明的第三方面,提供一种1,3-丁二醇的制造方法,包括:在选自丙酮酸及糖类中的丙酮酸供给化合物的存在下对微生物进行培养以生产1,3-丁二醇的工序,其中,所述微生物包含以下基因:(a)第一基因,对催化丙酮酸与羰基化合物的羟醛反应的酶进行编码,(b)第二基因,对催化α-酮酸的脱羧反应的酶进行编码,及(c)第三基因,对催化醛的还原反应的酶进行编码。根据本发明的第四方面,提供一种2,4-二羟基羧酸的制造方法,包括:在丙酮酸供给化合物以及羰基化合物的存在下对微生物进行培养以生产2,4-二羟基羧酸的工序,其中,所述微生物包含以下基因:(a)第一基因,对催化丙酮酸与羰基化合物的羟醛反应的酶进行编码,及(d)第四基因,对催化α-酮酸的还原反应的酶进行编码,所述丙酮酸供给化合物选自丙酮酸及糖类中,所述羰基化合物由下述通式(1)表示:r101c(o)r102(此处,r101及r102相互独立地为氢、或具有1个~5个碳原子的烷基),所述2,4-二羟基羧酸由下述通式(5)表示:r101c(r102)(oh)ch2ch(oh)cooh(所述通式(5)中的r101及r102分别为与所述通式(1)中的r101及r102相同的基)。根据本发明的第五方面,提供一种2-氨基-4-羟基羧酸的制造方法,包括:使α-酮酸、氮源以及还原剂在谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶的存在下进行反应,以生产2-氨基-4-羟基羧酸的工序,其中,所述α-酮酸由下述通式(2)表示:r101c(r102)(oh)ch2cocooh(此处,r101及r102相互独立地为氢、或具有1个~5个碳原子的烷基),所述2-氨基-4-羟基羧酸由下述通式(6)表示:r101c(r102)(oh)ch2ch(nh2)cooh(所述通式(6)中的r101及r102分别为与所述通式(2)中的r101及r102相同的基)。根据本发明的第六方面,提供一种α-酮酸的制造方法,包括:使2-氨基-4-羟基羧酸以及氧化剂在谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶的存在下进行反应,以生产α-酮酸的工序,其中,所述2-氨基-4-羟基羧酸由下述通式(6)表示:r101c(r102)(oh)ch2ch(nh2)cooh(此处,r101及r102相互独立地为氢、或具有1个~5个碳原子的烷基),所述α-酮酸由下述通式(2)表示:r101c(r102)(oh)ch2cocooh(所述通式(2)中的r101及r102分别为与所述通式(6)中的r101及r102相同的基)。根据本发明的第七方面,提供一种2-氨基-4-羟基羧酸的制造方法,包括:在丙酮酸供给化合物以及羰基化合物的存在下对微生物进行培养以生产2-氨基-4-羟基羧酸的工序,其中,所述微生物包含以下基因:(a)第一基因,对催化丙酮酸与羰基化合物的羟醛反应的酶进行编码,及(e)第五基因,对催化α-酮酸的还原氨基化反应的酶进行编码,所述丙酮酸供给化合物选自丙酮酸及糖类中,所述羰基化合物由下述通式(1)表示:r101c(o)r102(此处,r101及r102相互独立地为氢、或具有1个~5个碳原子的烷基),所述2-氨基-4-羟基羧酸由下述通式(6)表示:r101c(r102)(oh)ch2ch(nh2)cooh(所述通式(6)中的r101及r102分别为与所述通式(1)中的r101及r102相同的基)。根据本发明的第八方面,提供一种高丝氨酸、苏氨酸及2-氨基丁酸中的至少一者的制造方法,包括:在选自丙酮酸及糖类中的丙酮酸供给化合物以及甲醛的存在下对微生物进行培养,以生产高丝氨酸、苏氨酸及2-氨基丁酸中的至少一者的工序,其中,所述微生物包含以下基因:(a)第一基因,对催化丙酮酸与羰基化合物的羟醛反应的酶进行编码,及(e)第五基因,对催化α-酮酸的还原氨基化反应的酶进行编码。根据本发明的第九方面,提供一种2-氨基-4-甲基硫代羧酸的制造方法,包括:在丙酮酸供给化合物、甲硫醇(methylmercaptan)、以及羰基化合物的存在下对微生物进行培养以生产2-氨基-4-甲基硫代羧酸的工序,其中,所述微生物包含以下基因:(a)第一基因,对催化丙酮酸与羰基化合物的羟醛反应的酶进行编码,(e)第五基因,对催化α-酮酸的还原氨基化反应的酶进行编码,及(f)第六基因,对催化由甲硫醇所具有的甲巯基(methylmercapto)取代2-氨基-4-膦酰氧基羧酸所具有的磷酸基的反应的酶进行编码,所述丙酮酸供给化合物选自丙酮酸及糖类中,所述羰基化合物由下述通式(1)表示:r101c(o)r102(此处,r101及r102相互独立地为氢、或具有1个~5个碳原子的烷基),所述2-氨基-4-甲基硫代羧酸由下述通式(7)表示:r101c(r102)(sch3)ch2ch(nh2)cooh(所述通式(7)中的r101及r102分别为与所述通式(1)中的r101及r102相同的基)。根据本发明的第十方面,提供一种棒状细菌,包含选自由以下所组成的群组中的第一基因:(1-1)对包含序列号2中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-2)对包含序列号2中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-3)对包含序列号4中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-4)对包含序列号4中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-5)对包含序列号6中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,及(1-6)对包含序列号6中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因。根据本发明,提供一种制造有机化合物的方法及可用于所述制造方法的棒状细菌。附图说明图1是表示微生物生产4-羟基-2-氧代丁酸的工艺的示意图。图2是表示微生物生产1,3-丁二醇的工艺的示意图。图3是表示微生物生产2,4-二羟基丁酸的工艺的示意图。图4是表示微生物生产高丝氨酸的工艺的示意图。图5是表示微生物生产蛋氨酸的工艺的示意图。图6是表示气相色谱仪质谱的结果的图。图7是表示气相色谱仪质谱的结果的图。图8是表示气相色谱仪质谱的结果的图。图9是表示气相色谱仪质谱的结果的图。具体实施方式以下对本发明进行详细说明,但以下说明的目的在于对本发明进行详细说明,并未意图限定本发明。(1.)α-酮酸的制造方法α-酮酸的制造方法包括:在丙酮酸供给化合物以及羰基化合物的存在下对微生物进行培养以生产α-酮酸的工序,其中,所述微生物包含对催化丙酮酸与羰基化合物的羟醛反应的酶进行编码的基因,所述丙酮酸供给化合物选自丙酮酸及糖类中,所述羰基化合物由下述通式(1)表示:r101c(o)r102(此处,r101及r102相互独立地为氢、或具有1个~5个碳原子的烷基),所述α-酮酸由下述通式(2)表示:r101c(r102)(oh)ch2cocooh(所述通式(2)中的r101及r102分别为与所述通式(1)中的r101及r102相同的基)。在以下说明中,将包含对催化丙酮酸与羰基化合物的羟醛反应的酶进行编码的基因(以下称为第一基因)的所述微生物也称为“α-酮酸生产微生物”。α-酮酸生产微生物可为原本便具有第一基因的微生物,也可为通过利用第一基因对宿主进行转化而获得的微生物。以下,以α-酮酸生产微生物为转化体的情况为例进行说明。(1.1)转化体(1.1.1)宿主作为宿主,可使用任意的微生物。作为宿主,例如可使用酵母、细菌,更具体而言,可使用好氧性细菌,更具体而言,可使用棒状细菌(corynebacteria)、大肠杆菌、或需钠弧菌(vibrionatriegens)。优选宿主为棒状细菌。所谓棒状细菌,是伯杰氏细菌鉴定手册[bargeysmanualofdeterminativebacteriology,第8卷(vol.8),599(1974)]中所定义的一群组微生物,只要是在通常的好氧条件下增殖的微生物,则并无特别限定。若列举具体例,则可列举:棒状杆菌属菌、短杆菌(brevibacterium)属菌、节杆菌(arthrobacter)属菌、分枝杆菌(mycobacterium)属菌、微球菌(micrococcus)属菌等。在棒状细菌中,优选为棒状杆菌属菌。作为棒状杆菌属菌,可列举:谷氨酸棒状杆菌(corynebacteriumglutamicum)、有效棒状杆菌(corynebacteriumefficiens)、产氨棒状杆菌(corynebacteriumammoniagenes)、耐盐棒状杆菌(corynebacteriumhalotolerance)、解烷棒状杆菌(corynebacteriumalkanolyticum)等。其中,就α-酮酸的生产性高的方面而言,优选为谷氨酸棒状杆菌。作为优选的菌株,可列举:美国菌种保藏中心(americantypeculturecollection,atcc)13032株、atcc13869株、atcc13058株、atcc13059株、atcc13060株、atcc13232株、atcc13286株、atcc13287株、atcc13655株、atcc13745株、atcc13746株、atcc13761株、atcc14020株、atcc31831株、mj-233(fermbp-1497)、mj-233ab-41(fermbp-1498)等。其中,优选为atcc13032株、atcc13869株。此外,根据分子生物学的分类,黄色短杆菌(brevibacteriumflavum)、乳糖发酵短杆菌(brevibacteriumlactofermentum)、散枝短杆菌(brevibacteriumdivaricatum)、百合棒状杆菌(corynebacteriumlilium)等棒状细菌的菌名也统一于谷氨酸棒状杆菌(corynebacteriumglutamicum)中[利布尔等人(liebl,w.etal.,)散枝短杆菌dsm20297t、“黄色短杆菌”dsm20411、“乳糖发酵短杆菌”dsm20412和dsm1412、与谷氨酸棒状杆菌的转化及其利用rrna基因限制性图案的区分(transferofbrevibacteriumdivaricatumdsm20297t,“brevibacteriumflavum”dsm20411,“brevibacteriumlactofermentum”dsm20412anddsm1412,andcorynebacteriumglutamicumandtheirdistinctionbyrrnagenerestrictionpatterns.)国际系统菌学杂志(internationaljournalofsystematicbacteriology,intjsystbacteriol.)41:255-260.(1991),驹形和男等,棒状细菌的分类,发酵与工业,45:944-963(1987)]。旧分类的乳糖发酵短杆菌atcc13869株、黄色短杆菌的mj-233株(fermbp-1497)、mj-233ab-41株(fermbp-1498)等也是优选的谷氨酸棒状杆菌。作为短杆菌属菌,可列举产氨短杆菌(brevibacteriumammoniagenes)(例如atcc6872株)等。作为节杆菌属菌,可列举球形节杆菌(arthrobacterglobiformis)(例如atcc8010株、atcc4336株、atcc21056株、atcc31250株、atcc31738株、atcc35698株)等。作为分枝杆菌属菌,可列举牛分枝杆菌(mycobacteriumbovis)(例如atcc19210株、atcc27289株)等。作为微球菌属菌,可列举弗氏微球菌(micrococcusfreudenreichii)(例如no.239株(fermp-13221))、藤黄微球菌(micrococcusleuteus)(例如no.240株(fermp-13222))、脲微球菌(micrococcusureae)(例如应用微生物研究所(instituteofappliedmicrobiology,iam)1010株)、玫瑰色微球菌(micrococcusroseus)(例如大阪发酵研究所(instituteoffermentationosaka,ifo)3764株)等。接着,对导入宿主中的第一基因进行说明。(1.1.2)第一基因第一基因对“催化丙酮酸与羰基化合物的羟醛反应的酶”进行编码。所谓“催化丙酮酸与羰基化合物的羟醛反应的酶”,是指依照后述的测定方法,且作为酶反应液而使用包含纯化蛋白质、丙酮酸(初始基质浓度1mm)及羰基化合物(初始基质浓度1mm)的酶反应液来进行测定时,具有10毫活性单位/毫克蛋白质(mu/mgprotein)以上的活性的酶。“催化丙酮酸与羰基化合物的羟醛反应的酶”中的羰基化合物例如为甲醛、乙醛、丙醛、丁醛、异丁醛、戊醛或丙酮。丁醛具体而言为正丁醛或异丁醛。戊醛具体而言为正戊醛。“催化丙酮酸与羰基化合物的羟醛反应的酶”例如为醛缩酶(aldolase)。第一基因可为对以下所例示的醛缩酶进行编码的基因。(a1)2-脱氢-3-脱氧-磷酸葡萄糖酸醛缩酶(2-dehydro-3-deoxy-phosphogluconatealdolase,酶学委员会(enzymecommission,ec)编号:4.1.2.14),(a2)2-脱氢-3-脱氧-6-磷酸葡萄糖酸醛缩酶(2-dehydro-3-deoxy-6-phosphogluconatealdolase,ec编号4.1.2.55),(a3)4-羟基-2-氧代戊二酸醛缩酶(4-hydroxy-2-oxoglutaratealdolase,ec编号:4.1.3.16),(a4)(4s)-4-羟基-2-氧代戊二酸醛缩酶((4s)-4-hydroxyl-2-oxoglutaratealdolase,ec编号4.1.3.42),(a5)2-脱氢-3-脱氧-d-戊糖酸醛缩酶(2-dehydro-3-deoxy-d-pentonatealdolase,ec编号4.1.2.28),(a6)2-脱氢-3-脱氧-d-葡萄糖酸醛缩酶(2-dehydro-3-deoxy-d-gluconatealdolase,ec编号4.1.2.51),(a7)3-脱氧-d-甘露-辛酮糖酸醛缩酶(3-deoxy-d-manno-octulosonatealdolase,ec编号4.1.2.23),(a8)4-羟基-2-氧代戊酸醛缩酶(4-hydroxyl-2-oxovaleratealdolase,ec编号4.1.3.39),(a9)4-(2-羧基苯基)-2-氧代丁-3-烯酸醛缩酶(4-(2-carboxyphenyl)-2-oxobut-3-enoatealdolase,ec编号4.1.2.34),(a10)4-羟基-2-氧代庚烷二酸醛缩酶(4-hydroxy-2-oxoheptanedioatealdolase,ec编号4.1.2.52),(a11)2-脱氢-3-脱氧葡萄糖二酸醛缩酶(2-dehydro-3-deoxyglucaratealdolase,ec编号4.1.2.20),(a12)2-酮-3-脱氧-l-鼠李糖酸醛缩酶(2-keto-3-deoxy-l-rhamnonatealdolase,ec编号4.1.2.53),(a13)4-羟基-4-甲基-2-氧代戊二酸醛缩酶(4-hydroxyl-4-methyl-2-oxoglutaratealdolase,ec编号4.1.3.17),及(a14)4-羟基-2-氧代己酸醛缩酶(4-hydroxy-2-oxohexanonatealdolase,ec编号4.1.3.43)。作为(a1)、(a2)、(a3)及(a4)中包含的醛缩酶,例如可列举eda蛋白质。优选eda蛋白质来源于大肠杆菌。作为(a2)中包含的醛缩酶,例如可列举dgoa蛋白质。优选dgoa蛋白质来源于大肠杆菌。作为(a5)中包含的醛缩酶,例如可列举yjhh蛋白质。优选yjhh蛋白质来源于大肠杆菌。作为(a6)中包含的醛缩酶,例如可列举yage蛋白质。优选yage蛋白质来源于大肠杆菌。作为(a7)中包含的醛缩酶,例如可列举nana蛋白质。优选nana蛋白质来源于大肠杆菌。作为(a8)中包含的醛缩酶,例如可列举mhpe蛋白质。优选mhpe蛋白质来源于大肠杆菌。此外,在第一基因为mhpe基因的情况下,mhpe基因可在与mhpf基因连结的状态下导入宿主中。作为(a8)及(a10)中包含的醛缩酶,例如可列举hpai蛋白质。优选hpai蛋白质来源于大肠杆菌。作为(a8)及(a14)中包含的醛缩酶,例如可列举bphi蛋白质。优选bphi蛋白质来源于食异源化合物伯克霍尔德氏菌(burkholderiaxenovorans)。此外,在第一基因为bphi基因的情况下,bphi基因可在与bphj基因连结的状态下导入宿主中。作为(a9)中包含的醛缩酶,例如可列举phdj蛋白质。优选phdj蛋白质来源于类诺卡氏菌属菌(nocardioidessp.)。作为(a11)中包含的醛缩酶,例如可列举garl蛋白质。优选garl蛋白质来源于大肠杆菌。作为(a12)中包含的醛缩酶,例如可列举rhma蛋白质。优选rhma蛋白质来源于大肠杆菌。作为(a13)中包含的醛缩酶,例如可列举galc蛋白质。优选galc蛋白质来源于恶臭假单胞菌(pseudomonasputida)。第一基因可对i类醛缩酶进行编码,也可对ii类醛缩酶进行编码。作为i类醛缩酶,例如可列举:eda蛋白质、yjhh蛋白质、yage蛋白质、dgoa蛋白质、nana蛋白质、mphe蛋白质及phdj蛋白质。作为ii类醛缩酶,例如可列举:hpai蛋白质、garl蛋白质、rhma蛋白质、galc蛋白质及bphi蛋白质。优选第一基因选自由以下所组成的群组中:(1-1)对作为包含序列号2中记载的氨基酸序列的蛋白质(即,来源于大肠杆菌的hpai蛋白质)的、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-2)对包含序列号2中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-3)对作为包含序列号4中记载的氨基酸序列的蛋白质(即,来源于大肠杆菌的rhma蛋白质)的、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-4)对包含序列号4中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-5)对作为包含序列号6中记载的氨基酸序列的蛋白质(即,来源于大肠杆菌的nana蛋白质)的、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-6)对包含序列号6中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-7)对作为包含序列号8中记载的氨基酸序列的蛋白质(即,来源于大肠杆菌的eda蛋白质)的、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-8)对包含序列号8中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-9)对作为包含序列号10中记载的氨基酸序列的蛋白质(即,来源于大肠杆菌的yjhh蛋白质)的、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-10)对包含序列号10中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-11)对作为包含序列号12中记载的氨基酸序列的蛋白质(即,来源于大肠杆菌的dgoa蛋白质)的、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-12)对包含序列号12中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-13)对作为包含序列号14中记载的氨基酸序列的蛋白质(即,来源于大肠杆菌的mhpe蛋白质)的、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-14)对包含序列号14中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-15)对作为包含序列号16中记载的氨基酸序列的蛋白质(即,来源于大肠杆菌的garl蛋白质)的、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-16)对包含序列号16中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-17)对作为包含序列号18中记载的氨基酸序列的蛋白质(即,来源于恶臭假单胞菌的galc蛋白质)的、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-18)对包含序列号18中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-19)对作为包含序列号20中记载的氨基酸序列的蛋白质(即,来源于类诺卡氏菌属菌的phdj蛋白质)的、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-20)对包含序列号20中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-21)对作为包含序列号22中记载的氨基酸序列的蛋白质(即,来源于食异源化合物伯克霍尔德氏菌的bphi蛋白质)的、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,及(1-22)对包含序列号22中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因。在本说明书中,“一个或多个氨基酸缺失、经取代或加成而成的”这一表述中的“一个或多个”根据氨基酸残基在蛋白质的立体结构中的位置或氨基酸残基的种类而不同,优选意指1个~60个,更优选意指1个~30个,进而优选意指1个~15个,进而优选意指1个~10个,进而优选意指1个~5个。所述一个或多个氨基酸的缺失、取代或加成例如为正常维持蛋白质的功能下的保守性突变。作为保守性突变,代表性的是保守性取代。所谓保守性取代,在取代部位为芳香族氨基酸的情况下,是在phe、trp、tyr间彼此进行取代的突变,在取代部位为疏水性氨基酸的情况下,是在leu、ile、val间彼此进行取代的突变,在取代部位为极性氨基酸的情况下,是在gln、asn间彼此进行取代的突变,在取代部位为碱性氨基酸的情况下,是在lys、arg、his间彼此进行取代的突变,在取代部位为酸性氨基酸的情况下,是在asp、glu间彼此进行取代的突变,在取代部位为具有羟基的氨基酸的情况下,是在ser、thr间彼此进行取代的突变。作为可视作保守性取代的取代,具体而言,可列举:ala取代为ser或thr;arg取代为gln、his或lys;asn取代为glu、gln、lys、his或asp;asp取代为asn、glu或gln;cys取代为ser或ala;gln取代为asn、glu、lys、his、asp或arg;glu取代为gly、asn、gln、lys或asp;gly取代为pro、his取代为asn、lys、gln、arg或tyr;ile取代为leu、met、val或phe;leu取代为ile、met、val或phe;lys取代为asn、glu、gln、his或arg;met取代为ile、leu、val或phe;phe取代为trp、tyr、met、ile或leu;ser取代为thr或ala;thr取代为ser或ala;trp取代为phe或tyr;tyr取代为his、phe或trp;及val取代为met、ile或leu。另外,氨基酸的缺失、取代或加成还包括基因在基于来源细菌的个体差异、种类不同的情况等下天然产生的突变(变异(mutant)或变型(variant))所产生的突变。“对包含序列号2中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因”可为“对包含相对于序列号2中记载的氨基酸序列而具有80%以上、优选为90%以上、更优选为95%以上、进而优选为97%以上、进而优选为98%以上、进而优选为99%以上的同一性的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因”。“对包含序列号4中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因”可为“对包含相对于序列号4中记载的氨基酸序列而具有80%以上、优选为90%以上、更优选为95%以上、进而优选为97%以上、进而优选为98%以上、进而优选为99%以上的同一性的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因”。“对包含序列号6中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因”可为“对包含相对于序列号6中记载的氨基酸序列而具有80%以上、优选为95%以上、更优选为97%以上、进而优选为98%以上、进而优选为99%以上的同一性的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因”。“对包含序列号8中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因”可为“对包含相对于序列号8中记载的氨基酸序列而具有80%以上、优选为95%以上、更优选为97%以上、进而优选为98%以上、进而优选为99%以上的同一性的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因”。“对包含序列号10中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因”可为“对包含相对于序列号10中记载的氨基酸序列而具有80%以上、优选为95%以上、更优选为97%以上、进而优选为98%以上、进而优选为99%以上的同一性的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因”。“对包含序列号12中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因”可为“对包含相对于序列号12中记载的氨基酸序列而具有80%以上、优选为95%以上、更优选为97%以上、进而优选为98%以上、进而优选为99%以上的同一性的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因”。“对包含序列号14中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因”可为“对包含相对于序列号14中记载的氨基酸序列而具有80%以上、优选为95%以上、更优选为97%以上、进而优选为98%以上、进而优选为99%以上的同一性的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因”。“对包含序列号16中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因”可为“对包含相对于序列号16中记载的氨基酸序列而具有80%以上、优选为95%以上、更优选为97%以上、进而优选为98%以上、进而优选为99%以上的同一性的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因”。“对包含序列号18中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因”可为“对包含相对于序列号18中记载的氨基酸序列而具有80%以上、优选为95%以上、更优选为97%以上、进而优选为98%以上、进而优选为99%以上的同一性的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因”。“对包含序列号20中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因”可为“对包含相对于序列号20中记载的氨基酸序列而具有80%以上、优选为95%以上、更优选为97%以上、进而优选为98%以上、进而优选为99%以上的同一性的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因”。“对包含序列号22中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因”可为“对包含相对于序列号22中记载的氨基酸序列而具有80%以上、优选为95%以上、更优选为97%以上、进而优选为98%以上、进而优选为99%以上的同一性的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因”。来源于大肠杆菌的hpai蛋白质的通用蛋白质资源知识库(universalproteinresourceknowledgebase,uniprotkb)登录号(accessionnumber)例如为q47098,来源于大肠杆菌的rhma蛋白质的uniprotkb登录号例如为p76469,来源于大肠杆菌的nana蛋白质的uniprotkb登录号例如为p0a6l4,来源于大肠杆菌的eda蛋白质的uniprotkb登录号例如为p0a955,来源于大肠杆菌的yjhh蛋白质的uniprotkb登录号例如为p39359,来源于大肠杆菌的dgoa蛋白质的uniprotkb登录号例如为q6bf16,来源于大肠杆菌的mhpe蛋白质的uniprotkb登录号例如为p51020,来源于大肠杆菌的garl蛋白质的uniprotkb登录号例如为p23522,来源于恶臭假单胞菌的galc蛋白质的uniprotkb登录号例如为q88jx9,来源于类诺卡氏菌属菌的phdj蛋白质的uniprotkb登录号例如为q79em8,来源于食异源化合物伯克霍尔德氏菌的bphi蛋白质的uniprotkb登录号例如为p51015。更优选第一基因为:包含序列号1中记载的碱基序列的来源于大肠杆菌的hpai基因、包含序列号3中记载的碱基序列的来源于大肠杆菌的rhma基因、包含序列号5中记载的碱基序列的来源于大肠杆菌的nana基因、包含序列号7中记载的碱基序列的来源于大肠杆菌的eda基因、包含序列号9中记载的碱基序列的来源于大肠杆菌的yjhh基因、包含序列号11中记载的碱基序列的来源于大肠杆菌的dgoa基因、包含序列号13中记载的碱基序列的来源于大肠杆菌的mhpe基因、包含序列号15中记载的碱基序列的来源于大肠杆菌的garl基因、包含序列号17中记载的碱基序列的来源于来源于恶臭假单胞菌的galc基因、包含序列号19中记载的碱基序列的来源于类诺卡氏菌属菌的phdj基因、或包含序列号21中记载的碱基序列的来源于食异源化合物伯克霍尔德氏菌的bphi基因。序列号1、序列号3、序列号5、序列号7、序列号9、序列号11、序列号13、序列号15、序列号17、序列号19及序列号21中记载的碱基序列与序列号2、序列号4、序列号6、序列号8、序列号10、序列号12、序列号14、序列号16、序列号18、序列号20及序列号22中记载的氨基酸序列如下。[表1][表2][表3][表4][表5][表6][表7][表8][表9][表10][表11][表12][表13][表14][表15][表16][表17][表18][表19][表20][表21][表22]氨基酸序列的同一性可使用卡林及阿尔丘尔(karlinandaltschul)的算法即基本局部比对搜索工具(basiclocalalignmentsearchtool,blast)[美国科学院院报(proceedingsofthenationalacademyofsciencesoftheunitedstatesofamerica,pro.natl.acad.sci.usa),90,5873(1993)]或快速自适应收缩/阈值算法(fastadaptiveshrinkage/thresholdingalgorithm,fasta)[酶学方法(methodsinenzymology,methodsenzymol.),183,63(1990)]来决定。基于所述算法blast,开发了一种称为blastn或blastx的程序[分子生物学杂志(journalofmolecularbiology,j.mol.biol.),215,403(1990)]。另外,在基于blast而利用blastx对氨基酸序列进行分析的情况下,参数例如设为分值(score)=50、字长(wordlength)=3。为了获得空位比对(gappedalignment),如阿尔丘尔(altschul)等人(1997,核酸研究(nucleicacidsresearch,nucleicacidsres.)25:3389-3402)所记载,可利用空位blast(gappedblast)。或者可使用psi-blast或phi-blast来进行用以检测分子间的位置关系(id.)及共有共同图案的分子间的关系的重复检索。在利用blast、gappedblast、psi-blast及phi-blast程序的情况下,可使用各程序的默认参数(defaultparameter)。请参照http://www.ncbi.nlm.nih.gov.。催化丙酮酸与羰基化合物的羟醛反应的活性例如可通过以下方式来算出:在含有2mm氯化镁的100mm4-(2-羟乙基)-1-哌嗪乙烷磺酸(4-(2-hydroxyethyl)-1-piperazineethanesulfonicacid,hepes)-氢氧化钠(naoh)缓冲液(buffer)(ph8.0)中在25℃下进行所述酶反应,测定由作为原料的丙酮酸与羰基化合物生成的羟醛化合物的初始生成速度。羟醛化合物的生成速度例如可根据羟醛化合物自身浓度的时间变化来算出。羟醛化合物的浓度的测定例如可通过以下方式来进行:通过将酶反应液与130mm的o-苄基羟基胺盐酸盐溶液(吡啶:甲醇:水=33:15:2)的溶液以1:5混合而使反应停止,使用高效液相色谱来检测此时由羟醛化合物生成的o-苄基肟衍生物,并与浓度已知的样品进行比较。此处,将在25℃、1分钟内形成1μmol的羟醛化合物的活性设为1个单位。“对包含序列号2中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因(以下称为hpai基因突变体)”例如可通过聚合酶链式反应(polymerasechainreaction,pcr)或杂交(hybridization)而自其他生物种的脱氧核糖核酸(deoxyribonucleicacid,dna)文库(library)中选择,所述pcr或杂交使用了依照基于序列号2的碱基序列的信息而设计的引物(primer)或探针(probe)。以所述方式选择的基因以高概率对具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行了编码。“对包含序列号4中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因(rhma基因突变体)”可通过与选择hpai基因突变体的所述方法相同的方法而自其他生物种的dna文库中选择。“对包含序列号6中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因(nana基因突变体)”可通过与选择hpai基因突变体的所述方法相同的方法而自其他生物种的dna文库中选择。“对包含序列号8中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因(eda基因突变体)”可通过与选择hpai基因突变体的所述方法相同的方法而自其他生物种的dna文库中选择。“对包含序列号10中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因(yjhh基因突变体)”可通过与选择hpai基因突变体的所述方法相同的方法而自其他生物种的dna文库中选择。“对包含序列号12中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因(dgoa基因突变体)”可通过与选择hpai基因突变体的所述方法相同的方法而自其他生物种的dna文库中选择。“对包含序列号14中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因(mhpe基因突变体)”可通过与选择hpai基因突变体的所述方法相同的方法而自其他生物种的dna文库中选择。“对包含序列号16中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因(garl基因突变体)”可通过与选择hpai基因突变体的所述方法相同的方法而自其他生物种的dna文库中选择。“对包含序列号18中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因(galc基因突变体)”可通过与选择hpai基因突变体的所述方法相同的方法而自其他生物种的dna文库中选择。“对包含序列号20中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因(phdj基因突变体)”可通过与选择hpai基因突变体的所述方法相同的方法而自其他生物种的dna文库中选择。“对包含序列号22中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因(bphi基因突变体)”可通过与选择hpai基因突变体的所述方法相同的方法而自其他生物种的dna文库中选择。(1.1.3)用于转化的重组载体的构建第一基因可组入到适当的质粒载体(plasmidvector)中以进行转化。作为质粒载体,可根据宿主而使用公知的质粒载体。作为质粒载体,可包含在宿主内掌控自主复制功能的基因,也可包含组入到宿主的染色体时所需的碱基序列。可使用所获得的重组载体来制作转化体。(1.1.4)转化转化方法可无限制地使用公知的方法。作为此种公知的方法,例如可列举氯化钙/氯化铷法、磷酸钙法、二乙氨基乙基(diethylaminoethyl,deae)-葡聚糖(dextran)介导转染(transfection)、电脉冲法等。所获得的转化体可在转化后迅速使用通常用于转化体的培养的培养基进行培养。培养温度只要是适于转化体增殖的温度,则可为任意温度。培养基的ph只要是适于转化体增殖的ph,则可为任意ph。培养基的ph调整可通过公知的方法进行。培养时间只要是对于转化体的增殖而言充分的时间,则可为任意时间。此外,在如上所述使用重组载体制作转化体的情况下,第一基因的可组入到宿主的染色体中,或者也可以重组载体的形态存在于宿主的细胞质内。(1.1.5)宿主染色体基因的破坏或缺失宿主不仅可为野生株,也可为其突变株或人工的基因重组体。在宿主为棒状细菌的情况下,宿主可为通过使作为野生株的棒状细菌本来所具有的下述基因的至少一个破坏或缺失而获得的基因破坏株或基因缺失株:乳酸(lactate)脱氢酶(lactatedehydrogenase,例如ldha)基因、磷酸烯醇丙酮酸羧化酶(phosphoenolpyrvatecarboxylase,例如ppc)基因、丙酮酸羧化酶(pyruvatecarboxylase,例如pyc)基因、丙酮酸脱氢酶(pyruvatedehydrogenase,例如poxb)基因、谷氨酸-丙酮酸氨基转移酶(glutamate-pyruvateaminotransferase,例如alaa)基因、乙酰乳酸合酶(acetolactatesynthase,例如ilvb)基因、n-琥珀酰二氨基庚二酸(n-succinyldiaminopimelateaminotransferase,例如cg0931)基因、s-(羟甲基)分枝硫醇脱氢酶(s-(hydroxymethyl)mycothioldehydrogenase,例如adhe)基因、及乙醛脱氢酶(acetaldehydedehydrogenase,例如ald)基因。通过将此种基因破坏株或基因缺失株用作宿主,可提高α-酮酸的生产性、或抑制副生成物的生成。基因破坏株或基因缺陷株的构建可通过公知的方法进行。(1.1.6)α-酮酸生产微生物的具体例具体而言,作为α-酮酸生产微生物,可使用包含选自由以下所组成的群组中的第一基因的棒状细菌:(1-1)对包含序列号2中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-2)对包含序列号2中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-3)对包含序列号4中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-4)对包含序列号4中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-5)对包含序列号6中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,及(1-6)对包含序列号6中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因。(1.2)培养工序可在丙酮酸供给化合物及羰基化合物的存在下对α-酮酸生产微生物(例如所述转化体)进行培养,以生产α-酮酸。“在丙酮酸供给化合物及羰基化合物的存在下进行培养”可通过在包含丙酮酸供给化合物及羰基化合物的培养液中进行培养来进行。“在丙酮酸供给化合物及羰基化合物的存在下进行培养”优选可通过在添加了丙酮酸供给化合物及羰基化合物的培养液中进行培养来进行。在丙酮酸供给化合物及羰基化合物的存在下进行培养之前,优选在好氧条件下对所述转化体进行培养以使其增殖。所述在好氧条件下进行的培养以下称为增殖培养,在丙酮酸供给化合物及羰基化合物的存在下进行的培养以下称为生产培养。具体而言,例如,所谓在好氧条件下进行的培养,是指在培养期间以对于转化体增殖而言充分的量向培养液中供给氧的条件下进行培养。在好氧条件下进行的培养可通过公知的方法进行。在好氧条件下进行的培养例如可通过利用通气、搅拌、振荡或它们的组合而向培养液中供给氧来实现。更具体而言,在好氧条件下进行的培养可通过振荡培养、深部通气搅拌培养来实现。当在生产培养之前进行增殖培养时,增殖培养与其后的生产培养例如可以如下方式进行。在增殖培养后,首先,可将包含增殖培养中所使用的培养液(以下称为增殖用培养液)以及悬浮于增殖用培养液中的转化体的容器置于离心分离机中,使转化体沉淀。然后,可自容器中去除增殖用培养液,并将分离出的转化体悬浮于生产培养中使用的培养液(以下称为生产用培养液)中,以进行生产培养。或者,增殖培养与其后的生产培养可通过在增殖培养后向含有转化体的增殖用培养液中添加丙酮酸供给化合物及羰基化合物,并将好氧条件变更为厌氧条件或微好氧条件,由此在不进行培养液的更换的条件下进行生产培养。如此,也可连续进行增殖培养与生产培养。在本说明书中,“培养”这一用语是指在适于转化体生长的受到特定管理的条件下维持转化体。在培养期间,转化体可增殖,也可不增殖。因此,“培养”这一用语也可改称为“孵化(incubation)”。(1.2.1)增殖用培养液增殖用培养液可使用通常用于转化体的培养的培养基,例如含有碳源、氮源及无机盐类等的公知的培养基。增殖培养的培养温度只要是适于转化体增殖的温度,则可为任意温度。增殖用培养液的ph只要是适于转化体增殖的ph,则可为任意ph。增殖用培养液的ph调整可通过公知的方法进行。增殖培养的培养时间只要是对于转化体的增殖而言充分的时间,则可为任意时间。(1.2.2)生产用培养液作为生产用培养液,可使用含有丙酮酸供给化合物、羰基化合物、及其他必要成分的培养液。作为其他必要成分,例如可使用无机盐类、糖类以外的碳源、或氮源。本说明书中记载的培养液中的各成分的浓度是指添加各成分的时间点下的培养液中的最终浓度。作为丙酮酸供给化合物,可使用选自丙酮酸及糖类中的化合物。丙酮酸供给化合物可为丙酮酸本身,也可为在微生物的生物体内转变为丙酮酸的糖类。作为丙酮酸供给化合物,可使用丙酮酸、糖类、或它们的组合。作为糖类,只要是转化体可纳入生物体内且可转变为丙酮酸的糖类,则可使用任意的糖类。具体而言,作为糖类,可列举葡萄糖、果糖、甘露糖、木糖、阿拉伯糖、半乳糖之类的单糖;蔗糖、麦芽糖、乳糖、纤维二糖(cellobiose)、木二糖(xylobiose)、海藻糖之类的二糖;淀粉之类的多糖;糖蜜等。其中,优选为单糖,更优选为果糖及葡萄糖。另外,也优选为包含葡萄糖作为构成单糖的糖类,具体而言为蔗糖等二糖、包含葡萄糖作为构成单糖的寡糖、包含葡萄糖作为构成单糖的多糖。糖类可使用一种,也可混合使用两种以上。另外,糖类也可以糖化液(其包含葡萄糖、木糖等多种糖类)的形式添加,所述糖化液是通过利用糖化酶等对稻草、蔗渣(bagasse)、玉米秸秆(cornstover)等非可食用农产废弃物、或柳枝稷(switchgrass)、象草、芒草等能源作物加以糖化而获得。在不妨碍α-酮酸的生产的范围内,生产用培养液中丙酮酸供给化合物的浓度可尽可能地提高。生产用培养液中丙酮酸供给化合物的浓度优选在0.1(w/v)%~40(w/v)%的范围内,更优选在1(w/v)%~20(w/v)%的范围内。另外,可与伴随α-酮酸的生产而丙酮酸供给化合物减少的情况对应地进行丙酮酸供给化合物的追加添加。作为羰基化合物,可使用由下述通式(1)表示的羰基化合物:r101c(o)r102(此处,r101及r102相互独立地为氢、或具有1个~5个碳原子的烷基)。根据一例,作为羰基化合物,可使用所述通式(1)中r101为氢或具有1个~5个碳原子的烷基且r102为氢的羰基化合物。根据另一例,羰基化合物可使用所述通式(1)中r101为甲基且r102为具有1个~5个碳原子的烷基的羰基化合物。具体而言,作为羰基化合物,可使用以下羰基化合物:在所述通式(1)中,r101为氢且r102为氢的羰基化合物(即,甲醛);r101为甲基且r102为氢的羰基化合物(即,乙醛);r101为乙基且r102为氢的羰基化合物(即,丙醛);r101为丙基且r102为氢的羰基化合物(即,丁醛),具体而言,r101为正丙基且r102为氢的羰基化合物(即,正丁醛)、或r101为异丙基且r102为氢的羰基化合物(即,异丁醛);或者r101为戊基且r102为氢的羰基化合物(即,戊醛),具体而言,r101为正戊基且r102为氢的羰基化合物(即,正戊醛)。另外,作为羰基化合物,也可使用所述通式(1)中r101及r102均为甲基的羰基化合物(即,丙酮)。羰基化合物可使用一种,也可混合使用两种以上。生产用培养液中羰基化合物的浓度优选在0.001(w/v)%~10(w/v)%的范围内,更优选在0.01(w/v)%~1(w/v)%的范围内。另外,可与伴随α-酮酸的生产而羰基化合物减少的情况对应地进行羰基化合物的追加添加。此外,当在生产用培养液中使用一种羰基化合物时,可容易地进行后述“(1.2.4)α-酮酸的回收”一栏中记载的分离纯化。进而,根据需要,还可添加无机盐类。作为无机盐类,可使用磷酸盐、硫酸盐、镁、钾、锰、铁、锌等金属盐。具体而言,可使用磷酸亚钾、磷酸钾、硫酸镁、氯化钠、硝酸亚铁、硫酸铁(ii)、硫酸锰、硫酸锌、硫酸钴、碳酸钙等。无机盐可使用一种,也可混合使用两种以上。生产用培养液中无机盐类的浓度根据所使用的无机盐而不同,但通常可设为约0.01(w/v)%~1(w/v)%。进而,根据需要,还可添加糖类以外的碳源。作为糖类以外的碳源,可使用:甘露醇、山梨糖醇、木糖醇、甘油(glycerol)、丙三醇(glycerin)之类的糖醇;乙酸、柠檬酶、乳酸、富马酸、马来酸、葡萄糖酸之类的有机酸;正烷烃(normalparaffin)之类的烃等。进而,根据需要,还可添加氮源。作为氮源,可使用:氯化铵、硫酸铵、硝酸铵、乙酸铵之类的无机或有机的铵盐;尿素;氨水;硝酸钠、硝酸钾等硝酸盐等。另外,也可使用:玉米浆(cornsteepliquor);肉提取物;酵母膏;大豆水解物;蛋白胨、nz-胺或酪蛋白分解物等蛋白质水解物;氨基酸等含氮有机化合物等。氮源可使用一种,也可混合使用两种以上。生产用培养液中氮源的浓度根据使用的氮化合物而不同,但通常可设为约0.1(w/v)%~10(w/v)%。进而,根据需要,还可添加维生素类。作为维生素类,可列举:生物素、硫胺素(维生素b1)、吡哆醇(维生素b6)、泛酸、肌醇、烟酸等。作为具体的生产用培养液,可使用包含葡萄糖、甲醛、磷酸二氢钾、磷酸氢二钾、硫酸镁、硫酸铁(ii)及硫酸锰(ii)且具有6.0的ph的培养基。作为具体的生产用培养液,也可使用包含丙酮酸、甲醛、磷酸二氢钾、磷酸氢二钾、硫酸镁、硫酸铁(ii)、硫酸锰(ii)及4-吗啉丙磺酸的培养基。另外,作为生产用培养液,也可使用在与增殖培养中所使用的增殖用培养液相同组成的基础培养液中添加丙酮酸供给化合物与羰基化合物而获得的培养液。此外,在所述基础培养液中存在充分量的丙酮酸供给化合物的情况下,也可不添加丙酮酸供给化合物。(1.2.3)生产培养的条件生产培养的培养温度只要是适于生产α-酮酸的温度,则可为任意温度。生产培养的培养温度优选为约20℃~50℃,更优选为约25℃~47℃。若为所述温度范围,则可效率良好地制造α-酮酸。生产用培养液的ph只要是适于生产α-酮酸的ph,则可为任意ph。生产用培养液的ph优选维持于约6~8的范围内。生产用培养液的ph调整可使用无机酸或有机酸;氢氧化钾水溶液等碱溶液;尿素;碳酸钙;氨;包含4-吗啉丙磺酸等的ph缓冲液等进行。在生产培养过程中也可根据需要适宜调整生产用培养液的ph。生产培养的培养时间只要是对于转化体生产α-酮酸而言充分的时间,则可为任意时间。生产培养的培养时间优选为约3小时~7天,更优选为约1天~3天。生产培养可在好氧条件下进行,也可在厌氧条件或微好氧条件下进行。其原因在于:所述转化体具有在好氧条件下及厌氧条件或微好氧条件下均起作用的生产α-酮酸的途径。生产α-酮酸的途径在后述的“(1.3)作用及效果”一栏中叙述。<厌氧条件或微好氧条件>生产培养优选在厌氧条件或微好氧条件下进行。若在厌氧条件下或微好氧条件下培养转化体,则转化体实质上不会增殖,可更有效率地生产α-酮酸。“厌氧条件或微好氧条件”例如是指生产用培养液中的溶解氧浓度在0ppm~2ppm范围内的条件。“厌氧条件或微好氧条件”优选是指生产用培养液中的溶解氧浓度在0ppm~1ppm范围内的条件,更优选是指生产用培养液中的溶解氧浓度在0ppm~0.5ppm范围内的条件。培养液中的溶解氧浓度例如可使用溶解氧计来测定。严格来说,“厌氧条件”是指不存在溶解氧及硝酸等氧化物之类的电子受体的条件的技术用语。另一方面,作为生产培养的优选条件,若为如下所述,则不需要采用所述严格的条件:所述电子受体并不充分,或者基于所述电子受体的性质,转化体不会增殖,且相应地供给的碳源被用于α-酮酸的生产,从而可提高其生产效率。即,作为生产培养的优选条件,只要可抑制转化体的增殖并提高α-酮酸的生产效率,则生产用培养液中也可存在溶解氧及硝酸等氧化物之类的电子受体。因此,本说明书中使用的“厌氧条件或微好氧条件”这一表述也包括此种状态。厌氧条件及微好氧条件例如可通过不通入包含氧的气体,使得自气液界面供给的氧对转化体的增殖而言变得不充分来实现。或者可通过在生产用培养液中通入惰性气体、具体而言为氮气来实现。或者可通过将用于生产培养的容器加以密闭来实现。<高密度条件>生产培养优选在使转化体高密度地悬浮于生产用培养液中的状态下进行。若在此种状态下培养转化体,则可更有效率地生产α-酮酸。“使转化体高密度地悬浮于生产用培养液中的状态”例如是指以转化体的湿菌体重量%成为1(w/v)%~50(w/v)%的范围内的方式使转化体悬浮于生产用培养液中的状态。“使转化体高密度地悬浮于生产用培养液中的状态”优选是指以转化体的湿菌体重量%成为3(w/v)%~30(w/v)%的范围内的方式使转化体悬浮于生产用培养液中的状态。生产培养更优选在厌氧条件或微好氧条件下,在使转化体高密度地悬浮于生产用培养液中的状态下进行。(1.2.4)α-酮酸的回收如上所述,当在生产用培养液中对包含第一基因的转化体进行培养时,在生产用培养液中会生产出α-酮酸。具体而言,当在生产用培养液中使用由下述通式(1):r101c(o)r102(此处,r101及r102相互独立地为氢、或具有1个~5个碳原子的烷基)表示的羰基化合物时,可生产由下述通式(2)表示的α-酮酸:r101c(r102)(oh)ch2cocooh(所述通式(2)中的r101及r102分别为与所述通式(1)中的r101及r102相同的基)。更具体而言,在使用所述通式(1)中r101为氢且r102为氢的羰基化合物的情况下,可生产所述通式(2)中r101为氢且r102为氢的α-酮酸(即,4-羟基-2-氧代丁酸)。在使用所述通式(1)中r101为甲基且r102为氢的羰基化合物的情况下,可生产所述通式(2)中r101为甲基且r102为氢的α-酮酸(即,4-羟基-2-氧代戊酸)。在使用所述通式(1)中r101为乙基且r102为氢的羰基化合物的情况下,可生产所述通式(2)中r101为乙基且r102为氢的α-酮酸(即,4-羟基-2-氧代己酸)。在使用所述通式(1)中r101为丙基且r102为氢的羰基化合物的情况下,可生产所述通式(2)中r101为丙基且r102为氢的α-酮酸(即,4-羟基-2-氧代庚酸)。具体而言,在使用所述通式(1)中r101为正丙基且r102为氢的羰基化合物的情况下,可生产所述通式(2)中r101为正丙基且r102为氢的α-酮酸(即,4-羟基-2-氧代正庚酸)。另外,具体而言,在使用所述通式(1)中r101为异丙基且r102为氢的羰基化合物的情况下,可生产所述通式(2)中r101为异丙基且r102为氢的α-酮酸(即,4-羟基-2-氧代异庚酸)。在使用所述通式(1)中r101为戊基且r102为氢的羰基化合物的情况下,可生产所述通式(2)中r101为戊基且r102为氢的α-酮酸(即,4-羟基-2-氧代辛酸)。具体而言,在使用所述通式(1)中r101为正戊基且r102为氢的羰基化合物的情况下,可生产所述通式(2)中r101为正戊基且r102为氢的α-酮酸(即,4-羟基-2-氧代正辛酸)。在使用所述通式(1)中r101及r102均为甲基的羰基化合物的情况下,可生产所述通式(2)中r101及r102均为甲基的α-酮酸(即,4-甲基-4-羟基-2-氧代戊酸)。可通过回收生产用培养液来回收所述α-酮酸,但也可进一步通过公知的方法自生产用培养液中分离纯化α-酮酸。作为此种公知的方法,可列举晶析法、色谱法、离子交换树脂法、活性炭吸附洗脱法、溶媒萃取法等。另外,在使用多种羰基化合物的情况下,培养液中会生产出多种α-酮酸。多种α-酮酸可通过晶析或色谱相互分离。(1.3)作用及效果将α-酮酸生产微生物生产α-酮酸的工艺示意性地示于图1。在图1所示的工艺中,以丙酮酸供给化合物为葡萄糖、羰基化合物为甲醛、α-酮酸为4-羟基-2-氧代丁酸的情况为例进行说明。如图1所示,首先,α-酮酸生产微生物1纳入葡萄糖2及甲醛3。接着,葡萄糖2通过糖酵解体系而转变为丙酮酸4。接着,丙酮酸4与甲醛3通过第一基因所编码的“催化丙酮酸与醛的羟醛反应的酶”而转变为4-羟基-2-氧代丁酸5。以如上方式生产4-羟基-2-氧代丁酸。在图1中,对使用醛作为羰基化合物的情况进行了说明,但即使在使用酮作为羰基化合物的情况下,通过“催化丙酮酸与羰基化合物的羟醛反应的酶”,也进行将酮与丙酮酸转变为α-酮酸的反应。其原因在于:醛与酮均属于同一种类的化合物(即,羰基化合物),因此在酶反应等有机化学反应中,醛与酮均可成为同一反应的基质。上述中所说明的制法发现了通过如上所述般在羰基化合物的存在下对具有特定的基因的微生物进行培养而获得氨基酸等作为有用物质合成的关键的中间体的生产工艺,从而得以完成。一般而言,羰基化合物对微生物的生长是有害的,因此在其存在下获得了有用的化合物令人惊讶。另外,此时,所述羰基化合物被纳入微生物代谢体系中,因此可获得在通常的微生物代谢体系中不会生产的中间体,此可有望作为满足由生物来源原料制作多种化合物这一未来需求的方法。实际上,如本说明书之后所述,经由所述中间体可开展各种有用物质的生产的情况显示了通过本发明技术可生产多种化合物的可能性的一部分。(2.)1,3-二醇的制造方法1,3-二醇的制造方法包括:在丙酮酸供给化合物以及羰基化合物的存在下对微生物进行培养以生产1,3-二醇的工序,其中,所述微生物包含以下基因:(a)第一基因,对催化丙酮酸与羰基化合物的羟醛反应的酶进行编码,(b)第二基因,对催化α-酮酸的脱羧反应的酶进行编码,及(c)第三基因,对催化醛的还原反应的酶进行编码,所述丙酮酸供给化合物选自丙酮酸及糖类中,所述羰基化合物由下述通式(3)表示:r103c(o)r104(此处,r103及r104相互独立地为氢、或具有1个~5个碳原子的烷基。其中,当r103为氢时,r104不为氢),所述1,3-二醇由下述通式(4)表示:r103c(r104)(oh)ch2ch2oh(所述通式(4)中的r103及r104分别为与所述通式(3)中的r103及r104相同的基)。在以下说明中,将包含第一基因、第二基因及第三基因的所述微生物也称为“1,3-二醇生产微生物”。1,3-二醇生产微生物可为原本便具有第一基因、第二基因及第三基因的微生物,也可为通过利用第一基因、第二基因及第三基因对宿主进行转化而获得的微生物。以下,以1,3-二醇生产微生物为转化体的情况为例进行说明。(2.1)转化体(2.1.1)宿主作为宿主,可使用与“(1.1.1)宿主”一栏中所记载的宿主相同的宿主。接着,对导入宿主中的第一基因、第二基因及第三基因进行说明。(2.1.2)第一基因作为第一基因,可使用与“(1.1.2)第一基因”一栏中所记载的第一基因相同的基因。(2.1.3)第二基因第二基因对“催化α-酮酸的脱羧反应的酶”进行编码。所谓“催化α-酮酸的脱羧反应的酶”,是指依照后述的测定方法,且作为酶反应液而使用包含纯化蛋白质及α-酮酸(初始基质浓度1mm)的酶反应液来进行测定时,具有1mu/mgprotein以上的活性的酶。第二基因对催化α-酮酸的脱羧反应的酶进行编码,所述α-酮酸例如是通过第一基因所编码的蛋白质催化的羟醛反应而获得。“催化α-酮酸的脱羧反应的酶”中的α-酮酸例如为“(1.)α-酮酸的制造方法”一栏中所记载的由通式(2)表示的α-酮酸。“催化α-酮酸的脱羧反应的酶”例如为脱羧酶(decarboxylase)。第二基因可为对以下所例示的脱羧酶进行编码的基因。(b1)丙酮酸脱羧酶(pyruvatedecarboxylase,ec编号4.1.1.1),(b2)苯甲酰甲酸脱羧酶(benzoylformatedecarboxylase,ec编号4.1.1.7),及(b3)吲哚丙酮酸脱羧酶(indolepyruvatedecarboxylase,ec编号4.1.1.74)。作为(b1)中包含的脱羧酶,例如可列举pdc蛋白质。优选pdc蛋白质来源于运动发酵单胞菌(zymomonasmobilis)。作为(b2)中包含的脱羧酶,例如可列举mdlc蛋白质。优选mdlc蛋白质来源于恶臭假单胞菌(pseudomonasputida)。作为(b3)中包含的脱羧酶,例如可列举kivd蛋白质。优选kivd蛋白质来源于乳酸乳球菌(lactococcuslactis)。优选第二基因选自由以下所组成的群组中:(2-1)对作为包含序列号24中记载的氨基酸序列的蛋白质(即,来源于恶臭假单胞菌的mdlc蛋白质)的、且催化α-酮酸的脱羧反应的蛋白质进行编码的基因,及(2-2)对包含序列号24中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的脱羧反应的活性的蛋白质进行编码的基因。“对包含序列号24中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的脱羧反应的活性的蛋白质进行编码的基因”可为“对包含相对于序列号24中记载的氨基酸序列而具有80%以上、优选为90%以上、更优选为95%以上、进而优选为97%以上、进而优选为98%以上、进而优选为99%以上的同一性的氨基酸序列、且具有催化α-酮酸的脱羧反应的活性的蛋白质进行编码的基因”。来源于恶臭假单胞菌的mdlc蛋白质的uniprotkb登录号例如为p20906。更优选第二基因为包含序列号23中记载的碱基序列的来源于恶臭假单胞菌的mdlc基因。序列号23中记载的碱基序列与序列号24中记载的氨基酸序列如下。