半监督的盾构隧道掌子面地质类型预估方法及系统与流程
骤:
8.步骤1:从机器数据中筛选出与地质条件有关的机器参数;
9.步骤2:对筛选出的机器参数进行预处理;
10.步骤3:根据预处理后的机器参数构造无标签数据集和带标签数据集;
11.步骤4:建立预测隧道掌子面地质条件的半监督框架,得到地质特征提取器和特征 分类器;
12.步骤5:利用带约束的densenet自编码网络与无标签数据集训练地质特征提取器;
13.步骤6:利用深度神经网络与带标签数据集训练地质特征分类器,最终实现对掌子 面前方地质类型的预测。
14.优选的,所述步骤5还包括在原始的损失函数中加上环内提取的特征具有相似性的 约束以及邻近环提取的特征与该环提取的特征具有相似性的约束。
15.优选的,所述步骤5还包括改进的损失函数如下:
[0016][0017]
其中,m
k
为第k环样本大小,x
i,k
为第k环的第i个样本,为x
i,k
的重构结果, f
i,k
为第k环第i个样本提取的特征,为第k环提取的特征的平均值,为第k环后 面第j环特征的平均值,为第k环前面第j环特征的平均值,λ0和λ
j
为对应的权重 因子,loss为损失函数,用于训练神经网络进行调参。
[0018]
优选的,所述步骤2包括如下步骤:
[0019]
步骤2.1:利用孤立森林算法对筛选的机器参数的异常值进行检测,并删除异常值;
[0020]
步骤2.2:利用筛选的机器参数的额定值或者量程对异常值处理后的数据进行归一 化处理。
[0021]
优选的,所述步骤3包括:对不同的地质类型进行编号,利用各环筛选的机器参数 构造无标签数据集,利用带地质标签的环的机器参数构造带标签数据集。
[0022]
优选的,所述步骤3中对无标签数据集和带标签数据集的划分方式如下:
[0023]
对于无标签数据集,将一条隧道前l环数据用于构造无标签训练集,将其余环数据 用于构造无标签验证集;
[0024]
对于带标签数据集,将一条隧道部分环数据用于构造带标签训练集与带标签验证集, 将该隧道其余环数据用于构造第一带标签测试集,同时将另一条隧道的数据用于构造第 二带标签测试集。
[0025]
优选的,该方法还包括步骤7:利用带地质标签数据集验证盾构隧道掌子面地质类 型预测模型的有效性,并与多种常用的有监督学习算法的识别结果进行比较,最终证明 了所提的方法的有效性与优越性。
[0026]
根据本发明提供的一种半监督的盾构隧道掌子面地质类型预测系统,其特征在
于, 应用权利要求1
‑
7任一所述的一种半监督的盾构隧道掌子面地质类型预测方法,包括如 下模块:
[0027]
模块m1:从机器数据中筛选出与地质条件有关的机器参数;
[0028]
模块m2:对筛选出的机器参数进行预处理;
[0029]
模块m3:根据预处理后的机器参数构造无标签数据集和带标签数据集;
[0030]
模块m4:建立预测隧道掌子面地质条件的半监督框架,得到地质特征提取器和特征 分类器;
[0031]
模块m5:利用带约束的densenet自编码网络与无标签数据集训练地质特征提取器;
[0032]
模块m6:利用深度神经网络与带标签数据集训练地质特征分类器,最终实现对掌子 面前方地质类型的预测。
[0033]
优选的,所述模块m5还包括在原始的损失函数中加上环内提取的特征具有相似性 的约束以及邻近环提取的特征与该环提取的特征具有相似性的约束。
[0034]
优选的,所述模块m5还包括改进的损失函数如下:
[0035][0036]
其中,m
k
为第k环样本大小,x
i,k
为第k环的第i个样本,为x
i,k
的重构结果, f
i,k
为第k环第i个样本提取的特征,为第k环提取的特征的平均值,为第k环后 面第j环特征的平均值,为第k环前面第j环特征的平均值,λ0和λ
j
为对应的权重 因子,loss为损失函数,用于训练神经网络进行调参。
[0037]
与现有技术相比,本发明具有如下的有益效果:
[0038]
1、本发明提出了一种预测盾构隧道掌子面地质条件的半监督框架,相对于现有的 无监督和有监督方法,能充分利用有限的带地质标签的机器数据和大量的无地质标签的 机器数据来训练地质类型预测模型,同时在无监督训练中加入邻近空间地质特征具有相 似性的约束以提高地质特征提取的精度,相比于传统的仅利用有标签数据的有监督学习 方法,具有更高的分类精度和更好的泛化性能,能更有效地指导盾构施工,提高盾构掘 进效率;
[0039]
