基于近红外高光谱技术无损检测杨梅中多酚含量的方法与流程
本发明涉及一种基于近红外高光谱无损测定多酚含量的方法,尤其涉及一种基于近红外高光谱技术无损检测杨梅中多酚含量的方法。
背景技术:
杨梅是我国的特色水果,在浙江、福建和广东等省份有较大面积的种植。杨梅具有较高的营养价值,果肉中含有丰富的碳水化合物、蛋白质、氨基酸、有机酸、矿物质、维生素和多酚类物质。《本草纲目》记载杨梅“止渴,和五赃,能涤肠胃,除烦溃恶气”。近代生物学和医学进一步证明杨梅具有防止便秘,抗菌,缓解食欲不振等功效。
杨梅多酚是杨梅中所含有的多酚类物质的总称,包括黄酮、黄酮醇、花色苷、原儿茶酸、没食子酸等。杨梅多酚具有较高的生物活性作用,能清除活性氧自由基,具有抗氧化性,抗肿瘤,抑菌,抗血小板凝聚等作用(夏其乐,程绍南.杨梅的营养价值及其加工进展[j].中国食物与营养,2005(6):21-22.)。
杨梅多酚是杨梅中的主要活性物质,并对其风味、口感和营养价值等有重要影响,是决定杨梅感官质量的重要因素之一。杨梅是中国特色浆果资源,且含有丰富的多酚。因此,研究杨梅中的多酚含量有助于评价杨梅的营养价值,对进一步开发杨梅资源具有十分重要的意义。
化学方法检测杨梅中多酚的含量需要先进行样品提取,此步骤会破坏检测样品,难以实现大样本量的快速无损检测。近年来,近红外高光谱成像技术作为一种无损检测方法引起了广泛的关注。其最大特点是结合光谱技术与计算机图像技术两者的优点,可获得大量包含连续波长光谱信息的图像块,由于其具有检测速度快、效率高、成本低等优点,越来越多地应用于农产品品质与安全的无损检测。因此可以利用近红外高光谱成像技术来快速无损检测杨梅中多酚含量。
技术实现要素:
本发明的目的在于提供一种基于近红外高光谱的杨梅中多酚含量测定的方法,旨在实现无损、快速、大样本量的检测。
本发明提供了一种杨梅中多酚含量的无损测定方法,该基于近红外高光谱的杨梅中多酚含量测定的方法包括以下步骤:
1)样本光谱的建立:
收集不同品种新鲜杨梅样本随机分配,建立校正样本集和检验样本集;对校正和检验样本集中的样本运用高光谱成像系统进行光谱扫描,其中镜头与样本距离为10~40cm,曝光时间为0.5~4s,样本移动速度为5~15mm/s,采集900~1700nm近红外波段高光谱图像,得到校正和检验样本集光谱;
2)样本多酚含量的测定:
采用福林-酚法测定杨梅样本中多酚含量,样本采用30~90%乙醇提取,取适量提取液与福林酚反应,在760nm波长下检测,以没食子酸为标准品进行定量;
3)样本光谱的预处理:
采用平滑法(移动平均平滑法(movingaverage)、卷积平滑法(savitzky-golay)、高斯平滑滤波(gaussianfilter)和中值滤波平滑(medianfiltersmoothing)等)对样本原始光谱进行处理,消除光谱噪声,提高分辨率和灵敏度;结合标准正态变量变换算法(standardnormalvariatetransformation,snv)或多元散射校正算法(multiplicativescattercorrection,msc)处理,消除固体颗粒大小、表面散射以及光程变化对光谱的影响。预处理过程中需剔除差异性较大的个别数据。
4)采用多元回归算法建立校正模型:
首先结合预处理后校正样本集900~1700nm的光谱数据和多酚含量,采用偏最小二乘回归法(partialleastsquaresregression,plsr)建模,通过x-载荷(x-loadingweight)图,提取光谱特征值,选取波峰及波谷段光谱,特征光谱波长范围是920~930、960~980、1030~1075、1140~1160、1240~1290nm,以第一次建模得到的部分或全部校正特征光谱波长数据和多酚含量再次使用plsr建模,建模后代入检测样本集光谱数据,计算多酚实际值,与预测值的相关性系数(r2),优化上述特征光谱范围至r2大于0.9,选取r2最大值时对应的特征光谱波长范围,得到最佳建模特征光谱,建立杨梅中多酚含量的最优预测模型。