[表23][表24]催化α-酮酸的脱羧反应的活性例如可通过以下方式来算出:在含有0.5mm硫胺素焦磷酸(thiaminepyrophosphate)、1mm氯化镁、10mm还原型烟酰胺腺嘌呤二核苷酸(reducedformofnicotinamideadeninedinucleotide,nadh)、过量的醇脱氢酶的100mm磷酸钾缓冲液(ph6.0)中在30℃下进行所述酶反应,测定由作为原料的α-酮酸生成的醛化合物被逐次还原而产生的醇化合物的初始生成速度。醇化合物的生成速度例如可根据醇化合物自身浓度的时间变化来算出。醇化合物的浓度的测定例如可通过以下方式来进行:使用高效液相色谱对所述醇化合物进行检测,并将其与浓度已知的样品加以比较。此处,将在30℃、1分钟内可使1μmol的α-酮酸脱羧的活性设为1个单位。“对包含序列号24中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的脱羧反应的活性的蛋白质进行编码的基因(mdlc基因突变体)”可通过与选择hpai基因突变体的所述方法相同的方法而自其他生物种的dna文库中选择。(2.1.4)第三基因第三基因对“催化醛的还原反应的酶”进行编码。所谓“催化醛的还原反应的酶”,是指依照后述的测定方法,且作为酶反应液而使用包含纯化蛋白质及醛(初始基质浓度1mm)的酶反应液来进行测定时,具有10mu/mgprotein以上的活性的酶。第三基因对催化醛的还原反应的酶进行编码,所述醛例如是通过第二基因所编码的蛋白质催化的脱羧反应而获得。“催化醛的还原反应的酶”中的醛例如为3-羟基丁醛、3-羟基戊醛、3-羟基己醛、3-羟基异己醛、3-羟基庚醛或3-甲基-3-羟基丁醛。“催化醛的还原反应的酶”例如为醇脱氢酶。第三基因例如可为对1,3-丙二醇脱氢酶(1,3-propanedioldehydrogenase,ec编号1.1.1.202)进行编码的基因。作为1,3-丙二醇脱氢酶,例如可列举dhat蛋白质或lpo蛋白质。优选dhat蛋白质来源于肺炎克雷伯菌(klebsiellapneumoniae)。另外,优选lpo蛋白质来源于罗伊氏乳杆菌(lactobacillusreuteri)。优选第三基因选自由以下所组成的群组中:(3-1)对作为包含序列号26中记载的氨基酸序列的蛋白质(即,来源于肺炎克雷伯菌的dhat蛋白质)的、且催化醛的还原反应的蛋白质进行编码的基因,及(3-2)对包含序列号26中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化醛的还原反应的活性的蛋白质进行编码的基因。“对包含序列号26中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化醛的还原反应的活性的蛋白质进行编码的基因”可为“对包含相对于序列号26中记载的氨基酸序列而具有80%以上、优选为90%以上、更优选为95%以上、进而优选为97%以上、进而优选为98%以上、进而优选为99%以上的同一性的氨基酸序列、且具有催化醛的还原反应的活性的蛋白质进行编码的基因”。来源于肺炎克雷伯菌的dhat蛋白质的uniprotkb登录号例如为q59477。更优选第三基因为包含序列号25中记载的碱基序列的来源于肺炎克雷伯菌的dhat基因。序列号25中记载的碱基序列与序列号26中记载的氨基酸序列如下。[表25][表26]催化醛的还原反应的活性例如可通过以下方式来算出:在含有0.2mmnadh的50mm2-(n-吗啉)乙磺酸(2-(n-morpholino)ethanesulfonicacid,mes)-naoh缓冲液(ph6.5)中在30℃下进行所述酶反应,测定作为原料的醛被还原为醇化合物时所消耗的nadh的初始消耗速度。nadh的初始消耗速度例如可通过测定来源于酶反应液中的nadh的、340nm下的吸光度的减少速度来算出。此处,将在30℃、1分钟内可使1μmol的醛还原的活性设为1个单位。“对包含序列号26中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化醛的还原反应的活性的蛋白质进行编码的基因(dhat基因突变体)”可通过与选择hpai基因突变体的所述方法相同的方法而自其他生物种的dna文库中选择。(2.1.5)用于转化的重组载体的构建第一基因、第二基因及第三基因可组入到适当的质粒载体中以进行转化。作为质粒载体,可使用与“(1.1.3)用于转化的重组载体的构建”一栏中所记载的质粒载体相同的质粒载体。第一基因、第二基因及第三基因分别可组入到各不相同的质粒载体中,或者也可组入到同一质粒载体中。可使用所获得的重组载体来制作转化体。(2.1.6)转化转化方法可无限制地使用公知的方法。作为此种公知的方法,可使用与“(1.1.4)转化”一栏中所记载的方法相同的方法。此外,在如上所述使用重组载体制作转化体的情况下,第一基因、第二基因及第三基因分别可组入到宿主的染色体中,或者也可以重组载体的形态存在于宿主的细胞质内。(2.1.7)宿主染色体基因的破坏或缺失宿主不仅可为野生株,也可为其突变株或人工的基因重组体。在宿主为棒状细菌的情况下,宿主可使用与“(1.1.5)宿主染色体基因的破坏或缺失”一栏中所记载的基因破坏株或基因缺失株相同的基因破坏株或基因缺失株。另外,作为制作基因破坏株或基因缺失株的方法,可使用与“(1.1.5)宿主染色体基因的破坏或缺失”一栏中所记载的方法相同的方法。通过将此种基因破坏株或基因缺失株用作宿主,可提高1,3-二醇的生产性、或抑制副生成物的生成。(2.1.8)1,3-二醇生产微生物的具体例具体而言,作为1,3-二醇生产微生物,可使用包含第一基因、第二基因及第三基因的棒状细菌,所述第一基因选自由以下所组成的群组中:(1-1)对包含序列号2中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-2)对包含序列号2中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-3)对包含序列号4中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-4)对包含序列号4中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-5)对包含序列号6中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,及(1-6)对包含序列号6中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因;所述第二基因选自由以下所组成的群组中:(2-1)对包含序列号24中记载的氨基酸序列、且催化α-酮酸的脱羧反应的蛋白质进行编码的基因,及(2-2)对包含序列号24中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的脱羧反应的活性的蛋白质进行编码的基因;所述第三基因选自由以下所组成的群组中:(3-1)对包含序列号26中记载的氨基酸序列、且催化醛的还原反应的蛋白质进行编码的基因,及(3-2)对包含序列号26中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化醛的还原反应的活性的蛋白质进行编码的基因。(2.2)培养工序可在丙酮酸供给化合物及羰基化合物的存在下对1,3-二醇生产微生物(例如所述转化体)进行培养,以生产1,3-二醇。“在丙酮酸供给化合物及羰基化合物的存在下进行培养”可通过在包含丙酮酸供给化合物及羰基化合物的培养液中进行培养来进行。“在丙酮酸供给化合物及羰基化合物的存在下进行培养”优选可通过在添加了丙酮酸供给化合物及羰基化合物的培养液中进行培养来进行。在丙酮酸供给化合物及羰基化合物的存在下进行培养之前,优选进行“(1.2)培养工序”一栏中所记载的增殖培养。当在生产培养之前进行增殖培养时,增殖培养与其后的生产培养例如可如“(1.2)培养工序”一栏所记载般进行。(2.2.1)增殖用培养液作为增殖用培养液,可使用与“(1.2.1)增殖用培养液”一栏中所记载的增殖用培养液相同的培养液。(2.2.2)生产用培养液作为生产用培养液,可使用含有丙酮酸供给化合物、羰基化合物、及其他必要成分的培养液。作为其他必要成分,例如可使用无机盐类、糖类以外的碳源或氮源。作为丙酮酸供给化合物,可使用“(1.2.2)生产用培养液”一栏中所记载的丙酮酸供给化合物。作为羰基化合物,可使用由下述通式(3)表示的羰基化合物:r103c(o)r104(此处,r103及r104相互独立地为氢、或具有1个~5个碳原子的烷基。其中,当r103为氢时,r104不为氢)。根据一例,作为羰基化合物,可使用所述通式(3)中r103为氢或具有1个~5个碳原子的烷基且r104为氢的羰基化合物。根据另一例,羰基化合物可使用所述通式(3)中r103为甲基且r104为具有1个~5个碳原子的烷基的羰基化合物。具体而言,作为羰基化合物,可使用以下羰基化合物:在所述通式(1)中,r103为甲基且r104为氢的羰基化合物(即,乙醛);r103为乙基且r104为氢的羰基化合物(即,丙醛);r103为丙基且r104为氢的羰基化合物(即,丁醛),具体而言,r103为正丙基且r104为氢的羰基化合物(即,正丁醛)、或r103为异丙基且r104为氢的羰基化合物(即,异丁醛);或者r103为戊基且r104为氢的羰基化合物(即,戊醛),具体而言,r103为正戊基且r104为氢的羰基化合物(即,正戊醛)。另外,作为羰基化合物,可使用所述通式(3)中r103及r104均为甲基的酮(即,丙酮)。羰基化合物可使用一种,也可混合使用两种以上。生产用培养液中羰基化合物的浓度优选在0.001(w/v)%~10(w/v)%的范围内,更优选在0.01(w/v)%~1(w/v)%的范围内。另外,可与伴随1,3-二醇的生产而羰基化合物减少的情况对应地进行羰基化合物的追加添加。此外,当在生产用培养液中使用一种羰基化合物时,可容易地进行后述“(2.2.4)1,3-二醇的回收”中叙述的分离纯化。作为其他必要成分,可使用与“(1.2.2)生产用培养液”一栏中所记载的其他必要成分相同的成分。作为具体的生产用培养液,可使用包含葡萄糖、甲醛、磷酸二氢钾、磷酸氢二钾、硫酸镁、硫酸铁(ii)及硫酸锰(ii)且具有6.0的ph的培养基。另外,作为生产用培养液,也可使用在与增殖培养中所使用的增殖用培养液相同组成的基础培养液中添加丙酮酸供给化合物与羰基化合物而获得的培养液。此外,在所述基础培养液中存在充分量的丙酮酸供给化合物的情况下,也可不添加丙酮酸供给化合物。(2.2.3)生产培养的条件生产培养的培养温度只要是适于生产1,3-二醇的温度,则可为任意温度。生产培养的培养温度优选为约20℃~50℃,更优选为约25℃~47℃。若为所述温度范围,则可效率良好地制造1,3-二醇。生产用培养液的ph只要是适于生产1,3-二醇的ph,则可为任意ph。生产用培养液的ph优选维持于约6~8的范围内。生产用培养液的ph调整可使用无机酸或有机酸;氢氧化钾水溶液等碱溶液;尿素;碳酸钙;氨;包含4-吗啉丙磺酸等的ph缓冲液等进行。在生产培养过程中也可根据需要适宜调整生产用培养液的ph。生产培养的培养时间只要是对于转化体生产1,3-二醇而言充分的时间,则可为任意时间。生产培养的培养时间优选为约3小时~7天,更优选为约1天~3天。生产培养可在好氧条件下进行,也可在厌氧条件或微好氧条件下进行。其原因在于:所述转化体具有在好氧条件下及厌氧条件或微好氧条件下均起作用的生产1,3-二醇的途径。生产1,3-二醇的途径在后述的“(2.3)作用及效果”一栏中叙述。<厌氧条件或微好氧条件>生产培养优选在厌氧条件或微好氧条件下进行。若在厌氧条件下或微好氧条件下培养转化体,则转化体实质上不会增殖,可更有效率地生产1,3-二醇。“厌氧条件或微好氧条件”可设为与“(1.2.3)生产培养的条件”一栏中所记载的“厌氧条件或微好氧条件”相同的条件。<高密度条件>生产培养优选在使转化体高密度地悬浮于生产用培养液中的状态下进行。若在此种状态下培养转化体,则可更有效率地生产1,3-二醇。“使转化体高密度地悬浮于生产用培养液中的状态”可设为与“(1.2.3)生产培养的条件”一栏中所记载的“使转化体高密度地悬浮于生产用培养液中的状态”相同的状态。生产培养更优选在厌氧条件或微好氧条件下,在使转化体高密度地悬浮于生产用培养液中的状态下进行。(2.2.4)1,3-二醇的回收如上所述,当在生产用培养液中对包含第一基因、第二基因及第三基因的转化体进行培养时,在生产用培养液中会生产出1,3-二醇。具体而言,当在生产用培养液中使用由下述通式(3):下述通式(3):r103c(o)r104(此处,r103及r104相互独立地为氢、或具有1个~5个碳原子的烷基。其中,r103及r104不均为氢)表示的羰基化合物时,可生产由下述通式(4)表示的1,3-二醇:r103c(r104)(oh)ch2ch2oh(所述通式(4)中的r103及r104分别为与所述通式(3)中的r103及r104相同的基)。更具体而言,在使用所述通式(3)中r103为甲基且r104为氢的羰基化合物的情况下,可生产所述通式(4)中r103为甲基且r104为氢的1,3-二醇(即,1,3-丁二醇)。在使用所述通式(3)中r103为乙基且r104为氢的羰基化合物的情况下,可生产所述通式(4)中r103为乙基且r104为氢的1,3-二醇(即,1,3-戊二醇)。在使用所述通式(3)中r103为丙基且r104为氢的羰基化合物的情况下,可生产所述通式(4)中r103为丙基且r104为氢的1,3-二醇(即,1,3-己二醇)。具体而言,在使用所述通式(3)中r103为正丙基且r104为氢的羰基化合物的情况下,可生产所述通式(4)中r103为正丙基且r104为氢的1,3-二醇(即,1,3-正己二醇)。另外,具体而言,在使用所述通式(3)中r103为异丙基且r103为氢的羰基化合物的情况下,可生产所述通式(4)中r103为异丙基且r104为氢的1,3-二醇(即,4-甲基-1,3-戊二醇)。在使用所述通式(3)中r103为戊基且r104为氢的羰基化合物的情况下,可生产所述通式(4)中r103为戊基且r104为氢的1,3-二醇(即,1,3-庚二醇)。具体而言,在使用所述通式(3)中r103为正戊基且r104为氢的羰基化合物的情况下,可生产所述通式(4)中r103为正戊基且r104为氢的1,3-二醇(即,1,3-正庚二醇)。在使用所述通式(3)中r103及r104均为甲基的羰基化合物的情况下,可生产所述通式(4)中r103及r104均为甲基的1,3-二醇(即,3-甲基-1,3-丁二醇)。可通过回收生产用培养液来回收所述1,3-二醇,但也可进一步通过公知的方法自生产用培养液中分离纯化1,3-二醇。作为此种公知的方法,可列举蒸馏法、浓缩法、离子交换树脂法、活性炭吸附洗脱法、溶媒萃取法、晶析法等。此外,还可自生产用培养液中回收通过第一基因所编码的酶催化的羟醛反应而产生的α-酮酸等物质。另外,在使用多种羰基化合物的情况下,培养液中会生产出多种1,3-二醇。多种1,3-二醇可通过蒸馏或色谱相互分离。(2.3)作用及效果将1,3-二醇生产微生物生产1,3-二醇的工艺示意性地示于图2。在图2所示的工艺中,以丙酮酸供给化合物为葡萄糖、羰基化合物为乙醛、1,3-二醇为1,3-丁二醇的情况为例进行说明。如图2所示,首先,1,3-二醇生产微生物6纳入葡萄糖2及乙醛7。接着,葡萄糖2通过糖酵解体系而转变为丙酮酸4。接着,丙酮酸4与乙醛7通过第一基因所编码的“催化丙酮酸与醛的羟醛反应的酶”而转变为4-羟基-2-氧代戊酸8。接着,4-羟基-2-氧代戊酸8通过第二基因所编码的“催化α-酮酸的脱羧反应的酶”而转变为3-羟基丁醛9。接着,3-羟基丁醛9通过第三基因所编码的“催化醛的还原反应的酶”而转变为1,3-丁二醇10。以如上方式生产1,3-丁二醇。或者,作为另一实施方式,在“(2.)1,3-二醇的制造方法”一栏中所说明的1,3-二醇的制造方法中,仅在生产1,3-丁二醇的情况下,生产用培养液也可不包含乙醛。即,所述实施方式的1,3-丁二醇的制造方法包括在丙酮酸供给化合物的存在下对1,3-二醇生产微生物进行培养以生产1,3-丁二醇的工序。所述实施方式除了在生产用培养液中不添加乙醛以外,可依照与所述“1,3-二醇的制造方法”同样的流程来实施。关于即便生产用培养液不包含乙醛也可生产1,3-丁二醇的理由,本发明人认为如下。首先,1,3-二醇生产微生物将生产用培养液中的丙酮酸供给化合物纳入生物体内。接着,在丙酮酸供给化合物为丙酮酸的情况下,通过被第二基因编码的酶,丙酮酸的一部分转变为乙醛。在丙酮酸供给化合物为糖类的情况下,糖类转变为丙酮酸,然后通过被第二基因编码的酶,丙酮酸的一部分转变为乙醛。接着,乙醛与丙酮酸通过被第一基因编码的酶而转变为4-羟基-2-氧代戊酸。其次,4-羟基-2-氧代戊酸通过被第二基因编码的酶而转变为3-羟基丁醛。其次,3-羟基丁醛转变为1,3-丁二醇。如此,1,3-二醇生产微生物可在生物体内生产乙醛。因此,即便生产用培养液不包含乙醛也可生产1,3-丁二醇。此外,1,3-二醇生产微生物所生产的乙醛也可自1,3-二醇生产微生物分泌到培养液中。(3.)2,4-二羟基羧酸的制造方法2,4-二羟基羧酸的制造方法包括:在丙酮酸供给化合物以及羰基化合物的存在下对微生物进行培养以生产2,4-二羟基羧酸的工序,其中,所述微生物包含以下基因:(a)第一基因,对催化丙酮酸与羰基化合物的羟醛反应的酶进行编码,及(d)第四基因,对催化α-酮酸的还原反应的酶进行编码,所述丙酮酸供给化合物选自丙酮酸及糖类中,所述羰基化合物由下述通式(1)表示:r101c(o)r102(此处,r101及r102相互独立地为氢、或具有1个~5个碳原子的烷基),所述2,4-二羟基羧酸由下述通式(5)表示:r101c(r102)(oh)ch2ch(oh)cooh(所述通式(5)中的r101及r102分别为与所述通式(1)中的r101及r102相同的基)。在以下说明中,将包含第一基因及第四基因的所述微生物也称为“2,4-二羟基羧酸生产微生物”。2,4-二羟基羧酸生产微生物可为原本便具有第一基因及第四基因的微生物,也可为通过利用第一基因及第四基因对宿主进行转化而获得的微生物。以下,以2,4-二羟基羧酸生产微生物为转化体的情况为例进行说明。(3.1)转化体(3.1.1)宿主作为宿主,可使用与“(1.1.1)宿主”一栏中所记载的宿主相同的宿主。接着,对导入宿主中的第一基因及第四基因进行说明。(3.1.2)第一基因作为第一基因,可使用与“(1.1.2)第一基因”一栏中所记载的第一基因相同的基因。(3.1.3)第四基因第四基因对“催化α-酮酸的还原反应的酶”进行编码。所谓“催化α-酮酸的还原反应的酶”,是指依照后述的测定方法,且作为酶反应液而使用包含纯化蛋白质及α-酮酸(初始基质浓度1mm)的酶反应液来进行测定时,具有10mu/mgprotein以上的活性的酶。第四基因对催化α-酮酸的还原反应的酶进行编码,所述α-酮酸例如是通过第一基因所编码的蛋白质催化的羟醛反应而获得。“催化α-酮酸的还原反应的酶”中的α-酮酸例如为“(1.)α-酮酸的制造方法”一栏中所记载的由通式(2)表示的α-酮酸。“催化α-酮酸的还原反应的酶”例如为脱氢酶。第四基因例如可为对乳酸脱氢酶(lactatedehydrogenase,ec编号1.1.1.27)进行编码的基因。作为乳酸脱氢酶,例如可列举ldha蛋白质。ldha蛋白质优选为来源于乳酸乳球菌(lactococcuslactis)的蛋白质。此外,所谓“来源于乳酸乳球菌的蛋白质”,可为自乳酸乳球菌中分离出的蛋白质,只要维持了所述蛋白质的活性,则也可为分离出的蛋白质的突变体。ldha蛋白质更优选为来源于乳酸乳球菌nite生物资源中心(nitebiologicalresourcecenter,nbrc)100676株的蛋白质。进而优选为来源于乳酸乳球菌nbrc100676株的ldha蛋白质,且为自n末端起的第85个谷氨酰胺(glutamine)残基经胱氨酸(cystine)残基取代的蛋白质。优选第四基因选自由以下所组成的群组中:(4-1)对作为包含序列号28中记载的氨基酸序列的蛋白质(即,来源于乳酸乳球菌nbrc100676株的ldha蛋白质,且为自n末端起的第85个谷氨酰胺残基经胱氨酸残基取代的蛋白质)的、且催化α-酮酸的还原反应的蛋白质进行编码的基因,及(4-2)对包含序列号28中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的还原反应的活性的蛋白质进行编码的基因。“对包含序列号28中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的还原反应的活性的蛋白质进行编码的基因”可为“对包含相对于序列号28中记载的氨基酸序列而具有80%以上、优选为90%以上、更优选为95%以上、进而优选为97%以上、进而优选为98%以上、进而优选为99%以上的同一性的氨基酸序列、且具有催化α-酮酸的还原反应的活性的蛋白质进行编码的基因”。“对包含序列号28中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的还原反应的活性的蛋白质进行编码的基因”优选对自n末端起的第85个残基中维持有胱氨酸残基的蛋白质进行了编码。第四基因更优选为包含序列号27中记载的碱基序列的来源于乳酸乳球菌nbrc100676株的ldha基因。此外,序列号27中记载的碱基序列对自n末端起的第85个残基中具有胱氨酸残基的蛋白质进行了编码。序列号27中记载的碱基序列与序列号28中记载的氨基酸序列如下。[表27][表28]催化α-酮酸的还原反应的活性例如可通过以下方式来算出:在含有0.25mmnadh、50mm氯化钾、5mm氯化镁、5mm氯化镁、5mmd-果糖1,6-双磷酸的60mmhepes-naoh缓冲液(ph7.0)中在30℃下进行所述酶反应,测定作为原料的α-酮酸被还原时所消耗的nadh的初始消耗速度。nadh的初始消耗速度例如可通过测定来源于酶反应液中的nadh的、340nm下的吸光度的减少速度来算出。此处,将在30℃、1分钟内可使1μmol的α-酮酸还原的活性设为1个单位。“对包含序列号28中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的还原反应的活性的蛋白质进行编码的基因(ldha基因突变体)”可通过与选择hpai基因突变体的所述方法相同的方法而自其他生物种的dna文库中选择。(3.1.4)用于转化的重组载体的构建第一基因及第四基因可组入到适当的质粒载体中以进行转化。作为质粒载体,可使用与“(1.1.3)用于转化的重组载体的构建”一栏中所记载的质粒载体相同的质粒载体。第一基因及第四基因分别可组入到各不相同的质粒载体中,或者也可组入到同一质粒载体中。可使用所获得的重组载体来制作转化体。(3.1.5)转化转化方法可无限制地使用公知的方法。作为此种公知的方法,可使用与“(1.1.4)转化”一栏中所记载的方法相同的方法。此外,在如上所述使用重组载体制作转化体的情况下,第一基因及第四基因分别可组入到宿主的染色体中,或者也可以重组载体的形态存在于宿主的细胞质内。(3.1.6)宿主染色体基因的破坏或缺失宿主不仅可为野生株,也可为其突变株或人工的基因重组体。在宿主为棒状细菌的情况下,宿主可使用与“(1.1.5)宿主染色体基因的破坏或缺失”一栏中所记载的基因破坏株或基因缺失株相同的基因破坏株或基因缺失株。另外,作为制作基因破坏株或基因缺失株的方法,可使用与“(1.1.5)宿主染色体基因的破坏或缺失”一栏中所记载的方法相同的方法。通过将此种基因破坏株或基因缺失株用作宿主,可提高2,4-二羟基羧酸的生产性、或抑制副生成物的生成。(3.1.7)2,4-二羟基羧酸生产微生物的具体例具体而言,作为2,4-二羟基羧酸生产微生物,可使用包含第一基因及第四基因的棒状细菌,所述第一基因选自由以下所组成的群组中:(1-1)对包含序列号2中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-2)对包含序列号2中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-3)对包含序列号4中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-4)对包含序列号4中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-5)对包含序列号6中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,及(1-6)对包含序列号6中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因;所述第四基因选自由以下所组成的群组中:(4-1)对包含序列号28中记载的氨基酸序列、且催化α-酮酸的还原反应的蛋白质进行编码的基因;及(4-2)对包含序列号28中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的还原反应的活性的蛋白质进行编码的基因。(3.2)培养工序可在丙酮酸供给化合物及羰基化合物的存在下对2,4-二羟基羧酸生产微生物(例如所述转化体)进行培养,以生产2,4-二羟基羧酸。“在丙酮酸供给化合物及羰基化合物的存在下进行培养”可通过在包含丙酮酸供给化合物及羰基化合物的培养液中进行培养来进行。“在丙酮酸供给化合物及羰基化合物的存在下进行培养”优选可通过在添加了丙酮酸供给化合物及羰基化合物的培养液中进行培养来进行。在丙酮酸供给化合物及羰基化合物的存在下进行培养之前,优选进行“(1.2)培养工序”一栏中所记载的增殖培养。当在生产培养之前进行增殖培养时,增殖培养与其后的生产培养例如可如“(1.2)培养工序”一栏所记载般进行。(3.2.1)增殖用培养液作为增殖用培养液,可使用与“(1.2.1)增殖用培养液”一栏中所记载的增殖用培养液相同的培养液。(3.2.2)生产用培养液作为生产用培养液,可使用与“(1.2.2)生产用培养液”一栏中所记载的生产用培养液相同的培养液。作为具体的生产用培养液,可使用包含葡萄糖、甲醛、磷酸二氢钾、磷酸氢二钾、硫酸镁、硫酸铁(ii)及硫酸锰(ii)且具有7.0的ph的培养基。此外,当在生产用培养液中使用一种羰基化合物时,可容易地进行后述“(3.2.4)2,4-二羟基羧酸的回收”一栏中记载的分离纯化。(3.2.3)生产培养的条件生产培养的培养温度只要是适于生产2,4-二羟基羧酸的温度,则可为任意温度。生产培养的培养温度优选为约20℃~50℃,更优选为约25℃~47℃。若为所述温度范围,则可效率良好地制造2,4-二羟基羧酸。生产用培养液的ph只要是适于生产2,4-二羟基羧酸的ph,则可为任意ph。生产用培养液的ph优选维持于约6~8的范围内。生产用培养液的ph调整可使用无机酸或有机酸;氢氧化钾水溶液等碱溶液;尿素;碳酸钙;氨;包含4-吗啉丙磺酸等的ph缓冲液等进行。在生产培养过程中也可根据需要适宜调整生产用培养液的ph。生产培养的培养时间只要是对于转化体生产2,4-二羟基羧酸而言充分的时间,则可为任意时间。生产培养的培养时间优选为约3小时~7天,更优选为约1天~3天。生产培养可在好氧条件下进行,也可在厌氧条件或微好氧条件下进行。其原因在于:所述转化体具有在好氧条件下及厌氧条件或微好氧条件下均起作用的生产2,4-二羟基羧酸的途径。生产2,4-二羟基羧酸的途径在后述的“(3.3)作用及效果”一栏中叙述。<厌氧条件或微好氧条件>生产培养优选在厌氧条件或微好氧条件下进行。若在厌氧条件下或微好氧条件下培养转化体,则转化体实质上不会增殖,可更有效率地生产2,4-二羟基羧酸。“厌氧条件或微好氧条件”可设为与“(1.2.3)生产培养的条件”一栏中所记载的“厌氧条件或微好氧条件”相同的条件。<高密度条件>生产培养优选在使转化体高密度地悬浮于生产用培养液中的状态下进行。若在此种状态下培养转化体,则可更有效率地生产2,4-二羟基羧酸。“使转化体高密度地悬浮于生产用培养液中的状态”可设为与“(1.2.3)生产培养的条件”一栏中所记载的“使转化体高密度地悬浮于生产用培养液中的状态”相同的状态。生产培养更优选在厌氧条件或微好氧条件下,在使转化体高密度地悬浮于生产用培养液中的状态下进行。(3.2.4)2,4-二羟基羧酸的回收如上所述,当在生产用培养液中对包含第一基因及第四基因的转化体进行培养时,在生产用培养液中会生产出2,4-二羟基羧酸。具体而言,当在生产用培养液中使用由下述通式(1):r101c(o)r102(此处,r101及r102相互独立地为氢、或具有1个~5个碳原子的烷基)表示的羰基化合物时,可生产由下述通式(5)表示的2,4-二羟基羧酸:r101c(r102)(oh)ch2ch(oh)cooh(所述通式(5)中的r101及r102分别为与所述通式(1)中的r101及r102相同的基)。更具体而言,在使用所述通式(1)中r101为氢且r102为氢的羰基化合物的情况下,可生产所述通式(5)中r101为氢且r102为氢的2,4-二羟基羧酸(即,2,4-二羟基丁酸)。在使用所述通式(1)中r101为甲基且r102为氢的羰基化合物的情况下,可生产所述通式(5)中r101为甲基且r102为氢的2,4-二羟基羧酸(即,2,4-二羟基戊酸)。在使用所述通式(1)中r101为乙基且r102为氢的羰基化合物的情况下,可生产所述通式(5)中r101为乙基且r102为氢的2,4-二羟基羧酸(即,2,4-二羟基己酸)。在使用所述通式(1)中r101为丙基且r102为氢的羰基化合物的情况下,可生产所述通式(5)中r101为丙基且r102为氢的2,4-二羟基羧酸(即,2,4-二羟基庚酸)。具体而言,在使用所述通式(1)中r101为正丙基且r102为氢的羰基化合物的情况下,可生产所述通式(5)中r101为正丙基且r102为氢的2,4-二羟基羧酸(即,2,4-二羟基正庚酸)。另外,具体而言,在使用所述通式(1)中r101为异丙基且r102为氢的羰基化合物的情况下,可生产所述通式(5)中r101为异丙基且r102为氢的2,4-二羟基羧酸(即,2,4-二羟基异庚酸)。在使用所述通式(1)中r101为戊基且r102为氢的羰基化合物的情况下,可生产所述通式(5)中r101为戊基且r102为氢的2,4-二羟基羧酸(即,2,4-二羟基辛酸)。具体而言,在使用所述通式(1)中r101为正戊基且r102为氢的羰基化合物的情况下,可生产所述通式(5)中r101为正戊基且r102为氢的2,4-二羟基羧酸(即,2,4-二羟基正辛酸)。更具体而言,在使用所述通式(1)中r101及r102均为甲基的羰基化合物的情况下,可生产所述通式(5)中r101及r102均为甲基的2,4-二羟基羧酸(即,4-甲基-2,4-二羟基戊酸)。可通过回收生产用培养液来回收所述2,4-二羟基羧酸,但也可进一步通过公知的方法自生产用培养液中分离纯化2,4-二羟基羧酸。作为此种公知的方法,可列举晶析法、色谱法、离子交换树脂法、活性炭吸附洗脱法、溶媒萃取法等。此外,还可自生产用培养液中回收通过第一基因所编码的酶催化的羟醛反应而产生的α-酮酸等物质。另外,在使用多种羰基化合物的情况下,培养液中会生产出多种2,4-二羟基羧酸。多种2,4-二羟基羧酸可通过晶析或色谱相互分离。(3.3)作用及效果将2,4-二羟基羧酸生产微生物生产2,4-二羟基羧酸的工艺示意性地示于图3。在图3所示的工艺中,以丙酮酸供给化合物为葡萄糖、羰基化合物为甲醛、2,4-二羟基羧酸为2,4-二羟基丁酸的情况为例进行说明。如图3所示,首先,2,4-二羟基羧酸生产微生物11纳入葡萄糖2及甲醛3。接着,葡萄糖2通过糖酵解体系而转变为丙酮酸4。接着,丙酮酸4与甲醛3通过第一基因所编码的“催化丙酮酸与醛的羟醛反应的酶”而转变为4-羟基-2-氧代丁酸5。接着,4-羟基-2-氧代丁酸5通过第四基因所编码的“催化α-酮酸的还原反应的酶”而转变为2,4-二羟基丁酸12。以如上方式生产2,4-二羟基丁酸。(4.)2-氨基-4-羟基羧酸的制造方法(生物学方法)2-氨基-4-羟基羧酸的制造方法包括:在丙酮酸供给化合物以及羰基化合物的存在下对微生物进行培养以生产2-氨基-4-羟基羧酸的工序,其中,所述微生物包含以下基因:(a)第一基因,对催化丙酮酸与羰基化合物的羟醛反应的酶进行编码,及(e)第五基因,对催化α-酮酸的还原氨基化反应的酶进行编码,所述丙酮酸供给化合物选自丙酮酸及糖类中,所述羰基化合物由下述通式(1)表示:r101c(o)r102(此处,r101及r102相互独立地为氢、或具有1个~5个碳原子的烷基),所述2-氨基-4-羟基羧酸由下述通式(6)表示:r101c(r102)(oh)ch2ch(nh2)cooh(所述通式(6)中的r101及r102分别为与所述通式(1)中的r101及r102相同的基)。在以下说明中,将包含第一基因及第五基因的所述微生物也称为“2-氨基-4-羟基羧酸生产微生物”。2-氨基-4-羟基羧酸生产微生物可为原本便具有第一基因及第五基因的微生物,也可为通过利用第一基因及第五基因对宿主进行转化而获得的微生物。以下,以2-氨基-4-羟基羧酸生产微生物为转化体的情况为例进行说明。(4.1)转化体(4.1.1)宿主作为宿主,可使用与“(1.1.1)宿主”一栏中所记载的宿主相同的宿主。接着,对导入宿主中的第一基因及第五基因进行说明。(4.1.2)第一基因作为第一基因,可使用与“(1.1.2)第一基因”一栏中所记载的第一基因相同的基因。(4.1.3)第五基因第五基因对“催化α-酮酸的还原氨基化反应的酶”进行编码。所谓“催化α-酮酸的还原氨基化反应的酶”,是指依照后述的测定方法,且作为酶反应液而使用包含纯化蛋白质及α-酮酸(初始基质浓度1mm)的酶反应液来进行测定时,具有10mu/mgprotein以上的活性的酶。第五基因对催化α-酮酸的还原氨基化反应的酶进行编码,所述α-酮酸例如是通过第一基因所编码的蛋白质催化的羟醛反应而获得。“催化α-酮酸的还原氨基化反应的酶”中的α-酮酸例如为“(1.)α-酮酸的制造方法”一栏中所记载的由通式(2)表示的α-酮酸。“催化α-酮酸的还原氨基化反应的酶”例如为谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶[glutamate/phenylalanine/leucine/valinedehydrogenase,(ipr006095)]。在所述
技术领域:
中,“谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶”是作为包含谷氨酸脱氢酶、苯丙氨酸脱氢酶、亮氨酸脱氢酶及缬氨酸脱氢酶的脱氢酶家族(dehydrogenasefamily)的含义的用语来使用。根据一例,“谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶”为选自由谷氨酸脱氢酶、苯丙氨酸脱氢酶、亮氨酸脱氢酶及缬氨酸脱氢酶所组成的群组中的至少一种脱氢酶。第五基因可为对以下所例示的谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶进行编码的基因。(d1)亮氨酸脱氢酶(leucinedehydrogenase,ec编号1.4.1.9),(d2)苯丙氨酸脱氢酶(phenylalaninedehydrogenase,ec编号1.4.1.20),及(d3)缬氨酸脱氢酶(valinedehydrogenase,ec编号1.4.1.8及ec编号1.4.1.23)。作为(d1)中包含的脱氢酶,例如可列举leudh蛋白质。leudh蛋白质优选来源于球形赖氨酸芽孢杆菌(lysinibacillussphaericus)、蜡样芽孢杆菌(bacilluscereus)或嗜热脂肪地芽孢杆菌(geobacillusstearothermophillus)。作为(d2)中包含的脱氢酶,例如可列举phedh蛋白质。phedh蛋白质优选来源于栗褐芽孢杆菌(bacillusbadius)。作为(d3)中包含的脱氢酶,例如可列举valdh蛋白质。valdh蛋白质优选来源于费氏链霉菌(streptomycesfradiae)。优选第五基因选自由以下所组成的群组中:(5-1)对作为包含序列号30中记载的氨基酸序列的蛋白质(即,来源于球形赖氨酸芽孢杆菌的leudh蛋白质)的、且催化α-酮酸的还原氨基化反应的蛋白质进行编码的基因,(5-2)对包含序列号30中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的还原氨基化反应的活性的蛋白质进行编码的基因,(5-3)对作为包含序列号32中记载的氨基酸序列的蛋白质(即,来源于栗褐芽孢杆菌的phedh蛋白质)的、且催化α-酮酸的还原氨基化反应的蛋白质进行编码的基因,(5-4)对包含序列号32中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的还原氨基化反应的活性的蛋白质进行编码的基因,(5-5)对作为包含序列号34中记载的氨基酸序列的蛋白质(即,来源于费氏链霉菌的valdh蛋白质)的、且催化α-酮酸的还原氨基化反应的蛋白质进行编码的基因,及(5-6)对包含序列号34中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的还原氨基化反应的活性的蛋白质进行编码的基因。“对包含序列号30中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的还原氨基化反应的活性的蛋白质进行编码的基因”可为“对包含相对于序列号30中记载的氨基酸序列而具有80%以上、优选为90%以上、更优选为95%以上、进而优选为97%以上、进而优选为98%以上、进而优选为99%以上的同一性的氨基酸序列、且具有催化α-酮酸的还原氨基化反应的活性的蛋白质进行编码的基因”。“对包含序列号32中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的还原氨基化反应的活性的蛋白质进行编码的基因”可为“对包含相对于序列号32中记载的氨基酸序列而具有80%以上、优选为90%以上、更优选为95%以上、进而优选为97%以上、进而优选为98%以上、进而优选为99%以上的同一性的氨基酸序列、且具有催化α-酮酸的还原氨基化反应的活性的蛋白质进行编码的基因”。“对包含序列号34中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的还原氨基化反应的活性的蛋白质进行编码的基因”可为“对包含相对于序列号34中记载的氨基酸序列而具有80%以上、优选为90%以上、更优选为95%以上、进而优选为97%以上、进而优选为98%以上、进而优选为99%以上的同一性的氨基酸序列、且具有催化α-酮酸的还原氨基化反应的活性的蛋白质进行编码的基因”。更优选第五基因为:包含序列号30中记载的碱基序列的来源于球形赖氨酸芽孢杆菌的leudh基因、包含序列号32中记载的碱基序列的来源于栗褐芽孢杆菌的phedh基因、或包含序列号34中记载的碱基序列的来源于费氏链霉菌的valdh基因。序列号29中记载的碱基序列与序列号30中记载的氨基酸序列如下。[表29][表30]序列号31中记载的碱基序列与序列号32中记载的氨基酸序列如下。[表31][表32]序列号33中记载的碱基序列与序列号34中记载的氨基酸序列如下。[表33][表34]催化α-酮酸的还原氨基化反应的活性例如可通过以下方式来算出:在含有0.2mmnadh、200mm氯化铵的100mmhepes-koh缓冲液(ph7.5)中在25℃下进行所述酶反应,测定作为原料的α-酮酸被还原成α-氨基酸时所消耗的nadh的初始消耗速度。nadh的初始消耗速度例如可通过测定来源于酶反应液中的nadh的、340nm下的吸光度的减少速度来算出。此处,将在25℃、1分钟内可使1μmol的α-酮酸还原成α-氨基酸的活性设为1个单位。“对包含序列号30中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的还原氨基化反应的活性的蛋白质进行编码的基因(leudh基因突变体)”可通过与选择hpai基因突变体的所述方法相同的方法而自其他生物种的dna文库中选择。“对包含序列号32中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的还原氨基化反应的活性的蛋白质进行编码的基因(phedh基因突变体)”可通过与选择hpai基因突变体的所述方法相同的方法而自其他生物种的dna文库中选择。“对包含序列号34中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的还原氨基化反应的活性的蛋白质进行编码的基因(valdh基因突变体)”可通过与选择hpai基因突变体的所述方法相同的方法而自其他生物种的dna文库中选择。(4.1.4)用于转化的重组载体的构建第一基因及第五基因可组入到适当的质粒载体中以进行转化。作为质粒载体,可使用与“(1.1.3)用于转化的重组载体的构建”一栏中所记载的质粒载体相同的质粒载体。第一基因及第五基因分别可组入到各不相同的质粒载体中,或者也可组入到同一质粒载体中。可使用所获得的重组载体来制作转化体。(4.1.5)转化转化方法可无限制地使用公知的方法。作为此种公知的方法,可使用与“(1.1.4)转化”一栏中所记载的方法相同的方法。此外,在如上所述使用重组载体制作转化体的情况下,第一基因及第五基因分别可组入到宿主的染色体中,或者也可以重组载体的形态存在于宿主的细胞质内。(4.1.6)宿主染色体基因的破坏或缺失宿主不仅可为野生株,也可为其突变株或人工的基因重组体。在宿主为棒状细菌的情况下,宿主可使用与“(1.1.5)宿主染色体基因的破坏或缺失”一栏中所记载的基因破坏株或基因缺失株相同的基因破坏株或基因缺失株。另外,作为制作基因破坏株或基因缺失株的方法,可使用与“(1.1.5)宿主染色体基因的破坏或缺失”一栏中所记载的方法相同的方法。通过将此种基因破坏株或基因缺失株用作宿主,可提高2-氨基-4-羟基羧酸的生产性、或抑制副生成物的生成。(4.1.7)2-氨基-4-羟基羧酸生产微生物的具体例具体而言,作为2-氨基-4-羟基羧酸生产微生物,可使用包含第一基因及第五基因的棒状细菌,所述第一基因选自由以下所组成的群组中:(1-1)对包含序列号2中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-2)对包含序列号2中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-3)对包含序列号4中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-4)对包含序列号4中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-5)对包含序列号6中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,及(1-6)对包含序列号6中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因;所述第五基因选自由以下所组成的群组中:(5-1)对包含序列号30中记载的氨基酸序列、且催化α-酮酸的还原氨基化反应的蛋白质进行编码的基因,(5-2)对包含序列号30中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的还原氨基化反应的活性的蛋白质进行编码的基因,(5-3)对包含序列号32中记载的氨基酸序列、且催化α-酮酸的还原氨基化反应的蛋白质进行编码的基因,(5-4)对包含序列号32中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的还原氨基化反应的活性的蛋白质进行编码的基因,(5-5)对包含序列号34中记载的氨基酸序列、且催化α-酮酸的还原氨基化反应的蛋白质进行编码的基因,及(5-6)对包含序列号34中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的还原氨基化反应的活性的蛋白质进行编码的基因。(4.2)培养工序可在丙酮酸供给化合物及羰基化合物的存在下对2-氨基-4-羟基羧酸生产微生物(例如所述转化体)进行培养,以生产2-氨基-4-羟基羧酸。“在丙酮酸供给化合物及羰基化合物的存在下进行培养”可通过在包含丙酮酸供给化合物及羰基化合物的培养液中进行培养来进行。“在丙酮酸供给化合物及羰基化合物的存在下进行培养”优选可通过在添加了丙酮酸供给化合物及羰基化合物的培养液中进行培养来进行。在丙酮酸供给化合物及羰基化合物的存在下进行培养之前,优选进行“(1.2)培养工序”一栏中所记载的增殖培养。当在生产培养之前进行增殖培养时,增殖培养与其后的生产培养例如可如“(1.2)培养工序”一栏所记载般进行。(4.2.1)增殖用培养液作为增殖用培养液,可使用与“(1.2.1)增殖用培养液”一栏中所记载的增殖用培养液相同的培养液。(4.2.2)生产用培养液作为生产用培养液,可使用与“(1.2.2)生产用培养液”一栏中所记载的生产用培养液相同的培养液。作为具体的生产用培养液,可使用包含葡萄糖、甲醛、硫酸铵、磷酸二氢钾、磷酸氢二钾、硫酸镁、硫酸铁(ii)及硫酸锰(ii)且具有7.0的ph的培养基。此外,当在生产用培养液中使用一种羰基化合物时,可容易地进行后述“(4.2.4)2-氨基-4-羟基羧酸的回收”一栏中记载的分离纯化。(4.2.3)生产培养的条件生产培养的培养温度只要是适于生产2-氨基-4-羟基羧酸的温度,则可为任意温度。生产培养的培养温度优选为约20℃~50℃,更优选为约25℃~47℃。若为所述温度范围,则可效率良好地制造2-氨基-4-羟基羧酸。生产用培养液的ph只要是适于生产2-氨基-4-羟基羧酸的ph,则可为任意ph。生产用培养液的ph优选维持于约6~8的范围内。生产用培养液的ph调整可使用无机酸或有机酸;氢氧化钾水溶液等碱溶液;尿素;碳酸钙;氨;包含4-吗啉丙磺酸等的ph缓冲液等进行。在生产培养过程中也可根据需要适宜调整生产用培养液的ph。生产培养的培养时间只要是对于转化体生产2-氨基-4-羟基羧酸而言充分的时间,则可为任意时间。生产培养的培养时间优选为约3小时~7天,更优选为约1天~3天。生产培养可在好氧条件下进行,也可在厌氧条件或微好氧条件下进行。其原因在于:所述转化体具有在好氧条件下及厌氧条件或微好氧条件下均起作用的生产2-氨基-4-羟基羧酸的途径。生产2-氨基-4-羟基羧酸的途径在后述的“(4.3)作用及效果”一栏中叙述。<厌氧条件或微好氧条件>生产培养优选在厌氧条件或微好氧条件下进行。若在厌氧条件下或微好氧条件下培养转化体,则转化体实质上不会增殖,可更有效率地生产2-氨基-4-羟基羧酸。“厌氧条件或微好氧条件”可设为与“(1.2.3)生产培养的条件”一栏中所记载的“厌氧条件或微好氧条件”相同的条件。<高密度条件>生产培养优选在使转化体高密度地悬浮于生产用培养液中的状态下进行。若在此种状态下培养转化体,则可更有效率地生产2-氨基-4-羟基羧酸。“使转化体高密度地悬浮于生产用培养液中的状态”可设为与“(1.2.3)生产培养的条件”一栏中所记载的“使转化体高密度地悬浮于生产用培养液中的状态”相同的状态。生产培养更优选在厌氧条件或微好氧条件下,在使转化体高密度地悬浮于生产用培养液中的状态下进行。(4.2.4)2-氨基-4-羟基羧酸的回收如上所述,当在生产用培养液中对包含第一基因及第五基因的转化体进行培养时,在生产用培养液中会生产出2-氨基-4-羟基羧酸。具体而言,当在生产用培养液中使用由下述通式(1):r101c(o)r102(此处,r101及r102相互独立地为氢、或具有1个~5个碳原子的烷基)表示的羰基化合物时,可生产由下述通式(6)表示的2-氨基-4-羟基羧酸:r101c(r102)(oh)ch2ch(nh2)cooh(所述通式(6)中的r101及r102分别为与所述通式(1)中的r101及r102相同的基)。更具体而言,在使用所述通式(1)中r101为氢且r102为氢的羰基化合物的情况下,可生产所述通式(6)中r101为氢且r102为氢的2-氨基-4-羟基羧酸(即,2-氨基-4-羟基丁酸)。在使用所述通式(1)中r101为甲基且r102为氢的羰基化合物的情况下,可生产所述通式(6)中r101为甲基且r102为氢的2-氨基-4-羟基羧酸(即,2-氨基-4-羟基戊酸)。在使用所述通式(1)中r101为乙基且r102为氢的羰基化合物的情况下,可生产所述通式(6)中r101为乙基且r102为氢的2-氨基-4-羟基羧酸(即,2-氨基-4-羟基己酸)。在使用所述通式(1)中r101为丙基且r102为氢的羰基化合物的情况下,可生产所述通式(6)中r101为丙基且r102为氢的2-氨基-4-羟基羧酸(即,4-羟基-2-氧代庚酸)。具体而言,在使用所述通式(1)中r101为正丙基且r102为氢的羰基化合物的情况下,可生产所述通式(6)中r101为正丙基且r102为氢的2-氨基-4-羟基羧酸(即,2-氨基-4-羟基正庚酸)。另外,具体而言,在使用所述通式(1)中r101为异丙基且r102为氢的羰基化合物的情况下,可生产所述通式(6)中r101为异丙基且r102为氢的2-氨基-4-羟基羧酸(即,2-氨基-4-羟基异庚酸)。在使用所述通式(1)中r101为戊基且r102为氢的羰基化合物的情况下,可生产所述通式(6)中r101为戊基且r102为氢的2-氨基-4-羟基羧酸(即,2-氨基-4-羟基辛酸)。具体而言,在使用所述通式(1)中r101为正戊基且r102为氢的羰基化合物的情况下,可生产所述通式(6)中r101为正戊基且r102为氢的2-氨基-4-羟基羧酸(即,2-氨基-4-羟基正辛酸)。更具体而言,在使用所述通式(1)中r101及r102均为甲基的羰基化合物的情况下,可生产所述通式(6)中r101及r102均为甲基的2-氨基-4-羟基羧酸(即,4-甲基-2-氨基-4-羟基戊酸)。在使用所述通式(1)中r101为氢且r102为氢的羰基化合物的情况下所获得的2-氨基-4-羟基丁酸也称为高丝氨酸(homoserine)。高丝氨酸例如为l-高丝氨酸。在使用所述通式(1)中r101为氢且r102为氢的羰基化合物的情况下,在生产用培养液中不仅会生产出高丝氨酸,也会生产出高丝氨酸衍生物。作为高丝氨酸衍生物,可列举苏氨酸(threonine)及2-氨基丁酸。苏氨酸例如通过2-氨基-4-羟基羧酸生产微生物所保持的、将高丝氨酸转变为苏氨酸的酶(例如高丝氨酸激酶(homoserinekinase)及苏氨酸合酶(threoninesynthase))而由高丝氨酸生产。苏氨酸例如为l-苏氨酸。2-氨基丁酸例如通过2-氨基-4-羟基羧酸生产微生物所保持的、将苏氨酸转变为2-氨基丁酸的酶(例如,苏氨酸脱氨酶(threoninedeaminase)与氨基酸脱氢酶或氨基转移酶的任一者的组合)而由苏氨酸生产。氨基酸脱氢酶例如为谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶。谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶具体而言为亮氨酸脱氢酶。可通过回收生产用培养液来回收所述2-氨基-4-羟基羧酸或高丝氨酸衍生物,但也可进一步通过公知的方法自生产用培养液中分离纯化2-氨基-4-羟基羧酸。作为此种公知的方法,可列举晶析法、色谱法、离子交换树脂法、活性炭吸附洗脱法、溶媒萃取法等。此外,还可自生产用培养液中回收通过第一基因所编码的酶催化的羟醛反应而产生的α-酮酸等物质。如上所述,在使用所述通式(1)中r101为氢且r102为氢的羰基化合物的情况下,在培养液中会生产出高丝氨酸、苏氨酸及2-氨基丁酸。高丝氨酸、苏氨酸及2-氨基丁酸可通过晶析或色谱相互分离。另外,在使用多种羰基化合物的情况下,培养液中会生产出多种2-氨基-4-羟基羧酸。多种2-氨基-4-羟基羧酸可通过晶析或色谱相互分离。(4.3)作用及效果将2-氨基-4-羟基羧酸生产微生物生产2-氨基-4-羟基羧酸的工艺示意性地示于图4。在图4所示的工艺中,以丙酮酸供给化合物为葡萄糖、羰基化合物为甲醛、2-氨基-4-羟基羧酸为高丝氨酸的情况为例进行说明。如图4所示,首先,2-氨基-4-羟基羧酸生产微生物13纳入葡萄糖2及甲醛3。接着,葡萄糖2通过糖酵解体系而转变为丙酮酸4。接着,丙酮酸4与甲醛3通过第一基因所编码的“催化丙酮酸与醛的羟醛反应的酶”而转变为4-羟基-2-氧代丁酸5。接着,4-羟基-2-氧代丁酸5通过第五基因所编码的“催化α-酮酸的还原氨基化反应的酶”而转变为高丝氨酸14。以如上方式生产高丝氨酸。(5.)2-氨基-4-羟基羧酸的制造方法(化学方法)在“(4.)2-氨基-4-羟基羧酸的制造方法”一栏中,对通过使用了微生物的生物学方法制造2-氨基-4-羟基羧酸的方法进行了说明,但所述方法也可不使用微生物而通过化学方法来实施。即,2-氨基-4-羟基羧酸的制造方法包括:使α-酮酸、氮源以及还原剂在谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶的存在下进行反应,以生产2-氨基-4-羟基羧酸的工序,其中,所述α-酮酸由下述通式(2)表示:r101c(r102)(oh)ch2cocooh(此处,r101及r102相互独立地为氢、或具有1个~5个碳原子的烷基),所述2-氨基-4-羟基羧酸由下述通式(6)表示:r101c(r102)(oh)ch2ch(nh2)cooh(所述通式(6)中的r101及r102分别为与所述通式(2)中的r101及r102相同的基)。使α-酮酸、氮源以及还原剂在谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶的存在下进行反应例如可在包含α-酮酸、氮源、还原剂、谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶以及缓冲液的反应液中进行。以下,关于使α-酮酸、氮源以及还原剂在谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶的存在下进行的反应,以在反应液中进行的情况为例进行说明。(5.1)反应液以下对反应液中包含的各成分进行说明。本说明书中记载的反应液中的各成分的浓度是指添加各成分的时间点下的反应液中的最终浓度。(5.1.1)α-酮酸α-酮酸由下述通式(2)表示:r101c(r102)(oh)ch2cocooh(此处,r101及r102相互独立地为氢、或具有1个~5个碳原子的烷基)。根据一例,α-酮酸可使用所述通式(2)中r101为氢、或具有1个~5个碳原子的烷基且r102为氢的α-酮酸。根据另一例,α-酮酸可使用所述通式(2)中r101为甲基且r102为具有1个~5个碳原子的烷基的α-酮酸。具体而言,作为由所述通式(2)表示的α-酮酸,可使用以下α-酮酸:在所述通式(2)中,r101为氢且r102为氢的α-酮酸(即,4-羟基-2-氧代丁酸);r101为甲基且r102为氢的α-酮酸(即,4-羟基-2-氧代戊酸);r101为乙基且r102为氢的α-酮酸(即,4-羟基-2-氧代己酸);r101为丙基且r102为氢的α-酮酸(即,4-羟基-2-氧代庚酸),具体而言,r101为正丙基且r102为氢的α-酮酸(即,4-羟基-2-氧代正庚酸)、或r101为异丙基且r102为氢的α-酮酸(即,4-羟基-2-氧代异庚酸);或者r101为戊基且r102为氢的α-酮酸(即,4-羟基-2-氧代辛酸),具体而言,r101为正戊基且r102为氢的α-酮酸(即,4-羟基-2-氧代正辛酸)。另外,作为由所述通式(2)表示的α-酮酸,也可使用所述通式(2)中r101及r102均为甲基的α-酮酸(即,4-甲基-4-羟基-2-氧代戊酸)。α-酮酸可使用一种,也可混合使用两种以上。在不妨碍2-氨基-4-羟基羧酸的生产的范围内,反应液中α-酮酸的浓度可尽可能地提高。反应液中α-酮酸的浓度优选在0.1mm~1m的范围内,更优选在1mm~300mm的范围内。另外,可与伴随2-氨基-4-羟基羧酸的生产而α-酮酸减少的情况对应地进行α-酮酸的追加添加。此外,当在反应液中使用一种α-酮酸时,可容易地进行后述“(5.3)2-氨基-4-羟基羧酸的回收”一栏中记载的分离纯化。(5.1.2)氮源作为氮源,可使用在谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶所催化的还原氨基化反应中供给氨基的任意化合物。作为氮源,具体而言,可使用在反应液中解离而产生铵离子的铵盐,例如可使用氯化铵、硫酸铵、碳酸铵。在不妨碍2-氨基-4-羟基羧酸的生产的范围内,反应液中氮源的浓度可尽可能地提高。反应液中氮源的浓度优选在0.1mm~1m的范围内,更优选在1mm~300mm的范围内。另外,可与伴随2-氨基-4-羟基羧酸的生产而氮源减少的情况对应地进行氮源的追加添加。(5.1.3)还原剂作为还原剂,可使用谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶可利用的任意电子供体。例如可使用nadh、还原型烟酰胺腺嘌呤二核苷酸磷酸(reducedformofnicotinamideadeninedinucleotidephosphate,nadph)。反应液中还原剂的浓度优选在0.01mm~100mm的范围内,更优选在0.1mm~10mm的范围内。另外,伴随2-氨基-4-羟基羧酸的生产而减少的还原剂可使用适当的化合物与酶进行再生。适当的化合物与酶例如为乙醇与醇脱氢酶。(5.1.4)谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶作为谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶,可使用谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶中包含的任意酶。根据一例,“谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶”是选自由谷氨酸脱氢酶、苯丙氨酸脱氢酶、亮氨酸脱氢酶及缬氨酸脱氢酶所组成的群组中的至少一种脱氢酶。作为谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶,可使用以下所例示的脱氢酶。(d1)亮氨酸脱氢酶(leucinedehydrogenase,ec编号1.4.1.9),(d2)苯丙氨酸脱氢酶(phenylalaninedehydrogenase,ec编号1.4.1.20),及(d3)缬氨酸脱氢酶(valinedehydrogenase,ec编号1.4.1.8及ec编号1.4.1.23)。作为(d1)中包含的脱氢酶,例如可列举leudh蛋白质。leudh蛋白质优选来源于球形赖氨酸芽孢杆菌(lysinibacillussphaericus)、蜡样芽孢杆菌(bacilluscereus)或嗜热脂肪地芽孢杆菌(geobacillusstearothermophillus)。作为(d2)中包含的脱氢酶,例如可列举phedh蛋白质。phedh蛋白质优选来源于栗褐芽孢杆菌(bacillusbadius)。作为(d3)中包含的脱氢酶,例如可列举valdh蛋白质。valdh蛋白质优选来源于费氏链霉菌(streptomycesfradiae)。优选谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶选自由以下所组成的群组中:(5'-1)包含序列号30中记载的氨基酸序列、且催化α-酮酸的还原氨基化反应的蛋白质,(5'-2)包含序列号30中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的还原氨基化反应的活性的蛋白质,(5'-3)包含序列号32中记载的氨基酸序列、且催化α-酮酸的还原氨基化反应的蛋白质,(5'-4)包含序列号32中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的还原氨基化反应的活性的蛋白质,(5'-5)包含序列号34中记载的氨基酸序列、且催化α-酮酸的还原氨基化反应的蛋白质,及(5'-6)包含序列号34中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的还原氨基化反应的活性的蛋白质。“包含序列号30中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的还原氨基化反应的活性的蛋白质”可为“包含相对于序列号30中记载的氨基酸序列而具有80%以上、优选为90%以上、更优选为95%以上、进而优选为97%以上、进而优选为98%以上、进而优选为99%以上的同一性的氨基酸序列、且具有催化α-酮酸的还原氨基化反应的活性的蛋白质”。“包含序列号32中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的还原氨基化反应的活性的蛋白质”可为“包含相对于序列号32中记载的氨基酸序列而具有80%以上、优选为90%以上、更优选为95%以上、进而优选为97%以上、进而优选为98%以上、进而优选为99%以上的同一性的氨基酸序列、且具有催化α-酮酸的还原氨基化反应的活性的蛋白质”。