一种鸡粪便污染的微生物溯源方法与流程
本发明涉及微生物溯源技术领域,具体涉及一种鸡粪便污染的微生物溯源方法。
背景技术:
随着禽类养殖业的繁荣发展,鸡粪便的产生日益增加。鸡的粪便因雨水冲刷或人为管理不善,将会流入地表水中,对水体环境造成一定的污染。而且鸡粪便中含有大量的致病菌,可能会对人体健康造成一定的威胁。如何快速鉴别水体中是否存在鸡粪便污染,对水体和人类健康保护均具有重要的意义。
微生物溯源是一种利用基因标记物特异性地区分来自不同动物粪便污染的技术。根据鸡粪源标记物能够特异性的识别来自鸡粪便的污染。
但是,现有鸡粪源标记物要么无法对鸡粪便污染准确识别,要么不能对污染进行定量。另外,现有标记物大多没有在我国进行过验证,其在我国的适用性存在不确定性。以上这些因素对鸡粪源标记物在我国的实际应用造成了困难。
因此,发明一种适用于我国的且能够特异性检测鸡粪源污染物并定量的微生物溯源方法是本领域技术人员亟需解决的问题。
技术实现要素:
有鉴于此,本发明提供了一种鸡粪便污染的微生物溯源方法。将两种在分别在鸡粪便污染定性和定量方面表现较好的标记物进行结合使用,在得到高准确的定性效果的同时也获得定量效果,并适用于我国的实际应用。
为了实现上述目的,本发明采用如下技术方案:
一种鸡粪便污染的微生物溯源引物组,包括ckmito1-g、ckmito1-d、ckmiton1-g、ckmiton1-d、nd5-f、nd5-r和nd5-p,引物序列为:
ckmito1-g:5’-accctatttgactccctcaa-3’,seqidno:1所示;
ckmito1-d:5’-atgtcgaccaggggtttatg-3’,seqidno:2所示;
ckmiton1-g:5’-cccccacactaacaagcaat-3’,seqidno:3所示;
ckmiton1-d:5’-ggttgtaaggtggtcgtgat-3’,seqidno:4所示;
nd5-f:5’-acctcccccaactagc-3’,seqidno:5所示;
nd5-r:5’-ttgccaatggttaggcaggag-3’,seqidno:6所示;
nd5-p:5’-tcaacccatgccttctt-3’,seqidno:7所示;
其中,nd5-p的5′端标记荧光染料6-fam、3′端标记mgb基团。
本发明还提供了一种基于上述引物组的试剂盒,包括反应液、工作标准品和阳性对照。
优选的:反应液包括包括10×extaqbuffer、2×taqmanenvironmentalmastermix2.0、dntpmixture、extaq酶、上游引物、下游引物、探针和无菌水。
本发明还提供了一种鸡粪便污染的微生物溯源方法,包括下列步骤:
(1)巢式pcr:
(s1)以ckmito1-g/d为引物,对检测样品进行第一步pcr反应;
(s2)以第一步pcr反应中显阳性的扩增产物为模板,以ckmiton1-g/d为引物进行第二步pcr反应,确定显阳性的dna样品;
(2)荧光定量pcr反应,对步骤(s2)显阳性的粪便dna样品进行定量测定。
优选的:步骤(1)第一步和第二步pcr反应体系:4μl10×extaqbuffer、2μldntpmixture、0.35μl5u/μlextaq酶、终浓度为200nm的上游引物、终浓度为200nm的下游引物、1μl的dna模板,加无菌水至25μl。
优选的:步骤(1)第一步和第二步pcr反应条件如下:94℃预变性5min;95℃变性40s,55℃退火1min,72℃延伸1min,共40个循环。循环结束后保持72℃共6min。
反应结束后,将目的片段使用1%的琼脂糖在恒压100v,电泳时间40min的条件下进行电泳,随后观察目的条带是否存在进而判断是否存在污染物。
优选的:步骤(2)荧光定量pcr反应体系:10μl2×taqmanenvironmentalmastermix2.0,终浓度为900nm的上游引物nd5-f、终浓度为900nm的下游引物nd5-r、终浓度为250nm的探针nd5-p、2μl的dna模板,加无菌水至20μl。
