一种基于端到端的深度强化学习换道决策方法和装置
1.本发明属于自动驾驶技术领域,尤其涉及一种基于端到端的深度强化学习换道决策方法和装置。
背景技术:
2.换道问题是自动驾驶领域中一个基础且关键的问题,是一项艰巨的任务,自动驾驶车辆需要警惕地观察其自身车道前方车辆和旁边车道上的周围车辆,并根据这些相关车辆所表现出的潜在对抗性或合作反应采取适当的行动。为了实现高级自动化且安全的换道驾驶,自动驾驶车辆就需要在复杂场景下学习做出正确合理的决策并控制其移动。
3.现有的自动驾驶换道决策方法主要分为三类:基于规则的换道决策方法、基于机器学习的换道决策方法以及基于强化学习的换道决策方法。
4.基于规则的换道决策方法,例如根据当前周围车辆的距离及车速,预定义一些换道规则来建立模型,这些方法多数引入一个虚拟换道轨迹或一系列的路点,以便换道时,自动驾驶车辆可以随轨迹行驶。它们的共同限制是在动态情况和不同驾驶风格下,计划轨迹缺乏灵活性。此外,虽然它在预先定义的情况下或在模型范围内可能工作得相对较好,但在处理超出定义范围的情况时,效果很不理想。
5.基于机器学习的换道决策方法,例如基于支持向量机的换道决策方法,在对大量样本数据进行适当训练后,可以在没有明确具体的设计和编程规则的情况下,能处理复杂场景中不可预见的情况。然而,在缺乏训练有素的模型和适当的策略设计时,自动驾驶车辆的行为仍然不够理想。
6.基于强化学习的换道决策方法,例如基于q-learning的换道决策方法,它有能力从试验和错误中学习,并为长期目标寻求最佳策略,具有更好的鲁棒性和安全性。但是,基于强化学习的换道决策算法难以处理高维度的输入数据,状态空间越大,算法构建就越复杂。
技术实现要素:
7.基于规则的换道决策方法在预先定义的情况下或在模型范围内可能工作得相对较好,但在处理超出定义范围的情况方面远远不够,而基于机器学习的换道决策方法在没有训练有素的模型和适当的策略设计,其最终效果可能难以让人满意。为了解决以上方法中存在的问题,同时也因为雷达设备的高成本问题,本发明使用低成本的单目相机作为输入设备,设计了一种端到端的基于注意力机制的深度强化学习网络,并以此为基础实现了一种基于端到端的深度强化学习换道决策方法和装置
8.为实现上述目的,本发明采用如下的技术方案
9.一种基于端到端的深度强化学习换道决策方法,包括以下步骤:
10.步骤1、初始化深度强化学习网络;
11.步骤2、将自动驾驶车辆前方相机采集图像信息输入到所述深度强化学习网络以
得到训练数据;
12.步骤3、根据所述训练数据训练深度强化学习网络,得到换道决策模型,所述换道决策模型用于建立所述图像信息与换道决策的直接连贯映射关系;
13.步骤4、根据自动驾驶车辆的当前环境,通过所述换道决模型进行正确安全的换道决策。
14.作为优选,步骤1中,初始化深度强化学习网络包括:定义并设置状态空间、奖励函数、记忆表以及动作空间。
15.作为优选,步骤2包括以下步骤:
16.步骤2.1、对自动驾驶车辆前方相机采集的图像信息进行预处理,获得符合要求的采集数据;
17.步骤2.2、将采集数据输入深度强化学习网络,得到车辆动作的第一奖励值,所述车辆动作包含左换道、右换道和保持车道;
18.步骤2.3、将采集数据、最高第一奖励值、第一奖励值最高的车辆动作以及执行车辆动作后的新状态存入记忆表中;然后判断记忆表是否装满,如果未装满则返回步骤2.1,如果装满则进入步骤3。
19.作为优选,步骤3包括以下步骤:
20.步骤3.1、将装满后记忆表中每条记录中的数据输入到深度强化学习网络,获得车辆动作的第二奖励值;
21.步骤3.2,根据第二奖励值计算其对应的损失值;
22.步骤3.3,根据所述损失值调整深度强化学习网络;若记忆表中仍存在未被使用的数据,则跳转到步骤3.1继续训练;若记忆表中的数据都已被使用,未终止则跳转到步骤2.1进行新一轮训练,若终止,则完成训练。
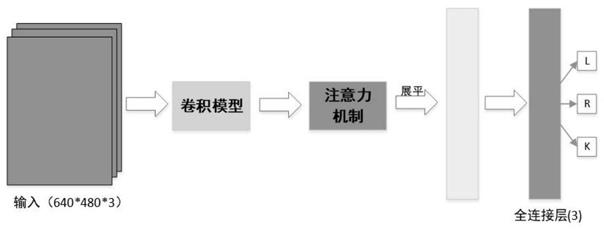