“包含序列号34中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的还原氨基化反应的活性的蛋白质”可为“包含相对于序列号34中记载的氨基酸序列而具有80%以上、优选为90%以上、更优选为95%以上、进而优选为97%以上、进而优选为98%以上、进而优选为99%以上的同一性的氨基酸序列、且具有催化α-酮酸的还原氨基化反应的活性的蛋白质”。催化α-酮酸的还原氨基化反应的活性可通过与“(4.1.3)第五基因”一栏中所记载的测定活性的方法相同的方法进行测定。谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶例如可使用市售的酶,也可使用通过在大肠杆菌或棒状细菌等宿主中表达对谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶进行编码的基因而获得的酶。在后者的情况下,可将表达所述酶的微生物的细胞破碎液用作酶,也可将对所述细胞破碎液进行纯化而获得的含酶液用作酶。在不妨碍2-氨基-4-羟基羧酸生产的范围内,反应液中谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶的浓度可尽可能地提高。反应液中谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶的浓度优选在0.01ug/ml~1mg/ml的范围内,更优选在0.1ug/ml~100ug/ml的范围内。(5.1.5)缓冲液缓冲液例如含有缓冲剂及其他必要成分。作为缓冲剂,可使用任意的缓冲剂。作为缓冲剂,例如可使用hepes或甘氨酸。反应液中缓冲剂的浓度可设为1mm~1m的范围内。进而,根据需要,还可添加无机盐等。(5.2)反应条件反应温度只要是适于生产2-氨基-4-羟基羧酸的温度,则可为任意温度。反应温度优选为约4℃~80℃,更优选为约20℃~60℃。若为所述温度范围,则可效率良好地制造2-氨基-4-羟基羧酸。反应液的ph只要是适于生产2-氨基-4-羟基羧酸的ph,则可为任意ph。反应液的ph优选维持于约5~11的范围内。反应液的ph调整可使用盐酸或氢氧化钾水溶液等进行。在反应过程中也可根据需要适宜调整反应液的ph。反应时间只要是对于生产2-氨基-4-羟基羧酸而言充分的时间,则可为任意时间。反应时间优选为约1分钟~10天的时间,更优选为约1小时~3天。(5.3)2-氨基-4-羟基羧酸的回收如上所述,当使α-酮酸、氮源以及还原剂在谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶的存在下进行反应时,会生产出2-氨基-4-羟基羧酸。具体而言,当使用由下述通式(2):r101c(r102)(oh)ch2cocooh(此处,r101及r102相互独立地为氢、或具有1个~5个碳原子的烷基)表示的α-酮酸时,可生产由下述通式(6)表示的2-氨基-4-羟基羧酸:r101c(r102)(oh)ch2ch(nh2)cooh(所述通式(6)中的r101及r102分别为与所述通式(2)中的r101及r102相同的基)。更具体而言,在使用所述通式(2)中r101为氢且r102为氢的α-酮酸的情况下,可生产所述通式(6)中r101为氢且r102为氢的2-氨基-4-羟基羧酸(即,2-氨基-4-羟基丁酸)。在使用所述通式(2)中r101为甲基且r102为氢的α-酮酸的情况下,可生产所述通式(6)中r101为甲基且r102为氢的2-氨基-4-羟基羧酸(即,2-氨基-4-羟基戊酸)。在使用所述通式(2)中r101为乙基且r102为氢的α-酮酸的情况下,可生产所述通式(6)中r101为乙基且r102为氢的2-氨基-4-羟基羧酸(即,2-氨基-4-羟基己酸)。在使用所述通式(2)中r101为丙基且r102为氢的α-酮酸的情况下,可生产所述通式(6)中r101为丙基且r102为氢的2-氨基-4-羟基羧酸(即,2-氨基-4-羟基庚酸)。具体而言,在使用所述通式(2)中r101为正丙基且r102为氢的α-酮酸的情况下,可生产所述通式(6)中r101为正丙基且r102为氢的2-氨基-4-羟基羧酸(即,2-氨基-4-羟基正庚酸)。另外,具体而言,在使用所述通式(2)中r101为异丙基且r102为氢的α-酮酸的情况下,可生产所述通式(6)中r101为异丙基且r102为氢的2-氨基-4-羟基羧酸(即,2-氨基-4-羟基异庚酸)。在使用所述通式(2)中r101为戊基且r102为氢的α-酮酸的情况下,可生产所述通式(6)中r101为异戊基且r102为氢的2-氨基-4-羟基羧酸(即,2-氨基-4-羟基辛酸)。具体而言,在使用所述通式(2)中r101为正戊基且r102为氢的α-酮酸的情况下,可生产所述通式(6)中r101为正戊基且r102为氢的2-氨基-4-羟基羧酸(即,2-氨基-4-羟基正辛酸)。在使用所述通式(2)中r101及r102均为甲基的α-酮酸的情况下,可生产所述通式(6)中r101及r102均为甲基的2-氨基-4-羟基羧酸(即,4-甲基-2-氨基-4-羟基戊酸)。可通过回收反应液来回收2-氨基-4-羟基羧酸,但也可进一步通过公知的方法自反应液中分离纯化2-氨基-4-羟基羧酸。作为此种公知的方法,可列举晶析法、色谱法、离子交换树脂法、活性炭吸附洗脱法、溶媒萃取法等。另外,在使用多种α-酮酸的情况下,反应液中会生产出多种2-氨基-4-羟基羧酸。多种2-氨基-4-羟基羧酸可通过晶析或色谱方法相互分离。(5.4)利用谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶的氧化脱氨基化反应的α-酮酸的制造方法所述2-氨基-4-羟基羧酸的制造方法利用谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶的还原氨基化反应。一般而言,谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶等氨基酸脱氢酶催化还原氨基化反应及其逆反应、即氧化脱氨基化反应的任一反应,另外,所述脱氢酶的活性强度具有相关关系(例如,生物化学与生物物理学报(biochimicaetbiophysicaacta,biochim.biophys.acta)96,248-262(1965),生物化学杂志(journalofbiologicalchemistry,j.biol.chem.)253,5719-5725(1978),欧洲生物化学杂志(europeanjournalofbiochemistry,eur.j.biochem.)100,29-39(1979))。因此,利用谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氨酶的氧化脱氨基化,可由2-氨基-4-羟基羧酸生产α-酮酸。由此,根据另一实施方式,提供一种利用谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶的氧化脱氨基化反应的α-酮酸的制造方法。即,所述实施方式的α-酮酸的制造方法包括:使2-氨基-4-羟基羧酸以及氧化剂在谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶的存在下进行反应,以生产α-酮酸的工序,其中,所述2-氨基-4-羟基羧酸选自由下述通式(6)表示的2-氨基-4-羟基羧酸中:r101c(r102)(oh)ch2ch(nh2)cooh(此处,r101及r102相互独立地为氢、或具有1个~5个碳原子的烷基),所述α-酮酸由下述通式(2)表示:r101c(r102)(oh)ch2cocooh(所述通式(2)中的r101及r102分别为与所述通式(6)中的r101及r102相同的基)。使2-氨基-4-羟基羧酸在谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶的存在下进行反应例如可在包含2-氨基-4-羟基羧酸、氧化剂、谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶以及缓冲液的反应液中进行。作为由所述通式(6)表示的2-氨基-4-羟基羧酸,可使用“(5.3)2-氨基-4-羟基羧酸的回收”一栏中所记载的由通式(6)表示的2-氨基-4-羟基羧酸。2-氨基-4-羟基羧酸可使用一种,也可混合使用两种以上。此外,当在反应液中使用一种2-氨基-4-羟基羧酸时,可容易地进行后述α-酮酸的分离纯化。作为谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶,可使用“(5.1.4)谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶”一栏中所记载的谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶。作为氧化剂,可使用谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶可利用的任意电子受体。例如可使用氧化型烟酰胺腺嘌呤二核苷酸(nad+)、氧化型烟酰胺腺嘌呤二核苷酸磷酸(nadp+)。反应液中氧化剂的浓度优选在0.01mm~100mm的范围内,更优选在0.1mm~10mm的范围内。另外,伴随α-酮酸的生产而减少的氧化剂可使用适当的化合物与酶进行再生。适当的化合物与酶例如为丙酮酸与乳酸脱氢酶。作为缓冲液,可使用“(5.1.5)缓冲液”一栏中所记载的缓冲液。反应温度只要是适于生产α-酮酸的温度,则可为任意温度。反应温度优选为约4℃~80℃,更优选为约20℃~60℃。若为所述温度范围,则可效率良好地制造α-酮酸。反应液的ph只要是适于生产α-酮酸的ph,则可为任意ph。反应液的ph优选维持于约5~11的范围内。反应液的ph调整可使用盐酸或氢氧化钾水溶液等进行。在反应过程中也可根据需要适宜调整反应液的ph。反应时间只要是对于生产α-酮酸而言充分的时间,则可为任意时间。反应时间优选为约1分钟~10天的时间,更优选为约1小时~3天。如上所述,当使2-氨基-4-羟基羧酸以及氧化剂在谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶的存在下进行反应时,会生产出α-酮酸。具体而言,当使用由下述通式(6):r101c(r102)(oh)ch2ch(nh2)cooh(此处,r101及r102相互独立地为氢、或具有1个~5个碳原子的烷基)表示的2-氨基-4-羟基羧酸时,可生产由下述通式(2)表示的α-酮酸:r101c(r102)(oh)ch2cocooh(所述通式(2)中的r101及r102分别为与所述通式(6)中的r101及r102相同的基)。更具体而言,在使用所述通式(6)中r101为氢且r102为氢的2-氨基-4-羟基羧酸的情况下,可生产所述通式(2)中r101为氢且r102为氢的α-酮酸(即,4-羟基-2-氧代丁酸)。在使用所述通式(6)中r101为甲基且r102为氢的2-氨基-4-羟基羧酸的情况下,可生产所述通式(2)中r101为甲基且r102为氢的α-酮酸(即,4-羟基-2-氧代戊酸)。在使用所述通式(6)中r101为乙基且r102为氢的2-氨基-4-羟基羧酸的情况下,可生产所述通式(2)中r101为乙基且r102为氢的α-酮酸(即,4-羟基-2-氧代己酸)。在使用所述通式(6)中r101为丙基且r102为氢的2-氨基-4-羟基羧酸的情况下,可生产所述通式(2)中r101为丙基且r102为氢的α-酮酸(即,4-羟基-2-氧代庚酸)。具体而言,在使用所述通式(6)中r101为正丙基且r102为氢的2-氨基-4-羟基羧酸的情况下,可生产所述通式(2)中r101为正丙基且r102为氢的α-酮酸(即,4-羟基-2-氧代正庚酸)。另外,具体而言,在使用所述通式(6)中r101为异丙基且r102为氢的2-氨基-4-羟基羧酸的情况下,可生产所述通式(2)中r101为异丙基且r102为氢的α-酮酸(即,4-羟基-2-氧代异庚酸)。在使用所述通式(6)中r101为戊基且r102为氢的2-氨基-4-羟基羧酸的情况下,可生产所述通式(2)中r101为戊基且r102为氢的α-酮酸(即,4-羟基-2-氧代辛酸)。具体而言,在使用所述通式(6)中r101为正戊基且r102为氢的2-氨基-4-羟基羧酸的情况下,可生产所述通式(2)中r101为正戊基且r102为氢的α-酮酸(即,4-羟基-2-氧代正辛酸)。在使用所述通式(6)中r101及r102均为甲基的2-氨基-4-羟基羧酸的情况下,可生产所述通式(2)中r101及r102均为甲基的α-酮酸(即,4-甲基-4-羟基-2-氧代戊酸)。可通过回收反应液来回收所述α-酮酸,但也可进一步通过公知的方法自反应液中分离纯化α-酮酸。作为此种公知的方法,可列举晶析法、色谱法、离子交换树脂法、活性炭吸附洗脱法、溶媒萃取法等。另外,在使用多种2-氨基-4-羟基羧酸的情况下,反应液中会生产出多种α-酮酸。多种α-酮酸可通过晶析或色谱相互分离。(6.)2-氨基-4-甲基硫代羧酸的制造方法2-氨基-4-甲基硫代羧酸的制造方法包括:在丙酮酸供给化合物、甲硫醇、以及羰基化合物的存在下对微生物进行培养以生产2-氨基-4-甲基硫代羧酸的工序,其中,所述微生物包含以下基因:(a)第一基因,对催化丙酮酸与羰基化合物的羟醛反应的酶进行编码,(e)第五基因,对催化α-酮酸的还原氨基化反应的酶进行编码,及(f)第六基因,对催化由甲硫醇所具有的甲巯基取代2-氨基-4-膦酰氧基羧酸所具有的磷酸基的反应的酶进行编码,所述丙酮酸供给化合物选自丙酮酸及糖类中,所述羰基化合物由下述通式(1)表示:r101c(o)r102(此处,r101及r102相互独立地为氢、或具有1个~5个碳原子的烷基),所述2-氨基-4-甲基硫代羧酸由下述通式(7)表示:r101c(r102)(sch3)ch2ch(nh2)cooh(所述通式(7)中的r101及r102分别为与所述通式(1)中的r101及r102相同的基)。在以下说明中,将包含第一基因、第五基因及第六基因的所述微生物也称为“2-氨基-4-甲基硫代羧酸生产微生物”。2-氨基-4-甲基硫代羧酸生产微生物可为原本便具有第一基因、第五基因及第六基因的微生物,也可为通过利用第一基因、第五基因及第六基因对宿主进行转化而获得的微生物。以下,以2-氨基-4-甲基硫代羧酸生产微生物为转化体的情况为例进行说明。(6.1)转化体(6.1.1)宿主作为宿主,可使用与“(1.1.1)宿主”一栏中所记载的宿主相同的宿主。接着,对导入宿主中的第一基因、第五基因及第六基因进行说明。(6.1.2)第一基因作为第一基因,可使用与“(1.1.2)第一基因”一栏中所记载的第一基因相同的基因。(6.1.3)第五基因作为第五基因,可使用与“(4.1.3)第五基因”一栏中所记载的第一基因相同的基因。(6.1.4)第六基因第六基因对“催化由甲硫醇所具有的甲巯基取代2-氨基-4-膦酰氧基羧酸所具有的磷酸基的反应的酶”进行编码。所谓“催化由甲硫醇所具有的甲巯基取代2-氨基-4-膦酰氧基羧酸所具有的磷酸基的反应的酶”,是指依照后述的测定方法,且作为酶反应液而使用包含纯化蛋白质、2-氨基-4-膦酰氧基羧酸(初始基质浓度1mm)及甲硫醇(初始基质浓度5mm)的酶反应液来进行测定时,具有0.1mu/mgprotein以上的活性的酶。第六基因对催化由甲硫醇所具有的甲巯基取代2-氨基-4-膦酰氧基羧酸所具有的磷酸基的反应的酶进行编码,所述2-氨基-4-膦酰氧基羧酸例如是经由第五基因所编码的蛋白质催化的还原氨基化反应而获得。“催化由甲硫醇所具有的甲巯基取代2-氨基-4-膦酰氧基羧酸所具有的磷酸基的反应的酶”例如为转硫(transsulfuration)酶。此外,在第五基因所编码的蛋白质催化的反应与第六基因所编码的蛋白质催化的反应之间存在进一步的反应(参照图5)。具体而言存在以下反应:通过第五基因所编码的蛋白质催化的反应而获得的2-氨基-4-羟基羧酸通过2-氨基-4-甲基硫代羧酸生产微生物所保持的、对2-氨基-4-羟基羧酸进行磷酸化的酶(例如高丝氨酸激酶)而转变为2-氨基-4-膦酰氧基羧酸。2-氨基-4-膦酰氧基羧酸用作第六基因所编码的蛋白质催化的反应的基质。第六基因例如可为对胱硫醚γ-合酶(cystathionineγ-synthase,ec编号2.5.1.48)进行编码的基因。作为胱硫醚γ-合酶,例如可列举cgs1蛋白质。cgs1蛋白质优选来源于拟南芥(阿拉伯芥(arabidopsisthaliana))。cgs1蛋白质更优选为来源于拟南芥的cgs1成熟蛋白质。来源于拟南芥的cgs1成熟蛋白质是来源于拟南芥的野生型cgs1蛋白质中自n末端起的第2~68个氨基酸残基缺失的蛋白质。优选第六基因选自由以下所组成的群组中:(6-1)对作为包含序列号36中记载的氨基酸序列的蛋白质(即,来源于拟南芥的cgs1成熟蛋白质)的、且催化由甲硫醇所具有的甲巯基取代2-氨基-4-膦酰氧基羧酸所具有的磷酸基的反应的蛋白质进行编码的基因,及(6-2)对包含序列号36中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化由甲硫醇所具有的甲巯基取代2-氨基-4-膦酰氧基羧酸所具有的磷酸基的反应的活性的蛋白质进行编码的基因。“对包含序列号36中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化由甲硫醇所具有的甲巯基取代2-氨基-4-膦酰氧基羧酸所具有的磷酸基的反应的活性的蛋白质进行编码的基因”可为“对包含相对于序列号36中记载的氨基酸序列而具有80%以上、优选为90%以上、更优选为95%以上、进而优选为97%以上、进而优选为98%以上、进而优选为99%以上的同一性的氨基酸序列、且具有催化由甲硫醇所具有的甲巯基取代2-氨基-4-膦酰氧基羧酸所具有的磷酸基的反应的活性的蛋白质进行编码的基因”。来源于拟南芥的cgs1蛋白质的uniprotkb登录号为p55217。第六基因更优选为以如下方式合成的基因:使包含序列号35中记载的碱基序列的来源于拟南芥的cgs1基因内的形成成熟蛋白质的部位最适合于棒状细菌中的表达。序列号35中记载的碱基序列与序列号36中记载的氨基酸序列如下。[表35][表36]催化由甲硫醇所具有的甲巯基取代2-氨基-4-膦酰氧基羧酸所具有的磷酸基的反应的活性例如可通过以下方式来算出:在含有1mm二硫苏糖醇(dithiothreitol)的100mmhepes-koh缓冲液(ph7.5)中在25℃下进行所述酶反应,测定伴随反应而游离的无机磷酸根离子的初始生成速度。若有必要,也可加入微量的磷酸吡哆醇。无机磷酸根离子的生成速度例如可根据无机磷酸根离子浓度的时间变化来算出。关于无机磷酸根离子浓度的测定,例如可将酶反应液与20%(w/v)三氯乙酸以1:2的比率混合而使反应停止后,通过孔雀绿(malachitegreen)法来进行。此处,将在25℃、1分钟内形成1μmol的硫醚化合物的活性设为1个单位。“对包含序列号36中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化由甲硫醇所具有的甲巯基取代2-氨基-4-膦酰氧基羧酸所具有的磷酸基的反应的活性的蛋白质进行编码的基因(cgs1基因突变体)”可通过与选择hpai基因突变体的所述方法相同的方法而自其他生物种的dna文库中选择。(6.1.5)用于转化的重组载体的构建第一基因、第五基因及第六基因可组入到适当的质粒载体中以进行转化。作为质粒载体,可使用与“(1.1.3)用于转化的重组载体的构建”一栏中所记载的质粒载体相同的质粒载体。第一基因、第五基因及第六基因分别可组入到各不相同的质粒载体中,或者也可组入到同一质粒载体中。可使用所获得的重组载体来制作转化体。(6.1.6)转化转化方法可无限制地使用公知的方法。作为此种公知的方法,可使用与“(1.1.4)转化”一栏中所记载的方法相同的方法。此外,在如上所述使用重组载体制作转化体的情况下,第一基因、第五基因及第六基因分别可组入到宿主的染色体中,或者也可以重组载体的形态存在于宿主的细胞质内。(6.1.7)宿主染色体基因的破坏或缺失宿主不仅可为野生株,也可为其突变株或人工的基因重组体。在宿主为棒状细菌的情况下,宿主可使用与“(1.1.5)宿主染色体基因的破坏或缺失”一栏中所记载的基因破坏株或基因缺失株相同的基因破坏株或基因缺失株。另外,作为制作基因破坏株或基因缺失株的方法,可使用与“(1.1.5)宿主染色体基因的破坏或缺失”一栏中所记载的方法相同的方法。通过将此种基因破坏株或基因缺失株用作宿主,可提高2-氨基-4-甲基硫代羧酸的生产性、或抑制副生成物的生成。(6.1.8)2-氨基-4-甲基硫代羧酸生产微生物的具体例具体而言,作为2-氨基-4-甲基硫代羧酸生产微生物,可使用包含第一基因、第五基因及第六基因的棒状细菌,所述第一基因选自由以下所组成的群组中:(1-1)对包含序列号2中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-2)对包含序列号2中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-3)对包含序列号4中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-4)对包含序列号4中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-5)对包含序列号6中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,及(1-6)对包含序列号6中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因;所述第五基因选自由以下所组成的群组中:(5-1)对包含序列号30中记载的氨基酸序列、且催化α-酮酸的还原氨基化反应的蛋白质进行编码的基因,(5-2)对包含序列号30中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的还原氨基化反应的活性的蛋白质进行编码的基因,(5-3)对包含序列号32中记载的氨基酸序列、且催化α-酮酸的还原氨基化反应的蛋白质进行编码的基因,(5-4)对包含序列号32中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的还原氨基化反应的活性的蛋白质进行编码的基因,(5-5)对包含序列号34中记载的氨基酸序列、且催化α-酮酸的还原氨基化反应的蛋白质进行编码的基因,及(5-6)对包含序列号34中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的还原氨基化反应的活性的蛋白质进行编码的基因;所述第六基因选自由以下所组成的群组中:(6-1)对包含序列号36中记载的氨基酸序列、且催化由甲硫醇所具有的甲巯基取代2-氨基-4-膦酰氧基羧酸所具有的磷酸基的反应的蛋白质进行编码的基因,及(6-2)对包含序列号36中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化由甲硫醇所具有的甲巯基取代2-氨基-4-膦酰氧基羧酸所具有的磷酸基的反应的活性的蛋白质进行编码的基因。(6.2)培养工序可在丙酮酸供给化合物、羰基化合物以及甲硫醇的存在下对2-氨基-4-甲基硫代羧酸生产微生物(例如所述转化体)进行培养,以生产2-氨基-4-甲基硫代羧酸。“在丙酮酸供给化合物、羰基化合物以及甲硫醇的存在下进行培养”可通过在包含丙酮酸供给化合物、羰基化合物以及甲硫醇的培养液中进行培养来进行。“在丙酮酸供给化合物、羰基化合物以及甲硫醇的存在下进行培养”优选可通过在添加了丙酮酸供给化合物、羰基化合物以及甲硫醇的培养液中进行培养来进行。在丙酮酸供给化合物、羰基化合物以及甲硫醇的存在下进行培养之前,优选进行“(1.2)培养工序”一栏中所记载的增殖培养。当在生产培养之前进行增殖培养时,增殖培养与其后的生产培养例如可以如下方式进行。在增殖培养后,首先,可将包含增殖培养中所使用的培养液(以下称为增殖用培养液)以及悬浮于增殖用培养液中的转化体的容器置于离心分离机中,使转化体沉淀。然后,可自容器中去除增殖用培养液,并将分离出的转化体悬浮于生产培养中使用的培养液(以下称为生产用培养液)中,以进行生产培养。或者,增殖培养与其后的生产培养可通过在增殖培养后向含有转化体的增殖用培养液中添加丙酮酸供给化合物、羰基化合物以及甲硫醇,并将好氧条件变更为厌氧条件或微好氧条件,由此在不进行培养液的更换的条件下进行生产培养。如此,也可连续进行增殖培养与生产培养。(6.2.1)增殖用培养液作为增殖用培养液,可使用与“(1.2.1)增殖用培养液”一栏中所记载的增殖用培养液相同的培养液。(6.2.2)生产用培养液作为生产用培养液,可使用含有丙酮酸供给化合物、羰基化合物、甲硫醇、及其他必要成分的培养液。作为其他必要成分,例如可使用无机盐类、糖类以外的碳源或氮源。作为丙酮酸供给化合物,可使用“(1.2.2)生产用培养液”一栏中所记载的丙酮酸供给化合物。作为羰基化合物,可使用“(1.2.2)生产用培养液”一栏中所记载的羰基化合物。此外,当在生产用培养液中使用一种羰基化合物时,可容易地进行后述“(6.2.4)2-氨基-4-甲基硫代羧酸的回收”一栏中叙述的分离纯化。生产用培养液中甲硫醇的浓度优选在1mm~1m的范围内,更优选在10mm~300mm的范围内。另外,可与随着2-氨基-4-甲巯基羧酸的生产而甲硫醇减少的情况对应地进行甲硫醇的追加添加。作为其他必要成分,可使用与“(1.2.2)生产用培养液”一栏中所记载的其他必要成分相同的成分。作为具体的生产用培养液,可使用包含葡萄糖、甲醛、甲硫醇、硫酸铵、磷酸二氢钾、磷酸氢二钾、硫酸镁、硫酸铁(ii)及硫酸锰(ii)且具有7.0的ph的培养基。另外,作为生产用培养液,也可使用在与增殖培养中所使用的增殖用培养液相同组成的基础培养液中添加丙酮酸供给化合物、羰基化合物以及甲硫醇而获得的培养液。此外,在所述基础培养液中存在充分量的丙酮酸供给化合物的情况下,也可不添加丙酮酸供给化合物。(6.2.3)生产培养的条件生产培养的培养温度只要是适于生产2-氨基-4-甲基硫代羧酸的温度,则可为任意温度。生产培养的培养温度优选为约20℃~50℃,更优选为约25℃~47℃。若为所述温度范围,则可效率良好地制造2-氨基-4-甲基硫代羧酸。生产用培养液的ph只要是适于生产2-氨基-4-甲基硫代羧酸的ph,则可为任意ph。生产用培养液的ph优选维持于约6~8的范围内。生产用培养液的ph调整可使用无机酸或有机酸;氢氧化钾水溶液等碱溶液;尿素;碳酸钙;氨;包含4-吗啉丙磺酸等的ph缓冲液等进行。在生产培养过程中也可根据需要适宜调整生产用培养液的ph。生产培养的培养时间只要是对于转化体生产2-氨基-4-甲基硫代羧酸而言充分的时间,则可为任意时间。生产培养的培养时间优选为约3小时~7天,更优选为约1天~3天。生产培养可在好氧条件下进行,也可在厌氧条件或微好氧条件下进行。其原因在于:所述转化体具有在好氧条件下及厌氧条件或微好氧条件下均起作用的生产2-氨基-4-甲基硫代羧酸的途径。生产2-氨基-4-甲基硫代羧酸的途径在后述的“(6.3)作用及效果”一栏中叙述。<厌氧条件或微好氧条件>生产培养优选在厌氧条件或微好氧条件下进行。若在厌氧条件下或微好氧条件下培养转化体,则转化体实质上不会增殖,可更有效率地生产2-氨基-4-甲基硫代羧酸。“厌氧条件或微好氧条件”可设为与一栏中所记载的“(1.2.3)生产培养的条件”一栏中所记载的“厌氧条件或微好氧条件”相同的条件。<高密度条件>生产培养优选在使转化体高密度地悬浮于生产用培养液中的状态下进行。若在此种状态下培养转化体,则可更有效率地生产2-氨基-4-甲基硫代羧酸。“使转化体高密度地悬浮于生产用培养液中的状态”可设为与“(1.2.3)生产培养的条件”一栏中所记载的“使转化体高密度地悬浮于生产用培养液中的状态”相同的状态。生产培养更优选在厌氧条件或微好氧条件下,在使转化体高密度地悬浮于生产用培养液中的状态下进行。(6.2.4)2-氨基-4-甲基硫代羧酸的回收如上所述,当在生产用培养液中对包含第一基因、第五基因及第六基因的转化体进行培养时,在生产用培养液中会生产出2-氨基-4-甲基硫代羧酸。具体而言,当在生产用培养液中使用由下述通式(1):r101c(o)r102(此处,r101及r102相互独立地为氢、或具有1个~5个碳原子的烷基)表示的羰基化合物时,可生产由下述通式(7)表示的2-氨基-4-甲基硫代羧酸:r101c(r102)(sch3)ch2ch(nh2)cooh(所述通式(7)中的r101及r102分别为与所述通式(1)中的r101及r102相同的基)。更具体而言,在使用所述通式(1)中r101为氢且r102为氢的羰基化合物的情况下,可生产所述通式(7)中r101为氢且r102为氢的2-氨基-4-甲基硫代羧酸(即,2-氨基-4-甲基硫代丁酸)。在使用所述通式(1)中r101为甲基且r102为氢的羰基化合物的情况下,可生产所述通式(7)中r101为甲基且r102为氢的2-氨基-4-甲基硫代羧酸(即,2-氨基-4-甲基硫代戊酸)。在使用所述通式(1)中r101为乙基且r102为氢的羰基化合物的情况下,可生产所述通式(7)中r101为乙基且r102为氢的2-氨基-4-甲基硫代羧酸(即,2-氨基-4-甲基硫代己酸)。在使用所述通式(1)中r101为丙基且r102为氢的羰基化合物的情况下,可生产所述通式(7)中r101为丙基且r102为氢的2-氨基-4-甲基硫代羧酸(即,2-氨基-4-甲基硫代庚酸)。具体而言,在使用所述通式(1)中r101为正丙基且r102为氢的羰基化合物的情况下,可生产所述通式(7)中r101为正丙基且r102为氢的2-氨基-4-甲基硫代羧酸(即,2-氨基-4-甲基硫代正庚酸)。另外,具体而言,在使用所述通式(1)中r101为异丙基且r102为氢的羰基化合物的情况下,可生产所述通式(7)中r101为异丙基且r102为氢的2-氨基-4-甲基硫代羧酸(即,2-氨基-4-甲基硫代异庚酸)。在使用所述通式(1)中r101为戊基且r102为氢的羰基化合物的情况下,可生产所述通式(7)中r101为戊基且r102为氢的2-氨基-4-甲基硫代羧酸(即,2-氨基-4-甲基硫代辛酸)。具体而言,在使用所述通式(1)中r101为正戊基且r102为氢的羰基化合物的情况下,可生产所述通式(7)中r101为正戊基且r102为氢的2-氨基-4-甲基硫代羧酸(即,2-氨基-4-甲基硫代正辛酸)。在使用所述通式(1)中r101及r102均为甲基的羰基化合物的情况下,可生产所述通式(7)中r101及r102均为甲基的2-氨基-4-甲基硫代羧酸(即,4-甲基-2-氨基-4-甲基硫代戊酸)。此外,2-氨基-4-甲基硫代丁酸也称为蛋氨酸(methionine)。蛋氨酸例如为l-蛋氨酸。可通过回收生产用培养液来回收所述2-氨基-4-甲基硫代羧酸,但也可进一步通过公知的方法自生产用培养液中分离纯化2-氨基-4-甲基硫代羧酸。作为此种公知的方法,可列举晶析法、色谱法、离子交换树脂法、活性炭吸附洗脱法、溶媒萃取法等。此外,还可自生产用培养液中回收通过第一基因所编码的酶催化的羟醛反应而产生的α-酮酸等物质。另外,在使用多种羰基化合物的情况下,培养液中会生产出多种2-氨基-4-甲基硫代羧酸。多种2-氨基-4-甲基硫代羧酸可通过晶析或色谱相互分离。(6.3)作用及效果将2-氨基-4-甲基硫代羧酸生产微生物生产2-氨基-4-甲基硫代羧酸的工艺示意性地示于图5。在图5所示的工艺中,以丙酮酸供给化合物为葡萄糖、羰基化合物为甲醛、2-氨基-4-甲基硫代羧酸为蛋氨酸的情况为例进行说明。如图5所示,首先,2-氨基-4-甲基硫代羧酸生产微生物15纳入葡萄糖2、甲醛3及甲硫醇16。接着,葡萄糖2通过糖酵解体系而转变为丙酮酸4。接着,丙酮酸4与甲醛3通过第一基因所编码的“催化丙酮酸与醛的羟醛反应的酶”而转变为4-羟基-2-氧代丁酸5。接着,4-羟基-2-氧代丁酸5通过第五基因所编码的“催化α-酮酸的还原氨基化反应的酶”而转变为高丝氨酸14。接着,高丝氨酸14通过2-氨基-4-甲基硫代羧酸生产微生物原本便具有的高丝氨酸激酶而转变为o-磷酸高丝氨酸17。甲硫醇16与o-磷酸高丝氨酸17通过第六基因所编码的“将o-磷酸高丝氨酸转变为蛋氨酸的酶”而转变为蛋氨酸18。以如上方式生产蛋氨酸。(7.)优选实施方式以下,汇总示出本发明的优选实施方式。[a1]一种α-酮酸的制造方法,包括:在丙酮酸供给化合物以及羰基化合物的存在下对微生物进行培养以生产α-酮酸的工序,其中,所述微生物包含对催化丙酮酸与羰基化合物的羟醛反应的酶进行编码的基因,所述丙酮酸供给化合物选自丙酮酸及糖类中,所述羰基化合物由下述通式(1)表示:r101c(o)r102(此处,r101及r102相互独立地为氢、或具有1个~5个碳原子的烷基),所述α-酮酸由下述通式(2)表示:r101c(r102)(oh)ch2cocooh(所述通式(2)中的r101及r102分别为与所述通式(1)中的r101及r102相同的基)。[a2]根据[a1]所述的方法,其中,所述通式(1)及通式(2)中,r102为氢。[a3]根据[a1]或[a2]所述的方法,其中,所述通式(1)及通式(2)中,r101为氢、甲基、乙基、丙基或戊基,且r102为氢。[a4]根据[a1]至[a3]中任一项所述的方法,其中,所述通式(1)及通式(2)中,r101为氢、甲基、乙基、正丙基、异丙基或正戊基,且r102为氢。[a5]根据[a1]至[a4]中任一项所述的方法,其中,所述培养通过在包含所述丙酮酸供给化合物及羰基化合物的培养液中对所述微生物进行培养来进行。[a6]根据[a5]所述的方法,其中,所述培养液是添加了所述丙酮酸供给化合物及羰基化合物的培养液。[a7]根据[a6]所述的方法,其中,以在所述培养液中成为0.1(w/v)%~40(w/v)%、优选成为1(w/v)%~20(w/v)%的浓度的方式添加所述丙酮酸供给化合物。[a8]根据[a6]或[a7]所述的方法,其中,以在所述培养液中成为0.001(w/v)%~10(w/v)%、优选成为0.01(w/v)%~1(w/v)%的浓度的方式添加羰基化合物。[a9]根据[a1]至[a8]中任一项所述的方法,其中,所述丙酮酸供给化合物为糖类。[a10]根据[a1]至[a9]中任一项所述的方法,其中,所述糖类为:单糖,例如果糖或葡萄糖;二糖,例如蔗糖;多糖,例如包含葡萄糖作为构成单糖的多糖;或者利用糖化酶对植物(例如非可食用农产废弃物或能量作物)进行处理而获得的糖化液。[a11]根据[a1]至[a10]中任一项所述的方法,其中,所述糖类为葡萄糖。[a12]根据[a1]至[a8]中任一项所述的方法,其中,所述丙酮酸供给化合物为丙酮酸。[a13]根据[a1]至[a12]中任一项所述的方法,其中,所述培养在厌氧条件或微好氧条件下进行。[a14]根据[a13]所述的方法,其中,所述培养通过在包含所述丙酮酸供给化合物及羰基化合物的培养液中对所述微生物进行培养来进行。[a15]根据[a14]所述的方法,其中,所述厌氧条件或所述微好氧条件是所述培养液中的溶解氧浓度在0ppm~2ppm的范围内、优选在0ppm~1ppm的范围内、更优选在0ppm~0.5ppm的范围内的条件。[a16]根据[a1]至[a15]中任一项所述的方法,其中,所述培养在使所述微生物高密度地悬浮于培养液中的状态下进行。[a17]根据[a16]所述的方法,其中,所述培养通过在包含所述丙酮酸供给化合物及羰基化合物的培养液中对所述微生物进行培养来进行。[a18]根据[a17]所述的方法,其中,使所述微生物高密度地悬浮于所述培养液中的所述状态是以所述微生物的湿菌体重量%成为1(w/v)%~50(w/v)%的范围内的方式使所述微生物悬浮于所述培养液中的状态,优选是以所述微生物的湿菌体重量%成为3(w/v)%~30(w/v)%的范围内的方式使所述微生物悬浮于所述培养液中的状态。[a19]根据[a1]至[a18]中任一项所述的方法,其中,所述基因对醛缩酶进行编码。[a20]根据[a1]至[a19]中任一项所述的方法,其中,所述基因对i类醛缩酶进行编码。[a21]根据[a1]至[a19]中任一项所述的方法,其中,所述基因对ii类醛缩酶进行编码。[a22]根据[a1]至[a21]中任一项所述的方法,其中,所述基因对选自由以下所组成的群组中的醛缩酶进行编码:(a1)2-脱氢-3-脱氧-磷酸葡萄糖酸醛缩酶(2-dehydro-3-deoxy-phosphogluconatealdolase),(a2)2-脱氢-3-脱氧-6-磷酸葡萄糖酸醛缩酶(2-dehydro-3-deoxy-6-phosphogluconatealdolase),(a3)4-羟基-2-氧代戊二酸醛缩酶(4-hydroxy-2-oxoglutaratealdolase),(a4)(4s)-4-羟基-2-氧代戊二酸醛缩酶((4s)-4-hydroxyl-2-oxoglutaratealdolase),(a5)2-脱氢-3-脱氧-d-戊糖酸醛缩酶(2-dehydro-3-deoxy-d-pentonatealdolase),(a6)2-脱氢-3-脱氧-d-葡萄糖酸醛缩酶(2-dehydro-3-deoxy-d-gluconatealdolase),(a7)3-脱氧-d-甘露-辛酮糖酸醛缩酶(3-deoxy-d-manno-octulosonatealdolase),(a8)4-羟基-2-氧代戊酸醛缩酶(4-hydroxyl-2-oxovaleratealdolase),(a9)4-(2-羧基苯基)-2-氧代丁-3-烯酸醛缩酶(4-(2-carboxyphenyl)-2-oxobut-3-enoatealdolase),(a10)4-羟基-2-氧代庚烷二酸醛缩酶(4-hydroxy-2-oxoheptanedioatealdolase),(a11)2-脱氢-3-脱氧葡萄糖二酸醛缩酶(2-dehydro-3-deoxyglucaratealdolase),(a12)2-酮-3-脱氧-l-鼠李糖酸醛缩酶(2-keto-3-deoxy-l-rhamnonatealdolase),(a13)4-羟基-4-甲基-2-氧代戊二酸醛缩酶(4-hydroxyl-4-methyl-2-oxoglutaratealdolase),及(a14)4-羟基-2-氧代己酸醛缩酶(4-hydroxy-2-oxohexanonatealdolase)。[a23]根据[a1]至[a22]中任一项所述的方法,其中,所述基因对选自由以下所组成的群组中的醛缩酶进行编码:eda蛋白质,优选为来源于大肠杆菌的eda蛋白质;dgoa蛋白质,优选为来源于大肠杆菌的dgoa蛋白质;yjhh蛋白质,优选为来源于大肠杆菌的yjhh蛋白质;yage蛋白质,优选为来源于大肠杆菌的yage蛋白质;nana蛋白质,优选为来源于大肠杆菌的nana蛋白质;mhpe蛋白质,优选为来源于大肠杆菌的mhpe蛋白质;hpai蛋白质,优选为来源于大肠杆菌的hpai蛋白质;bphi蛋白质,优选为来源于食异源化合物伯克霍尔德氏菌的bphi蛋白质;phdj蛋白质,优选为来源于类诺卡氏菌属菌的phdj蛋白质;garl蛋白质,优选为来源于大肠杆菌的garl蛋白质;rhma蛋白质,优选为来源于大肠杆菌的rhma蛋白质;及galc蛋白质,优选为来源于恶臭假单胞菌的galc蛋白质。[a24]根据[a1]至[a23]中任一项所述的方法,其中,所述基因选自由以下所组成的群组中:(1-1)对包含序列号2中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-2)对包含序列号2中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-3)对包含序列号4中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-4)对包含序列号4中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-5)对包含序列号6中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-6)对包含序列号6中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-7)对包含序列号8中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-8)对包含序列号8中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-9)对包含序列号10中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-10)对包含序列号10中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-11)对包含序列号12中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-12)对包含序列号12中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-13)对包含序列号14中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-14)对包含序列号14中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-15)对包含序列号16中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-16)对包含序列号16中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-17)对包含序列号18中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-18)对包含序列号18中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-19)对包含序列号20中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-20)对包含序列号20中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-21)对包含序列号22中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,及(1-22)对包含序列号22中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因。[a25]根据[a1]至[a24]中任一项所述的方法,其中,所述基因选自由以下所组成的群组中:包含序列号1中记载的碱基序列的基因,包含序列号3中记载的碱基序列的基因,包含序列号5中记载的碱基序列的基因,包含序列号7中记载的碱基序列的基因,包含序列号9中记载的碱基序列的基因,包含序列号11中记载的碱基序列的基因,包含序列号13中记载的碱基序列的基因,包含序列号15中记载的碱基序列的基因,包含序列号17中记载的碱基序列的基因,包含序列号19中记载的碱基序列的基因,及包含序列号21中记载的碱基序列的基因。[a26]根据[a1]至[a25]中任一项所述的方法,其中,所述微生物为好氧性细菌,优选为棒状细菌,更优选为棒状杆菌属(corynebacterium)菌,更优选为谷氨酸棒状杆菌(corynebacteriumglutamicum)。[a27]根据[a1]至[a26]中任一项所述的方法,其中,所述微生物是通过所述基因进行了转化的微生物。[a28]根据[a1]至[a27]中任一项所述的方法,其中,所述微生物是选自由以下所组成的群组中的至少一种基因的缺陷株:乳酸(lactate)脱氢酶(lactatedehydrogenase)基因、磷酸烯醇丙酮酸羧化酶(phosphoenolpyrvatecarboxylase)基因、丙酮酸羧化酶(pyruvatecarboxylase)基因、丙酮酸脱氢酶(pyruvatedehydrogenase)基因、谷氨酸-丙酮酸氨基转移酶(glutamate-pyruvateaminotransferase)基因、乙酰乳酸合酶(acetolactatesynthase)基因、n-琥珀酰二氨基庚二酸(n-succinyldiaminopimelateaminotransferase)基因、s-(羟甲基)分枝硫醇脱氢酶(s-(hydroxymethyl)mycothioldehydrogenase)基因、及乙醛脱氢酶(acetaldehydedehydrogenase)基因。[a29]根据[a1]至[a28]中任一项所述的方法,还包括:在所述培养之前,在好氧条件下对所述微生物进行培养。[a30]根据[a1]至[a29]中任一项所述的方法,还包括:对所生产的α-酮酸进行回收。[b1]一种1,3-二醇的制造方法,包括:在丙酮酸供给化合物以及羰基化合物的存在下对微生物进行培养以生产1,3-二醇的工序,其中,所述微生物包含以下基因:(a)第一基因,对催化丙酮酸与羰基化合物的羟醛反应的酶进行编码,(b)第二基因,对催化α-酮酸的脱羧反应的酶进行编码,及(c)第三基因,对催化醛的还原反应的酶进行编码,所述丙酮酸供给化合物选自丙酮酸及糖类中,所述羰基化合物由下述通式(3)表示:r103c(o)r104(此处,r103及r104相互独立地为氢、或具有1个~5个碳原子的烷基。其中,当r103为氢时,r104不为氢),所述1,3-二醇由下述通式(4)表示:r103c(r104)(oh)ch2ch2oh(所述通式(4)中的r103及r104分别为与所述通式(3)中的r103及r104相同的基)。[b2]根据[b1]所述的方法,其中,所述通式(3)及通式(4)中,r104为氢。[b3]根据[b1]或[b2]所述的方法,其中,所述通式(3)及通式(4)中,r103为氢、甲基、乙基、丙基或戊基,且r104为氢。[b4]根据[b1]至[b3]中任一项所述的方法,其中,所述通式(3)及通式(4)中,r103为甲基、乙基、正丙基、异丙基或正戊基,且r104为氢。[b5]根据[b1]至[b4]中任一项所述的方法,其中,所述培养通过在包含所述丙酮酸供给化合物及羰基化合物的培养液中对所述微生物进行培养来进行。[b6]根据[b5]所述的方法,其中,所述培养液是添加了所述丙酮酸供给化合物及羰基化合物的培养液。[b7]根据[b6]所述的方法,其中,以在所述培养液中成为0.1(w/v)%~40(w/v)%、优选成为1(w/v)%~20(w/v)%的浓度的方式添加所述丙酮酸供给化合物。[b8]根据[b6]或[b7]所述的方法,其中,以在所述培养液中成为0.001(w/v)%~10(w/v)%、优选成为0.01(w/v)%~1(w/v)%的浓度的方式添加羰基化合物。[b9]根据[b1]至[b8]中任一项所述的方法,其中,所述丙酮酸供给化合物为糖类。[b10]根据[b1]至[b9]中任一项所述的方法,其中,所述糖类为:单糖,例如果糖或葡萄糖;二糖,例如蔗糖;多糖,例如包含葡萄糖作为构成单糖的多糖;或者利用糖化酶对植物(例如非可食用农产废弃物或能量作物)进行处理而获得的糖化液。[b11]根据[b1]至[b10]中任一项所述的方法,其中,所述糖类为葡萄糖。[b12]根据[b1]至[b8]中任一项所述的方法,其中,所述丙酮酸供给化合物为丙酮酸。[b13]根据[b1]至[b12]中任一项所述的方法,其中,所述培养在厌氧条件或微好氧条件下进行。[b14]根据[b13]所述的方法,其中,所述培养通过在包含所述丙酮酸供给化合物及羰基化合物的培养液中对所述微生物进行培养来进行。[b15]根据[b14]所述的方法,其中,所述厌氧条件或所述微好氧条件是所述培养液中的溶解氧浓度在0ppm~2ppm的范围内、优选在0ppm~1ppm的范围内、更优选在0ppm~0.5ppm的范围内的条件。[b16]根据[b1]至[b15]中任一项所述的方法,其中,所述培养在使所述微生物高密度地悬浮于培养液中的状态下进行。[b17]根据[b16]所述的方法,其中,所述培养通过在包含所述丙酮酸供给化合物及羰基化合物的培养液中对所述微生物进行培养来进行。[b18]根据[b17]所述的方法,其中,使所述微生物高密度地悬浮于所述培养液中的所述状态是以所述微生物的湿菌体重量%成为1(w/v)%~50(w/v)%的范围内的方式使所述微生物悬浮于所述培养液中的状态,优选是以所述微生物的湿菌体重量%成为3(w/v)%~30(w/v)%的范围内的方式使所述微生物悬浮于所述培养液中的状态。[b19]根据[b1]至[b18]中任一项所述的方法,还包括:对所生产的1,3-二醇进行回收。[b20]一种1,3-丁二醇的制造方法,包括:在选自丙酮酸及糖类中的丙酮酸供给化合物的存在下对微生物进行培养以生产1,3-丁二醇的工序,其中,所述微生物包含以下基因:(a)第一基因,对催化丙酮酸与羰基化合物的羟醛反应的酶进行编码,(b)第二基因,对催化α-酮酸的脱羧反应的酶进行编码,及(c)第三基因,对催化醛的还原反应的酶进行编码。[b21]根据[b20]所述的方法,其中,所述培养通过在包含所述丙酮酸供给化合物的培养液中对所述微生物进行培养来进行。[b22]根据[b21]所述的方法,其中,所述培养液是添加了所述丙酮酸供给化合物的培养液。[b23]根据[b22]所述的方法,其中,以在所述培养液中成为0.1(w/v)%~40(w/v)%、优选成为1(w/v)%~20(w/v)%的浓度的方式添加所述丙酮酸供给化合物。[b24]根据[b20]至[b23]中任一项所述的方法,其中,所述丙酮酸供给化合物为糖类。[b25]根据[b20]至[b24]中任一项所述的方法,其中,所述糖类为:单糖,例如果糖或葡萄糖;二糖,例如蔗糖;多糖,例如包含葡萄糖作为构成单糖的多糖;或者利用糖化酶对植物(例如非可食用农产废弃物或能量作物)进行处理而获得的糖化液。[b26]根据[b20]至[b25]中任一项所述的方法,其中,所述糖类为葡萄糖。[b27]根据[b20]至[b26]中任一项所述的方法,其中,所述培养在厌氧条件或微好氧条件下进行。[b28]根据[b27]所述的方法,其中,所述培养通过在包含所述丙酮酸供给化合物的培养液中对所述微生物进行培养来进行。[b29]根据[b28]所述的方法,其中,所述厌氧条件或所述微好氧条件是所述培养液中的溶解氧浓度在0ppm~2ppm的范围内、优选在0ppm~1ppm的范围内、更优选在0ppm~0.5ppm的范围内的条件。[b30]根据[b20]至[b29]中任一项所述的方法,其中,所述培养在使所述微生物高密度地悬浮于培养液中的状态下进行。[b31]根据[b30]所述的方法,其中,所述培养通过在包含所述丙酮酸供给化合物的培养液中对所述微生物进行培养来进行。[b32]根据[b31]所述的方法,其中,使所述微生物高密度地悬浮于所述培养液中的所述状态是以所述微生物的湿菌体重量%成为1(w/v)%~50(w/v)%的范围内的方式使所述微生物悬浮于所述培养液中的状态,优选是以所述微生物的湿菌体重量%成为3(w/v)%~30(w/v)%的范围内的方式使所述微生物悬浮于所述培养液中的状态。[b33]根据[b20]至[b32]中任一项所述的方法,还包括:对所生产的1,3-丁二醇进行回收。[b34]根据[b1]至[b33]中任一项所述的方法,其中,所述第一基因对醛缩酶进行编码。[b35]根据[b1]至[b34]中任一项所述的方法,其中,所述第一基因对i类醛缩酶进行编码。[b36]根据[b1]至[b34]中任一项所述的方法,其中,所述第一基因对ii类醛缩酶进行编码。[b37]根据[b1]至[b36]中任一项所述的方法,其中,所述第一基因对选自由以下所组成的群组中的醛缩酶进行编码:(a1)2-脱氢-3-脱氧-磷酸葡萄糖酸醛缩酶(2-dehydro-3-deoxy-phosphogluconatealdolase),(a2)2-脱氢-3-脱氧-6-磷酸葡萄糖酸醛缩酶(2-dehydro-3-deoxy-6-phosphogluconatealdolase),(a3)4-羟基-2-氧代戊二酸醛缩酶(4-hydroxy-2-oxoglutaratealdolase),(a4)(4s)-4-羟基-2-氧代戊二酸醛缩酶((4s)-4-hydroxyl-2-oxoglutaratealdolase),(a5)2-脱氢-3-脱氧-d-戊糖酸醛缩酶(2-dehydro-3-deoxy-d-pentonatealdolase),(a6)2-脱氢-3-脱氧-d-葡萄糖酸醛缩酶(2-dehydro-3-deoxy-d-gluconatealdolase),(a7)3-脱氧-d-甘露-辛酮糖酸醛缩酶(3-deoxy-d-manno-octulosonatealdolase),(a8)4-羟基-2-氧代戊酸醛缩酶(4-hydroxyl-2-oxovaleratealdolase),(a9)4-(2-羧基苯基)-2-氧代丁-3-烯酸醛缩酶(4-(2-carboxyphenyl)-2-oxobut-3-enoatealdolase),(a10)4-羟基-2-氧代庚烷二酸醛缩酶(4-hydroxy-2-oxoheptanedioatealdolase),(a11)2-脱氢-3-脱氧葡萄糖二酸醛缩酶(2-dehydro-3-deoxyglucaratealdolase),(a12)2-酮-3-脱氧-l-鼠李糖酸醛缩酶(2-keto-3-deoxy-l-rhamnonatealdolase),(a13)4-羟基-4-甲基-2-氧代戊二酸醛缩酶(4-hydroxyl-4-methyl-2-oxoglutaratealdolase),及(a14)4-羟基-2-氧代己酸醛缩酶(4-hydroxy-2-oxohexanonatealdolase)。[b38]根据[b1]至[b37]中任一项所述的方法,其中,所述第一基因对选自由以下所组成的群组中的醛缩酶进行编码:eda蛋白质,优选为来源于大肠杆菌的eda蛋白质;dgoa蛋白质,优选为来源于大肠杆菌的dgoa蛋白质;yjhh蛋白质,优选为来源于大肠杆菌的yjhh蛋白质;yage蛋白质,优选为来源于大肠杆菌的yage蛋白质;nana蛋白质,优选为来源于大肠杆菌的nana蛋白质;mhpe蛋白质,优选为来源于大肠杆菌的mhpe蛋白质;hpai蛋白质,优选为来源于大肠杆菌的hpai蛋白质;bphi蛋白质,优选为来源于食异源化合物伯克霍尔德氏菌的bphi蛋白质;phdj蛋白质,优选为来源于类诺卡氏菌属菌的phdj蛋白质;garl蛋白质,优选为来源于大肠杆菌的garl蛋白质;rhma蛋白质,优选为来源于大肠杆菌的rhma蛋白质;及galc蛋白质,优选为来源于恶臭假单胞菌的galc蛋白质。[b39]根据[b1]至[b38]中任一项所述的方法,其中,所述第一基因选自由以下所组成的群组中:(1-1)对包含序列号2中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-2)对包含序列号2中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-3)对包含序列号4中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-4)对包含序列号4中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-5)对包含序列号6中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-6)对包含序列号6中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-7)对包含序列号8中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-8)对包含序列号8中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-9)对包含序列号10中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-10)对包含序列号10中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-11)对包含序列号12中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-12)对包含序列号12中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-13)对包含序列号14中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-14)对包含序列号14中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-15)对包含序列号16中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-16)对包含序列号16中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-17)对包含序列号18中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-18)对包含序列号18中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-19)对包含序列号20中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-20)对包含序列号20中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-21)对包含序列号22中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,及(1-22)对包含序列号22中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因。[b40]根据[b1]至[b39]中任一项所述的方法,其中,所述第一基因选自由以下所组成的群组中:包含序列号1中记载的碱基序列的基因,包含序列号3中记载的碱基序列的基因,包含序列号5中记载的碱基序列的基因,包含序列号7中记载的碱基序列的基因,包含序列号9中记载的碱基序列的基因,包含序列号11中记载的碱基序列的基因,包含序列号13中记载的碱基序列的基因,包含序列号15中记载的碱基序列的基因,包含序列号17中记载的碱基序列的基因,包含序列号19中记载的碱基序列的基因,及包含序列号21中记载的碱基序列的基因。[b41]根据[b1]至[b40]中任一项所述的方法,其中,所述第二基因对催化α-酮酸的脱羧反应的所述酶进行编码,所述α-酮酸是通过所述羟醛反应而获得。[b42]根据[b1]至[b41]中任一项所述的方法,其中,所述第二基因对脱羧酶进行编码。[b43]根据[b1]至[b42]中任一项所述方法,其中,所述第二基因对选自由以下所组成的群组中的脱羧酶进行编码:(b1)丙酮酸脱羧酶(pyruvatedecarboxylase),(b2)苯甲酰甲酸脱羧酶(benzoylformatedecarboxylase),及(b3)吲哚丙酮酸脱羧酶(indolepyruvatedecarboxylase)。[b44]根据[b1]至[b43]中任一项所述的方法,其中,所述第二基因对选自由以下所组成的群组中的脱羧酶进行编码:pdc蛋白质,优选为来源于运动发酵单胞菌的pdc蛋白质;mdlc蛋白质,优选为来源于恶臭假单胞菌的mdlc蛋白质;kivd蛋白质,优选为来源于乳酸乳球菌的kivd蛋白质。[b45]根据[b1]至[b44]中任一项所述的方法,其中,所述第二基因对mdlc蛋白质、优选为来源于恶臭假单胞菌的mdlc蛋白质进行编码。[b46]根据[b1]至[b45]中任一项所述的方法,其中,所述第二基因选自由以下所组成的群组中:(2-1)对包含序列号24中记载的氨基酸序列、且催化α-酮酸的脱羧反应的蛋白质进行编码的基因,及(2-2)对包含序列号24中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的脱羧反应的活性的蛋白质进行编码的基因。[b47]根据[b1]至[b46]中任一项所述的方法,其中,所述第二基因为包含序列号23中记载的碱基序列的基因。[b48]根据[b1]至[b47]中任一项所述的方法,其中,所述第三基因对催化醛的还原反应的所述酶进行编码,所述醛与作为所述第一基因所编码的所述酶催化的所述羟醛反应的基质的醛为不同种类。