优选的:步骤(2)荧光定量pcr反应条件如下:50℃预变性2min;95℃预变性10min;95℃变性15s,60℃退火和延伸1min,共40个循环。
检测信号在退火和延伸阶段收集。
经由上述的技术方案可知,与现有技术相比,本发明公开提供了一种鸡粪便污染的微生物溯源方法,取的技术效果为解决了国内外无法对鸡粪便污染进行高度识别并定量的现状,使用本发明的引物组和检测顺序,对鸡粪便污染的检测准确率高、特异性好且能够定量。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
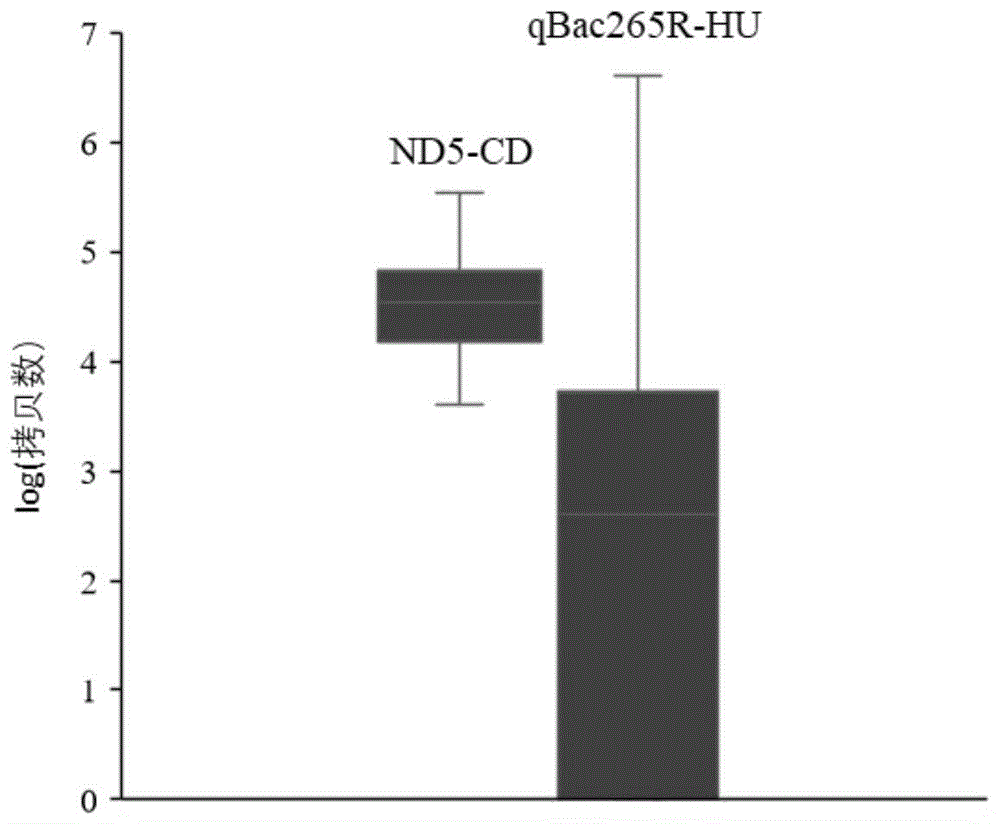
图1附图为本发明中使用的标记物nd5-cd和qbac265r-hu对75个鸡粪便样品进行定量检测的结果示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明实施例公开了一种鸡粪便污染的微生物溯源方法。
所涉及的单一药品、组分均为市售渠道采购,例如,10×extaqbuffer(mg2+plus)来源为takarabio,otsu,japan;dntpmixture来源为takarabio,otsu,japan;qiaampdnastoolminikit来源为qiagen,hilden,germany;试剂盒onesteptmpcrinhibitorremovalkit来源为zymoresearchcorps,irvine,ca,usa等,未提及的方法为常规实验方法,未提及的试验设备为常规实验设备,对其品牌不做限定,在此不再一一赘述。
实施例1
样品的采集
为使样品具有代表性,共在内蒙古、北京、河南、江西和广东5个地区采集了共计148份样品,包括75份鸡粪便样品(采集自25个不同的养殖场)和73份非鸡粪便样品。其中,73份非鸡粪便样品包括10份鸭粪便样品、14份鹅粪便样品、6份鸽子粪便样品、10份猪粪便样品、6份狗粪便样品、6份马粪便样品、5份驴粪便样品、6份牛粪便样品和10份羊粪便样品。样品采集完成后,使用干冰将样品运送回实验室,并保存于-80℃冰箱内。
实施例2
dna的提取
①取180-220mg粪便样品,按照说明书要求使用qiaampdnastoolminikit(qiagen,hilden,germany)dna提取试剂盒提取样品dna。
②使用试剂盒onesteptmpcrinhibitorremovalkit(zymoresearchcorps,irvine,ca,usa)去除dna样品中的抑制剂。
③使用nanodrop2000spectrophotometer(thermofishertechnologies,fostercity,ca,usa)测定dna样品的浓度。
实施例3
引物组的准备
该发明为两种标记物ckmito和nd5-cd的结合,这两种标记物对应的信息见表1。其中,ckmito标记物包括ckmito1和ckmiton1,使用巢式pcr的方法进行检测。该标记物被用于检测鸡粪便的污染并且具有良好的特异性和敏感性,但是该标记物无法对来自鸡粪便的污染进行定量;nd5-cd标记物可利用荧光定量pcr技术对鸡和鸭的粪便污染进行定量检测,但是该标记物无法准确判断样品污染源是否为鸡粪便。基于上述情况,遂将两者进行结合以准确检测并定量鸡粪便污染。此外,为了说明该结合的指示效果和定量效果,还加入了对比标记物qc160f-hu。
表1标记物信息
注:表1中nd5-p的5′端标记荧光染料6-fam、3′端标记mgb基团。
实施例4
工作标准品的制备:含有标记物nd5-cd或qc160f-hu目标基因片段的克隆子,具体准备过程如下:
①扩增目的片段。使用引物nd5-f/r或qc160f-hu/qbac265r-hu以鸡粪便样品dna为模板进行常规pcr实验,反应体系如下:5μl10xextaqbuffer(mg2+plus)(takarabio,otsu,japan),4μldntpmixture(各2.5mm),终浓度为500nm的引物nd5-f/r或终浓度为300nm的引物qc160f-hu/qbac265r-hu,0.25μl5u/μltakaraextaq,2μl的dna模板,加无菌水至50μl。反应条件如下:94℃预变性3min;94℃变性30s,54℃退火30s,72℃延伸40s,共35个循环;72℃延伸10min。得到目的片段。
