一种β冠状病毒抗原、其制备方法和应用与流程
本发明涉及生物医药技术领域,具体涉及一种β冠状病毒抗原、其制备方法和应用。
背景技术:
冠状病毒属于冠状病毒科冠状病毒属,是有囊膜的正链rna病毒,在所有rna病毒中其基因组最大,动物和人类都是冠状病毒的宿主。冠状病毒主要感染哺乳动物和鸟类的呼吸道和消化道,目前已知的有7种冠状病毒感染人,其中四种引起不严重的感冒(hcov-229e,hcov-nl63,oc43和hku1),对全球公共卫生威胁最大的有三种,分别是2002-2003年爆发的严重呼吸综合征冠状病毒(sars-cov);2012年爆发并持续至今的中东呼吸综合征冠状病毒(mers-cov);以及2019年暴发的新型冠状病毒(2019-ncov),这三种都属于β冠状病毒。
中东呼吸综合征(mers)是由中东呼吸综合征冠状病毒(mers-cov)感染所致的疾病。2012年6月沙特阿拉伯发现第一例mers病例,并从病例痰液标本中分离到一种新的冠状病毒。这种病毒随后被国际病毒分类委员会冠状病毒小组命名为mers-cov。这种病毒在中东地区传播开来,并传至亚洲,非洲,欧洲和北美洲等地。据who统计,截止到2015年10月6日,在世界范围内,感染人数1589例,死亡人数567例,死亡率为35.6%(http://www.who.int/entity/emergencies/mers-cov/en/)。尤其是2015年5、6月间由中东输入到韩国的mers疫情,造成了186人感染,36人死亡的结果。甚至有1例mers病例输入到我国,给世界公共卫生体系带来了严重威胁。mers-cov病毒和2003年爆发的sars病毒同属于beta-冠状病毒亚属,却有着比sars-cov更高的致死率。mers-cov可能通过气溶胶的形式传播,因此很难防控。在中东许多国家的单峰驼的血清里能检测出mers-cov的中和抗体,提示单峰驼是mers-cov的中间宿主,而单峰驼在中东国家是重要的交通工具。因此,从2012年mers-cov被发现以来,在中东地区偶发性的mers-cov感染人事件一直没有中断。由此,随着国际交流的日益频繁,mers在全球传播的风险一直存在。目前世界上仍然没有疫苗和有效的治疗手段。因此,开发一种安全、有效的针对mers-cov的疫苗十分紧迫和重要。
2019年,出现了不明原因的肺炎病例,经过病毒的电镜图鉴定,确定是冠状病毒,暂时命名为2019新型冠状病毒(2019novelcoronavirus,2019-ncov),后又被命名为sars-cov-2。新型冠状病毒可以通过呼吸道和飞沫途径在人与人之间传播,也存在通过空气和消化道传播的可能。传染源主要是感染了新型冠状病毒的患者,但是不排除无症状的感染者也是传播源的可能,感染该病毒后可能不会立即发病,病毒的潜伏期较长,1-14天,这对疾病的防控造成困难。新型冠状病毒进入人体后,和sars类似,通过血管紧张素转酶2(ace2)进入细胞,感染人体,导致病人出现发烧,干咳以及肌肉疼等临床症状,少数人还会出现鼻塞,咽痛,腹泻等症状,严重的患者快速进展为急性呼吸窘迫综合征、脓毒症休克、难以纠正的代谢性酸中毒和出凝血功能障碍,造成生命危险。暂时还没有特异性药物,也没有疫苗可以预防,只能使用对症支持治疗。
此外,一些其他的冠状病毒也引发许多严重的动物疾病,尤其对农业牲畜和宠物带来严重威胁。比如,猪传染性胃肠炎病毒(tgev)可以引发猪的严重腹泻,死亡率极高;其缺失病毒猪呼吸道冠状病毒(prcv)可以引起猪严重的呼吸道疾病;猫腹膜炎病毒(fipv)可引起猫腹膜炎和腹水聚集,致死率很高;犬冠状病毒(ccov)则可使犬发生不同程度的肠胃炎症状,传播快,难控制;猪流行性腹泻病毒(pedv)引起猪流行性腹泻等肠道疾病,容易在猪群里传播致死率很高。此外还有鼠、牛等冠状病毒。这些冠状病毒对人和动物的健康造成了严重的威胁。因此,开发针对冠状病毒的疫苗有着重要的意义。
表面刺突蛋白(s蛋白)是冠状病毒的主要中和抗原。mers-cov、sars-cov、2019-ncov的s蛋白的受体结合区(receptorbindingdomain,rbd)被认为是诱导机体产生中和抗体的最主要的抗原靶区域。rbd作为疫苗能够将机体刺激产生的中和抗体更加聚焦在针对病毒的受体结合,可以提高疫苗的免疫原性和免疫效率。mers-cov通过rbd与宿主细胞的受体(cd26,又名dpp4)结合而侵入细胞。此外,sars-cov和2019-ncov都发现通过其rbd与宿主细胞受体hace2结合而进入细胞。
公开于该背景技术部分的信息仅仅旨在增加对本发明的总体背景的理解,而不应当被视为承认或以任何形式暗示该信息构成已为本领域一般技术人员所公知的现有技术。
技术实现要素:
发明目的
本发明的目的在于提供一种β冠状病毒抗原、其制备方法和应用。本发明实施例中基于mers二聚体rbd蛋白比单体rbd蛋白能更好的的激发中和抗体的结论,尝试将两段编码相同或基本相同的单体rbd蛋白的核苷酸序列直接串联或通过连接段串联,所表达的两个相同或基本相同的单体rbd蛋白通过n端和c端的柔性区串联起来,结果显示该种方法可以很好地实现单链rbd二聚体的表达。相对于2个rbd单体简单通过其中的半胱氨酸以二硫键结合所形成的非单链形式的二聚体rbd蛋白而言,本发明实施例所得单链二聚体rbd蛋白不会因为二硫键的形成不稳定而导致生产过程中二聚体rbd蛋白含量不稳定,即避免以单体rbd形式为主,少有二聚体rbd形成的表达情况,从而使二聚体rbd表达稳定,形式均一,产量大大提高。相对于2个rbd单体简单通过其中的半胱氨酸以二硫键结合所形成的二聚体rbd蛋白而言,本发明实施例所表达的单链二聚体作为β冠状病毒抗原具有相当的免疫原性,该单链二聚体作为β冠状病毒抗原制备成的疫苗能够激发小鼠产生很高滴度的中和抗体。
解决方案
为实现本发明目的,本发明实施例提供了以下技术方案:
一种β冠状病毒抗原,其氨基酸序列包括:按照(a-b)-(a-b)样式排列的氨基酸序列或(a-b)-c-(a-b)样式排列的氨基酸序列或(a-b)-(a-b’)样式排列的氨基酸序列或(a-b)-c-(a-b’)样式排列的氨基酸序列,其中:a-b表示β冠状病毒的表面刺突蛋白的受体结合区的部分氨基酸序列或全部氨基酸序列,c表示连接氨基酸序列,a-b’表示a-b中的氨基酸序列经取代、缺失或添加一个或多个氨基酸获得的氨基酸序列,a-b’编码的蛋白质具有与a-b所编码的蛋白质相同或基本相同的免疫原性,所述β冠状病毒抗原为单链二聚体结构。可选地,β冠状病毒的表面刺突蛋白的受体结合区的部分氨基酸序列为β冠状病毒的表面刺突蛋白的受体结合区的全部氨基酸序列的至少50%、60%、70%、80%、90%、95%、99%。
上述β冠状病毒抗原在一种可能的实现方式中,所述β冠状病毒包括:严重呼吸综合征冠状病毒、中东呼吸综合征冠状病毒和2019新型冠状病毒(2019新型冠状病毒也可称为2019-ncov或者sars-cov-2)。
上述β冠状病毒抗原在一种可能的实现方式中,所述连接氨基酸序列包括:(ggs)n连接序列,其中n表示ggs的个数,n为≥1的整数;可选地,n为选自1-10的整数;进一步可选地,n为选自1-5的整数。ggs三个字母分别表示氨基酸g、g、s。
上述β冠状病毒抗原在一种可能的实现方式中,当β冠状病毒为中东呼吸综合征冠状病毒时,其表面刺突蛋白的受体结合区的部分氨基酸序列或全部氨基酸序列选自包括以下氨基酸序列的任意一种:
(1)seqidno:1,seqidno:2,或seqidno:3;
(2)在(1)中的氨基酸序列经取代、缺失或添加一个或多个氨基酸获得的氨基酸序列,该氨基酸序列编码的蛋白质具有与(1)所编码的蛋白质相同或基本相同的免疫原性;
可选地,其表面刺突蛋白的受体结合区的部分氨基酸序列包括seqidno:2。
其中:seqidno:1,seqidno:2,或seqidno:3序列均来源于mers-covs蛋白(ncbi上的genbank:afs88936.1)的一部分,分别是mers-covs蛋白的rbd的e367-y606区域、e367-n602区域、v381-l588区域。
上述β冠状病毒抗原在一种可能的实现方式中,当β冠状病毒为中东呼吸综合征冠状病毒时,β冠状病毒抗原的氨基酸序列包括选自以下氨基酸序列的任意一种:
(1)通过ggsggs连接序列串联起来的2个重复seqidno:1氨基酸序列,即e367-y606-ggsggs-e367-y606;
(2)通过ggs连接序列串联起来的2个重复seqidno:1氨基酸序列,即e367-y606-ggs-e367-y606;
(3)直接串联的2个重复seqidno:1氨基酸序列,即e367-y606-e367-y606。
(4)通过ggs连接序列串联起来的2个重复seqidno:2氨基酸序列,即e367-n602-ggs-e367-n602;
(5)直接串联的2个重复seqidno:2氨基酸序列,即e367-n602-e367-n602;
(6)通过ggsggsggsggsggs连接序列串联起来的2个重复seqidno:3氨基酸序列,即v381-l588-ggsggsggsggsggs-v381-l588;
(7)通过ggsggsggsggs连接序列串联起来的2个重复seqidno:3氨基酸序列,即v381-l588-ggsggsggsggs-v381-l588;
(8)通过ggsggsggs连接序列串联起来的2个重复seqidno:3氨基酸序列,即v381-l588-ggsggsggs-v381-l588;
(9)通过ggs连接序列串联起来的2个重复seqidno:3氨基酸序列,即v381-l588-ggs-v381-l588;
(10)直接串联的2个重复seqidno:3氨基酸序列,即v381-l588-v381-l588;
可选地,β冠状病毒抗原的氨基酸序列包括直接串联的2个重复seqidno:2氨基酸序列,即e367-n602-e367-n602。
上述β冠状病毒抗原在一种可能的实现方式中,当β冠状病毒为2019新型冠状病毒时,其表面刺突蛋白的受体结合区的部分氨基酸序列或全部氨基酸序列选自包括以下氨基酸序列的任意一种:
(1)seqidno:5,seqidno:6,或seqidno:7;
(2)在(1)中的氨基酸序列经取代、缺失或添加一个或几个氨基酸获得的氨基酸序列,该氨基酸序列编码的蛋白质具有与(1)所编码的蛋白质相同或基本相同的免疫原性;
可选地,其表面刺突蛋白的受体结合区的部分氨基酸序列包括seqidno:6。
其中:seqidno:5,seqidno:6,或seqidno:7序列均来源于2019-ncov的wh01株的s蛋白序列(ncbi上的genbank:qhr63250)的一部分,分别是2019-ncovs蛋白的rbd的r319-s530区域、r319-k537区域、r319-f541区域。
上述β冠状病毒抗原在一种可能的实现方式中,当β冠状病毒为2019新型冠状病毒时,β冠状病毒抗原的氨基酸序列包括选自以下氨基酸序列的任意一种:
直接串联的2个重复seqidno:5氨基酸序列,即r319-s530-r319-s530;
直接串联的2个重复seqidno:6氨基酸序列,即r319-k537-r319-k537;
直接串联的2个重复seqidno:7氨基酸序列,即r319-f541-r319-f541;
可选地,β冠状病毒抗原的氨基酸序列包括直接串联的2个重复seqidno:6氨基酸序列,即r319-k537-r319-k537。
上述β冠状病毒抗原在一种可能的实现方式中,当β冠状病毒为严重呼吸综合征冠状病毒时,其表面刺突蛋白的受体结合区的部分氨基酸序列或全部氨基酸序列选自包括以下氨基酸序列的任意一种:
(1)seqidno:8;
(2)在(1)中的氨基酸序列经取代、缺失或添加一个或几个氨基酸获得的氨基酸序列,该氨基酸序列编码的蛋白质具有与(1)所编码的蛋白质相同或基本相同的免疫原性。
其中:seqidno:8序列来源于sars-cov的s蛋白序列(ncbi上的genbank:aar07630)的一部分,是sars-covs蛋白的rbd的r306-q523区域。
上述β冠状病毒抗原在一种可能的实现方式中,当β冠状病毒为严重呼吸综合征冠状病毒时,β冠状病毒抗原的氨基酸序列包括:直接串联的2个重复seqidno:8氨基酸序列,即r306-q523-r306-q523。
上述β冠状病毒抗原在一种可能的实现方式中,编码通过ggsggs连接序列串联起来的2个重复seqidno:1氨基酸序列的核苷酸序列如seqidno:9所示;
编码通过ggs连接序列串联起来的2个重复seqidno:1氨基酸序列的核苷酸序列如seqidno:10所示;
编码直接串联的2个重复seqidno:1氨基酸序列的核苷酸序列如seqidno:11所示;
编码通过ggs连接序列串联起来的2个重复seqidno:2氨基酸序列的核苷酸序列如seqidno:12所示;
编码直接串联的2个重复seqidno:2氨基酸序列的核苷酸序列如seqidno:13所示;
编码通过ggsggsggsggsggs连接序列串联起来的2个重复seqidno:3氨基酸序列的核苷酸序列如seqidno:14所示;
编码通过ggsggsggsggs连接序列串联起来的2个重复seqidno:3氨基酸序列的核苷酸序列如seqidno:15所示;
编码通过ggsggsggs连接序列串联起来的2个重复seqidno:3氨基酸序列的核苷酸序列如seqidno:16所示;
编码通过ggs连接序列串联起来的2个重复seqidno:3氨基酸序列的核苷酸序列如seqidno:17所示;
编码直接串联的2个重复seqidno:3氨基酸序列的核苷酸序列如seqidno:18所示;
编码直接串联的2个重复seqidno:5氨基酸序列的核苷酸序列如seqidno:19所示;
编码直接串联的2个重复seqidno:6氨基酸序列的核苷酸序列如seqidno:20所示;
编码直接串联的2个重复seqidno:7氨基酸序列的核苷酸序列如seqidno:21所示;
编码直接串联的2个重复seqidno:8氨基酸序列的核苷酸序列如seqidno:23所示。
本发明还提供了一种制备上述β冠状病毒抗原的方法,包括以下步骤:在编码上述β冠状病毒抗原的核苷酸序列的5’端加入编码信号肽的序列,3’端加上终止密码子,进行克隆表达,筛选正确的重组子,然后转染表达系统的细胞进行表达,表达后收集细胞上清,纯化得到β冠状病毒抗原。
上述方法在一种可能的实现方式中,所述表达系统的细胞包括为哺乳动物细胞、昆虫细胞、酵母细胞或细菌细胞,可选地;所述哺乳动物细胞包括293t细胞或cho细胞,所述细菌细胞包括大肠杆菌细胞。
本发明还提供了一种编码上述β冠状病毒抗原的核苷酸序列、一种包括上述核苷酸序列的重组载体、一种包括上述重组载体的表达系统细胞。
本发明还提供了一种上述β冠状病毒抗原、编码上述β冠状病毒抗原的核苷酸序列、包括上述核苷酸序列的重组载体、包括上述重组载体的表达系统细胞在制备β冠状病毒疫苗中的应用。
本发明还提供了一种β冠状病毒疫苗,包括上述β冠状病毒抗原和佐剂。
上述β冠状病毒疫苗在一种可能的实现方式中,所述佐剂选自铝佐剂、mf59佐剂或类mf59佐剂。
本发明还提供了一种β冠状病毒dna疫苗,其包括有:包含编码上述β冠状病毒抗原的dna序列的重组载体。
本发明还提供了一种β冠状病毒mrna疫苗,其包括有:包含编码上述β冠状病毒抗原的mrna序列的重组载体。
本发明还提供了一种β冠状病毒病毒载体疫苗,其包括有:包含编码上述β冠状病毒抗原的核苷酸序列的重组病毒载体;可选地,病毒载体选自以下的一种或几种:腺病毒载体、痘病毒载体、流感病毒载体、腺相关病毒载体。
有益效果
(1)本发明实施例β冠状病毒抗原中,基于mers二聚体rbd蛋白比单体rbd蛋白能更好的的激发中和抗体的结论,进一步通过解析mers-cov二聚体rbd蛋白的晶体结构,发现了mers二聚体rbd蛋白能够形成头并头的二聚体,因此发明人尝试将两段编码相同或基本相同的单体rbd蛋白的核苷酸序列直接串联或通过连接段串联,所得两个相同或基本相同的单体rbd蛋白通过n端和c端的柔性区串联起来,结果显示该种方法可以实现很好地实现单链二聚体的表达。相对于2个rbd单体简单通过其中的半胱氨酸以二硫键结合所形成的非单链形式的二聚体rbd蛋白而言,本发明实施例所得单链二聚体rbd蛋白不会因为二硫键的形成不稳定而导致生产过程中二聚体rbd蛋白含量不稳定,即避免以单体rbd形式为主,少有二聚体形成的表达情况,从而使二聚体rbd表达稳定,形式均一,产量大大提高。相对于2个rbd单体简单通过其中的半胱氨酸以二硫键结合所形成的非单链形式的二聚体rbd蛋白而言,本发明实施例所表达的单链二聚体作为β冠状病毒抗原具有相当的免疫原性,该单链二聚体作为β冠状病毒抗原制备成的β冠状病毒疫苗能够激发小鼠产生很高滴度的中和抗体。
