一种带自表达的电子鼻非目标干扰气体识别方法与流程
本发明属于一种电子鼻的气体检测领域。
背景技术:
中国专利文献CN102866179 A于2013年1月9日公开了基于人工智能学习机的电子鼻中非目标干扰气味的在线识别和抑制方法,其识别方法的步骤包括目标气体和典型非目标干扰气味数据样本的采集、传感器阵列信号预处理、目标气体和非目标干扰气味样本的特征提取、人工智能学习机的训练学习和智能学习机对非目标干扰气味的实时在线识别。它利用人工智能模式识别出了目标气体和非目标干扰气味,赋予了检测信号的类别标志。
由于上述方法采用二类分类器:目标气体视为一类,非目标气体视为一类,两类对象的标志分别设为0和1,其中“0”代表非目标干扰气体类,“1”代表目标气体类。首先获取目标气体数据集和非目标气体数据集,然后训练一个二类分类器,并进行分类,从而可以判别出干扰气体样本。但是这种方法存在一个问题:虽然六种目标气体(即甲醛、苯、甲苯、一氧化碳、二氧化氮和氨气)已确定,但非目标干扰气体种类和数量繁多,在实际生活中,有无数种干扰气味的存在。然而,由于实验条件和现实原因,无法获得非目标干扰气体足够的样本进行训练,使用上述方法就不能识别。
技术实现要素:
针对现有技术存在的问题,本发明所要解决的技术问题就是提供一种带自表达的电子鼻非目标干扰气体识别方法,该方法只需要待检测的目标气体的数据,以及很少部分非目标干扰气体数据,分两步进行训练,就能够识别出其他非目标干扰气体。
本发明所要解决的技术问题是通过这样的技术方案实现的,它包括有
步骤1、取电子鼻检测的多类目标气体数据和少量非目标干扰气体数据,并将目标气体数据分为目标气体训练集X和目标气体误差阈值训练集X1两部分,非目标干扰气体数据为干扰气体误差阈值训练集Y。其中目标气体训练集X用于第一阶段训练,即找到自表达矩阵α,而目标气体误差阈值训练集X1和干扰气体误差阈值训练集Y用于第二阶段训练,即找到区别目标气体与干扰气体的误差阈值T,该误差是利用第一阶段训练出的自表达矩阵α进行计算获得;
步骤2、已知目标气体训练集X,由以下式子求解表达系数矩阵α=[α1,α2,…,αN];
式(1)中αi为自表达向量,表示样本xi被X中所有样本表达的程度,i=1,2,…,N,N为目标气体训练集X的样本总数;λ是正则项系数;
步骤3、使用目标气体误差阈值训练集X1和干扰气体误差阈值训练集Y,对应(7)式分别计算出两个训练集的平均误差集e1和e2;
计算e1时,y表示目标气体误差阈值训练集X1的单个样本;计算e2时,y表示干扰气体训练集Y的单个样本;
步骤4、根据E=[e1,e2]确定区分目标气体与非目标干扰气体阈值T的搜索范围[Emin,Emax],针对每个T值得到目标气体误差阈值训练集X1的准确度P1和非目标干扰气体误差阈值训练集Y的检测准确度P2;
步骤5、P=P1+P2,P值最大对应的T值为所找的理想阈值。
由于采用了上述技术方案,本发明的技术效果是:它避免了大量采集非目标干扰气体数据的实验过程,以及复杂的训练程序,能够简便地识别出非目标干扰气体。
附图说明
本发明的附图说明如下:
图1为p=2时目标-干扰气体识别率随阈值T的变化曲线图;
图2为p=1时目标-干扰气体识别率随阈值T的变化曲线图;
图3为p=2时传感器对干扰数据集1的测试响应曲线;
图4为p=2时传感器对干扰数据集2的测试响应曲线;
图5为p=1时传感器对干扰数据集1的测试响应曲线;
图6为p=1时传感器对干扰数据集2的测试响应曲线。
具体实施方式
下面结合附图和实施例对本发明作进一步说明:
本发明的构思是:假设某些非目标气体的数据是没有的,因为在现实生活中,非目标干扰气体有无数种,而要采集无数种非目标气体的数据集显然是不可能的。因此,本发明所面临的问题是,只有目标气体数据和目标气体之外的少量预选的非目标气体数据情况下,如何实现对任何非目标气体的识别。因此本发明构建了自表达模型,也就是为目标气体数据建立一个自身模型,当某个样本违背了该模型时,就认为是可能属于非目标气体样本,这种“违背”是通过误差阈值进行量化和评判的。
