基于路径信息的纯电动汽车剩余里程模型预测方法与流程
本发明涉及一种基于路径信息的纯电动汽车剩余里程模型预测方法,属于新能源汽车技术领域。
背景技术:
纯电动汽车(batteryelectricvehicle,bev)在能耗和排放方面对比传统的内燃机汽车有明显的优势,如动力性好,行驶噪声小,节能和零排放等。但是,由于受到电池技术发展的限制,电动汽车的续驶里程还较短并且充电时间较长。纯电动汽车驾驶员会担心他们在当前剩余能量下是否能抵达目的地,这被称为“里程焦虑”,里程焦虑是目前限制电动汽车接受程度的主要因素之一。显然,安装大容量电池,快速充电和建立更多的充电站是有效缓解和解决“里程焦虑”的有效手段,但是,由于受到目前技术水平和资金条件的限制,这些方法仍需要较长的时间才能实现。另外一种有效的手段是“精确的剩余行驶里程预测”,驾驶员可以通过预测的“剩余行驶里程”(remainingdrivingrange,rdr)判断车辆是否能抵达目的地,并提前对行程和充电地点进行规划。此外,准确的里程预测也是电动汽车能量管理的基础,依据剩余行驶里程,bev能量管理系统可以合理优化电能的使用,提高电动汽车的行驶里程,这也会缓解驾驶员的“里程焦虑”。
目前,许多研究者提出了多种bev能耗和rdr预测方法,这些方法基本上可以分成两类:基于历史数据的rdr预测和基于模型的rdr预测。基于历史数据的rdr预测方法是目前商业运行的bev上常用的rdr预测方法。这种方法对一段时间的历史能耗数据进行统计,假定未来的能耗和当前能耗相近,计算出当前的能量消耗率,然后根据电池荷电状态(stateofcharge,soc)估算出剩余能量,最后得到预测的剩余行驶里程。这种方法的优点是计算简单,实时性好并且易于实现。所以,大多数电动汽车的rdr预测都采用这种方法。但是,这种方法的缺点是:当未来工况发生较大的变化时,这种预测的误差会变大甚至预测结果完全无法信赖。bev能耗受到许多因素的影响,如工况(车速),驾驶员驾驶行为(驾驶风格),坡度,温度,电池soc,电池健康状态(stateofhealth,soh),风速,路面条件等。其中,工况(车速)是影响能耗的最主要因素之一,在不同类型的工况下,如城市、城郊和高速等,电动汽车能耗存在巨大的差别,显然当工况条件发生变化时,基于历史数据的rdr预测必然会失效。
技术实现要素:
为了解决现有技术存在的上述问题,本发明提供一种基于路径信息的纯电动汽车剩余里程模型预测方法。对一定数量的驾驶员历史行驶数据进行分析,提取路径信息,生成符合驾驶员行为特征的状态转移概率矩阵(transitionprobabilitymatrix,tpm);然后基于未来路径的道路信息和相应的tpm,基于马尔科夫随机理论,生成一种受到未来道路信息控制的预测工况(车速)。接下来,基于电动汽车性能试验,建立电动汽车精确能耗模型,该模型考虑了温度、坡度、电池荷电状态(soc)等主要影响能耗和rdr的因素。从车载传感器、天气预报系统、电子地图中获取路径信息,并对车辆模型中的相关参数进行模型估计,将第一步生成的预测车速输入到该能耗模型中,实现bev能耗和剩余行驶里程的准确预测。
本发明的目的是通过以下技术方案实现的:
一种基于路径信息的纯电动汽车剩余里程模型预测方法,包括以下步骤:
步骤一、建立车速预测模型以生成未来路径预测车速:对一定数量的驾驶员历史行驶数据进行分析,提取路径信息,生成符合驾驶员行为特征的状态转移概率矩阵;基于未来路径的道路信息和相应的状态转移概率矩阵,基于马尔科夫随机理论,生成受到未来道路信息控制的预测车速;
步骤二、建立参数估计模型,对影响汽车能耗及剩余行驶里程的行驶参数进行估计;
步骤三、建立rdr计算模型以预测车辆剩余行驶里程:rdr计算模型包括:能耗预测模型、剩余能量预测模型以及剩余行驶里程显示模型;能耗预测模型以车速预测模型得到的预测车速和参数估计模型估算的行驶参数作为模型输入,计算出车辆能量消耗率;剩余能量预测模型用于预估车辆电池剩余能量;综合车辆能量消耗率及电池剩余能量即可预测车辆剩余行驶里程,并通过剩余行驶里程显示模型进行显示。