上述最优建模特征光谱波长范围是924~928、965~972、1052、1149~1153和1264nm,模型预测值与实际值的r2为0.9214,均方根误差(root-mean-squareerror,rmse)值为0.0841。
5)预测样本多酚含量测定:
扫描样品特征光谱波长,采集近红外高光谱数据,将光谱数据输入杨梅多酚含量预测模型,计算得到待测样品中多酚含量。
光谱数据预处理、建模及预测均在theunscramblerx软件上操作。
本发明提供的基于近红外高光谱的杨梅中多酚含量测定的方法,通过采用近红外高光谱图像提取杨梅光谱数据,通过福林-酚法测定杨梅中的多酚含量,结合光谱预处理方法,提取特征光谱,利用最小二乘回归法(plsr)建模,得到杨梅中多酚含量的预测模型。
本发明建模中通过选取特征光谱波长数据建模,检测样本多酚含量是,仅需扫描特征光谱波长数据,可以缩短扫描时间,提高检测速率。第一次建模采用的是900~1700nm波长的所有数据,第一次建模可以得出波长与含量之间的关系,可以通过第一次建模,得到特征光谱波长段,第二次建模利用第一次建模得到的特征波长段再次建模,选择特定波长段的数据,提高建模准确性,减少数据计算量。
本发明可以避免现有的化学检测法会破坏检测对象,可实现无损、快速和大量的检测杨梅中多酚的含量。
附图说明
图1是本发明实施例一提供的基于近红外高光谱的杨梅中多酚含量测定的方法流程图;
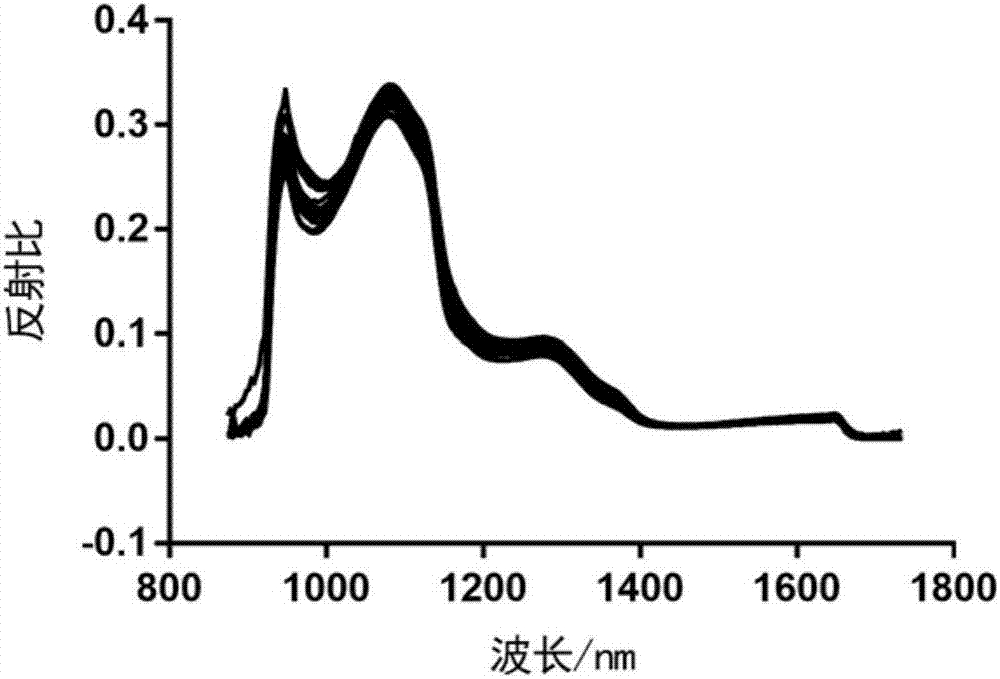
图2是本发明实施例二提供的近红外高光谱图像的平均光谱曲线图;
图3是本发明实施例三提供的经平滑处理和多元散射校正算法(msc)处理后的近红外高光谱曲线图;
图4是本发明实施例三提供的杨梅多酚的x-载荷(x-loadingweight)图;
图5是本发明实施例四提供的plsr建模方法下杨梅中多酚预测值与实际值的比较示意图;
具体实施方式
下面结合具体实施例对本发明作进一步描述,以下列举的仅是本发明的具体实施例,但本发明的保护范围并不仅限于此:
实施例一
1)样本光谱的建立:
收集不同品种新鲜杨梅样本(400颗)随机分配,建立校正样本集(200颗)和检验样本集(200颗);对校正和检验样本集中的样本运用高光谱成像系统进行光谱扫描,其中镜头与样本距离为10cm,曝光时间为0.5s,样本移动速度为5mm/s,采集1000~1600nm近红外波段高光谱图像,得到校正和检验样本集光谱;
2)样本多酚含量的测定:
采用福林-酚法测定杨梅样本中多酚含量,样本采用90%乙醇提取,取适量提取液与福林酚反应,在760nm波长下检测,以没食子酸为标准品进行定量;
3)样本光谱的预处理:
采用移动平均平滑法(movingaverage)对样本原始光谱进行处理,消除光谱噪声,提高分辨率和灵敏度;结合标准正态变量变换算法(standardnormalvariatetransformation,snv),消除固体颗粒大小、表面散射以及光程变化对光谱的影响。预处理过程中需剔除差异性较大的个别数据。
4)采用多元回归算法建立校正模型:
首先结合预处理后校正样本集900~1700nm的光谱数据和多酚含量,采用偏最小二乘回归法(partialleastsquaresregression,plsr)建模,通过x-载荷(x-loadingweight)图,提取光谱特征值,选取波峰及波谷段光谱,选择特征光谱波长是920~930、965~972、1052nm的波段,与和多酚含量再次使用plsr建模,建模后代入检测样本集光谱数据,计算多酚实际值与预测值的相关性系数(r2),建立杨梅中多酚含量的最优预测模型。模型预测值与实际值的r2为0.9021,均方根误差(root-mean-squareerror,rmse)值为0.1263。
