一种基于CC‑PLS‑RBFNN优化模型的近红外光谱分析方法与流程
本发明涉及近红外光谱分析领域,尤其是涉及一种基于cc-pls-rbfnn优化模型的近红外光谱分析方法。
背景技术:
近红外光谱分析技术作为一种快速无损的定量分析方法,已成功应用于农业、食品、化工和生物科学等多个领域,创造了可观的经济、社会效益。近红外光谱中包含了丰富的样品基团信息,然而近红外谱区内光谱吸收带较宽并且存在严重的光谱重叠,对此通常引入统计学方法建立合适的多元校正模型,从而实现光谱数据与预测目标数据间的关联。
目前,关于近红外光谱分析中校正模型的研究,典型的线性建模方法有多元线性回归、主成分回归以及偏最小二乘法等,非线性校正方法主要包含支持向量机和神经网络。多元线性回归的局限性在于,建模过程中包含对光谱矩阵或样本性质矩阵求逆的步骤,该步骤在矩阵奇异时无法完成,同时多元线性回归模型自身不具备去除数据噪声的能力;主成分回归通过对光谱矩阵或样本性质矩阵进行分解从而确保矩阵非奇异,但进行分解时未考虑到光谱数据和样本性质数据间的关联性,因此不适用于分析目标信息在光谱信息中含量微弱的情况;偏最小二乘法在主成分回归的基础上考虑了光谱数据和样本性质数据的相关性,但作为一种线性校正方法,其建立的模型始终存在一定的非线性误差;基于支持向量机的回归模型有较好的非线性拟合能力,但在建模过程中借助二次规划来求解支持向量,涉及样本数量阶次的矩阵计算,在样本数量偏大时耗费大量的机器内存和计算时间;神经网络模型可以映射任意复杂的非线性关系,并且学习规则简单便于计算机实现,但对数据的充分性有很高的要求,当数据量不足时容易过拟合,降低模型鲁棒性,上述现有方法的局限性,影响了模型的鲁棒性和精度。
技术实现要素:
本发明的目的在于,针对现有技术的不足,提出将相关系数法(correlationcoefficientmethod,简称cc)、偏最小二乘法(partialleastsquares,简称pls)、径向基函数神经网络(radialbasisfunctionneuralnetwork,简称rbfnn)相结合并优化选取重要参数,提供一种基于cc-pls-rbfnn优化模型的近红外光谱分析方法,以提升近红外光谱建模的鲁棒性和精度。
为此,本发明采用如下解决方案:
一种基于cc-pls-rbfnn优化模型的近红外光谱分析方法,所述基于cc-pls-rbfnn优化模型的近红外光谱分析方法包括:利用三阶savitzky-golay卷积平滑滤波及一阶导数校正对原始光谱进行预处理;在全波长段建立pls模型并优化选取平滑滤波的窗口宽度和pls提取的主成分个数;计算每个波长变量的相关系数,截取相关系数大于设定阈值的波长变量参与建模并优化选取阈值大小;利用优化选取的窗口宽度、主成分个数和波长变量得到优化pls模型;用优化pls模型提取的主成分得分和性质矩阵训练rbf神经网络,获得最终的cc-pls-rbfnn优化模型;具体步骤包括:
步骤(1):参数初始化:将样本划分为校正集和预测集;校正集的光谱矩阵为xs(s×p),具有s个样本,全波长点有p个,校正集的样本性质矩阵为ys(s×1);预测集的光谱矩阵为xt(t×p),具有t个样本,全波长点有p个,预测集的样本性质矩阵为yt(t×1);定义n为平滑滤波的窗口宽度,q为主成分个数,th为相关系数阈值;设定最大窗口宽度n_max,最大主成分个数q_max,相关系数阈值遍历间隔d_th,最大相关系数阈值th_max,以及设定rbf神经网络核函数扩展因子σ,网络神经元数量m;窗口宽度n初始化为5,主成分个数q初始化为5,相关系数阈值th初始化为0;
步骤(2):光谱预处理:对校正集原始光谱矩阵xs(s×p)逐行进行n点三阶savitzky-golay卷积平滑滤波,并进行一阶求导完成光谱预处理,得到校正集预处理后光谱矩阵xs’(s×p);