本发明的有益效果在于:
(1)本发明将历史工况和未来路径信息相结合,同时考虑了驾驶员驾驶特征和路径信息特征,进行可控随机工况预测。该方法实时性好,准确度高,驾驶员行为特征适应性好。
(2)驾驶员历史工况数据经处理后成为以驾驶风格和道路类型为索引的马尔科夫概率转移矩阵,存储量小,计算方便,并可实时更新。随行驶里程增加,概率转移矩阵对驾驶员驾驶行为特征代表性增强,但存储量保持不变;当储存的道路类型增加时,预测准确性大幅提高,存储量仅小幅增加,适应车载系统要求。
(3)所提出的bev能耗模型考虑了温度、坡度、电池荷电状态(soc)等道路信息对能耗的影响,并对模型参数进行精确估计。该模型采用逆向建模方法,基于车辆性能试验,综合考虑了车辆行驶能耗,动力系统传动损失,辅助系统能耗和再生制动回收能量等,模型精度高,计算量小,实时性好。
附图说明
本发明的具体实施方式将在下文通过结合应用示例进行详细阐述。
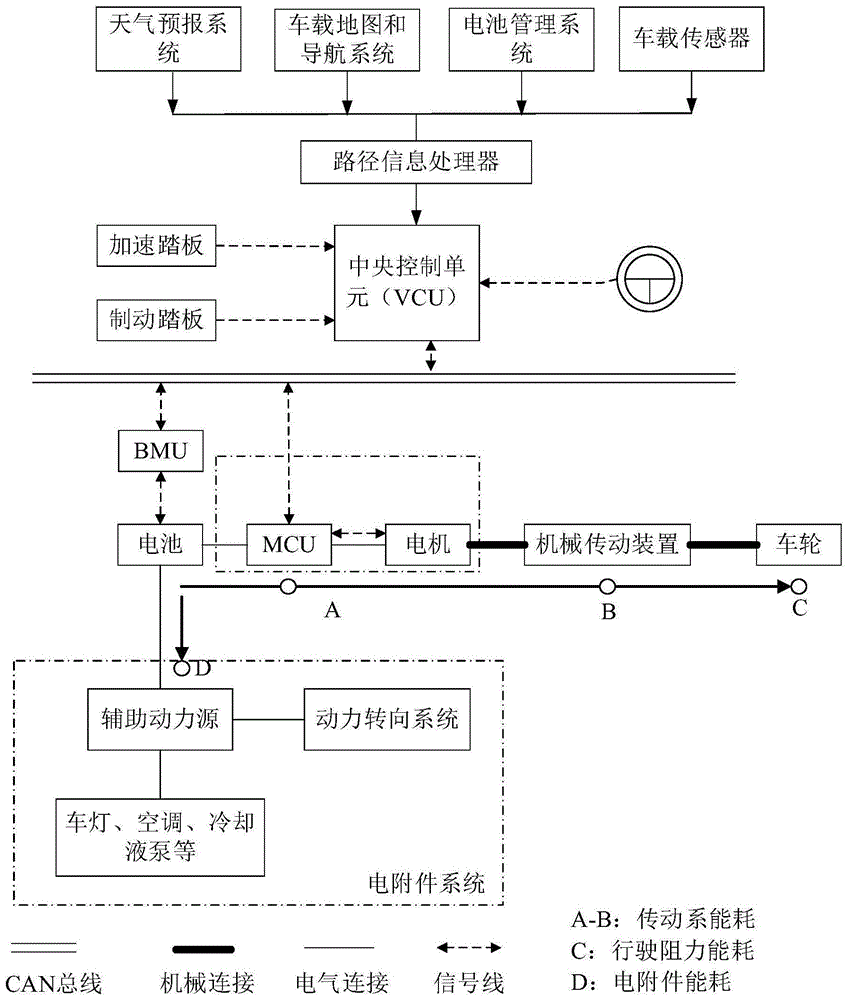
图1是bev及能量管理系统硬件结构;
图2是剩余行驶里程预测算法架构;
图3是汽车受力平衡图;
图4是不同转速下传动系统损失功率与电机输入功率关系试验曲线;
图5是电池开路电压与soc关系试验曲线;
图6是车速生成算法流程图;
图7是某城市道路试验路径及路径信息;
图8为某城市道路试验车速及路径信息;
图9为城市“二类”道路工况片段;
图10为城市“二类”道路加速及减速阶段;
图11为加速阶段车速数据网格化及生成tpms示意图;
图12为城市“二类”道路加速及减速阶段tpms;
图13为城市道路参考工况及预测车速;
图14为工况段生成算法示意图;
图15为不同驾驶员城市道路能耗实测与预测曲线;
图16为城市道路rdr实际与预测曲线。
具体实施方式
下面结合附图对本发明做进一步说明。以下实例将有助于本领域的技术人员进一步理解本发明,但不以任何形式限制本发明。
图1是bev剩余行驶里程预测系统硬件结构。本例中的bev动力系统由电机、电机控制器(motorcontrolunit,mcu)电池、电池管理单元(bmu)和减速器等组成。为了实现剩余里程预测功能,在该bev上装有车载gps导航系统(gvns)、智能交通系统(its)、地理信息系统(gis),以及天气预报系统(weatherreportsystem,wrs)等。信息融合处理器的功能是从上述系统中获取所需的路径信息,并对这些信息进行数据采集、存储、清洗和格式对齐等,将不同格式不同类型的路径信息融合成能够被能量本发明提出的rdr预测算法在能量管理单元中(emu)运行,该单元的作用是对bev能耗进行估算,计算剩余行驶里程和bev能量管理。emu通过can线与bmu和mcu通信,协调和优化bev能量使用。
图2为剩余行驶里程预测算法架构,该架构包含三个部分:
第一部分(part1)rdr(剩余行驶里程)计算模型,该模型的功能是计算bev能量消耗率和电池剩余能量,并计算剩余行驶里程,最后根据行驶需求显示剩余行驶里程预测结果。该部分包括3个子模型:能耗预测模型(车辆模型)、剩余能量预测模型(电池模型)和剩余行驶里程显示模型。
第二部分(part2)参数估计模型,该部分模型是对rdr计算模型所需的行驶参数,如整车质量、路面坡度和空气密度等进行估计。该部分模型中包含上述参数的估计模型。
第三部分(part3)车速预测模型,又称工况预测模型。车速是参数估计模型和rdr预测模型的输入。车速预测模型依据未来路径信息及驾驶员历史行驶数据,基于马尔科夫随机理论,生成未来路径预测车速。
将车速预测模型得到的预测车速和参数估计模型估算的行驶参数输入到rdr计算模型中,最终得到rdr的预测值,并显示在仪表板上,准确的rdr预测可以有效缓解驾驶员的“里程焦虑”。
下面以实例的方式依次介绍上述三部分模型。
part1rdr计算模型
(1)能耗预测模型(车辆模型)