(2)本发明实施例β冠状病毒抗原中,通过对所包含的rbd不同区域氨基酸的选择,发现从如图14astart的第一个氨基酸开始,到图14bstop最后一个半胱氨酸之前的一个氨基酸为止是表达最优的构建,这样可以尽量避免末端未配对的半胱氨酸对蛋白表达和其稳定性的影响。
(3)本发明实施例β冠状病毒抗原中,通过对两段编码相同或基本相同的单体rbd蛋白的核苷酸序列直接串联或通过连接段串联的选择,发现在不引入任何外源连接序列的情况下,即将两段编码相同或基本相同的单体rbd蛋白的核苷酸序列直接串联的情况下,表达量最高,且由于没有外源序列的加入,也最为安全。由于本发明实施例中获得各种单链二聚体rbd作为β冠状病毒抗原都有很好的免疫效果,所以关键在于产量。
(4)本发明实施例β冠状病毒抗原中,所涉及的头并头单链二聚体结构适用于严重呼吸综合征冠状病毒、中东呼吸综合征冠状病毒和2019新型冠状病毒。
附图说明
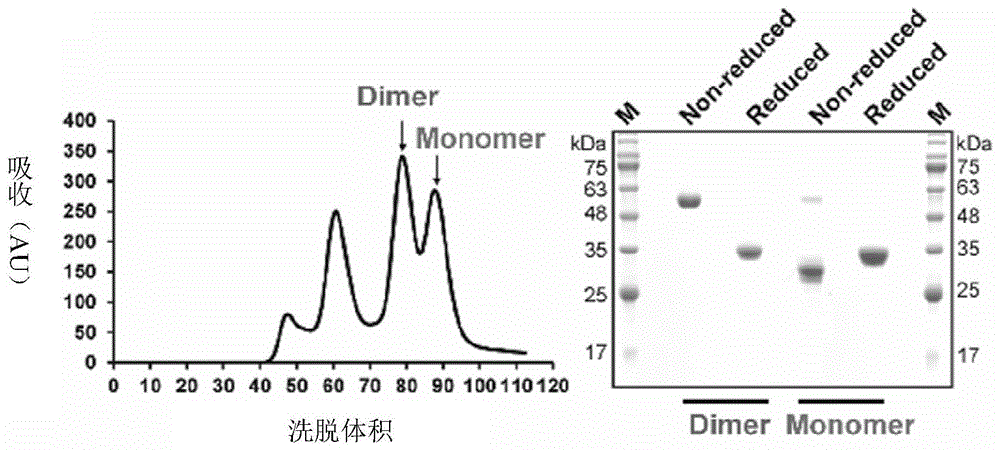
图1是实施例1中通过构建的载体pfastbac-sp-mers-rbd(e367-y606)所获得的rbd蛋白进行superdex200hiload16/60柱子(ge)分子筛层析时的紫外吸收图,以及收集紫外吸收图中的二聚体(dimer)峰和单体(monomer)峰获得的蛋白质在还原条件下(+dtt)或非还原条件下(-dtt)进行sds-page的电泳图。
图2是实施例2到实施例7中的免疫和mers-cov攻毒策略图。
图3是实施例3结果,为实施例2中小鼠第三次免疫后按照图2中的免疫策略取血的血清中mers-covrbd特异性抗体igg滴度。其中:dimer表示使用的免疫源为mers-covrbd二聚体,rbdmonomer表示使用的免疫源为mers-covrbd单体,addavax表示使用了addavax佐剂,alum表示使用了铝佐剂,未表示佐剂的表示没有使用佐剂,3μg、10μg、30μg表示每一次免疫使用的免疫源的免疫量。显著性差异分析:ns,p>0.05;*,p<0.05;**,p<0.01;***,p<0.001;****,p<0.0001。
图4是实施例5结果,为实施例2中小鼠第三次免疫后按照图2中的免疫策略取血的血清中mers-cov假病毒90%中和抗体滴度。其中:dimer表示使用的免疫源为mers-covrbd二聚体,rbdmonomer表示使用的免疫源为mers-covrbd单体,addavax表示使用了addavax佐剂,alum表示使用了铝佐剂,未表示佐剂的表示没有使用佐剂,3μg、10μg、30μg表示每一次免疫使用的免疫源的免疫量。显著性差异分析:ns,p>0.05;***,p<0.001。
图5是实施例6结果,为实施例2中小鼠第三次免疫后按照图2中的免疫策略取血的血清中对mers-cov真病毒(emc株)的50%中和抗体滴度结果图。其中:dimer表示使用的免疫源为mers-covrbd二聚体,addavax表示使用了addavax佐剂,alum表示使用了铝佐剂,未表示佐剂的表示没有使用佐剂,3μg、10μg、30μg表示每一次免疫使用的免疫源的免疫量。显著性差异分析:ns,p>0.05;***,p<0.001;****,p<0.0001。
图6是实施例7中按照图2中的免疫策略对第三次免疫后的小鼠滴鼻感染表达hcd26(hdpp4)的腺病毒,5天后用mers-cov攻毒,攻毒之后3天,取出小鼠的肺脏,组织匀浆用来检测病毒滴度(tcid50)的结果图。dimer表示使用的免疫源为mers-covrbd二聚体,addavax表示使用了addavax佐剂,alum表示使用了铝佐剂,未表示佐剂的表示没有使用佐剂,3μg、10μg、30μg表示每一次免疫使用的免疫源的免疫量。显著性差异分析:ns,p>0.05;*,p<0.05;**,p<0.01;***,p<0.001;****,p<0.0001。
图7是实施例8检测疫苗对小鼠肺组织保护效果的病理结果。将实施例7中攻毒的小鼠在解剖后取出肺经过4%多聚甲醛固定、石蜡包埋、苏木精-伊红染色和切片观察病理变化。其中addavax表示使用了addavax佐剂,alum表示使用了铝佐剂,3μg、10μg、30μg表示每一次免疫使用的免疫源的免疫量。slight、mild和severe分别说明肺组织病变程度为轻微、中等和严重。
图8是实施例9中解析出的mers-cov-rbddimer(e367-y606)的结构。
图9a、图9b、图9c是实施例10中基于mers-covrbd-dimer二聚体结构设计的单链rbd二聚体设计方案。
图10是实施例10中表达的mers-rbd-c1至mers-rbd-c10单链二聚体在还原(+dtt)或非还原(-dtt)的条件下进行westernblot的结果图。其中rbdmonomer为mers-covrbd单体蛋白。
图11是实施例11中表达的mers-rbd-c5单链二聚体进行进行superdex200hiload16/60柱子(ge)分子筛层析时的紫外吸收图,以及纯化所得单链二聚体在还原(+dtt)或非还原(-dtt)的条件下下进行sds-page的结果图。
图12是实施例12中小鼠免疫mers-cov-rbd单链二聚体和二硫键连接的非单链二聚体蛋白后,诱导产生的mers-cov-rbd特异性igg抗体滴度。其中sc-dimer是单链二聚体,dimer是二硫键连接的非单链二聚体。显著性差异分析:ns,p>0.05;*,p<0.05;***,p<0.001;****,p<0.0001。
图13是实施例12中小鼠免疫mers-cov-rbd单链二聚体和二硫键连接的非单链二聚体蛋白后,诱导产生的mers-cov假病毒90%中和抗体滴度。其中sc-dimer是单链二聚体,dimer是二硫键连接的非单链二聚体。显著性差异分析:ns,p>0.05;*,p<0.05;****,p<0.0001。
图14a和图14b是实施例13中beta冠状病毒的受体结合区(rbd)的比对图,两张图中的序列连续,比对了以下几种β冠状病毒:
mers-cov(afs88936),sars-cov(aas00003),sars-cov-2(qhr63290),bat-cov_hku5(abn10875),rousettus_bat-cov(aog30822),bat-cov_bm48-31(adk66841),bat-cov_hku9(abn10911),bat_hp-betacov(ail94216),sars-related-cov(apo40579),btrs-beta-cov(qdf43825),bat-sars-like-cov(ato98231),sars-like-cov_wiv16(alk02457),bat-cov(ari44804),btr1-beta-cov(qdf43815),hcov_hku1(azs52618),mcov_mhv1(acn89742),betacov_hku24(aja91217),hcov_oc43(aar01015),betacov_erinaceus(agx27810)。
图15是实施例13中sars-cov-rbd二聚体或2019-ncov-rbd二聚体的结构模拟图以及设计的表达2019-ncov-rbd二聚体、2019-ncov-rbd单体和sars-cov-rbd二聚体的构建。
图16是实施例13中表达的几种关于sars-cov-rbd和2019-ncov-rbd的单链二聚体在还原(+dtt)或非还原(-dtt)的条件下进行westernblot的结果图。
图17是实施例14中2019-ncov-rbd-c2抗原进行纯化时的紫外280nm吸光度图,以及纯化所得单链二聚体在还原(+dtt)或非还原(-dtt)的条件下进行sds-page的结果图。
图18是实施例14中sars-cov-rbd-c1抗原进行纯化时的紫外280nm吸光度图,以及纯化所得单链二聚体在还原(+dtt)或非还原(-dtt)的条件下进行sds-page的结果图。
图19为实施例15中小鼠三次免疫后(1免后19天,2免后14天,3免后14天)分别收集的血清的2019-ncov-rbd特异性igg抗体滴度。其中:sc-dimer表示使用的免疫源为ncov-rbd单链二聚体,monomer表示使用的免疫源为ncov-rbd单体。显著性差异分析:****,p<0.0001。
图20是实施例15中小鼠三次免疫后(1免后19天,2免后14天,3免后14天)分别收集的血清的2019-ncov假病毒90%中和抗体滴度。其中:sc-dimer表示使用的免疫源为ncov-rbd单链二聚体,monomer表示使用的免疫源为ncov-rbd单体。显著性差异分析:ns,p>0.05;**,p<0.01;****,p<0.0001。
图21是实施例15中小鼠第二次免疫后(2免后14天)收集的血清的2019-ncov真病毒(2020xn4276株)50%中和抗体滴度。其中:sc-dimer表示使用的免疫源为ncov-rbd单链二聚体,monomer表示使用的免疫源为ncov-rbd单体。
图22为实施例16中小鼠三次免疫后(1免后19天,2免后14天,3免后14天)分别收集的血清的sars-rbd特异性igg抗体滴度。其中:sc-dimer表示使用的免疫源为sars-cov-rbd单链二聚体,monomer表示使用的免疫源为sars-cov-rbd单体。显著性差异分析:ns,p>0.05;*,p<0.05;**,p<0.01;****,p<0.0001。
图23是实施例16中小鼠三次免疫后(1免后19天,2免后14天,3免后14天)分别收集的血清的sars-cov假病毒90%中和抗体滴度。其中:sc-dimer表示使用的免疫源为sars-cov-rbd单链二聚体,monomer表示使用的免疫源为sars-rbd单体。显著性差异分析:ns,p>0.05;*,p<0.05;**,p<0.01;***,p<0.001;****,p<0.0001。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
另外,为了更好的说明本发明,在下文的具体实施方式中给出了众多的具体细节。本领域技术人员应当理解,没有某些具体细节,本发明同样可以实施。在一些实施例中,对于本领域技术人员熟知的原料、元件、方法、手段等未作详细描述,以便于凸显本发明的主旨。
除非另有其它明确表示,否则在整个说明书和权利要求书中,术语“包括”或其变换如“包含”或“包括有”等等将被理解为包括所陈述的元件或组成部分,而并未排除其它元件或其它组成部分。
名词解释
二硫键连接的非单链形式的rbd二聚体和rbd单体:将编码rbd单体的核苷酸序列插入载体,然后转染表达系统的细胞进行表达,表达后收集细胞上清,纯化得到rbd单体和二硫键连接的非单链形式的rbd二聚体,其中:二硫键连接的非单链形式的rbd二聚体中的2个rbd单体简单通过其中的半胱氨酸以二硫键结合所形成的二聚体rbd。二硫键连接的非单链形式的rbd二聚体、非单链形式的二聚体rbd蛋白均具有相同的含义;rbd单体、单体rbd、单体rbd蛋白均具有相同的含义。
单链形式的rbd二聚体:将两段编码相同或基本相同的单体rbd的核苷酸序列直接串联或通过连接段串联,在该核苷酸序列的5’端加入编码信号肽的序列,3’端加上终止密码子,进行克隆表达,筛选正确的重组子,然后转染表达系统的细胞进行表达,表达后收集细胞上清,纯化得到重组蛋白,该蛋白含有两个rbd单体,两个rbd单体相同或基本相同,可以直接通过肽键连接在一起也可以通过一段连接序列(比如ggs、ggsggs等)连接在一起,即为单链形式的rbd二聚体。本申请中单链rbd二聚体、rbd单链二聚体、单链二聚体、sc-rbddimer、single-chainrbddimer等均具有相同的含义。
实施例1:表达mers-cov抗原的重组杆状病毒制备和rbd蛋白的表达纯化
将编码mers-covs蛋白(序列如genbank:afs88936.1)中的氨基酸rbd(e367-y606)序列(如seqidno:1所示)的核苷酸序列(如seqidno:24所示)3’端加上翻译终止密码子后克隆到包含gp67信号肽的pfastbac载体(pfastbac-sp来自invitrogen公司)的ecori和xhoi酶切位点之间,使得蛋白编码区在信号肽gp67序列的后面融合表达,用于目的蛋白的分泌,并且使目的蛋白c端带上6个组氨酸,得到载体pfastbac-sp-mers-rbd(e367-y606),然后转染表达系统的细胞进行表达,表达后收集细胞上清,纯化。
所得rbd蛋白纯化过superdex200hiload16/60柱子(ge)进行分子筛层析之后,典型的蛋白纯化紫外吸收图如图1所示。有一个二聚体的峰(dimer)还有一个单体的峰(monomer)。取mers-rbd蛋白在洗脱体积78ml附近的洗脱峰进行sds-page分析。洗脱体积78ml附近的蛋白在非还原条件下(不加dtt)的情况下,大小约为60kd;而在还原条件下(加入dtt),大小约为30kd,证明该峰中所获得蛋白质是二聚体。取洗脱体积90ml附近的洗脱峰进行sds-page分析,目的蛋白在非还原条件下(不加dtt)和还原条件的情况下大小均约为30kd,证明该峰主要是rbd单体。以上获得为二硫键连接的非单链形式的rbd二聚体和rbd单体,以下实施例2-实施例9中使用的二聚体或单体为本实施例中获得的二硫键连接的非单链形式的rbd二聚体和rbd单体。
实施例2:mers-rbd蛋白免疫小鼠实验
mf59(以下使用的addavax是一种mf59-like佐剂)和铝佐剂是sfda批准的两种常用佐剂,我们使用这两个佐剂作为疫苗组分对于后续的临床试验有着更直接的指导作用。体外中和试验是检测疫苗保护效果的经典方法。因此,我们将不同剂量的抗原分别与addavax佐剂和imjecttmalum佐剂进行混合,进行免疫。免疫分组情况、各组使用的rbd类别、每1次免疫使用的rbd免疫量和佐剂情况如表1所示,空白格部分表示“无”。
将实施例1获得的mers-rbd抗原(二聚体或单体)于生理盐水中稀释成所需浓度,并与佐剂进行分组乳化。然后对4-6周龄的balb/c小鼠(平均体重15-20g,下同)进行分组免疫,每组6只。
表1
免疫策略如图2,即通过大腿肌肉注射的方式,每只小鼠分别在第0天,第21天,第42天接受3次疫苗免疫,每次100μl的接种体积。第56天(即三免后的第14天),对小鼠进行尾部取血。小鼠血清通过静置后3000rpm离心10分钟获得,并与-20℃冰箱保存,用于特异性抗体滴度检测和假病毒中和检测。
实施例3:elisa实验检测疫苗诱导的特异性抗体滴度
(1)将mers-cov的rbd单体蛋白用elisa包被液(索莱宝,c1050)稀释至3μg/ml,96孔elisa板(coring,3590)每孔加入100μl,4℃放置12小时。
(2)倒掉包被液,加入pbs,洗一遍。使用pbs配制的5%脱脂牛奶作为封闭液,加入96孔板中,每孔100μl,封闭,室温放置1小时。封闭完后用pbs溶液洗一遍。
(3)封闭期间稀释小鼠血清。血清样品也用封闭液稀释。血清样品从20倍起始梯度稀释。之后在elisa板中每孔加入100μl,阴性对照为加入封闭液,37度孵育2小时,之后使用pbst洗4遍。
(4)加入使用封闭液1:2000稀释的偶联hrp的羊抗鼠二抗(abcam,ab6789),37℃孵育1.5小时,之后pbst洗5-6遍。加入tmb显色液显色,反应适当时间后加入2m盐酸终止反应,在酶标仪上检测od450读值。抗体滴度值被定义为反应值大于2.5倍阴性对照值的血清最高稀释倍数。当最低稀释倍数(检测限)的反应值仍小于2.5倍背景值时,该样品的滴度定义为最低稀释倍数的一半即1:10。
结果如图3所示,使用addavax佐剂3μg和10μg剂量下,rbd二聚体组和单体组诱导的抗体水平有显著差异,使用铝佐剂3μg、10μg和30μg剂量下,rbd二聚体组和单体组诱导的抗体水平有显著差异,且二聚体组诱导的抗体水平较高,显示出二聚体rbd抗原激活小鼠抗体反应的能力明显强于rbd单体疫苗。
本发明实施例中所有的elisa实验的包被蛋白都使用的是mers-cov的rbd单体蛋白。
实施例4:mers-cov假病毒的制备
pnl43-luci假病毒包装
(1)细胞铺盘:转染前一天,用胰酶进行消化以收获对数期生长的293t细胞,计数,重新接种细胞于10cm培养皿中培养过夜,至18-24h时细胞达到70-90%汇合时,进行转染(不含抗生素)。
(2)pei法进行质粒共转染:将共20μg质粒(hivpnl4-3.luc.re(invitrogen)10μg,pcaggs-mers-s10μg,这里pcaggs-mers-s是将编码mers的spike蛋白(m1-h1352)的dna序列插入到pcaggs载体的ecori和xhoi位点。)和40μlpei(2mg/ml)分别溶于生理盐水或hbs中,终体积为500μl,混匀;静置5min后,将两者混合,再静置20min,将混合物逐滴加入到细胞培养皿中,4-6h后,pbs洗涤细胞2次更换新鲜的无血清培养基。