23.作为优选,步骤2中,深度强化学习网络为xception模型与cbam(convolutional block attention module)注意力机制以及两层全连接层组成的dqn(deep q net work)神经网络。
24.作为优选,步骤1中,状态空间大小为[640,480,3];动作空间大小为3,分别为左换道、右换道以及保持车道三个动作;记忆表大小为2000,用于存储当前状态、下一时刻状态、选取车辆动作以及车辆动作的奖励值;奖励函数为基于保持车道动作的第一奖励函数,所述第一奖励函数取决于当前车辆与前方车辆的距离以及速度差,或者奖励函数为基于左右换道的第二奖励函数,第二奖励函数取决于目标车道上的目标车辆的距离与车速。
[0025]
作为优选,步骤2中,dqn神经网络的输入为当前状态值,输出的为预测的各车辆动作价值量,在每一个时间步,根据各个动作价值量,通过贪婪算法e-greedy选择动作,根据选择的动作得到奖励值以及下一个时刻状态,其中下一时刻状态指车辆执行动作后的新状态。
[0026]
作为优选,步骤3中,深度强化学习网络的损失函数定义如下:
[0027]
l=e[r+γmaxq(s',a')-q(s,a)]2[0028]
其中,s与a为当前时刻的状态和动作,s'与a'为下一时刻的状态和动作,γ为学习率,r为奖励值,e为求数学期望,q为网络的输出值即输入动作s和a来获得网络输出值q。
[0029]
本发明还公开一种基于端到端的深度强化学习换道决策装置,包括,
[0030]
初始化模块,用于初始化深度强化学习网络;
[0031]
获取模块,用于将自动驾驶车辆前方相机采集图像信息输入到所述深度强化学习网络以得到训练数据;
[0032]
训练模块,用于根据所述训练数据训练深度强化学习网络,得到换道决策模型,所述换道决策模型用于建立所述图像信息与换道决策的直接连贯映射关系;
[0033]
决策模块,用于根据自动驾驶车辆的当前环境,通过所述换道决模型进行正确安全的换道决策。
[0034]
作为优选,深度强化学习网络包括:定义并设置状态空间、奖励函数、记忆表以及动作空间;其中,状态空间大小为[640,480,3];动作空间大小为3,分别为左换道、右换道以及保持车道三个动作;记忆表大小为2000,用于存储当前状态、下一时刻状态、选取车辆动作以及车辆动作的奖励值;奖励函数为基于保持车道动作的第一奖励函数,所述第一奖励函数取决于当前车辆与前方车辆的距离以及速度差,或者奖励函数为基于左右换道的第二奖励函数,第二奖励函数取决于目标车道上的目标车辆的距离与车速。
[0035]
本发明的端到端的网络结构将输入的图像信息与换道决策输出形成直接连贯的映射,简单来说就是输入一张自动驾驶车辆前方相机采集的图片到深度强化学习网络中,网络直接输出左换道或右换道或保持车道的决策。本发明的方法针对自动驾驶车辆在实际道路上的换道决策的问题,提出基于端到端的深度强化学习的换道决策方法,同时端到端的设计,使得视觉输入与决策输出实现了直接映射,有效防止了模块之间的误差传递与积累,使得自动驾驶车辆可根据图像特征与换道决策形成映射关系,且由于网络中增加了注意力机制,网络的收敛速度得到提升。相比于其他传统的方法,该方法不仅具有较高的鲁棒性,而且可以大大降低开发成本以及硬件成本,为自动驾驶技术的落地增加了可能性。
附图说明
[0036]
图1为本发明基于端到端的深度强化学习换道决策方法的网络结构;
[0037]
图2为本发明基于端到端的深度强化学习换道决策方法的流程图;
[0038]
图3为本发明基于端到端的深度强化学习换道决策装置的结构示意图。
具体实施方式
[0039]
如图1和2所示,本发明提供一种基于端到端的深度强化学习换道决策方法,包括以下步骤:
[0040]
步骤1、初始化深度强化学习网络,定义并设置状态空间、奖励函数、记忆表、以及动作空间;
[0041]