[b49]根据[b1]至[b48]中任一项所述的方法,其中,所述第三基因对催化醛的还原反应的所述酶进行编码,所述醛是通过所述脱羧反应而获得。[b50]根据[b1]至[b49]中任一项所述的方法,其中,所述第三基因对醇脱氢酶进行编码。[b51]根据[b1]至[b50]中任一项所述的方法,其中,所述第三基因对1,3-丙二醇脱氢酶(1,3-propanedioldehydrogenase)进行编码。[b52]根据[b1]至[b51]中任一项所述的方法,其中,所述第三基因对选自由以下所组成的群组中的1,3-丙二醇脱氢酶进行编码:dhat蛋白质,优选为来源于肺炎克雷伯菌的dhat蛋白质;及lpo蛋白质,优选为来源于罗伊氏乳杆菌的lpo蛋白质。[b53]根据[b1]至[b52]中任一项所述的方法,其中,所述第三基因选自由以下所组成的群组中:(3-1)对包含序列号26中记载的氨基酸序列、且催化醛的还原反应的蛋白质进行编码的基因,及(3-2)对包含序列号26中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化醛的还原反应的活性的蛋白质进行编码的基因。[b54]根据[b1]至[b53]中任一项所述的方法,其中,所述第三基因为包含序列号25中记载的碱基序列的基因。[b55]根据[b1]至[b54]中任一项所述的方法,其中,所述微生物为好氧性细菌,优选为棒状细菌,更优选为棒状杆菌属(corynebacterium)菌,更优选为谷氨酸棒状杆菌(corynebacteriumglutamicum)。[b56]根据[b1]至[b55]中任一项所述的方法,其中,所述微生物是通过所述第一基因、所述第二基因及所述第三基因进行了转化的微生物。[b57]根据[b1]至[b56]中任一项所述的方法,其中,所述微生物是选自由以下所组成的群组中的至少一种基因的缺陷株:乳酸(lactate)脱氢酶(lactatedehydrogenase)基因、磷酸烯醇丙酮酸羧化酶(phosphoenolpyrvatecarboxylase)基因、丙酮酸羧化酶(pyruvatecarboxylase)基因、丙酮酸脱氢酶(pyruvatedehydrogenase)基因、谷氨酸-丙酮酸氨基转移酶(glutamate-pyruvateaminotransferase)基因、乙酰乳酸合酶(acetolactatesynthase)基因、n-琥珀酰二氨基庚二酸(n-succinyldiaminopimelateaminotransferase)基因、s-(羟甲基)分枝硫醇脱氢酶(s-(hydroxymethyl)mycothioldehydrogenase)基因、及乙醛脱氢酶(acetaldehydedehydrogenase)基因。[b58]根据[b1]至[b57]中任一项所述的方法,还包括:在所述培养之前,在好氧条件下对所述微生物进行培养。[c1]一种2,4-二羟基羧酸的制造方法,包括:在丙酮酸供给化合物以及羰基化合物的存在下对微生物进行培养以生产2,4-二羟基羧酸的工序,其中,所述微生物包含以下基因:(a)第一基因,对催化丙酮酸与羰基化合物的羟醛反应的酶进行编码,及(d)第四基因,对催化α-酮酸的还原反应的酶进行编码,所述丙酮酸供给化合物选自丙酮酸及糖类中,所述羰基化合物由下述通式(1)表示:r101c(o)r102(此处,r101及r102相互独立地为氢、或具有1个~5个碳原子的烷基),所述2,4-二羟基羧酸由下述通式(5)表示:r101c(r102)(oh)ch2ch(oh)cooh(所述通式(5)中的r101及r102分别为与所述通式(1)中的r101及r102相同的基)。[c2]根据[c1]所述的方法,其中,所述通式(1)及通式(5)中,r102为氢。[c3]根据[c1]或[c2]中任一项所述的方法,其中,所述通式(1)及通式(5)中,r101为氢、甲基、乙基、丙基或戊基,且r102为氢。[c4]根据[c1]至[c3]中任一项所述的方法,其中,所述通式(1)及通式(5)中,r101及r102为氢。[c5]根据[c1]至[c4]中任一项所述的方法,其中,所述培养通过在包含所述丙酮酸供给化合物及羰基化合物的培养液中对所述微生物进行培养来进行。[c6]根据[c5]所述的方法,其中,所述培养液是添加了所述丙酮酸供给化合物及羰基化合物的培养液。[c7]根据[c6]所述的方法,其中,以在所述培养液中成为0.1(w/v)%~40(w/v)%、优选成为1(w/v)%~20(w/v)%的浓度的方式添加所述丙酮酸供给化合物。[c8]根据[c6]或[c7]所述的方法,其中,以在所述培养液中成为0.001(w/v)%~10(w/v)%、优选成为0.01(w/v)%~1(w/v)%的浓度的方式添加羰基化合物。[c9]根据[c1]至[c8]中任一项所述的方法,其中,所述丙酮酸供给化合物为糖类。[c10]根据[c1]至[c9]中任一项所述的方法,其中,所述糖类为:单糖,例如果糖或葡萄糖;二糖,例如蔗糖;多糖,例如包含葡萄糖作为构成单糖的多糖;或者利用糖化酶对植物(例如非可食用农产废弃物或能量作物)进行处理而获得的糖化液。[c11]根据[c1]至[c10]中任一项所述的方法,其中,所述糖类为葡萄糖。[c12]根据[c1]至[c11]中任一项所述的方法,其中,所述丙酮酸供给化合物为丙酮酸。[c13]根据[c1]至[c12]中任一项所述的方法,其中,所述培养在厌氧条件或微好氧条件下进行。[c14]根据[c13]所述的方法,其中,所述培养通过在包含所述丙酮酸供给化合物及羰基化合物的培养液中对所述微生物进行培养来进行。[c15]根据[c14]所述的方法,其中,所述厌氧条件或所述微好氧条件是所述培养液中的溶解氧浓度在0ppm~2ppm的范围内、优选在0ppm~1ppm的范围内、更优选在0ppm~0.5ppm的范围内的条件。[c16]根据[c1]至[c15]中任一项所述的方法,其中,所述培养在使所述微生物高密度地悬浮于培养液中的状态下进行。[c17]根据[c16]所述的方法,其中,所述培养通过在包含所述丙酮酸供给化合物及羰基化合物的培养液中对所述微生物进行培养来进行。[c18]根据[c17]所述的方法,其中,使所述微生物高密度地悬浮于所述培养液中的所述状态是以所述微生物的湿菌体重量%成为1(w/v)%~50(w/v)%的范围内的方式使所述微生物悬浮于所述培养液中的状态,优选是以所述微生物的湿菌体重量%成为3(w/v)%~30(w/v)%的范围内的方式使所述微生物悬浮于所述培养液中的状态。[c19]根据[c1]至[c18]中任一项所述的方法,其中,所述第一基因对醛缩酶进行编码。[c20]根据[c1]至[c19]中任一项所述的方法,其中,所述第一基因对i类醛缩酶进行编码。[c21]根据[c1]至[c29]中任一项所述的方法,其中,所述第一基因对ii类醛缩酶进行编码。[c22]根据[c1]至[c21]中任一项所述的方法,其中,所述第一基因对选自由以下所组成的群组中的醛缩酶进行编码:(a1)2-脱氢-3-脱氧-磷酸葡萄糖酸醛缩酶(2-dehydro-3-deoxy-phosphogluconatealdolase),(a2)2-脱氢-3-脱氧-6-磷酸葡萄糖酸醛缩酶(2-dehydro-3-deoxy-6-phosphogluconatealdolase),(a3)4-羟基-2-氧代戊二酸醛缩酶(4-hydroxy-2-oxoglutaratealdolase),(a4)(4s)-4-羟基-2-氧代戊二酸醛缩酶((4s)-4-hydroxyl-2-oxoglutaratealdolase),(a5)2-脱氢-3-脱氧-d-戊糖酸醛缩酶(2-dehydro-3-deoxy-d-pentonatealdolase),(a6)2-脱氢-3-脱氧-d-葡萄糖酸醛缩酶(2-dehydro-3-deoxy-d-gluconatealdolase),(a7)3-脱氧-d-甘露-辛酮糖酸醛缩酶(3-deoxy-d-manno-octulosonatealdolase),(a8)4-羟基-2-氧代戊酸醛缩酶(4-hydroxyl-2-oxovaleratealdolase),(a9)4-(2-羧基苯基)-2-氧代丁-3-烯酸醛缩酶(4-(2-carboxyphenyl)-2-oxobut-3-enoatealdolase),(a10)4-羟基-2-氧代庚烷二酸醛缩酶(4-hydroxy-2-oxoheptanedioatealdolase),(a11)2-脱氢-3-脱氧葡萄糖二酸醛缩酶(2-dehydro-3-deoxyglucaratealdolase),(a12)2-酮-3-脱氧-l-鼠李糖酸醛缩酶(2-keto-3-deoxy-l-rhamnonatealdolase),(a13)4-羟基-4-甲基-2-氧代戊二酸醛缩酶(4-hydroxyl-4-methyl-2-oxoglutaratealdolase),及(a14)4-羟基-2-氧代己酸醛缩酶(4-hydroxy-2-oxohexanonatealdolase)。[c23]根据[c1]至[c22]中任一项所述的方法,其中,所述第一基因对选自由以下所组成的群组中的醛缩酶进行编码:eda蛋白质,优选为来源于大肠杆菌的eda蛋白质;dgoa蛋白质,优选为来源于大肠杆菌的dgoa蛋白质;yjhh蛋白质,优选为来源于大肠杆菌的yjhh蛋白质;yage蛋白质,优选为来源于大肠杆菌的yage蛋白质;nana蛋白质,优选为来源于大肠杆菌的nana蛋白质;mhpe蛋白质,优选为来源于大肠杆菌的mhpe蛋白质;hpai蛋白质,优选为来源于大肠杆菌的hpai蛋白质;bphi蛋白质,优选为来源于食异源化合物伯克霍尔德氏菌的bphi蛋白质;phdj蛋白质,优选为来源于类诺卡氏菌属菌的phdj蛋白质;garl蛋白质,优选为来源于大肠杆菌的garl蛋白质;rhma蛋白质,优选为来源于大肠杆菌的rhma蛋白质;及galc蛋白质,优选为来源于恶臭假单胞菌的galc蛋白质。[c24]根据[c1]至[c23]中任一项所述的方法,其中,所述第一基因选自由以下所组成的群组中:(1-1)对包含序列号2中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-2)对包含序列号2中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-3)对包含序列号4中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-4)对包含序列号4中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-5)对包含序列号6中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-6)对包含序列号6中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-7)对包含序列号8中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-8)对包含序列号8中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-9)对包含序列号10中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-10)对包含序列号10中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-11)对包含序列号12中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-12)对包含序列号12中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-13)对包含序列号14中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-14)对包含序列号14中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-15)对包含序列号16中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-16)对包含序列号16中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-17)对包含序列号18中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-18)对包含序列号18中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-19)对包含序列号20中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-20)对包含序列号20中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-21)对包含序列号22中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,及(1-22)对包含序列号22中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因。[c25]根据[c1]至[c24]中任一项所述的方法,其中,所述第一基因选自由以下所组成的群组中:包含序列号1中记载的碱基序列的基因,包含序列号3中记载的碱基序列的基因,包含序列号5中记载的碱基序列的基因,包含序列号7中记载的碱基序列的基因,包含序列号9中记载的碱基序列的基因,包含序列号11中记载的碱基序列的基因,包含序列号13中记载的碱基序列的基因,包含序列号15中记载的碱基序列的基因,包含序列号17中记载的碱基序列的基因,包含序列号19中记载的碱基序列的基因,及包含序列号21中记载的碱基序列的基因。[c26]根据[c1]至[c23]中任一项所述的方法,其中,所述第四基因对催化α-酮酸的α-酮酸的还原反应的所述酶进行编码,所述α-酮酸是通过所述羟醛反应而获得。[c27]根据[c1]至[c26]中任一项所述的方法,其中,所述第四基因对脱氢酶进行编码。[c28]根据[c1]至[c27]中任一项所述的方法,其中,所述第四基因对乳酸脱氢酶进行编码。[c29]根据[c1]至[c28]中任一项所述的方法,其中,所述第四基因对如下蛋白质进行编码:所述蛋白质为ldha蛋白质,优选为来源于乳酸乳球菌的ldha蛋白质,更优选为来源于乳酸乳球菌nbrc100676株的ldha蛋白质,进而优选为作为来源于乳酸乳球菌nbrc100676株的ldha蛋白质的、自n末端起的第85个谷氨酰胺残基经胱氨酸残基取代的蛋白质。[c30]根据[c1]至[c29]中任一项所述的方法,其中,所述第四基因选自由以下所组成的群组中:(4-1)对包含序列号28中记载的氨基酸序列、且催化α-酮酸的还原反应的蛋白质进行编码的基因,及(4-2)对包含序列号28中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的还原反应的活性的蛋白质进行编码的基因。[c31]根据[c1]至[c30]中任一项所述的方法,其中,对包含序列号28中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的还原反应的活性的所述蛋白质进行编码的所述基因对在自n末端起的第85个残基中维持了胱氨酸残基的蛋白质进行了编码。[c32]根据[c1]至[c31]中任一项所述的方法,其中,所述第四基因是包含序列号27中记载的碱基序列的基因。[c33]根据[c1]至[c32]中任一项所述的方法,其中,所述微生物为好氧性细菌,优选为棒状细菌,更优选为棒状杆菌属(corynebacterium)菌,更优选为谷氨酸棒状杆菌(corynebacteriumglutamicum)。[c34]根据[c1]至[c33]中任一项所述的方法,其中,所述微生物是通过所述第一基因及所述第四基因进行了转化的微生物。[c35]根据[c1]至[c34]中任一项所述的方法,其中,所述微生物是选自由以下所组成的群组中的至少一种基因的缺陷株:乳酸(lactate)脱氢酶(lactatedehydrogenase)基因、磷酸烯醇丙酮酸羧化酶(phosphoenolpyrvatecarboxylase)基因、丙酮酸羧化酶(pyruvatecarboxylase)基因、丙酮酸脱氢酶(pyruvatedehydrogenase)基因、谷氨酸-丙酮酸氨基转移酶(glutamate-pyruvateaminotransferase)基因、乙酰乳酸合酶(acetolactatesynthase)基因、n-琥珀酰二氨基庚二酸(n-succinyldiaminopimelateaminotransferase)基因、s-(羟甲基)分枝硫醇脱氢酶(s-(hydroxymethyl)mycothioldehydrogenase)基因、及乙醛脱氢酶(acetaldehydedehydrogenase)基因。[c36]根据[c1]至[c35]中任一项所述的方法,还包括:在所述培养之前,在好氧条件下对所述微生物进行培养。[c37]根据[c1]至[c36]中任一项所述的方法,还包括:对所生产的2,4-二羟基羧酸进行回收。[d1]一种2-氨基-4-羟基羧酸的制造方法,包括:在丙酮酸供给化合物以及羰基化合物的存在下对微生物进行培养以生产2-氨基-4-羟基羧酸的工序,其中,所述微生物包含以下基因:(a)第一基因,对催化丙酮酸与羰基化合物的羟醛反应的酶进行编码,及(e)第五基因,对催化α-酮酸的还原氨基化反应的酶进行编码,所述丙酮酸供给化合物选自丙酮酸及糖类中,所述羰基化合物由下述通式(1)表示:r101c(o)r102(此处,r101及r102相互独立地为氢、或具有1个~5个碳原子的烷基),所述2-氨基-4-羟基羧酸由下述通式(6)表示:r101c(r102)(oh)ch2ch(nh2)cooh(所述通式(6)中的r101及r102分别为与所述通式(1)中的r101及r102相同的基)。[d2]根据[d1]所述的方法,其中,所述通式(1)及通式(6)中,r102为氢。[d3]根据[d1]或[d2]所述的方法,其中,所述通式(1)及通式(6)中,r101为氢、甲基、乙基、丙基或戊基,且r102为氢。[d4]根据[d1]至[d3]中任一项所述的方法,其中,所述通式(1)及通式(6)中,r101及r102为氢。[d5]根据[d1]至[d4]中任一项所述的方法,还包括:对所生产的2-氨基-4-羟基羧酸进行回收。[d6]一种高丝氨酸、苏氨酸及2-氨基丁酸中的至少一者的制造方法,包括:在选自丙酮酸及糖类中的丙酮酸供给化合物以及甲醛(其为羰基化合物)的存在下对微生物进行培养,以生产高丝氨酸、苏氨酸及2-氨基丁酸中的至少一者的工序,其中,所述微生物包含以下基因:(a)第一基因,对催化丙酮酸与羰基化合物的羟醛反应的酶进行编码,及(e)第五基因,对催化α-酮酸的还原氨基化反应的酶进行编码。[d7]根据[d6]所述的方法,还包括:对所生产的高丝氨酸、苏氨酸及2-氨基丁酸中的至少一者进行回收。[d8]根据[d1]至[d7]中任一项所述的方法,其中,所述培养通过在包含所述丙酮酸供给化合物及羰基化合物的培养液中对所述微生物进行培养来进行。[d9]根据[d8]所述的方法,其中,所述培养液是添加了所述丙酮酸供给化合物及羰基化合物的培养液。[d10]根据[d9]所述的方法,其中,以在所述培养液中成为0.1(w/v)%~40(w/v)%、优选成为1(w/v)%~20(w/v)%的浓度的方式添加了所述丙酮酸供给化合物。[d11]根据[d9]或[d10]所述的方法,其中,以在所述培养液中成为0.001(w/v)%~10(w/v)%、优选成为0.01(w/v)%~1(w/v)%的浓度的方式添加了羰基化合物。[d12]根据[d1]至[d11]中任一项所述的方法,其中,所述丙酮酸供给化合物为糖类。[d13]根据[d1]至[d12]中任一项所述的方法,其中,所述糖类为:单糖,例如果糖或葡萄糖;二糖,例如蔗糖;多糖,例如包含葡萄糖作为构成单糖的多糖;或者利用糖化酶对植物(例如非可食用农产废弃物或能量作物)进行处理而获得的糖化液。[d14]根据[d1]至[d13]中任一项所述的方法,其中,所述糖类为葡萄糖。[d15]根据[d1]至[d14]中任一项所述的方法,其中,所述丙酮酸供给化合物为丙酮酸。[d16]根据[d1]至[d15]中任一项所述的方法,其中,所述培养在厌氧条件或微好氧条件下进行。[d17]根据[d16]所述的方法,其中,所述培养通过在包含所述丙酮酸供给化合物及羰基化合物的培养液中对所述微生物进行培养来进行。[d18]根据[d17]所述的方法,其中,所述厌氧条件或所述微好氧条件是所述培养液中的溶解氧浓度在0ppm~2ppm的范围内、优选在0ppm~1ppm的范围内、更优选在0ppm~0.5ppm的范围内的条件。[d19]根据[d1]至[d18]中任一项所述的方法,其中,所述培养在使所述微生物高密度地悬浮于培养液中的状态下进行。[d20]根据[d19]所述的方法,其中,所述培养通过在包含所述丙酮酸供给化合物及羰基化合物的培养液中对所述微生物进行培养来进行。[d21]根据[d20]所述的方法,其中,使所述微生物高密度地悬浮于所述培养液中的所述状态是以所述微生物的湿菌体重量%成为1(w/v)%~50(w/v)%的范围内的方式使所述微生物悬浮于所述培养液中的状态,优选是以所述微生物的湿菌体重量%成为3(w/v)%~30(w/v)%的范围内的方式使所述微生物悬浮于所述培养液中的状态。[d22]根据[d1]至[d21]中任一项所述的方法,其中,所述第一基因对醛缩酶进行编码。[d23]根据[d1]至[d22]中任一项所述的方法,其中,所述第一基因对i类醛缩酶进行编码。[d24]根据[d1]至[d22]中任一项所述的方法,其中,所述第一基因对ii类醛缩酶进行编码。[d25]根据[d1]至[d24]中任一项所述的方法,其中,所述第一基因对选自由以下所组成的群组中的醛缩酶进行编码:(a1)2-脱氢-3-脱氧-磷酸葡萄糖酸醛缩酶(2-dehydro-3-deoxy-phosphogluconatealdolase),(a2)2-脱氢-3-脱氧-6-磷酸葡萄糖酸醛缩酶(2-dehydro-3-deoxy-6-phosphogluconatealdolase),(a3)4-羟基-2-氧代戊二酸醛缩酶(4-hydroxy-2-oxoglutaratealdolase),(a4)(4s)-4-羟基-2-氧代戊二酸醛缩酶((4s)-4-hydroxyl-2-oxoglutaratealdolase),(a5)2-脱氢-3-脱氧-d-戊糖酸醛缩酶(2-dehydro-3-deoxy-d-pentonatealdolase),(a6)2-脱氢-3-脱氧-d-葡萄糖酸醛缩酶(2-dehydro-3-deoxy-d-gluconatealdolase),(a7)3-脱氧-d-甘露-辛酮糖酸醛缩酶(3-deoxy-d-manno-octulosonatealdolase),(a8)4-羟基-2-氧代戊酸醛缩酶(4-hydroxyl-2-oxovaleratealdolase),(a9)4-(2-羧基苯基)-2-氧代丁-3-烯酸醛缩酶(4-(2-carboxyphenyl)-2-oxobut-3-enoatealdolase),(a10)4-羟基-2-氧代庚烷二酸醛缩酶(4-hydroxy-2-oxoheptanedioatealdolase),(a11)2-脱氢-3-脱氧葡萄糖二酸醛缩酶(2-dehydro-3-deoxyglucaratealdolase),(a12)2-酮-3-脱氧-l-鼠李糖酸醛缩酶(2-keto-3-deoxy-l-rhamnonatealdolase),(a13)4-羟基-4-甲基-2-氧代戊二酸醛缩酶(4-hydroxyl-4-methyl-2-oxoglutaratealdolase),及(a14)4-羟基-2-氧代己酸醛缩酶(4-hydroxy-2-oxohexanonatealdolase)。[d26]根据[d1]至[d25]中任一项所述的方法,其中,所述第一基因对选自由以下所组成的群组中的醛缩酶进行编码:eda蛋白质,优选为来源于大肠杆菌的eda蛋白质;dgoa蛋白质,优选为来源于大肠杆菌的dgoa蛋白质;yjhh蛋白质,优选为来源于大肠杆菌的yjhh蛋白质;yage蛋白质,优选为来源于大肠杆菌的yage蛋白质;nana蛋白质,优选为来源于大肠杆菌的nana蛋白质;mhpe蛋白质,优选为来源于大肠杆菌的mhpe蛋白质;hpai蛋白质,优选为来源于大肠杆菌的hpai蛋白质;bphi蛋白质,优选为来源于食异源化合物伯克霍尔德氏菌的bphi蛋白质;phdj蛋白质,优选为来源于类诺卡氏菌属菌的phdj蛋白质;garl蛋白质,优选为来源于大肠杆菌的garl蛋白质;rhma蛋白质,优选为来源于大肠杆菌的rhma蛋白质;及galc蛋白质,优选为来源于恶臭假单胞菌的galc蛋白质。[d27]根据[d1]至[d26]中任一项所述的方法,其中,所述第一基因选自由以下所组成的群组中:(1-1)对包含序列号2中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-2)对包含序列号2中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-3)对包含序列号4中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-4)对包含序列号4中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-5)对包含序列号6中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-6)对包含序列号6中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-7)对包含序列号8中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-8)对包含序列号8中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-9)对包含序列号10中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-10)对包含序列号10中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-11)对包含序列号12中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-12)对包含序列号12中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-13)对包含序列号14中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-14)对包含序列号14中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-15)对包含序列号16中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-16)对包含序列号16中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-17)对包含序列号18中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-18)对包含序列号18中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-19)对包含序列号20中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-20)对包含序列号20中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-21)对包含序列号22中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,及(1-22)对包含序列号22中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因。[d28]根据[d1]至[d27]中任一项所述的方法,其中,所述第一基因选自由以下所组成的群组中:包含序列号1中记载的碱基序列的基因,包含序列号3中记载的碱基序列的基因,包含序列号5中记载的碱基序列的基因,包含序列号7中记载的碱基序列的基因,包含序列号9中记载的碱基序列的基因,包含序列号11中记载的碱基序列的基因,包含序列号13中记载的碱基序列的基因,包含序列号15中记载的碱基序列的基因,包含序列号17中记载的碱基序列的基因,包含序列号19中记载的碱基序列的基因,及包含序列号21中记载的碱基序列的基因。[d29]根据[d1]至[d28]中任一项所述的方法,其中,所述第五基因对催化α-酮酸的还原氨基化反应的所述酶进行编码,所述α-酮酸是通过所述羟醛反应而获得。[d30]根据[d1]至[d29]中任一项所述的方法,其中,所述第五基因对谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶进行编码。[d31]根据[d1]至[d30]中任一项所述的方法,其中,所述第五基因对选自由谷氨酸脱氢酶、苯丙氨酸脱氢酶、亮氨酸脱氢酶及缬氨酸脱氢酶所组成的群组中的至少一个脱氢酶进行编码。[d32]根据[d1]至[d31]中任一项所述的方法,其中,所述第五基因对选自由以下所组成的群组中的谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶进行编码:(d1)亮氨酸脱氢酶(leucinedehydrogenase,ec编号1.4.1.9),(d2)苯丙氨酸脱氢酶(phenylalaninedehydrogenase,ec编号1.4.1.20),及(d3)缬氨酸脱氢酶(valinedehydrogenase,ec编号1.4.1.8及ec编号1.4.1.23)。[d33]根据[d1]至[d32]中任一项所述的方法,其中,所述第五基因对选自由以下所组成的群组中的醛缩酶进行编码:leudh蛋白质,优选为来源于球形赖氨酸芽孢杆菌的leudh蛋白质、来源于蜡样芽孢杆菌的leudh蛋白质、或来源于嗜热脂肪地芽孢杆菌的leudh蛋白质;phedh蛋白质,优选为来源于栗褐芽孢杆菌的phedh蛋白质;及valdh蛋白质,优选为来源于费氏链霉菌的valdh蛋白质。[d34]根据[d1]至[d33]中任一项所述的方法,其中,所述第五基因选自由以下所组成的群组中:(5-1)对包含序列号30中记载的氨基酸序列、且催化α-酮酸的还原氨基化反应的蛋白质进行编码的基因,(5-2)对包含序列号30中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的还原氨基化反应的活性的蛋白质进行编码的基因,(5-3)对包含序列号32中记载的氨基酸序列、且催化α-酮酸的还原氨基化反应的蛋白质进行编码的基因,(5-4)对包含序列号32中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的还原氨基化反应的活性的蛋白质进行编码的基因,(5-5)对包含序列号34中记载的氨基酸序列、且催化α-酮酸的还原氨基化反应的蛋白质进行编码的基因,及(5-6)对包含序列号34中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的还原氨基化反应的活性的蛋白质进行编码的基因。[d35]根据[d1]至[d34]中任一项所述的方法,其中,所述第五基因选自由以下所组成的群组中:包含序列号29中记载的碱基序列的基因,包含序列号31中记载的碱基序列的基因,及包含序列号33中记载的碱基序列的valdh基因。[d36]根据[d1]至[d35]中任一项所述的方法,其中,所述微生物为好氧性细菌,优选为棒状细菌,更优选为棒状杆菌属(corynebacterium)菌,更优选为谷氨酸棒状杆菌(corynebacteriumglutamicum)。[d37]根据[d1]至[d36]中任一项所述的方法,其中,所述微生物是通过所述第一基因及所述第五基因进行了转化的微生物。[d38]根据[d1]至[d37]中任一项所述的方法,其中,所述微生物是选自由以下所组成的群组中的至少一种基因的缺陷株:乳酸(lactate)脱氢酶(lactatedehydrogenase)基因、磷酸烯醇丙酮酸羧化酶(phosphoenolpyrvatecarboxylase)基因、丙酮酸羧化酶(pyruvatecarboxylase)基因、丙酮酸脱氢酶(pyruvatedehydrogenase)基因、谷氨酸-丙酮酸氨基转移酶(glutamate-pyruvateaminotransferase)基因、乙酰乳酸合酶(acetolactatesynthase)基因、n-琥珀酰二氨基庚二酸(n-succinyldiaminopimelateaminotransferase)基因、s-(羟甲基)分枝硫醇脱氢酶(s-(hydroxymethyl)mycothioldehydrogenase)基因、及乙醛脱氢酶(acetaldehydedehydrogenase)基因。[d39]根据[d1]至[d38]中任一项所述的方法,还包括:在所述培养之前,在好氧条件下对所述微生物进行培养。[e1]一种2-氨基-4-甲基硫代羧酸的制造方法,包括:在丙酮酸供给化合物、甲硫醇、以及羰基化合物的存在下对微生物进行培养以生产2-氨基-4-甲基硫代羧酸的工序,其中,所述微生物包含以下基因:(a)第一基因,对催化丙酮酸与羰基化合物的羟醛反应的酶进行编码,(e)第五基因,对催化α-酮酸的还原氨基化反应的酶进行编码,及(f)第六基因,对催化由甲硫醇所具有的甲巯基取代2-氨基-4-膦酰氧基羧酸所具有的磷酸基的反应的酶进行编码,所述丙酮酸供给化合物选自丙酮酸及糖类中,所述羰基化合物由下述通式(1)表示:r101c(o)r102(此处,r101及r102相互独立地为氢、或具有1个~5个碳原子的烷基),所述2-氨基-4-甲基硫代羧酸由下述通式(7)表示:r101c(r102)(sch3)ch2ch(nh2)cooh(所述通式(7)中的r101及r102分别为与所述通式(1)中的r101及r102相同的基)。[e2]根据[e1]所述的方法,其中,所述通式(1)及通式(7)中,r102为氢。[e3]根据[e1]或[e2]所述的方法,其中,所述通式(1)及通式(7)中,r101为氢、甲基、乙基、丙基或戊基,且r102为氢。[e4]根据[e1]至[e3]中任一项所述的方法,其中,所述通式(1)及通式(7)中,r101及r102为氢。[e5]根据[e1]至[e4]中任一项所述的方法,其中,所述培养通过在包含所述丙酮酸供给化合物、所述羰基化合物以及甲硫醇的培养液中对所述微生物进行培养来进行。[e6]根据[e5]所述的方法,其中,所述培养液是添加了所述丙酮酸供给化合物、所述羰基化合物以及甲硫醇的培养液。[e7]根据[e6]所述的方法,其中,以在所述培养液中成为0.1(w/v)%~40(w/v)%、优选成为1(w/v)%~20(w/v)%的浓度的方式添加所述丙酮酸供给化合物。[e8]根据[e6]或[e7]所述的方法,其中,以在所述培养液中成为0.001(w/v)%~10(w/v)%、优选成为0.01(w/v)%~1(w/v)%的浓度的方式添加羰基化合物。[e9]根据[e6]至[e8]中任一项所述的方法,其中,以在所述培养液中成为1mm~1m、优选成为10mm~300mm的浓度的方式添加甲硫醇。[e10]根据[e1]至[e9]中任一项所述的方法,其中,所述丙酮酸供给化合物为糖类。[e11]根据[e1]至[e10]中任一项所述的方法,其中,所述糖类为:单糖,例如果糖或葡萄糖;二糖,例如蔗糖;多糖,例如包含葡萄糖作为构成单糖的多糖;或者利用糖化酶对植物(例如非可食用农产废弃物或能量作物)进行处理而获得的糖化液。[e12]根据[e1]至[e11]中任一项所述的方法,其中,所述糖类为葡萄糖。[e13]根据[e1]至[e9]中任一项所述的方法,其中,所述丙酮酸供给化合物为丙酮酸。[e14]根据[e1]至[e13]中任一项所述的方法,其中,所述培养在厌氧条件或微好氧条件下进行。[e15]根据[e17]所述的方法,其中,所述培养通过在包含所述丙酮酸供给化合物、所述羰基化合物以及甲硫醇的培养液中对所述微生物进行培养来进行。[e16]根据[e15]所述的方法,其中,所述厌氧条件或所述微好氧条件是所述培养液中的溶解氧浓度在0ppm~2ppm的范围内、优选在0ppm~1ppm的范围内、更优选在0ppm~0.5ppm的范围内的条件。[e17]根据[e1]至[e16]中任一项所述的方法,其中,所述培养在使所述微生物高密度地悬浮于培养液中的状态下进行。[e18]根据[e17]所述的方法,其中,所述培养通过在包含所述丙酮酸供给化合物、所述羰基化合物以及甲硫醇的培养液中对所述微生物进行培养来进行。[e19]根据[e18]所述的方法,其中,使所述微生物高密度地悬浮于所述培养液中的所述状态是以所述微生物的湿菌体重量%成为1(w/v)%~50(w/v)%的范围内的方式使所述微生物悬浮于所述培养液中的状态,优选是以所述微生物的湿菌体重量%成为3(w/v)%~30(w/v)%的范围内的方式使所述微生物悬浮于所述培养液中的状态。[e20]根据[e1]至[e19]中任一项所述的方法,其中,所述第一基因对醛缩酶进行编码。[e21]根据[e1]至[e20]中任一项所述的方法,其中,所述第一基因对i类醛缩酶进行编码。[e22]根据[e1]至[e20]中任一项所述的方法,其中,所述第一基因对ii类醛缩酶进行编码。[e23]根据[e1]至[e22]中任一项所述的方法,其中,所述第一基因对选自由以下所组成的群组中的醛缩酶进行编码:(a1)2-脱氢-3-脱氧-磷酸葡萄糖酸醛缩酶(2-dehydro-3-deoxy-phosphogluconatealdolase),(a2)2-脱氢-3-脱氧-6-磷酸葡萄糖酸醛缩酶(2-dehydro-3-deoxy-6-phosphogluconatealdolase),(a3)4-羟基-2-氧代戊二酸醛缩酶(4-hydroxy-2-oxoglutaratealdolase),(a4)(4s)-4-羟基-2-氧代戊二酸醛缩酶((4s)-4-hydroxyl-2-oxoglutaratealdolase),(a5)2-脱氢-3-脱氧-d-戊糖酸醛缩酶(2-dehydro-3-deoxy-d-pentonatealdolase),(a6)2-脱氢-3-脱氧-d-葡萄糖酸醛缩酶(2-dehydro-3-deoxy-d-gluconatealdolase),(a7)3-脱氧-d-甘露-辛酮糖酸醛缩酶(3-deoxy-d-manno-octulosonatealdolase),(a8)4-羟基-2-氧代戊酸醛缩酶(4-hydroxyl-2-oxovaleratealdolase),(a9)4-(2-羧基苯基)-2-氧代丁-3-烯酸醛缩酶(4-(2-carboxyphenyl)-2-oxobut-3-enoatealdolase),(a10)4-羟基-2-氧代庚烷二酸醛缩酶(4-hydroxy-2-oxoheptanedioatealdolase),(a11)2-脱氢-3-脱氧葡萄糖二酸醛缩酶(2-dehydro-3-deoxyglucaratealdolase),(a12)2-酮-3-脱氧-l-鼠李糖酸醛缩酶(2-keto-3-deoxy-l-rhamnonatealdolase),(a13)4-羟基-4-甲基-2-氧代戊二酸醛缩酶(4-hydroxyl-4-methyl-2-oxoglutaratealdolase),及(a14)4-羟基-2-氧代己酸醛缩酶(4-hydroxy-2-oxohexanonatealdolase)。[e24]根据[e1]至[e23]中任一项所述的方法,其中,所述第一基因对选自由以下所组成的群组中的醛缩酶进行编码:eda蛋白质,优选为来源于大肠杆菌的eda蛋白质;dgoa蛋白质,优选为来源于大肠杆菌的dgoa蛋白质;yjhh蛋白质,优选为来源于大肠杆菌的yjhh蛋白质;yage蛋白质,优选为来源于大肠杆菌的yage蛋白质;nana蛋白质,优选为来源于大肠杆菌的nana蛋白质;mhpe蛋白质,优选为来源于大肠杆菌的mhpe蛋白质;hpai蛋白质,优选为来源于大肠杆菌的hpai蛋白质;bphi蛋白质,优选为来源于食异源化合物伯克霍尔德氏菌的bphi蛋白质;phdj蛋白质,优选为来源于类诺卡氏菌属菌的phdj蛋白质;garl蛋白质,优选为来源于大肠杆菌的garl蛋白质;rhma蛋白质,优选为来源于大肠杆菌的rhma蛋白质;及galc蛋白质,优选为来源于恶臭假单胞菌的galc蛋白质。[e25]根据[e1]至[e24]中任一项所述的方法,其中,所述第一基因选自由以下所组成的群组中:(1-1)对包含序列号2中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-2)对包含序列号2中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-3)对包含序列号4中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-4)对包含序列号4中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-5)对包含序列号6中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-6)对包含序列号6中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-7)对包含序列号8中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-8)对包含序列号8中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-9)对包含序列号10中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-10)对包含序列号10中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-11)对包含序列号12中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-12)对包含序列号12中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-13)对包含序列号14中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-14)对包含序列号14中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-15)对包含序列号16中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-16)对包含序列号16中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-17)对包含序列号18中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-18)对包含序列号18中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-19)对包含序列号20中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-20)对包含序列号20中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-21)对包含序列号22中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,及(1-22)对包含序列号22中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因。[e26]根据[e1]至[e25]中任一项所述的方法,其中,所述第一基因选自由以下所组成的群组中:包含序列号1中记载的碱基序列的基因,包含序列号3中记载的碱基序列的基因,包含序列号5中记载的碱基序列的基因,包含序列号7中记载的碱基序列的基因,包含序列号9中记载的碱基序列的基因,包含序列号11中记载的碱基序列的基因,包含序列号13中记载的碱基序列的基因,包含序列号15中记载的碱基序列的基因,包含序列号17中记载的碱基序列的基因,包含序列号19中记载的碱基序列的基因,及包含序列号21中记载的碱基序列的基因。[e27]根据[e1]至[e26]中任一项所述的方法,其中,所述第五基因对催化α-酮酸的还原氨基化反应的所述酶进行编码,所述α-酮酸是通过所述羟醛反应而获得。[e28]根据[e1]至[e27]中任一项所述的方法,其中,所述第五基因对谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶进行编码。[e29]根据[e1]至[e28]中任一项所述的方法,其中,所述第五基因对选自由谷氨酸脱氢酶、苯丙氨酸脱氢酶、亮氨酸脱氢酶及缬氨酸脱氢酶所组成的群组中的至少一个脱氢酶进行编码。[e30]根据[e1]至[e29]中任一项所述的方法,其中,所述第五基因对选自由以下所组成的群组中的谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶进行编码:(d1)亮氨酸脱氢酶(leucinedehydrogenase,ec编号1.4.1.9),(d2)苯丙氨酸脱氢酶(phenylalaninedehydrogenase,ec编号1.4.1.20),及(d3)缬氨酸脱氢酶(valinedehydrogenase,ec编号1.4.1.8及ec编号1.4.1.23)。[e31]根据[e1]至[e30]中任一项所述的方法,其中,所述第五基因对选自由以下所组成的群组中的醛缩酶进行编码:leudh蛋白质,优选为来源于球形赖氨酸芽孢杆菌的leudh蛋白质、来源于蜡样芽孢杆菌的leudh蛋白质、或来源于嗜热脂肪地芽孢杆菌的leudh蛋白质;phedh蛋白质,优选为来源于栗褐芽孢杆菌的phedh蛋白质;及valdh蛋白质,优选为来源于费氏链霉菌的valdh蛋白质。[e32]根据[e1]至[e31]中任一项所述的方法,其中,所述第五基因选自由以下所组成的群组中:(5-1)对包含序列号30中记载的氨基酸序列、且催化α-酮酸的还原氨基化反应的蛋白质进行编码的基因,(5-2)对包含序列号30中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的还原氨基化反应的活性的蛋白质进行编码的基因,(5-3)对包含序列号32中记载的氨基酸序列、且催化α-酮酸的还原氨基化反应的蛋白质进行编码的基因,(5-4)对包含序列号32中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的还原氨基化反应的活性的蛋白质进行编码的基因,(5-5)对包含序列号34中记载的氨基酸序列、且催化α-酮酸的还原氨基化反应的蛋白质进行编码的基因,及(5-6)对包含序列号34中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的还原氨基化反应的活性的蛋白质进行编码的基因。[e33]根据[e1]至[e32]中任一项所述的方法,其中,所述第五基因选自由以下所组成的群组中:包含序列号30中记载的碱基序列的基因,包含序列号32中记载的碱基序列的基因,及包含序列号34中记载的碱基序列的基因。[e34]根据[b1]至[b33]中任一项所述的方法,其中,所述第六基因对转硫酶进行编码。[e35]根据[e1]至[e34]中任一项所述的方法,其中,所述第六基因对胱硫醚γ-合酶(cystathionineγ-synthase)进行编码。[e36]根据[e1]至[e35]中任一项所述的方法,其中,所述第六基因对cgs1蛋白质、优选为来源于拟南芥的cgs1蛋白质、更优选为来源于拟南芥的cgs1成熟蛋白质进行编码。[e37]根据[e1]至[e36]中任一项所述的方法,其中,所述第六基因选自由以下所组成的群组中:(6-1)对包含序列号36中记载的氨基酸序列、且催化由甲硫醇所具有的甲巯基取代2-氨基-4-膦酰氧基羧酸所具有的磷酸基的反应的蛋白质进行编码的基因,及(6-2)对包含序列号36中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化由甲硫醇所具有的甲巯基取代2-氨基-4-膦酰氧基羧酸所具有的磷酸基的反应的活性的蛋白质进行编码的基因。[e38]根据[e1]至[e37]中任一项所述的方法,其中,第六基因是包含序列号35中记载的碱基序列的基因。[e39]根据[e1]至[e38]中任一项所述的方法,其中,所述微生物为好氧性细菌,优选为棒状细菌,更优选为棒状杆菌属(corynebacterium)菌,更优选为谷氨酸棒状杆菌(corynebacteriumglutamicum)。[e40]根据[e1]至[e39]中任一项所述的方法,其中,所述微生物是通过所述第一基因、所述第五基因及所述第六基因进行了转化的微生物。[e41]根据[e1]至[e43]中任一项所述的方法,其中,所述微生物是选自由以下所组成的群组中的至少一种基因的缺陷株:乳酸(lactate)脱氢酶(lactatedehydrogenase)基因、磷酸烯醇丙酮酸羧化酶(phosphoenolpyrvatecarboxylase)基因、丙酮酸羧化酶(pyruvatecarboxylase)基因、丙酮酸脱氢酶(pyruvatedehydrogenase)基因、谷氨酸-丙酮酸氨基转移酶(glutamate-pyruvateaminotransferase)基因、乙酰乳酸合酶(acetolactatesynthase)基因、n-琥珀酰二氨基庚二酸(n-succinyldiaminopimelateaminotransferase)基因、s-(羟甲基)分枝硫醇脱氢酶(s-(hydroxymethyl)mycothioldehydrogenase)基因、及乙醛脱氢酶(acetaldehydedehydrogenase)基因。[e42]根据[e1]至[e41]中任一项所述的方法,还包括:在所述培养之前,在好氧条件下对所述微生物进行培养。[e43]根据[e1]至[e42]中任一项所述的方法,还包括:对所生产的2-氨基-4-甲基硫代羧酸进行回收。[f1]一种2-氨基-4-羟基羧酸的制造方法,包括:使α-酮酸、氮源以及还原剂在谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶的存在下进行反应,以生产2-氨基-4-羟基羧酸的工序,其中,所述α-酮酸由下述通式(2)表示:r101c(r102)(oh)ch2cocooh(此处,r101及r102相互独立地为氢、或具有1个~5个碳原子的烷基),所述2-氨基-4-羟基羧酸由下述通式(6)表示:r101c(r102)(oh)ch2ch(nh2)cooh(所述通式(6)中的r101及r102分别为与所述通式(2)中的r101及r102相同的基)。[f2]根据[f1]所述的方法,其中,所述通式(2)及通式(6)中,r102为氢。[f3]根据[f1]或[f2]所述的方法,其中,所述通式(2)及通式(6)中,r101及r102为氢。[f4]根据[f1]至[f3]中任一项所述的方法,其中,所述反应在包含由所述通式(2)表示的所述α-酮酸、所述氮源、所述还原剂以及谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶的反应液中进行。[f5]根据[f4]所述的方法,其中,所述反应液是添加了由所述通式(2)表示的所述α-酮酸、所述氮源、所述还原剂以及谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶的反应液。[f6]根据[f5]所述的方法,其中,以在所述反应液中成为0.1mm~1m、优选成为1mm~300mm的浓度的方式添加由所述通式(2)表示的所述α-酮酸。[f7]根据[f5]或[f6]所述的方法,其中,以在所述反应液中成为0.1mm~1m、优选成为1mm~300mm的浓度的方式添加所述氮源。[f8]根据[f5]至[f7]中任一项所述的方法,其中,以在所述反应液中成为0.01mm~100mm、优选成为0.1mm~10mm的浓度的方式添加所述还原剂。[f9]根据[f5]至[f8]中任一项所述的方法,其中,以在所述反应液中成为0.01ug/ml~1mg/ml、优选成为0.1ug/ml~100ug/ml的浓度的方式添加谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶。[f10]根据[f1]至[f19]中任一项所述的方法,其中,所述氮源为铵盐。[f11]根据[f1]至[f10]中任一项所述的方法,其中,所述氮源为选自由氯化铵、硫酸铵、碳酸铵所组成的群组中的至少一种铵盐。[f12]根据[f1]至[f11]中任一项所述的方法,其中,所述还原剂为选自由nadh及nadph所组成的群组中的至少一种。[f13]根据[f1]至[f12]中任一项所述的方法,其中,谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶是选自由谷氨酸脱氢酶、苯丙氨酸脱氢酶、亮氨酸脱氢酶及缬氨酸脱氢酶所组成的群组中的至少一种脱氢酶。[f14]根据[f1]至[f13]中任一项所述的方法,其中,谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶选自由以下所组成的群组中:、(d1)亮氨酸脱氢酶(leucinedehydrogenase),(d2)苯丙氨酸脱氢酶(phenylalaninedehydrogenase),及(d3)缬氨酸脱氢酶(valinedehydrogenase)。[f15]根据[f1]至[f14]中任一项所述的方法,其中,谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶为选自由以下所组成的群组中的脱氢酶:leudh蛋白质,优选为来源于球形赖氨酸芽孢杆菌的leudh蛋白质、来源于蜡样芽孢杆菌的leudh蛋白质或来源于嗜热脂肪地芽孢杆菌的leudh蛋白质;phedh蛋白质,优选为来源于栗褐芽孢杆菌的phedh蛋白质;及valdh蛋白质,优选为来源于费氏链霉菌的valdh蛋白质。[f16]根据[f1]至[f15]中任一项所述的方法,其中,谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶选自由以下所组成的群组中:(5'-1)包含序列号30中记载的氨基酸序列、且催化α-酮酸的还原氨基化反应的蛋白质,(5'-2)包含序列号30中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的还原氨基化反应的活性的蛋白质,(5'-3)包含序列号32中记载的氨基酸序列、且催化α-酮酸的还原氨基化反应的蛋白质,(5'-4)包含序列号32中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的还原氨基化反应的活性的蛋白质,(5'-5)包含序列号34中记载的氨基酸序列、且催化α-酮酸的还原氨基化反应的蛋白质,及(5'-6)包含序列号34中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的还原氨基化反应的活性的蛋白质。[g1]一种α-酮酸的制造方法,包括:使2-氨基-4-羟基羧酸以及氧化剂在谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶的存在下进行反应,以生产α-酮酸的工序,其中,所述2-氨基-4-羟基羧酸由下述通式(6)表示:r101c(r102)(oh)ch2ch(nh2)cooh(此处,r101及r102相互独立地为氢、或具有1个~5个碳原子的烷基),所述α-酮酸由下述通式(2)表示:r101c(r102)(oh)ch2cocooh(所述通式(2)中的r101及r102分别为与所述通式(6)中的r101及r102相同的基)。[g2]根据[g1]所述的方法,其中,所述通式(6)及通式(2)中,r102为氢。[g3]根据[g1]或[g2]所述的方法,其中,所述通式(6)及通式(2)中,r101及r102为氢。[g4]根据[g1]至[g3]中任一项所述的方法,其中,所述反应在包含由所述通式(6)表示的所述2-氨基-4-羟基羧酸、所述氧化剂以及谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶的反应液中进行。[g5]根据[g4]所述的方法,其中,所述反应液是添加了由所述通式(6)表示的所述2-氨基-4-羟基羧酸、所述氧化剂以及谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶的反应液。[g6]根据[g5]所述的方法,其中,以在所述反应液中成为0.1mm~1m、优选成为1mm~300mm的浓度的方式添加由所述通式(6)表示的所述2-氨基-4-羟基羧酸。[g7]根据[g5]或[g6]所述的方法,其中,以在所述反应液中成为0.01mm~100mm、优选成为0.1mm~10mm的浓度的方式添加所述氧化剂。[g8]根据[g5]至[g7]中任一项所述的方法,其中,以在所述反应液中成为0.01ug/ml~1mg/ml、优选成为0.1ug/ml~100ug/ml的浓度的方式添加谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶。[g9]根据[g1]至[g8]中任一项所述的方法,其中,所述氧化剂为选自由nad+及nadp+所组成的群组中的至少一种。[g10]根据[g1]至[g9]中任一项所述的方法,其中,谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶是选自由谷氨酸脱氢酶、苯丙氨酸脱氢酶、亮氨酸脱氢酶及缬氨酸脱氢酶所组成的群组中的至少一种脱氢酶。[g11]根据[g1]至[g10]中任一项所述的方法,其中,谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶选自由以下所组成的群组中:、(d1)亮氨酸脱氢酶(leucinedehydrogenase),(d2)苯丙氨酸脱氢酶(phenylalaninedehydrogenase),及(d3)缬氨酸脱氢酶(valinedehydrogenase)。[g12]根据[g1]至[g11]中任一项所述的方法,其中,谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶为选自由以下所组成的群组中的脱氢酶:leudh蛋白质,优选为来源于球形赖氨酸芽孢杆菌的leudh蛋白质、来源于蜡样芽孢杆菌的leudh蛋白质或来源于嗜热脂肪地芽孢杆菌的leudh蛋白质;phedh蛋白质,优选为来源于栗褐芽孢杆菌的phedh蛋白质;及valdh蛋白质,优选为来源于费氏链霉菌的valdh蛋白质。[g13]根据[g1]至[g12]中任一项所述的方法,其中,谷氨酸/苯丙氨酸/亮氨酸/缬氨酸脱氢酶选自由以下所组成的群组中:(5'-1)包含序列号30中记载的氨基酸序列、且催化α-酮酸的还原氨基化反应的蛋白质,(5'-2)包含序列号30中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的还原氨基化反应的活性的蛋白质,(5'-3)包含序列号32中记载的氨基酸序列、且催化α-酮酸的还原氨基化反应的蛋白质,(5'-4)包含序列号32中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的还原氨基化反应的活性的蛋白质,(5'-5)包含序列号34中记载的氨基酸序列、且催化α-酮酸的还原氨基化反应的蛋白质,及(5'-6)包含序列号34中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的还原氨基化反应的活性的蛋白质。