GPU并行三维地震波场生成方法和系统与流程
本发明属于数值模拟与高性能计算技术领域,涉及地震波场正演模拟方法,具体涉及一种基于GPU并行加速的三维地震波场的正演模拟方法及其系统。
背景技术:
地震波场正演模拟是有效反映地下介质构造变化的一种数值模拟方法。随着油气勘探开发技术的发展,以及计算机运算能力的提升,地震波场正演模拟的方法已得到了广泛的应用。
地震波场数值正演模拟是在地下介质结构和参数已知的情况下,利用理论计算的方法研究地震波在地下介质中的传播规律,并获得人工合成地震记录的一种技术。在现有的方法中,有限差分方法具有很好的灵活性而被广泛应用于数值计算之中。
其中,有限差分方法的研究始于1968年,Alterman和Karal在文献[1]中,首先将弹性波有限差分模拟的方法应用到了拟合地层的层状介质中。之后,有限差分技术快速发展,文献[2]记载了Alford等比较了高阶差分与低阶差分保持同样精度时对网格间距的要求,深入研究有限差分法算法精度。随后,Kelly等文献[3]中研究了用有限差分法人工合成了地震记录,将方法与实际数据紧紧连系在了一起。在文献[4]中,Virieux提出了稳定有限差分交错网格的差分形式,适用于任何泊松比的介质,同时,交错网格提高了局部计算精度和算法的稳定性。之后,文献[5]记载了Levander将Virieux的结果进行了差分阶数的提升,得到更高精度的结果。在文献[6]中,Crase则将精度提高到任意阶数,进行高阶差分,因而对CPU、内存以及储存空间的要求也大大提升。在文献[7]中,Graves又在三维空间下完成了这一方法的实践应用,使该方法更好的结合到我们实际的勘探工作中。董国良等在文献[8]~[9]中对一阶弹性波交错网格高阶差分的方法以及其稳定性问题进行了深入研究。文献[10]中记载了张剑锋和刘铁林将网格的研究进一步发展,提出了矩形网格和三角网格相结合的方法,提高有限差分法在构造较复杂地区结果的精度。在文献[11]中,董国良和李培明又在前人的基础上针对频散这一问题进行了更加详细的讨论。文献[12]记载了李胜军等对地震波数值模拟中的频散压制方法的总结分析。之后,有限差分方法越来越多的应用到了勘探工业界,在实际工作中起着重要作用。目前,有限差分法可以说是最常用的数值模拟方法,已经较为成熟,它正向着高精度和高效率的波场模拟方向发展。
正演模拟的方法还包括限元法、伪谱法、克希霍夫积分法等等。但从方法上而言,在有限差分法中,我们用相应的空间、时间的差分代替波场函数的空间、时间导数,对于各种条件下的介质都有着广泛的应用,能够真实并准确地模拟波在地下介质中的运动方式。同时,其具有运算快、数据量小的优势,这是其他方法都难以比拟的。因此,该方法是勘探应用最重要的方法之一。
在数值模拟计算中,中央处理器CPU能完成复杂的逻辑运算,但其串行的结构限制了单位时间内运算的数据量,运算效率较低。近几年以来,图形处理器在并行计算中逐渐被广泛应用。文献[13]~[14]记载了图形处理器GPU采用的是浮点运算,其多核运算模式在数据量庞大的科学计算上有着巨大的优势。2007年,GPU技术迈出了历史性的一步,NVIDIA公司推出了CUDA平台,并开发了CUDA C语言,这一进步大大降低编译工作者的工作难度,程序也直接可以以C语言的形式进行编译开发。同时,CUDA是一种CPU和GPU的混合编程平台,其上代码不但包括GPU上的并行计算运行指令,还包括CPU上逻辑串行指令部分;在GPU上运行的程序为内核函数(Kernel)。CUDA并行程序将直接控制GPU上的数据操作,操作完成之后,CUDA指令可以控制主机端和设备端之间的数据交换,此外,CUDA还可以控制设备存储空间的分配和释放,管理纹理内存储空间。
CUDA采用三维无符号整型向量来对线程与线程块进行组织和编号。其并行构架中,由内核函数Kernel进行运算编译,核函数被置入计算网格(Grid),每个网格中包含若干线程块(Block),而每个线程块又可以包含若干个线程(Thread)内。因此Kernel函数就是运算的中心,文献[14]~[15]即记载了利用Blocks和Threads的工作方式即可完成并行计算。线程块可以是一维至三维的组织方式,而线程块内的线程组织方式也可以是一至三维的。这使得网格中的每个线程块的每个线程的位置更加直观和精确。
如今,GPU(Graphic Process Unit)图形处理单元得到了迅速的发展,以往的GPU只是按照固定的流水线进行工作,负责图形处理,而现今,GPU已经发展到了可编程模式,例如现今NVIDIA的CUDA编程平台已经发展了多个版本,GPU硬件的功能也逐步强大。