步骤2、将自动驾驶车辆前方相机采集图像信息输入到所述深度强化学习网络以得到训练数据,包括以下步骤:
[0042]
步骤2.1、对自动驾驶车辆前方相机采集的图像信息进行预处理,获得符合要求的采集数据;
[0043]
步骤2.2、将采集数据输入深度强化学习网络,得到车辆动作的第一奖励值,所述车辆动作包含左换道、右换道和保持车道;
[0044]
步骤2.3、将采集数据、最高第一奖励值、第一奖励值最高的车辆动作以及执行车
辆动作后的新状态存入记忆表中;然后判断记忆表是否装满,如果未装满则返回步骤2.1,如果装满则进入步骤3;
[0045]
步骤3、根据所述训练数据训练深度强化学习网络,得到换道决策模型,包括以下步骤:
[0046]
步骤3.1、将装满后记忆表中每条记录中的数据输入到深度强化学习网络,获得车辆动作的第二奖励值;
[0047]
步骤3.2,根据第二奖励值计算其对应的损失值;
[0048]
步骤3.3,根据所述损失值调整深度强化学习网络;若记忆表中仍存在未被使用的数据,则跳转到步骤3.1继续训练;若记忆表中的数据都已被使用,未终止则跳转到步骤2.1进行新一轮训练,若终止,则完成训练;
[0049]
步骤4、根据自动驾驶车辆的当前环境,通过训练后的换道决策模型进行正确安全的换道决策。
[0050]
进一步,步骤1中,深度强化学习网络为xception模型与cbam注意力机制以及两层全连接层组成的dqn神经网络。
[0051]
进一步,步骤1中,状态空间大小为[640,480,3],也就是经过处理后的图片数据;动作空间大小为3,分别为左换道、右换道以及保持车道三个动作;记忆表大小为2000,用以存储决策时的当前状态、下一状态、获得的奖励以及采取的动作;奖励函数分为两种情况:第一种情况是选择保持车道动作的奖励函数,该奖励函数取决于当前车辆与前方车辆的距离以及速度差,奖励函数如下:
[0052]
r1=w1*(x
dis-x
safe
)+w2*(v
self-v
front
)
ꢀꢀꢀ
(1)
[0053]
其中,w1与w2为权重常数,通常设置w1为0.5,w2为-0.5,x
dis
为当前车辆与前车的距离,v
self
为当前车辆车速,v
front
为前方车辆车速,x
safe
为安全距离,其计算与当前车速有关,公式如下:
[0054][0055]
其中,t为人的反应时间,u为当前车辆纵向加速度,d
t
是一个安全阈值,可以根据需求定义,一般是1。
[0056]
第二种情况为选取左右换道的奖励函数,该奖励函数取决于目标车道上的目标车辆的距离与车速,公式如下:
[0057]
r2=w3*(x
dis-x
safe-(v
self-v
target
)t1)
ꢀꢀꢀ
(3)
[0058]
其中,w3为权重常数,通常设置为0.5,x
dis
为当前车辆与目标车辆的距离,t1为换道所需时间,通常为1.5秒左右。
[0059]
进一步,步骤2中,相机采集到的rgb图像大小为640
×
480,在输入进深度强化学习模型前,将图片数据转化为维度[640,480,3]的数组数据。最终的输入层包含3通道,每一个通道都为640
×
480。
[0060]
进一步,步骤2中,dqn神经网络的输入是当前状态值s,输出的是预测的各动作价值量q(s,a),在每一个时间步,根据个动作价值量q(s,a),使用贪婪算法e-greedy选择动作,做出决策,根据选择动作得到一个奖励值r以及下一个状态s',这样就完成一个时间步。
[0061]
进一步,步骤3中,深度强化学习网络的损失函数定义如下:
[0062]
l=e[r+γmaxq(s',a')-q(s,a)]2ꢀꢀꢀ
(4)
[0063]
其中,s与a为当前时刻的状态和动作,s'与a'为下一时刻的状态和动作,γ为学习率,r为奖励值。
[0064]
如图3所示,本发明提供一种基于端到端的深度强化学习换道决策装置,实现上述深度强化学习换道决策方法包括:
[0065]
初始化模块,用于初始化深度强化学习网络;
[0066]