2、本发明提出了一种新的基于带约束的densenet自编码(cdae)与深度神经网络 (dnn)的盾构隧道掌子面地质类型预测方法,在无监督学习的损失函数中加入环内与 环间特征具有相似性的约束,保证提取的特征与地质类型有关,提升了盾构隧道掌子面 前方地质类型预测模型的分类精度和泛化性能,能为盾构司机优化操作提供指导,最终 提升隧道施工效率和安全性。
[0040]
3、本发明能在无监督学习中提取出与地质类型有关的特征,并进一步利用有监督 学习算法对特征进行分类识别,能充分利用无地质标签的机器数据和带地质标签的机器 数据,最终提升模型的分类精度和泛化性能。
附图说明
[0041]
通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明的其它特征、 目的和优点将会变得更明显:
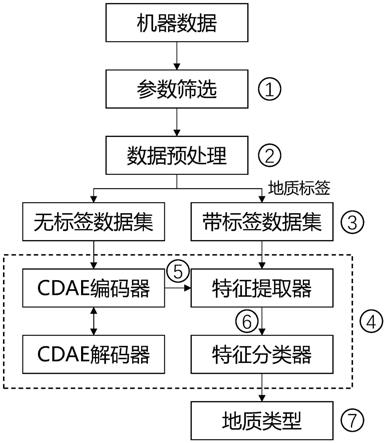
[0042]
图1为本发明基于带约束的densenet自编码与深度神经网络的半监督的盾构隧道 掌子面地质类型预测方法流程图;
[0043]
图2为基于带约束的densenet自编码与深度神经网络的半监督的盾构隧道掌子面 地质类型预测方法所提算法的优越性的验证图;
具体实施方式
[0044]
下面结合具体实施例对本发明进行详细说明。以下实施例将有助于本领域的技术人 员进一步理解本发明,但不以任何形式限制本发明。应当指出的是,对本领域的普通技 术人员来说,在不脱离本发明构思的前提下,还可以做出若干变化和改进。这些都属于 本发明的保护范围。
[0045]
本发明实施例公开了一种半监督的盾构隧道掌子面地质类型预测方法及系统,如图 1所示,包括如下步骤如下:
[0046]
步骤1:筛选出与地质条件有关的机器参数,这些参数来自推进系统、刀盘驱动系 统、注浆系统、土仓添加剂注入系统、盾尾密封系统、排土系统及电气系统等,共177 个机器参数,作为模型的输入特征。推进系统相关机器参数有推力、液压缸推进速度、 铰接油缸角度等。刀盘驱动系统相关机器参数有刀盘转速、扭矩、电机功率等。注浆系 统相关机器参数有a/b液流量、a/b液压力等。土仓添加剂注入系统相关机器参数有土 仓压力、膨润土/聚合物/泡沫流量等,盾尾密封系统相关机器参数有密封油脂压力等, 排土系统相关机器参数有螺旋输送机转速、压力等,电气系统相关机器参数有系统电压、 电流等。
[0047]
步骤2:对筛选出的机器参数进行预处理,包括异常值处理和归一化处理。
[0048]
步骤2包括如下步骤:步骤2.1:利用孤立森林算法对筛选出的机器参数的数据异 常值进行检测,并删除异常值。步骤2.2:利用筛选的机器参数的额定值或者量程对异 常值处理后的数据进行归一化处理,额定值比如是传感器额定值,量程比如是传感器量 程。具体方式如下:
[0049][0050]
其中,x
i
为第i(i=1,2,3,
…
,177)个机器参数的实时监测值,x
i_min
为第i个变量的额 定最小值,x
i_max
为第i个变量的额定最大值,x
i_norm
为x
i
归一化处理后的结果。
[0051]
步骤3:对不同的地质类型进行编号(0~n),n为整数,用于表征不同地质的标签, 比如有五类地质类型,那么标签就为0~4(0,1,2,3,4),标签均为整数,本实施例 n=4,利用各环筛选的机器数据构造无标签数据集,利用带地质标签的环的机器数据构 造带标签数据集,无地质标签数据集与带地质标签数据集的划分方式如下:
[0052]
(1)对于无地质标签数据集,将其中一条隧道前l(l比如是400)环数据用于构造 无标签训练集,将其余环数据(400至500环数据)用于构造无标签验证集;
[0053]
(2)对于带地质标签数据集,将一条隧道部分环数据用于构造带标签训练集与带 标签验证集,将该隧道其余环数据用于构造第一带标签测试集,同时将另一条隧道的数 据
用于构造第二带标签测试集。将构造无标签数据集对应的隧道的10个钻探点对应的 环的数据用于构造带标签训练集与带标签验证集(带标签训练集:带标签验证集=8:2), 将该隧道其余5个钻探点对应的环的前40次采样数据用于构造第一带标签测试集,同 时将另一条隧道6个钻探点对应的环的前40次采样数据也用于构造第二带标签测试集。
[0054]
步骤4:提出一种预测隧道掌子面地质条件的半监督框架,它利用无地质标签的机 器数据与无监督自编码算法训练地质特征提取器,利用带地质标签的机器数据与有监督 算法实现对提取的地质特征的分类,其中无监督学习的损失函数为改进的重构误差,有 监督学习的损失函数为交叉熵。