从制造工艺上来讲,GPU已经经过多代更新和发展,过去的十多年时间里,每年都会产生新一代的GPU,在其不断完善和发展中,GPU的性能也不断强大,可编程性也大大提高。现在,一些高端的GPU的计算性能已经可以相当于一个高性能计算集群系统。一方面,GPU在硬件技术的不断提高中,将会拥有更加强大的运算能力,存储性能和更高的数据传输速度,另外一个方面,计算平台的发展使GPU的通用性更强,越来越多的程序可以使用GPU实现高性能计算,GPU编程的简单化也使得GPU高性能计算拥有越来越广泛的适用人群。
在地震勘探技术领域,三维弹性波场正演模拟的结果能更加接近野外采集的实际数据,具有很好的参照性和对比性,同时,也能为之后的三维反演提供模型数据基础。但是,由于三维数据计算带来了庞大的计算量,而现有技术计算效率低,耗时长,难以达到高精度计算要求。目前,地震波场数值模拟技术尚需要提高计算效率,进一步提高计算的稳定性和精度。
参考文献:
[1]Alterman,Z.,and Karal,F.C..Propagation of elastic wave in layered media by finite difference method[J].Bulletin of the Seismological Society of America,1968,58(1):367-398.
[2]Alford,R.M.,Kelly,K.R.,Boore,D.M..Accuracy of finite difference modeling of the acoustic wave equation[J].Geophysics.1974,39(6):834-842.
[3]Kelly,K.R.,et al.Synthetic seismograms;a finite difference approach[J].Geophysics.1976,41(1):2-27.
[4]Virieux,J..P-SV wave propagation in heterogeneous media:Velocity-stress finite-difference method(Shear waves)[J].Geophysics,1986,51(4):889-901.
[5]Levander,A.R..Fourth-order finite-difference P-SV seismograms[J].Geophysics.1988.53(11):1425-1436.
[6]Crase,E..High-order(space and time)finite-difference modeling of elastic wave equation[J].Expanded Abstracts of 60th SEG Annual Meeting.1990.987-991.
[7]Graves,R.W..Simulating Seismic Wave Propagation in 3D Elastic Media Using Staggered-Grid Finite-Differences[J].Bulletin of seismological Society of America.1996,86(4):1091-1106.
[8]董国良,马在田,曹景忠等.一阶弹性波方程交错网格高阶差分解法[J].地球物理学报.2000a,43(3):411-419.
[9]董国良,马在田,曹景忠等.一阶弹性波方程交错网格高阶差分解法稳定性研究[J].地球物理学报.2000b,43(6):856-864.
[10]张剑锋,刘铁林.各向异性介质中弹性波的数值模拟[J].固体力学学报.2000,21(3):234-242.
[11]董国良,李培明.地震波传播数值模拟中的频散问题[J].天然气工业.2004,24(6):53-56.
[12]李胜军,孙成禹,高建虎等.地震波数值模拟中的频散压制方法分析[J].石油物探.2008,47(5):444-449.
[13]Sanders,J.,Kandrot,E..CUDA by Example:An Introduction to General-purpose GPU Programming[M].U.S.A:Pearson Education.
[14]Farber,R..CUDA Application Design and Development[M].U.S.A:Elsevier Inc.,2013.
[15]Michéa,D.,and Komatitsch,D..Acceleration a three-dimensional finite-difference wave propagation code using GPU graphics cards[J].Geophysical Journal International,2010,182:389-402.
