基于LMD近似熵和SVM的模拟电路故障诊断方法与流程
本发明涉及模拟电路技术领域,特别是一种基于lmd(localmeandecomposition,局部均值分解)近似熵和svm(supportvectormachine,支持向量机)的模拟电路故障诊断方法。
背景技术:
随着全球信息时代的来临,电子设备广泛应用于国防科研、工业生产和日常生活等各个领域。由于电子设备的运行环境复杂多样,为了保证系统的正常运行,对其可靠性指标有严格的要求,特别在航空航天、军事领域和医疗部门,对电子设备可靠性指标的要求更全面、更苛刻。为了进一步提高电子设备的可靠性,减少维修所耗费的精力和财力,促使人们研究新的技术和方法,通过测试手段来对设备的故障进行诊断和辨识,以便在故障发生后,可及时地对故障部件进行检修和更换,减少损失。由于电子工业的迅速发展使电子设备的复杂性越来越高,数字电路占电路系统的绝大部分,但在一个完整的系统中,模拟器件和电路不可缺少。据统计,尽管在电子设备中超过80%为数字电路,但80%以上的故障都来自模拟电路,因此模拟电路的可靠性对整个电子设备的可靠性至关重要。研究模拟电路故障诊断方法和技术,在电路运行中如果发生故障时能够准确而及时地找出故障的原因或位置,对实现电子系统的自动诊断和提高电子设备的可靠性有重要的意义和价值。
技术实现要素:
针对上述缺陷,本发明提出一种基于lmd近似熵和svm的模拟电路故障诊断方法,以更快更准确的识别模拟电路的故障。
基于lmd近似熵和svm的模拟电路故障诊断方法,包括以下步骤:
a1、用软件模拟诊断对象的故障;
a2、对每种故障利用蒙特卡洛分析法进行分析,把电路故障信号分解为一系列pf分量,选取前三个pf分量,求它们的近似熵,作为故障特征向量;
a3、在对故障进行分类时选用svm,寻找最优的svm参数,前半部分特征向量用于训练,后半部分特征向量用于验证分类的正确性;
a4、将在a2中所述故障特征向量放在a3中得到的用于训练的特征向量进行验证,得出分类的正确率以及分类的时间。
a1中的所述软件是orcad或pspice。
a2中利用lmd算法得到pf分量,具体包括以下步骤:
a1-1、计算信号的局部极值点集合,再计算任意2个相邻极值点的平均值;
a1-2、根据局部极值点集合确定包络估计值集合;
a1-3、利用计算所得的局部均值点集合和包络估计值集合将集合中所有相邻的2个极值,分别用折线相连,进行平滑处理,得到局部均值函数和包络估计函数;
a1-4、将局部均值函数从原始信号中分离出去;分离后的信号进行解调得到纯调频信号;
a1-5、把a1-1~a1-4迭代过程中产生的包络估计函数相乘得到包络信号;
a1-6、将包络信号和纯调频信号相乘,得到原始信号的首个pf分量;
a1-7、从信号中分离出来的pf,对应得到一个新的信号,将新信号作为原始信号重复a1-1~a1-6,直到误差△=0.001或残余信号为单调函数,停止迭代。
a2中所述选取前三个pf分量,求它们的近似熵,作为故障的特征向量的具体过程为:
a2-1、设给定长度为n的一维时间序列{u(i),i=1,2...n},按式xi={u(i),u(i+1)...u(i+m-1)}重构m维向量xi,i=1,2,....n,n=n+m-1;
a2-2、计算向量xi与其他向量xj(j=1,2,...n,n=n+m-1)之间的距离
d=max|u(i+j)-u(j+k)|k=0,1,2....,m-1;
a2-3、给定一个阀值r,对每个向量xi统计d≤r的数目以及此数目与距离总数(n-m)的比值,记为
a2-4、对
a2-5、将m加1,重复a2-1~a2-4,求得
a2-6、由φm和φm+1得近似熵
a3中训练svm,寻找最优的svm参数采用混沌粒子群算法,具体如下:
a3-1、cpso参数设置:设置粒子群的规模、适应度误差限、允许最大迭代次数、惯性权重以及学习因子c1,c2等参数;
a3-2、混沌粒子位置和速度,随机产生各粒子的初始速度vi=(v1,v2,.....,vm);
a3-3、将每个粒子的个体极值位置设置为当前位置,计算出每个粒子的适应度,采用均方误差作为粒子适应值的评价函数,取适应度最好的粒子所对应的个体极值作为最初的全局极值;
a3-4、按下式进行迭代计算,更新粒子的位置,速度,
vid=wwid+c1r(pid-xid)+c2r(gd-xid)
xid=xid+αvid