获取模块,用于将自动驾驶车辆前方相机采集图像信息输入到所述深度强化学习网络以得到训练数据;
[0067]
训练模块,用于根据所述训练数据训练深度强化学习网络,得到换道决策模型,所述换道决策模型用于建立所述图像信息与换道决策的直接连贯映射关系;
[0068]
决策模块,用于根据自动驾驶车辆的当前环境,通过所述换道决模型进行正确安全的换道决策。
[0069]
进一步,深度强化学习网络包括:定义并设置状态空间、奖励函数、记忆表以及动作空间;其中,状态空间大小为[640,480,3];动作空间大小为3,分别为左换道、右换道以及保持车道三个动作;记忆表大小为2000,用于存储当前状态、下一时刻状态、选取车辆动作以及车辆动作的奖励值;奖励函数为基于保持车道动作的第一奖励函数,所述第一奖励函数取决于当前车辆与前方车辆的距离以及速度差,或者奖励函数为基于左右换道的第二奖励函数,第二奖励函数取决于目标车道上的目标车辆的距离与车速
[0070]
实施例1:
[0071]
本实施例1的软件环境为ubuntu18.04系统,python为3.7,仿真实验平台为carla0.9.10,tensorflow-gpu版本为2.1.0,相机输入为仿真平台中的rgb相机分辨率为640
×
480。
[0072]
本发明实施例包括以下步骤:
[0073]
步骤1、初始化深度强化学习网络,深度强化学习网络为xception模型与三层全连接层组成的dqn网络,定义并设置状态空间、奖励函数、记忆表、以及动作空间。状态空间大小为640
×
480
×
3,记忆表大小为2000,动作空间大小为3;
[0074]
步骤2、将自动驾驶车辆前方相机采集图像信息输入到所述深度强化学习网络以得到训练数据,包括以下步骤:
[0075]
步骤2.1、对自动驾驶车辆前方相机采集的图像信息进行预处理,获得符合要求的采集数据;
[0076]
步骤2.2、将采集数据输入深度强化学习网络,得到车辆动作的第一奖励值,所述车辆动作包含左换道、右换道和保持车道;
[0077]
步骤2.3、选取奖励值最高的动作来进行下一步行动。若选取左换道,则自动驾驶车辆将进行左换道操作,换道(成功或者撞车失败)结束后,将采集数据、左换道对应的第一奖励值、左换道以及执行左换道后的新状态存入记忆表中;然后判断记忆表是否装满,如果未装满则返回步骤2.1,如果装满则进入步骤3;
[0078]
步骤3、根据所述训练数据训练深度强化学习网络,得到换道决策模型,包括以下步骤:
[0079]
步骤3.1、将装满后记忆表中每条记录中的数据输入到深度强化学习网络,获得车
辆动作的第二奖励值;
[0080]
步骤3.2,根据第二奖励值计算其对应的损失值;
[0081]
步骤3.3,根据所述损失值调整深度强化学习网络;若记忆表中仍存在未被使用的数据,则跳转到步骤3.1继续训练;若记忆表中的数据都已被使用,未终止则跳转到步骤2.1进行新一轮训练,若终止,则完成训练;
[0082]
步骤4、根据自动驾驶车辆的当前环境,通过训练后的换道决策模型进行正确安全的换道决策。
[0083]
本发明的方法针对自动驾驶车辆在实际道路上的换道行为存在的问题,提出基于端到端的深度强化学习的换道决策方法,同时端到端的设计,使得视觉输入与决策输出实现了直接映射,有效防止了模块之间的误差传递与积累,使得自动驾驶车辆可根据图像特征与换道决策形成映射关系。相比于其他传统的方法,该方法不仅具有较高的鲁棒性,而且可以大大降低开发成本以及硬件成本,为自动驾驶技术的落地增加了可能性。
[0084]
尽管已参照优选实施例描述了本发明的方法原理,但本领域的技术人员应理解,上述实施例仅供说明本发明之用,而并非是对本发明的限制,有关技术领域的普通技术人员,在不脱离本发明范围的情况下,做出的各种变化、变型、修改、替换、改进等技术方案,均应属于本发明公开的范畴。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1