本例中的目标车辆是一款小型纯电动轿车,其整备质量为1060kg、最高车速130km/h、电池容量为91ah,在69km/h匀速行驶条件下,其续驶里程可达228km。该车结构如附图1所示,在车辆行驶过程中,能量消耗可分为三个部分:第一部分是电机和传动系统的能耗损失,如图1中a-b点所示;第二部分为克服行驶阻力消耗的能量,如图1中c点所示;第三部分为辅助系统能耗,如图1中d点所示。另外,还需要去除再生制动系统回收的能量。采用逆向建模方法建立能耗预测模型,即模型的输入为车速,输出为电池输出功率pbat(w),即
其中,fw(n)为汽车驱动力,如图6中的汽车受力平衡图所示,其与汽车行驶阻力相等,即fw=fr+faero+fg+fm;v(m/s)为车辆行驶速度,由part3的车速预测模型得到;ppt_loss(w)为bev传动系统损失功率;paux(w)是电附件消耗功率。
滚动阻力fr(n)可由下式计算
fr=frmvgcos(αslop)(1.2)
其中fr为滚动阻力系数,受环境温度和路面类型的影响,该系数将由part2中的滚动阻力系数估算模型得到;mv(kg)为bev整车质量,由part2中的整车质量估算模型得到;g(m/s2)为重力加速度,取9.81m/s2;αslop(rad)为路面坡度,由part2的路面坡度估算模型得到。
空气阻力faero(n)为
其中ρ(kg/m3)为空气密度,取为1.29kg/m3;af(m2)为汽车的迎风面积,本例中目标车辆的迎风面积为1.97m2;cd是空气阻力系数,本例中取为0.3;vwin(m/s)是行驶方向上的风速,由天气预报系统获得。
坡度阻力fg(n)为
fg=mvgsin(αslop)(1.4)
加速阻力fm(n)为
这里jw(kg·m2)为车轮转动惯量,为0.75kgm2;jm(kg·m2)为电机转动惯量,为0.0384kgm2;r(m)为轮胎半径,为0.278m;ig是变速箱传动比,为8.654;dv/dt(m/s2)是纵向汽车加速度,有车速微分得到,车速由part3的车速预测模型得到。
系统损失功率ppt_loss(w)可由测功机实验测得,其值为电机输出功率pelec(w)和转鼓机械功率pmec(w)之差
ppt_loss=pelec-pmec(1.6)
图4为目标车辆不同转速下传动系统损失功率与电机输入功率关系试验曲线。为了简化计算,采用拟合方程对传动系统损失功率进行描述。采用matlab参数估计工具箱对图4的试验曲线进行拟合,获得拟合公式并优化得到拟合参数。由于驱动模式和再生制动模式的拟合公式结构不同,所以分别采用经验公式进行拟合,即
其中,电机转矩tm(n·m)为
tm=fwr/ig(1.8)
电机转速
pc(w)为电机空转损失功率,经验公式为
pc=c1·v3+c2·v2+c3·v+c4(1.10)
其中,ai(i=1~4),bi(i=1~2),ci(i=1~4)为拟合系数。
本例中目标车辆传动系统损失功率拟合公式为
在加速行驶模式
在再生制动模式
其中:
pc=0.06v3-4.85v2+116.93v+170(1.13)
电附件能耗paux(w)具有很大的随机性,本例中采用在多种循环工况下电附件平均能耗作为电附件能耗,即
paux=paux_avg(1.14)
其中,paux_avg(w)为在多种循环工况下电附件系统平均能耗,取为210w。
最后得到bev能量消耗率eavg(kw/km),即
其中sr(m)为路径长度,从导航系统中获取。
(2)剩余能量预测模型(电池模型)
由于电池是复杂的电化学系统,电池剩余能量在不同的工况下会存在很大差异。在剩余能量预测模型中,本发明考虑了电池健康状态(stateofhealth,soh)以及电池温度等对电池剩余能量的影响。电池剩余能量erue(kwh)可由下式计算
erue=q0·soh·ctemput,nom·(soc-socend,nom)(1.16)
其中,q0(ah)为新电池额定容量,取为91ah;ctemp为电池温度修正系数,由电池特性试验确定;ut,nom(v)为电池额定端电压;socend,nom为最低电池放电soc;soh为电池健康状态,定义为
