一种基于深度强化学习的智能汽车稳定性控制方法与流程
本发明涉及汽车动力学控制领域,更具体地说是一种基于深度强化学习的智能汽车稳定性控制方法。
背景技术:
汽车在转向时,轮胎侧偏角增大,侧向力增大,使车辆能够按照驾驶员意图行驶,但在一些低附着和急转向工况下,车辆的侧向力容易达到附着极限,车辆会发生侧滑、急转、侧翻等危险工况。目前,能对上述危险工况进行干预的主要方式是主动转向控制和直接横摆力矩控制。主动转向控制是通过给方向盘输入修正转角,改变车辆的横摆力矩;直接横摆力矩控制主要是通过调节车轮制动力形成制动力差,从而产生附加横摆力矩来调整车辆的转向不足或转向过度。
主动转向和直接横摆力矩控制对汽车性能的影响各有优缺点,单独主动转向控制对车速影响较小,保证了驾乘人员的舒适性,但在极限工况下效果不佳,无法控制车辆稳定,满足不了驾乘人员的安全性要求;单独的直接横摆力矩控制系统,可以保证驾乘人员在极限工况下的安全,但对车辆纵向加速度影响较大,满足不了驾乘人员的舒适性要求。而车辆作为复杂的非线性系统,各系统之间存在很多耦合作用,在车辆的每个状态,控制车辆稳定都有相对最优的控制输出,这些最优的控制输出之间并不是简单的线性关系,通过设计线性协调控制器也不能很好的保证驾乘人员的安全性和舒适性。
技术实现要素:
本发明为解决上述现有技术存在的不足,提出一种基于深度强化学习的智能汽车稳定性控制方法,以期能实现稳定工况和极限工况下直接横摆力矩控制和转向控制之间的最优协调控制规律,从而实现车辆稳定性控制,保证驾乘人员的安全性和舒适性。
本发明为解决技术问题采用如下技术方案:
本发明一种基于深度强化学习的智能汽车稳定性控制方法的特点是按如下步骤进行:
步骤1:获取车辆横向控制器决策输出的前轮转角δf以及车辆结构参数,包括:车辆轮距l、质心到前后轴距离lf和lr、前后轮侧偏刚度c1和c2、汽车质量m;
获取车辆行驶参数,包括:方向盘转角sw、车速u和路面摩擦系数μ;
步骤2:利用式(1)计算理想横摆角速度wd:
式(1)中,g为重力加速度,w为横摆角速度,并有:
步骤3:利用式(3)计算理想质心侧偏角βd:
βd=-min{|β|,|βmax|}·sign(δf)(3)
式(3)中,β为车辆质心侧偏角,βmax为车辆最大质心侧偏角,并有:
步骤4:利用式(6)定义深度强化学习方法的车辆状态参数s:
s={w,β,sw,wd,βd}(6)
步骤5:利用式(7)定义深度强化学习方法的动作参数a:
式(7)中,
步骤6:利用式(8)建立深度强化学习方法的奖励函数r:
r=re+rps+rv+rm+rsw+rst(8)
式(8)中,re为误差奖励函数,并有:
式(9)中,
式(8)中,rps为固定奖励值函数,并有:
式(8)中,rv为速度差奖励函数,并有:
式(8)中,rm为附加横摆力矩奖励函数,并有:
式(8)中,rsw为修正角奖励函数,并有:
式(8)中,rst为稳定域奖励函数,并有:
步骤7:构建深度强化学习方法的网络模型:
步骤7.1:构建动作网络模型,包括:包含一个神经元的一层输入层,各自包含n1个神经元的m1层隐藏层,包含2个神经元的一层输出层;初始化动作网络参数为θμ;
步骤7.2:构建评价网络模型,包括:各包含1个神经元的两层输入层,各自包含n2个神经元的m2层隐藏层,其中,第m2层隐藏层为全连接层,包含1个神经元的一层输出层;初始化评价网络参数为θq;
步骤7.3:构建与所述动作网络模型结构相同的目标动作网络模型,且令目标动作网络参数θμ′=θμ,构建与所述评价网络模型结构相同的目标评价网络模型,且令目标评价网络参数θq′=θq;