(3)收毒:转染48h后,收集细胞及上清,1000rpm低速离心10min去除细胞碎片,分装,于-80℃保存,避免反复冻融造成病毒滴度下降。
(4)感染:第一天,细胞铺板,培养过夜,至18-24h时细胞达到80-100%;
第二天,pbs洗涤易感细胞去除血清,取病毒上清感染易感细胞,4-6h换为含血清的培养基。根据实验需要,可在不同时间点测定luciferase值,参考promega公司luciferaseassaysystemprotocol或dualluciferasereporterassaysystemprotocol。将收取的病毒液按5倍比稀释,加入到96孔板中的huh7细胞(人肝癌细胞)中。感染4小时后,弃掉病毒液,pbs洗涤细胞2次,换为含10%血清的dmem完全培养基。48小时候,弃掉培养基,pbs洗涤2次,加入细胞裂解液。-80℃冻融一次后,每孔取20μl利用glomax96microplateluminometer(promega)检测荧光素酶活性值。通过reed-muech法计算tcid50。
实施例5:免疫血清的假病毒中和实验
实施例2中获得的血清倍比稀释,与100tcid50假病毒混合,37℃共孵育30分钟。将混合液加入到已铺满huh7细胞的96孔板中。37℃孵育4小时后,弃掉病毒液,pbs洗涤细胞2次,换为含10%血清的完全培养基dmem。48小时后,弃掉培养液,pbs洗涤细胞2次,加入细胞裂解液,检测荧光素酶活性值。假病毒表面带有刺突蛋白,假病毒感染细胞释放dna,表达荧光素酶,但不复制。如果有中和抗体存在的情况下,假病毒就无法感染细胞,则不表达荧光素酶。以此方法来检验血清的中和滴度。
第三次免疫后免疫原性检测结果见图4。结果显示rbd二聚体(e367-y606)在三次免疫之后,无论addavax佐剂组还是铝佐剂组(+alum表示),都产生了中和抗体。特别是addavax佐剂10μg组的中和抗体nt90平均值可达1:1000以上(如图4所示)。而rbd单体(e379-e589)在三次免疫之后,除了2只小鼠有较弱的中和抗体产生,其余都检测不到(如图4所示)。假病毒中和实验证明了二聚体rbd诱导的中和抗体远比单体rbd高。
上述rbd单体(e379-e589)通过以下方法获得:将编码mers-covs蛋白中的氨基酸(e379-e589)序列(如seqidno:4所示)的核酸片段(如seqidno:25所示)插入pfastbac-sp的ecori和xhoi酶切位点,使得蛋白编码区在信号肽gp67序列的后面融合表达,用于目的蛋白的分泌,并且使目的蛋白c端带上6个组氨酸,得到载体pfastbac-sp-mers-rbd(e379-e589)
实施例6:免疫血清的真病毒中和(emc株)
使用三次免疫之后的血清,进行mers-cov真病毒(emc株,该病毒株已于yaoy,baol,dengw,etal.ananimalmodelofmersproducedbyinfectionofrhesusmacaqueswithmerscoronavirus.jinfectdis.2014;209(2):236-242.doi:10.1093/infdis/jit590中公开,由北京协和医学院实验动物研究所提供)的中和实验。实验结果如图5。结果显示,无论addavax佐剂还是铝佐剂,rbd二聚体都能诱导小鼠产生很高的中和抗体。最高的组(addavax佐剂10μgrbd二聚体)能达到ic50大于1:600。这结果通过mers-cov真病毒中和实验证明二聚体rbd可以诱导小鼠产生较高的的中和抗体。
实施例7:攻毒保护实验
实施例2中三次免疫后的小鼠,根据图2所示,第77天滴鼻感染表达hcd26(hdpp4)的腺病毒。这样在肺部能够瞬时表达mers-cov的受体hcd26,从而使得小鼠对mers-cov易感(参照chih等.dnavaccineencodingmiddleeastrespiratorysyndromecoronaviruss1proteininducesprotectiveimmuneresponsesinmice[j].vaccine,2017,35(16):2069-2075)。5天后用mers-cov(emc株)攻毒(一次攻毒剂量5x105pfu)。攻毒之后3天,取出小鼠的肺脏,组织匀浆用来检测病毒滴度(tcid50),结果如图6所示。相比pbs对照组,疫苗组小鼠的肺组织的病毒量显著降低。其中addavax佐剂3μgrbd二聚体组的病毒量较pbs组下降了近1000倍,显示出了很好的保护效果。这些结果显示,rbd二聚体作为疫苗有着非常显著的针对mers-cov活毒攻毒的保护效果。
实施例8:检测疫苗对小鼠肺组织的保护效果
将实施例7中mers-cov攻毒实验的小鼠肺组织使用4%多聚甲醛固定,之后经苏木精-伊红染色,切片观察肺部的病例变化,结果如图7所示,所有对照组小鼠(即pbs组)的肺组织呈现严重的间质性肺炎,肺泡炎,炎症细胞浸润以及支气管上皮细胞坏死(如图7)。而免疫组小鼠,无论是使用addavax还是alum作为佐剂都能够极大的缓解病毒攻毒引起的肺损伤,呈现出轻中度的肺损伤,肺泡清晰可见,较少有炎症细胞浸润。小量的肺部组织病变可能是由于一次攻毒剂量很大(5x105pfu)导致的。这些结果显示,rbd二聚体作为疫苗能够极大的缓解mers-cov攻毒引起的肺部损伤。
实施例9:mers-rbd二聚体晶体结构解析
按照实施例1的方法,表达rbd(e367-y606)蛋白。纯化后收集二聚体蛋白峰。蛋白浓缩到10mg/ml,蛋白与结晶池液按照体积比1:1的比例进行混合,再通过
实施例10:基于mers-rbd二聚体结构设计单链rbd二聚体(sc-rbddimer)
基于图8的mers-rbd晶体结构,rbd两个亚基的n端(n’)和c端(c’)处于之中头对头的排列形式。n端与c端各有一段看不见的柔性序列(如图9a)。因此,我们设计通过两个亚基之间串联起来,获得单链rbd二聚体(sc-rbddimer)。
第一种设计(如图9a)包括:
(1)在两个重复串联的(e367-y606)序列之间加入2个ggs连接序列,得到mers-rbd-c1(简称c1),编码该氨基酸序列的核苷酸序列为seqidno:9;
(2)在两个重复串联的(e367-y606)序列之间加入1个ggs连接序列,得到mers-rbd-c2(简称c2),编码该氨基酸序列的核苷酸序列为seqidno:10;
(3)两个重复(e367-y606)序列直接串联,得到mers-rbd-c3(简称c3),编码该氨基酸序列的核苷酸序列为seqidno:11。
第二种设计(如图9b)为了避免c端603位的半胱氨酸(c603)对表达的影响,构建截到n602,包括:
(4)在两个重复的串联的(e367-n602)序列之间加入1个ggs连接序列,得到mers-rbd-c4(简称c4),编码该氨基酸序列的核苷酸序列为seqidno:12;
(5)两个重复的(e367-n602)序列直接串联,得到mers-rbd-c5(简称c5),编码该氨基酸序列的核苷酸序列为seqidno:13。
第三种设计(如图9c)直接表达结构可见序列,通过不同长度的连接序列连接起来,包括:
(6)在两个重复的串联的(v381-l588)序列之间加入5个ggs连接序列,得到mers-rbd-c6(简称c6),编码该氨基酸序列的核苷酸序列为seqidno:14;
(7)在两个重复的串联的(v381-l588)序列之间加入4个ggs连接序列,得到mers-rbd-c7(简称c7),编码该氨基酸序列的核苷酸序列为seqidno:15;
(8)在两个重复的串联的(v381-l588)序列之间加入3个ggs连接序列,得到mers-rbd-c8(简称c8),编码该氨基酸序列的核苷酸序列为seqidno:16;
(9)在两个重复的串联的(v381-l588)序列之间加入1个ggs连接序列,得到mers-rbd-c9(简称c9),编码该氨基酸序列的核苷酸序列为seqidno:17;
(10)把两个重复的(v381-l588)直接串联起来,得到mers-rbd-c10(简称c10),编码该氨基酸序列的核苷酸序列为seqidno:18。
将编码以上mers-rbd-c1到c10的核苷酸序列的5’端加上编码mers-s蛋白自身信号肽(mihsvfllmflltptes)的核苷酸序列,3’端加上编码6个组氨酸的核苷酸序列后,再在3’端加上终止密码子,所得核苷酸序列插入到pcaggs载体ecori和xhoi酶切位点之间,其起始密码子上游含有kozak序列gccacc。以上质粒转染293t细胞,48小时后,取上清,目的蛋白n端带有信号肽,通过蛋白印迹法(westernblot)检测目的蛋白的表达,结果如图10所示。结果显示除了c2,其余构建均有表达。无论是还原(+dtt)还是非还原(-dtt)的条件下,蛋白都在二聚体的大小左右(50-60kda)。其中c4和c5的表达量最高。考虑到c5构建没有引入外源连接序列,完全是mers-cov自身的序列,因此对于临床使用更有优势、更安全。我们就进一步评价mers-rbd-c5作为疫苗的效果。
实施例11:哺乳动物表达mers-covrbd单链二聚体(sc-rbddimer)与蛋白纯化
使用哺乳动物293t细胞表达mers-rbd-c5。质粒转染293t细胞之后,进行表达并收获上清。细胞上清通过0.22μm的滤膜过滤,除去细胞碎片。将细胞培养上清液挂镍亲和柱(histrap),4度过夜。以缓冲液a(20mmtris,150mmnacl,ph8.0)洗涤树脂,以除去非特异结合蛋白。最后目的蛋白以缓冲液b(20mmtris,150mmnacl,ph8.0,300mm咪唑)从树脂上洗脱下来,并以10k截留(10cutoff)浓缩管将洗脱液浓缩至5ml以内。再通过superdex200hiload16/60柱子(ge)进行分子筛层析进行进一步的目的蛋白纯化。分子筛层析缓冲液为20mmtris,150mmnacl,ph8.0。经过分子筛层析,只在洗脱体积80ml附近有1个主峰。收集进行sds-page分析。sds-page的结果可见,mers-rbd-c5蛋白显示1条明显的蛋白带,在55-72kd之间,是rbd二聚体的大小。证明获得了mers-rbd单链二聚体,如图11所示。同时我们也使用实施例10中的方法,即293t细胞表达纯化了非单链形式的mersrbd二聚体,用于和sc-rbddimer作比较。
实施例12:mers-covrbd单链二聚体(sc-rbddimer)蛋白免疫小鼠实验
将实施例11获得的mers-rbd单链二聚体抗原于生理盐水中稀释,并与佐剂进行分组乳化。然后对4-6周龄的balb/c小鼠进行分组免疫,每组6只小鼠,另外,一组小鼠免疫pbs作为阴性对照。一组小鼠免疫293t细胞表达的非单链形式的二聚体。通过大腿肌肉注射的方式,每只小鼠分别在第0天,第21天和第42天接受3次疫苗免疫,每次100μl的接种体积(含10μg免疫源)。1免后19天,2免14天和3免后14天,对小鼠进行眼眶取血。小鼠血清通过静置后3000rpm离心10分钟获得,并于-20℃冰箱保存,用于特异性抗体检测和假病毒中和检测。
通过elisa实验检测小鼠血清的特异性抗体滴度,实验方法见实施例3,结果如图12所示,rbd-sc-dimer组小鼠和二硫键连接的非单链rbd-dimer组(dimer表示)小鼠都能被诱导产生抗体反应,sc-dimer组的滴度均值比dimer组高,在三次免疫后二者有显著差异(*,p<0.05)。此结果表明,sc-dimer和二硫键连接的非单链rbd-dimer一样具有很好的免疫原性。
假病毒中和实验参照实施例5进行。结果如图13所示,sc-dimer组小鼠和二硫键连接的非单链rbd-dimer组(dimer表示)小鼠都能被诱导产生抗体反应,sc-dimer组的滴度均值比dimer组高,在第一次免疫和第二次免疫后二者有显著差异(图13)。在三次免疫后sc-dimer组小鼠的假病毒中和滴度均值已经大于1:1000。此结果预示着用sc-dimer分开发的疫苗具有很大的临床开发潜力。
实施例13、单链rbd二聚体技术在其他冠状病毒疫苗中的应用
为了验证这一思路是否能应用于所有其他冠状病毒的疫苗设计,我们将19种常见的beta冠状病毒的受体结合区(rbd)进行了比较,如图14a和图14b。所有的beta冠状病毒rbd都在mers-cov的c603位置呈现保守的半胱氨酸,如图14b。我们选取了2019-ncov(以下简称ncov)和sars-cov两种冠状病毒来进行验证。根据sars-rbd的结构(pdb:3d0g),通过pymol软件,我们将sars-rbd的晶体结构建模到
将编码以上ncov-rbd-c1到c4的核苷酸序列和编码sars-cov-rbd-c1的核苷酸序列(seqidno:23)的5’端加上编码mers-s蛋白自身信号肽(mihsvfllmflltptes)的核苷酸序列;3’端加上编码6个组氨酸的核苷酸序列后,再在3’端加上终止密码子,插入到pcaggs载体ecori和xhoi酶切位点,其起始密码子上游含有kozak序列gccacc。以上质粒转染293t细胞,48小时后,取上清,通过蛋白印迹法(westernblot)检测目的蛋白的表达。表达结果如图16。结果显示在2019-ncov的几种抗原设计中ncov-rbd-c2的表达最高。而sars-cov-rbd-c1的构建蛋白表达量也很高。
以上结果说明,beta冠状病毒的单链二聚体设计,从图14a的第一个氨基酸(标记为start)开始,到图14b最后一个半胱氨酸(标记为stop)之前的一个氨基酸为止是表达最优的构建。
实施例14、2019-ncov-rbd单链二聚体抗原和sars-cov-rbd单链二聚体抗原的表达纯化
哺乳动物293t细胞表达ncov-rbd-c2。质粒转染293t细胞之后,收获上清。细胞上清通过0.22μm的滤膜过滤,除去细胞碎片。将细胞培养上清液挂镍亲和柱(histrap),4度过夜。以缓冲液a(20mmtris,150mmnacl,ph8.0)洗涤树脂,以除去非特异结合蛋白。最后目的蛋白以缓冲液b(20mmtris,150mmnacl,ph8.0,300mm咪唑)从树脂上洗脱下来,并以10k截留(10cutoff)浓缩管将洗脱液浓缩至5ml以内。再通过superdex200hiload16/60柱子(ge)进行分子筛层析进行进一步的目的蛋白纯化。分子筛层析缓冲液为20mmtris,150mmnacl,ph8.0。经过分子筛层析,只在洗脱体积80ml附近有1个主峰。收集进行sds-page分析。sds-page的结果显示,ncov-rbd-c2蛋白显示1条明显的蛋白带,在48-63kd之间,是rbd二聚体的大小。证明获得了2019-ncov-rbd单链二聚体,如图17。纯度在95%以上。该结果表明,这样的构建能够获得足量、高纯度的2019-ncov单链二聚体蛋白。
以相同的方法表达和纯化了2019-ncov单体rbd蛋白(由ncov-rbd-c4构建表达获得)、sars-cov单体rbd蛋白(sars-covrbdr306-f527,氨基酸序列和编码其氨基酸序列的核苷酸序列如seqidno:26和seqidno:27所示)和sars-cov单链二聚体蛋白(由sars-cov-rbd-c1构建表达获得)。
sars-cov单链二聚体蛋白结果如图18所示,可见经过分子筛层析,只在洗脱体积80ml附近有1个主峰。收集进行sds-page分析,由图18可见sars-cov-rbd-c1目的蛋白分子量在在55-72kd之间,是rbd二聚体的大小。证明获得了sars-rbd单链二聚体,如图18,且具有很高的纯度。
实施例15:2019-ncov-rbd单链二聚体蛋白免疫小鼠实验
将实施例14获得的2019-ncov-rbd单链二聚体和2019-ncov-rbd单体于pbs溶液中稀释,并与addavax佐剂进行分组乳化。然后对6-8周龄的balb/c小鼠(平均体重15-20g,下同)进行分组免疫,每组8只小鼠。通过大腿肌肉注射的方式,每只小鼠分别在第0天,第21天和第42天接受3次疫苗免疫,每次100μl的接种体积(含10μg免疫源)。分别在1免19天,2免14天和3免14天,对小鼠进行采血。小鼠血清通过静置后3000rpm离心10分钟获得,并于-20℃冰箱保存,用于特异性抗体检测和假病毒中和检测。