步骤(3):pls初始建模:对预处理后的s个校正集的样本利用pls模型提取q个主成分,对预处理后光谱矩阵xs’(s×p)及对应的样本性质矩阵ys(s×1)进行回归建模并得到全波长pls模型,并采取留一交叉验证的方法,得到相应的rmsecv值;
步骤(4):选择模型参数:依次遍历不同的n和q,重复步骤(2)到步骤(3),直至n=n_max,q=q_max,得到不同模型参数下的rmsecv值;n和q的遍历间隔分别为2和1,选取使得rmsecv最小的n和q作为优化选取下的模型参数;
步骤(5):筛选光谱矩阵:对校正集预处理后光谱矩阵xs’(s×p)及对应样本性质矩阵ys(s×1)展开相关分析,得到p个波长变量的相关系数,构成相关系数矩阵c(1×p);设相关系数大于设定的相关系数阈值th的波长变量共有p’个,选取这部分波长变量对应的预处理后光谱矩阵xs’(s×p)的子集,构成筛选后光谱矩阵xs_selected(s×p’);
步骤(6):部分波长pls建模:在步骤(4)优化选取的模型参数下,对筛选后光谱矩阵xs_selected(s×p’)及对应样本性质矩阵ys(s×1)进行预处理和pls回归建模,得到部分波长下的pls模型,并采取留一交叉验证的方法,得到相应的rmsecv值;
步骤(7):选择相关系数阈值th:以d_th为相关系数阈值遍历间隔,依次遍历不同的th,重复步骤(5)至步骤(6),直至th=th_max,得到不同的rmsecv值;选取使得rmsecv最小的th作为优化选取的相关系数阈值,建立部分波长下的优化pls模型;
步骤(8):训练rbf神经网络:将步骤(7)所得的优化模型所提取的主成分得分矩阵score(s×q)作为输入变量,对应的样本性质矩阵ys(s×1)作为目标变量,进行rbf神经网络的训练,得到最终的cc-pls-rbfnn优化模型。
在采用上述技术方案的同时,本发明还可以采用或者组合采用以下进一步的技术方案:
所述步骤(4)中,所述最大窗口宽度n_max的取值范围优选15到45之间。
所述步骤(4)中,所述最大主成分个数q_max的取值范围优选10到50之间。
所述步骤(7)中,所述相关系数阈值遍历间隔d_th的取值范围优选0.001到0.1之间。
所述步骤(7)中,所述最大相关系数阈值th_max的取值范围优选0.4到0.6之间。
所述步骤(8)中,所述步骤(8)中,所述rbf神经网络所用径向基函数为高斯核函数,形式为k(||x-xc||)=exp[-||x-xc||2/(2σ2)],式中xc是核函数中心;σ为扩展因子,优选为0.1至2之间;网络的神经元数量m优选s/3到s之间,其中s为训练网络的校正集样本数量。
本发明所提供的近红外光谱分析方法具有以下优点:
(1通过卷积平滑滤波和求导校正对原始光谱进行预处理,降低光谱中随机噪声对建模的不利影响;
(2)采用相关系数法对光谱进行波长筛选,最大化甄别出有益波长参与建模;
(3)通过pls模型和rbfnn模型的结合,在保留pls提取光谱有效信息能力的同时,利用rbfnn的任意非线性拟合能力,降低主成分得分的非线性回归残差,提升了模型精度;
(4)采用留一交互验证,最优化选择建模过程中的关键参数从而优化所建模型,提升了模型的鲁棒性和精度。
附图说明
图1为本发明基于cc-pls-rbfnn优化模型的近红外光谱分析方法的流程图。
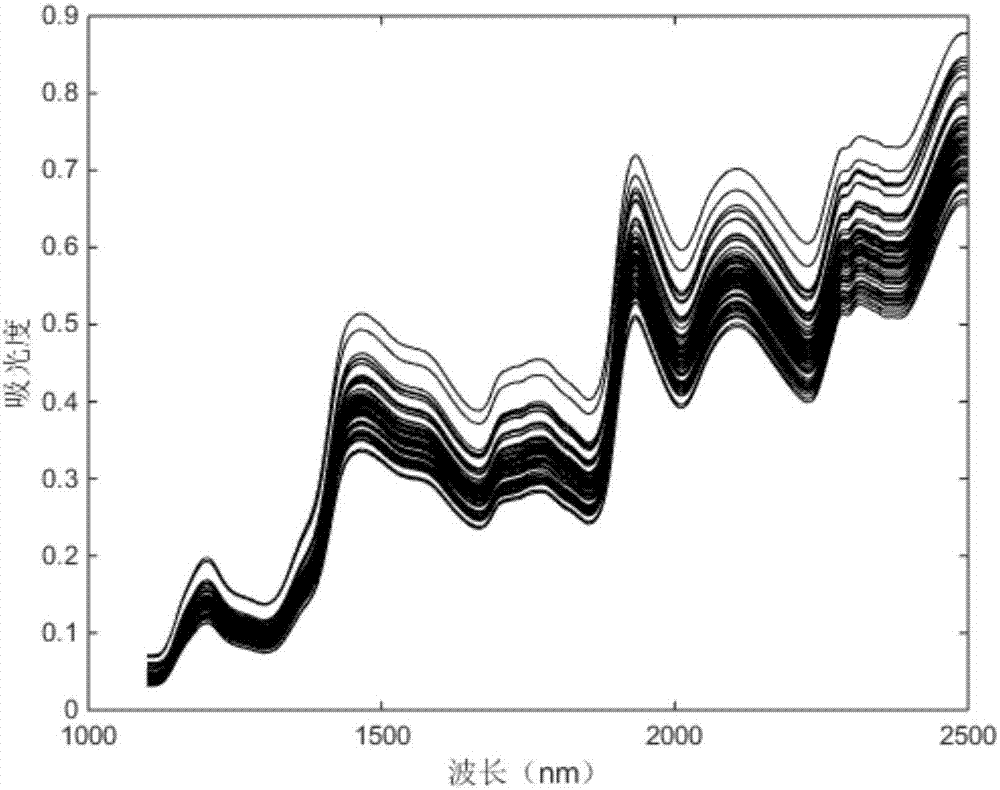
图2为玉米籽粒的原始近红外光谱图。
图3为滤波窗口宽度、pls主成分个数与模型rmsecv的关系图,图中标出点为筛选出的最优参数点。
图4为经滤波并求导后的近红外光谱图。
图5为相关系数阈值与模型rmsecv的关系图,图中标出点是筛选出的最优阈值点。
