一种基于近红外光谱的籽棉杂质检测方法与流程
本发明涉及棉花检测技术领域,具体是一种基于近红外光谱的籽棉杂质检测方法。
背景技术:
对棉花中杂质的检测是判断棉花品质的重要方法,目前,绝大部分棉花杂质检测研究的检测对象是皮棉中的杂质,而对籽棉中的杂质检测报道非常少见。主要原因在于籽棉不是最终的棉花产品,需要经过清理、轧花等工序,其所含杂质大部分将被清除。
但随着新国标GB1103颁布与实施,规定收购籽棉时按公定重量结算,实际收购中通常按籽棉的重量扣除水和杂质的重量后结算。由于没有一个完整的籽棉含杂的行业标准,对籽棉杂质含量检测没有明确规范,缺乏快速、准确的籽棉杂质含量检测方法,从而导致较多的贸易纠纷。特别是机采籽棉量大集中,按现行标准规定的程序收购工作量太大,加之近年来全国产棉区开始大面积推广机采作业,以新疆为例,平均棉花机采比例约为50~60%,部分地区棉花机采比例更是在80%以上。
由于机采棉含杂率较高,扣杂成为籽棉交易各方特别关心的问题。所以,如何检测出籽棉杂质含量和类别,对于提高清理效率并减少棉纤维损伤、提高棉纤维品质有着重要意义。
技术实现要素:
本发明的目的在于提供一种基于近红外光谱的籽棉杂质检测方法,该方法能够分析检测籽棉中杂质的含量与类别,提高籽棉的清理效率,减少棉纤维损伤、提高棉纤维品质。
本发明解决其技术问题所采用的技术方案是:
一种基于近红外光谱的籽棉杂质检测方法,包括以下步骤:
S1、采集各类籽棉,并将各类籽棉分别制作成标准籽棉样本;
S2、采集各个标准籽棉样本的近红外光谱;
S3、分别计算步骤S2得到的各个近红外光谱的一阶导数光谱,所述一阶导数光谱第i点的值为原始光谱第i与第i+1点之间线段的斜率;
S4、去除步骤S3得到各个标准籽棉样本一阶导数光谱中的零值:
采用紧临零值一阶导数的非零一阶导数值替换零值一阶导数,替换后光谱一阶导数仅有负值和正值;
S5、将步骤S4处理后的各个标准籽棉样本的一阶导数光谱二值化,所有正值的光谱一阶导数值均替换为1,所有负值的光谱一阶导数值均替换为0;
S6、计算各个标准籽棉样本的光谱特征峰参数;
S7、建立各个标准籽棉样本的模型,并生成包含模型与各个标准籽棉样本特征信息的数据库;
S8、制作待测籽棉样本,并对待测籽棉样本进行采集近红外光谱、计算近红外光谱的一阶导数光谱、去除一阶导数光谱中的零值、将一阶导数光谱二值化以及计算光谱特征峰参数;
S9、按照公式count/n计算标准籽棉样本光谱与待测籽棉样本光谱的相似度,count为在全波段范围内待测籽棉样本一阶导数光谱与标准籽棉样本一阶导数光谱在相同波段一阶导数同时为0或1的次数,n为光谱一阶导数数据点数;调用与待测籽棉样品光谱相似度最高的标准籽棉样本光谱所对应的模型与数据库信息作为分析待测籽棉样本的基础,从而获得待测籽棉样本的含杂情况。
本发明的有益效果是:
广泛搜集具有代表性的标准籽棉样品,采集这些标准样品的光谱数据,提取这些标准样品光谱数据的特征信息,建立各类标准籽棉及其杂质近红外光谱数据库,从而作为标准参照信息;将待测籽棉样本的光谱特征信息与标准籽棉的光谱特征信息进行比对,找出与待测籽棉样品相似度最高的标准籽棉样本,作为分析待测籽棉样本的基础,从而快速地分析出待测籽棉样品的含杂情况。
附图说明
下面结合附图和实施例对本发明进一步说明:
图1是本发明中建立标准籽棉样品近红外光谱数据库系统流程图;
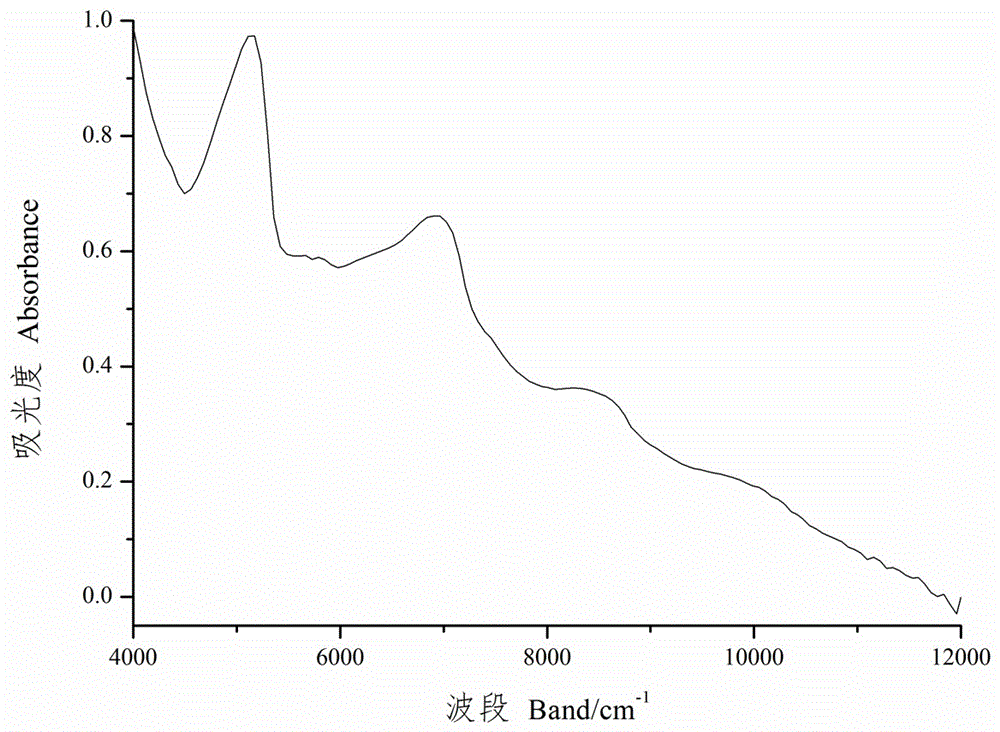
图2是本发明标准籽棉样品原始光谱曲线;
图3是本发明标准籽棉样品原始光谱的一阶导数光谱曲线;
图4是本发明标准籽棉样品二值化后的一阶导数光谱曲线。
具体实施方式
如图1所示,本发明提供一种基于近红外光谱的籽棉杂质检测方法,包括以下步骤:
S1、采集各类籽棉,并将各类籽棉分别制作成标准籽棉样本;
具体为:将各类籽棉样本分别经过样本筛选、样本标号、每份样本质量统一在10±0.1g范围之内、样品平衡温度在20±1℃范围之内,统一采用相同质量压样器压实样品;