通过elisa实验检测小鼠血清的2019-covrbd特异性抗体滴度,实验方法见实施例3,结果如图19所示,单链二聚体rbd(标记sc-dimer)和单体rbd(标记monomer)都能诱导小鼠产生抗体反应,每次免疫后单链二聚体rbd组的滴度均值都比单体rbd组高(10-100倍提高),且每次免疫后二者都有显著差异(图19)。三次免疫后单链二聚体rbd诱导小鼠产生的抗体水平高达约1:106。此结果表明,单链二聚体形式的rbd抗原比单体形式的rbd抗原免疫原性更强,作为潜在的新冠病毒疫苗具有极大潜力。
2019-ncov假病毒中和实验方法参照实施例5进行。结果如图20所示,一次免疫后,仅单链二聚体rbd(标记sc-dimer)组诱导产生了中和抗体,单体rbd(标记monomer)和pbs组都检测不到中和抗体,单链二聚体rbd组与单体rbd组中和抗体滴度有显著差异(图20)。第二次和第三次免疫后,单链二聚体rbd和单体rbd都能诱导小鼠产生中和抗体,每次免疫后单链二聚体rbd组的中和抗体滴度均值都比单体rbd组高(10-100倍提高),且每次免疫后二者都有显著差异(图20)。三次免疫后单链二聚体rbd诱导小鼠产生的中和抗体水平高达约1:104。此结果表明,单链二聚体rbd抗原相比单体rbd抗原能够诱导小鼠产生更高的中和抗体水平,在应用中单链二聚体rbd抗原具有很高的优势。
使用二次免疫之后的血清,进行2019-ncov真病毒(2020xn4276株,该病毒株公开于luj,duplessisl,liuz,etal.genomicepidemiologyofsars-cov-2inguangdongprovince,china.cell.2020;181(5):997-1003.e9.doi:10.1016/j.cell.2020.04.023,由广东省疾病预防控制中心提供)的中和实验。实验结果见图21。结果显示,rbd二聚体能诱导小鼠产生很高的新冠病毒中和抗体,最高的中和nt50能大于4096,nt50最低的一只鼠数值是512。而rbd单体组的8只鼠,仅2只检测出新冠病毒中和抗体,nt50较低,分别是128和256。此结果表明二聚体rbd可以诱导小鼠产生较高的的新冠病毒中和抗体。
实施例16:sars-rbd单链二聚体蛋白免疫小鼠实验
将实施例14获得的sars-rbd单链二聚体和sars-rbd单体于pbs溶液中稀释,并与addavax佐剂进行分组乳化。然后对6-8周龄的balb/c小鼠进行分组免疫,每组6只小鼠。通过大腿肌肉注射的方式,每只小鼠分别在第0天,第2天和第42天接受3次疫苗免疫,每次100μl的接种体积(含10μg免疫源)。分别在1免19天,2免14天和3免14天,对小鼠进行采血。小鼠血清通过静置后3000rpm离心10分钟获得,并与-20℃冰箱保存,用于特异性抗体检测和假病毒中和检测。
通过elisa实验检测小鼠血清的sars-rbd特异性抗体滴度,实验方法见实施例3,结果如图22所示,单链二聚体rbd(标记sc-dimer)和单体rbd(标记monomer)都能诱导小鼠产生抗体反应,每次免疫后单链二聚体rbd组的滴度均值都比单体rbd组高,在第二次和第三次免疫后二者都有显著差异(图22)。三次免疫后二聚体rbd诱导小鼠产生的抗体水平高达约1:106。此结果表明,二聚体形式的rbd抗原比单体形式的rbd抗原免疫原性更强。
sars-cov假病毒中和实验方法参照实施例5进行。结果如图23所示,两次免疫后,二聚体rbd(标记sc-dimer)组和单体rbd(标记monomer)组都诱导产生了中和抗体,但是二聚体rbd组滴度值更高,二者相比具有显著差异(图23)。第三次免疫后,二聚体rbd组的中和抗体滴度均值仍然比单体rbd组高,且具有显著差异(图23)。三次免疫后二聚体rbd诱导小鼠产生的中和抗体水平高于1:103。此结果表明,二聚体rbd抗原相比单体rbd抗原能够诱导小鼠产生更高的中和抗体水平,在应用中二聚体rbd抗原具有很高的优势。
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
sequencelisting
<110>中国科学院微生物研究所
<120>一种β冠状病毒抗原、其制备方法和应用
<130>1087-200363f
<150>cn202010085038.9
<151>2020-02-10
<160>27
<170>patentinversion3.5
<210>1
<211>240
<212>prt
<213>mers-cov
<220>
<221>domain
<222>(1)..(240)
<223>mers-covs蛋白(序列如genbank:afs88936.1)的rbd中
e367-y606氨基酸序列
<400>1
glualalysproserglyservalvalgluglnalagluglyvalglu
151015
cysasppheserproleuleuserglythrproproglnvaltyrasn
202530
phelysargleuvalphethrasncysasntyrasnleuthrlysleu
354045
leuserleupheservalasnaspphethrcysserglnileserpro
505560
alaalailealaserasncystyrserserleuileleuasptyrphe
65707580
sertyrproleusermetlysseraspleuservalserseralagly
859095
proileserglnpheasntyrlysglnserpheserasnprothrcys
100105110
leuileleualathrvalprohisasnleuthrthrilethrlyspro
115120125
leulystyrsertyrileasnlyscysserargleuleuseraspasp
130135140
argthrgluvalproglnleuvalasnalaasnglntyrserprocys
145150155160
valserilevalproserthrvaltrpgluaspglyasptyrtyrarg
165170175
lysglnleuserproleugluglyglyglytrpleuvalalasergly
180185190
serthrvalalametthrgluglnleuglnmetglypheglyilethr
195200205
valglntyrglythraspthrasnservalcysprolysleugluphe
210215220
alaasnaspthrlysilealaserglnleuglyasncysvalglutyr
225230235240
<210>2
<211>236
<212>prt
<213>mers-cov
<220>
<221>domain
<222>(1)..(236)
<223>mers-covs蛋白(序列如genbank:afs88936.1)的rbd中
e367-n602氨基酸序列
<400>2
glualalysproserglyservalvalgluglnalagluglyvalglu
151015
cysasppheserproleuleuserglythrproproglnvaltyrasn
202530
phelysargleuvalphethrasncysasntyrasnleuthrlysleu
354045
leuserleupheservalasnaspphethrcysserglnileserpro
505560
alaalailealaserasncystyrserserleuileleuasptyrphe
65707580
sertyrproleusermetlysseraspleuservalserseralagly
859095
proileserglnpheasntyrlysglnserpheserasnprothrcys
100105110
leuileleualathrvalprohisasnleuthrthrilethrlyspro
115120125
leulystyrsertyrileasnlyscysserargleuleuseraspasp
130135140
argthrgluvalproglnleuvalasnalaasnglntyrserprocys
145150155160
valserilevalproserthrvaltrpgluaspglyasptyrtyrarg
165170175
lysglnleuserproleugluglyglyglytrpleuvalalasergly
180185190
serthrvalalametthrgluglnleuglnmetglypheglyilethr
195200205
valglntyrglythraspthrasnservalcysprolysleugluphe
210215220
alaasnaspthrlysilealaserglnleuglyasn
225230235
<210>3
<211>208
<212>prt
<213>mers-cov
<220>
<221>domain
<222>(1)..(208)
<223>mers-covs蛋白(序列如genbank:afs88936.1)的rbd中
v381-l588氨基酸序列
<400>3
valglucysasppheserproleuleuserglythrproproglnval
151015
tyrasnphelysargleuvalphethrasncysasntyrasnleuthr
202530
lysleuleuserleupheservalasnaspphethrcysserglnile
354045
serproalaalailealaserasncystyrserserleuileleuasp
505560
tyrphesertyrproleusermetlysseraspleuservalserser
65707580
alaglyproileserglnpheasntyrlysglnserpheserasnpro
859095
thrcysleuileleualathrvalprohisasnleuthrthrilethr
100105110
lysproleulystyrsertyrileasnlyscysserargleuleuser
115120125
aspaspargthrgluvalproglnleuvalasnalaasnglntyrser
130135140
procysvalserilevalproserthrvaltrpgluaspglyasptyr
145150155160
tyrarglysglnleuserproleugluglyglyglytrpleuvalala
165170175
serglyserthrvalalametthrgluglnleuglnmetglyphegly
180185190
ilethrvalglntyrglythraspthrasnservalcysprolysleu
195200205
<210>4
<211>211
<212>prt
<213>mers-cov
<220>
<221>domain
<222>(1)..(211)
<223>mers-covs蛋白(序列如genbank:afs88936.1)的rbd中
e379-e589氨基酸序列
<400>4
gluglyvalglucysasppheserproleuleuserglythrpropro
151015
glnvaltyrasnphelysargleuvalphethrasncysasntyrasn
202530
leuthrlysleuleuserleupheservalasnaspphethrcysser
354045
glnileserproalaalailealaserasncystyrserserleuile
505560
leuasptyrphesertyrproleusermetlysseraspleuserval
65707580
serseralaglyproileserglnpheasntyrlysglnserpheser
859095
asnprothrcysleuileleualathrvalprohisasnleuthrthr
100105110
ilethrlysproleulystyrsertyrileasnlyscysserargleu
115120125
leuseraspaspargthrgluvalproglnleuvalasnalaasngln
130135140
tyrserprocysvalserilevalproserthrvaltrpgluaspgly
145150155160
asptyrtyrarglysglnleuserproleugluglyglyglytrpleu
165170175
valalaserglyserthrvalalametthrgluglnleuglnmetgly
180185190
pheglyilethrvalglntyrglythraspthrasnservalcyspro
195200205
lysleuglu
210
<210>5
<211>212
<212>prt
<213>2019-ncov
<220>
<221>domain
<222>(1)..(212)
<223>2019-ncov的wh01株的s蛋白序列(ncbi上的genbank:
qhr63250)的rbd中r319-s530氨基酸序列
<400>5
argvalglnprothrgluserilevalargpheproasnilethrasn
151015
leucyspropheglygluvalpheasnalathrargphealaserval
202530
tyralatrpasnarglysargileserasncysvalalaasptyrser
354045
valleutyrasnseralaserpheserthrphelyscystyrglyval
505560
serprothrlysleuasnaspleucysphethrasnvaltyralaasp
65707580
serphevalileargglyaspgluvalargglnilealaproglygln
859095
thrglylysilealaasptyrasntyrlysleuproaspaspphethr
100105110
glycysvalilealatrpasnserasnasnleuaspserlysvalgly
115120125
glyasntyrasntyrleutyrargleuphearglysserasnleulys
130135140
prophegluargaspileserthrgluiletyrglnalaglyserthr
145150155160
procysasnglyvalgluglypheasncystyrpheproleuglnser
165170175
tyrglypheglnprothrasnglyvalglytyrglnprotyrargval
180185190
valvalleuserphegluleuleuhisalaproalathrvalcysgly
195200205
prolyslysser
210
<210>6
<211>219
<212>prt
<213>2019-ncov
<220>
<221>domain
<222>(1)..(219)
<223>2019-ncov的wh01株的s蛋白序列(ncbi上的genbank:
qhr63250)的rbd中r319-k537氨基酸序列
<400>6
argvalglnprothrgluserilevalargpheproasnilethrasn
151015
leucyspropheglygluvalpheasnalathrargphealaserval
202530
tyralatrpasnarglysargileserasncysvalalaasptyrser
354045
valleutyrasnseralaserpheserthrphelyscystyrglyval
505560
serprothrlysleuasnaspleucysphethrasnvaltyralaasp
65707580
serphevalileargglyaspgluvalargglnilealaproglygln
859095
thrglylysilealaasptyrasntyrlysleuproaspaspphethr
100105110
glycysvalilealatrpasnserasnasnleuaspserlysvalgly
115120125