其中,qbat(ah)为当前电池额定容量。soh与电池充放电循环次数有关,可由电池试验确定soh与充放电循环次数的关系,并从电池管理系统获取当前电池的soh。
采用简单的电池内阻模型对式(1.16)的电池soc进行估算,电池开路电压为
voc=vout+ir(1.18)
其中,vout(v)为电池输出电压;i(a)为电池输出电流;r(ω)为电池内阻。电池开路电压与soc的关系曲线由电池试验确定,如图5所示。电池内阻r和放电电流i之间的关系可由电池充放电试验确定,拟合式为
r=d1|i|3+d2|i|2+d3|i|+d4(1.19)
其中,di(i=1~4)为拟合系数,依据试验曲线,由matlab参数估计工具箱优化得到,即
r=-3.84×10-7|i|3+2.04×10-5|i|2-3.7×10-3|i|+0.41(1.20)
电池输出功率pbat(w)为
pbat=vouti=voci-i2r(1.21)
采用安时法对soc进行估计,即
(3)剩余行驶里程显示模型
从能耗预测模型和剩余能量预测模型中分别计算得到能量消耗率eavg和电池剩余能量erue后,由下式可以计算得到当前时刻t2的剩余行驶里程rdrcal(km),即
另一种剩余行驶里程的计算方法为
其中,rdrcal(t1)为在过去t1时刻的采用式(1.23)计算得到的rdr预测结果;δlcum(t1,t2)为从t1到t2时刻行驶过的实际距离,由实际车速积分得到。
由式(1.23)得到的rdrcal能够如实的反应当前车辆的能量状态和车辆能量消耗情况。它能够对驾驶循环工况的变化做出快速的响应。然而,在工况突然变化时,采用这种方法预测的rdr结果会出现较大的跳变,这种剧烈的变化会引起驾驶员的焦虑影响驾驶体验。由式(1.24)计算得到的rdrcum是连续平缓的变化的,但是,它无法反应工况变化对rdr的影响,预测的最终结果将出现较大的误差。为了综合上述两种rdr的预测方法优点并克服其缺点,用于最终显示的rdr预测结果rdrdis(km)可由下式计算
rdrdis(t2)=wdisrdrcal(t2)+(1-wdis)rdrcum(t2)(1.25)
其中,wdis为权重系数,取值范围为[0,1]。设计者可以根据具体的rdr显示需求选择该系数的值。
part2参数估计模型
在part1的rdr计算模型中,一些汽车行驶参数,如滚动阻力系数,路面坡度及整车质量等需要进行计算或估算,本部分阐述上述参数的计算或估计模型。
(1)滚动阻力系数初值估计模型
为了计算滚动阻力fr(n)(式(1.2))需要对滚动阻力系数fr进行估算,fr与环境温度,轮胎温度、车速以及路面类型等有关。本发明的fr估算模型有两个:fr初值估计模型和动态估计模型。初值估计模型用于fr的粗略估计,并为动态估计模型提供初值。这种估算方法计算量小,在精度要求不高的条件下,也可单独作为fr的估计。研究表明,轮胎温度以及车速对fr的影响远小于路面类型和环境温度对其的影响。因此,在本例中仅考虑环境温度和路面类型两个因素。在不同路面和温度条件下,采用目标车辆做滑行实验(coastdowntests),获得滚动阻力系数、环境温度和路面类型关系试验曲线。滚动阻力系数初值fr0拟合公式为
其中,ei(i=1~3)为拟合系数,ki为路面类型修正系数。
在本例中,在温度范围2~28℃,5种不同类型的路面上进行滑行实验,拟合得到的fr表达式为
其中,高速道路k1=1;光滑城市道路k2=1.05;光滑乡村道路k3=1.15;粗糙乡村道路k4=1.35;比利时(路面)道路k5=1.40。
(2)路面坡度计算模型
在路径已知的前提下,通过地理信息系统(gis)和gps路径经纬度可以计算得到路面坡度aslop(rad),即
其中,δh(m)为两个连续测量点之间的高度差。未来路径的高度数据由gis系统获得,如本例中的gis系统为nasa的srtm(shuttleradartopographymission)系统,路面高程采样点间隔为30m。