S2、结合图2所示,采集各个标准籽棉样本的近红外光谱,得到各个标准籽棉样本的原始光谱;
具体为:打开并检查光谱仪状态,将光谱仪分辨率设置在8cm-1,扫描次数32次,打开光源进行光谱仪预热约90分钟后开始光谱采集;
S3、结合图3所示,分别计算步骤S2得到的各个近红外光谱的一阶导数光谱,所述一阶导数光谱第i点的值为原始光谱第i与第i+1点之间线段的斜率;
S4、去除步骤S3得到各个标准籽棉样本一阶导数光谱中的零值:
采用紧临零值一阶导数的非零一阶导数值替换零值一阶导数,替换后光谱一阶导数仅有负值和正值; 如f’(i-1)=-1,f’(i)=0,则将f’(i)的值改为-1;
S5、结合图4所示,将步骤S4处理后的各个标准籽棉样本的一阶导数光谱二值化,所有正值的光谱一阶导数值均替换为1,所有负值的光谱一阶导数值均替换为0;如f’(i)=-1,则令f’(i)=0,否则令f’(i)=1;
S6、计算各个标准籽棉样本的光谱特征峰参数,包括特征峰位、峰高、左半峰宽、右半峰宽与峰面积;
S7、建立各个标准籽棉样本的模型,并生成包含模型与各个标准籽棉样本特征信息的数据库;
所述数据库采用Microsoft SQL Server 2008 R2作为数据库管理系统,光谱数据格式为.xlsx格式文件,数据库字符串包括光谱的吸光度字符串和光谱的波段字符串,所述字符串中的每个吸光度值使用“_”链接;
从起始波段开始,从0到n-1,依次将第i个吸光度值转换为字符串,并使用“_”链接为目标字符串,n为光谱数据点数,本实施例中n等于2179;
具体过程通过下面的程序实现:
CString temp=””;临时字符串变量,用于转换和保存当前吸光度转换得到的字符串
CString aim=””;目标字符串变量,用于拼接和保存已经转换的所有吸光度字符串
for(int i=0;;i<n; i++) 从起始波段到终止波段,挨个转换并拼接,直到所有的吸光度值都转换完毕
{temp.Format(“%f”,absorbance[i]);将第i个吸光度值转换为字符串
aim=aim+temp+”_”;}拼接字符串
所述光谱的波段字符串组成形式为:“起始波段+终止波段+数据点数”,按照上述方式,依次将所有样品光谱添加到数据库中;
S8、制作待测籽棉样本,并对待测籽棉样本进行采集近红外光谱、计算近红外光谱的一阶导数光谱、去除一阶导数光谱中的零值、将一阶导数光谱二值化以及计算光谱特征峰参数;具体方法与获得标准棉样本光谱一致;
S9、按照公式count/n计算标准籽棉样本光谱与待测籽棉样本光谱的相似度,count为在全波段范围内待测籽棉样本一阶导数光谱与标准籽棉样本一阶导数光谱在相同波段一阶导数同时为0或1的次数,n为光谱一阶导数数据点数;调用与待测籽棉样品光谱相似度最高的标准籽棉样本光谱所对应的模型与数据库信息作为分析待测籽棉样本的基础,从而获得待测籽棉样本的含杂情况;
首先将标准籽棉样本光谱,也即是以字符串形式保存的参照光谱逐一还原为原始光谱,具体实现程序如下:
int i=0;用于记录当前还原的数据点序号
int mark=0;用于标记字符串中连接符为位置
int length=0;计算原字符串长度
CString temp=””;临时保存当前数据点吸光度字符串
do{循环控制,没有连接符为止
mark=reference.Find(“_”);从左向右寻找当前参照光谱字符串中的第一个连接符
temp=reference.Left(mark);截取当前参照光谱字符串中的第一个吸光度字符串
absorbance[i]=aoti(temp);将当前数据点吸光度字符串转换为浮点型数据,实现光谱吸光度数据的还原和保存
length=len(reference);计算当前参照光谱字符串的长度
reference=reference.Right(length-mark-1);截断参照光谱字符串,删除已经还原的部分
i++;数组下标自增
}while(mark>0) 当没有连接符时,结束光谱由字符串到二维数组的还原过程