glyasntyrasntyrleutyrargleuphearglysserasnleulys
130135140
prophegluargaspileserthrgluiletyrglnalaglyserthr
145150155160
procysasnglyvalgluglypheasncystyrpheproleuglnser
165170175
tyrglypheglnprothrasnglyvalglytyrglnprotyrargval
180185190
valvalleuserphegluleuleuhisalaproalathrvalcysgly
195200205
prolyslysserthrasnleuvallysasnlys
210215
<210>7
<211>223
<212>prt
<213>2019-ncov
<220>
<221>domain
<222>(1)..(223)
<223>2019-ncov的wh01株的s蛋白序列(ncbi上的genbank:
qhr63250)的rbd中r319-f541氨基酸序列
<400>7
argvalglnprothrgluserilevalargpheproasnilethrasn
151015
leucyspropheglygluvalpheasnalathrargphealaserval
202530
tyralatrpasnarglysargileserasncysvalalaasptyrser
354045
valleutyrasnseralaserpheserthrphelyscystyrglyval
505560
serprothrlysleuasnaspleucysphethrasnvaltyralaasp
65707580
serphevalileargglyaspgluvalargglnilealaproglygln
859095
thrglylysilealaasptyrasntyrlysleuproaspaspphethr
100105110
glycysvalilealatrpasnserasnasnleuaspserlysvalgly
115120125
glyasntyrasntyrleutyrargleuphearglysserasnleulys
130135140
prophegluargaspileserthrgluiletyrglnalaglyserthr
145150155160
procysasnglyvalgluglypheasncystyrpheproleuglnser
165170175
tyrglypheglnprothrasnglyvalglytyrglnprotyrargval
180185190
valvalleuserphegluleuleuhisalaproalathrvalcysgly
195200205
prolyslysserthrasnleuvallysasnlyscysvalasnphe
210215220
<210>8
<211>218
<212>prt
<213>sars-cov
<220>
<221>domain
<222>(1)..(218)
<223>sars-cov的s蛋白序列(ncbi上的genbank:aar07630)的rbd中
r306-q523氨基酸序列
<400>8
argvalvalproserglyaspvalvalargpheproasnilethrasn
151015
leucyspropheglygluvalpheasnalathrlyspheproserval
202530
tyralatrpgluarglyslysileserasncysvalalaasptyrser
354045
valleutyrasnserthrphepheserthrphelyscystyrglyval
505560
seralathrlysleuasnaspleucyspheserasnvaltyralaasp
65707580
serphevalvallysglyaspaspvalargglnilealaproglygln
859095
thrglyvalilealaasptyrasntyrlysleuproaspaspphemet
100105110
glycysvalleualatrpasnthrargasnileaspalathrserthr
115120125
glyasntyrasntyrlystyrargtyrleuarghisglylysleuarg
130135140
prophegluargaspileserasnvalpropheserproaspglylys
145150155160
procysthrproproalaleuasncystyrtrpproleuasnasptyr
165170175
glyphetyrthrthrthrglyileglytyrglnprotyrargvalval
180185190
valleuserphegluleuleuasnalaproalathrvalcysglypro
195200205
lysleuserthraspleuilelysasngln
210215
<210>9
<211>1458
<212>dna
<213>artificialsequence
<220>
<221>cds
<222>(1)..(1458)
<223>编码通过ggsggs连接序列串联起来的2个重复seqidno:1氨基酸序列的核苷酸序列
<400>9
gaagcaaaaccttctggctcagttgtggaacaggctgaaggtgttgaatgtgatttttca60
cctcttctgtctggcacacctcctcaggtttataatttcaagcgtttggtttttaccaat120
tgcaattataatcttaccaaattgctttcacttttttctgtgaatgattttacttgtagt180
caaatatctccagcagcaattgctagcaactgttattcttcactgattttggattacttt240
tcatacccacttagtatgaaatccgatctcagtgttagttctgctggtccaatatcccag300
tttaattataaacagtccttttctaatcccacatgtttgattttagcgactgttcctcat360
aaccttactactattactaagcctcttaagtacagctatattaacaagtgctctcgtctt420
ctttctgatgatcgtactgaagtacctcagttagtgaacgctaatcaatactcaccctgt480
gtatccattgtcccatccactgtgtgggaagacggtgattattataggaaacaactatct540
ccacttgaaggtggtggctggcttgttgctagtggctcaactgttgccatgactgagcaa600
ttacagatgggctttggtattacagttcaatatggtacagacaccaatagtgtttgcccc660
aagcttgaatttgctaatgacacaaaaattgcctctcaattaggcaattgcgtggaatat720
ggcggctcaggcggctcagaagcaaaaccttctggctcagttgtggaacaggctgaaggt780
gttgaatgtgatttttcacctcttctgtctggcacacctcctcaggtttataatttcaag840
cgtttggtttttaccaattgcaattataatcttaccaaattgctttcacttttttctgtg900
aatgattttacttgtagtcaaatatctccagcagcaattgctagcaactgttattcttca960
ctgattttggattacttttcatacccacttagtatgaaatccgatctcagtgttagttct1020
gctggtccaatatcccagtttaattataaacagtccttttctaatcccacatgtttgatt1080
ttagcgactgttcctcataaccttactactattactaagcctcttaagtacagctatatt1140
aacaagtgctctcgtcttctttctgatgatcgtactgaagtacctcagttagtgaacgct1200
aatcaatactcaccctgtgtatccattgtcccatccactgtgtgggaagacggtgattat1260
tataggaaacaactatctccacttgaaggtggtggctggcttgttgctagtggctcaact1320
gttgccatgactgagcaattacagatgggctttggtattacagttcaatatggtacagac1380
accaatagtgtttgccccaagcttgaatttgctaatgacacaaaaattgcctctcaatta1440
ggcaattgcgtggaatat1458
<210>10
<211>1449
<212>dna
<213>artificialsequence
<220>
<221>cds
<222>(1)..(1449)
<223>编码通过ggs连接序列串联起来的2个重复seqidno:1氨基酸序列的核苷酸序列
<400>10
gaagcaaaaccttctggctcagttgtggaacaggctgaaggtgttgaatgtgatttttca60
cctcttctgtctggcacacctcctcaggtttataatttcaagcgtttggtttttaccaat120
tgcaattataatcttaccaaattgctttcacttttttctgtgaatgattttacttgtagt180
caaatatctccagcagcaattgctagcaactgttattcttcactgattttggattacttt240
tcatacccacttagtatgaaatccgatctcagtgttagttctgctggtccaatatcccag300
tttaattataaacagtccttttctaatcccacatgtttgattttagcgactgttcctcat360
aaccttactactattactaagcctcttaagtacagctatattaacaagtgctctcgtctt420
ctttctgatgatcgtactgaagtacctcagttagtgaacgctaatcaatactcaccctgt480
gtatccattgtcccatccactgtgtgggaagacggtgattattataggaaacaactatct540
ccacttgaaggtggtggctggcttgttgctagtggctcaactgttgccatgactgagcaa600
ttacagatgggctttggtattacagttcaatatggtacagacaccaatagtgtttgcccc660
aagcttgaatttgctaatgacacaaaaattgcctctcaattaggcaattgcgtggaatat720
ggcggctcagaagcaaaaccttctggctcagttgtggaacaggctgaaggtgttgaatgt780
gatttttcacctcttctgtctggcacacctcctcaggtttataatttcaagcgtttggtt840
tttaccaattgcaattataatcttaccaaattgctttcacttttttctgtgaatgatttt900
acttgtagtcaaatatctccagcagcaattgctagcaactgttattcttcactgattttg960
gattacttttcatacccacttagtatgaaatccgatctcagtgttagttctgctggtcca1020
atatcccagtttaattataaacagtccttttctaatcccacatgtttgattttagcgact1080
gttcctcataaccttactactattactaagcctcttaagtacagctatattaacaagtgc1140
tctcgtcttctttctgatgatcgtactgaagtacctcagttagtgaacgctaatcaatac1200
tcaccctgtgtatccattgtcccatccactgtgtgggaagacggtgattattataggaaa1260
caactatctccacttgaaggtggtggctggcttgttgctagtggctcaactgttgccatg1320
actgagcaattacagatgggctttggtattacagttcaatatggtacagacaccaatagt1380
gtttgccccaagcttgaatttgctaatgacacaaaaattgcctctcaattaggcaattgc1440
gtggaatat1449
<210>11
<211>1440
<212>dna
<213>artificialsequence
<220>
<221>cds
<222>(1)..(1440)
<223>编码直接串联的2个重复seqidno:1氨基酸序列的核苷酸序列
<400>11
gaagcaaaaccttctggctcagttgtggaacaggctgaaggtgttgaatgtgatttttca60
cctcttctgtctggcacacctcctcaggtttataatttcaagcgtttggtttttaccaat120
tgcaattataatcttaccaaattgctttcacttttttctgtgaatgattttacttgtagt180
caaatatctccagcagcaattgctagcaactgttattcttcactgattttggattacttt240
tcatacccacttagtatgaaatccgatctcagtgttagttctgctggtccaatatcccag300
tttaattataaacagtccttttctaatcccacatgtttgattttagcgactgttcctcat360
aaccttactactattactaagcctcttaagtacagctatattaacaagtgctctcgtctt420
ctttctgatgatcgtactgaagtacctcagttagtgaacgctaatcaatactcaccctgt480
gtatccattgtcccatccactgtgtgggaagacggtgattattataggaaacaactatct540
ccacttgaaggtggtggctggcttgttgctagtggctcaactgttgccatgactgagcaa600
ttacagatgggctttggtattacagttcaatatggtacagacaccaatagtgtttgcccc660
aagcttgaatttgctaatgacacaaaaattgcctctcaattaggcaattgcgtggaatat720
gaagcaaaaccttctggctcagttgtggaacaggctgaaggtgttgaatgtgatttttca780
cctcttctgtctggcacacctcctcaggtttataatttcaagcgtttggtttttaccaat840
tgcaattataatcttaccaaattgctttcacttttttctgtgaatgattttacttgtagt900
caaatatctccagcagcaattgctagcaactgttattcttcactgattttggattacttt960
tcatacccacttagtatgaaatccgatctcagtgttagttctgctggtccaatatcccag1020
tttaattataaacagtccttttctaatcccacatgtttgattttagcgactgttcctcat1080
aaccttactactattactaagcctcttaagtacagctatattaacaagtgctctcgtctt1140
ctttctgatgatcgtactgaagtacctcagttagtgaacgctaatcaatactcaccctgt1200
gtatccattgtcccatccactgtgtgggaagacggtgattattataggaaacaactatct1260
ccacttgaaggtggtggctggcttgttgctagtggctcaactgttgccatgactgagcaa1320