技术实现要素:
为了克服上述现有技术的不足,本发明提供一种GPU并行三维地震波场生成方法和系统,基于高阶有限差分和GPU并行加速,实现高精度、高效率地求解三维地震波动方程,大大提高计算效率的同时,有效地提高计算精度,满足对计算效率和精度的要求。
本发明的核心是:本发明将GPU的二维运行模式用于三维的勘探地震波正演模拟生成。基于GPU并行生成勘探地震波,首先获取地震子波及观测系统数据、获取地质参数信息;根据地震子波数据和地质参数信息,再根据初始条件、边界条件以及算法稳定性条件,对地震波传播方程进行三维高阶有限差分,通过数值模拟得到高精度的勘探地震波传播数据;基于GPU修改算法结构,完成三维并行加速处理,实现高精度结果的高效输出;最后输出波场时间切片结果和地面地震记录结果。本发明实现了三维地震正演模拟和GPU加速技术的有效结合,数倍加快正演模拟的计算速度。
本发明提供的技术方案如下:
GPU并行三维地震波场生成方法,对地震波传播方程进行高阶有限差分,通过数值模拟计算得到高精度的勘探地震波传播数据。在计算过程中,通过GPU并行加速处理,高精度地、高效地生成地面地震记录数据和波场切片结果;包括如下步骤:
1)获取地震子波及观测系统数据、获取地质参数信息;
2)根据地震子波数据和地质参数信息,再根据初始条件、边界条件以及算法稳定性条件,对地震波传播方程进行高阶有限差分正演模拟;
3)通过正演模拟算法得到高精度勘探地震波传播数据,基于GPU修改所述正演模拟算法结构,完成分维度并行加速处理,实现高精度结果的高效输出;
4)输出波场切片结果和地面地震记录数据,模拟生成勘探地震波场。
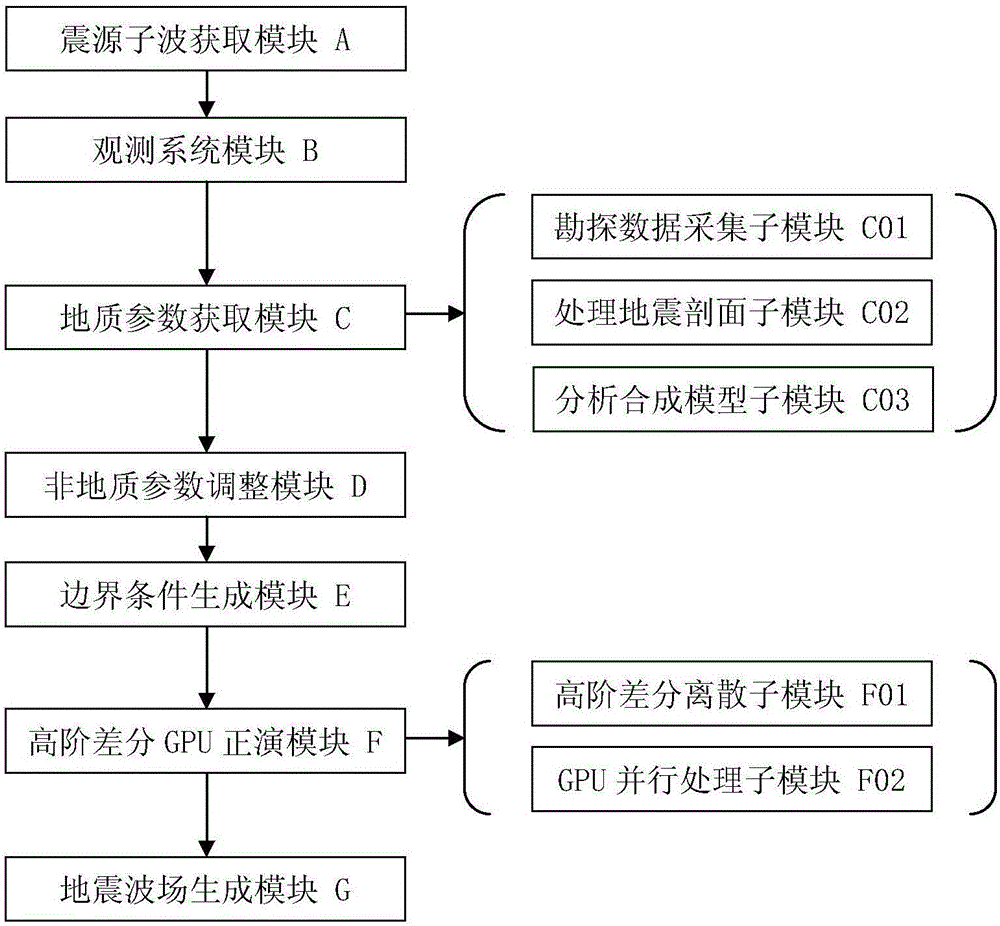
本发明还提供一种GPU并行三维地震波场生成系统,包括震源子波获取模块、观测系统模块、地质参数获取模块、非地质参数调整模块、边界条件生成模块、高阶差分GPU正演模块和地震波场生成模块;具体地:
A.震源子波获取模块,用于获取地震子波数据;
B.观测系统模块,用于建立地面数据收集系统;
C.地质参数获取模块,用于获取模型所对应对的地质参数信息;
C01.勘探数据采集子模块,采集地震数据;
C02.处理地震剖面子模块,利用地震工业处理软件处理所述地震数据得出地震剖面和建模数据;
C03.分析合成模型子模块,对所述地震剖面和建模数据进行分析得出对应的地质参数信息,合成模型数据。
D.非地质参数调整模块,用于调整合适的参数,满足稳定性条件;
E.边界条件生成模块,用于生成模型所对应的完全匹配层边界条件;
F.高阶差分GPU正演模块,用于完成弹性波波动方程高阶差分离散和GPU并行加速处理,达到高精度、高效率;
F01.高阶有限差分离散子模块,利用高阶差分对波动方程进行一维化数值离散;
F02.GPU并行处理子模块,通过GPU语言进行修改,分维度并行处理整个空间的差分数据。
G.地震波场生成模块,用于生成地面地震记录和波场切片结果。
与现有技术相比,本发明的有益效果是:
本发明提供一种GPU并行三维地震波场生成方法和系统,基于高阶差分和GPU并行加速,实现高精度、高效率地求解三维地震波动方程,大大提高计算效率的同时,保证最有效的精度要求。本发明在具体实施时,应用了CUDA构架下的GPU和CPU协同加速方法,在保证稳定性的前提下,大大提高计算的效率。本发明提供的GPU并行三维地震波场生成方法能够为三维复杂区地震波传播规律分析研究提供高精度、高效率、稳定性好的数值模拟计算。
附图说明
图1是本发明提供的GPU并行三维地震波场生成方法的流程框图。