5)预测样本多酚含量测定:
扫描样品特征光谱波长,采集近红外高光谱数据,将光谱数据输入杨梅多酚含量预测模型,计算得到待测样品中多酚含量。
光谱数据预处理、建模及预测均在theunscramblerx软件上操作。
图1是本发明的基于近红外高光谱的杨梅中多酚含量测定的方法流程图,主要步骤包括样品的采集,近红外高光谱扫描,读取光谱数据,光谱数据预处理,化学检测杨梅中多酚含量,结合光谱数据和多酚含量建立预测模型;
实施例二
基于近红外高光谱的杨梅中多酚含量无损测定的方法,其特征在于该方法的步骤如下:
1)样本光谱的建立:
收集不同品种新鲜杨梅样本(600颗)随机分配,建立校正样本集(400颗)和检验样本集(200颗);;对校正和检验样本集中的样本运用高光谱成像系统进行光谱扫描,其中镜头与样本距离为40cm,曝光时间为3s,样本移动速度为15mm/s,采集900~1700nm近红外波段高光谱图像,得到校正和检验样本集光谱;
2)样本多酚含量的测定:
采用福林-酚法测定杨梅样本中多酚含量,样本采用30~90%乙醇提取,取适量提取液与福林酚反应,在760nm波长下检测,以没食子酸为标准品进行定量;
3)样本光谱的预处理:
采用卷积平滑法(savitzky-golay)对样本原始光谱进行处理,消除光谱噪声,提高分辨率和灵敏度;结合标准正态变量变换算法(standardnormalvariatetransformation,snv),消除固体颗粒大小、表面散射以及光程变化对光谱的影响。预处理过程中需剔除差异性较大的个别数据。
4)采用多元回归算法建立校正模型:
首先结合预处理后校正样本集900~1700nm的光谱数据和多酚含量,采用偏最小二乘回归法(partialleastsquaresregression,plsr)建模,通过x-载荷(x-loadingweight)图,提取光谱特征值,选取波峰及波谷段光谱,选择特征光谱波长是920~930、965~972、1052、1149~1153、1240~1290nm的波段,与多酚含量再次使用plsr建模,建模后代入检测样本集光谱数据,计算多酚实际值与预测值的相关性系数(r2),建立杨梅中多酚含量的最优预测模型,模型预测值与实际值的r2为0.9168,均方根误差(root-mean-squareerror,rmse)值为0.0957。
5)预测样本多酚含量测定:
扫描样品特征光谱波长,采集近红外高光谱数据,将光谱数据输入杨梅多酚含量预测模型,计算得到待测样品中多酚含量。
光谱数据预处理、建模及预测均在theunscramblerx软件上操作。
图2是本发明的近红外高光谱图像的平均光谱曲线图。
实施例三
基于近红外高光谱的杨梅中多酚含量无损测定的方法,其特征在于该方法的步骤如下:
1)样本光谱的建立:
收集不同品种新鲜杨梅样本(300颗)随机分配,建立校正样本集(200颗)和检验样本集(100颗);对校正和检验样本集中的样本运用高光谱成像系统进行光谱扫描,其中镜头与样本距离为20cm,曝光时间为2s,样本移动速度为10mm/s,采集900~1700nm近红外波段高光谱图像,得到校正和检验样本集光谱;
2)样本多酚含量的测定:
采用福林-酚法测定杨梅样本中多酚含量,样本采用70%乙醇提取,取适量提取液与福林酚反应,在760nm波长下检测,以没食子酸为标准品进行定量;
3)样本光谱的预处理:
采用高斯平滑滤波(gaussianfilter)对样本原始光谱进行处理,消除光谱噪声,提高分辨率和灵敏度;结合多元散射校正算法(multiplicativescattercorrection,msc)处理,消除固体颗粒大小、表面散射以及光程变化对光谱的影响。预处理过程中需剔除差异性较大的个别数据。