本专利申请所使用的符号说明:目标气体α训练集其中D是每个样本的维数,N为目标气体α训练集X的样本总数,是自表达系数矩阵;i=1,2,…,N,表示X中任一样本,表示xi由X中所有样本表达的系数向量,X1表示目标气体误差阈值训练集,Y表示非目标气体误差阈值训练集,表示未知气体(目标或干扰)的一个样本。T为区分目标气体和非目标气体的阈值,λ为正则化系数,||||F是F范数,||||1是l1范数,||||2是l2范数,(·)T表示转置运算,(·)-1表示求逆运算。全文采用大写的粗黑体表示矩阵,小写的粗黑体表示向量,变量用斜体字表示。
本发明包括步骤1:获取电子鼻各类目标气体数据和少量非目标干扰气体数据,并将目标气体数据分为目标气体训练集X和目标气体误差阈值训练集X1两部分,非目标干扰气体数据为干扰气体误差阈值训练集Y。其中目标气体训练集X用于找到自表达矩阵α,目标气体训练集X1和干扰气体误差阈值训练集Y用于找到区别目标气体和干扰气体的误差阈值T。
步骤2,利用目标气体训练集X计算线性表示系数α,对任一样本xi,构建一个线性表达式;
由于非目标气体未知且种类繁多且数量庞大,我们无法具体地获得所有非目标干扰气体的传感器响应,但考虑到已知的六种目标气体,能够利用目标气体的先验信息。因此对目标气体任一样本xi,都能由目标气体训练集X的N个样本来线性表示,即:
xi=α1x1+α2x2+α3x3+···+αNxN (1)
式(1)中,x1,x2,x3,…,xN为目标气体训练集X的样本,N为目标气体训练集X的样本总数,α1、α2、α3、αN为表达式系数。
式(1)也可表达为:
xi=Xαi
上式中,X为目标气体α训练集,为系数向量;i=1,2,…,N;
即每一个目标气体样本都可以表示成为电子鼻所测六种目标气体集合的线性组合。如果未知气体为非目标干扰气体,传感器对它的响应趋势将不同于已知的六种目标气体样本中任何一种,那么它就无法用已知目标气体的组合式子所线性表达,或者说表达误差相当大。
步骤3,根据目标气体每一个样本xi与步骤2所构建的(1)式之间的误差最小,求解表达式系数αi;
目标气体每一个样本分别与所有的N个样本按(1)式表达后,确定目标气体样本与(1)式之间的误差最小化,为保证系统的鲁棒性,加上了正则项,得到如下式子:
p表示lp范数,p的取值可为1,也可为2;λ为正则化系数;表示目标气体训练集中第i个样本由目标气体中所有N个样本的表达系数向量,为目标气体α训练集,则刚好与目标气体的任一样本长度一致。
利用矩阵表达形式,式(2)可转化如下形式:
1.若p=2,式(2)可表示为式(3)所示
对α进行求导可以得到:
-XT(X-Xα)+λα=0 (4)
即可求得
α=(XTX+λI)-1XTX (5)
2.若p=1,即α采用l1范数,得到目标函数如下
(6)式通常被称为LASSO问题(least absolute shrinkage and selection operator),它的优良性质是能够产生稀疏解,使得α中的无关项变为0,其求解的步骤为:
步骤1):初始化i=1,j=1,其中i,j均为1~N的数值,表示第i个样本的第j个系数项;
步骤2):初始化
步骤3):更新其中
其中λ是正则项系数;
步骤4):j=j+1;
步骤5):若j≤N,重复步骤2)、步骤3)和步骤4);否则,执行步骤6);
步骤6):αi=[αi,1,αi,2,...,αi,N]T
步骤7):i=i+1。
步骤8):若i≤N,重复步骤2)至步骤7);否则,执行步骤9);
步骤9):α=[α1,α2,...,αN]
步骤4,若y表示目标气体误差阈值训练集X1和非目标干扰气体误差阈值训练集Y中的任一样本,那么按(7)式对应计算两个误差阈值训练集中每一个样本y的平均误差集e1和e2;
如果y属于目标气体,则它一定能够用目标气体α训练集X的N个样本所表示,则平均误差e很小;相反,如果y属于非目标干扰气体,则平均误差e很大。
步骤5,确定区分目标气体与非目标干扰气体的阈值T;
利用步骤4所得的目标气体阈值训练集X1和非目标干扰气体阈值训练集Y的平均误差集E=[e1,e2],确定T的取值范围[Emin,Emax];按以下步骤选定阈值T:
步骤(1):初始化T=Emin,设定变化增量delta;
步骤(2):根据T的值,利用步骤4所得的平均误差集E,判断并确定目标气体阈值训练集X1的准确度P1和非目标干扰气体阈值训练集Y的检测准确度P2;
步骤(3):令T=T+delta,若T<Emax,返回步骤(2);否则,执行步骤(4);