图2是本发明实施例提供的GPU并行三维地震波场生成系统的结构框图。
图3是本发明实施例提供的GPU并行加速正演模拟方法的流程框图。
图4是本发明完全匹配层边界条件的示意图;
其中,密集横竖线标示的阴影部分为完全匹配层边界区域。
图5是本发明实施例采用现有的CPU与采用本发明的GPU并行数值模拟三维弹性波场的结果对比;
其中,(a)为现有的CPU方法数值模拟三维弹性波场的结果;(b)为采用本发明的GPU并行数值模拟三维弹性波场的结果。
图6是本发明实施例采用现有的CPU与采用本发明的GPU并行数值模拟三维弹性波场的二维波场记录切片结果对比;
其中,(a)为现有的CPU方法数值模拟三维弹性波场的二维波场记录切片结果;(b)为采用本发明的GPU并行数值模拟三维弹性波场的二维波场记录切片结果。
图7是本发明实施例采用现有的CPU与采用本发明的GPU并行数值模拟三维弹性波场计算时间的结果对比。
具体实施方式
下面结合附图,通过实施例进一步描述本发明,但不以任何方式限制本发明的范围。
本发明提供一种基于GPU并行三维地震波场生成方法和系统,基于高阶有限差分和GPU并行加速,对地震波传播方程进行高阶有限差分,通过GPU并行加速处理数值模拟,得到高精度的勘探地震波传播数据,从而高精度地、高效地生成地面地震记录数据和波场切片结果,由此实现高精度、高效率地求解三维地震波动方程,大大提高计算效率的同时,保证最有效的精度要求的目的。
本发明中,高阶有限差分方法具有较高的精度和较好的数值稳定性,特别是在三维计算中,微小数值变化所带来的影响更为严重,需要高阶高精度的计算,才能得到更加准确,逼近真实数据的结果。同时,针对高阶有限差分的大数据量,基于GPU的并行加速计算能大大提高其计算效率。另外,本发明实施例以CUDA C语言为基础,优化了模拟过程中的并行构架,使CPU和GPU各司其职,协同计算,高效且高精准地完成弹性波场正演模拟。再而,完全匹配边界条件可以用于波场边界上进行振幅衰减。本发明针对高阶差分对边界层进行调整,保证了边界吸收的效果。如图4所示,对三维数据而言,在其坐标方向的切片上均满足图示的吸收边界层设计。
本发明采用的三维地震正演模拟的计算方程为地震弹性波应力-速度方程,如公式(1):
式中ρ为密度;Vi为速度分量(i:x、y、z);σij为应力分量(i、j:x、y、z);λ、μ为描述弹性介质的拉梅常数;x、y、z为笛卡尔坐标系的三分量;t为时间。
时间和空间差分方式定义为2阶时间、2L阶空间差分;i、j、r分别代表计算网格的坐标位置;n表示时间迭代中时间网格的位置。差分格式如下:
式中Δx、Δy、Δz为笛卡尔坐标系中三个方向上的差分间距;Δt为时间差分间距。差分定义为2阶时间、2L阶空间差分。为差分系数。
本发明在具体实施时,应用了CUDA构架下的GPU和CPU协同加速方法,在保证稳定性的前提下,大大提高计算的效率。图1所示为本发明提供的GPU并行三维地震波场生成方法的流程,包括以下步骤:
1)获取地震子波及观测系统数据,获取地质参数信息;
2)根据所述的地质参数信息,确定正演模拟模型的初始条件、生成边界条件以及算法稳定性条件,对地震波传播方程进行高阶有限差分,数值模拟得到高精度的勘探地震波传播数据;
三维地震正演模拟的计算方程为地震弹性波应力-速度方程(公式(1))。利用高阶有限差分对波动方程进行数值离散计算,具体通过步骤3)中GPU并行加速处理数值模拟得到高精度的勘探地震波传播数据,生成地面地震记录数据和波场切片结果;通过公式(2)-(10)进行方程计算和差分,得到差分计算的结果;