[h1]一种棒状细菌,包含选自由以下所组成的群组中的第一基因:(1-1)对包含序列号2中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-2)对包含序列号2中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-3)对包含序列号4中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-4)对包含序列号4中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-5)对包含序列号6中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,及(1-6)对包含序列号6中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因。[h2]一种棒状细菌,包含选自由以下所组成的群组中的第一基因:(1-1)对包含序列号2中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-2)对包含序列号2中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-3)对包含序列号4中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-4)对包含序列号4中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-5)对包含序列号6中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-6)对包含序列号6中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因;(1-7)对包含序列号8中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-8)对包含序列号8中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-9)对包含序列号10中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-10)对包含序列号10中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-11)对包含序列号12中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-12)对包含序列号12中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-13)对包含序列号14中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-14)对包含序列号14中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-15)对包含序列号16中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-16)对包含序列号16中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-17)对包含序列号18中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-18)对包含序列号18中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-19)对包含序列号20中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,(1-20)对包含序列号20中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因,(1-21)对包含序列号22中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的蛋白质进行编码的基因,及(1-22)对包含序列号22中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化丙酮酸与羰基化合物的羟醛反应的活性的蛋白质进行编码的基因。[h3]根据[h1]或[h2]所述的棒状细菌,其中,对包含序列号2中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的所述蛋白质进行编码的所述基因是包含序列号1中记载的碱基序列的基因。[h4]根据[h1]至[h3]中任一项所述的棒状细菌,其中,对包含序列号4中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的所述蛋白质进行编码的所述基因是包含序列号3中记载的碱基序列的基因。[h5]根据[h1]至[h4]中任一项所述的棒状细菌,其中,对包含序列号6中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的所述蛋白质进行编码的所述基因是包含序列号5中记载的碱基序列的基因。[h6]根据[h1]至[h5]中任一项所述的棒状细菌,其中,对包含序列号8中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的所述蛋白质进行编码的所述基因是包含序列号7中记载的碱基序列的基因。[h7]根据[h1]至[h6]中任一项所述的棒状细菌,其中,对包含序列号10中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的所述蛋白质进行编码的所述基因是包含序列号9中记载的碱基序列的基因。[h8]根据[h1]至[h7]中任一项所述的棒状细菌,其中,对包含序列号12中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的所述蛋白质进行编码的所述基因是包含序列号11中记载的碱基序列的基因。[h9]根据[h1]至[h8]中任一项所述的棒状细菌,其中,对包含序列号14中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的所述蛋白质进行编码的所述基因是包含序列号13中记载的碱基序列的基因。[h10]根据[h1]至[h9]中任一项所述的棒状细菌,其中,对包含序列号16中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的所述蛋白质进行编码的所述基因是包含序列号15中记载的碱基序列的基因。[h11]根据[h1]至[h10]中任一项所述的棒状细菌,其中,对包含序列号18中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的所述蛋白质进行编码的所述基因是包含序列号17中记载的碱基序列的基因。[h12]根据[h1]至[h11]中任一项所述的棒状细菌,其中,对包含序列号20中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的所述蛋白质进行编码的所述基因是包含序列号19中记载的碱基序列的基因。[h13]根据[h1]至[h12]中任一项所述的棒状细菌,其中,对包含序列号22中记载的氨基酸序列、且催化丙酮酸与羰基化合物的羟醛反应的所述蛋白质进行编码的所述基因是包含序列号21中记载的碱基序列的基因。[h14]根据[h1]至[h13]中任一项所述的棒状细菌,其中,所述棒状细菌为棒状杆菌属(corynebacterium)菌,优选为谷氨酸棒状杆菌(corynebacteriumglutamicum),更优选为保藏编号为nitebp-02780、nitebp-02781、nitebp-02782、nitebp-02783或nitebp-02784的棒状细菌。[h15]根据[h1]至[h14]中任一项所述的方法,其中,所述棒状细菌是通过所述第一基因进行了转化的棒状细菌。[h16]根据[h1]至[h15]中任一项所述的棒状细菌,还包含选自由以下所组成的群组中的第二基因:(2-1)对包含序列号24中记载的氨基酸序列、且催化α-酮酸的脱羧反应的蛋白质进行编码的基因,及(2-2)对包含序列号24中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的脱羧反应的活性的蛋白质进行编码的基因;以及选自由以下所组成的群组中的第三基因:(3-1)对包含序列号26中记载的氨基酸序列、且催化醛的还原反应的蛋白质进行编码的基因,及(3-2)对包含序列号26中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化醛的还原反应的活性的蛋白质进行编码的基因。[h17]根据[h16]所述的棒状细菌,其中,对包含序列号24中记载的氨基酸序列、且催化α-酮酸的脱羧反应的所述蛋白质进行编码的所述基因是包含序列号23中记载的碱基序列的基因。[h18]根据[h16]或[h17]所述的棒状细菌,其中,对包含序列号26中记载的氨基酸序列、且催化醛的还原反应的所述蛋白质进行编码的所述基因是包含序列号25中记载的碱基序列的基因。[h19]根据[h16]至[h18]中任一项所述的棒状细菌,其中,所述棒状细菌为棒状杆菌属(corynebacterium)菌,优选为谷氨酸棒状杆菌(corynebacteriumglutamicum),更优选为保藏编号为nitebp-02780或nitebp-02781的棒状细菌。[h20]根据[h16]至[h19]中任一项所述的方法,其中,所述棒状细菌是通过所述第一基因、所述第二基因及所述第三基因进行了转化的棒状细菌。[h21]根据[h1]至[h20]中任一项所述的棒状细菌,还包含选自由以下所组成的群组中的第四基因:(4-1)对包含序列号28中记载的氨基酸序列、且催化α-酮酸的还原反应的蛋白质进行编码的基因,及(4-2)对包含序列号28中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的还原反应的活性的蛋白质进行编码的基因。[h21]根据[h20]所述的棒状细菌,其中,对包含序列号28中记载的氨基酸序列、且催化α-酮酸的还原反应的所述蛋白质进行编码的所述基因是包含序列号27中记载的碱基序列的基因。[h22]根据[h20]或[h21]所述的棒状细菌,其中,所述棒状细菌为棒状杆菌属(corynebacterium)菌,优选为谷氨酸棒状杆菌(corynebacteriumglutamicum),更优选为保藏编号为nitebp-02782的棒状细菌。[h23]根据[h20]至[h22]中任一项所述的方法,其中,所述棒状细菌是通过所述第一基因及所述第四基因进行了转化的棒状细菌。[h24]根据[h1]至[h23]中任一项所述的棒状细菌,还包含选自由以下所组成的群组中的第五基因:(5-1)对包含序列号30中记载的氨基酸序列、且催化α-酮酸的还原氨基化反应的蛋白质进行编码的基因,(5-2)对包含序列号30中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的还原氨基化反应的活性的蛋白质进行编码的基因,(5-3)对包含序列号32中记载的氨基酸序列、且催化α-酮酸的还原氨基化反应的蛋白质进行编码的基因,(5-4)对包含序列号32中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的还原氨基化反应的活性的蛋白质进行编码的基因,(5-5)对包含序列号34中记载的氨基酸序列、且催化α-酮酸的还原氨基化反应的蛋白质进行编码的基因,及(5-6)对包含序列号34中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的还原氨基化反应的活性的蛋白质进行编码的基因。[h25]根据[h24]所述的棒状细菌,其中,对包含序列号30中记载的氨基酸序列、且催化α-酮酸的还原氨基化反应的所述蛋白质进行编码的所述基因是包含序列号29中记载的碱基序列的基因。[h26]根据[h24]或[h25]所述的棒状细菌,其中,对包含序列号32中记载的氨基酸序列、且催化α-酮酸的还原氨基化反应的所述蛋白质进行编码的所述基因是包含序列号31中记载的碱基序列的基因。[h27]根据[h24]至[h26]中任一项所述的棒状细菌,其中,对包含序列号34中记载的氨基酸序列、且催化α-酮酸的还原氨基化反应的所述蛋白质进行编码的所述基因是包含序列号33中记载的碱基序列的基因。[h28]根据[h24]至[h27]中任一项所述的棒状细菌,其中,所述棒状细菌为棒状杆菌属(corynebacterium)菌,优选为谷氨酸棒状杆菌(corynebacteriumglutamicum),更优选为保藏编号为nitebp-02783的棒状细菌。[h29]根据[h24]至[h28]中任一项所述的方法,其中,所述棒状细菌是通过所述第一基因及所述第五基因进行了转化的棒状细菌。[h30]根据[h1]至[h29]中任一项所述的棒状细菌,还包含选自由以下所组成的群组中的第五基因:(5-1)对包含序列号30中记载的氨基酸序列、且催化α-酮酸的还原氨基化反应的蛋白质进行编码的基因,(5-2)对包含序列号30中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的还原氨基化反应的活性的蛋白质进行编码的基因,(5-3)对包含序列号32中记载的氨基酸序列、且催化α-酮酸的还原氨基化反应的蛋白质进行编码的基因,(5-4)对包含序列号32中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的还原氨基化反应的活性的蛋白质进行编码的基因,(5-5)对包含序列号34中记载的氨基酸序列、且催化α-酮酸的还原氨基化反应的蛋白质进行编码的基因,及(5-6)对包含序列号34中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化α-酮酸的还原氨基化反应的活性的蛋白质进行编码的基因;以及选自由以下所组成的群组中的第六基因:(6-1)对包含序列号36中记载的氨基酸序列、且催化由甲硫醇所具有的甲巯基取代2-氨基-4-膦酰氧基羧酸所具有的磷酸基的反应的蛋白质进行编码的基因,及(6-2)对包含序列号36中一个或多个氨基酸缺失、经取代或加成而成的氨基酸序列、且具有催化由甲硫醇所具有的甲巯基取代2-氨基-4-膦酰氧基羧酸所具有的磷酸基的反应的活性的蛋白质进行编码的基因。[h31]根据[h30]所述的棒状细菌,其中,对包含序列号30中记载的氨基酸序列、且催化α-酮酸的还原氨基化反应的所述蛋白质进行编码的所述基因是包含序列号29中记载的碱基序列的基因。[h32]根据[h30]或[h31]所述的棒状细菌,其中,对包含序列号32中记载的氨基酸序列、且催化α-酮酸的还原氨基化反应的所述蛋白质进行编码的所述基因是包含序列号31中记载的碱基序列的基因。[h33]根据[h30]至[h32]中任一项所述的棒状细菌,其中,对包含序列号34中记载的氨基酸序列、且催化α-酮酸的还原氨基化反应的所述蛋白质进行编码的所述基因是包含序列号33中记载的碱基序列的基因。[h34]根据[h30]至[h33]中任一项所述的棒状细菌,其中,对包含序列号36中记载的氨基酸序列、且催化由甲硫醇所具有的甲巯基取代2-氨基-4-膦酰氧基羧酸所具有的磷酸基的反应的所述蛋白质进行编码的所述基因是包含序列号35中记载的碱基序列的基因。[h35]根据[h30]至[h34]中任一项所述的棒状细菌,其中,所述棒状细菌为棒状杆菌属(corynebacterium)菌,优选为谷氨酸棒状杆菌(corynebacteriumglutamicum),更优选为保藏编号为nitebp-02784的棒状细菌。[h36]根据[h30]至[h35]中任一项所述的方法,其中,所述棒状细菌是通过所述第一基因及所述第五基因进行了转化的棒状细菌。[实施例]1.材料及方法(1-1)培养基若未特别指明,则试剂是自富士胶片和光纯药股份有限公司购入。(a培养基)将尿素2.0g、硫酸铵7.0g、磷酸二氢钾0.50g、磷酸氢二钾0.50g、硫酸镁七水合物0.50g、酵母膏(迪福科(difco)公司制造)2.0g、酪蛋白氨基酸(casaminoacid)维生素分析(vitaminassay)(迪福科(difco)公司制造)7.0g、硫酸铁(ii)七水合物6.0mg、硫酸锰(ii)一水合物4.2mg、d(+)-生物素0.20mg、盐酸硫胺素0.20mg溶解于0.92l的水中,使用5m氢氧化钾水溶液将ph调整为7.0。对其在121℃下进行20分钟高压釜灭菌,并在冷却至室温后,加入已完成高压釜灭菌的50%(w/v)葡萄糖水溶液80ml,由此制备的液体培养基。(a琼脂培养基)将尿素2.0g、硫酸铵7.0g、磷酸二氢钾0.50g、磷酸氢二钾0.50g、硫酸镁七水合物0.50g、酵母膏(迪福科(difco)公司制造)2.0g、酪蛋白氨基酸维生素分析(vitaminassay)(迪福科(difco)公司制造)7.0g、硫酸铁(ii)七水合物6.0mg、硫酸锰(ii)一水合物4.2mg、d(+)-生物素0.20mg、盐酸硫胺素0.20mg、琼脂15g溶解、悬浮于0.92l的水中,使用5m氢氧化钾水溶液将ph调整制备为7.0。对其在121℃下进行20分钟高压釜灭菌,并在冷却至50℃后,加入已完成高压釜灭菌的50%(w/v)葡萄糖水溶液80ml,分注至培养皿后进行冷却固化,由此制备的固体培养基。(ba培养基)将尿素2.0g、硫酸铵7.0g、磷酸二氢钾0.50g、磷酸氢二钾0.50g、硫酸镁七水合物0.50g、酵母膏(迪福科(difco)公司制造)2.0g、酪蛋白氨基酸维生素分析(vitaminassay)(迪福科(difco)公司制造)7.0g、硫酸铁(ii)七水合物6.0mg、硫酸锰(ii)一水合物4.2mg、d(+)-生物素0.20mg、盐酸硫胺素0.20mg、4-吗啉丙磺酸21g溶解于0.92l的水中,使用5m氢氧化钾水溶液将ph调整为7.0。对其在121℃下进行20分钟高压釜灭菌,冷却至室温后,加入已完成高压釜灭菌的50%(w/v)葡萄糖水溶液80ml,由此制备的液体培养基。(lb培养基)将细菌用胰胨(bacto-tryptone)(迪福科(difco)公司制造)10g、酵母膏(迪福科(difco)公司制造)5.0g、氯化钠10g溶解于1l的水中,使用5m氢氧化钠水溶液将ph调整为7.0后,在121℃下进行20分钟高压釜灭菌,由此制备的液体培养基。(lb琼脂培养基)将细菌用胰胨(迪福科(difco)公司制造)10g、酵母膏(迪福科(difco)公司制造)5.0g、氯化钠10g、琼脂15g溶解、悬浮于1l的水中,使用5m氢氧化钠水溶液将ph调整为7.0后,在121℃下进行20分钟高压釜灭菌,冷却至50℃后,分注至培养皿并进行冷却固化,由此制备的固体培养基。(suc琼脂培养基)将细菌用胰胨(迪福科(difco)公司制造)10g、酵母膏(迪福科(difco)公司制造)5.0g、氯化钠10g、琼脂15g溶解、悬浮于0.5l的水中,使用5m氢氧化钠水溶液将ph调整为7.0。对其在121℃下进行20分钟高压釜灭菌,冷却至50℃后,加入已完成高压釜灭菌的20%(w/v)的蔗糖水溶液0.5l,分注至培养皿后进行冷却固化,由此制备的固体培养基。(bhis培养基)将脑心浸液(brainheartinfusion)(迪福科(difco)公司制造)36g、山梨糖醇91g溶解于1l的水中,使用5m氢氧化钠水溶液将ph调整为7.0后,在121℃下进行20分钟高压釜灭菌,由此制备的液体培养基。(bhis-git培养基)将脑心浸液(迪福科(difco)公司制造)36g、甘氨酸8.0g、异烟肼(isoniazide)1.3g、吐温(tween)803ml、山梨糖醇91g溶解于1l的水中,使用5m氢氧化钠水溶液将ph调整为7.0后,在121℃下进行20分钟高压釜灭菌,由此制备的液体培养基。(1-2)缓冲液及试剂(te缓冲液)将三羟甲基氨基甲烷1.2g、乙二胺-n,n,n',n'-四乙酸二钠盐二水合物0.37g溶解于1l的水中,使用6m盐酸将ph调整为8.0后,在121℃下进行20分钟高压釜灭菌,由此制备的缓冲液。(tg缓冲液)将三羟甲基氨基甲烷0.12g、甘油10g溶解于1l的水中,使用6m盐酸将ph调整为7.5后,在121℃下进行20分钟高压釜灭菌,由此制备的缓冲液。(10%甘油水溶液)将甘油100g溶解于1l的水中后,在121℃下进行20分钟高压釜灭菌,由此调整的水溶液。(br缓冲液)将磷酸二氢钾0.50g、磷酸氢二钾0.50g、硫酸镁七水合物0.50g、硫酸铁(ii)七水合物6.0mg、硫酸锰(ii)一水合物4.2mg溶解于1.0l的水中,使用5m氢氧化钾水溶液将ph调整为7.0,由此获得的缓冲液。(bs缓冲液)将磷酸二氢钾0.50g、磷酸氢二钾0.50g、硫酸镁七水合物0.50g、硫酸铁(ii)七水合物6.0mg、硫酸锰(ii)一水合物4.2mg、4-吗啉丙磺酸21g溶解于1.0l的水中,使用5m氢氧化钾水溶液将ph调整为7.0,由此获得的缓冲液。(bt缓冲液)将硫酸铵7.0g、磷酸二氢钾0.50g、磷酸氢二钾0.50g、硫酸镁七水合物0.50g、硫酸铁(ii)七水合物6.0mg、硫酸锰(ii)一水合物4.2mg溶解于1.0l的水中,使用5m氢氧化钾水溶液将ph调整为7.0,由此获得的缓冲液。(1-3)分析条件的定义及实验方法(琼脂糖凝胶电泳(agarosegelelectrophoresis)后的dna片段的提取、纯化)将牛克劳斯宾(nucleospin)(注册商标)凝胶与pcr清除(gelandpcrclean-up)(马歇雷纳高(macherey-nagel)公司制造)按照其使用说明书加以使用,来进行dna片段的提取、纯化。(质粒提取)将牛克劳斯宾(nucleospin)(注册商标)质粒易净(plasmideasypure)(马歇雷纳高(macherey-nagel)公司制造)按照其使用说明书加以使用,来进行质粒的提取、纯化。(pcr法)使用以下任一种dna聚合酶及其附属的试剂,依照其使用说明书进行pcr:原恒星(primestar)(注册商标)hsdna聚合酶(hsdnapolymerase)(宝生物(takarabio)公司制造)、原恒星(primestar)(注册商标)maxdna聚合酶(maxdnapolymerase)(宝生物(takarabio)公司制造)、tks吉福乐斯tmdna聚合酶(tksgflextmdnapolymerase)(宝生物(takarabio)公司制造)。(有机酸分析用液相色谱)使用包括岛津制作所制造的以下设备的有机酸分析系统。系统控制器:cbm-20a;送液单元:lc-20ab;在线脱气单元:dgu-20a3r;自动注射器(autoinjector):sil-20ac;柱温箱(columnoven):cto-20ac;光电二极管阵列检测器:spd-m20a。分析条件如下。保护柱:tskgeloapak-p(东曹公司制造)分析柱:tskgeloapak-a(东曹公司制造)柱温箱温度:40℃流动相:0.75mm硫酸流速:1.0ml/min。(糖分析用液相色谱)使用包括岛津制作所制造的以下设备的糖分析系统。系统控制器:cbm-20a;送液单元:lc-20ab;在线脱气单元:dgu-20a3r;自动注射器:sil-20ac;柱温箱:cto-20ac;折射率检测器:rid-10a。分析条件如下。预处理:脱盐筒(cartridge)(伯乐(bio-rad)公司制造)分析柱:阿米内科斯(aminex)hpx-87p(伯乐(bio-rad)公司制造)柱温箱温度:85℃流动相:水流速:0.6ml/min。(氨基酸分析用液相色谱)使用包括岛津制作所制造的以下设备的的氨基酸分析系统。系统控制器:cbm-20a;送液单元:一台lc-20ab、两台lc-20ad;流路切换阀:fcv-11al;在线脱气单元:dgu-20a3r;自动注射器:sil-20ac;柱温箱:cto-20ac;荧光检测器:rf-20axs。分析条件按照岛津高效液相色谱仪卓越(prominence)氨基酸分析系统操作说明书中所示的na型快速条件,使用氨捕集柱(ammoniatrapcolumn)isc-30/s0504na(岛津制作所制造)及分析柱西姆派克氨基-na(shim-packamino-na)(岛津制作所制造)进行分析。(气相色谱仪质谱(气相色谱质谱(gaschromatographymassspectrometry,gcms)))gcms使用气相色谱仪四极型质谱计(7890bgc/5977amsd,安捷伦科技(agilenttechnologies)公司制造)及多功能自动进样器(autosampler)(mps2-xt,哲斯泰(gerstel)公司制造),在以下条件下进行。<热解吸采样条件>加热条件:50℃(0.5min)→50℃/min→300℃(10min)捕获温度:-100℃→12℃/s→300℃<气相色谱仪条件>分离柱:db-5ht[30m×0.25mmid,0.10μm,安捷伦科技(agilenttechnologies)公司制造]升温条件度:40℃(5min)→10℃/min→320℃(12min)<质谱条件>电离法:电子电离(electronionization,ei)测定质量范围:m/z=29-550(基因组(genome)dna提取)将按照提供方的使用说明书进行了液体培养的微生物通过离心分离予以回收,并在-80℃下冻结。将菌体颗粒在室温下解冻,加入10mg/ml溶菌酶水溶液537μl,在37℃下振荡1小时。接着加入0.5m乙二胺四乙酸(ethylenediaminetetraaceticacid,edta)水溶液30μl、10%十二烷基硫酸钠(sodiumdodecylsulfate,sds)水溶液30μl、20mg/ml蛋白酶(proteinase)k水溶液3μl,在37℃下振荡1小时。然后进一步加入5m氯化钠水溶液100μl与10%溴化十六烷基三甲基铵水溶液(0.7m氯化钠中)80μl,在65℃下加热10分钟。冷却至室温后,加入氯仿-异戊醇(24:1)780μl,并加以平稳混合。在15000xg、4℃下进行5分钟离心分离,回收水层600μl。向其中加入苯酚-氯仿-异戊醇(25:24:1)600μl,并加以平稳混合。在15000xg、4℃下进行5分钟离心分离,回收水层500μl。向其中加入异丙醇300μl,在15000xg、4℃下进行5分钟离心分离后,去除上清液。加入70%乙醇500μl来清洗作为沉淀物而获得的基因组dna,并在15000xg、4℃下进行5分钟离心分离。将所述清洗重复进行两次,在室温下加以干燥后,将所获得的基因组dna溶解于te缓冲液100μl中。(用于转化谷氨酸棒状杆菌atcc13032来源株的电穿孔法)在无菌条件下,在a琼脂培养基中接种将要进行转化的谷氨酸棒状杆菌atcc13032来源株的甘油原种(glycerolstock),在33℃下进行培养。将琼脂培养基上生长出的菌体接种到10ml的a培养基中,在33℃下进行振荡培养,制成种子培养液。将所述种子培养液以浊度成为0.2的方式接种到500ml烧瓶中所准备的100ml的牛心浸液补充剂(beefheartinfusionsupplement,bhis)培养基中。在33℃下进行振荡,培养至浊度成为0.5-0.7为止。对所述培养液在4℃、5500xg下进行20分钟离心分离,去除上清液。利用10ml的tg缓冲液来清洗所回收的菌体,在4℃、5500xg下进行5分钟离心分离,去除上清液。进行两次所述清洗后,利用10ml的10%甘油水溶液进行清洗,在4℃、5500xg下进行5分钟离心分离,去除上清液。使所获得的菌体颗粒悬浮于1ml的10%甘油水溶液中,并分注到已完成灭菌的1.5ml管中各150μl后,使用液氮进行冻结,并作为感受态细胞(competentcell)而保存于-80℃下。基因组dna上的基因缺失及基因取代的情况:在冰上融解150μl的感受态细胞,并加入500ng的质粒。将其移至已完成灭菌的0.2cm间距电穿孔杯(electroporationcuvettes)(伯乐(bio-rad)公司制造)中,使用基因脉冲器x单元tm(genepulserxcelltm)电穿孔系统(伯乐(bio-rad)公司制造),在25μf、200ω、2500v下进行电穿孔。利用1ml的bhis培养基来稀释菌体悬浮液,并在46℃下孵化6分钟后,在33℃下进行1小时孵化。将所述菌体悬浮液接种到包含适当的抗生素的a琼脂培养基中,并选择目标转化体。导入基因超表达用质粒的情况:在冰上融解50μl的感受态细胞,并加入200ng的质粒。将其移至已完成灭菌的0.2cm间距电穿孔杯(伯乐(bio-rad)公司制造)中,使用基因脉冲器x单元tm(genepulserxcelltm)电穿孔系统(伯乐(bio-rad)公司制造),在25μf、200ω、2500v下进行电穿孔。利用1ml的bhis培养基来稀释菌体悬浮液,并在46℃下孵化6分钟后,在33℃下进行1小时孵化。将所述菌体悬浮液接种到包含适当的抗生素的a琼脂培养基中,并选择目标转化体。(菌落(colony)pcr)使用可扩增目标dna序列的引物的组合,按照takaraextaq(注册商标)(宝生物(takarabio)公司制造)的使用说明书将模板dna以外的试剂混合。在其中少量悬浮琼脂培养基中所产生的菌株的菌落,将其固有的dna作为模板,按照使用说明书进行pcr。对pcr产物利用琼脂糖凝胶电泳进行分析,确认到保持了目标质粒、或基因组上相应的dna序列已缺失或经取代。(浊度测定)大肠杆菌及谷氨酸棒状杆菌的培养液的浊度是使用乌特罗斯派克(ultrospec)8000(ge保健(gehealthcare)公司制造)在610nm的波长下进行测定。(1-4)引物dna、菌体及质粒的详情引物dna、菌体及质粒的详情记载于以下的表37~表67中。[表37][表38]表38[表39][表40][表41][表42][表43][表44][表45][表46][表47][表48][表49][表50][表51][表52][表53][表54][表55][表56][表57][表58]表58[表59][表60][表61][表62][表63][表64][表65][表66][表67]表67株id宿主株质粒ges1007bl21(de3)pge11485ges1057bl21(de3)pge1175ges1136bl21(de3)pge12372.质粒构建(2-1)基因缺失篇2-1-(1)基因破坏用质粒的构建以pnic28-bsa4(源生物科学(sourcebioscience)公司制造)为模板,使用由gep007(序列号37)与gep008(序列号38)所表示的碱基序列的dna,通过pcr法对包含来源于枯草芽孢杆菌(bacillussubtilis)的sacb基因的dna片段[分子微生物学(molecularmicrobiology,mol.microbiol.),6,1195(1992)]进行扩增。利用bamhi及psti对所述pcr产物进行处理,并在进行琼脂糖凝胶电泳后进行dna片段的提取、纯化。另外,利用bamhi及psti对具有赋予相对于卡那霉素(kanamycin)的抗性的基因的质粒phsg299(宝生物(takarabio)公司制造)进行处理,并在进行琼脂糖凝胶电泳后进行dna片段的提取、纯化。将dna连接试剂盒(dnaligationkit)<强混合(mightymix)>(宝生物(takarabio)公司制造)按照其使用说明书加以使用,来将所述两个dna片段连结,获得质粒pge015。出于pge015将sacb上所具有的kpni识别部位删除的目的,以pge015为模型,使用由gep808(序列号39)及gep809(序列号40)所表示的碱基序列的dna,将原恒星(primestar)(注册商标)突变形成基底试剂盒(mutagenesisbasalkit)(宝生物(takarabio)公司制造)按照其使用说明书加以使用,来进行突变导入及质粒的扩增,获得pge209。2-1-(2)ppc基因破坏株制作用质粒的构建谷氨酸棒状杆菌atcc13032株是作为nbrc12168株而自独立行政法人制品评价技术基盘机构生物技术中心获取,并在按照随附的使用说明书进行培养后,进行了基因组dna提取。以atcc13032株的基因组dna为模板,使用由gep132(序列号41)与gep133(序列号42)所表示的碱基序列的dna的组合、及由gep134(序列号43)与gep135(序列号44)所表示的碱基序列的dna的组合,通过pcr法获得两种pcr产物,对所述两种pcr产物在进行琼脂糖凝胶电泳后进行提取、纯化。进而,利用ecori对pge015进行处理,并对其在进行琼脂糖凝胶电泳后进行提取、纯化。将所述三个dna片段混合,并将因福森(in-fusion)(注册商标)hd克隆试剂盒(hdcloningkit)按照其使用说明书加以使用,来进行dna片段的结合反应。使用反应产物,对大肠杆菌dh5α感受态细胞(e.colidh5αcompetentcells)(宝生物(takarabio)公司制造)按照其使用说明书进行转化。目标转化株是通过在包含50μg/ml的卡那霉素的lb琼脂培养基上进行培养来选择。在包含50μg/ml的卡那霉素的lb培养基中对所述转化株进行培养,使用所获得的培养悬浮液进行质粒提取。将如此般获得的质粒设为pge020。2-1-(3)ppc基因缺失株的制作使用pge020,通过电穿孔法对谷氨酸棒状杆菌atcc13032株进行转化,在33℃下在包含25μg/ml的卡那霉素的a培养基上选择了卡那霉素抗性株。接着,将所获得的卡那霉素抗性株涂布于suc琼脂培养基上,在33℃下进行培养。对生长出的菌落进一步在a培养基中进行培养,并选择通过菌落pcr而ppc基因已缺失的株。将其命名为ges007。2-1-(4)ldha基因破坏株制作用质粒的构建以atcc13032株的基因组dna为模板,使用由gep169(序列号45)与gep170(序列号46)所表示的碱基序列的dna的组合、及由gep215(序列号47)与gep216(序列号48)所表示的碱基序列的dna的组合,通过pcr法获得两种pcr产物,对所述两种pcr产物在进行琼脂糖凝胶电泳后进行提取、纯化。进而,利用ecori对pge015进行处理,并对其在进行琼脂糖凝胶电泳后进行提取、纯化。将所述三个dna片段混合,并进行与制作pge020时相同的操作,将由此获得的质粒设为pge033。2-1-(5)ldha基因缺失株的制作使用pge033,通过电穿孔法对ges007进行转化,并进行与制作ges007时相同的操作,将由此选择的株命名为ges048。2-1-(6)pyc基因破坏株制作用质粒的构建以atcc13032株的基因组dna为模板,使用由gep615(序列号49)与gep616(序列号50)所表示的碱基序列的dna的组合、及由gep617(序列号51)与gep618(序列号52)所表示的碱基序列的dna的组合,通过pcr法获得两种pcr产物,对所述两种pcr产物在进行琼脂糖凝胶电泳后进行提取、纯化。进而,利用ecori对pge015进行处理,并对其在进行琼脂糖凝胶电泳后进行提取、纯化。将所述三个dna片段混合,并进行与制作pge020时相同的操作,将由此获得的质粒设为pge177。2-1-(7)pyc基因缺失株的制作使用pge177,通过电穿孔法对ges048进行转化,并进行与制作ges007时相同的操作,将由此选择的株命名为ges385。2-1-(8)poxb基因破坏株制作用质粒的构建以atcc13032株的基因组dna为模板,使用由gep406(序列号53)与gep407(序列号54)所表示的碱基序列的dna的组合、及由gep698(序列号55)与gep409(序列号56)所表示的碱基序列的dna的组合,通过pcr法获得两种pcr产物,对所述两种pcr产物在进行琼脂糖凝胶电泳后进行提取、纯化。进而,利用ecori对pge015进行处理,并对其在进行琼脂糖凝胶电泳后进行提取、纯化。将所述三个dna片段混合,并进行与制作pge020时相同的操作,将由此获得的质粒设为pge191。2-1-(9)poxb基因缺失株的制作使用pge191,通过电穿孔法对ges385进行转化,并进行与制作ges007时相同的操作,将由此选择的株命名为ges388。2-1-(10)alaa基因破坏株制作用质粒的构建以atcc13032株的基因组dna为模板,使用由gep810(序列号57)与gep811(序列号58)所表示的碱基序列的dna的组合、及由gep812(序列号59)与gep813(序列号60)所表示的碱基序列的dna的组合,通过pcr法获得两种pcr产物,对所述两种pcr产物在进行琼脂糖凝胶电泳后进行提取、纯化。进而,利用ecori对pge015进行处理,并对其在进行琼脂糖凝胶电泳后进行提取、纯化。将所述三个dna片段混合,并进行与制作pge020时相同的操作,将由此获得的质粒设为pge210。2-1-(11)alaa基因缺失株的制作使用pge210,通过电穿孔法对ges388进行转化,并进行与制作ges007时相同的操作,将由此选择的株命名为ges393。2-1-(12)ilvb基因破坏株制作用质粒的构建以atcc13032株的基因组dna为模板,使用由gep956(序列号61)与gep957(序列号62)所表示的碱基序列的dna的组合、及由gep958(序列号63)与gep959(序列号64)所表示的碱基序列的dna的组合,通过pcr法获得两种pcr产物,对所述两种pcr产物在进行琼脂糖凝胶电泳后进行提取、纯化。进而,利用ecori对pge015进行处理,并对其在进行琼脂糖凝胶电泳后进行提取、纯化。将所述三个dna片段混合,并进行与制作pge020时相同的操作,将由此获得的质粒设为pge228。2-1-(13)ilvb基因缺失株的制作使用pge228,通过电穿孔法对ges393进行转化,并进行与制作ges007时相同的操作,将由此选择的株命名为ges405。2-1-(14)cg0931基因破坏株制作用质粒的构建以atcc13032株的基因组dna为模板,使用由gep1132(序列号65)与gep1133(序列号66)所表示的碱基序列的dna的组合、及由gep1134(序列号67)与gep1135(序列号68)所表示的碱基序列的dna的组合,通过pcr法获得两种pcr产物,对所述两种pcr产物在进行琼脂糖凝胶电泳后进行提取、纯化。进而,利用ecori对pge015进行处理,并对其在进行琼脂糖凝胶电泳后进行提取、纯化。将所述三个dna片段混合,并进行与制作pge020时相同的操作,将由此获得的质粒设为pge253。2-1-(15)cg0931基因缺失株的制作使用pge253,通过电穿孔法对ges405进行转化,并进行与制作ges007时相同的操作,将由此选择的株命名为ges435。2-1-(16)adhe基因破坏株制作用质粒的构建以atcc13032株的基因组dna为模板,使用由gep2606(序列号69)与gep2607(序列号70)所表示的碱基序列的dna的组合、及由gep2608(序列号71)与gep2609(序列号72)所表示的碱基序列的dna的组合,通过pcr法获得两种pcr产物,对所述两种pcr产物在进行琼脂糖凝胶电泳后进行提取、纯化。进而,利用kpni与bamhi对pge209进行处理,并对其在进行琼脂糖凝胶电泳后进行提取、纯化。将所述三个dna片段混合,并进行与制作pge020时相同的操作,将由此获得的质粒设为pge1171。以atcc13032株的基因组dna为模板,使用由gep2688(序列号73)与gep2607(序列号70)所表示的碱基序列的dna的组合、及由gep2608(序列号71)与gep2689(序列号74)所表示的碱基序列的dna的组合,通过pcr法获得两种pcr产物,对所述两种pcr产物在进行琼脂糖凝胶电泳后进行提取、纯化。进而,利用kpni与bamhi对pge209进行处理,并对其在进行琼脂糖凝胶电泳后进行提取、纯化。将所述三个dna片段混合,并进行与制作pge020时相同的操作,将由此获得的质粒设为pge1218。2-1-(17)adhe基因缺失株的制作使用pge1171,通过电穿孔法对ges048进行转化,并进行与制作ges007时相同的操作,将由此选择的株命名为ges1041。使用pge1171,通过电穿孔法对ges435进行转化,并进行与制作ges007时相同的操作,将由此选择的株命名为ges1042。2-1-(18)ald基因破坏株制作用质粒的构建以atcc13032株的基因组dna为模板,使用由gep2610(序列号75)与gep2611(序列号76)所表示的碱基序列的dna的组合、及由gep2612(序列号77)与gep2613(序列号78)所表示的碱基序列的dna的组合,通过pcr法获得两种pcr产物,对所述两种pcr产物在进行琼脂糖凝胶电泳后进行提取、纯化。进而,利用kpni与bamhi对pge209进行处理,并对其在进行琼脂糖凝胶电泳后进行提取、纯化。将所述三个dna片段混合,并进行与制作pge020时相同的操作,将由此获得的质粒设为pge1172。以atcc13032株的基因组dna为模板,使用由gep2692(序列号79)与gep2611(序列号76)所表示的碱基序列的dna的组合、及由gep2612(序列号77)与gep2693(序列号80)所表示的碱基序列的dna的组合,通过pcr法获得两种pcr产物,对所述两种pcr产物在进行琼脂糖凝胶电泳后进行提取、纯化。进而,利用kpni与bamhi对pge209进行处理,并对其在进行琼脂糖凝胶电泳后进行提取、纯化。将所述三个dna片段混合,并进行与制作pge020时相同的操作,将由此获得的质粒设为pge1221。2-1-(19)ald基因缺失株的制作使用pge1172,通过电穿孔法对ges1041进行转化,并进行与制作ges007时相同的操作,将由此选择的株命名为ges1070。使用pge1172,通过电穿孔法对ges1042进行转化,并进行与制作ges007时相同的操作,将由此选择的株命名为ges1211。(2-2)基因取代篇2-2-(1)pge409的构建以phsg298(宝生物(takarabio)公司制造)为模板,使用由gep433(序列号81)与gep434(序列号82)所表示的碱基序列的dna的组合、及由gep437(序列号83)与gep438(序列号84)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在进行琼脂糖凝胶电泳后进行提取、纯化。它们分别是包含卡那霉素抗性基因及大肠杆菌用复制起点pucori的dna片段。自独立行政法人制品评价技术基盘机构生物技术中心获取谷氨酸棒状杆菌nbrc12169株,按照随附的使用说明书进行培养,并通过离心分离回收菌体。利用1ml的10mm环己二胺四乙酸(cyclohexylenedinitrilotetraaceticacid)、25mmtris-hcl(ph8.0)缓冲液来清洗菌体颗粒,在6,000xg、4℃下进行5分钟离心分离,并再次进行回收。使菌体颗粒悬浮于包含15mg/ml溶菌酶的300μl的缓冲液a1(buffera1)(附属于马歇雷纳高(macherey-nagel)公司制造的牛克劳斯宾(nucleospin)(注册商标)质粒易净(plasmideasypure))中,在37℃下振荡2小时。然后,依照牛克劳斯宾(nucleospin)(注册商标)质粒易净(plasmideasypure)的使用说明书,进行pcg1质粒的提取及纯化。以此为模板,使用由gep445(序列号85)与gep446(序列号86)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在进行琼脂糖凝胶电泳后进行提取、纯化。其为包含棒状杆菌用复制起点pcg1ori的dna片段。将以上三个dna片段混合,并将因福森(in-fusion)(注册商标)hd克隆试剂盒(hdcloningkit)按照其使用说明书加以使用,来进行dna片段的结合反应。使用反应产物,对大肠杆菌dh5α感受态细胞(e.colidh5αcompetentcells)(宝生物(takarabio)公司制造)按照其使用说明书进行转化。目标转化株是通过在包含50μg/ml的卡那霉素的lb琼脂培养基上进行培养来选择。在包含50μg/ml的卡那霉素的lb培养基中对所述转化株进行培养,使用所获得的培养悬浮液进行质粒提取。将如此般获得的质粒设为pge403。以atcc13032株的基因组dna为模板,使用由gep472(序列号87)与gep478(序列号88)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在进行琼脂糖凝胶电泳后进行提取、纯化。另外,以pflag-ctc(西格玛奥德里奇(sigmaaldrich)公司制造)为模板,使用由gep467(序列号89)与gep468(序列号90)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在进行琼脂糖凝胶电泳后进行提取、纯化。它们分别是包含atcc13032株的gapa启动子(promoter)(pgapa)及大肠杆菌核糖体核糖核酸(ribonucleicacid,rna)转录终止子(terminator)(trrnb)的dna片段。进而,利用bamhi与ecorv对pge403进行处理,并对其在进行琼脂糖凝胶电泳后进行提取、纯化。将所述三个dna片段混合,并将因福森(in-fusion)(注册商标)hd克隆试剂盒(hdcloningkit)按照其使用说明书加以使用,来进行dna片段的结合反应。使用反应产物,对大肠杆菌dh5α感受态细胞(e.colidh5αcompetentcells)(宝生物(takarabio)公司制造)按照其使用说明书进行转化。目标转化株是通过在包含50μg/ml的卡那霉素的lb琼脂培养基上进行培养来选择。在包含50μg/ml的卡那霉素的lb培养基中对所述转化株进行培养,使用所获得的培养悬浮液进行质粒提取。将如此般获得的质粒设为pge409。2-2-(2)pge1185(δadhe::hpai取代株制作用质粒)的构建购买ecostm感受态大肠杆菌(competente.coli)bl21(de3)(日本基因(nippongene)公司制造),将其在无菌条件下接种到lb琼脂培养基中,并在37℃下进行培养。将琼脂培养基上生长出的菌体接种到10ml的lb培养基中,回收生长出的菌体,并进行基因组dna提取。以bl21(de3)株的基因组dna为模板,使用由gep2268(序列号91)与gep2269(序列号92)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在进行琼脂糖凝胶电泳后进行提取、纯化。其为包含大肠杆菌bl21(de3)株hpai基因(ec_hpai)的dna片段。进而,利用ndei对pet-15b(安诺伦(novagen)公司制造)进行处理,并对其在进行琼脂糖凝胶电泳后进行提取、纯化。将所述两个dna片段混合,并将因福森(in-fusion)(注册商标)hd克隆试剂盒(hdcloningkit)按照其使用说明书加以使用,来进行dna片段的结合反应。使用反应产物,对大肠杆菌dh5α感受态细胞(e.colidh5αcompetentcells)(宝生物(takarabio)公司制造)按照其使用说明书进行转化。目标转化株是通过在包含100μg/ml的氨苄青霉素(ampicillin)的lb琼脂培养基上进行培养来选择。在包含100μg/ml的氨苄青霉素的lb培养基中对所述转化株进行培养,使用所获得的培养悬浮液进行质粒提取。如此般获得了ec_hpai被克隆到pet-15b的质粒pge1031。以pge1031为模板,使用由gep2519(序列号93)与gep2518(序列号94)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在进行琼脂糖凝胶电泳后进行提取、纯化。进而,利用ndei与bamhi对pge409进行处理,并对其在进行琼脂糖凝胶电泳后进行提取、纯化。将所述两个dna片段混合,并将因福森(in-fusion)(注册商标)hd克隆试剂盒(hdcloningkit)按照其使用说明书加以使用,来进行dna片段的结合反应。使用反应产物,对大肠杆菌dh5α感受态细胞(e.colidh5αcompetentcells)(宝生物(takarabio)公司制造)按照其使用说明书进行转化。目标转化株是通过在包含50μg/ml的卡那霉素的lb琼脂培养基上进行培养来选择。在包含50μg/ml的卡那霉素的lb培养基中对所述转化株进行培养,使用所获得的培养悬浮液进行质粒提取。如此般获得了ec_hpai被亚克隆到pge409的质粒pge1143。以pge1143为模板,使用由gep2637(序列号95)与gep2638(序列号96)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在进行琼脂糖凝胶电泳后进行提取、纯化。其为包含pgapa-hpai-trrnb的dna片段。进而,利用xhoi对pge1171进行处理,并对其在进行琼脂糖凝胶电泳后进行提取、纯化。将所述两个dna片段混合,并将因福森(in-fusion)(注册商标)hd克隆试剂盒(hdcloningkit)按照其使用说明书加以使用,来进行dna片段的结合反应。使用反应产物,对大肠杆菌dh5α感受态细胞(e.colidh5αcompetentcells)(宝生物(takarabio)公司制造)按照其使用说明书进行转化。目标转化株是通过在包含50μg/ml的卡那霉素的lb琼脂培养基上进行培养来选择。在包含50μg/ml的卡那霉素的lb培养基中对所述转化株进行培养,使用所获得的培养悬浮液进行质粒提取。将如此般获得的质粒设为pge1185。2-2-(3)pge1186(δald::hpai取代株制作用质粒)的构建以pge1143为模板,使用由gep2639(序列号97)与gep2640(序列号98)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在进行琼脂糖凝胶电泳后进行提取、纯化。其为包含pgapa-hpai-trrnb的dna片段。进而,利用xhoi对pge1172进行处理,并对其在进行琼脂糖凝胶电泳后进行提取、纯化。将所述两个dna片段混合,并进行与制作pge1185时相同的操作,将由此获得的质粒设为pge1186。2-2-(4)δadhe::hpaiδald::hpai取代株的制作使用pge1186,通过电穿孔法对ges1041进行转化,在33℃下在包含25μg/ml的卡那霉素的a培养基上选择了卡那霉素抗性株。接着,将所获得的卡那霉素抗性株涂布于suc琼脂培养基上,在33℃下进行培养。对生长出的菌落进一步在a培养基中进行培养,并选择通过菌落pcr而ald基因对pgapa-hpai-trrnb进行了取代的株。将其命名为ges1052。进而,使用pge1185,通过电穿孔法对ges1052进行转化,并进行与制作ges1052时相同的操作,由此选择在adhe基因的位置插入有pgapa-hpai-trrnb的株。将其命名为ges1063。使用pge1186,通过电穿孔法对ges1042进行转化,并进行与制作ges1052时相同的操作,由此选择ald基因对pgapa-hpai-trrnb进行了取代的株。将其命名为ges1053。使用pge1185,通过电穿孔法对ges1053进行转化,并进行与制作ges1052时相同的操作,由此选择在adhe基因的位置插入有pgapa-hpai-trrnb的株。将其命名为ges1064。2-2-(5)pge1304(δadhe::rhma取代株制作用质粒)的构建购买大肠杆菌dh5α感受态细胞(e.colidh5αcompetentcells)(宝生物(takarabio)公司制造),将其在无菌条件下接种到lb琼脂培养基中,在37℃下进行培养。将琼脂培养基上生长出的菌体接种到10ml的lb培养基中,回收生长出的菌体,并进行基因组dna提取。以dh5α株的基因组dna为模板,使用由gep2765(序列号99)与gep2766(序列号100)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在进行琼脂糖凝胶电泳后进行提取、纯化。其为包含大肠杆菌dh5α株rhma基因(ec_rhma)的dna片段。进而,利用ndei与bamhi对pge409进行处理,并对其在进行琼脂糖凝胶电泳后进行提取、纯化。将所述两个dna片段混合,并进行与制作ge1143时相同的操作,由此获得ec_rhma被克隆到pge409的质粒pge1258。以pge1258为模板,使用由gep2637(序列号95)与gep2638(序列号96)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在进行琼脂糖凝胶电泳后进行提取、纯化。其为包含pgapa-rhma-trrnb的dna片段。进而,利用xhoi对pge1218进行处理,并对其在进行琼脂糖凝胶电泳后进行提取、纯化。将所述两个dna片段混合,并进行与制作pge1185时相同的操作,将由此获得的质粒设为pge1304。2-2-(6)pge1302(δald::rhma取代株制作用质粒)的构建以pge1258为模板,使用由gep2639(序列号97)与gep2640(序列号98)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在进行琼脂糖凝胶电泳后进行提取、纯化。进而,利用xhoi对pge1221进行处理,并对其在进行琼脂糖凝胶电泳后进行提取、纯化。其为包含pgapa-rhma-trrnb的dna片段。将所述两个dna片段混合,并进行与制作pge1185时相同的操作,将由此获得的质粒设为pge1302。2-2-(7)δadhe::rhmaδald::rhma取代株的制作使用pge1302,通过电穿孔法对ges1041进行转化,并进行与制作ges1052时相同的操作,由此选择ald基因对pgapa-rhma-trrnb进行了取代的株。将其命名为ges1215。进而,使用pge1304,通过电穿孔法对ges1215进行转化,并进行与制作ges1052时相同的操作,由此选择在adhe基因的位置插入有pgapa-rhma-trrnb的株。将其命名为ges1242。2-2-(8)pge1272(δadhe::nana取代株制作用质粒)的构建购买大肠杆菌dh5α感受态细胞(e.colidh5αcompetentcells)(宝生物(takarabio)公司制造),将其在无菌条件下接种到lb琼脂培养基中,在37℃下进行培养。将琼脂培养基上生长出的菌体接种到10ml的lb培养基中,回收生长出的菌体,并进行基因组dna提取。以dh5α株的基因组dna为模板,使用由gep2722(序列号101)与gep2723(序列号102)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在进行琼脂糖凝胶电泳后进行提取、纯化。其为包含大肠杆菌dh5α株nana基因(ec_nana)的dna片段。进而,利用ndei与bamhi对pge409进行处理,并对其在进行琼脂糖凝胶电泳后进行提取、纯化。将所述两个dna片段混合,并进行与制作pge1143时相同的操作,由此获得ec_nana被克隆到pge409的质粒pge1226。以pge1226为模板,使用由gep2637(序列号95)与gep2638(序列号96)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在进行琼脂糖凝胶电泳后进行提取、纯化。其为包含pgapa-nana-trrnb的dna片段。进而,利用xhoi对pge1218进行处理,并对其在进行琼脂糖凝胶电泳后进行提取、纯化。将所述两个dna片段混合,并进行与制作pge1185时相同的操作,将由此获得的质粒设为pge1272。2-2-(9)pge1273(δald::nana取代株制作用质粒)的构建以pge1226为模板,使用由gep2639(序列号97)与gep2640(序列号98)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在进行琼脂糖凝胶电泳后进行提取、纯化。进而,利用xhoi对pge1221进行处理,并对其在进行琼脂糖凝胶电泳后进行提取、纯化。其为包含pgapa-nana-trrnb的dna片段。将所述两个dna片段混合,并进行与制作pge1185时相同的操作,将由此获得的质粒设为pge1273。2-2-(10)δadhe::nanaδald::nana取代株的制作使用pge1273,通过电穿孔法对ges1041进行转化,并进行与制作ges1052时相同的操作,由此选择ald基因对pgapa-nana-trrnb进行了取代的株。将其命名为ges1188。进而,使用pge1272,通过电穿孔法对ges1188进行转化,并进行与制作ges1052时相同的操作,由此选择在adhe基因的位置插入有pgapa-nana-trrnb的株。将其命名为ges1223。使用pge1273,通过电穿孔法对ges1042进行转化,并进行与制作ges1052时相同的操作,由此选择ald基因对pgapa-nana-trrnb进行了取代的株。将其命名为ges1189。进而,使用pge1272,通过电穿孔法对ges1189进行转化,并进行与制作ges1052时相同的操作,由此选择在adhe基因的位置插入有pgapa-nana-trrnb的株。将其命名为ges1233。2-2-(11)δadheδald株的制作使用pge1273,通过电穿孔法对ges1041进行转化,并进行与制作ges1052时相同的操作,由此选择ald基因对pgapa-nana-trrnb进行了取代的株。将其命名为ges1188。进而,使用pge1272,通过电穿孔法对ges1188进行转化,并进行与制作ges1052时相同的操作,由此选择在adhe基因的位置插入有pgapa-hpai-trrnb的株。将其命名为ges1223。使用pge1273,通过电穿孔法对ges1042进行转化,并进行与制作ges1052时相同的操作,由此选择ald基因对pgapa-nana-trrnb进行了取代的株。将其命名为ges1189。进而,使用pge1272,通过电穿孔法对ges1189进行转化,并进行与制作ges1052时相同的操作,由此选择在adhe基因的位置插入有pgapa-nana-trrnb的株。将其命名为ges1233。(2-3)超表达用质粒篇2-3-(1)pge411的构建以phsg298(宝生物(takarabio)公司制造)为模板,使用由gep433(序列号81)与gep434(序列号82)所表示的碱基序列的dna的组合、及由gep437(序列号83)与gep438(序列号84)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在进行琼脂糖凝胶电泳后进行提取、纯化。它们分别是包含卡那霉素抗性基因及大肠杆菌用复制起点pucori的dna片段。自理化学研究所生物资源研究中心获取乳酪棒状杆菌(corynebacteriumcasei)jcm12072株,按照随附的使用说明书进行培养,并通过离心分离回收菌体。使菌体颗粒悬浮于1ml的10mm环己二胺四乙酸、25mmtris-hcl(ph8.0)缓冲液中,在6,000xg、4℃下进行5分钟离心分离,并再次进行回收。使菌体颗粒悬浮于包含15mg/ml溶菌酶的300μl的缓冲液a1(buffera1)(附属于马歇雷纳高(macherey-nagel)公司制造的牛克劳斯宾(nucleospin)(注册商标)质粒易净(plasmideasypure))中,在37℃下振荡2小时。然后,依照牛克劳斯宾(nucleospin)(注册商标)质粒易净(plasmideasypure)的使用说明书,进行pcase1质粒的提取及纯化。以此为模板,使用由gep443(序列号103)与gep444(序列号104)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在进行琼脂糖凝胶电泳后进行提取、纯化。其为包含棒状杆菌用复制起点pcase1ori的dna片段。将以上三个dna片段混合,并将因福森(in-fusion)(注册商标)hd克隆试剂盒(hdcloningkit)按照其使用说明书加以使用,来进行dna片段的结合反应。使用反应产物,对大肠杆菌dh5α感受态细胞(e.colidh5αcompetentcells)(宝生物(takarabio)公司制造)按照其使用说明书进行转化。目标转化株是通过在包含50μg/ml的卡那霉素的lb琼脂培养基上进行培养来选择。