(3)整车质量及滚动阻力系数动态估算模型
bev整车质量mv随装载乘员数量以及货物的不同而变化,对bev能耗和剩余行驶里程产生较大的影响。但是,整车质量很难在车辆行驶时直接测量,因此,需要对行驶时的整车质量进行估计。同时,滚动阻力系数也会随着轮胎温度和路面条件而变化,前述的滚动阻力系数初值估计模型仅能用于预测精度要求不高的场合。
因此,为了精确估计车辆行驶时的整车质量和滚动阻力系数,本发明使用一种基于递推最小二乘(recursiveleast-squares,rls)估计算法的mv和fr动态估算模型。
rls估计算法基于车辆纵向动力学模型,在车辆行驶过程中,电机输出功率pm(w)为
其中,ffric(n)为车轮处的传动系统摩擦力,该值可由车轮自由转动试验获取,本例中,目标车辆的ffric值为15n。
将式(2.4)展开并写成线性估计的标准型为
其中,
选择经典rls方法使下式最小
其递归解为
其中
p的初始值设为1,信号采样频率为25hz,整车质量初始值设为1250kg,滚动阻力系数初值由式(2.1)确定。rls估算方法需要一定的时间才能稳定收敛,因此,在预测值未收敛前,rdr预测模型采用整车质量和滚动阻力系数的初始值。
part3车速预测模型
车速-时间历程曲线又称为行驶循环工况,简称工况。它是rdr预测模型的输入,也是bev能耗和rdr最主要的影响因素之一。车速-时间历程是一个典型的马尔科夫过程。因此,车速-时间历程经采样后是一条离散马尔科夫链(markovchain),所谓离散马尔科夫链是指具有马尔科夫过程特征的随机变量序列x1,x2,x3,...xn…,即在给定当前状态时,它与过去状态是条件独立的,表示为
由于车速-时间历程为马尔科夫链,因此,可以基于马尔科夫随机理论对车速历史数据进行统计并生成一条随机的车速-时间历程。在足够长的时间或运行足够多的次数的前提下,生成的车速曲线与历史车速曲线在统计特征上具有一致性。离散马尔科夫链生成预测车速保持了随机性,并且能够反映驾驶员的驾驶风格。但是,这种方法生成的车速具有很大的随机性,当运行次数较少时,所生成的预测车速与实测车速会存在很大的误差。因此,本发明提出一种基于路径信息的随机车速预测方法,通过gps、its获取未来的路径信息,并结合马尔科夫方法,生成一种可控的随机车速。其优点是,任意一次生成的随机车速统计特征都能与实测车速统计特征接近,并且保持了生成车速的随机性。
图6车速生成算法流程图。车速生成算法包括“生成转移概率矩阵(transitionprobabilitymatrices,tpms)”和“生成预测车速”两部分。第一部分主要是依据驾驶员的历史车速数据和路径信息,生成该驾驶员在不同路面上的转移概率矩阵。第二部分是基于未来的路径信息结合tpms生成预测车速。
(1)生成转移概率矩阵
步骤1工况数据采集与路径信息提取
历史车速数据的采集分为两个阶段:实车工况试验数据采集和用户实时工况数据采集。
在第一阶段,整车厂或系统制造商应使用匹配样车进行实车道路试验,试验车辆应装备有gps、电子地图、gis以及can数据采集系统。所需要获取的数据有车速时间(v-t)历程数据、车辆行驶轨迹(gps坐标)、道路信息(路径长度,道路类型,信号灯位置及红绿灯变换时间,转角位置及转角半径,减速带位置,交通流量数据等),驾驶员驾驶数据(方向盘转角,踏板开度,档位等),以及车辆行驶数据(电池soc、电池温度、电机转矩、电池端电压,电池端电流、电附件状态及消耗功率等)。道路试验应由不同行驶风格的驾驶员驾驶样车在不同类型的道路上完成,并且试验行驶里程要足够。该阶段采集的试验数据主要用于rdr计算模型和参数估计模型的初始校准以及生成基本的tpms数据库。
为了生成不同驾驶风格驾驶员的tpms,需要对驾驶风格进行评价和分类。驾驶员在某类型道路i上的驾驶风格指标jd(i)为
jd(i)=w1·eavg(i)+w2vm(i)+w3vmax(i)+w4aam(i)+w5abm(i)(3.2)