步骤(4):依据P1和P2,由P=P1+P2的值最大原则,选定最佳的T值。
实施例
本实施例将电子鼻系统检测的六种气体,即甲醛、苯、甲苯、一氧化碳、氨气和二氧化氮作为目标气体,通过实验共获得188个甲醛样本、72个苯样本、66个甲苯样本、58个一氧化碳样本、60个氨气样本和38个二氧化氮样本,共482个目标数据样本(482分成了3份:X,X1和X2),另外,选取48个酒精样本为干扰训练样本集。
采用的数据说明:
用于求解自表达系数α的目标气体训练集
X:从目标数据样本中随机选择162个样本
用于搜索误差阈值T的目标气体和非目标气体训练集
X1:从余下的目标数据样本中随机选择213个样本
Y:从酒精样本中随机选择24个样本
用于测试本发明中获得的α和T的测试集
X2:目标数据样本剩余的107个样本
Y1:酒精样本剩余的24个样本
实时测试数据
(1)干扰数据集1
该数据集是将电子鼻系统置于仅有非目标干扰气体的环境下的恒温恒湿箱内采集的。每个传感器的采样点数为2400。在样本的实验采集过程中,分四个阶段分别往箱内注入香水和花露水两种非目标干扰气体,前两个阶段为香水,后两个阶段为花露水:被香水干扰的传感器响应信号区域大致为95~308采样点和709~958采样点;被花露水干扰的传感器响应信号区域大致为1429~1765采样点和2056~2265采样点;在每次注入干扰采集完后会采用气泵对恒温恒湿箱进行抽气清洗以净化箱内环境。
(2)干扰数据集2
为了检验该模型在目标和非目标气体同时存在时的识别有效性,本实验选择室内常出现的甲醛目标气体作为参考气体。实验过程分为以下三个阶段:
阶段1:将电子鼻系统置入恒温恒湿箱内,注入甲醛,等待达到稳定状态;开始注入酒精,等待稳定后,用泵抽气,十分钟后,停止抽气;
阶段2:注入甲醛,等待达到稳定状态;开始注入花露水干扰气味,等待稳定后,用泵抽气,十分钟后,停止抽气;
阶段3:注入甲醛,等待达到稳定状态;开始注入香水与橙子混合气味,等待稳定后,用泵抽气,采集数据完毕后,停止抽气。
该实验方法的目的是为了研究在目标气体环境下注入干扰气味和在干扰环境下注入目标气体时,干扰抑制模型的应用效果。按照上述实验过程,获得该数据集其长度为2400,传感器对甲醛的3个响应窗口区域为102~250采样点,719~880采样点和1380~1580采样点;传感器被酒精干扰的一个窗口区域为260~410采样点;传感器被花露水干扰的一个窗口区域为881~1064采样点;传感器被香水和橙子的混合干扰的一个窗口区域为1599~1899采样点。
1、选定表达矩阵α和阈值T
利用目标气体α训练集X求解出α,然后利用目标气体误差阈值训练集X1和非目标气体误差阈值训练集Y,由本发明误差阈值T的确定步骤找到一个最佳的T值。
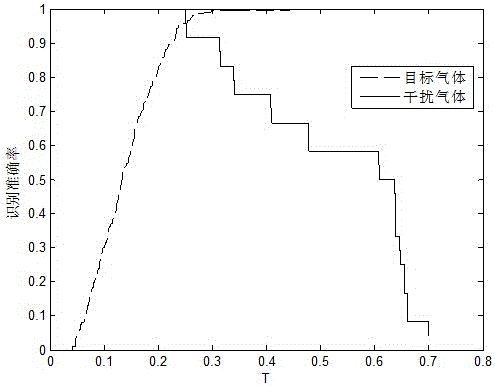
当p=1时(即l1范数约束),目标-干扰气体识别率随阈值T的变化曲线图如图1所示,从图中可以看出,随着阈值T值的增加,目标气体识别率逐渐增加,干扰气体识别率逐渐降低。本实验通过计算目标识别率和干扰识别率和最大原则来选取阈值T,得到T=0.2457。
当p=2时(即l2范数约束),目标-干扰气体识别率随阈值T的变化曲线图如图2所示,从图中可以看出,随着阈值T值的增加,目标气体识别率逐渐增加,干扰气体识别率逐渐降低。本实验通过计算目标识别率和干扰识别率和最大原则来选取阈值T,得到T=0.1256。
2、非目标气体识别测试
采用测试集的样本,使用本方法发明对107个目标气体样本和24个非目标气体样本进行识别。
从表格可以看出,本方法发明对非目标干扰气体的识别准确率为100%
3、传感器测试响应曲线
(1)当p=2时,对干扰数据集1和干扰数据集2的识别情况如图3和图4所示;
(2)当p=1时,对干扰数据集1和干扰数据集2的识别情况如图5和图6所示;
图3~图6中,传感器响应突然升起的横线部分为干扰,虚线标出的矩形窗为本方法发明识别出来的干扰区,测试响应曲线可以看到矩形窗刚好为干扰区域。另外,测试响应曲线使我们能够区分哪些部分属于干扰区、哪些部分属于目标气体区。
上述目标气体选定为6种,根据本领域技术人员的常识,目标气体的不仅限于6种,可以少于6种,也可以多于6种。目标气体根据使用场合选用。
- 还没有人留言评论。精彩留言会获得点赞!