其中,生成边界条件是生成模型所对应的完全匹配层边界条件,通过边界波场衰减达到吸收边界波场的效果,能很大程度上减少人工反射的干扰,边界条件的生成主要包括如下步骤:首先设置衰减系数得到衰减因子,再分解运算方程并加入衰减项,最后代入原方程重新进行差分计算。完全匹配层是基于衰减因子在边界处的衰减作用实现的,本发明采用衰减因子如下:
其中,Vmax的取值为速度模型中最大纵波速度,δ为匹配层宽度,x、y、z为三个方向上的网格点位置,Δx、Δy、Δz为笛卡尔坐标系中三个方向上的差分间距,R为理想边界层反射系数,即衰减系数(一般取值介于10-4-10-10);为调节系数,可以自行调节边界吸收的强度;ddx(x)、ddy(y)、ddz(z)为衰减因子,当ddx(x)、ddy(y)、ddz(z)不都为零时是衰减状态,ddx(x)、ddy(y)、ddz(z)均为零时是不衰减状态。加入完全匹配层边界条件的具体过程为:首先设置衰减系数和调节系数,进行测试和对比,得到合适的衰减因子;再将方程(1)分解在x、y、z三个方向上,只要有相关方向的差分计算,均需要在该方向做分解;而后在x、y、z三个方向上分别加入变量衰减项,衰减项中包含衰减因子;最后带入差分方程在x、y、z三个方向上分别进行数值差分计算。
稳定性是弹性波数值模拟中需关注的重要标准之一。数值算法一般可分为无条件稳定算法和有条件稳定算法。本发明采用的递推算法属于有条件稳定算法,对于本发明计算公式(2)-(10)所用的交错网格而言,其差分格式要满足以下式15的稳定性条件:
式中,Δx、Δy、Δz为笛卡尔坐标系中三个方向上的差分间距;Δt为时间差分间距。差分定义为2阶时间、2L阶空间差分。此处研究的是各项同性弹性介质,地震波传播速度与传播方向无关。Vmax的取值为速度模型中最大纵波速度。ε是稳定性因子,由差分的方式决定,同时也可以自行调节稳定性的强度。模型需要完成了稳定性的检测,才能保证计算结果的稳定。
3)基于GPU修改正演模拟算法结构,完成并行加速处理,实现高精度结果的高效输出;
根据三维地震正演模拟的弹性波应力-速度方程,本发明将数据计算顺序分为速度分量计算和应力分量计算两部分,分别进行速度分量和应力分量的计算,具体在循环中以先后顺序进行迭代计算,使得高阶有限差分算法适用于GPU并行加速;
图3是本发明具体实施中GPU并行加速正演模拟的流程框图,如图3所示,本发明中,地震波动方程在GPU下并行生成包括如下步骤:
31)CPU向GPU拷贝内存:在三维地震波场数值模拟中,由于计算中的初始三维变量数据均存储于CPU所对应的内存中,首先需要将三维变量数据从CPU内存传送至GPU的内存(Global Memory)中,这一步骤中,需要将三维数据数组排列成一维数组的形式,通过CUDA中的cudaMemcpy函数将数据由CPU拷贝到GPU,运行函数如下:
cudaMemcpy(GPU中变量,CPU中变量,变量大小,cudaMemcpyHostToDevice);
32)选择GPU中的处理单元Block和Thread分配:Block和Thread均是GPU中的处理单元,每个Block下分配有多个Thread,以Block和Thread编号标记的GPU线程可以表示一个二维的数据分配模式,因而,具体实施中采用二维模式进行地震波场数据GPU并行加速计算,将地震波场数据的第三维转化成循环状态进行处理;即选择GPU中的处理单元Block和Thread作为两个方向分配地震波场第一、第二维度的数据,并储存地震波场第一、第二维度的数据的检索坐标用于并行计算,将地震波场数据的第三维转化成循环状态进行处理;此时,数据为一维数据,检索号保持为三维的检索标准;