其中,eavg为该驾驶员在该类型道路上的平均能耗率,(kw/km);vm为平均速度,(km/h);vmax为最大速度,(km/h);aam为平均加速度,(m/s2);;abm为平均减速度(绝对值),(m/s2);w1~5为权系数。
在采集了多名驾驶员的样车道路试验数据后,由式(3.2)计算各驾驶员在各类型道路上的jd(i)并进行聚类分析。同一类性的道路试验数据将合并在一起,作为该类驾驶员的实车道路试验数据。聚类中心处的jd(i)即为该类典型驾驶风格指标jdnor(i)。本例中,将驾驶风格分为三类:普通型jdnor1(i),激进型jdnor2(i)和温和型jdnor3(i)。相对于普通型,激进型驾驶员在相同的驾驶环境下,具有较高的能耗、平均车速、最高车速和平均加减速度,温和型则相反。
在第二阶段,bev能耗预测和管理系统仍然需要收集用户的驾驶数据,具体的数据与第一阶段基本相同。该阶段采集的用户驾驶数据主要用于rdr计算模型和参数估计模型的在线校准以及生成该用户特有的tpms数据库。
表1道路类型及工况分段方法
在本例中,采用第一阶段道路试验方式获取工况试验数据。在某国典型公共道路上,采用目标车辆进行实测道路试验,工况数据总里程为600km,对工况数据进行数据处理,如滤波,异点剔除和数据对齐等。并按照道路类型将数据进行分类,对相同道路类型的车速数据进行分析,获得车速频次分布后进行数据拟合,获得该类型道路的“最大”车速vmax(包含80%车速数据处的车速值),“最小”车速vmin(包含20%车速数据的车速值)以及“平均”车速vnom(包含50%车速数据的车速值),(注意,这里的“最大”、“最小”和“平均”与通常意义不同,它们来自车速频次分布)如表1所示。本例将该国道路类型分成“城市”、“城郊”和“高速”三类,又将“城市”道路细分为“住宅区”、“三类”、“二类”和“主干路”。
图7为采用目标车辆在某城市内进行道路试验的路径及路径信息示意图。图中显示了本次试验的路径,该路径包括“住宅区”、“三类”和“主干道”三种城市道路类型,从电子地图可以获取上述道路的类型和长度。图中还标示出了路径转角(+)及交通灯(□)位置,以及当前的风向等。将上述路径信息与某次在该道路上的试验车速数据整合在一起,如图8所示。图中还显示了三种道路类型的最大车速vmax、最小车速vmin和平均车速vnom。
步骤2依据道路类型划分工况段
从图8可以看出,行驶工况(车速)是由工况片段组成的。在本发明中,工况片段定义为2个“最小”车速vmin之间的车速历程。按照该定义将整条工况分割成工况段,其方法是对车速历程求二阶导数,导数为零的点即为车速历程曲线的拐点,然后拐点中车速小于最小车速vmin的即为片段间断点vb,即
图8工况的片段间断点如图中“*”号所示。依据片段间断点将整条测试工况分成数个工况段。并按照工况段所处的路面类型,将工况段分类。图9为图8中“二类”道路的工况片段。
步骤3分割加速和减速阶段
每一个工况段都由一个加速阶段和一个减速阶段组成。分类后的工况片段还需要继续分割成加速阶段和减速阶段并计算加速度段距离比。其阶段间断点为各工况段的最大值点,如图9中的“*”所示。图10为将图9的“二类”道路工况片段分割成加速阶段和减速阶段,并聚类在一张图中。加速段距离比rda定义为
其中,n为工况段个数;sda(i)(km)为第i个工况段加速片段的长度;sd(i)(km)为第i个工况段的长度。
步骤4阶段车速数据网格化
重复步骤1~3,直到获取足够的试验车速数据,然后将同一驾驶员在同类道路上的加速段和减速段车速数据集中在一起,并对上述车速数据重新网格化和插值。在本例中,原车速数据距离单位为km,车速单位为km/s,在网格化时将单位转化为m和m/s。图11为加速阶段车速数据网格化示意图。本例中,距离的采样间隔为1m,车速的采样间隔为0.1m/s。车速数据网格化的方法是,按照距离间隔1m对阶段车速数据进行采样,若车速数据不在网格点上,需要对车速数据进行圆整。
步骤5统计状态转移数