ttacagatgggctttggtattacagttcaatatggtacagacaccaatagtgtttgcccc1380
aagcttgaatttgctaatgacacaaaaattgcctctcaattaggcaattgcgtggaatat1440
<210>12
<211>1425
<212>dna
<213>artificialsequence
<220>
<221>cds
<222>(1)..(1425)
<223>编码通过ggs连接序列串联起来的2个重复seqidno:2氨基酸序列的核苷酸序列
<400>12
gaagcaaaaccttctggctcagttgtggaacaggctgaaggtgttgaatgtgatttttca60
cctcttctgtctggcacacctcctcaggtttataatttcaagcgtttggtttttaccaat120
tgcaattataatcttaccaaattgctttcacttttttctgtgaatgattttacttgtagt180
caaatatctccagcagcaattgctagcaactgttattcttcactgattttggattacttt240
tcatacccacttagtatgaaatccgatctcagtgttagttctgctggtccaatatcccag300
tttaattataaacagtccttttctaatcccacatgtttgattttagcgactgttcctcat360
aaccttactactattactaagcctcttaagtacagctatattaacaagtgctctcgtctt420
ctttctgatgatcgtactgaagtacctcagttagtgaacgctaatcaatactcaccctgt480
gtatccattgtcccatccactgtgtgggaagacggtgattattataggaaacaactatct540
ccacttgaaggtggtggctggcttgttgctagtggctcaactgttgccatgactgagcaa600
ttacagatgggctttggtattacagttcaatatggtacagacaccaatagtgtttgcccc660
aagcttgaatttgctaatgacacaaaaattgcctctcaattaggcaatggcggctcagaa720
gcaaaaccttctggctcagttgtggaacaggctgaaggtgttgaatgtgatttttcacct780
cttctgtctggcacacctcctcaggtttataatttcaagcgtttggtttttaccaattgc840
aattataatcttaccaaattgctttcacttttttctgtgaatgattttacttgtagtcaa900
atatctccagcagcaattgctagcaactgttattcttcactgattttggattacttttca960
tacccacttagtatgaaatccgatctcagtgttagttctgctggtccaatatcccagttt1020
aattataaacagtccttttctaatcccacatgtttgattttagcgactgttcctcataac1080
cttactactattactaagcctcttaagtacagctatattaacaagtgctctcgtcttctt1140
tctgatgatcgtactgaagtacctcagttagtgaacgctaatcaatactcaccctgtgta1200
tccattgtcccatccactgtgtgggaagacggtgattattataggaaacaactatctcca1260
cttgaaggtggtggctggcttgttgctagtggctcaactgttgccatgactgagcaatta1320
cagatgggctttggtattacagttcaatatggtacagacaccaatagtgtttgccccaag1380
cttgaatttgctaatgacacaaaaattgcctctcaattaggcaat1425
<210>13
<211>1416
<212>dna
<213>artificialsequence
<220>
<221>cds
<222>(1)..(1416)
<223>编码直接串联的2个重复seqidno:2氨基酸序列的核苷酸序列
<400>13
gaagcaaaaccttctggctcagttgtggaacaggctgaaggtgttgaatgtgatttttca60
cctcttctgtctggcacacctcctcaggtttataatttcaagcgtttggtttttaccaat120
tgcaattataatcttaccaaattgctttcacttttttctgtgaatgattttacttgtagt180
caaatatctccagcagcaattgctagcaactgttattcttcactgattttggattacttt240
tcatacccacttagtatgaaatccgatctcagtgttagttctgctggtccaatatcccag300
tttaattataaacagtccttttctaatcccacatgtttgattttagcgactgttcctcat360
aaccttactactattactaagcctcttaagtacagctatattaacaagtgctctcgtctt420
ctttctgatgatcgtactgaagtacctcagttagtgaacgctaatcaatactcaccctgt480
gtatccattgtcccatccactgtgtgggaagacggtgattattataggaaacaactatct540
ccacttgaaggtggtggctggcttgttgctagtggctcaactgttgccatgactgagcaa600
ttacagatgggctttggtattacagttcaatatggtacagacaccaatagtgtttgcccc660
aagcttgaatttgctaatgacacaaaaattgcctctcaattaggcaatgaagcaaaacct720
tctggctcagttgtggaacaggctgaaggtgttgaatgtgatttttcacctcttctgtct780
ggcacacctcctcaggtttataatttcaagcgtttggtttttaccaattgcaattataat840
cttaccaaattgctttcacttttttctgtgaatgattttacttgtagtcaaatatctcca900
gcagcaattgctagcaactgttattcttcactgattttggattacttttcatacccactt960
agtatgaaatccgatctcagtgttagttctgctggtccaatatcccagtttaattataaa1020
cagtccttttctaatcccacatgtttgattttagcgactgttcctcataaccttactact1080
attactaagcctcttaagtacagctatattaacaagtgctctcgtcttctttctgatgat1140
cgtactgaagtacctcagttagtgaacgctaatcaatactcaccctgtgtatccattgtc1200
ccatccactgtgtgggaagacggtgattattataggaaacaactatctccacttgaaggt1260
ggtggctggcttgttgctagtggctcaactgttgccatgactgagcaattacagatgggc1320
tttggtattacagttcaatatggtacagacaccaatagtgtttgccccaagcttgaattt1380
gctaatgacacaaaaattgcctctcaattaggcaat1416
<210>14
<211>1293
<212>dna
<213>artificialsequence
<220>
<221>cds
<222>(1)..(1293)
<223>编码通过ggsggsggsggsggs连接序列串联起来的2个重复seqidno:3氨基酸序列的核苷酸序列
<400>14
gttgaatgtgatttttcacctcttctgtctggcacacctcctcaggtttataatttcaag60
cgtttggtttttaccaattgcaattataatcttaccaaattgctttcacttttttctgtg120
aatgattttacttgtagtcaaatatctccagcagcaattgctagcaactgttattcttca180
ctgattttggattacttttcatacccacttagtatgaaatccgatctcagtgttagttct240
gctggtccaatatcccagtttaattataaacagtccttttctaatcccacatgtttgatt300
ttagcgactgttcctcataaccttactactattactaagcctcttaagtacagctatatt360
aacaagtgctctcgtcttctttctgatgatcgtactgaagtacctcagttagtgaacgct420
aatcaatactcaccctgtgtatccattgtcccatccactgtgtgggaagacggtgattat480
tataggaaacaactatctccacttgaaggtggtggctggcttgttgctagtggctcaact540
gttgccatgactgagcaattacagatgggctttggtattacagttcaatatggtacagac600
accaatagtgtttgccccaagcttggcggctcaggcggctcaggcggctcaggcggctca660
ggcggctcagttgaatgtgatttttcacctcttctgtctggcacacctcctcaggtttat720
aatttcaagcgtttggtttttaccaattgcaattataatcttaccaaattgctttcactt780
ttttctgtgaatgattttacttgtagtcaaatatctccagcagcaattgctagcaactgt840
tattcttcactgattttggattacttttcatacccacttagtatgaaatccgatctcagt900
gttagttctgctggtccaatatcccagtttaattataaacagtccttttctaatcccaca960
tgtttgattttagcgactgttcctcataaccttactactattactaagcctcttaagtac1020
agctatattaacaagtgctctcgtcttctttctgatgatcgtactgaagtacctcagtta1080
gtgaacgctaatcaatactcaccctgtgtatccattgtcccatccactgtgtgggaagac1140
ggtgattattataggaaacaactatctccacttgaaggtggtggctggcttgttgctagt1200
ggctcaactgttgccatgactgagcaattacagatgggctttggtattacagttcaatat1260
ggtacagacaccaatagtgtttgccccaagctt1293
<210>15
<211>1284
<212>dna
<213>artificialsequence
<220>
<221>cds
<222>(1)..(1284)
<223>编码通过ggsggsggsggs连接序列串联起来的2个重复seqidno:3氨基酸序列的核苷酸序列
<400>15
gttgaatgtgatttttcacctcttctgtctggcacacctcctcaggtttataatttcaag60
cgtttggtttttaccaattgcaattataatcttaccaaattgctttcacttttttctgtg120
aatgattttacttgtagtcaaatatctccagcagcaattgctagcaactgttattcttca180
ctgattttggattacttttcatacccacttagtatgaaatccgatctcagtgttagttct240
gctggtccaatatcccagtttaattataaacagtccttttctaatcccacatgtttgatt300
ttagcgactgttcctcataaccttactactattactaagcctcttaagtacagctatatt360
aacaagtgctctcgtcttctttctgatgatcgtactgaagtacctcagttagtgaacgct420
aatcaatactcaccctgtgtatccattgtcccatccactgtgtgggaagacggtgattat480
tataggaaacaactatctccacttgaaggtggtggctggcttgttgctagtggctcaact540
gttgccatgactgagcaattacagatgggctttggtattacagttcaatatggtacagac600
accaatagtgtttgccccaagcttggcggctcaggcggctcaggcggctcaggcggctca660
gttgaatgtgatttttcacctcttctgtctggcacacctcctcaggtttataatttcaag720
cgtttggtttttaccaattgcaattataatcttaccaaattgctttcacttttttctgtg780
aatgattttacttgtagtcaaatatctccagcagcaattgctagcaactgttattcttca840
ctgattttggattacttttcatacccacttagtatgaaatccgatctcagtgttagttct900
gctggtccaatatcccagtttaattataaacagtccttttctaatcccacatgtttgatt960
ttagcgactgttcctcataaccttactactattactaagcctcttaagtacagctatatt1020
aacaagtgctctcgtcttctttctgatgatcgtactgaagtacctcagttagtgaacgct1080
aatcaatactcaccctgtgtatccattgtcccatccactgtgtgggaagacggtgattat1140
tataggaaacaactatctccacttgaaggtggtggctggcttgttgctagtggctcaact1200
gttgccatgactgagcaattacagatgggctttggtattacagttcaatatggtacagac1260
accaatagtgtttgccccaagctt1284
<210>16
<211>1275
<212>dna
<213>artificialsequence
<220>
<221>cds
<222>(1)..(1275)
<223>编码通过ggsggsggs连接序列串联起来的2个重复seqidno:3氨基酸序列的核苷酸序列
<400>16
gttgaatgtgatttttcacctcttctgtctggcacacctcctcaggtttataatttcaag60
cgtttggtttttaccaattgcaattataatcttaccaaattgctttcacttttttctgtg120
aatgattttacttgtagtcaaatatctccagcagcaattgctagcaactgttattcttca180
ctgattttggattacttttcatacccacttagtatgaaatccgatctcagtgttagttct240
gctggtccaatatcccagtttaattataaacagtccttttctaatcccacatgtttgatt300
ttagcgactgttcctcataaccttactactattactaagcctcttaagtacagctatatt360
aacaagtgctctcgtcttctttctgatgatcgtactgaagtacctcagttagtgaacgct420
aatcaatactcaccctgtgtatccattgtcccatccactgtgtgggaagacggtgattat480
tataggaaacaactatctccacttgaaggtggtggctggcttgttgctagtggctcaact540