在包含50μg/ml的卡那霉素的lb培养基中对所述转化株进行培养,使用所获得的培养悬浮液进行质粒提取。将如此般获得的质粒设为pge402。以atcc13032株的基因组dna为模板,使用由gep474(序列号105)与gep477(序列号106)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在进行琼脂糖凝胶电泳后进行提取、纯化。另外,以pflag-ctc(西格玛奥德里奇(sigmaaldrich)公司制造)为模板,使用由gep467(序列号89)与gep468(序列号90)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在进行琼脂糖凝胶电泳后进行提取、纯化。它们分别是包含atcc13032株的ldha启动子(pldha)及大肠杆菌核糖体rna转录终止子(trrnb)的dna片段。进而,利用bamhi与ecorv对pge402进行处理,并对其在进行琼脂糖凝胶电泳后进行提取、纯化。将所述三个dna片段混合,并将因福森(in-fusion)(注册商标)hd克隆试剂盒(hdcloningkit)按照其使用说明书加以使用,来进行dna片段的结合反应。使用反应产物,对大肠杆菌dh5α感受态细胞(e.colidh5αcompetentcells)(宝生物(takarabio)公司制造)按照其使用说明书进行转化。目标转化株是通过在包含50μg/ml的卡那霉素的lb琼脂培养基上进行培养来选择。在包含50μg/ml的卡那霉素的lb培养基中对所述转化株进行培养,使用所获得的培养悬浮液进行质粒提取。将如此般获得的质粒设为pge411。2-3-(2)pge945-2的构建以pcr8/gw/topo(英杰(invitrogen)公司制造)为模板,使用由gep435(序列号107)与gep436(序列号108)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在进行琼脂糖凝胶电泳后进行提取、纯化。另外,以phsg298(宝生物(takarabio)公司制造)为模板,使用由gep437(序列号83)与gep438(序列号84)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在进行琼脂糖凝胶电泳后进行提取、纯化。它们分别是包含壮观霉素(spectinomycin)抗性基因及大肠杆菌用复制起点pucori的dna片段。将以上两个dna片段、及pge402的制作时所获得的包含pcase1ori的dna片段混合,并将因福森(in-fusion)(注册商标)hd克隆试剂盒(hdcloningkit)按照其使用说明书加以使用,来进行dna片段的结合反应。使用反应产物,对大肠杆菌dh5α感受态细胞(e.colidh5αcompetentcells)(宝生物(takarabio)公司制造)按照其使用说明书进行转化。目标转化株是通过在包含100μg/ml的壮观霉素的lb琼脂培养基上进行培养来选择。在包含100μg/ml的壮观霉素的lb培养基中对所述转化株进行培养,使用所获得的培养悬浮液进行质粒提取。将如此般获得的质粒设为pge619。以atcc13032株的基因组dna为模板,使用由gep474(序列号105)与gep477(序列号106)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在进行琼脂糖凝胶电泳后进行提取、纯化。另外,以pflag-ctc(西格玛奥德里奇(sigmaaldrich)公司制造)为模板,使用由gep467(序列号89)与gep2897(序列号109)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在进行琼脂糖凝胶电泳后进行提取、纯化。它们分别是包含atcc13032株的ldha启动子(pldha)及大肠杆菌核糖体rna转录终止子(trrnb)的dna片段。进而,利用bamhi及ecorv对pge619进行处理,并对其在进行琼脂糖凝胶电泳后进行提取、纯化。将所述三个dna片段混合,并将因福森(in-fusion)(注册商标)hd克隆试剂盒(hdcloningkit)按照其使用说明书加以使用,来进行dna片段的结合反应。使用反应产物,对大肠杆菌dh5α感受态细胞(e.colidh5αcompetentcells)(宝生物(takarabio)公司制造)按照其使用说明书进行转化。目标转化株是通过在包含100μg/ml的壮观霉素的lb琼脂培养基上进行培养来选择。在包含100μg/ml的壮观霉素的lb培养基中对所述转化株进行培养,使用所获得的培养悬浮液进行质粒提取。将如此般获得的质粒设为pge945-2。2-3-(3)pp_mdlc超表达用质粒的构建自独立行政法人制品评价技术基盘机构生物技术中心获取恶臭假单胞菌nbrc14164株,按照随附的使用说明书进行培养后进行基因组dna提取。以nbrc14164株的基因组dna为模板,使用由gep2550(序列号110)与gep2551(序列号111)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在进行琼脂糖凝胶电泳后进行提取、纯化。其为包含恶臭假单胞菌nbrc14164株mdlc基因(pp_mdlc)的dna片段。进而,利用ndei对pet-15b(安诺伦(novagen)公司制造)进行处理,并对其在进行琼脂糖凝胶电泳后进行提取、纯化。将所述两个dna片段混合,并进行与制作pge1031时相同的操作,由此获得pp_mdlc被克隆到pet-15b的质粒pge1161。以pge1161为模板,使用由gep2653(序列号112)与gep2654(序列号113)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在进行琼脂糖凝胶电泳后进行提取、纯化。进而,利用ndei对pge409进行处理,并对其在进行琼脂糖凝胶电泳后进行提取、纯化。将所述两个dna片段混合,并进行与制作pge1185时相同的操作,由此获得pp_mdlc被亚克隆到pge409的质粒pge1197。2-3-(4)kp_dhat超表达用质粒的构建由广岛大学田岛誉久博士提供了包含来源于肺炎克雷伯菌的基因(日本dna数据库(dnadatabankofjapan,ddbj)登录号:lc412902)的质粒pha12-dhabt。以其为模板,使用由gep2529(序列号114)与gep2530(序列号115)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在进行琼脂糖凝胶电泳后进行提取、纯化。其为包含肺炎克雷伯菌dhat基因(kp_dhat)的dna片段。进而,利用ndei对pet-15b(安诺伦(novagen)公司制造)进行处理,并对其在进行琼脂糖凝胶电泳后进行提取、纯化。将所述两个dna片段混合,并进行与制作pge1161时相同的操作,由此获得kp_dhat被克隆到pet-15b的质粒pge1150。利用ndei与bamhi对pge1150进行处理,并对1.2kb的dna片段在进行琼脂糖凝胶电泳后进行提取、纯化。进而,利用ndei与bamhi对pge945-2进行处理,并对其在进行琼脂糖凝胶电泳后进行提取、纯化。将所述两个dna片段混合,并将连接高版本2(ligationhighver.2)(东洋纺公司制造)按照其使用说明书加以使用,来进行dna片段的结合反应。使用反应产物,对大肠杆菌dh5α感受态细胞(e.colidh5αcompetentcells)(宝生物(takarabio)公司制造)按照其使用说明书进行转化。目标转化株是通过在包含100μg/ml的壮观霉素的lb琼脂培养基上进行培养来选择。在包含100μg/ml的壮观霉素的lb培养基中对所述转化株进行培养,使用所获得的培养悬浮液进行质粒提取。如此般获得kp_dhat被亚克隆到pge945-2的质粒pge1190。2-3-(5)ll_ldhaq85c超表达用质粒的构建自独立行政法人制品评价技术基盘机构生物技术中心获取乳酸乳球菌nbrc100676株,按照随附的使用说明书进行培养后进行基因组dna提取。以nbrc100676株的基因组dna为模板,使用由gep2799(序列号116)与gep2800(序列号117)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在进行琼脂糖凝胶电泳后进行提取、纯化。其为包含乳酸乳球菌nbrc100676株ldha基因(ll_ldha)的dna片段。进而,利用ndei对pet-15b(安诺伦(novagen)公司制造)进行处理,并对其在进行琼脂糖凝胶电泳后进行提取、纯化。将所述两个dna片段混合,并进行与制作pge1031时相同的操作,由此获得ll_ldha被克隆到pet-15b的质粒pge1274。出于向来源于乳酸乳球菌nbrc100676株的乳酸脱氢酶导入突变的目的,以pge1274为模板,使用由gep2803(序列号118)及gep2804(序列号119)所表示的碱基序列的dna,将原恒星(primestar)(注册商标)突变形成基底试剂盒(mutagenesisbasalkit)(宝生物(takarabio)公司制造)按照其使用说明书加以使用,来进行突变导入及质粒的扩增,获得具有ll_ldha的突变基因ll_ldhaq85c的序列的质粒pge1275。以pge1275为模板,使用由gep2801(序列号120)与gep2802(序列号121)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在进行琼脂糖凝胶电泳后进行提取、纯化。进而,利用ndei与bamhi对pge945-2进行处理,并对其在进行琼脂糖凝胶电泳后进行提取、纯化。将所述两个dna片段混合,并将因福森(in-fusion)(注册商标)hd克隆试剂盒(hdcloningkit)按照其使用说明书加以使用,来进行dna片段的结合反应。使用反应产物,对大肠杆菌dh5α感受态细胞(e.colidh5αcompetentcells)(宝生物(takarabio)公司制造)按照其使用说明书进行转化。目标转化株是通过在包含100μg/ml的壮观霉素的lb琼脂培养基上进行培养来选择。在包含100μg/ml的壮观霉素的lb培养基中对所述转化株进行培养,使用所获得的培养悬浮液进行质粒提取。如此般获得ll_ldhaq85c被亚克隆到pge945-2的质粒pge1286。2-3-(6)ls_leudh超表达用质粒的构建自独立行政法人制品评价技术基盘机构生物技术中心获取球形赖氨酸芽孢杆菌nbrc3525株,按照随附的使用说明书进行培养后进行基因组dna提取。以nbrc3525株的基因组dna为模板,使用由gep2525(序列号122)与gep2526(序列号123)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在进行琼脂糖凝胶电泳后进行提取、纯化。其为包含球形赖氨酸芽孢杆菌nbrc3525株leudh基因(ls_leudh)的dna片段。进而,利用ndei对pet-15b(安诺伦(novagen)公司制造)进行处理,并对其在进行琼脂糖凝胶电泳后进行提取、纯化。将所述两个dna片段混合,并进行与制作pge1031时相同的操作,由此获得ls_leudh被克隆到pet-15b的质粒pge1148。以pge1148为模板,使用由gep2655(序列号124)与gep2650(序列号125)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在进行琼脂糖凝胶电泳后进行提取、纯化。进而,利用ndei与bamhi对pge945-2进行处理,并对其在进行琼脂糖凝胶电泳后进行提取、纯化。将所述两个dna片段混合,并进行与制作pge1286时相同的操作,由此获得ls_leudh被亚克隆到pge945-2的质粒pge1203。2-3-(7)sf_valdh超表达用质粒的构建自美国模式培养物集存库(americantypeculturecollection)获取费氏链霉菌atcc19609株,按照随附的使用说明书进行培养后进行基因组dna提取。以atcc19609株的基因组dna为模板,使用由gep2600(序列号126)与gep2601(序列号127)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在进行琼脂糖凝胶电泳后进行提取、纯化。其为包含费氏链霉菌atcc19609株valdh基因(sf_valdh)的dna片段。进而,利用ndei对pet-15b(安诺伦(novagen)公司制造)进行处理,并对其在进行琼脂糖凝胶电泳后进行提取、纯化。将所述两个dna片段混合,并进行与制作pge1031时相同的操作,由此获得sf_valdh被克隆到pet-15b的质粒pge1175。2-3-(8)bb_phedh超表达用质粒的构建自独立行政法人制品评价技术基盘机构生物技术中心获取栗褐芽孢杆菌nbrc15713株,按照随附的使用说明书进行培养后进行基因组dna提取。以nbrc15713株的基因组dna为模板,使用由gep2678(序列号128)与gep2679(序列号129)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在进行琼脂糖凝胶电泳后进行提取、纯化。其为包含栗褐芽孢杆菌nbrc15713株phedh基因(bb_phedh)的dna片段。进而,利用ndei对pet-15b(安诺伦(novagen)公司制造)进行处理,并对其在进行琼脂糖凝胶电泳后进行提取、纯化。将所述两个dna片段混合,并进行与制作pge1031时相同的操作,由此获得bb_phedh被克隆到pet-15b的质粒pge1237。2-3-(9)atcgs1超表达用质粒的构建自赛默飞世尔(thermofisher)公司购入pmk-atcgs。pmk-atcgs是包含如下合成dna的质粒:在所述合成dna中,使拟南芥的cgs1基因(生物化学杂志(biochemicaljournal,biochem.j.)331,639-648(1998),ddbj登录号:u43709)所编码的氨基酸序列中的第69个氨基酸以后的序列最适合于谷氨酸棒状杆菌中的表达。以所述pmk-atcgs为模板,使用由gep1053(序列号130)与gep1054(序列号131)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在进行琼脂糖凝胶电泳后进行提取、纯化。其是包含使得最适合于谷氨酸棒状杆菌中的表达的拟南芥cgs1基因(atcgs1)的dna片段。进而,利用ndei对pge411进行处理,并对其在进行琼脂糖凝胶电泳后进行提取、纯化。将所述两个dna片段混合,并进行与制作pge1185时相同的操作,由此获得atcgs1被克隆到pge411的质粒pge479。利用ndei与bamhi对pge479进行处理,并对1.5kb的dna片段在进行琼脂糖凝胶电泳后进行提取、纯化。进而,利用ndei与bamhi对pge409进行处理,并对其在进行琼脂糖凝胶电泳后进行提取、纯化。将所述两个dna片段混合,并将连接高版本2(ligationhighver.2)(东洋纺公司制造)按照其使用说明书加以使用,来进行dna片段的结合反应。使用反应产物,对大肠杆菌dh5α感受态细胞(e.colidh5αcompetentcells)(宝生物(takarabio)公司制造)按照其使用说明书进行转化。目标转化株是通过在包含50μg/ml的卡那霉素的lb琼脂培养基上进行培养来选择。在包含50μg/ml的卡那霉素的lb培养基中对所述转化株进行培养,使用所获得的培养悬浮液进行质粒提取。如此般获得atcgs1被亚克隆到pge409的质粒pge513。2-3-(10)各种醛缩酶超表达用质粒的构建以dh5α株的基因组dna为模板,使用由gep2712(序列号132)与gep2713(序列号133)所表示的碱基序列的dna的组合、由gep2714(序列号134)与gep2715(序列号135)所表示的碱基序列的dna的组合、由gep2720(序列号136)与gep2721(序列号137)所表示的碱基序列的dna的组合、由gep2726(序列号138)与gep2727(序列号139)所表示的碱基序列的dna的组合、由gep2767(序列号140)与gep2768(序列号141)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在进行琼脂糖凝胶电泳后进行提取、纯化。它们分别是包含大肠杆菌dh5α株eda基因(ec_eda)、yjjj基因(ec_yjhh)、dgoa基因(ec_dgoa)、mhpfe基因(ec_mhpfe)、garl基因(ec_garl)的dna片段。进而,利用ndei与bamhi对pge409进行处理,并对其在进行琼脂糖凝胶电泳后进行提取、纯化。将具有各种基因的dna片段及来源于pge409的dna片段混合,并进行与制作pge1185时相同的操作,由此获得ec_eda、ec_yjhh、ec_dgoa、ec_mhpfe、ec_garl被克隆到pge409的质粒pge1223、质粒pge1224、质粒pge1225、质粒pge1227、质粒pge1259。以恶臭假单胞菌nbrc14164株的基因组dna为模板,使用由gep2769(序列号142)与gep2770(序列号143)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在进行琼脂糖凝胶电泳后进行提取、纯化。其为包含恶臭假单胞菌nbrc14164株galc基因(pp_galc)的dna片段。进而,利用ndei与bamhi对pge409进行处理,并对其在进行琼脂糖凝胶电泳后进行提取、纯化。将所述两个dna片段混合,并进行与制作pge1185时相同的操作,由此获得pp_galc被克隆到pge409的质粒pge1260。自独立行政法人制品评价技术基盘机构生物技术中心获取类诺卡氏菌属nbrc109351株,按照随附的使用说明书进行培养后进行基因组dna提取。以nbrc109351株的基因组dna为模板,使用由gep2716(序列号144)与gep2717(序列号145)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在进行琼脂糖凝胶电泳后进行提取、纯化。其为包含类诺卡氏菌属nbrc109351株phdj基因(ns_phdj)的dna片段。进而,利用ndei与bamhi对pge409进行处理,并对其在进行琼脂糖凝胶电泳后进行提取、纯化。将所述两个dna片段混合,并进行与制作pge1185时相同的操作,由此获得ns_phdj被克隆到pge409的质粒pge1239。自德国微生物与细胞培养物保存中心(deutschesammlungvonmikroorganismenundzellkulturengmbh)获取食异源化合物伯克霍尔德氏菌dsmz17367株,按照随附的使用说明书进行培养后进行基因组dna提取。以dsmz17367株的基因组dna为模板,使用由gep2771(序列号146)与gep2772(序列号147)所表示的碱基序列的dna的组合,通过pcr法获得pcr产物,对所述pcr产物在进行琼脂糖凝胶电泳后进行提取、纯化。其为包含食异源化合物伯克霍尔德氏菌dsmz17367株bphji基因(bx_bphji)的dna片段。进而,利用ndei与bamhi对pge409进行处理,并对其在进行琼脂糖凝胶电泳后进行提取、纯化。将所述两个dna片段混合,并进行与制作pge1185时相同的操作,由此获得bx_bphji被克隆到pge409的质粒pge1262。3.菌体构建(3-1)pp_mdlc及kp_dhat超表达质粒导入株的制作使用pge1197与pge1190,通过电穿孔法对ges1070进行转化,在33℃下在包含25μg/ml的卡那霉素与100μg/ml的壮观霉素的a琼脂培养基上选择卡那霉素与壮观霉素抗性株。将其命名为ges1206。使用pge1197与pge1190,通过电穿孔法对ges1063进行转化,在33℃下在包含25μg/ml的卡那霉素与100μg/ml的壮观霉素的a琼脂培养基上选择卡那霉素与壮观霉素抗性株。将其命名为ges1077。使用pge1197与pge1190,通过电穿孔法对ges1064进行转化,在33℃下在包含25μg/ml的卡那霉素与100μg/ml的壮观霉素的a琼脂培养基上选择卡那霉素与壮观霉素抗性株。将其命名为ges1068。谷氨酸棒状杆菌(corynebacteriumglutamicum)ges1068寄存在日本千叶县木更津市上总镰足2-5-8(邮政编码292-0818)的独立行政法人制品评价技术基盘机构专利微生物寄存中心(寄存日:2018年9月13日,保藏编号:nitebp-02780)使用pge1197与pge1190,通过电穿孔法对ges1223进行转化,在33℃下在包含25μg/ml的卡那霉素与100μg/ml的壮观霉素的a琼脂培养基上选择卡那霉素与壮观霉素抗性株。将其命名为ges1253。使用pge1197与pge1190,通过电穿孔法对ges1233进行转化,在33℃下在包含25μg/ml的卡那霉素与100μg/ml的壮观霉素的a琼脂培养基上选择卡那霉素与壮观霉素抗性株。将其命名为ges1254。谷氨酸棒状杆菌(corynebacteriumglutamicum)ges1254寄存在日本千叶县木更津市上总镰足2-5-8(邮政编码292-0818)的独立行政法人制品评价技术基盘机构专利微生物寄存中心(寄存日:2018年9月13日,保藏编号:nitebp-02781)使用pge1197与pge1190,通过电穿孔法对ges1242进行转化,在33℃下在包含25μg/ml的卡那霉素与100μg/ml的壮观霉素的a琼脂培养基上选择卡那霉素与壮观霉素抗性株。将其命名为ges1282。(3-2)ll_ldhaq85c超表达质粒导入株的制作使用pge1286,通过电穿孔法对ges1064进行转化,在33℃下在包含100μg/ml的壮观霉素的a琼脂培养基上选择壮观霉素抗性株。将其命名为ges1232。谷氨酸棒状杆菌(corynebacteriumglutamicum)ges1232寄存在日本千叶县木更津市上总镰足2-5-8(邮政编码292-0818)的独立行政法人制品评价技术基盘机构专利微生物寄存中心(寄存日:2018年9月13日,保藏编号:nitebp-02782)使用pge1286,通过电穿孔法对ges1211进行转化,在33℃下在包含100μg/ml的壮观霉素的a琼脂培养基上选择壮观霉素抗性株。将其命名为ges1294。(3-3)ls_leudh超表达质粒导入株的制作使用pge1203,通过电穿孔法对ges1064进行转化,在33℃下在包含100μg/ml的壮观霉素的a琼脂培养基上选择壮观霉素抗性株。将其命名为ges1073。谷氨酸棒状杆菌(corynebacteriumglutamicum)ges1073寄存在日本千叶县木更津市上总镰足2-5-8(邮政编码292-0818)的独立行政法人制品评价技术基盘机构专利微生物寄存中心(寄存日:2018年9月13日,保藏编号:nitebp-02783)使用pge1203,通过电穿孔法对ges1211进行转化,在33℃下在包含100μg/ml的壮观霉素的a琼脂培养基上选择壮观霉素抗性株。将其命名为ges1295。(3-4)ls_leudh及atcgs1表达质粒导入株的制作使用pge1203与pge513,通过电穿孔法对ges1064进行转化,在33℃下在包含25μg/ml的卡那霉素与100μg/ml的壮观霉素的a琼脂培养基上选择卡那霉素与壮观霉素抗性株。将其命名为ges1097。谷氨酸棒状杆菌(corynebacteriumglutamicum)ges1097寄存在日本千叶县木更津市上总镰足2-5-8(邮政编码292-0818)的独立行政法人制品评价技术基盘机构专利微生物寄存中心(寄存日:2018年9月13日,保藏编号:nitebp-02784)(3-5)各种醛缩酶表达质粒导入株的制作分别使用pge1143、pge1223、pge1224、pge1225、pge1226、pge1227、pge1239、pge1258、pge1259、pge1260、pge1262,通过电穿孔法对ges435进行转化,在33℃下在包含25μg/ml的卡那霉素的a琼脂培养基上选择卡那霉素抗性株。将其分别命名为ges1009、ges1119、ges1120、ges1121、ges1122、ges1123、ges1127、ges1154、ges1155、ges1156、ges1157。4.物质生产实验(4-1)4-羟基-2-氧代丁酸(hob)的生产4-1-(1)ges1077的培养将ges1077的甘油原种在无菌条件下接种到包含卡那霉素25μg/ml及壮观霉素100μg/ml的a琼脂培养基中,在33℃下进行培养。将琼脂培养基上生长出的菌体接种到包含卡那霉素25μg/ml及壮观霉素100μg/ml的10ml的ba培养基中,在33℃下进行振荡培养,制成种子培养液。将所述种子培养液以浊度成为0.1的方式接种到2l烧瓶中所准备的、包含卡那霉素25μg/ml及壮观霉素100μg/ml的500ml的ba培养基中。在33℃下进行振荡,培养一整夜。对所述正式培养液在4℃、5500xg下进行15分钟离心分离,将上清液去除。将如此般获得的湿菌体用于以下反应。4-1-(2)使用ges1077的hob的生产将如上所述般制备的湿菌体以成为10%(w/v)的方式悬浮于br缓冲液中。向所述菌体悬浮液中加入50%(w/v)的葡萄糖水溶液及1.2m的甲醛水溶液,使它们分别成为50mm、40mm,一边使用1.0m氢氧化钾水溶液将ph维持于6.0,一边在33℃下进行培养。在所述湿菌体浓度下,将搅拌抑制在氢氧化钾水溶液得到有效率地混合的程度,且若不进行通气,则会自然地实现厌氧条件下或微好氧条件。3小时后,通过有机酸分析用液相色谱对反应液的上清液进行分析,结果生成了0.65mm的hob。4-1-(3)比较例1将如上所述般制备的湿菌体以成为10%(w/v)的方式悬浮于br缓冲液中。向所述菌体悬浮液中加入50%(w/v)的葡萄糖水溶液而使所述葡萄糖水溶液成为50mm,一边使用1.0m氢氧化钾水溶液将ph维持于6.0,一边在33℃下进行反应。3小时后,通过有机酸分析用液相色谱对反应悬浮液的上清液进行分析,结果未检测到hob。4-1-(4)比较例2对ges1206进行与所述4-1-(1)、4-1-(2)相同的实验。反应3小时后,通过有机酸分析用液相色谱对反应悬浮液的上清液进行分析,结果未检测到hob。根据4-1-(2)、4-1-(3)、4-1-(4)的结果可知,如ges1077般的具有对二类醛缩酶进行编码的基因的菌体通过在糖类及醛存在下进行培养,由糖类生成丙酮酸,且所述酶催化所述丙酮酸与醛之间的羟醛反应,由此生成如hob所代表的羟醛化合物。4-1-(5)ges1282的培养将以与4-1-(1)相同的方式自ges1282的甘油原种进行培养而获得的湿菌体用于以下反应。4-1-(6)使用ges1282的hob的生产以与4-1-(2)相同的方式对如上所述般制备的湿菌体进行培养。在培养过程中进行搅拌,以便有效率地混合氢氧化钾水溶液,且未进行通气。此外,通过所述操作,在所述湿菌体浓度下实现了厌氧条件或微好氧条件。3小时后,通过有机酸分析用液相色谱对反应液的上清液进行分析,结果生成了0.36mm的hob。4-1-(7)比较例1以与4-1-(3)相同的方式对如上所述般制备的湿菌体进行培养。在培养过程中进行搅拌,以便有效率地混合氢氧化钾水溶液,且未进行通气。此外,通过所述操作,在所述湿菌体浓度下实现了厌氧条件或微好氧条件。3小时后,通过有机酸分析用液相色谱对反应悬浮液的上清液进行分析,结果未检测到hob。根据4-1-(6)、4-1-(7)、4-1-(4)的结果可知,如ges1282般的具有对与ges1077相比而不同的二类醛缩酶进行编码的基因的菌体也通过在糖类及醛存在下进行培养而由糖类生成丙酮酸,且所述酶催化所述丙酮酸与醛之间的羟醛反应,由此生成如hob所代表的羟醛化合物。4-1-(8)ges1253的培养将以与4-1-(1)相同的方式自ges1253的甘油原种进行培养而获得的湿菌体用于以下反应。4-1-(9)使用ges1253的hob的生产以与4-1-(2)相同的方式对如上所述般制备的湿菌体进行培养。在培养过程中进行搅拌,以便有效率地混合氢氧化钾水溶液,且未进行通气。此外,通过所述操作,在所述湿菌体浓度下实现了厌氧条件或微好氧条件。3小时后,通过有机酸分析用液相色谱对反应液的上清液进行分析,结果生成了0.34mm的hob。4-1-(10)比较例1以与4-1-(2)相同的方式对如上所述般制备的湿菌体进行培养。在培养过程中进行搅拌,以便有效率地混合氢氧化钾水溶液,且未进行通气。此外,通过所述操作,在所述湿菌体浓度下实现了厌氧条件或微好氧条件。3小时后,通过有机酸分析用液相色谱对反应悬浮液的上清液进行分析,结果未检测到hob。根据4-1-(9)、4-1-(10)、4-1-(4)的结果可知,如ges1253般的具有对一类醛缩酶进行编码的基因的菌体通过在糖类及醛存在下进行培养,由糖类生成丙酮酸,且所述酶催化所述丙酮酸与醛之间的羟醛反应,由此生成如hob所代表的羟醛化合物。4-1-(11)ges1068及ges1254的培养将以与4-1-(1)相同的方式自ges1068及ges1254的甘油原种进行培养而获得的湿菌体用于以下反应。4-1-(12)使用ges1068及ges1254的hob的生产以与4-1-(2)相同的方式对如上所述般制备的湿菌体进行培养。在培养过程中进行搅拌,以便有效率地混合氢氧化钾水溶液,且未进行通气。此外,通过所述操作,在所述湿菌体浓度下实现了厌氧条件或微好氧条件。3小时后,通过有机酸分析用液相色谱对反应液的上清液进行分析,结果在使用ges1068的反应中生成了1.2mm的hob,在使用ges1254的反应中生成了0.42mm的hob。根据4-1-(12)的结果可知,即使是如ges1068及ges1254般的与ges1077及ges1253为不同基因型的微生物,但只要是具有对二类醛缩酶进行编码的基因的菌体,则通过在糖类及醛存在下进行培养,也由糖类生成丙酮酸,且所述酶催化所述丙酮酸与醛之间的羟醛反应,由此也生成如hob所代表的羟醛化合物。(4-2)1,3-丙二醇(pdo)的生产4-2-(1)ges1077、ges1068的培养将ges1077、ges1068的甘油原种在无菌条件下接种到包含卡那霉素25μg/ml及壮观霉素100μg/ml的a琼脂培养基中,在33℃下进行培养。将琼脂培养基上生长出的菌体接种到包含卡那霉素25μg/ml及壮观霉素100μg/ml的10ml的ba培养基中,在33℃下进行振荡培养,制成种子培养液。将所述种子培养液以浊度成为0.1的方式接种到2l烧瓶中所准备的、包含卡那霉素25μg/ml及壮观霉素100μg/ml的500ml的ba培养基中。在33℃下进行振荡,培养一整夜。对所述正式培养液在4℃、5500xg下进行15分钟离心分离,将上清液去除。将如此般获得的湿菌体用于以下反应。4-2-(2)使用ges1077、ges1068的pdo的生产将如上所述般制备的湿菌体以成为10%(w/v)的方式悬浮于br缓冲液中。向所述菌体悬浮液中加入50%(w/v)的葡萄糖水溶液及1.2m的甲醛水溶液,使它们分别成为50mm、40mm,一边使用1.0m氢氧化钾水溶液将ph维持于6.0,一边在33℃下进行培养。在培养过程中进行搅拌,以便有效率地混合氢氧化钾水溶液,且未进行通气。此外,通过所述操作,在所述湿菌体浓度下实现了厌氧条件或微好氧条件。3小时后,通过糖分析用液相色谱对反应液的上清液进行分析,结果在使用ges1077的反应中生成了7.4mm的pdo,在使用ges1068的反应中生成了11.4mm的pdo。根据以上结果可知,如ges1077及ges1068般的具有对二类醛缩酶进行编码的基因、且当在糖类及甲醛存在下进行培养时可生产hob的菌体在还具有对脱羧酶及醇脱氢酶进行编码的基因的情况下,hob进一步转变为pdo,从而可制造pdo。4-2-(3)ges1282的培养将以与4-2-(1)相同的方式自ges1282的甘油原种进行培养而获得的湿菌体用于以下反应。4-2-(4)使用ges1282的pdo的生产以与4-2-(2)相同的方式对如上所述般制备的湿菌体进行培养。在培养过程中进行搅拌,以便有效率地混合氢氧化钾水溶液,且未进行通气。此外,通过所述操作,在所述湿菌体浓度下实现了厌氧条件或微好氧条件。6小时后,通过糖分析用液相色谱对反应液的上清液进行分析,结果生成了1.4mm的pdo。根据以上结果可知,如ges1282般的具有对与ges1077及ges1068相比而不同的二类醛缩酶进行编码的基因、且当在糖类及甲醛存在下进行培养时可生产hob的菌体在还具有对脱羧酶及醇脱氢酶进行编码的基因的情况下,hob也进一步转变为pdo,从而也可制造pdo。4-2-(5)ges1253、ges1254的培养将以与4-2-(1)相同的方式自ges1254的甘油原种进行培养而获得的湿菌体用于以下反应。4-2-(6)使用ges1253、ges1254的pdo的生产以与4-2-(2)相同的方式对如上所述般制备的湿菌体进行培养。在培养过程中进行搅拌,以便有效率地混合氢氧化钾水溶液,且未进行通气。此外,通过所述操作,在所述湿菌体浓度下实现了厌氧条件或微好氧条件。6小时后,通过糖分析用液相色谱对反应液的上清液进行分析,结果在使用ges1253的反应中生成了4.1mm的pdo,在使用ges1254的反应中生成了5.8mm的pdo。根据以上结果可知,如ges1253及ges1254般的具有对一类醛缩酶进行编码的基因、且当在糖类及甲醛存在下进行培养时可生产hob的菌体在还具有对脱羧酶及醇脱氢酶进行编码的基因的情况下,hob进一步转变为pdo,从而可制造pdo。(4-3)1,3-丁二醇(bdo)的生产4-3-(1)ges1068的培养将以与4-2-(1)相同的方式自ges1068的甘油原种进行培养而获得的湿菌体用于以下反应。4-3-(2)使用ges1068的bdo的生产将如上所述般制备的湿菌体以成为10%(w/v)的方式悬浮于br缓冲液中。向所述菌体悬浮液中加入50%(w/v)的葡萄糖水溶液及1.2m的乙醛水溶液,使它们分别成为50mm、40mm,一边使用1.0m氢氧化钾水溶液将ph维持于6.0,一边在33℃下进行培养。在培养过程中进行搅拌,以便有效率地混合氢氧化钾水溶液,且未进行通气。此外,通过所述操作,在所述湿菌体浓度下实现了厌氧条件或微好氧条件。3小时后,通过糖分析用液相色谱对反应液的上清液进行分析,结果生成了8.2mm的bdo。根据以上结果可知,通过在糖类及乙醛存在下,对如ges1068般的具有对醛缩酶、脱羧酶及醇脱氢酶进行编码的基因的菌体进行培养,可制造bdo。此外,在4-2-(2)中,若在反应时间超过3小时而甲醛浓度降低后仍继续反应,则在22小时后,在使用ges1077的反应中生成了3.5mm的bdo,在使用ges1068的反应中生成了2.7mm的bdo。对此,认为当甲醛降低到无法参与醛缩酶的反应的浓度时,通过mdlc(脱羧酶)对丙酮酸的催化作用而产生乙醛,所述乙醛与另一分子的丙酮酸进行羟醛反应,产生4-羟基-2-氧代戊酸酯(4-hydroxy-2-oxovalerat,hov),所述4-羟基-2-氧代戊酸酯进一步通过mdlc、dhat的催化作用而受到脱羧、还原,由此产生了bdo。因此,对于具有对醛羧酶进行编码的基因、进而具有对脱羧酶及醇脱氢酶进行编码的基因的菌体,仅将糖类作为碳源来进行培养便可生产bdo。实际上,对于ges1077,在与4-2-(2)中记载的条件相比不添加甲醛的条件下进行了培养,结果在22小时后生成了0.60mm的bdo。(4-4)各种1,3-二醇的生产4-4-(1)ges1068的培养将以与4-2-(1)相同的方式自ges1068的甘油原种进行培养而获得的湿菌体用于以下反应。4-4-(2)使用ges1068的各种1,3-二醇的生产将如上所述般制备的湿菌体以成为10%(w/v)的方式悬浮于br缓冲液中。向所述菌体悬浮液中加入50%(w/v)的葡萄糖水溶液及醛(丙醛、正丁醛、异丁醛、正戊醛),使它们分别成为50mm、40mm,一边使用1.0m氢氧化钾水溶液将ph维持于6.0,一边在33℃下进行培养。在培养过程中进行搅拌,以便有效率地混合氢氧化钾水溶液,且未进行通气。此外,通过所述操作,在所述湿菌体浓度下实现了厌氧条件或微好氧条件。3小时后,通过gcms对反应液的上清液进行分析,结果在各反应中分别确认到了来源于丙醛的1,3-戊二醇、来源于正丁醛的1,3-己二醇、来源于异丁醛的4-甲基-1,3-戊二醇、来源于正戊醛的1,3-庚二醇。图6表示使用丙醛时的气相色谱仪质谱的结果。图7表示使用正丁醛时的气相色谱仪质谱的结果。图8表示使用异丁醛时的气相色谱仪质谱的结果。图8表示使用正戊醛时的气相色谱仪质谱的结果。根据以上结果可知,通过在糖类及丙醛或正丁醛、异丁醛、正戊醛存在下,对如ges1068般的具有对醛缩酶、脱羧酶及醇脱氢酶进行编码的基因的菌体进行培养,可制造1,3-戊二醇、1,3-己二醇、4-甲基-1,3-戊二醇、1,3-庚二醇。另外,一般而言,通过在糖类及醛类存在下,对如ges1068般的具有对醛缩酶、脱羧酶及醇脱氢酶进行编码的基因的菌体进行培养,而由糖类生成丙酮酸,根据所述丙酮酸与醛类的反应而生成羟醛化合物即4-羟基-2-氧代羧酸,所述4-羟基-2-氧代羧酸转变为3-羟基醛化合物,进而转变为1,3-二醇,从而有望可最终制造1,3-二醇。(4-5)2,4-二羟基丁酸(dhb)的生产4-5-(1)ges1232的培养将ges1232的甘油原种在无菌条件下接种到包含壮观霉素100μg/ml的a琼脂培养基中,在33℃下进行培养。将琼脂培养基上生长出的菌体接种到包含壮观霉素100μg/ml的10ml的ba培养基中,在33℃下进行振荡培养,制成种子培养液。将所述种子培养液以浊度成为0.1的方式接种到2l烧瓶中所准备的、包含壮观霉素100μg/ml的500ml的ba培养基中。在33℃下进行振荡,培养一整夜。对所述正式培养液在4℃、5500xg下进行15分钟离心分离,将上清液去除。将如此般获得的湿菌体用于以下反应。4-5-(2)使用ges1232的dhb的生产将如上所述般制备的湿菌体以成为10%(w/v)的方式悬浮于br缓冲液中。向所述菌体悬浮液中加入50%(w/v)的葡萄糖水溶液及1.2m的甲醛水溶液,使它们分别成为100mm、40mm,一边使用1.0m氢氧化钾水溶液将ph维持于7.0,一边在33℃下进行培养。在培养过程中进行搅拌,以便有效率地混合氢氧化钾水溶液,且未进行通气。此外,通过所述操作,在所述湿菌体浓度下实现了厌氧条件或微好氧条件。3小时后,通过有机酸分析用液相色谱对反应液的上清液进行分析,结果生成了11mm的dhb。4-5-(3)比较例1将如上所述般制备的湿菌体以成为10%(w/v)的方式悬浮于br缓冲液中。向所述菌体悬浮液中加入50%(w/v)的葡萄糖水溶液而使所述葡萄糖水溶液成为100mm,一边使用1.0m氢氧化钾水溶液将ph维持于7.0,一边在33℃下进行反应。3小时后,通过有机酸分析用液相色谱对反应液的上清液进行分析,结果未检测到dhb。4-5-(4)比较例2对ges1294进行与所述(1)、(2)相同的实验。反应3小时后,通过有机酸分析用液相色谱对反应悬浮液的上清液进行分析,结果未检测到dhb。根据以上结果可知,如ges1232般的具有对醛缩酶进行编码的基因、且当在糖类及甲醛存在下进行培养时可生产hob的菌体在还具有对具有hob还原活性的脱氢酶进行编码的基因的情况下,通过在糖类及甲醛存在下对所述菌体进行培养,hob进一步转变为dhb,从而可制造dhb。(4-6)l-高丝氨酸n-脱氢酶活性的确认4-6-(1)亮氨酸脱氢酶的表达与氧化脱氨基化反应活性的测定使用pge1148,对ecostm感受态大肠杆菌(competente.coli)bl21(de3)(日本基因(nippongene)公司制造)按照其使用说明书进行转化,将所获得的菌株设为ges1007。将ges1007在无菌条件下接种到包含氨苄青霉素100μg/ml的lb琼脂培养基中,在37℃下进行培养。将琼脂培养基上生长出的菌体接种到包含氨苄青霉素100μg/ml的10ml的lb培养基中,在37℃下进行振荡培养,制成种子培养液。将所述种子培养液以浊度成为0.1的方式接种到500ml烧瓶中所准备的包含氨苄青霉素100μg/ml的100ml的lb培养基中。在37℃下进行振荡,培养至浊度成为0.7。以最终浓度成为0.2mm的方式加入异丙基硫代半乳糖苷(isopropylthio-β-galactoside,iptg),在16℃下进行一整夜振荡培养。对所述正式培养液在4℃、6000xg下进行5分钟离心分离,将上清液去除。将如此般获得的湿菌体在-80℃下冻结一次后,在室温下使其融解。使所述菌体悬浮在4.5ml的50mm磷酸钠缓冲液(ph8.0)、500mm氯化钠、10%甘油中,向其中加入2.0g的玻璃珠ygb01φ0.1mm(安井器械公司制造),使用多珠振动器(multibeadsshocker)mb1001c(s)(安井器械公司制造)在2500rpm、4℃下进行菌体的破碎。在18000xg、4℃下进行3分钟离心分离,并回收上清液。对所述破碎液的蛋白质浓度进行测定,结果为12mg/ml。使用所述菌体破碎液,测定对l-高丝氨酸的氧化脱氨基化反应活性。关于反应条件,将经适宜稀释的菌体破碎液与100mm甘氨酸-kcl-koh(ph10.0)、2.5mmnad+、50mml-高丝氨酸混合,使用维奥斯堪(varioskan)lux(赛默飞世尔(thermofisher)公司制造),测定340nm下的由nadh进行的吸光的连续增加。其结果,所述菌体破碎液对l-高丝氨酸的比活性为0.21u/mgprotein。4-6-(2)缬氨酸脱氢酶的表达与氧化脱氨基化反应活性的测定使用pge1175,对ecostm感受态大肠杆菌(competente.coli)bl21(de3)(日本基因(nippongene)公司制造)按照其使用说明书进行转化,将所获得的菌株设为ges1057。针对ges1057进行与ges1007相同的操作,并对由此获得的破碎液的蛋白质浓度进行测定,结果为4.2mg/ml。使用所述菌体破碎液,以与4-6-(1)相同的方式测定对l-高丝氨酸的氧化脱氨基化反应活性,结果,所述菌体破碎液对l-高丝氨酸的比活性为0.21u/mgprotein。4-6-(3)苯丙氨酸脱氢酶的表达与氧化脱氨基化反应活性的测定使用pge1237,对ecostm感受态大肠杆菌(competente.coli)bl21(de3)(日本基因(nippongene)公司制造)按照其使用说明书进行转化,将所获得的菌株设为ges1136。针对ges1136进行与ges1007相同的操作,并对由此获得的破碎液的蛋白质浓度进行测定,结果为11mg/ml。使用所述菌体破碎液,以与4-6-(1)相同的方式测定对l-高丝氨酸的氧化脱氨基化反应活性,结果,所述菌体破碎液对l-高丝氨酸的比活性为0.045u/mgprotein。根据以上4-6-(1)、4-6-(2)、4-6-(3)的结果可知,亮氨酸脱氢酶、缬氨酸脱氢酶、苯丙氨酸脱氢酶均具有将l-高丝氨酸氧化为hob的活性。一般而言,氨基酸脱氢酶催化氧化脱氨基化反应及还原氨基化反应中的任一反应,另外,它们的活性强度具有相关关系。(例如,生物化学与生物物理学报(biochimicaetbiophysicaacta,biochim.biophys.acta)96,248-262(1965),生物化学杂志(journalofbiologicalchemistry,j.biol.chem.)253,5719-5725(1978),欧洲生物化学杂志(europeanjournalofbiochemistry,eur.j.biochem.)100,29-39(1979)。因此,亮氨酸脱氢酶、缬氨酸脱氢酶、苯丙氨酸脱氢酶均有望催化hob向l-高丝氨酸的还原氨基化反应。为了确认,对亮氨酸脱氢酶进行了纯化,并对hob的还原氨基化反应进行了酶动力学分析。4-6-(4)亮氨酸脱氢酶的纯化与还原氨基化反应活性的测定使用孔径0.2μm的针头式过滤器(syringefilter)(赛多利斯(sartorius)公司制造)对4-6-(1)中所获得的菌体破碎液进行过滤处理。使用连接有西斯拉普tm(histraptm)ff1ml柱的akta纯化(aktapurifier)系统(ge保健(gehealthcare)公司制造),将50mm磷酸钠缓冲液(ph8.0)、500mm氯化钠、10%甘油作为吸附缓冲液,将50mm磷酸钠缓冲液(ph8.0)、500mm氯化钠、10%甘油、500mm咪唑作为洗脱缓冲液,对所述菌体破碎液进行分馏。对利用十二烷基硫酸钠-聚丙烯酰胺凝胶电泳(sodiumdodecylsulfate-polyacrylamidegelelectrophoresis,sds-page)确认到的含有亮氨酸脱氢酶的馏分进行回收,使用超滤进行浓缩,然后使用pd-10柱(ge保健(gehealthcare)公司制造),与50mm磷酸钾(ph7.4)、100mm氯化钠、1mmedta、10%甘油进行缓冲液置换,使用超滤再次进行浓缩,由此获得5.9mg/ml的亮氨酸脱氢酶水溶液。使用以所述方式获得的纯化亮氨酸脱氢酶,进行了以hob为基质的基于米氏(michaelis-menten)式的酶反应动力学分析。关于反应条件,设为100mmhepes·koh(ph7.5)、200mm氯化铵、0.2mmnadh、3.7μg/ml亮氨酸脱氢酶,测定hob浓度为3.13、6.25、12.5、25.0、50.0、100mm时的反应速度。反应速度是使用维奥斯堪(varioskan)lux(赛默飞世尔(thermofisher)公司制造)测定340nm下的由nadh进行的吸光的连续减少来算出。对各浓度下的反应速度进行绘图,并进行对米氏(michaelis-menten)式的拟合,由此算出酶反应动力学常数,结果为相对于hob的米氏常数(michaelisconstant)km为7.7mm,催化剂转化数kcat为2.7sec-1,因此,专一性常数kcat/km为0.35mm-1sec-1。根据所述结果可知,亮氨酸脱氢酶如所期待般显示出对hob的还原氨基化反应的催化活性。另外,根据所述结果认为,关于缬氨酸脱氢酶、苯丙氨酸脱氢酶,对还原氨基化反应也显示出催化活性。(4-7)氨基酸的生产4-7-(1)ges1073的培养将以与4-5-(1)相同的方式自ges1073的甘油原种进行培养而获得的湿菌体用于以下反应4-7-(2)使用ges1073的氨基酸的生产将如上所述般制备的湿菌体以成为10%(w/v)的方式悬浮于bt缓冲液中。向所述菌体悬浮液中加入50%(w/v)的葡萄糖水溶液及2.0m的甲醛水溶液,使它们分别成为2%(w/v)、100mm,一边使用5.0m氨水溶液将ph维持于7.0,一边在33℃下进行培养。在培养过程中进行搅拌,以便有效率地混合氢氧化钾水溶液,且未进行通气。此外,通过所述操作,在所述湿菌体浓度下实现了厌氧条件或微好氧条件。6小时后,通过氨基酸分析用液相色谱对反应液的上清液进行分析,结果生成了15.7mm的l-高丝氨酸、1.3mm的l-苏氨酸、0.15mm的2-氨基丁酸。4-7-(3)比较例1将如上所述般制备的湿菌体以成为10%(w/v)的方式悬浮于bt缓冲液中。向所述菌体悬浮液中加入50%(w/v)的葡萄糖水溶液而使所述葡萄糖水溶液成为2%(w/v),一边使用5.0m氨水溶液将ph维持于7.0,一边在33℃下进行反应。6小时后,通过氨基酸分析用液相色谱对反应液的上清液进行分析,结果均在l-高丝氨酸、l-苏氨酸、2-氨基丁酸的定量界限以下。4-7-(4)比较例2针对ges1295进行与所述4-7-(1)、4-7-(2)相同的实验。反应6小时后,通过氨基酸分析用液相色谱对反应悬浮液的上清液进行分析,结果均在l-高丝氨酸、l-苏氨酸、2-氨基丁酸的定量界限以下。根据以上结果可知,如ges1073般的具有对醛缩酶进行编码的基因、且当在糖类及甲醛存在下进行培养时可生产hob的菌体在还具有对具有将hob加以还原氨基化的活性的脱氢酶进行编码的基因的情况下,通过对所述菌体在糖类及甲醛存在下进行培养,hob进一步转变为l-高丝氨酸,从而可制造l-高丝氨酸。另外也可知,l-高丝氨酸通过内在性的代谢系统,其一部分经由o-磷酸-l-高丝氨酸(o-phospho-l-homoserine,oph)转变为l-苏氨酸,因此可制造l-苏氨酸。进而,l-苏氨酸通过内在性的代谢系统而脱水,成为2-氧代丁酸,并通过内在性的氨基酸脱氢酶或ges1073所特异性具有的亮氨酸脱氢酶而转变成2-氨基丁酸,因此可制造2-氨基丁酸。(4-8)l-蛋氨酸的生产4-8-(1)ges1097的培养将以与4-2-(1)相同的方式自ges1097的甘油原种进行培养而获得的湿菌体用于以下反应。4-8-(2)使用ges1097的氨基酸的生产将如上所述般制备的湿菌体以成为20%(w/v)的方式悬浮于bt缓冲液中。向所述菌体悬浮液中加入50%(w/v)的葡萄糖水溶液、2.0m的甲醛水溶液及0.2m的甲硫醇水溶液(使用bt缓冲液对15%甲硫醇钠水溶液(东京化成工业公司制造)进行稀释,并使用浓盐酸调整为ph8.0),进而利用bt缓冲液进行稀释,由此将葡萄糖水溶液、甲醛水溶液及甲硫醇水溶液分别调整为2%(w/v)、100mm、50mm。另外,此时,使最终湿菌体浓度成为10%(w/v)。一边使用5.0m氨水溶液将ph维持于7.0,一边在33℃下进行培养。在培养过程中进行搅拌,以便有效率地混合氢氧化钾水溶液,且未进行通气。此外,通过所述操作,在所述湿菌体浓度下实现了厌氧条件或微好氧条件。21小时后,通过氨基酸分析用液相色谱对反应液的上清液进行分析,结果生成了2.1mm的l-蛋氨酸。另外,生成了8.6mm的l-高丝氨酸、3.0mm的l-苏氨酸、0.86mm的2-氨基丁酸。4-8-(3)比较例1将如上所述般制备的湿菌体以成为20%(w/v)的方式悬浮于bt缓冲液中。向所述菌体悬浮液中加入50%(w/v)的葡萄糖水溶液及2.0m的甲醛水溶液,进而利用bt缓冲液进行稀释,由此将葡萄糖水溶液及甲醛水溶液分别调整为2%(w/v)、100mm。另外,此时,使最终湿菌体浓度成为10%(w/v)。一边使用5n氨水溶液将ph维持于7.0,一边在33℃下进行反应。21小时后,通过氨基酸分析用液相色谱对反应液的上清液进行分析,结果l-蛋氨酸在定量界限以下。另一方面,生成了5.4mm的l-高丝氨酸、5.6mm的l-苏氨酸、0.98mm的2-氨基丁酸。4-8-(4)比较例2针对ges1073进行与所述4-8-(1)、4-8-(2)相同的实验。反应21小时后,通过氨基酸分析用液相色谱对反应悬浮液的上清液进行分析,结果l-蛋氨酸的生成在定量界限以下。另一方面,生成了12.8mm的l-高丝氨酸、1.6mm的l-苏氨酸、0.40mm的2-氨基丁酸。根据以上结果可知,如ges1097般的具有对醛缩酶进行编码的基因及对具有将hob加以还原氨基化的活性的脱氢酶进行编码的基因、且当在糖类及甲醛存在下进行培养时可生产l-高丝氨酸的菌体在还具有对具有使oph与甲硫醇结合的活性的合酶进行编码的基因的情况下,通过对所述菌体在糖类、甲醛及甲硫醇存在下进行培养,l-高丝氨酸经由oph而转变为l-蛋氨酸,从而可制造l-蛋氨酸。5.由丙酮酸生产hob(5-1)ges1009、ges1119、ges1120、ges1121、ges1122、ges1123、ges1127、ges1154、ges1155、ges1156、ges1157的培养在无菌条件下,将ges1009、ges1119、ges1120、ges1121、ges1122、ges1123、ges1127、ges1154、ges1155、ges1156、ges1157的甘油原种接种到包含卡那霉素25μg/ml的a琼脂培养基中,并在33℃下进行培养。将琼脂培养基上生长出的菌体接种到包含卡那霉素25μg/ml的10ml的ba培养基中,在33℃下进行振荡,培养一整夜。对所述培养液在4℃、5500xg下进行15分钟离心分离,将上清液去除。将如此般获得的湿菌体用于以下反应。(5-2)使用ges1009、ges1119、ges1120、ges1121、ges1122、ges1123、ges1127、ges1154、ges1155、ges1156、ges1157由丙酮酸生产hob将如上所述般制备的湿菌体以成为10%(w/v)的方式悬浮于bs缓冲液中。向所述菌体悬浮液中加入1.0m丙酮酸水溶液及1.2m甲醛水溶液,使它们均成为40mm,在33℃下进行培养。在培养过程中进行搅拌,以便有效率地混合氢氧化钾水溶液,且未进行通气。此外,通过所述操作,在所述湿菌体浓度下实现了厌氧条件或微好氧条件。6小时后,通过有机酸分析用液相色谱对反应液的上清液进行分析,结果在使用ges1009的反应中生成了3.6mm的hob,在使用ges1119的反应中生成了4.1mm的hob,在使用ges1120的反应中生成了2.1mm的hob,在使用ges1121的反应中生成了3.4mm的hob,在使用ges1122的反应中生成了30.5mm的hob,在使用ges1123的反应中生成了1.9mm的hob,在使用ges1127的反应中生成了18.3mm的hob,在使用ges1154的反应中生成了19.5mm的hob,在使用ges1155的反应中生成了6.5mm的hob,在使用ges1156的反应中生成了4.5mm的hob,在使用ges1157的反应中生成了2.0mm的hob。(5-3)比较例1将如上所述般制备的湿菌体以成为10%(w/v)的方式悬浮于bs缓冲液中。向所述菌体悬浮液中加入1.0m丙酮酸水溶液而使所述丙酮酸水溶液成为40mm,在33℃下进行反应。6小时后,通过有机酸分析用液相色谱对反应液的上清液进行分析,结果在任一情况下均未检测到hob。根据以上结果可知,如ges1009、ges1119、ges1120、ges1121、ges1122、ges1123、ges1127、ges1154、ges1155、ges1156、ges1157般的具有对醛缩酶进行编码的基因的菌体均通过所述酶催化丙酮酸与甲醛之间的羟醛反应而生成以hob为代表的羟醛化合物。