步骤8:由第i条样本形成n条样本:
初始化第i个车辆状态参数si,并以第i个车辆状态参数si作为所述动作网络模型的输入,由所述动作网络模型输出μ(si|θμ);
利用式(17)得到第i个车辆动作参数ai:
ai=μ(si|θμ)+ni(17)
式(17)中,ni表示第i个随机噪声;
根据式(8)获取第i个车辆奖励值ri,并得到更新后的第i个车辆状态参数s′i;从而得到获得第i条样本,记为(si,ai,ri,s′i),进而得到n条样本;
步骤9:用所述n条样本对所述深度强化学习方法的网络模型进行训练,从而得到得到最优动作网络模型和最优评价网络模型;
步骤10:判断式(18)和式(19)是否均成立,若均成立,则表示汽车处于稳定状态,否则,表示汽车处于不稳定状态,并执行步骤11:
式(18)中,k1为稳定域第一边界系数,k2为稳定域第二边界系数;
式(19)中,ε为可调参数;
步骤11:获取车辆当前状态参数st作为最优动作网络模型的输入,从而利用所述最优动作网络模型输出当前附加横摆力矩
步骤12:判断式(20)是否成立,若成立,则表示汽车的转向性质为不足转向,则令动作车轮为内后轮,并执行步骤13,否则,表示汽车的转向性质为过多转向,则令动作车轮为外前轮,并执行步骤14;
wd×(w-wd)>0(20)
步骤13:若δf>0,则令修正转角
步骤14:若δf>0,则令修正转角
本发明所述的智能汽车稳定性控制方法的特点也在于,所述步骤9是按如下过程进行:
步骤9.1:初始化学习率参数为α,回报率参数为γ;初始化i=1;
步骤9.2:以所述第i个车辆状态参数si作为当前第i个动作网络模型的输入,由所述当前第i个动作网络模型输出第i个输出值μ(si|θμ);
以所述第i个车辆状态参数si、第i个车辆动作参数ai和所述动作网络的第i个输出值μ(si|θμ)均作为所述当前第i个评价网络模型的输入,由所述第i个车辆状态参数si和第i个车辆动作参数ai经过所述当前第i个评价网络模型输出第i个输出值qi(ai);由所述动作网络模型的第i个输出值μ(si|θμ)经过所述当前第i个评价网络模型输出第i个输出值qi(μ(si|θμ));
以所述更新后的第i个车辆状态参数s′i作为所述当前第i个目标动作网络模型的输入,由所述当前第i个目标动作网络模型输出第i个输出值μ(s′i|θμ′);
以所述更新后的第i个车辆状态参数s′i和目标动作网络模型的第i个输出值μ(s′i|θμ′)作为所述当前第i个目标评价网络模型的输入,由所述当前第i个目标评价网络模型输出第i个输出值q′i(a′i);
根据所述当前第i个评价网络模型的第i个输出值qi(μ(si|θμ))利用策略梯度法对所述当前第i个动作网络模型进行更新,从而得到第i次更新后的动作网络模型并作为第i+1个动作网络模型;
根据当前第i个评价网络模型的输出qi(ai)以及所述当前第i个目标评价网络模型的输出q′i(a′i),利用最小化损失函数对所述当前第i个评价网络模型进行更新,从而得到第i次更新后的评价网络模型并作为第i+1个评价网络模型;
步骤9.3:将i+1赋值给i后,判断i>n是否成立,若成立,则表示得到最优动作网络模型和最优评价网络模型,否则,返回步骤9.2执行。
与现有技术相比,本发明有益效果体现在:
1、本发明利用深度强化学习算法的无模型和泛化预测优势,确定了它与车辆稳定性控制相关的输入状态和输出动作,设计了适应于协调控制的奖励函数,构建并训练出最优动作网络模型,从而利用该模型在稳定工况和极限工况下都能决策出最优的协调稳定性控制策略,从而实现了车辆稳定性控制,保证了驾乘人员的安全性和舒适性;
2、本发明所基于的深度强化学习算法不需要基于车辆模型设计算法模型,所采用的深度神经网络具有很强的非线性表达能力,可以表达出汽车状态与主动转向、差分制动控制之间的非线性关系,相比于基于简化的车辆模型设计出的线性控制器更符合真实情况;
3、本发明的控制方法对比无控制、主动转向控制、直接横摆力矩控制和线性分配协调控制,在不同工况下都具有较好的控制效果,具有更好的鲁棒性、在极限工况下则具有更好的舒适性。
附图说明
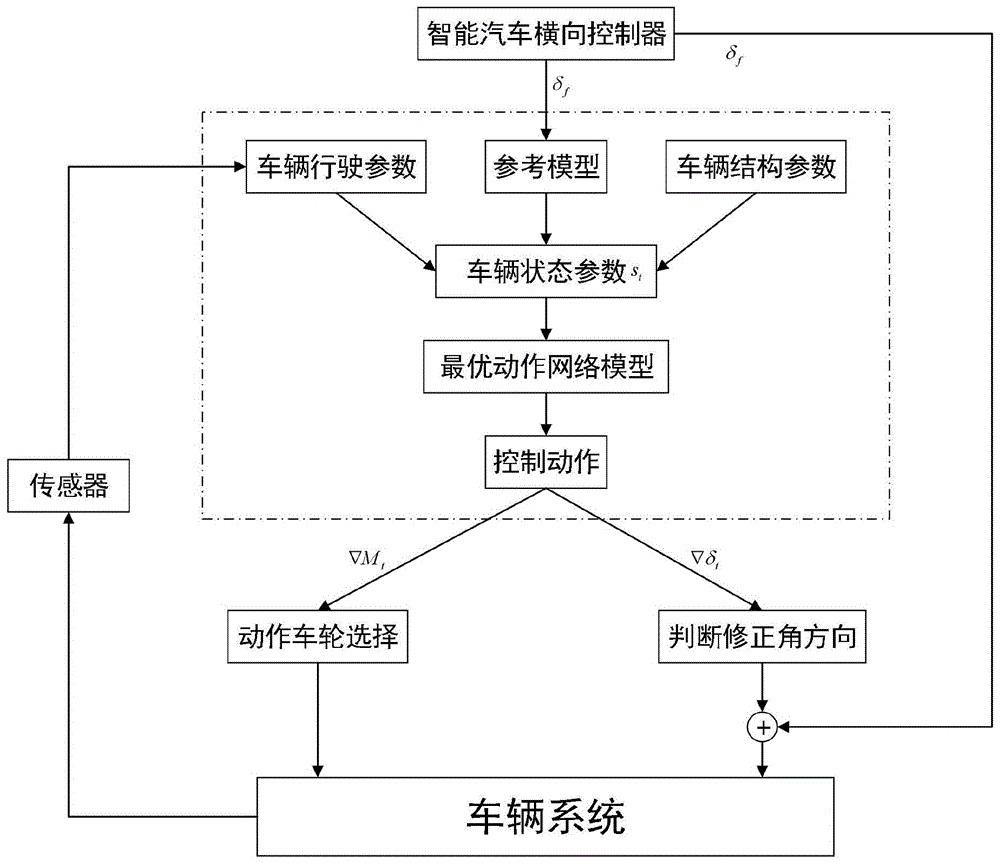
图1为本发明基于深度强化学习的智能汽车稳定性控制系统;
图2为本发明深度强化学习方法的训练过程图。
具体实施方式
本实施例中,一种基于深度强化学习的智能汽车稳定性控制方法能根据汽车当前状态参数,决策出当前修正转角和附加横摆力矩,从而实现汽车稳定性协调控制。具体的说,如图1所示,是按如下步骤进行:
步骤1:获取车辆横向控制器决策输出的前轮转角δf以及车辆结构参数,包括:车辆轮距l、质心到前后轴距离lf和lr、前后轮侧偏刚度c1和c2、汽车质量m;
获取车辆行驶参数,包括:方向盘转角sw、车速u和路面摩擦系数μ;
步骤2:利用式(1)计算理想横摆角速度wd:
式(1)中,g为重力加速度,w为横摆角速度,并有:
步骤3:利用式(3)计算理想质心侧偏角βd:
βd=-min{|β|,|βmax|}·sign(δf)(3)
式(3)中,β为车辆质心侧偏角,βmax为车辆最大质心侧偏角,并有:
步骤4:利用式(6)定义深度强化学习方法的车辆状态参数s:
s={w,β,sw,wd,βd}(6)
步骤5:利用式(7)定义深度强化学习方法的动作参数a:
式(7)中,
步骤6:利用式(8)建立深度强化学习方法的奖励函数r:
r=re+rps+rv+rm+rsw+rst(8)
奖励函数是整个深度强化学习算法的核心,能够引导深度神经网络参数的调整方向。在设计时应该首先给出设计原则,然后根据设计原则再设计具体的奖励函数。
本实例中奖励函数设置为4个优先级,优先级越高,则该原则越重要,设计原则为:
1级:本发明目的是实现汽车稳定性控制,因此保证汽车的稳定性是首要任务;
2级:转向控制相比于制动控制具有优势,所以要保证转向控制要优先于制动控制;
3级:尽可能使用较小的主动转向角或较小的制动压力控制汽车稳定;
4级:汽车在稳定区域内,尽可能使动作输出为0;
式(8)中,re为误差奖励函数,对应于1级设计原则,误差越小则奖励值越大,为了突出1级设计原则的重要性,误差奖励函数的变化率应该最大,因此设计二次函数作为1级奖励函数,并有:
式(9)中,
式(8)中,rps为固定奖励值函数,对应于2级设计原则,优先使用转向控制会获得较大的奖励值,并有:
式(8)中,rv为速度差奖励函数,对应于2级控制原则,转向相比于制动对速度影响较小,可以获得较大的奖励值,并有:
式(8)中,rm为附加横摆力矩奖励函数,对应于3级设计原则,并有:
式(8)中,rsw为修正角奖励函数,对应于3级设计原则,并有:
式(8)中,rst为稳定域奖励函数,对应于4级设计原则,在稳定域内,动作越小则奖励越大,并有:
步骤7:构建深度强化学习方法的网络模型:
步骤7.1:构建动作网络模型,包括:包含一个神经元的一层输入层,各自包含n1个神经元的m1层隐藏层,包含2个神经元的一层输出层;初始化动作网络参数为θμ;