33)Kernel分配变量数据计算顺序:对整个波场空间的模拟而言,每个网格点均需要大量的迭代运算,为了避免计算数据互相干扰而产生紊乱的现象,需要通过Kernel进行计算顺序分配,本发明中,三维正演模拟方程为弹性波应力-速度方程,将数据计算顺序分为速度分量计算和应力分量计算两部分,分别进行速度分量和应力分量的计算,具体在循环中以先后顺序进行迭代计算;
34)数据一维化并行计算:对于GPU而言,已经将三维数据体一维化导入到GPU的内存中,再对差分计算方程进行一维化,确定计算网格点的位置,并在CUDA核中进行并行运算,其中数据一维化的过程是将三维数据数组排列成一维数组的形式,并将三维数组对应的差分计算方程修改成相应一维数组对应的差分计算方程;
35)计算结果输出及数据返回:得到了一个时间节点的数据后,则要将需要的结果导回CPU内存中输出,然后,再进行数据返回到GPU中进行下一个时间节点的运算,直到时间循环结束,这里需要通过CUDA中的cudaMemcpy函数将数据由GPU拷贝到CPU,运行函数如下:
cudaMemcpy(CPU中变量,GPU中变量,变量大小,cudaMemcpyDeviceToHost)。
4)输出波场时间切片结果和地面地震记录结果。
本发明中,高阶有限差分方法具有较高的精度和较好的数值稳定性。在三维计算中,微小数值变化所带来的影响非常严重,需要高阶高精度的计算,才能得到更加准确,逼近真实数据的结果。同时,针对高阶有限差分的大数据量,基于GPU的并行加速计算能大大提高其计算效率。另外,本发明以CUDA C语言为基础,优化了模拟过程中的并行构架,使CPU和GPU各司其职,协同计算,高效且高精准地完成弹性波场正演模拟计算。再而,完全匹配边界条件可以用于波场边界上进行振幅衰减。本发明针对高阶差分对边界层进行调整,保证了边界吸收的效果。图4是本发明完全匹配层边界条件的示意图。如图4所示,对三维数据而言,在其坐标方向的切片上均满足图示的完全匹配吸收边界层设计。
为了让本发明的目的、技术和优势更加清晰,下面将结合实施方式和附图,对本发明做进一步详细说明。在此,本发明的示意性实施方式及其说明用于解释本发明,但并不作为对本发明的限定。
图2是本发明提供的地震波场模拟系统的结构框图,包括震源子波获取模块、观测系统模块、地质参数获取模块、非地质参数调整模块、边界条件生成模块、高阶差分GPU正演模块和地震波场生成模块;具体地:
A.震源子波获取模块,用于获取地震子波数据,地震子波通常选取雷克子波,以震源的形式导入波动方程正演模拟计算中;
B.观测系统模块,用于建立地面数据收集系统,其包括地震炮点信息、地震检波点信息以及地震炮点和检波点的关系信息;
C.地质参数获取模块,用于获取模型所对应对的地质参数信息,包括速度、密度等重要的模型参数;
C01.勘探数据采集子模块,采集地震数据;
C02.处理地震剖面子模块,利用地震工业处理软件处理所述地震数据得出地震剖面和建模数据;
C03.分析合成模型子模块,对所述地震剖面和建模数据进行分析得出对应的地质参数信息,合成模型数据。
D.非地质参数调整模块,用于调整合适的参数,满足稳定性条件,参数包括地震子波的主频、时间空间差分网格的大小;
E.边界条件生成模块,用于生成模型所对应的完全匹配层边界条件,通过边界波场衰减达到吸收边界波场的效果,能很大程度上减少人工反射的干扰,边界条件的生成主要包括步骤如下:首先设置衰减系数,再分解运算方程并加入衰减项,最后代入原方程重新进行差分计算;