gttgccatgactgagcaattacagatgggctttggtattacagttcaatatggtacagac600
accaatagtgtttgccccaagcttggcggctcaggcggctcaggcggctcagttgaatgt660
gatttttcacctcttctgtctggcacacctcctcaggtttataatttcaagcgtttggtt720
tttaccaattgcaattataatcttaccaaattgctttcacttttttctgtgaatgatttt780
acttgtagtcaaatatctccagcagcaattgctagcaactgttattcttcactgattttg840
gattacttttcatacccacttagtatgaaatccgatctcagtgttagttctgctggtcca900
atatcccagtttaattataaacagtccttttctaatcccacatgtttgattttagcgact960
gttcctcataaccttactactattactaagcctcttaagtacagctatattaacaagtgc1020
tctcgtcttctttctgatgatcgtactgaagtacctcagttagtgaacgctaatcaatac1080
tcaccctgtgtatccattgtcccatccactgtgtgggaagacggtgattattataggaaa1140
caactatctccacttgaaggtggtggctggcttgttgctagtggctcaactgttgccatg1200
actgagcaattacagatgggctttggtattacagttcaatatggtacagacaccaatagt1260
gtttgccccaagctt1275
<210>17
<211>1257
<212>dna
<213>artificialsequence
<220>
<221>cds
<222>(1)..(1257)
<223>编码通过ggs连接序列串联起来的2个重复seqidno:3氨基酸序列的核苷酸序列
<400>17
gttgaatgtgatttttcacctcttctgtctggcacacctcctcaggtttataatttcaag60
cgtttggtttttaccaattgcaattataatcttaccaaattgctttcacttttttctgtg120
aatgattttacttgtagtcaaatatctccagcagcaattgctagcaactgttattcttca180
ctgattttggattacttttcatacccacttagtatgaaatccgatctcagtgttagttct240
gctggtccaatatcccagtttaattataaacagtccttttctaatcccacatgtttgatt300
ttagcgactgttcctcataaccttactactattactaagcctcttaagtacagctatatt360
aacaagtgctctcgtcttctttctgatgatcgtactgaagtacctcagttagtgaacgct420
aatcaatactcaccctgtgtatccattgtcccatccactgtgtgggaagacggtgattat480
tataggaaacaactatctccacttgaaggtggtggctggcttgttgctagtggctcaact540
gttgccatgactgagcaattacagatgggctttggtattacagttcaatatggtacagac600
accaatagtgtttgccccaagcttggcggctcagttgaatgtgatttttcacctcttctg660
tctggcacacctcctcaggtttataatttcaagcgtttggtttttaccaattgcaattat720
aatcttaccaaattgctttcacttttttctgtgaatgattttacttgtagtcaaatatct780
ccagcagcaattgctagcaactgttattcttcactgattttggattacttttcataccca840
cttagtatgaaatccgatctcagtgttagttctgctggtccaatatcccagtttaattat900
aaacagtccttttctaatcccacatgtttgattttagcgactgttcctcataaccttact960
actattactaagcctcttaagtacagctatattaacaagtgctctcgtcttctttctgat1020
gatcgtactgaagtacctcagttagtgaacgctaatcaatactcaccctgtgtatccatt1080
gtcccatccactgtgtgggaagacggtgattattataggaaacaactatctccacttgaa1140
ggtggtggctggcttgttgctagtggctcaactgttgccatgactgagcaattacagatg1200
ggctttggtattacagttcaatatggtacagacaccaatagtgtttgccccaagctt1257
<210>18
<211>1248
<212>dna
<213>artificialsequence
<220>
<221>cds
<222>(1)..(1248)
<223>编码直接串联的2个重复seqidno:3氨基酸序列的核苷酸序列
<400>18
gttgaatgtgatttttcacctcttctgtctggcacacctcctcaggtttataatttcaag60
cgtttggtttttaccaattgcaattataatcttaccaaattgctttcacttttttctgtg120
aatgattttacttgtagtcaaatatctccagcagcaattgctagcaactgttattcttca180
ctgattttggattacttttcatacccacttagtatgaaatccgatctcagtgttagttct240
gctggtccaatatcccagtttaattataaacagtccttttctaatcccacatgtttgatt300
ttagcgactgttcctcataaccttactactattactaagcctcttaagtacagctatatt360
aacaagtgctctcgtcttctttctgatgatcgtactgaagtacctcagttagtgaacgct420
aatcaatactcaccctgtgtatccattgtcccatccactgtgtgggaagacggtgattat480
tataggaaacaactatctccacttgaaggtggtggctggcttgttgctagtggctcaact540
gttgccatgactgagcaattacagatgggctttggtattacagttcaatatggtacagac600
accaatagtgtttgccccaagcttgttgaatgtgatttttcacctcttctgtctggcaca660
cctcctcaggtttataatttcaagcgtttggtttttaccaattgcaattataatcttacc720
aaattgctttcacttttttctgtgaatgattttacttgtagtcaaatatctccagcagca780
attgctagcaactgttattcttcactgattttggattacttttcatacccacttagtatg840
aaatccgatctcagtgttagttctgctggtccaatatcccagtttaattataaacagtcc900
ttttctaatcccacatgtttgattttagcgactgttcctcataaccttactactattact960
aagcctcttaagtacagctatattaacaagtgctctcgtcttctttctgatgatcgtact1020
gaagtacctcagttagtgaacgctaatcaatactcaccctgtgtatccattgtcccatcc1080
actgtgtgggaagacggtgattattataggaaacaactatctccacttgaaggtggtggc1140
tggcttgttgctagtggctcaactgttgccatgactgagcaattacagatgggctttggt1200
attacagttcaatatggtacagacaccaatagtgtttgccccaagctt1248
<210>19
<211>1272
<212>dna
<213>artificialsequence
<220>
<221>cds
<222>(1)..(1272)
<223>编码直接串联的2个重复seqidno:5氨基酸序列的核苷酸序列
<400>19
agagtgcaacctacagaatcaatcgtgagatttcctaacatcacaaacctttgccctttc60
ggcgaggtgtttaacgcaacaagatttgcatcagtgtacgcatggaacagaaagcgtata120
tcaaactgcgtggcagattactcagtgctttacaactcagcatcattcagtacgtttaaa180
tgctacggagtgtcacctacaaagctaaatgatctttgctttacaaacgtgtacgcagat240
tcatttgtgatcagaggagatgaagtgagacaaatcgcacctggacaaacaggaaagatt300
gccgattacaactacaaacttcctgatgatttcaccggctgcgtgatcgcatggaactca360
aacaaccttgattcaaaggtaggtggtaattataattatttgtataggctctttcgtaag420
agcaacttaaagccatttgagcgagatatctcaacagaaatctaccaagcaggatcaaca480
ccttgcaacggagtggaaggatttaactgctactttcctcttcaatcatacggatttcaa540
cctacaaacggagtgggataccaaccttacagagtggtggtgctttcatttgaacttctt600
cacgcacctgcaacagtgtgcggacctaagaagagcagagtgcaacctacagaatcaatc660
gtgagatttcctaacatcacaaacctttgccctttcggcgaggtgtttaacgcaacaaga720
tttgcatcagtgtacgcatggaacagaaagcgtatatcaaactgcgtggcagattactca780
gtgctttacaactcagcatcattcagtacgtttaaatgctacggagtgtcacctacaaag840
ctaaatgatctttgctttacaaacgtgtacgcagattcatttgtgatcagaggagatgaa900
gtgagacaaatcgcacctggacaaacaggaaagattgccgattacaactacaaacttcct960
gatgatttcaccggctgcgtgatcgcatggaactcaaacaaccttgattcaaaggtaggt1020
ggtaattataattatttgtataggctctttcgtaagagcaacttaaagccatttgagcga1080
gatatctcaacagaaatctaccaagcaggatcaacaccttgcaacggagtggaaggattt1140
aactgctactttcctcttcaatcatacggatttcaacctacaaacggagtgggataccaa1200
ccttacagagtggtggtgctttcatttgaacttcttcacgcacctgcaacagtgtgcgga1260
cctaagaagagc1272
<210>20
<211>1314
<212>dna
<213>artificialsequence
<220>
<221>cds
<222>(1)..(1314)
<223>编码直接串联的2个重复seqidno:6氨基酸序列的核苷酸序列
<400>20
agagtgcaacctacagaatcaatcgtgagatttcctaacatcacaaacctttgccctttc60
ggcgaggtgtttaacgcaacaagatttgcatcagtgtacgcatggaacagaaagcgtata120
tcaaactgcgtggcagattactcagtgctttacaactcagcatcattcagtacgtttaaa180
tgctacggagtgtcacctacaaagctaaatgatctttgctttacaaacgtgtacgcagat240
tcatttgtgatcagaggagatgaagtgagacaaatcgcacctggacaaacaggaaagatt300
gccgattacaactacaaacttcctgatgatttcaccggctgcgtgatcgcatggaactca360
aacaaccttgattcaaaggtaggtggtaattataattatttgtataggctctttcgtaag420
agcaacttaaagccatttgagcgagatatctcaacagaaatctaccaagcaggatcaaca480
ccttgcaacggagtggaaggatttaactgctactttcctcttcaatcatacggatttcaa540
cctacaaacggagtgggataccaaccttacagagtggtggtgctttcatttgaacttctt600
cacgcacctgcaacagtgtgcggacctaagaagagcacgaaccttgtgaagaataagaga660
gtgcaacctacagaatcaatcgtgagatttcctaacatcacaaacctttgccctttcggc720
gaggtgtttaacgcaacaagatttgcatcagtgtacgcatggaacagaaagcgtatatca780
aactgcgtggcagattactcagtgctttacaactcagcatcattcagtacgtttaaatgc840
tacggagtgtcacctacaaagctaaatgatctttgctttacaaacgtgtacgcagattca900
tttgtgatcagaggagatgaagtgagacaaatcgcacctggacaaacaggaaagattgcc960
gattacaactacaaacttcctgatgatttcaccggctgcgtgatcgcatggaactcaaac1020
aaccttgattcaaaggtaggtggtaattataattatttgtataggctctttcgtaagagc1080
aacttaaagccatttgagcgagatatctcaacagaaatctaccaagcaggatcaacacct1140
tgcaacggagtggaaggatttaactgctactttcctcttcaatcatacggatttcaacct1200
acaaacggagtgggataccaaccttacagagtggtggtgctttcatttgaacttcttcac1260
gcacctgcaacagtgtgcggacctaagaagagcacgaaccttgtgaagaataag1314
<210>21
<211>1338
<212>dna
<213>artificialsequence
<220>
<221>cds
<222>(1)..(1338)
<223>编码直接串联的2个重复seqidno:7氨基酸序列的核苷酸序列
<400>21
agagtgcaacctacagaatcaatcgtgagatttcctaacatcacaaacctttgccctttc60
ggcgaggtgtttaacgcaacaagatttgcatcagtgtacgcatggaacagaaagcgtata120
tcaaactgcgtggcagattactcagtgctttacaactcagcatcattcagtacgtttaaa180
tgctacggagtgtcacctacaaagctaaatgatctttgctttacaaacgtgtacgcagat240