对网格化后的阶段车速数据进行扫描,统计状态转移数,如图11所示。首先,生成tpms表格,表格的纵坐标为当前状态车速,横坐标为下一状态车速。扫描的车速间隔为0.1m/s,从最低车速到最高车速依次扫描状态车速。如图11,若当前扫描的车速状态为5.0m/s,图中有3个转移状态:5.1m/s、5.2m/s及5.3m/s。其中5.0m/s->5.1m/s和5.3m/s转移次数为1,5.0m/s->5.2m/s和5.2转移次数为2。没有转移的状态,转移次数为0。将上述转移数依次填入tpms表格。重复上述步骤,完成所有的阶段车速数据的扫描并得到所有状态转移数(频次)。
步骤6生成转移概率矩阵
转移概率pij由下式计算
其中,nij为从vi到vj的状态转移频次,s为总的转移状态数。
按照式(3.4)计算tpms表格中所有转移概率pij即能获得v-v形式的tpms,由加速度a=δv/δt,且δt=1s,得a=δv,可将v-v形式的tpms转化成v-a形式的tpms。图12为城市“二类”道路加速及减速阶段tpms。图中灰度的深浅代表着转移概率的大小。
重复上述步骤,生成不同驾驶风格(普通型,激进型和温和型),在各种道路上的加速及减速阶段tpms。并将这些tpms分类存储到数据库中并索引。
(2)生成预测车速
生成预测车速的过程如图6右侧所示,该过程基本上是tpms生成的逆过程。具体步骤如下:
步骤1获取未来路径坐标与路径信息
当驾驶员在车载导航系统中输入目的地后,系统从gps和电子地图中获取未来路径坐标(gps坐标)与路径信息(路径长度,道路类型,信号灯位置及红绿灯变换时间,转角位置及转角半径,减速带位置,交通流量数据等)。系统对上述数据进行处理,剔除异点,并依据行驶路径长度进行重采样。
步骤2生成参考工况
根据路径坐标以及路径信息生成一种模态工况,称为参考工况。下面以图7所示的某城市路径为例,说明模态工况的生成方法。图7中的路径包含3中路面类型,路径由路径节点(交通灯、转角和减速带等)分割成多个路段。一般地,驾驶员在通过路径节点时可能会减速或者停车,然后再加速行驶。因此,在2个节点之间可能会包含一个加速和减速阶段,即包含一个工况段。道路类型、节点的纬度lat和经度lon可从电子地图和导航系统上获取。
a、b两节点间的距离lab可由节点坐标计算得到,即
式中,r(m)为地球半径,lata和latb分别为a点和b点的纬度值,lona和lonb分别为a点和b点的经度值。
当路径上的拐角半径较大时,或者在十字路口上存在交通灯时,该处会存在多个节点。此时,应将多个节点合并成一个融合节点。当2个节点间的距离lab<lmin时,选取2节点中间位置作为融合节点的位置。
当节点仅为交通灯时(车辆直行),由于有一定的概率显示为绿灯,驾驶员将直接通过该节点。通过its系统,可以获取该交通灯红绿灯时长,并计算绿灯出现概率,即
由matalb随机函数生成一个0~1的随机数nlg,若nlg<plg,则该交通灯节点将被取消(认为是绿灯),否则,将保留该交通灯节点。
将上述节点按照位置排列,并将相同道路类型的节点用该类型的平均车速连接起来即组成该未来路径的“参考工况”,如图13所示。参考工况显示了道路类型,长度,平均车速以及节点位置等。它是将要生成的预测工况的“骨架”,2个节点之间即为一个工况片段。
步骤3tpms类型匹配
在生成“模态工况”之后,系统对当前车辆驾驶员的驾驶风格进行识别并匹配相应类型的tpms。
当车辆在某道路类型上行驶里程小于某一阈值sr1(如50km)时,系统无法获取足够的驾驶员行驶数据,此时,系统采用“普通型”驾驶风格的tpms。
当行驶里程超过sr1时,系统可以对该驾驶员的驾驶风格进行识别。按照式(3.2)计算该驾驶在道路类型i上的行驶风格指标jd(i),并计算与jdnor1(i)、jdnor2(i)和jdnor3(i)差的绝对值。差的绝对值最小的驾驶风格类型即为该驾驶员的驾驶风格。则使用该驾驶风格的tpms作为该驾驶员在该类型道路上的tpms。重复上述步骤,识别在各类型道路上该驾驶员的驾驶风格,并匹配tpms。