F.高阶差分GPU正演模块,用于完成弹性波波动方程高阶差分离散和GPU并行加速处理,达到高精度、高效率;
F01.高阶有限差分离散子模块,利用高阶差分对波动方程进行一维化数值离散,得到差分计算的结果;
F02.GPU并行处理子模块,通过GPU语言进行修改,分维度并行处理整个空间的差分数据。
G.地震波场生成模块,用于生成地面地震记录和波场切片结果,该模块的两个结果计算如下:波场切片的结果是在每一个时间节点时进行保存,即保存地震波场传播过程中的状态;地面地震记录的结果是通过计算每一时间节点地面的波场情况,在最后时间循环计算结束后进行保存。
下面通过实例对本发明的效果做进一步说明。
具体实施采用中原油田桥口地区三维速度模型,利用本发明提供方法生成三维地震波场,并对CPU和GPU数值模拟针对三维弹性波场结果进行对比。CPU选用型号为:i7-4770K主频3.50GHz;GPU选用型号为:K5200。图5是本发明实施例采用现有的CPU与采用本发明的GPU并行数值模拟三维弹性波场的结果对比;其中,(a)为现有的CPU方法数值模拟三维弹性波场的结果;(b)为采用本发明的GPU并行数值模拟三维弹性波场的结果。图6是本发明实施例采用现有的CPU与采用本发明的GPU并行数值模拟三维弹性波场的二维波场记录切片结果对比;其中,(a)为现有的CPU方法数值模拟三维弹性波场的二维波场记录切片结果;(b)为采用本发明的GPU并行数值模拟三维弹性波场的二维波场记录切片结果。其中,用于模拟的模型网格大小为3703,包含20个网格的完全匹配层边界。结果表明,本发明方法(GPU计算)与现有传统方法(CPU计算)的计算结果保持一致。
实施例针对中原油田桥口地区的三维模型,采用GPU并行三维地震波场生成方法进行正演模拟,具体包括如下步骤:
1)首先将实验分为两组,输入同样的模型、地震子波和观测系统文件;
2)对两组实验,设置相同的初始条件、边界条件,并验证算法的稳定性;
3)第一组实验应用传统方法(CPU计算),对三维地震数据进行三维数值差分,并通过时间迭代进行计算;第二组实验应用本发明方法(GPU计算),基于GPU修改算法结构,将三维数据数组一维排列并编号,从CPU导入GPU显存中,通过时间迭代进行计算。
4)第二组实验,在GPU内核中,针对三维模型的计算选择垂直方向为循环维度,两个水平方向为并行维度(分别分配给Block对应编号和Thread对应编号),进行垂直方向循环迭代、水平切片并行计算;
5)如果输出三维地震波场时间切片结果,需要通过GPU将数据导入CPU进行输出,输出结束后重新将数据输入GPU进入下一轮GPU循环计算;如果输出地面地震记录数据,则需要将所有时间节点保存的观测系统接收数据(波场时间切片的地面部分)在数值计算全部结束后统一输出。
实验结果记录了1s波场(2000时间步)单CPU和GPU计算时间的对比,如图7所示。结果表明,采用本发明提出的GPU并行三维地震波场生成方法,相比于本实施实验所用的高性能CPU,依然能够加快正演模拟的速度,加速可达约CPU的5.53倍。在实际应用中,如果使用更高级别的GPU设备,可取得更佳的加速效果。采用本发明提出的GPU并行三维地震波场生成方法有很好的应用前景。
需要注意的是,公布实施例的目的在于帮助进一步理解本发明,但是本领域的技术人员可以理解:在不脱离本发明及所附权利要求的精神和范围内,各种替换和修改都是可能的。因此,本发明不应局限于实施例所公开的内容,本发明要求保护的范围以权利要求书界定的范围为准。
- 还没有人留言评论。精彩留言会获得点赞!