tcatttgtgatcagaggagatgaagtgagacaaatcgcacctggacaaacaggaaagatt300
gccgattacaactacaaacttcctgatgatttcaccggctgcgtgatcgcatggaactca360
aacaaccttgattcaaaggtaggtggtaattataattatttgtataggctctttcgtaag420
agcaacttaaagccatttgagcgagatatctcaacagaaatctaccaagcaggatcaaca480
ccttgcaacggagtggaaggatttaactgctactttcctcttcaatcatacggatttcaa540
cctacaaacggagtgggataccaaccttacagagtggtggtgctttcatttgaacttctt600
cacgcacctgcaacagtgtgcggacctaagaagagcacgaaccttgtgaagaataagtgc660
gtgaactttagagtgcaacctacagaatcaatcgtgagatttcctaacatcacaaacctt720
tgccctttcggcgaggtgtttaacgcaacaagatttgcatcagtgtacgcatggaacaga780
aagcgtatatcaaactgcgtggcagattactcagtgctttacaactcagcatcattcagt840
acgtttaaatgctacggagtgtcacctacaaagctaaatgatctttgctttacaaacgtg900
tacgcagattcatttgtgatcagaggagatgaagtgagacaaatcgcacctggacaaaca960
ggaaagattgccgattacaactacaaacttcctgatgatttcaccggctgcgtgatcgca1020
tggaactcaaacaaccttgattcaaaggtaggtggtaattataattatttgtataggctc1080
tttcgtaagagcaacttaaagccatttgagcgagatatctcaacagaaatctaccaagca1140
ggatcaacaccttgcaacggagtggaaggatttaactgctactttcctcttcaatcatac1200
ggatttcaacctacaaacggagtgggataccaaccttacagagtggtggtgctttcattt1260
gaacttcttcacgcacctgcaacagtgtgcggacctaagaagagcacgaaccttgtgaag1320
aataagtgcgtgaacttt1338
<210>22
<211>669
<212>dna
<213>artificialsequence
<220>
<221>cds
<222>(1)..(669)
<223>编码2019-ncov的wh01株的s蛋白(序列如genbank:qhr63250)的rbd中
r319-f541氨基酸序列的核苷酸序列
<400>22
agagtgcaacctacagaatcaatcgtgagatttcctaacatcacaaacctttgccctttc60
ggcgaggtgtttaacgcaacaagatttgcatcagtgtacgcatggaacagaaagcgtata120
tcaaactgcgtggcagattactcagtgctttacaactcagcatcattcagtacgtttaaa180
tgctacggagtgtcacctacaaagctaaatgatctttgctttacaaacgtgtacgcagat240
tcatttgtgatcagaggagatgaagtgagacaaatcgcacctggacaaacaggaaagatt300
gccgattacaactacaaacttcctgatgatttcaccggctgcgtgatcgcatggaactca360
aacaaccttgattcaaaggtaggtggtaattataattatttgtataggctctttcgtaag420
agcaacttaaagccatttgagcgagatatctcaacagaaatctaccaagcaggatcaaca480
ccttgcaacggagtggaaggatttaactgctactttcctcttcaatcatacggatttcaa540
cctacaaacggagtgggataccaaccttacagagtggtggtgctttcatttgaacttctt600
cacgcacctgcaacagtgtgcggacctaagaagagcacgaaccttgtgaagaataagtgc660
gtgaacttt669
<210>23
<211>1308
<212>dna
<213>artificialsequence
<220>
<221>cds
<222>(1)..(1308)
<223>编码直接串联的2个重复seqidno:8氨基酸序列的核苷酸序列
<400>23
agggtagttccctccggtgacgtcgttcgtttcccaaatataacaaacctctgtccattt60
ggagaagtatttaacgcgactaaatttcctagcgtatacgcctgggaaaggaagaaaata120
agcaattgtgttgcggactattccgtactatataattcgactttcttcagcaccttcaag180
tgttatggagtatcggctactaaactcaacgacttgtgtttctcgaacgtctacgcggat240
tctttcgttgtcaaaggagatgatgtgagacagatagcacctggacaaaccggtgttatc300
gctgattacaactacaaacttcccgacgactttatgggctgtgtactagcctggaatact360
cggaatattgacgccacctctaccggtaattataattataagtataggtatttacgtcat420
gggaaactgaggccgtttgaaagggacatttccaatgtaccatttagtccagacgggaaa480
ccatgcacgccgccagcactcaattgttattggcccctaaacgactatggtttttatacg540
acgaccggaattgggtaccaaccctaccgtgttgtagtgctgagctttgaacttctaaat600
gcgcccgctactgtctgtggtccgaagctatcgactgacctcataaagaatcagcgtgtt660
gtcccatccggtgacgttgtccggtttcctaacatcacaaacttgtgtccctttggcgaa720
gtcttcaatgctaccaaatttcccagcgtctacgcgtgggaaagaaagaaaatatcaaat780
tgtgttgccgactattccgtcctatataatagcacgttcttctcgacgttcaagtgttat840
ggtgtctctgctacgaaacttaacgacttatgtttctcaaacgtgtacgcagattctttc900
gtagttaaaggtgatgatgtgaggcagattgcgcccggacaaacaggagtaatcgccgat960
tacaactacaaactcccggacgactttatggggtgtgtgttagcttggaatacgaggaat1020
atagacgccacgagtaccgggaattataattataagtatcgctatctccgacatggcaaa1080
ctcaggccatttgaacgcgacattagcaatgttccattctctccggacggcaaaccgtgc1140
actccaccggctttaaattgttattggccgttaaacgactatggcttttatacaacgacg1200
ggaatagggtaccaaccttacagagtagtagtactaagtttcgagctattaaatgcgccg1260
gccaccgtatgtgggcccaagctatcgacggacctaatcaagaatcag1308
<210>24
<211>720
<212>dna
<213>artificialsequence
<220>
<221>cds
<222>(1)..(720)
<223>编码mers-covs蛋白(序列如genbank:afs88936.1)的rbd中氨基酸
e367-y606序列的核苷酸序列
<400>24
gaagcaaaaccttctggctcagttgtggaacaggctgaaggtgttgaatgtgatttttca60
cctcttctgtctggcacacctcctcaggtttataatttcaagcgtttggtttttaccaat120
tgcaattataatcttaccaaattgctttcacttttttctgtgaatgattttacttgtagt180
caaatatctccagcagcaattgctagcaactgttattcttcactgattttggattacttt240
tcatacccacttagtatgaaatccgatctcagtgttagttctgctggtccaatatcccag300
tttaattataaacagtccttttctaatcccacatgtttgattttagcgactgttcctcat360
aaccttactactattactaagcctcttaagtacagctatattaacaagtgctctcgtctt420
ctttctgatgatcgtactgaagtacctcagttagtgaacgctaatcaatactcaccctgt480
gtatccattgtcccatccactgtgtgggaagacggtgattattataggaaacaactatct540
ccacttgaaggtggtggctggcttgttgctagtggctcaactgttgccatgactgagcaa600
ttacagatgggctttggtattacagttcaatatggtacagacaccaatagtgtttgcccc660
aagcttgaatttgctaatgacacaaaaattgcctctcaattaggcaattgcgtggaatat720
<210>25
<211>633
<212>dna
<213>artificialsequence
<220>
<221>cds
<222>(1)..(633)
<223>编码mers-covs蛋白(序列如genbank:afs88936.1)的rbd中氨基酸e379-e589序列
的核苷酸片段
<400>25
gaaggtgttgaatgtgatttttcacctcttctgtctggcacacctcctcaggtttataat60
ttcaagcgtttggtttttaccaattgcaattataatcttaccaaattgctttcacttttt120
tctgtgaatgattttacttgtagtcaaatatctccagcagcaattgctagcaactgttat180
tcttcactgattttggattacttttcatacccacttagtatgaaatccgatctcagtgtt240
agttctgctggtccaatatcccagtttaattataaacagtccttttctaatcccacatgt300
ttgattttagcgactgttcctcataaccttactactattactaagcctcttaagtacagc360
tatattaacaagtgctctcgtcttctttctgatgatcgtactgaagtacctcagttagtg420
aacgctaatcaatactcaccctgtgtatccattgtcccatccactgtgtgggaagacggt480
gattattataggaaacaactatctccacttgaaggtggtggctggcttgttgctagtggc540
tcaactgttgccatgactgagcaattacagatgggctttggtattacagttcaatatggt600
acagacaccaatagtgtttgccccaagcttgaa633
<210>26
<211>222
<212>prt
<213>sars-cov
<220>
<221>domain
<222>(1)..(222)
<223>sars-cov的s蛋白序列(ncbi上的genbank:aar07630)的rbd中r306-f527氨基酸序列
<400>26
argvalvalproserglyaspvalvalargpheproasnilethrasn
151015
leucyspropheglygluvalpheasnalathrlyspheproserval
202530
tyralatrpgluarglyslysileserasncysvalalaasptyrser
354045
valleutyrasnserthrphepheserthrphelyscystyrglyval
505560
seralathrlysleuasnaspleucyspheserasnvaltyralaasp
65707580
serphevalvallysglyaspaspvalargglnilealaproglygln
859095
thrglyvalilealaasptyrasntyrlysleuproaspaspphemet
100105110
glycysvalleualatrpasnthrargasnileaspalathrserthr
115120125
glyasntyrasntyrlystyrargtyrleuarghisglylysleuarg
130135140
prophegluargaspileserasnvalpropheserproaspglylys
145150155160
procysthrproproalaleuasncystyrtrpproleuasnasptyr
165170175
glyphetyrthrthrthrglyileglytyrglnprotyrargvalval
180185190
valleuserphegluleuleuasnalaproalathrvalcysglypro
195200205
lysleuserthraspleuilelysasnglncysvalasnphe
210215220
<210>27
<211>666
<212>dna
<213>artificialsequence
<220>
<221>cds
<222>(1)..(666)
<223>编码sars-cov的s蛋白序列(ncbi上的genbank:aar07630)的rbd中
r306-f527氨基酸序列的核苷酸序列
<400>27
cgtgttgtcccatccggtgacgttgtccggtttcctaacatcacaaacttgtgtcccttt60
ggcgaagtcttcaatgctaccaaatttcccagcgtctacgcgtgggaaagaaagaaaata120
tcaaattgtgttgccgactattccgtcctatataatagcacgttcttctcgacgttcaag180
tgttatggtgtctctgctacgaaacttaacgacttatgtttctcaaacgtgtacgcagat240
tctttcgtagttaaaggtgatgatgtgaggcagattgcgcccggacaaacaggagtaatc300
gccgattacaactacaaactcccggacgactttatggggtgtgtgttagcttggaatacg360
aggaatatagacgccacgagtaccgggaattataattataagtatcgctatctccgacat420
ggcaaactcaggccatttgaacgcgacattagcaatgttccattctctccggacggcaaa480
ccgtgcactccaccggctttaaattgttattggccgttaaacgactatggcttttataca540
acgacgggaatagggtaccaaccttacagagtagtagtactaagtttcgagctattaaat600
gcgccggccaccgtatgtgggcccaagctatcgacggacctaatcaagaatcagtgtgtt660
aatttc666
- 还没有人留言评论。精彩留言会获得点赞!