[0055]
步骤5:利用带约束的densenet自编码网络(constrained dense convolutional autoencoder,cdae)与无地质标签数据集训练地质特征提取器,在原始的损失函数的 重构误差中加上环内提取的特征具有相似性的约束以及邻近环提取的特征与该环提取 的特征具有相似性的约束,改进的损失函数如下:
[0056][0057]
其中,m
k
为第k环样本大小,x
i,k
为第k环的第i个样本,为x
i,k
的重构结果,f
i,k
为 第k环第i个样本提取的特征,为第k环提取的特征的平均值,为第k环后面第 j环特征的平均值,为第k环前面第j环特征的平均值,λ0和λ
j
为对应的权重因子。 loss为损失函数,用于训练神经网络进行调参;loss的第一项(等 号右边第一个加号之前)表征第k环数据的重构误差;loss的第二项征第k环数据的重构误差;loss的第二项(等号右边第一个加号之后,第二个加号之前)为第k环数据提取的特征与其特征 的平均值的偏差,表征环内特征相似性约束;loss的第三项内特征相似性约束;loss的第三项(等号右边第二个加号之后)为第k环数据提取的特征的平均值与其前后 相邻若干环特征的平均值的偏差,表征环间特征相似性约束。loss的第二项和第三项是 在无监督学习基础上施加的“约束”,用于保证学习到想要的特征。损失函数(loss)的 第一项为重构误差,第二项为环内特征相似性约束,第三项为环间特征相似性约束。无 监督学习的损失函数中环内及环间特征的相似性用欧式距离衡量,同时在相似性约束项 前面乘以权重系数。
[0058]
步骤6:利用深度神经网络(deep neural network,dnn)与带地质标签数据集的 训练集和验证集来训练地质特征分类器,最终实现对掌子面前方地质类型的预测。
[0059]
步骤7:利用带地质标签数据集验证盾构隧道掌子面地质类型预测模型的有效性, 并与多种常用的有监督学习算法的识别结果进行比较,最终证明了所提的方法的有效性 与优越性。步骤7包括如下步骤:
[0060]
步骤7.1:针对地质特征提取器有效性的验证,利用t
‑
sne对高维数据进行降维可 视化,对带地质标签训练集的原始输入进行降维可视化,同时将带地质标签训练集输入 到
训练好的特征提取器中得到带标签特征集的训练集并进行降维可视化,对比二者的聚 类结果,证明了建立的特征提取器的有效性。
[0061]
步骤7.2:针对地质特征分类器有效性的验证,将带地质标签测试集输入到训练好 的特征提取器中得到带标签特征集的测试集,然后将其输入到地质特征分类器,绘制多 分类混淆矩阵,统计查准率、查全率与f1度量,其中f1度量是对分类精度的综合评价。
[0062]
步骤7.3:如图2所示,针对所提算法优越性的验证,将带标签数据集的训练集、 第一带标签测试集和第二带标签测试集输入到卷积神经网络、深度神经网络、随机森林、 决策树、k最近邻和支持向量机这几个常用的有监督算法建立的分类器,绘制多分类混 淆矩阵,统计查准率、查全率与f1度量,并与所提方法识别效果展开对比,证明了所提 的方法的优越性。
[0063]
本领域技术人员知道,除了以纯计算机可读程序代码方式实现本发明提供的系统及 其各个装置、模块、单元以外,完全可以通过将方法步骤进行逻辑编程来使得本发明提 供的系统及其各个装置、模块、单元以逻辑门、开关、专用集成电路、可编程逻辑控制 器以及嵌入式微控制器等的形式来实现相同功能。所以,本发明提供的系统及其各项装 置、模块、单元可以被认为是一种硬件部件,而对其内包括的用于实现各种功能的装置、 模块、单元也可以视为硬件部件内的结构;也可以将用于实现各种功能的装置、模块、 单元视为既可以是实现方法的软件模块又可以是硬件部件内的结构。
[0064]
以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上 述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变化或修改, 这并不影响本发明的实质内容。在不冲突的情况下,本技术的实施例和实施例中的 特征可以任意相互组合。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1