步骤7.2:构建评价网络模型,包括:各包含1个神经元的两层输入层,各自包含n2个神经元的m2层隐藏层,其中,第m2层隐藏层为全连接层,包含1个神经元的一层输出层;初始化评价网络参数为θq;
步骤7.3:构建与动作网络模型结构相同的目标动作网络模型,且令目标动作网络参数θμ′=θμ,构建与评价网络模型结构相同的目标评价网络模型,且令目标评价网络参数θq′=θq;
步骤8:由第i条样本形成n条样本:
初始化第i个车辆状态参数si,并以第i个车辆状态参数si作为动作网络模型的输入,由动作网络模型输出μ(si|θμ);
利用式(17)得到第i个车辆动作参数ai:
ai=μ(si|θμ)+ni(17)
式(17)中,ni表示第i个随机噪声;
根据式(8)获取第i个车辆奖励值ri,并得到更新后的第i个车辆状态参数s′i;从而得到获得第i条样本,记为(si,ai,ri,s′i),进而得到n条样本;
步骤9:如图2所示,用n条样本对深度强化学习方法的网络模型进行训练:
步骤9.1:初始化学习率参数为α,回报率参数为γ;初始化i=1;
步骤9.2:以第i个车辆状态参数si作为当前第i个动作网络模型的输入,由当前第i个动作网络模型输出第i个输出值μ(si|θμ);
以第i个车辆状态参数si、第i个车辆动作参数ai和动作网络的第i个输出值μ(si|θμ)均作为当前第i个评价网络模型的输入,由第i个车辆状态参数si和第i个车辆动作参数ai经过当前第i个评价网络模型输出第i个输出值qi(ai);由动作网络模型的第i个输出值μ(si|θμ)经过当前第i个评价网络模型输出第i个输出值qi(μ(si|θμ));
以更新后的第i个车辆状态参数s′i作为当前第i个目标动作网络模型的输入,由当前第i个目标动作网络模型输出第i个输出值μ(s′i|θμ′);
以更新后的第i个车辆状态参数si'和目标动作网络模型的第i个输出值μ(s′i|θμ′)作为当前第i个目标评价网络模型的输入,由当前第i个目标评价网络模型输出第i个输出值q′i(a′i);
根据当前第i个评价网络模型的第i个输出值qi(μ(si|θμ))利用策略梯度法对当前第i个动作网络模型进行更新,从而得到第i次更新后的动作网络模型并作为第i+1个动作网络模型;
以当前第i个评价网络模型的输出qi(ai)以及当前第i个目标评价网络模型的输出q′i(a′i),利用最小化损失函数对当前第i个评价网络模型进行更新,从而得到第i次更新后的评价网络模型并作为第i+1个评价网络模型;
步骤9.3:将i+1赋值给i后,判断i>n是否成立,若成立,则表示得到最优动作网络模型和最优评价网络模型,否则,返回步骤9.2执行;
步骤10:判断式(18)和式(19)是否均成立,若均成立,则表示汽车处于稳定状态,否则,表示汽车处于不稳定状态,并执行步骤11:
式(18)中,k1为稳定域第一边界系数,k2为稳定域第二边界系数;
式(19)中,ε为可调参数;
步骤11:获取车辆当前状态参数st作为最优动作网络模型的输入,从而利用最优动作网络模型输出当前附加横摆力矩
步骤12:判断式(20)是否成立,若成立,则表示汽车的转向性质为不足转向,则令动作车轮为内后轮,并执行步骤13,否则,表示汽车的转向性质为过多转向,则令动作车轮为外前轮,并执行步骤14;
wd×(w-wd)>0(20)
步骤13:若δf>0,则令修正转角
步骤14:若δf>0,则令修正转角
- 还没有人留言评论。精彩留言会获得点赞!