②回收目的片段。将目的片段使用1%的琼脂糖在恒压100v,电泳时间40min的条件下进行电泳,使用sanprep柱式dna胶回收试剂盒(生工生物,上海,中国)纯化目的片段。
③重组质粒。将纯化后的目的片段插入到pucm-t质粒载体中,将重组质粒导入到大肠杆菌感受态细胞top10中过夜培养。使用蓝白斑对重组质粒进行筛选,选择颜色为白色的菌落进行下一步实验。
④目的片段的测序。使用t载体pcr产物克隆试剂盒(生工生物,上海,中国)提取培养后的重组质粒的dna,然后使用引物m13f/r对阳性克隆子进行测序,其中m13f的核苷酸序列(5’-3’)为:gttgtaaaacgacggccag,seqidno:10;m13r的核苷酸序列(5’-3’)为:caggaaacagctatgac,seqidno:11。
⑤目的片段序列的验证。标记物nd5-cd克隆子所含的目的基因序列为tacctcccccaactagccttcctccacatctcaacccatgccttctttaaagctatattattcctatgctccggcctaattatccacagcctcaatggagaacaagacatccgcaaaataggatgtctacaaaaaaccctcccaataaccacctcctgcctaaccattggca,seqidno:12所示;一方面,该序列包含探针nd5-p的序列tcaacccatgccttctt,seqidno:7所示,另一方面,将序列在ncbi上的blast(https://blast.ncbi.nlm.nih.gov/blast.cgi)结果表明该序列与鸡的线粒体dna相似。说明该序列的克隆子可以用做nd5-cd荧光定量pcr实验的工作标准品。标记物qc160f-hu克隆子所含的目的基因序列为tccgttaccccgcctactacctaatggaacgcacccccctcccgtaccgtaaatactttagtcaggtttacatgcgaactcctgacatcatcgggtattaatctccctt,seqidno:13所示,将序列在ncbi上的blast(https://blast.ncbi.nlm.nih.gov/blast.cgi),结果表明该序列与鸡粪便样品的16srrna基因相似。
实施例5
一种鸡粪便污染的微生物溯源方法,其特征在于,包括下列步骤:
(1)巢式pcr:
(s1)以ckmito1-g/d为引物,对检测样品进行第一步pcr反应;
(s2)以第一步pcr反应中显阳性的扩增产物为模板,以ckmiton1-g/d为引物进行第二步反应pcr,确定显阳性dna样品;
(2)荧光定量pcr,对步骤(s2)显阳性的粪便dna样品进行定量测定。
其中,步骤(1)第一步和第二步pcr反应体系均为:
4μl10×extaqbuffer、2μldntpmixture、0.35μl5u/μlextaq酶、终浓度为200nm的上游引物、终浓度为200nm的下游引物、1μl的dna模板,加无菌水至25μl。
步骤(1)第一步和第二步pcr反应条件均为:94℃预变性5min;95℃变性40s,55℃退火1min,72℃延伸1min,共40个循环。循环结束后保持72℃共6min。
步骤(2)荧光定量pcr反应体系:10μl2×taqmanenvironmentalmastermix2.0,终浓度为900nm的上游引物nd5-f、终浓度为900nm的下游引物nd5-r、终浓度为250nm的探针nd5-p、2μl的dna模板,加无菌水至20μl。
步骤(2)荧光定量pcr反应条件如下:50℃预变性2min;95℃预变性10min;95℃变性15s,60℃退火和延伸1min,共40个循环。
对比实验
(1)标记物定性效果评估
对比标记物qbac265r-hu,使用荧光定量pcr(sybr)进行检测。