参考资料序列表<110>绿色地球研究所株式会社<120>有机化合物的制造方法及棒状细菌<130>18f0400pct<160>147<170>patentinversion3.5<210>1<211>789<212>dna<213>大肠杆菌(escherichiacoli)<400>1atggaaaacagttttaaagcggcgctgaaagcaggccgtccgcagattggattatggctg60gggctgagcagcagctacagcgcggagttactggccggagcaggattcgactggttgttg120atcgacggtgagcacgcaccgaacaacgtacaaaccgtgctcacccagctacaggcgatt180gcgccctatcccagccagccggtagtacgtccgtcgtggaacgatccggtgcaaatcaaa240caactgctggacgtcggcacacaaaccttactggtgccgatggtacaaaacgccgacgaa300gcccgtgaagcggtacgcgccacccgttatccccccgccggtattcgcggtgtgggcagt360gcgctggctcgcgcctcgcgctggaatcgcattcctgattacctgcaaaaagccaacgat420caaatgtgcgtgctggtgcagatcgaaacgcgtgaggcaatgaagaacttaccgcagatt480ctggacgtggaaggcgtcgacggcgtgtttatcggcccggcggatctgagcgccgatatg540ggttatgccggtaatccgcagcacccggaagtacaggccgccattgagcaggcgatcgtg600cagatccgcgaagcgggcaaagcgccggggatcctgatcgccaatgagctactggcaaaa660cgctatctggaactgggcgcgctgtttgtcgccgtcggcgttgacaccaccctgctcgcc720cgcgccgccgaagcgctggcagcacggtttggcgcgcaggctacagcgattaagcccggc780gtgtattaa789<210>2<211>262<212>prt<213>大肠杆菌(escherichiacoli)<400>2metgluasnserphelysalaalaleulysalaglyargproglnile151015glyleutrpleuglyleusersersertyrseralagluleuleuala202530glyalaglypheasptrpleuleuileaspglygluhisalaproasn354045asnvalglnthrvalleuthrglnleuglnalailealaprotyrpro505560serglnprovalvalargprosertrpasnaspprovalglnilelys65707580glnleuleuaspvalglythrglnthrleuleuvalprometvalgln859095asnalaaspglualaargglualavalargalathrargtyrpropro100105110alaglyileargglyvalglyseralaleualaargalaserargtrp115120125asnargileproasptyrleuglnlysalaasnaspglnmetcysval130135140leuvalglnilegluthrargglualametlysasnleuproglnile145150155160leuaspvalgluglyvalaspglyvalpheileglyproalaaspleu165170175seralaaspmetglytyralaglyasnproglnhisprogluvalgln180185190alaalailegluglnalailevalglnileargglualaglylysala195200205proglyileleuilealaasngluleuleualalysargtyrleuglu210215220leuglyalaleuphevalalavalglyvalaspthrthrleuleuala225230235240argalaalaglualaleualaalaargpheglyalaglnalathrala245250255ilelysproglyvaltyr260<210>3<211>804<212>dna<213>大肠杆菌(escherichiacoli)<400>3atgaacgcattattaagcaatccctttaaagaacgtttacgcaagggcgaagtgcaaatt60ggtctgtggttaagctcaacgactgcctatatggcagaaattgccgccacttctggttat120gactggttgctgattgacggggagcacgcgccaaacaccattcaggatctttatcatcag180ctacaggcggtagcgccctatgccagccaacccgtgatccgtccggtggaaggcagtaaa240ccgctgattaaacaagtcctggatattggcgcgcaaactctactgatcccgatggtcgat300actgccgaacaggcacgtcaggtggtgtctgccacgcgctatcctccctacggtgagcgt360ggtgtcggggccagtgtggcacgggctgcgcgctggggacgcattgagaattacatggcg420caagttaacgattcgctttgtctgttggtgcaggtggaaagtaaaacggcactggataac480ctggacgaaatcctcgacgtcgaagggattgatggcgtgtttattggacctgcggatctt540tctgcgtcgttgggctacccggataacgccgggcacccggaagtgcagcgaattattgaa600accagtattcggcggatccgtgctgcgggtaaagcggctggttttctggctgtggctcct660gatatggcgcagcaatgcctggcgtggggagcgaactttgtcgctgttggcgttgacacg720atgctctacagcgatgccctggatcaacgactggcgatgtttaaatcaggcaaaaatggg780ccacgcataaaaggtagttattaa804<210>4<211>267<212>prt<213>大肠杆菌(escherichiacoli)<400>4metasnalaleuleuserasnprophelysgluargleuarglysgly151015gluvalglnileglyleutrpleuserserthrthralatyrmetala202530gluilealaalathrserglytyrasptrpleuleuileaspglyglu354045hisalaproasnthrileglnaspleutyrhisglnleuglnalaval505560alaprotyralaserglnprovalileargprovalgluglyserlys65707580proleuilelysglnvalleuaspileglyalaglnthrleuleuile859095prometvalaspthralagluglnalaargglnvalvalseralathr100105110argtyrproprotyrglygluargglyvalglyalaservalalaarg115120125alaalaargtrpglyargilegluasntyrmetalaglnvalasnasp130135140serleucysleuleuvalglnvalgluserlysthralaleuaspasn145150155160leuaspgluileleuaspvalgluglyileaspglyvalpheilegly165170175proalaaspleuseralaserleuglytyrproaspasnalaglyhis180185190progluvalglnargileilegluthrserileargargileargala195200205alaglylysalaalaglypheleualavalalaproaspmetalagln210215220glncysleualatrpglyalaasnphevalalavalglyvalaspthr225230235240metleutyrseraspalaleuaspglnargleualametphelysser245250255glylysasnglyproargilelysglysertyr260265<210>5<211>894<212>dna<213>大肠杆菌(escherichiacoli)<400>5atggcaacgaatttacgtggcgtaatggctgcactcctgactccttttgaccaacaacaa60gcactggataaagcgagtctgcgtcgcctggttcagttcaatattcagcagggcatcgac120ggtttatacgtgggtggttcgaccggcgaggcctttgtacaaagcctttccgagcgtgaa180caggtactggaaatcgtcgccgaagaggcgaaaggtaagattaaactcatcgcccacgtc240ggttgcgtcagcaccgccgaaagccaacaacttgcggcatcggctaaacgttatggcttc300gatgccgtctccgccgtcacgccgttctactatcctttcagctttgaagaacactgcgat360cactatcgggcaattattgattcggcggatggtttgccgatggtggtgtacaacattcca420gccctgagtggggtaaaactgaccctggatcagatcaacacacttgttacattgcctggc480gtaggtgcgctgaaacagacctctggcgatctctatcagatggagcagatccgtcgtgaa540catcctgatcttgtgctctataacggttacgacgaaatcttcgcctctggtctgctggcg600ggcgctgatggtggtatcggcagtacctacaacatcatgggctggcgctatcaggggatc660gttaaggcgctgaaagaaggcgatatccagaccgcgcagaaactgcaaactgaatgcaat720aaagtcattgatttactgatcaaaacgggcgtattccgcggcctgaaaactgtcctccat780tatatggatgtcgtttctgtgccgctgtgccgcaaaccgtttggaccggtagatgaaaaa840tatctgccagaactgaaggcgctggcccagcagttgatgcaagagcgcgggtaa894<210>6<211>297<212>prt<213>大肠杆菌(escherichiacoli)<400>6metalathrasnleuargglyvalmetalaalaleuleuthrprophe151015aspglnglnglnalaleuasplysalaserleuargargleuvalgln202530pheasnileglnglnglyileaspglyleutyrvalglyglyserthr354045glyglualaphevalglnserleusergluarggluglnvalleuglu505560ilevalalagluglualalysglylysilelysleuilealahisval65707580glycysvalserthralagluserglnglnleualaalaseralalys859095argtyrglypheaspalavalseralavalthrprophetyrtyrpro100105110pheserpheglugluhiscysasphistyrargalaileileaspser115120125alaaspglyleuprometvalvaltyrasnileproalaleusergly130135140vallysleuthrleuaspglnileasnthrleuvalthrleuprogly145150155160valglyalaleulysglnthrserglyaspleutyrglnmetglugln165170175ileargarggluhisproaspleuvalleutyrasnglytyraspglu180185190ilephealaserglyleuleualaglyalaaspglyglyileglyser195200205thrtyrasnilemetglytrpargtyrglnglyilevallysalaleu210215220lysgluglyaspileglnthralaglnlysleuglnthrglucysasn225230235240lysvalileaspleuleuilelysthrglyvalpheargglyleulys245250255thrvalleuhistyrmetaspvalvalservalproleucysarglys260265270propheglyprovalaspglulystyrleuprogluleulysalaleu275280285alaglnglnleumetglngluarggly290295<210>7<211>642<212>dna<213>大肠杆菌(escherichiacoli)<400>7atgaaaaactggaaaacaagtgcagaatcaatcctgaccaccggcccggttgtaccggtt60atcgtggtaaaaaaactggaacacgcggtgccgatggcaaaagcgttggttgctggtggg120gtgcgcgttctggaagtgactctgcgtaccgagtgtgcagttgacgctatccgtgctatc180gccaaagaagtgcctgaagcgattgtgggtgccggtacggtgctgaatccacagcagctg240gcagaagtcactgaagcgggtgcacagttcgcaattagcccgggtctgaccgagccgctg300ctgaaagctgctaccgaagggactattcctctgattccggggatcagcactgtttccgaa360ctgatgctgggtatggactacggtttgaaagagttcaaattcttcccggctgaagctaac420ggcggcgtgaaagccctgcaggcgatcgcgggtccgttctcccaggtccgtttctgcccg480acgggtggtatttctccggctaactaccgtgactacctggcgctgaaaagcgtgctgtgc540atcggtggttcctggctggttccggcagatgcgctggaagcgggcgattacgaccgcatt600actaagctggcgcgtgaagctgtagaaggcgctaagctgtaa642<210>8<211>213<212>prt<213>大肠杆菌(escherichiacoli)<400>8metlysasntrplysthrseralagluserileleuthrthrglypro151015valvalprovalilevalvallyslysleugluhisalavalpromet202530alalysalaleuvalalaglyglyvalargvalleugluvalthrleu354045argthrglucysalavalaspalaileargalailealalysgluval505560proglualailevalglyalaglythrvalleuasnproglnglnleu65707580alagluvalthrglualaglyalaglnphealaileserproglyleu859095thrgluproleuleulysalaalathrgluglythrileproleuile100105110proglyileserthrvalsergluleumetleuglymetasptyrgly115120125leulysgluphelysphepheproalaglualaasnglyglyvallys130135140alaleuglnalailealaglypropheserglnvalargphecyspro145150155160thrglyglyileserproalaasntyrargasptyrleualaleulys165170175servalleucysileglyglysertrpleuvalproalaaspalaleu180185190glualaglyasptyraspargilethrlysleualaargglualaval195200205gluglyalalysleu210<210>9<211>906<212>dna<213>大肠杆菌(escherichiacoli)<400>9atgaaaaaattcagcggcattattccaccggtatccagcacgtttcatcgtgacggaacc60cttgataaaaaggcaatgcgcgaagttgccgacttcctgattaataaaggggtcgacggg120ctgttttatctgggtaccggtggtgaatttagccaaatgaatacagcccagcgcatggca180ctcgccgaagaagctgtaaccattgtcgacgggcgagtgccggtattgattggcgtcggt240tccccttccactgacgaagcggtcaaactggcgcagcatgcgcaagcctacggcgctgat300ggtatcgtcgccatcaacccctactactggaaagtcgcaccacgaaatcttgacgactat360taccagcagatcgcccgtagcgtcaccctaccggtgatcctgtacaactttccgaatctg420acgggtcaggacttaaccccggaaaccgtgacgcgtctggctctgcaaaacgagaatatc480gttggcatcaaagacaccatcgacagcgttggtcacttgcgtacgatgatcaacacagtt540aagtcggtacgcccgtcgttttcggtattctgcggttacgatgatcatttgctgaatacg600atgctgctgagcggcgacggtgcgataaccgccagcgctaactttgctccggaactctcc660gtcggcatctaccgcgcctggcgtgaaggcgatctggcgaccgctgcgacgctgaataaa720aaactactacaactgcccgctatttacgccctcgaaacaccgtttgtctcactgatcaaa780tacagcatgcagtgtgtcgggctgcctgtagagacatattgcttaccaccgattcttgaa840gcatctgaagaagcaaaagataaagtccacgtgctgcttaccgcgcagggcattttacca900gtctaa906<210>10<211>301<212>prt<213>大肠杆菌(escherichiacoli)<400>10metlyslyspheserglyileileproprovalserserthrphehis151015argaspglythrleuasplyslysalametarggluvalalaaspphe202530leuileasnlysglyvalaspglyleuphetyrleuglythrglygly354045glupheserglnmetasnthralaglnargmetalaleualagluglu505560alavalthrilevalaspglyargvalprovalleuileglyvalgly65707580serproserthraspglualavallysleualaglnhisalaglnala859095tyrglyalaaspglyilevalalaileasnprotyrtyrtrplysval100105110alaproargasnleuaspasptyrtyrglnglnilealaargserval115120125thrleuprovalileleutyrasnpheproaspleuthrglyglnasp130135140leuthrprogluthrvalthrargleualaleuglnasngluasnile145150155160valglyilelysaspthrileaspservalglyhisleuargthrmet165170175ileasnthrvallysservalargproserpheservalphecysgly180185190tyraspasphisleuleuasnthrmetleuleuglyglyaspglyala195200205ilethralaseralaasnphealaprogluleuservalglyiletyr210215220argalatrparggluglyaspleualathralaalathrleuasnlys225230235240lysleuleuglnleuproalailetyralaleugluthrpropheval245250255serleuilelystyrsermetglncysvalglyleuprovalgluthr260265270tyrcysleuproproileleuglualasergluglualalysasplys275280285valhisvalleuleuthralaglnglyileleuproval290295300<210>11<211>618<212>dna<213>大肠杆菌(escherichiacoli)<400>11atgcagtggcaaactaaactcccgctgatcgccattttgcgcggtattacgcccgacgag60gcgctggcgcatgttggcgcggtgattgacgccgggttcgacgcggttgaaatcccgctg120aattccccacaatgggagcaaagcattcccgccatcgttgatgcgtacggcgacaaggcg180ttgattggcgcaggtacggtactgaaacctgaacaggtcgatgcgctcgccaggatgggc240tgtcagctcatcgttacgcccaatatccatagtgaagtgatccgccgtgcggtgggctac300ggcatgaccgtctgccccggctgcgcgacggcgaccgaagcctttaccgcgctcgaagcg360ggcgcgcaggcgctgaaaatatttccgtcatcggcttttggtccgcaatacatcaaagcg420ttaaaagcggtattgccatcggacatcgcagtctttgccgttggcggcgtgacgccagaa480aacctggcgcagtggatagacgcaggttgtgcaggggcgggcttaggcagcgatctctat540cgcgccgggcaatccgtagagcgcaccgcgcagcaggcagcagcatttgttaaggcgtat600cgagaggcagtgcaataa618<210>12<211>205<212>prt<213>大肠杆菌(escherichiacoli)<400>12metglntrpglnthrlysleuproleuilealaileleuargglyile151015thrproaspglualaleualahisvalglyalavalileaspalagly202530pheaspalavalgluileproleuasnserproglntrpgluglnser354045ileproalailevalaspalatyrglyasplysalaleuileglyala505560glythrvalleulysprogluglnvalaspalaleualaargmetgly65707580cysglnleuilevalthrproasnilehissergluvalileargarg859095alavalglytyrglymetthrvalcysproglycysalathralathr100105110glualaphethralaleuglualaglyalaglnalaleulysilephe115120125proserseralapheglyproglntyrilelysalaleulysalaval130135140leuproseraspilealavalphealavalglyglyvalthrproglu145150155160asnleualaglntrpileaspalaglycysalaglyalaglyleugly165170175seraspleutyrargalaglyglnservalgluargthralaglngln180185190alaalaalaphevallysalatyrargglualavalgln195200205<210>13<211>1014<212>dna<213>大肠杆菌(escherichiacoli)<400>13atgaacggtaaaaaactttatatctcggacgtcacattgcgtgacggtatgcacgccatt60cgtcatcagtattcgctggaaaacgttcgccagattgccaaagcactggacgatgcccgc120gtggattcgattgaagtggcccacggcgacggtttgcaaggttccagctttaactatggt180ttcggcgcacatagcgaccttgaatggattgaagcggcggcggatgtggtgaagcacgcc240aaaatcgcgacgttgttgctgccaggaatcggcactattcacgatctgaaaaatgcctgg300caggctggcgcgcgggtggttcgtgtggcaacgcactgtaccgaagctgatgtttccgcc360cagcatattcagtatgcccgcgagctcggaatggacaccgttggttttctgatgatgagc420catatgaccacgccggagaatctcgccaagcaggcaaagctgatggaaggctacggtgcg480acctgtatttatgtggtggattctggcggtgcgatgaacatgagcgatatccgtgaccgt540ttccgcgccctgaaagcagagctgaaaccagaaacgcaaactggcatgcacgctcaccat600aacctgagtcttggcgtggcgaactctatcgcggcggtggaagagggctgcgaccgaatc660gacgccagcctcgcgggaatgggcgcgggcgcaggtaacgcaccgctggaagtgtttatt720gccgccgcggataaactgggctggcagcatgggaccgatctctatgcgttaatggatgcc780gccgacgacctggtgcgtccgttgcaggatcgaccggtacgagtcgatcgcgaaacgctg840gcgctgggatacgctggtgtttactcgagcttcctgcgtcactgtgaaacggcggcggcg900cgttatggcttaagtgcggtggatattctcgttgagctgggcaaacgccggatggttggc960ggccaggaggatatgatcgttgacgtggcgctggatctgcgcaacaacaaataa1014<210>14<211>337<212>prt<213>大肠杆菌(escherichiacoli)<400>14metasnglylyslysleutyrileseraspvalthrleuargaspgly151015methisalailearghisglntyrserleugluasnvalargglnile202530alalysalaleuaspaspalaargvalaspserilegluvalalahis354045glyaspglyleuglnglyserserpheasntyrglypheglyalahis505560seraspleuglutrpileglualaalaalaaspvalvallyshisala65707580lysilealathrleuleuleuproglyileglythrilehisaspleu859095lysasnalatrpglnalaglyalaargvalvalargvalalathrhis100105110cysthrglualaaspvalseralaglnhisileglntyralaargglu115120125leuglymetaspthrvalglypheleumetmetserhismetthrthr130135140progluasnleualalysglnalalysleumetgluglytyrglyala145150155160thrcysiletyrvalvalaspserglyglyalametasnmetserasp165170175ileargaspargpheargalaleulysalagluleulysprogluthr180185190glnthrglymethisalahishisasnleuserleuglyvalalaasn195200205serilealaalavalglugluglycysaspargileaspalaserleu210215220alaglymetglyalaglyalaglyasnalaproleugluvalpheile225230235240alaalaalaasplysleuglytrpglnhisglythraspleutyrala245250255leumetaspalaalaaspaspleuvalargproleuglnaspargpro260265270valargvalasparggluthrleualaleuglytyralaglyvaltyr275280285serserpheleuarghiscysgluthralaalaalaargtyrglyleu290295300seralavalaspileleuvalgluleuglylysargargmetvalgly305310315320glyglngluaspmetilevalaspvalalaleuaspleuargasnasn325330335lys<210>15<211>771<212>dna<213>大肠杆菌(escherichiacoli)<400>15atgaataacgatgttttcccgaataaattcaaagccgcactggctgcgaaacaggtacaa60attggttgctggtcagcactctctaacccgattagcactgaagttcttggtttggctggg120tttgactggctggtgctggatggcgaacatgcgccaaacgatatctccacgtttattccg180cagttaatggccttgaaaggcagcgccagcgcgccagtagtgcgagtgccgaccaacgag240ccggtaattattaagcgtcttctggatatcggtttctataacttcctgattccttttgta300gaaacaaaagaggaagcagagctggcggtggcatcaacccgttacccaccggaaggcatt360cgcggcgtctccgtttctcaccgcgccaatatgtttggcaccgtggcggattatttcgct420cagtcgaacaagaacatcactattctggtccagatagaaagtcagcagggcgtagataac480gtcgatgccattgccgctaccgaaggcgtagacggcatcttcgtcggccccagcgatctg540gccgcggcattaggccatctcggcaatgcatcacacccggatgtacaaaaagcaattcag600cacatttttaaccgtgccagcgcgcacggcaaacccagcggtatcctcgcgccggtcgaa660gccgatgcgcgtcgttatctggaatggggcgcgacgtttgtggctgtcggcagcgatctc720ggcgtcttccgctctgccactcagaaactggctgatacctttaaaaaataa771<210>16<211>256<212>prt<213>大肠杆菌(escherichiacoli)<400>16metasnasnaspvalpheproasnlysphelysalaalaleualaala151015lysglnvalglnileglycystrpseralaleuserasnproileser202530thrgluvalleuglyleualaglypheasptrpleuvalleuaspgly354045gluhisalaproasnaspileserthrpheileproglnleumetala505560leulysglyseralaseralaprovalvalargvalprothrasnglu65707580provalileilelysargleuleuaspileglyphetyrasnpheleu859095ileprophevalgluthrlysgluglualagluleualavalalaser100105110thrargtyrproprogluglyileargglyvalservalserhisarg115120125alaasnmetpheglythrvalalaasptyrphealaglnserasnlys130135140asnilethrileleuvalglnilegluserglnglnglyvalaspasn145150155160valaspalailealaalathrgluglyvalaspglyilephevalgly165170175proseraspleualaalaalaleuglyhisleuglyasnalaserhis180185190proaspvalglnlysalaileglnhisilepheasnargalaserala195200205hisglylysproserglyileleualaprovalglualaaspalaarg210215220argtyrleuglutrpglyalathrphevalalavalglyseraspleu225230235240glyvalpheargseralathrglnlysleualaaspthrphelyslys245250255<210>17<211>717<212>dna<213>恶臭假单胞菌(pseudomonasputida)<400>17atgagtacgctcgtgggaaaaaccggcgttgtccttcgcaacatcgagcgagcgggcgcg60ggcctggtggacgaactggcggcgtacggtgttgccaccatccacgaggcacaagggcgc120aaagggttgctggcgccctcgatatcggcgattcagcagggcacttctgtcagcggctcg180gccgtcactgtgctggtggcgcccggggataactggatgttccacgttgctgttgaacaa240tgccgtcctagcgatgtgctggtagtggcacccagctctccctgtaccgacggctacttt300ggtgacctgctcgcaacctcgctcaaggcgcatggtgttcgtgcgctggtgatcgatgcc360ggggtgcgcgatacccgtacccttcggcaaatgggcttccccgtatggtcacgggcggtc420agcgcgcaaggcaccatcaaggaaacacttgggtcggtcaatctaccgatcatttgcggc480gggcagctggtcaaccccggtgacgtggtcgtggcggatgatgacggtgtggttattgtg540cgtcgcgatgaggtgacgcaggtgctggaggcgacccgtcggcgtgctgatctggaagag600cagaaggcgttgcgcctggccagcggcgaactcggtctggacatctacaacatgcgtccc660cgcttggccgagaaggggttacggtacatcgacagcctggatgaactgggagagtaa717<210>18<211>238<212>prt<213>恶臭假单胞菌(pseudomonasputida)<400>18metserthrleuvalglylysthrglyvalvalleuargasnileglu151015argalaglyalaglyleuvalaspgluleualaalatyrglyvalala202530thrilehisglualaglnglyarglysglyleuleualaproserile354045seralaileglnglnglythrservalserglyseralavalthrval505560leuvalalaproglyaspasntrpmetphehisvalalavalglugln65707580cysargproseraspvalleuvalvalalaproserserprocysthr859095aspglytyrpheglyaspleuleualathrserleulysalahisgly100105110valargalaleuvalileaspalaglyvalargaspthrargthrleu115120125argglnmetglypheprovaltrpserargalavalseralaglngly130135140thrilelysgluthrleuglyservalasnleuproileilecysgly145150155160glyglnleuvalasnproglyaspvalvalvalalaaspaspaspgly165170175valvalilevalargargaspgluvalthrglnvalleuglualathr180185190argargargalaaspleuglugluglnlysalaleuargleualaser195200205glygluleuglyleuaspiletyrasnmetargproargleualaglu210215220lysglyleuargtyrileaspserleuaspgluleuglyglu225230235<210>19<211>999<212>dna<213>类诺卡氏菌属菌(nocardioidessp.)<400>19atgacgtcacccgccgtgacatccgccgacattacagggctcgttggcatcgtgccgacg60ccctcgaagccgggctcggaagcgccggacgctgtagacaccgtcgacctcgacgagacc120gcgcgcatggtcgaactcatcgtcgcttccggtgttgacgtgctgctgaccaatggcacc180ttcggcgaagtcgctactctcacttatgaagaactactggcgttcaacgacacggtcatc240cgtacggtcgctaatcgcatacccgtcttctgcggggcctcgacgctgaacacccgcgac300acgatcgcccgcagcctcgccctaatggggctcggtgcgaacggtctcttcgtcgggcga360ccaatgtggctacctctcgacgacgagcagctggtgtcctactacgcggccgtgtgcgat420gccgttccggctgccgctgtcgtcgtctacgacaacactggagtgttcaagggcaaaatc480tcctccgccgcgtacgcggcgctggccgagatcccgcagatcgtggcatcgaagcatctg540ggcgtactctcgggcagcgatgcctatgcgagcgacctggccgctgtaaaaggccgcttt600cctctgttgcccaccgcggacaattggctcccctcactcgaggcattccccggcgaagtg660ccggcggcttggagcggtgatgtggcctgcggccccgaacccgtgatggcgctccgccgc720gcgatcgcggagggactctgggacgacgcccgtgccgtgcatgaagacatcgcatgggcc780acggagcccctgttcccgggcggcgatataagtaagttcatgccatacagcatccagatc840gaccgggccgagttcgaggccgccggttacatcgtgcccggccccagccggcatccctac900ggcaccgccccagccgcctacctcgaagggggcgccgaggtcggccgccgttgggcgggc960attcgccagaagtacgtcgcaactctcgccgaaccataa999<210>20<211>332<212>prt<213>类诺卡氏菌属菌(nocardioidessp.)<400>20metthrserproalavalthrseralaaspilethrglyleuvalgly151015ilevalprothrproserlysproglyserglualaproaspalaval202530aspthrvalaspleuaspgluthralaargmetvalgluleuileval354045alaserglyvalaspvalleuleuthrasnglythrpheglygluval505560alathrleuthrtyrglugluleuleualapheasnaspthrvalile65707580argthrvalalaasnargileprovalphecysglyalaserthrleu859095asnthrargaspthrilealaargserleualaleumetglyleugly100105110alaasnglyleuphevalglyargpromettrpleuproleuaspasp115120125gluglnleuvalsertyrtyralaalavalcysaspalavalproala130135140alaalavalvalvaltyraspasnthrglyvalphelysglylysile145150155160serseralaalatyralaalaleualagluileproglnilevalala165170175serlyshisleuglyvalleuserglyseraspalatyralaserasp180185190leualaalavallysglyargpheproleuleuprothralaaspasn195200205trpleuproserleuglualapheproglygluvalproalaalatrp210215220serglyaspvalalacysglyprogluprovalmetalaleuargarg225230235240alailealagluglyleutrpaspaspalaargalavalhisgluasp245250255ilealatrpalathrgluproleupheproglyglyaspileserlys260265270phemetprotyrserileglnileaspargalaglupheglualaala275280285glytyrilevalproglyproserarghisprotyrglythralapro290295300alaalatyrleugluglyglyalagluvalglyargargtrpalagly305310315320ileargglnlystyrvalalathrleualaglupro325330<210>21<211>1041<212>dna<213>伯克霍尔德氏菌(burkholderiaxenovorans)<400>21atgaagctagaaggcaaaaaagtcaccgtccacgacatgacgctgcgcgacggcatgcac60cccaagcgccaccagatgacgctggagcaaatgaaatccatcgcctgcggcctggatgcc120gcgggcatcccgctgatcgaagtcacccacggcgacggcctgggcggctcctccgtcaac180tacggctttccggcgcacagcgacgaggaatacctgggcgccgtgattccgttgatgaag240caggccaaggtcagtgccctgctcttgcccggcatcggcaccgtcgaacacctgaagatg300gccaaggacctgggcgtgaacaccatccgcgtggccacccactgcaccgaagccgatgtg360tcggagcagcacatcacccaatcgcgcaagctgggtctggacaccgtgggctttttgatg420atggcgcacatggccagcccagaaaagctggtcagccaggcactcttgatgcaaggctac480ggcgccaactgcatctacgtcaccgactcggccggctacatgctgcctgacgacgtgaaa540gcgcgcctgagtgccgtgcgtgccgcgctcaaacccgaaaccgagttgggctttcacggc600catcacaacctggccatgggcgtcgccaactcgatcgccgcgatcgaggccggggccacc660cgcatcgatgccgctgccgctggcctgggtgccggcgccggcaacacgccgatggaggtg720ttcatcgccgtatgcgcgcgcatggggatcgaaaccggagtcgatgtgttcaagatccag780gacgtggccgaagacctggtggtgccgatcatggaccatgtcatccgcatcgaccgcgac840tcgctcacgctgggctatgccggggtctattccagctttctgctgtttgccaaacgcgcc900agtgcgaagtacggcgtgccggcgcgcgacatcctggtcgagctgggacggcgcggcatg960gtcggcggccaggaagacatgattgaagacaccgccatgaccatggcacgtgagcgcggg1020ttgaccttgaccgccgcataa1041<210>22<211>346<212>prt<213>伯克霍尔德氏菌(burkholderiaxenovorans)<400>22metlysleugluglylyslysvalthrvalhisaspmetthrleuarg151015aspglymethisprolysarghisglnmetthrleugluglnmetlys202530serilealacysglyleuaspalaalaglyileproleuilegluval354045thrhisglyaspglyleuglyglyserservalasntyrglyphepro505560alahisseraspgluglutyrleuglyalavalileproleumetlys65707580glnalalysvalseralaleuleuleuproglyileglythrvalglu859095hisleulysmetalalysaspleuglyvalasnthrileargvalala100105110thrhiscysthrglualaaspvalsergluglnhisilethrglnser115120125arglysleuglyleuaspthrvalglypheleumetmetalahismet130135140alaserproglulysleuvalserglnalaleuleumetglnglytyr145150155160glyalaasncysiletyrvalthraspseralaglytyrmetleupro165170175aspaspvallysalaargleuseralavalargalaalaleulyspro180185190gluthrgluleuglyphehisglyhishisasnleualametglyval195200205alaasnserilealaalaileglualaglyalathrargileaspala210215220alaalaalaglyleuglyalaglyalaglyasnthrprometgluval225230235240pheilealavalcysalaargmetglyilegluthrglyvalaspval245250255phelysileglnaspvalalagluaspleuvalvalproilemetasp260265270hisvalileargileaspargaspserleuthrleuglytyralagly275280285valtyrserserpheleuleuphealalysargalaseralalystyr290295300glyvalproalaargaspileleuvalgluleuglyargargglymet305310315320valglyglyglngluaspmetilegluaspthralametthrmetala325330335arggluargglyleuthrleuthralaala340345<210>23<211>1587<212>dna<213>恶臭假单胞菌(pseudomonasputida)<400>23atggcttcggtacacggcaccacatacgaactcttgcgacgtcaaggcatcgatacggtc60ttcggcaatcctggctcgaacgagctcccgtttttgaaggactttccagaggactttcga120tacatcctggctttgcaggaagcgtgtgtggtgggcattgcagacggctatgcgcaagcc180agtcggaagccggctttcattaacctgcattctgctgctggtaccggcaatgctatgggt240gcactcagtaacgcctggaactcacattccccgctgatcgtcactgccggccagcagacc300agggcgatgattggcgttgaagctctgctgaccaacgtcgatgccgccaacctgccacga360ccacttgtcaaatggagctacgagcccgcaagcgcagcagaagtccctcatgcgatgagc420agggctatccatatggcaagcatggcgccacaaggccctgtctatctttcggtgccatat480gacgattgggataaggatgctgatcctcagtcccaccacctttttgatcgccatgtcagt540tcatcagtacgcctgaacgaccaggatctcgatattctggtgaaagctctcaacagcgca600tccaacccggcgatcgtcctgggcccggacgtcgacgcagcaaatgcgaacgcagactgc660gtcatgttggccgaacgcctcaaagctccggtttgggttgcgccatccgctccacgctgc720ccattccctacccgtcatccttgcttccgtggattgatgccagctggcatcgcagcgatt780tctcagctgctcgaaggtcacgatgtggttttggtaatcggcgctccagtgttccgttac840caccaatacgacccaggtcaatatctcaaacctggcacgcgattgatttcggtgacctgc900gacccgctcgaagctgcacgcgcgccaatgggcgatgcgatcgtggcagacattggtgcg960atggctagcgctcttgccaacttggttgaagagagcagccgccagctcccaactgcagct1020ccggaacccgcgaaggttgaccaagacgctggccgacttcacccagagacagtgttcgac1080acactgaacgacatggccccggagaatgcgatttacctgaacgagtcgacttcaacgacc1140gcccaaatgtggcagcgcctgaacatgcgcaaccctggtagctactacttctgtgcagct1200ggcggactgggcttcgccctgcctgcagcaattggcgttcaactcgcagaacccgagcga1260caagtcatcgccgtcattggcgacggatcggcgaactacagcattagtgcgttgtggact1320gcagctcagtacaacatccccactatcttcgtgatcatgaacaacggcacctacggtgcg1380ttgcgatggtttgccggcgttctcgaagcagaaaacgttcctgggctggatgtgccaggg1440atcgacttccgcgcactcgccaagggctatggtgtccaagcgctgaaagccgacaacctt1500gagcagctcaagggttcgctacaagaagcgctttctgccaaaggcccggtacttatcgaa1560gtaagcaccgtaagcccggtgaagtga1587<210>24<211>528<212>prt<213>恶臭假单胞菌(pseudomonasputida)<400>24metalaservalhisglythrthrtyrgluleuleuargargglngly151015ileaspthrvalpheglyasnproglyserasngluleupropheleu202530lysasppheprogluasppheargtyrileleualaleuglngluala354045cysvalvalglyilealaaspglytyralaglnalaserarglyspro505560alapheileasnleuhisseralaalaglythrglyasnalametgly65707580alaleuserasnalatrpasnserhisserproleuilevalthrala859095glyglnglnthrargalametileglyvalglualaleuleuthrasn100105110valaspalaalaasnleuproargproleuvallystrpsertyrglu115120125proalaseralaalagluvalprohisalametserargalailehis130135140metalasermetalaproglnglyprovaltyrleuservalprotyr145150155160aspasptrpasplysaspalaaspproglnserhishisleupheasp165170175arghisvalserserservalargleuasnaspglnaspleuaspile180185190leuvallysalaleuasnseralaserasnproalailevalleugly195200205proaspvalaspalaalaasnalaasnalaaspcysvalmetleuala210215220gluargleulysalaprovaltrpvalalaproseralaproargcys225230235240propheprothrarghisprocyspheargglyleumetproalagly245250255ilealaalaileserglnleuleugluglyhisaspvalvalleuval260265270ileglyalaprovalpheargtyrhisglntyraspproglyglntyr275280285leulysproglythrargleuileservalthrcysaspproleuglu290295300alaalaargalaprometglyaspalailevalalaaspileglyala305310315320metalaseralaleualaasnleuvalglugluserserargglnleu325330335prothralaalaprogluproalalysvalaspglnaspalaglyarg340345350leuhisprogluthrvalpheaspthrleuasnaspmetalaproglu355360365asnalailetyrleuasngluserthrserthrthralaglnmettrp370375380glnargleuasnmetargasnproglysertyrtyrphecysalaala385390395400glyglyleuglyphealaleuproalaalaileglyvalglnleuala405410415gluprogluargglnvalilealavalileglyaspglyseralaasn420425430tyrserileseralaleutrpthralaalaglntyrasnileprothr435440445ilephevalilemetasnasnglythrtyrglyalaleuargtrpphe450455460alaglyvalleuglualagluasnvalproglyleuaspvalprogly465470475480ileasppheargalaleualalysglytyrglyvalglnalaleulys485490495alaaspasnleugluglnleulysglyserleuglnglualaleuser500505510alalysglyprovalleuilegluvalserthrvalserprovallys515520525<210>25<211>1164<212>dna<213>肺炎克雷伯菌(klebsiellapneumoniae)<400>25atgagctatcgtatgttcgattatctggtgccaaacgttaacttttttggccccaacgcc60atttccgtagtcggcgaacgctgccagctgctgggggggaaaaaagccctgctggtcacc120gacaaaggcctgcgggcaattaaagatggcgcggtggacaaaaccctgcattatctgcgg180gaggccgggatcgaggtggcgatctttgacggcgtcgagccgaacccgaaagacaccaac240gtgcgcgacggcctcgctgtgtttcgccgcgaacagtgcgacatcatcgtcaccgtgggc300ggcggcagcccgcacgattgcggcaaaggcatcggcatcgccgccacccatgagggcgat360ctgtaccagtatgccggaatcgagaccctgaccaacccgctgccgcctatcgtcgcggtc420aataccaccgccggcaccgccagcgaggtcacccgccactgcgtcctgaccaacaccgaa480accaaagtgaagtttgtgatcgtcagctggcgcaacctgccgtcggtctctatcaacgat540ccactgctgatgatcggtaaaccggccgccctgaccgcggcgaccgggatggatgccctg600acccacgccgtagaggcctatatctccaaagacgctaacccggtgacggacgccgccgcc660atgcaggcgatccgcctcatcgcccgcaacctgcgccaggccgtggccctcggcagcaat720ctgcaggcgcgggaaaacatggcctatgcctctctgctggccgggatggctttcaataac780gccaacctcggctacgtgcacgccatggcacaccagctgggcggcctgtacgacatgccg840cacggcgtggccaacgctgtcctgctgccgcatgtggcgcgctacaacctgatcgccaac900ccggagaaattcgccgatattgctgaactgatgggcgaaaatatcaccggactgtccact960ctcgacgcggcggaaaaagccatcgccgctatcacgcgtctgtcgatggatatcggtatt1020ccgcagcatctgcgcgatctgggagtaaaagaggccgacttcccctacatggcggagatg1080gctctgaaagacggcaatgcgttctcgaacccgcgtaaaggcaacgagcaggagattgcc1140gcgattttccgccaggcattctaa1164<210>26<211>387<212>prt<213>肺炎克雷伯菌(klebsiellapneumoniae)<400>26metsertyrargmetpheasptyrleuvalproasnvalasnphephe151015glyproasnalaileservalvalglygluargcysglnleuleugly202530glylyslysalaleuleuvalthrasplysglyleuargalailelys354045aspglyalavalasplysthrleuhistyrleuargglualaglyile505560gluvalalailepheaspglyvalgluproasnprolysaspthrasn65707580valargaspglyleualavalpheargarggluglncysaspileile859095valthrvalglyglyglyserprohisaspcysglylysglyilegly100105110ilealaalathrhisgluglyaspleutyrglntyralaglyileglu115120125thrleuthrasnproleuproproilevalalavalasnthrthrala130135140glythralasergluvalthrarghiscysvalleuthrasnthrglu145150155160thrlysvallysphevalilevalsertrpargasnleuproserval165170175serileasnaspproleuleumetileglylysproalaalaleuthr180185190alaalathrglymetaspalaleuthrhisalavalglualatyrile195200205serlysaspalaasnprovalthraspalaalaalametglnalaile210215220argleuilealaargasnleuargglnalavalalaleuglyserasn225230235240leuglnalaarggluasnmetalatyralaserleuleualaglymet245250255alapheasnasnalaasnleuglytyrvalhisalametalahisgln260265270leuglyglyleutyraspmetprohisglyvalalaasnalavalleu275280285leuprohisvalalaargtyrasnleuilealaasnproglulysphe290295300alaaspilealagluleumetglygluasnilethrglyleuserthr305310315320leuaspalaalaglulysalailealaalailethrargleusermet325330335aspileglyileproglnhisleuargaspleuglyvallysgluala340345350asppheprotyrmetalaglumetalaleulysaspglyasnalaphe355360365serasnproarglysglyasngluglngluilealaalailephearg370375380glnalaphe385<210>27<211>978<212>dna<213>乳酸乳球菌(lactococcuslactis)<400>27atggctgataaacaacgtaagaaagttatccttgttggtgacggtgctgtaggttcatca60tacgcttttgcccttgttaaccaaggaattgcacaagaattaggtattgttgaccttttt120aaagaaaaaactcaaggggatgcagaagacctttctcatgccttggcatttacatcacct180aaaaagatttactctgcagactactctgatgcaagcgacgctgacctcgttgtcttgact240tctggtgctccatgcaaaccaggtgaaactcgtcttgaccttgttgaaaaaaatcttcgt300attactaaagatgttgtaactaaaattgttgcttcaggattcaaaggaatcttcctcgtt360gctgctaacccagttgacatcttgacatacgcaacttggaaattctctggtttccctaaa420aaccgtgttgtaggttcaggtacttcacttgatactgcacgttttcgtcaagcattggct480gaaaaagttgacgttgatgctcgttcaatccacgcatacatcatgggtgaacatggtgac540tcagaatttgctgtttggtcacacgctaacgttgctggtgttaaattggaacaatggttc600caagaaaatgactaccttaacgaagcagaaatcgttgaattgtttgaatctgtacgtgat660gcagcttactcaatcatcgctaaaaaaggtgcaacattctacggtgtggctgtagccctt720gctcgtattactaaagcaattcttgatgatgaacatgcagtacttcctgtatcagtattc780caagatggacaatatggcgtaagcgactgctaccttggtcaaccagctgtagttggtgct840gaaggtgttgttaacccaattcacattccattgaacgatgctgaaatgcaaaaaatggaa900gcttctggagctcaattgaaagctatcatcgatgaggcttttgctaaagaagaatttgct960tctgcagttaaaaactaa978<210>28<211>325<212>prt<213>乳酸乳球菌(lactococcuslactis)<400>28metalaasplysglnarglyslysvalileleuvalglyaspglyala151015valglysersertyralaphealaleuvalasnglnglyilealagln202530gluleuglyilevalaspleuphelysglulysthrglnglyaspala354045gluaspleuserhisalaleualaphethrserprolyslysiletyr505560seralaasptyrseraspalaseraspalaaspleuvalvalleuthr65707580serglyalaprocyslysproglygluthrargleuaspleuvalglu859095lysasnleuargilethrlysaspvalvalthrlysilevalalaser100105110glyphelysglyilepheleuvalalaalaasnprovalaspileleu115120125thrtyralathrtrplyspheserglypheprolysasnargvalval130135140glyserglythrserleuaspthralaargpheargglnalaleuala145150155160glulysvalaspvalaspalaargserilehisalatyrilemetgly165170175gluhisglyaspsergluphealavaltrpserhisalaasnvalala180185190glyvallysleugluglntrppheglngluasnasptyrleuasnglu195200205alagluilevalgluleuphegluservalargaspalaalatyrser210215220ileilealalyslysglyalathrphetyrglyvalalavalalaleu225230235240alaargilethrlysalaileleuaspaspgluhisalavalleupro245250255valservalpheglnaspglyglntyrglyvalseraspcystyrleu260265270glyglnproalavalvalglyalagluglyvalvalasnproilehis275280285ileproleuasnaspalaglumetglnlysmetglualaserglyala290295300glnleulysalaileileaspglualaphealalysgluglupheala305310315320seralavallysasn325<210>29<211>1095<212>dna<213>球形赖氨酸芽孢杆菌(lysinibacillussphaericus)<400>29atggaaatcttcaagtatatggaaaagtatgattatgaacaattggtattttgccaagac60gaagcatctgggttaaaagcgattatcgctatccatgacacaacacttggaccagcatta120ggtggtgctcgtatgtggacctacgcgacagaagaaaatgcgattgaggatgcattaaga180ttagcacgcgggatgacatataaaaatgcagctgctggtttaaaccttggcggtggaaaa240acggtcattattggggacccatttaaagataaaaacgaagaaatgttccgtgctttaggt300cgtttcattcaaggattaaacggtcgctatattaccgctgaagatgttggtacaaccgta360acagatatggatttaatccatgaggaaacaaattacgttacaggtatatcgccagcgttt420ggttcatcgggtaatccttcaccagtaactgcttatggcgtttatcgtggcatgaaagca480gcggcgaaagaagcatttggtacggatatgctagaaggtcgtactatatcggtacaaggg540ctaggaaacgtagcttacaagctttgcgagtatttacataatgaaggtgcaaaacttgta600gtaacagatattaaccaagcggctattgatcgtgttgtcaatgattttggcgctacagca660gttgcacctgatgaaatctattcacaagaagtcgatattttctcaccgtgtgcacttggc720gcaattttaaatgacgaaacgattccgcaattaaaagcaaaagttattgctggttctgct780aataaccaactacaagattcacgacatggagattatttacacgagctaggcattgtttat840gcacctgactatgtcattaatgcaggtggtgtaataaatgtcgcggacgaattatatggc900tataatcgtgaacgagcgttgaaacgtgtagatggtatttacgatagtattgaaaaaatc960tttgaaatttccaaacgtgatagtattccaacatatgttgcggcaaatcgtttggcagaa1020gaacgtattgctcgtgtagcgaaatcgcgtagtcagttcttaaaaaatgaaaaaaatatt1080ttgaacggccgttaa1095<210>30<211>364<212>prt<213>球形赖氨酸芽孢杆菌(lysinibacillussphaericus)<400>30metgluilephelystyrmetglulystyrasptyrgluglnleuval151015phecysglnaspglualaserglyleulysalaileilealailehis202530aspthrthrleuglyproalaleuglyglyalaargmettrpthrtyr354045alathrglugluasnalailegluaspalaleuargleualaarggly505560metthrtyrlysasnalaalaalaglyleuasnleuglyglyglylys65707580thrvalileileglyaspprophelysasplysasngluglumetphe859095argalaleuglyargpheileglnglyleuasnglyargtyrilethr100105110alagluaspvalglythrthrvalthraspmetaspleuilehisglu115120125gluthrasntyrvalthrglyileserproalapheglysersergly130135140asnproserprovalthralatyrglyvaltyrargglymetlysala145150155160alaalalysglualapheglythraspmetleugluglyargthrile165170175servalglnglyleuglyasnvalalatyrlysleucysglutyrleu180185190hisasngluglyalalysleuvalvalthraspileasnglnalaala195200205ileaspargvalvalasnasppheglyalathralavalalaproasp210215220gluiletyrserglngluvalaspilepheserprocysalaleugly225230235240alaileleuasnaspgluthrileproglnleulysalalysvalile245250255alaglyseralaasnasnglnleuglnaspserarghisglyasptyr260265270leuhisgluleuglyilevaltyralaproasptyrvalileasnala275280285glyglyvalileasnvalalaaspgluleutyrglytyrasnargglu290295300argalaleulysargvalaspglyiletyraspserileglulysile305310315320phegluileserlysargaspserileprothrtyrvalalaalaasn325330335argleualaglugluargilealaargvalalalysserargsergln340345350pheleulysasnglulysasnileleuasnglyarg355360<210>31<211>1143<212>dna<213>栗褐芽孢杆菌(bacillusbadius)<400>31atgagcttagtagaaaaaacatccatcataaaagatttcactctttttgaaaaaatgtct60gaacatgaacaagttgttttttgcaacgatccggcgacaggactaagggccattatcgct120attcatgacaccacactcggacctgcgctcggcggctgccgcatgcagccttataacagt180gtggaagaagcattggaagatgctcttcgcctttccaaaggaatgacttacaaatgcgcg240gcgtccgatgtcgactttggcggcggaaaagcagtcattatcggtgatccgcagaaagat300aaatctccagaactgttccgcgcgtttggccaatttgttgattcgcttggcggccgtttc360tatacaggtactgatatgggaacgaatatggaagatttcattcacgccatgaaagaaaca420aactgcattgttggggtgccggaagcttacggcggcggcggagattcctctattccaact480gccatgggtgtcctgtacggcattaaagcaaccaacaaaatgttgtttggcaaggacgat540cttggcggcgtcacttatgccattcaaggacttggcaaagtaggctacaaagtagcggaa600gggctgctcgaagaaggtgctcatttatttgtaacggatattaacgagcaaagcttggag660gctatccaggaaaaagcaaaaacaacatccggttctgtcacggtagtagcgagcgatgaa720atttattcccaggaagccgatgtgttcgttccgtgtgcatttggcggcgttgttaatgat780gaaacgatgaagcagttcaaggtgaaagcaatcgccggttcagccaacaatcagctgctt840acggaggatcacggcagacagcttgcagacaaaggcattctgtatgctccggattatatt900gttaactctggcggtctgatccaagtagccgacgaattgtatgaggtgaacaaagaacgc960gtgcttgcgaagacgaagcatatttacgacgcaattcttgaagtgtaccagcaagcggaa1020ttagatcaaatcaccacaatggaagcagccaacagaatgtgtgagcaaagaatggcggca1080agaggccgacgcaacagcttctttacttcttctgttaagccaaaatgggatattcgcaac1140taa1143<210>32<211>380<212>prt<213>栗褐芽孢杆菌(bacillusbadius)<400>32metserleuvalglulysthrserileilelysaspphethrleuphe151015glulysmetsergluhisgluglnvalvalphecysasnaspproala202530thrglyleuargalaileilealailehisaspthrthrleuglypro354045alaleuglyglycysargmetglnprotyrasnservalglugluala505560leugluaspalaleuargleuserlysglymetthrtyrlyscysala65707580alaseraspvalasppheglyglyglylysalavalileileglyasp859095proglnlysasplysserprogluleupheargalapheglyglnphe100105110valaspserleuglyglyargphetyrthrglythraspmetglythr115120125asnmetgluasppheilehisalametlysgluthrasncysileval130135140glyvalproglualatyrglyglyglyglyaspserserileprothr145150155160alametglyvalleutyrglyilelysalathrasnlysmetleuphe165170175glylysaspaspleuglyglyvalthrtyralaileglnglyleugly180185190lysvalglytyrlysvalalagluglyleuleuglugluglyalahis195200205leuphevalthraspileasngluglnserleuglualaileglnglu210215220lysalalysthrthrserglyservalthrvalvalalaseraspglu225230235240iletyrserglnglualaaspvalphevalprocysalapheglygly245250255valvalasnaspgluthrmetlysglnphelysvallysalaileala260265270glyseralaasnasnglnleuleuthrgluasphisglyargglnleu275280285alaasplysglyileleutyralaproasptyrilevalasnsergly290295300glyleuileglnvalalaaspgluleutyrgluvalasnlysgluarg305310315320valleualalysthrlyshisiletyraspalaileleugluvaltyr325330335glnglnalagluleuaspglnilethrthrmetglualaalaasnarg340345350metcysgluglnargmetalaalaargglyargargasnserphephe355360365thrserservallysprolystrpaspileargasn370375380<210>33<211>1116<212>dna<213>费氏链霉菌(streptomycesfradiae)<400>33atgaccgacgcgtcccaccccaccgccgccgacgacctcggcgccctctccaccctcttc60cgctccgagcagggcggccacgagcgggtcctgctctgccaggaccgcgagagcggcctc120aaggccgtcatcgccctccactcgaccgccctgggcccggccctcggcggcacccgcttc180catgcctacgcctccgacgaggaggccgtgctcgacgccctgaacctcgcccgcggcatg240tcgtacaagaacgccctcgccgggctgccgcacggcggcggcaaggccgtgatcatcggc300agccccgccccggtctccgagggcgggctgaagagcgaggcgctgctccgcgcgtacggc360cgcttcgtcgcctccctggacggccgttacgtcacggcctgtgacgtcggcacgtatgtc420gccgacatggacgtcgtcgcccgcgagtgccggtggaccaccggccgctccccggagaac480ggcggcgccggcgactcctccgtcctcaccgccttcggcgtcttccagggcatgcgggcc540agcgctcaggcgctgtggggcgagcccaccctgcgcggccggaccgtcggcgtggccggg600gtcggcaaggtcggccaccacctggtggaccacctggtggaggacggtgcccgggtcgtg660gtcaccgatgtgcggccggagagcgtggagcgggtgcgcgcccggcacccgcgggtggtg720gccgtgcccgacacggagtccctgatccgcgcggacctggacgtctacgccccctgcgcc780ctcggcggtgccctgaacgacgacacggtgcccgcgctgaccgcgcgcgtcgtctgcggc840gcggccaacaaccagctcgcccacccgggcgtcgaaaaggacctcgccggccgcggcatc900ctgtacgcgcccgactacgtcgtcaacgccggtggcgtgatccaggtcgccgacgagctg960ctcggttttgatttcgaccgggcgaaggccaaggcggcgcagatcttcgacacgacgctg1020gccatattcgaccgcgccaggaccgacggcgtcccgcccgccgtcgccgccgaccggatc1080gccgagcagcgcatggcggaggcccgcaccgtctaa1116<210>34<211>371<212>prt<213>费氏链霉菌(streptomycesfradiae)<400>34metthraspalaserhisprothralaalaaspaspleuglyalaleu151015serthrleupheargsergluglnglyglyhisgluargvalleuleu202530cysglnasparggluserglyleulysalavalilealaleuhisser354045thralaleuglyproalaleuglyglythrargphehisalatyrala505560seraspgluglualavalleuaspalaleuasnleualaargglymet65707580sertyrlysasnalaleualaglyleuprohisglyglyglylysala859095valileileglyserproalaprovalsergluglyglyleulysser100105110glualaleuleuargalatyrglyargphevalalaserleuaspgly115120125argtyrvalthralacysaspvalglythrtyrvalalaaspmetasp130135140valvalalaargglucysargtrpthrthrglyargserprogluasn145150155160glyglyalaglyaspserservalleuthralapheglyvalphegln165170175glymetargalaseralaglnalaleutrpglygluprothrleuarg180185190glyargthrvalglyvalalaglyvalglylysvalglyhishisleu195200205valasphisleuvalgluaspglyalaargvalvalvalthraspval210215220argprogluservalgluargvalargalaarghisproargvalval225230235240alavalproaspthrgluserleuileargalaaspleuaspvaltyr245250255alaprocysalaleuglyglyalaleuasnaspaspthrvalproala260265270leuthralaargvalvalcysglyalaalaasnasnglnleualahis275280285proglyvalglulysaspleualaglyargglyileleutyralapro290295300asptyrvalvalasnalaglyglyvalileglnvalalaaspgluleu305310315320leuglypheasppheaspargalalysalalysalaalaglnilephe325330335aspthrthrleualailepheaspargalaargthraspglyvalpro340345350proalavalalaalaaspargilealagluglnargmetalagluala355360365argthrval370<210>35<211>1491<212>dna<213>阿拉伯芥(arabidopsisthaliana)<400>35atggtgcgccagctgtccatcaaggcacgccgtaactgctccaacatcggcgtggcacag60atcgtggcagcaaagtggtccaacaacccatcctccgcactgccatccgcagcagcagca120gccgcaacctcctccgcatccgcagtgtcctccgcagcatccgcagctgccgcatcctcc180gctgcagcagcaccagtggcagcagccccaccagtggtgctgaagtccgtggatgaagag240gtggtggtggcagaagaaggcatccgcgaaaagatcggctccgtgcagctgaccgattcc300aagcactccttcttgtcctccgatggctccctgaccgtgcacgcaggcgaacgcttgggt360cgcggtatcgtgaccgatgcaatcaccaccccagtggtgaacacctccgcatactttttc420aagaaaaccgcagaactgatcgacttcaaagaaaagcgctccgtgtccttcgaatacggt480cgctacggcaacccaaccaccgtggtgctggaagataagatctccgcactggaaggcgca540gaatccaccctggtgatggcatccggcatgtgcgcatccaccgtgatgctgctggccctg600gtgccagcaggcggtcacatcgtgaccaccaccgattgctaccgcaagacccgtatcttc660atggaaaactttctgccaaagctgggcatcaccgtgaccgtgatcgatccagcagatatc720gcaggcctggaagcagcagtgaacgaattcaaggtgtccctgttcttcaccgaatcccca780accaacccattcctgcgctgcgtggatatcgaactggtgtccaagatctgccacaagcgt840ggcaccctggtgtgcatcgatggcaccttcgcaaccccactgaaccagaaggcactggca900cttggcgcagatctggtggtgcactccgcaaccaagtacatcggtggccacaacgatgtg960ctggcaggctgcatctgcggctccctgaagctggtgtccgaaatccgcaacctgcaccac1020gtgctgggtggcaccctgaacccaaacgcagcatacctgatcatccgtggcatgaaaacc1080ctgcacttgcgcgtgcagcagcagaactccaccgcattccgcatggcagaaatcctggaa1140gcacacccaaaggtgtcccacgtgtactacccaggcctgccatcccacccagaacacgaa1200ctggcaaagcgccagatgaccggcttcggtggcgtggtgtccttcgagatcgatggcgat1260atcgaaaccaccatcaagttcgtggattccctgaagatcccatacattgcaccatccttc1320ggtggctgcgaatccatcgtggatcagccagcaatcatgtcctactgggatctcccacaa1380gaagaacgcctgaagtacggcatcaaggataacctggtgcgcttctccttcggcgtggaa1440gatttcgaagatgtgaaggcagatatcctgcaggcactcgaagcaatctaa1491<210>36<211>496<212>prt<213>阿拉伯芥(arabidopsisthaliana)<400>36metvalargglnleuserilelysalaargargasncysserasnile151015glyvalalaglnilevalalaalalystrpserasnasnproserser202530alaleuproseralaalaalaalaalaalathrserseralaserala354045valserseralaalaseralaalaalaalaserseralaalaalaala505560provalalaalaalaproprovalvalleulysservalaspgluglu65707580valvalvalalaglugluglyileargglulysileglyservalgln859095leuthraspserlyshisserpheleuserseraspglyserleuthr100105110valhisalaglygluargleuglyargglyilevalthraspalaile115120125thrthrprovalvalasnthrseralatyrphephelyslysthrala130135140gluleuileaspphelysglulysargservalserpheglutyrgly145150155160argtyrglyasnprothrthrvalvalleugluasplysileserala165170175leugluglyalagluserthrleuvalmetalaserglymetcysala180185190serthrvalmetleuleualaleuvalproalaglyglyhisileval195200205thrthrthraspcystyrarglysthrargilephemetgluasnphe210215220leuprolysleuglyilethrvalthrvalileaspproalaaspile225230235240alaglyleuglualaalavalasngluphelysvalserleuphephe245250255thrgluserprothrasnpropheleuargcysvalaspilegluleu260265270valserlysilecyshislysargglythrleuvalcysileaspgly275280285thrphealathrproleuasnglnlysalaleualaleuglyalaasp290295300leuvalvalhisseralathrlystyrileglyglyhisasnaspval305310315320leualaglycysilecysglyserleulysleuvalsergluilearg325330335asnleuhishisvalleuglyglythrleuasnproasnalaalatyr340345350leuileileargglymetlysthrleuhisleuargvalglnglngln355360365asnserthralapheargmetalagluileleuglualahisprolys370375380valserhisvaltyrtyrproglyleuproserhisprogluhisglu385390395400leualalysargglnmetthrglypheglyglyvalvalserpheglu405410415ileaspglyaspilegluthrthrilelysphevalaspserleulys420425430ileprotyrilealaproserpheglyglycysgluserilevalasp435440445glnproalailemetsertyrtrpaspleuproglnglugluargleu450455460lystyrglyilelysaspasnleuvalargpheserpheglyvalglu465470475480aspphegluaspvallysalaaspileleuglnalaleuglualaile485490495<210>37<211>30<212>dna<213>人工序列(artificialsequence)<220><223>用于sacb基因的正向引物<400>37ggggaagcttgacgtccacatatacctgcc30<210>38<211>24<212>dna<213>人工序列(artificialsequence)<220><223>用于sacb基因的反向引物<400>38attcggatccgtatccacctttac24<210>39<211>26<212>dna<213>人工序列(artificialsequence)<220><223>用于删除sacb基因上的kpni识别部位的正向引物<400>39tgaacagataccatttgccgttcatt26<210>40<211>26<212>dna<213>人工序列(artificialsequence)<220><223>用于删除sacb基因上的kpni识别部位的反向引物<400>40aatggtatctgttcactgactcccgc26<210>41<211>35<212>dna<213>人工序列(artificialsequence)<220><223>用于ppc基因删除的上-正向引物<400>41ccatgattacgaattcgggaaacttttttaagaaa35<210>42<211>20<212>dna<213>人工序列(artificialsequence)<220><223>用于ppc基因删除的上-反向引物<400>42taactactttaaacactctt20<210>43<211>35<212>dna<213>人工序列(artificialsequence)<220><223>用于ppc基因删除的下-正向引物<400>43tgtttaaagtagttatccagccggctgggtagtac35<210>44<211>35<212>dna<213>人工序列(artificialsequence)<220><223>用于ppc基因删除的下-反向引物<400>44taccgagctcgaattgaagtattcaaggggatttc35<210>45<211>35<212>dna<213>人工序列(artificialsequence)<220><223>用于ldha基因删除的上-正向引物<400>45gacggccagtgaatttttcatacgaccacgggcta35<210>46<211>20<212>dna<213>人工序列(artificialsequence)<220><223>用于ldha基因删除的上-反向引物<400>46gacaatcttgttaccgacgg20<210>47<211>35<212>dna<213>人工序列(artificialsequence)<220><223>用于ldha基因删除的下-正向引物<400>47ggtaacaagattgtccattccgcaaataccctgcg35<210>48<211>35<212>dna<213>人工序列(artificialsequence)<220><223>用于ldha基因删除的下-反向引物<400>48taccgagctcgaattgggacgttgatgacgctgcc35<210>49<211>35<212>dna<213>人工序列(artificialsequence)<220><223>用于pyc基因删除的上-正向引物<400>49gacggccagtgaattgttgatgactgttggttcca35<210>50<211>26<212>dna<213>人工序列(artificialsequence)<220><223>用于pyc基因删除的上-反向引物<400>50ctcgagtagagtaattattcctttca26<210>51<211>35<212>dna<213>人工序列(artificialsequence)<220><223>用于pyc基因删除的下-正向引物<400>51attactctactcgagacctttctgtaaaaagcccc35<210>52<211>35<212>dna<213>人工序列(artificialsequence)<220><223>用于pyc基因删除的下-反向引物<400>52taccgagctcgaattcacgatccgccgggcagcct35<210>53<211>33<212>dna<213>人工序列(artificialsequence)<220><223>用于poxb基因删除的上-正向引物<400>53gacggccagtgaaaacgttaatgaggaaaaccg33<210>54<211>20<212>dna<213>人工序列(artificialsequence)<220><223>用于poxb基因删除的上-反向引物<400>54aattaattgttctgcgtagc20<210>55<211>41<212>dna<213>人工序列(artificialsequence)<220><223>用于poxb基因删除的下-正向引物<400>55gcagaacaattaattctcgagtcgaacataaggaatattcc41<210>56<211>35<212>dna<213>人工序列(artificialsequence)<220><223>用于poxb基因删除的下-反向引物<400>56taccgagctcgaattttccaggtacggaaagtgcc35<210>57<211>35<212>dna<213>人工序列(artificialsequence)<220><223>用于alaa基因删除的上-正向引物<400>57gacggccagtgaatttttcaccgaagtgacaccta35<210>58<211>26<212>dna<213>人工序列(artificialsequence)<220><223>用于alaa基因删除的上-反向引物<400>58ctcgagccgctcaatgttgccacttt26<210>59<211>35<212>dna<213>人工序列(artificialsequence)<220><223>用于alaa基因删除的下-正向引物<400>59attgagcggctcgagtagttgttaggattcaccac35<210>60<211>35<212>dna<213>人工序列(artificialsequence)<220><223>用于alaa基因删除的下-反向引物<400>60taccgagctcgaattgttccctggaaattgtttgc35<210>61<211>35<212>dna<213>人工序列(artificialsequence)<220><223>用于ilvb基因删除的上-正向引物<400>61gacggccagtgaattaccgcacgcgaccagttatt35<210>62<211>26<212>dna<213>人工序列(artificialsequence)<220><223>用于ilvb基因删除的上-反向引物<400>62gctagcgactttctggctcctttact26<210>63<211>35<212>dna<213>人工序列(artificialsequence)<220><223>用于ilvb基因删除的下-正向引物<400>63cagaaagtcgctagcggagagacccaagatggcta35<210>64<211>35<212>dna<213>人工序列(artificialsequence)<220><223>用于ilvb基因删除的下-反向引物<400>64taccgagctcgaattctcgatgtcgttggtgaaga35<210>65<211>35<212>dna<213>人工序列(artificialsequence)<220><223>用于cg0931基因删除的上-正向引物<400>65gacggccagtgaattagcagggacgaaagtcggga35<210>66<211>26<212>dna<213>人工序列(artificialsequence)<220><223>用于cg0931基因删除的上-反向引物<400>66ctcgaggcagctactatatttgatcc26<210>67<211>35<212>dna<213>人工序列(artificialsequence)<220><223>用于cg0931基因删除的下-正向引物<400>67agtagctgcctcgagtttgaacaggttgttggggg35<210>68<211>35<212>dna<213>人工序列(artificialsequence)<220><223>用于cg0931基因删除的下-反向引物<400>68taccgagctcgaattatcgacggcaaaacgcccaa35<210>69<211>35<212>dna<213>人工序列(artificialsequence)<220><223>用于adhe基因删除的上-正向引物<400>69gtgaattcgagctcgcagaagcagatcttgcaatc35<210>70<211>32<212>dna<213>人工序列(artificialsequence)<220><223>用于adhe基因删除的上-反向引物<400>70cttcctcgagaattccaggcactacagtgctc32<210>71<211>32<212>dna<213>人工序列(artificialsequence)<220><223>用于adhe基因删除的下-正向引物<400>71gaattctcgaggaagaggctttcaacaccatg32<210>72<211>35<212>dna<213>人工序列(artificialsequence)<220><223>用于adhe基因删除的下-反向引物<400>72aggtggatacggatcggaacaaagtgtctccagag35<210>73<211>37<212>dna<213>人工序列(artificialsequence)<220><223>用于adhe基因删除的上-正向引物<400>73gtgaattcgagctcgattcaggatttgcttcgcgacg37<210>74<211>37<212>dna<213>人工序列(artificialsequence)<220><223>用于adhe基因删除的下-反向引物<400>74aggtggatacggatcacagtgtccggatcatctgctg37<210>75<211>35<212>dna<213>人工序列(artificialsequence)<220><223>用于ald基因删除的上-正向引物<400>75gtgaattcgagctcgccgaaacctcaaagaatccc35<210>76<211>32<212>dna<213>人工序列(artificialsequence)<220><223>用于ald基因删除的上-反向引物<400>76ggtactcgagtcctggatttgcgtagacagtc32<210>77<211>32<212>dna<213>人工序列(artificialsequence)<220><223>用于ald基因删除的下-正向引物<400>77caggactcgagtaccagcagaccaagaacctg32<210>78<211>35<212>dna<213>人工序列(artificialsequence)<220><223>用于ald基因删除的下-反向引物<400>78aggtggatacggatcgatctccagaggtttcaagc35<210>79<211>38<212>dna<213>人工序列(artificialsequence)<220><223>用于ald基因删除的上-正向引物<400>79gtgaattcgagctcgaacgccagatggtcgtactttgc38<210>80<211>38<212>dna<213>人工序列(artificialsequence)<220><223>用于ald基因删除的下-反向引物<400>80aggtggatacggatcttcaacaccgctgatttcctacg38<210>81<211>39<212>dna<213>人工序列(artificialsequence)<220><223>用于knr基因的正向引物<400>81cggtaccgtcgacgatatcgaggtctgcctcgtgaagaa39<210>82<211>35<212>dna<213>人工序列(artificialsequence)<220><223>用于knr基因的反向引物<400>82gcctttttacggttcgatttattcaacaaagccgc35<210>83<211>35<212>dna<213>人工序列(artificialsequence)<220><223>用于pucori的正向引物<400>83gaaccgtaaaaaggccgcgttgctggcgtttttcc35<210>84<211>35<212>dna<213>人工序列(artificialsequence)<220><223>用于pucori的反向引物<400>84gcggccgcgtagaaaagatcaaaggatcttcttga35<210>85<211>35<212>dna<213>人工序列(artificialsequence)<220><223>用于pcg1ori的正向引物<400>85tttctacgcggccgcccatggtcgtcacagagctg35<210>86<211>40<212>dna<213>人工序列(artificialsequence)<220><223>用于pcg1ori的反向引物<400>86tcgtcgacggtaccggatccttgggagcagtccttgtgcg40<210>87<211>35<212>dna<213>人工序列(artificialsequence)<220><223>用于pgapa的正向引物<400>87ctgctcccaaggatcgaagaaatttagatgattga35<210>88<211>39<212>dna<213>人工序列(artificialsequence)<220><223>用于pgapa的反向引物<400>88ccgtcgacgatatcatatggtgtctcctctaaagattgt39<210>89<211>39<212>dna<213>人工序列(artificialsequence)<220><223>用于trrnb的正向引物<400>89tgatatcgtcgacggatcctgcctggcggcagtagcgcg39<210>90<211>35<212>dna<213>人工序列(artificialsequence)<220><223>用于trrnb的反向引物<400>90gaggcagacctcgataaaaaggccatccgtcagga35<210>91<211>35<212>dna<213>人工序列(artificialsequence)<220><223>用于ec_hpai的正向引物<400>91cgcgcggcagccatatggaaaacagttttaaagcg35<210>92<211>37<212>dna<213>人工序列(artificialsequence)<220><223>用于ec_hpai的反向引物<400>92ggatcctcgagcatattaatacacgccgggcttaatc37<210>93<211>36<212>dna<213>人工序列(artificialsequence)<220><223>用于ec_hpai的正向引物<400>93agaggagacaccatatgggcagcagccatcatcatc36<210>94<211>38<212>dna<213>人工序列(artificialsequence)<220><223>用于ec_hpai的反向引物<400>94ccgccaggcaggatccttaatacacgccgggcttaatc38<210>95<211>37<212>dna<213>人工序列(artificialsequence)<220><223>用于pgapa-hpai-trrnb的正向引物<400>95gcctggaattctcgagaaggactgctcccaaggatcg37<210>96<211>34<212>dna<213>人工序列(artificialsequence)<220><223>用于pgapa-hpai-trrnb的反向引物<400>96aagcctcttcctcgatcttcacgaggcagacctc34<210>97<211>37<212>dna<213>人工序列(artificialsequence)<220><223>用于pgapa-hpai-trrnb的正向引物<400>97aaatccaggactcgagaaggactgctcccaaggatcg37<210>98<211>34<212>dna<213>人工序列(artificialsequence)<220><223>用于pgapa-hpai-trrnb的反向引物<400>98tctgctggtactcgatcttcacgaggcagacctc34<210>99<211>34<212>dna<213>人工序列(artificialsequence)<220><223>用于ec_rhma的正向引物<400>99agaggagacaccatatgaacgcattattaagcaa34<210>100<211>41<212>dna<213>人工序列(artificialsequence)<220><223>用于ec_rhma的反向引物<400>100ccgccaggcaggatcagatcttaataactaccttttatgcg41<210>101<211>34<212>dna<213>人工序列(artificialsequence)<220><223>用于ec_nana的正向引物<400>101agaggagacaccatatggcaacgaatttacgtgg34<210>102<211>38<212>dna<213>人工序列(artificialsequence)<220><223>用于ec_nana的反向引物<400>102ccgccaggcaggatccttacccgcgctcttgcatcaac38<210>103<211>35<212>dna<213>人工序列(artificialsequence)<220><223>用于pcase1ori的正向引物<400>103tttctacgcggccgccactggaagggttcttcagg35<210>104<211>40<212>dna<213>人工序列(artificialsequence)<220><223>用于pcase1ori的反向引物<400>104tcgtcgacggtaccggatccctgacttggttacgatggac40<210>105<211>35<212>dna<213>人工序列(artificialsequence)<220><223>用于pldha的正向引物<400>105accaagtcagggatcgcggaactagctctgcaatg35<210>106<211>39<212>dna<213>人工序列(artificialsequence)<220><223>用于pldha的反向引物<400>106ccgtcgacgatatcatatgcgatcccacttcctgatttc39<210>107<211>39<212>dna<213>人工序列(artificialsequence)<220><223>用于spr基因的正向引物<400>107cggtaccgtcgacgatatctctagaccagccaggacaga39<210>108<211>35<212>dna<213>人工序列(artificialsequence)<220><223>用于spr基因的反向引物<400>108gcctttttacggttcctcgagggttatttgccgac35<210>109<211>35<212>dna<213>人工序列(artificialsequence)<220><223>用于trrnb的反向引物<400>109ggctggtctagagataaaaaggccatccgtcagga35<210>110<211>34<212>dna<213>人工序列(artificialsequence)<220><223>用于pp_mdlc的正向引物<400>110cgcgcggcagccatatggcttcggtacacggcac34<210>111<211>37<212>dna<213>人工序列(artificialsequence)<220><223>用于pp_mdlc的反向引物<400>111ggatcctcgagcatatcacttcaccgggcttacggtg37<210>112<211>34<212>dna<213>人工序列(artificialsequence)<220><223>用于pp_mdlc的正向引物<400>112agaggagacaccatatggcttcggtacacggcac34<210>113<211>36<212>dna<213>人工序列(artificialsequence)<220><223>用于pp_mdlc的反向引物<400>113gtcgacgatatcatatcacttcaccgggcttacggt36<210>114<211>39<212>dna<213>人工序列(artificialsequence)<220><223>用于kp_dhat的正向引物<400>114cgcgcggcagccatatgagctatcgtatgttcgattatc39<210>115<211>38<212>dna<213>人工序列(artificialsequence)<220><223>用于kp_dhat的反向引物<400>115ggatcctcgagcatattagaatgcctggcggaaaatcg38<210>116<211>38<212>dna<213>人工序列(artificialsequence)<220><223>用于ll_ldha的正向引物<400>116cgcgcggcagccatatggctgataaacaacgtaagaaa38<210>117<211>38<212>dna<213>人工序列(artificialsequence)<220><223>用于ll_ldha的反向引物<400>117ggatcctcgagcatattagtttttaactgcagaagcaa38<210>118<211>27<212>dna<213>人工序列(artificialsequence)<220><223>用于ll_ldha的正向引物<400>118gctccatgcaaaccaggtgaaactcgt27<210>119<211>27<212>dna<213>人工序列(artificialsequence)<220><223>用于ll_ldha的反向引物<400>119tggtttgcatggagcaccagaagtcaa27<210>120<211>38<212>dna<213>人工序列(artificialsequence)<220><223>用于ll_ldha的正向引物<400>120aagtgggatcgcatatggctgataaacaacgtaagaaa38<210>121<211>39<212>dna<213>人工序列(artificialsequence)<220><223>用于ll_ldha的反向引物<400>121ccgccaggcaggatccttagtttttaactgcagaagcaa39<210>122<211>35<212>dna<213>人工序列(artificialsequence)<220><223>用于ls_leudh的正向引物<400>122cgcgcggcagccatatggaaatcttcaagtatatg35<210>123<211>40<212>dna<213>人工序列(artificialsequence)<220><223>用于ls_leudh的反向引物<400>123ggatcctcgagcatattaacggccgttcaaaatatttttt40<210>124<211>36<212>dna<213>人工序列(artificialsequence)<220><223>用于ls_leudh的正向引物<400>124aagtgggatcgcatatggaaatcttcaagtatatgg36<210>125<211>40<212>dna<213>人工序列(artificialsequence)<220><223>用于ls_leudh的反向引物<400>125ccgccaggcaggatccttaacggccgttcaaaatattttt40<210>126<211>37<212>dna<213>人工序列(artificialsequence)<220><223>用于sf_valdh的正向引物<400>126cgcgcggcagccatatgaccgacgcgtcccaccccac37<210>127<211>40<212>dna<213>人工序列(artificialsequence)<220><223>用于sf_valdh的反向引物<400>127ggatcctcgagcatattagacggtgcgggcctccgccatg40<210>128<211>34<212>dna<213>人工序列(artificialsequence)<220><223>用于bb_phedh的正向引物<400>128cgcgcggcagccatatgagcttagtagaaaaaac34<210>129<211>38<212>dna<213>人工序列(artificialsequence)<220><223>用于bb_phedh的反向引物<400>129ggatcctcgagcatattagttgcgaatatcccattttg38<210>130<211>31<212>dna<213>人工序列(artificialsequence)<220><223>用于atcgs的正向引物<400>130aagtgggatcgcatatggtgcgccagctgtc31<210>131<211>39<212>dna<213>人工序列(artificialsequence)<220><223>用于atcgs的反向引物<400>131gtcgacgatatcatattagattgcttcgagtgcctgcag39<210>132<211>34<212>dna<213>人工序列(artificialsequence)<220><223>用于ec_eda的正向引物<400>132agaggagacaccatatgaaaaactggaaaacaag34<210>133<211>36<212>dna<213>人工序列(artificialsequence)<220><223>用于ec_eda的反向引物<400>133ccgccaggcaggatccttacagcttagcgccttcta36<210>134<211>34<212>dna<213>人工序列(artificialsequence)<220><223>用于ec_yjhh的正向引物<400>134agaggagacaccatatgaaaaaattcagcggcat34<210>135<211>38<212>dna<213>人工序列(artificialsequence)<220><223>用于ec_yjhh的反向引物<400>135ccgccaggcaggatccttagactggtaaaatgccctgc38<210>136<211>34<212>dna<213>人工序列(artificialsequence)<220><223>用于ec_dgoa的正向引物<400>136agaggagacaccatatgcagtggcaaactaaact34<210>137<211>38<212>dna<213>人工序列(artificialsequence)<220><223>用于ec_dgoa的反向引物<400>137ccgccaggcaggatccttattgcactgcctctcgatac38<210>138<211>34<212>dna<213>人工序列(artificialsequence)<220><223>用于ec_mhpfe的正向引物<400>138agaggagacaccatatgagtaagcgtaaagtcgc34<210>139<211>36<212>dna<213>人工序列(artificialsequence)<220><223>用于ec_mhpfe的反向引物<400>139ccgccaggcaggatccttatttgttgttgcgcagat36<210>140<211>34<212>dna<213>人工序列(artificialsequence)<220><223>用于ec_garl的正向引物<400>140agaggagacaccatatgaataacgatgttttccc34<210>141<211>36<212>dna<213>人工序列(artificialsequence)<220><223>用于ec_garl的反向引物<400>141ccgccaggcaggatccttattttttaaaggtatcag36<210>142<211>34<212>dna<213>人工序列(artificialsequence)<220><223>用于pp_galc的正向引物<400>142agaggagacaccatatgagtacgctcgtgggaaa34<210>143<211>37<212>dna<213>人工序列(artificialsequence)<220><223>用于pp_galc的反向引物<400>143ccgccaggcaggatccttactctcccagttcatccag37<210>144<211>34<212>dna<213>人工序列(artificialsequence)<220><223>用于ns_phdj的正向引物<400>144agaggagacaccatatgacgtcacccgccgtgac34<210>145<211>37<212>dna<213>人工序列(artificialsequence)<220><223>用于ns_phdj的反向引物<400>145ccgccaggcaggatccttatggttcggcgagagttgc37<210>146<211>34<212>dna<213>人工序列(artificialsequence)<220><223>用于bx_bphji的正向引物<400>146agaggagacaccatatgacgaaaaaaatcaaatg34<210>147<211>38<212>dna<213>人工序列(artificialsequence)<220><223>用于bx_bphji的反向引物<400>147ccgccaggcaggatccttatgcggcggtcaaggtcaac38当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1