图6为玉米籽粒淀粉含量预测值与真实值的比较图。
具体实施方式
本发明的具体实施方式,将结合附图和近红外光谱分析的具体实施例进行详述。
图1为本发明提出的基于cc-pls-rbfnn优化模型的近红外光谱分析方法。
本具体实施例,采用玉米籽粒近红外光谱数据样本来验证本发明的方法。该数据集包含80个近红外光谱测量样本,淀粉的质量含量范围为0%~100%(w/w),考察近红外光谱与玉米籽粒中淀粉含量之间的关系。样本集中,光谱仪的扫描区间为1100~2498nm,扫描间隔为2nm,即每份光谱样本数据中包含700个采样波长。
针对玉米籽粒近红外光谱数据样本,实施本发明提出的基于cc-pls-rbfnn优化模型的近红外光谱分析方法,步骤如下:
步骤(1):参数初始化:对于样本个数为80,波长个数为p=700,原波长集为v={x1,…,xp-1,xp}={1100,1102,…,2496,2498}的玉米籽粒近红外光谱样本集,按3:1随机划分校正集和预测集,得到校正集样本60个,光谱矩阵为xs(60×700),表征玉米籽粒中淀粉含量的性质矩阵为ys(60×1);得到预测集样本20个,光谱矩阵为xt(20×700),表征玉米籽粒中淀粉含量的性质矩阵为yt(20×1);所述最大窗口宽度n_max的取值范围优选15到45之间,所述最大主成分个数q_max的取值范围优选10到50之间,所述最大相关系数阈值th_max的取值范围优选0.4到0.6之间,n_max、q_max和th_max的值越大,参数寻优所需的时间越长,n_max、q_max和th_max的值太小,则搜索范围可能不包含最优解,本具体实施例中设定n_max=39,q_max=40,th_max=0.5;所述相关系数阈值遍历间隔d_th的取值范围优选0.001到0.1之间,决定相关系数阈值的搜索密度,太大会使得求解的参数不够逼近最优值,太小则寻优耗时过长,本具体实施例中d_th=0.02;所述扩展因子σ=1;所述神经元数量m=30;窗口宽度n初始化为5,主成分个数q初始化为5,相关系数阈值th初始化为0。
步骤(2):光谱预处理:对校正样本集光谱矩阵xs(60×700)逐行进行n点三阶savitzky-golay卷积平滑滤波,再求取一阶导数完成光谱的预处理,得到校正样本集预处理后的光谱矩阵xs’(60×700);
步骤(3):pls初始建模:对预处理后的校正集光谱矩阵xs’(60×700)以及对应样本性质矩阵ys(60×1),按公式(1)至公式(3)建立主成分个数为q的pls模型;该模型的数学表达式如下:
xs=tpt+e(1)
ys=uqt+f(2)
t=xw(ptw)-1(3)
其中校正光谱矩阵xs的得分矩阵是t,载荷矩阵是p,权重矩阵是w,残差光谱是e;校正样本性质矩阵ys的得分矩阵是u,载荷矩阵是q,残差光谱是f。
采取留一交叉验证的方法,得到所建立pls模型的交互验证均方根误差rmsecv。
步骤(4):选择模型参数:依次遍历不同的n和q,重复步骤(2)到步骤(3),直至n=n_max,q=q_max,得到不同模型参数n和q下的rmsecv值,n和q的遍历间隔分别为2和1。具体遍历过程为,先保持q值为初始值5,从n的初始值5开始,每次循环后若n<n_max,则执行n=n+2并继续循环过程;若n=n_max则再判断若q<q_max则令n回归初始值5,执行q=q+1并继续循环过程,当q=q_max时完成遍历终止循环。比较所有的rmsecv值,选取使得对应rmsecv最小的n和q作为优化选取的模型参数;
步骤(5):筛选光谱矩阵:对校正集预处理后光谱矩阵xs’(60×700)及对应样本性质矩阵ys(60×1)展开相关分析,得到700个波长变量的相关系数,构成相关系数矩阵c(1×700)。第p个波长变量上的相关系数计算公式如下