反应体系:10μlsybrpremixextaqii(tlirnasehplus)(takarabio,otsu,japan)、终浓度为300nm的上游引物、终浓度为300nm的下游引物、2μl的dna模板,加无菌水至20μl。
反应条件:95℃预变形30s;95℃变形5s,60℃退火和延伸共34s。扩增信号在退火和延伸阶段收集,利用溶解曲线确定扩增产物的特异性。
按实施例5对待样品进行检测,结果见表2。
表2标记物指示效果对比
ckmito标记物对鸡粪便样品的敏感和特异性分别为:
nd5-cd标记物对鸡粪便样品的敏感和特异性分别为:
qbac265r-hu标记物对鸡粪便样品的敏感和特异性分别为:
式中:tp(真阳性)为目标宿主显阳性的数量;fn(假阴性)为目标宿主显阴性的数量;tn(真阴性)为非目标宿主显阴性的数量;fp(假阳性)为非目标宿主显阳性的数量。
由定性结果可以看出,标记物ckmito对鸡粪便样品表现出高敏感性(93%)和特异性(100%);在nd5-cd实验中,鸡粪便的特异性仅为68%,无法准确排除来自非鸡的粪便污染;在qbac265r-hu实验中,鸡粪便的敏感性仅为59%,无法准确识别来自鸡粪便的污染。所以,标记物ckmito在定性评估中表现最好。
(2)标记物定量效果评估
使用实施例4中获得的工作标准品作为nd5-cd和qbac265r-hu荧光定量pcr实验的标准品,实验性能见表3。
表3荧光定量pcr实验性能
nd5-cd实验的标准曲线r2为0.999,且实验效率为96.4%,说明其可以准确反映样品中的污染情况。利用标记物nd5-cd对75个鸡粪便样品进行定量检测,所有鸡粪便样品均为阳性,检测结果见图1。本批次样品的定量结果为4.51±0.62sd拷贝数(平均数±标准方差)。定量结果以荧光定量pcr实验结果中的拷贝数进行log处理得出。
qbac265r-hu实验标准曲线的r2也为0.999,且实验效率在92.5%,说明其实验结果也很可信。利用标记物qbac265r-hu对75个鸡粪便样品,仅有44个鸡粪便样品为阳性(检测结果见图1),阳性样品的定量结果为3.64±1.07sd(平均数±标准方差)。定量结果以荧光定量pcr实验结果中的拷贝数进行log处理得出。
qbac265r-hu定量检测效果与预估存在较明显的差异,其在我国的适用性存在问题,检测效果不能满足要求。
(3)标记物的结合使用效果评估
从定性和定量结果可以看出,无法使用单一标记物对鸡粪便污染进行准确定性和定量分析。因此,可将上述三种标记物进行两两结合以评估结合后的检测效果。
结合1(ckmito+nd5-cd)。检测步骤如下:(1)使用ckmito标记物对疑似污染源进行定性分析,初步确定样品是否被鸡粪便污染,通过该步骤可使检测到93%的污染样品,排除掉100%的非鸡粪便污染样品;(2)使用nd5-cd标记物对上步检测到的鸡粪便污染样品进行定量,基于nd5-cd标记物对鸡粪便样品的敏感性为100%,总样品中的93%会得到定量结果。
结合2(ckmito+qbac265r-hu)。检测步骤如下:(1)使用ckmito标记物对疑似污染源进行定性分析,初步确定样品是否被鸡粪便污染,通过该步骤可使检测到93%的污染样品,排除掉100%的非鸡粪便污染样品;(2)使用标记物qbac265r-hu对上一步中检测到的鸡粪便污染样品进行定量,基于qbac265r-hu对鸡粪便样品59%的敏感性,最多会有59%的样品得到定量结果。
结合3(qbac265r-hu+nd5-cd)。因为nd5-cd为鸡和鸭特异性标记物,所以不能使用它先进行定性分析,因此使用鸡粪源标记物qbac265r-hu进行定性分析,检测步骤如下:(1)使用qbac265r-hu对疑似污染源进行定性分析,初步确定样品是否被鸡粪便污染,通过该步骤可使检测到59%的污染样品,排除掉93%的非鸡粪便污染样品;(2)使用nd5-cd标记物对上步检测到的鸡粪便污染样品进行定量,基于nd5-cd标记物对鸡粪便样品的敏感性为100%,总样品中的59%会得到定量结果。
结果表明,随意更换通用检测引物或改变检测步骤时,不能达到检测目的,而在对鸡粪便样品进行检测时,标记物ckmito和nd5-cd分别在定性和定量方面表现出优异的组合鉴定效果,尤其适用于我国样本的定性定量检测,因此按实施例的实验步骤将二者结合使用对鸡粪便污染的检测效果最好。
实施例6
一种基于实施例3制备的引物组的试剂盒,包括反应液、工作标准品和阳性对照。
反应液包括10×extaqbuffer、2×taqmanenvironmentalmastermix2.0、dntpmixture、extaq酶、上游引物、下游引物、探针和无菌水。
工作标准品按实施例4方法制备。
阳性标准品为确定含有鸡粪目标dna的样品。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
序列表
<110>中国科学院大学
<120>一种鸡粪便污染的微生物溯源方法
<160>13
<170>siposequencelisting1.0
<210>1
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>1
accctatttgactccctcaa20
<210>2
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>2
atgtcgaccaggggtttatg20
<210>3
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>3
cccccacactaacaagcaat20
<210>4
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>4
ggttgtaaggtggtcgtgat20
<210>5
<211>16
<212>dna
<213>人工序列(artificialsequence)
<400>5
acctcccccaactagc16
<210>6
<211>21
<212>dna
<213>人工序列(artificialsequence)
<400>6
ttgccaatggttaggcaggag21
<210>7
<211>17
<212>dna
<213>人工序列(artificialsequence)
<400>7
tcaacccatgccttctt17
<210>8
<211>24
<212>dna
<213>人工序列(artificialsequence)
<400>8
aagggagattaatacccgatgatg24
<210>9
<211>19
<212>dna
<213>人工序列(artificialsequence)
<400>9
ccgttaccccgcctactac19
<210>10
<211>19
<212>dna
<213>人工序列(artificialsequence)
<400>10
gttgtaaaacgacggccag19
<210>11
<211>17
<212>dna
<213>人工序列(artificialsequence)
<400>11
caggaaacagctatgac17
<210>12
<211>172
<212>dna
<213>人工序列(artificialsequence)
<400>12
tacctcccccaactagccttcctccacatctcaacccatgccttctttaaagctatatta60
ttcctatgctccggcctaattatccacagcctcaatggagaacaagacatccgcaaaata120
ggatgtctacaaaaaaccctcccaataaccacctcctgcctaaccattggca172
<210>13
<211>109
<212>dna
<213>人工序列(artificialsequence)
<400>13
tccgttaccccgcctactacctaatggaacgcacccccctcccgtaccgtaaatacttta60
gtcaggtttacatgcgaactcctgacatcatcgggtattaatctccctt109
- 还没有人留言评论。精彩留言会获得点赞!