在完成对参照光谱的还原之后,依次计算待测样品光谱和参照光谱之间的相似度,具体实现程序如下:
for(int i=0; i<n-1; i++) 在全光谱范围内计算光谱一阶导数
{sample.firstderivate[i].y=( sample.absorbance[i+1]-sample
.absorbance[i])/(sample.band[i+1]-sample.band[i]);计算样品光谱的一阶导数
if(sample.fisrtderivate[i].y==0) 判断当前样品光谱当前位置为一阶导数是否为0,如果为0,则将使用前面的非0值替换
sample.firstderivate[i].y= sample.firstderivate[i-1].y;替换零值一阶导数
If (sample.firstderivate[i].y>0) 对光谱一阶导数值进行二值化变换
sample.firstderivate[i].y=1; else sample.firstderivate[i].y=0;
sample.fisrtderivate[i].x=sample.band[i] 使用原始光谱第i个数据点的波段值对第i个一阶导数的波段值进行赋值
for(int i=0;i<records;i++) 对所有的参照光谱,计算并转换其一阶导数
for(int j=0;j<n;j++) 对每一条光谱,计算并转换其一阶导数
{reference[i].firstderivate[j].y=(reference[i].absorbance[j+1]-
reference[i].absorbance[j])/(reference[i].band[j+1]-reference[i].band[j]); 计算第i个参照光谱的第j个一阶导数
if(reference[i].firstderivate[j].y==0) 判断第i个参照光谱的第j个一阶导数值是否为0
reference[i].firstderivate[j].y=reference[i].firstderivate[j-1].y;如果第i个参照光谱的第j个一阶导数值等于零,将其使用第j-1个一阶导数值替换
If (reference.firstderivate[i].y>0) 对光谱一阶导数值进行二值化变换
reference.firstderivate[i].y=1;
else reference.firstderivate[i].y=0;
reference[i].firstderivate[j].x=reference[i].band[j];} 为第i个参照光谱的第j个一阶导数的波段值赋值
float count=0; 统计变量申明,用于统计参照光谱与样品光谱一阶导数相等的点数
float temp=0;临时变量申请
float *HIT=new float[records];匹配度保存变量申请
for(int i=0;i<records;i++) 与所有的参照光谱进行匹配
{count=0;对上次循环累计值清零
for(int j=0;j<n-1;j++) 在全光谱范围内循环,进行光谱匹配
{if(sample.fisrtderivate[j].y== reference[i].firstderivate[j].y)
count=count++;} 累加当前波段匹配度
HIT[i]=count/(N-1);} 原始光谱曲线共有N个数据点,则其一阶导数共有N-1个数据点
按照以上方式,计算待测样品光谱与所有参照光谱之间的匹配度。
以上所述,仅是本发明的较佳实施例而已,并非对本发明作任何形式上的限制;任何熟悉本领域的技术人员,在不脱离本发明技术方案范围情况下,都可利用上述揭示的方法和技术内容对本发明技术方案做出许多可能的变动和修饰,或修改为等同变化的等效实施例。因此,凡是未脱离本发明技术方案的内容,依据本发明的技术实质对以上实施例所做的任何简单修改、等同替换、等效变化及修饰,均仍属于本发明技术方案保护的范围内。
- 还没有人留言评论。精彩留言会获得点赞!