式中xi,p是预处理后光谱矩阵xs’(60×700)中第i个样本在第p个波长变量上的值,yi,p为样本性质矩阵ys(60×1)中第i个样本的值,其中
选取相关系数大于设定阈值th的总计p’个波长变量,该p’个波长变量对应的预处理后光谱矩阵xs’(60×700)的子集,构成筛选后光谱矩阵xs_selected(60×p’);
步骤(6):部分波长pls建模:在步骤(4)优化选取的模型参数n和q下,对筛选后光谱矩阵xs_selected(60×p’)及对应样本性质矩阵ys(60×1)进行预处理和pls回归建模,得到部分波长下的pls模型,采取留一交叉验证的方法,得到相应的rmsecv值;
步骤(7):选择相关系数阈值th:以d_th为相关系数阈值遍历间隔,依次遍历不同的th,重复步骤(5)至步骤(6),直至th=th_max,得到不同的rmsecv值。具体遍历过程为,从th的初始值0开始,每次循环后若th<th_max,则执行th=th+d_th并继续循环过程;若th=th_max,则完成遍历终止循环。最后选取使得rmsecv最小的th作为优化选取的相关系数阈值,建立部分波长下的优化pls模型;
步骤(8):训练rbf神经网络:将步骤(7)所得的优化pls模型所提取的主成分得分矩阵score(60×q)作为输入变量,对应的样本性质矩阵ys(60×1)作为目标变量,进行rbf神经网络的训练,得到最终的cc-pls-rbfnn优化模型。相比于更常用的反向传播(backpropagation,简称bp)神经网络而言,rbf神经网络具有唯一最佳逼近,避免陷入局部最优的能力。此处rbf神经网络选用高斯核函数为径向基函数,形式为k(||x-xc||)=exp[-||x-xc||2/(2σ2)],式中σ为扩展因子,其值过大会引起大的网络逼近误差,过小则容易造成过拟合现象,此处取σ=1;网络的神经元数量根据样本数选择为30。
图2为校正样本集的原始近红外光谱谱图;
图3为滤波窗口宽度n、pls主成分个数q与全波长pls模型交互验证均方根误差rmsecv的关系图,图中标出rmsecv取得最小值的点,对应最优模型参数n=19,q=30;
图4为经19点三阶savitzky-golay卷积平滑滤波并一次求导后的预处理后校正样本集光谱谱图,对比图2显示原始光谱中的噪声和基线漂移得到显著改善;
图5为相关系数阈值th与部分波长pls模型交互验证均方根误差rmsecv的关系图,图中标出rmsecv取最小值的点,对应最优相关系数阈值th=0.28;
结果验证:图6显示了采用上述方法得到的cc-pls-rbfnn优化模型对20个预测集样本淀粉含量的预测情况,通过回归分析得到预测值与真实值的关系。
表1
表1以预测均方根误差rmsep(rootmeansquareerrorofprediction)和回归相关系数作为评价指标,比较了本发明方法与基于pls回归模型、基于反向传播神经网络(bpnn)模型、基于径向基函数神经网络(rbfnn)模型以及基于偏最小二乘-反向传播神经网络(pls-bpnn)模型的建模分析方法的预测能力。比较结果显示本发明方法预测误差最小,回归相关系数最大。
表1的结果充分表明:本发明方法能够有效地加强模型的预测能力,提升近红外光谱分析的鲁棒性和精度。
本发明上述具体实施方式中所涉及的近红外光谱分析对象为玉米籽粒的淀粉含量,仅为优选实施例,具体实施时,也可以用于农业、食品、化工和生物科学等领域各种近红外光谱分析对象的分析过程中。
上述具体实施方式用来解释说明本发明,仅为本发明的优选实施例,而不是对本发明进行限制,在本发明的精神和权利要求的保护范围内,对本发明作出的任何修改、等同替换、改进等,都落入本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!