4)采用多元回归算法建立校正模型:
首先结合预处理后校正样本集900~1700nm的光谱数据和多酚含量,采用偏最小二乘回归法(partialleastsquaresregression,plsr)建模,通过x-载荷(x-loadingweight)图,提取光谱特征值,选取波峰及波谷段光谱,选择特征光谱波长是1052、1149~1153和1264nm的波段,与多酚含量再次使用plsr建模,建模后代入检测样本集光谱数据,计算多酚实际值与预测值的相关性系数(r2),建立杨梅中多酚含量的最优预测模型,模型预测值与实际值的r2为0.9003,均方根误差(root-mean-squareerror,rmse)值为0.0745。
5)预测样本多酚含量测定:
扫描样品特征光谱波长,采集近红外高光谱数据,将光谱数据输入杨梅多酚含量预测模型,计算得到待测样品中多酚含量。
图3是本发明实施例三提供的经平滑处理和多元散射校正算法(msc)处理后的近红外高光谱曲线图;
图4是本发明实施例三提供的杨梅多酚的x-载荷(x-loadingweight)图,通过载荷图的波峰和波谷可以选择特征波长。
实施例四
基于近红外高光谱的杨梅中多酚含量无损测定的方法,其特征在于该方法的步骤如下:
1)样本光谱的建立:
收集不同品种新鲜杨梅样本(500颗)随机分配,建立校正样本集(300颗)和检验样本集(200颗);对校正和检验样本集中的样本运用高光谱成像系统进行光谱扫描,其中镜头与样本距离为15cm,曝光时间为3.5s,样本移动速度为15mm/s,采集900~1700nm近红外波段高光谱图像,得到校正和检验样本集光谱;
2)样本多酚含量的测定:
采用福林-酚法测定杨梅样本中多酚含量,样本采用80%乙醇提取,取适量提取液与福林酚反应,在760nm波长下检测,以没食子酸为标准品进行定量;
3)样本光谱的预处理:
采用中值滤波平滑(medianfiltersmoothing)对样本原始光谱进行处理,消除光谱噪声,提高分辨率和灵敏度;结合多元散射校正算法(multiplicativescattercorrection,msc)处理,消除固体颗粒大小、表面散射以及光程变化对光谱的影响。预处理过程中需剔除差异性较大的个别数据。
4)采用多元回归算法建立校正模型:
首先结合预处理后校正样本集900~1700nm的光谱数据和多酚含量,采用偏最小二乘回归法(partialleastsquaresregression,plsr)建模,通过x-载荷(x-loadingweight)图,提取光谱特征值,选取波峰及波谷段光谱,选择特征光谱波长是924~928、965~972、1052、1149~1153和1264nm的波段,与多酚含量再次使用plsr建模,建模后代入检测样本集光谱数据,计算多酚实际值与预测值的相关性系数(r2),建立杨梅中多酚含量的最优预测模型,模型预测值与实际值的r2为0.9214,均方根误差(root-mean-squareerror,rmse)值为0.0841。
5)预测样本多酚含量测定:
扫描样品特征光谱波长,采集近红外高光谱数据,将光谱数据输入杨梅多酚含量预测模型,计算得到待测样品中多酚含量。
图5本发明的杨梅多酚预测模型,拟合度可达92.14%,说明该模型可以较好的预测杨梅中多酚含量。
最后,本发明可用其他的不违背本发明的精神和主要特征的具体形式来概述。因此,无论从那一点来看,本发明的上述实施方案都只能认为是对本发明的说明而不能限制本发明,权利要求书指出了本发明的范围,而上述的说明并未指出本发明的范围,因此,在与本发明的权利要求书相当的含义和范围内的任何改变,都应认为是包括在权利要求书的范围内。
- 还没有人留言评论。精彩留言会获得点赞!