当该车辆在该类型道路上的行驶里程超过sr2(如100km),系统可以生成该驾驶员在该类道路上的tpm,生成方法同上。系统会对tpms进行扩充,并采用该驾驶员特有的tpms。
因此,在本发明中驾驶员历史工况数据经统计后成为以驾驶风格和道路类型为索引的tpms,存储量小,计算方便,并可实时更新。随行驶里程增加,概率转移矩阵对驾驶员驾驶行为特征代表性将增强,但存储容量增加不大;当储存的道路类型和驾驶风格tpms增加时,预测准确性将大幅提高,存储量仅小幅增加,适应车载系统要求。
步骤4生成工况段
依据“参考工况”,依次生成各类型道路上的工况段。下面以图13“二类”道路上的第一个工况段为例说明工况段生成的算法。图14为工况段生成算法示意图。设在图13“二类”道路上的第一个节点a(转角)和第二个节点b(转角)之间存在一个工况段,这两个节点的距离lab由式(3.5)计算,并将结果圆整到1m。如图14中lab=10m;加速段距离比由式(3.3)统计得到,设rda=0.6;则加速段长度为6m,减速段长度为4m。
设生成车速点的间隔为1m,速度值间隔为0.1m/s。该工况段的起始点车速v0为上一工况段的末尾点车速,本例中v0=5.0m/s。则下一米的车速将由该道路类型的加速tpms相应状态点的转移概率确定,本例中,车速5.0m/s有三个可以转移的状态5.1m/s、5.2m/s和5.3m/s,转移概率为0.25、0.5和0.25。采用matlab的随机数生成函数round()生成一个0~1之间的随机数确定转移状态,即
如图14所示,若生成的随机数为0.54,则依据式(3.7),下一状态v1=5.2m/s。重复该步骤依次生成该加速段的车速点,直到满足该加速段长度为止。然后以该加速段最后一个速度点vend作为减速段的起始点,选用该类型道路的减速tpms,按照与加速段相同(图14)的算法,生成减速段车速点。直到满足减速段长度为止。
步骤5工况段整合与滤波
重复步骤4,依次生成其他工况段车速,直到满足该类型路段的长度为止。生成的路段车速需要进行平滑和重采样,本例中,采用巴特沃斯滤波器(butterworthfilter)对生成车速进行平滑。
步骤6生成预测车速曲线
当道路类型变化时,需要选择相应的tpms,依次生成各路段车速曲线,直到预测车速距离与未来路径长度相等为止。图13中的预测车速曲线即为该城市路径上生成的预测车速。
依据剩余行驶里程预测算法架构和三个部分的数学模型,采用matlab/simulink建立基于路径信息的电动汽车剩余行驶里程预测仿真模型。用图7所示的城市道路工况进行仿真并验证模型的有效性和精度。仿真中,分别采用了2个驾驶风格不同驾驶员的实测行驶数据,并生成了这两个驾驶员在该城市工况下的tpms。图15为2个驾驶员在城市道路上的能耗实测与预测曲线。可以看到,驾驶员2比驾驶员1的能耗更高,二者相差8%左右,证明不同驾驶风格对能耗会产生较大的影响。采用本文提出的模型对能耗进行预测,从图15中可以看到,2个驾驶员的预测能耗都能够很好的与各自的实测能耗相吻合,说明提出的算法可以适应不同驾驶风格对能耗的影响。图16为驾驶员1在城市道路上的rdr实际和预测曲线,二者能够很好的吻合。为了验证本文提出的rdr预测模型精度,采用端点相对误差(tre)和均方根值误差(rmse)进行评价。
tre的定义为
其中,pt为预测曲线端点值(对于能耗预测取行程结束点的能耗值,对于rdr预测取起始点的rdr值);mt为实际曲线端点值。该值表征整个行程的累积预测误差。
rmse的定义为
其中,i为曲线采样点;n为采样点总个数;pi为曲线采样点i处的预测值;mi为曲线采样点i处的实测值。该值表征预测曲线与实测值的吻合度。
由于本方法获得的预测曲线是随机生成的,每次运行获得的预测曲线并不完全相同。因此,多次运行预测程序,计算驾驶员1在城市道路上的预测误差,结果如表2所示。可以看到能耗预测tre为0.86%,rdr为1.1%,说明累积误差很小。此外,从rmse误差也较小,预测曲线与实测值的吻合度较好。
表2城市道路工况下能耗及rdr预测误差
- 还没有人留言评论。精彩留言会获得点赞!