其中vid表示粒子的速度,r,r表示均匀分布在(0,1)区间的随机数,α为控制速权重的约束因子,ω表示惯性权重,c1,c2表示学习因子,iter为当前迭代次数,itermax为总的迭代次数,vmax表示粒子的最大速度,wmax,wmin分别为最大、最小权重因子;
a3-5、对所有最优位置进行混沌优化,将pgi,i=1,2,...,d映射到logistic方程的定义域内,然后通过logistic方程的迭代,产生混沌变量序列
a3-6、用p*取代当前群体中任意一个粒子的位置;
a3-7、当达到最大迭代次数或解不再变化时停止搜索,否则返回到a3-3。
本发明的有益效果在于:①lmd算法在估计包络函数时使用使用滑动平均,避免了虚假分量的产生;近似熵可以作为时间序列复杂性的一种度量,信号经lmd分解后的pf分量为依次从高频到低频的时间序列,故用近似熵对pf分量进行量化,可实现以pf分量的复杂性作为目标的有用信息提取。求近似熵相对而言比较简单,快速。②用混沌粒子群算法优化支持向量机可以避免寻参时陷入局部最优,以达到更好的分类效果。
附图说明
图1为本发明实施例所选取的诊断对象带通滤波器电路图;
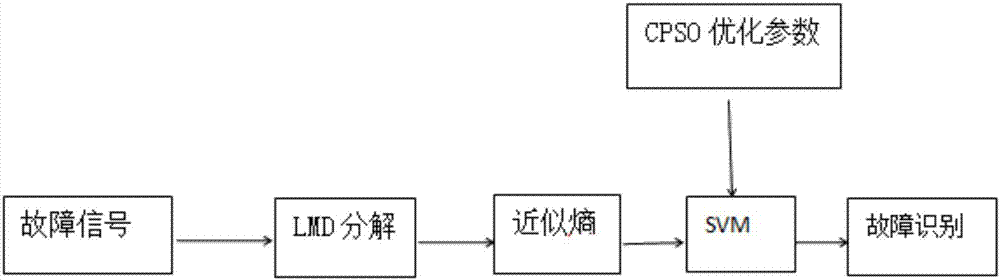
图2为图1中实施例基于lmd近似熵和svm的模拟电路故障诊断流程图;
图3为图2流程中r1↑故障信号经lmd分解得到前三个pf分量图;
图4为图2流程中部分lmd近似熵特征值;
图5为图2流程中混沌粒子群算法优化svm的流程图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
选取带通滤波器作为诊断对象,电路图如附图1,在orcad/pspice软件中画出电路,元件具有容差,设立电阻容差为标称值的5%,电感为10%。设立故障模式分别为c1↑,c1↓,c2↑,c2↓,,r1↑,r1↓,r2↑,r2↓,r3↑,r3↓,其中↑表示该值为大于标称值50%的故障值,↓为小于标称值50%的故障值。这样就有10种故障,再加上正常值,总共11种状态,用蒙特卡洛分析法对每种故障进行200次分析,在matlab软件中利用lmd算法把电路故障信号分解为一系列pf分量,再选取前三个pf分量,求它们的近似熵,作为故障的特征向量。在对故障进行分类时,还是在matlab软件中进行,选用svm,并利用混沌粒子群算法寻找最优的svm参数。前100次的特征向量用于训练,后一百次的特征向量用于验证分类的正确性。整个流程如附图2所示。
基于lmd近似熵和svm的模拟电路故障诊断分析方法如下:
(1)在orcad/pspice设置好电路的容差,进行蒙特卡洛分析,得到故障电路的信号。
(2)利用lmd算法得到电路的一系列pf分量。r1↑故障信号经lmd分解得到前三个pf分量图如图3。算法包含以下步骤:
①计算信号的局部极值点集合,再计算任意2个相邻极值点的平均值;
②利用①所得的局部极值点集合,确定包络估计值集合;
③利用计算所得的局部均值点集合和包络估计值集合将集合中所有相邻的2个值,分别用折线相连,然后进行平滑处理,得到局部极值函数和包络估计函数;
④将局部均值函数从原始信号中分离出去;
⑤将分离后的信号进行解调,理想情况下就得到了纯调频信号;
⑥把迭代过程中产生的包络估计函数相乘就得到了包络信号;
⑦将包络信号和纯调频信号相乘,得到原始信号的首个pf分量;
⑧从信号中分离出来的pf,对应得到一个新的信号,将新信号作为原始信号重复①一⑦步聚,直到残余信号是单调函数,停止迭代;
(3)选取前三个pf分量,分别求它们的近似熵作为故障的一组特征向量,部分lmd近似熵特征值如附图3,算法步骤如下:
1)设给定长度为n的一维时间序列{u(i),i=1,2...n},按式
xi={u(i),u(i+1)...u(i+m-1)}
重构m维向量xi,i=1,2,....n,n=n+m-1。
2)计算向量xi与其他向量xj(j=1,2,...n,n=n+m-1)之间的距离:
d=max|u(i+j)-u(j+k)|k=0,1,2....,m-1
3)给定一个阀值r,对每个向量xi统计d≤r的数目以及此数目与距离总数(n-m)的比值,记为
4)对
5)将m加1,重复前面1)一4)的步骤,求得
6)由φm和φm+1得近似熵:
(4)选取一部分特征向量作为训练样本,训练svm,并用混沌粒子群算(cpso)寻找最优的参数,主要是寻找最优的惩罚参数c和核参数以达α到最优的分类效果,算法流程图如图附图4所示,算法步骤如下:
a、cpso参数设置。设置粒子群的规模、适应度误差限、允许最大迭代次数、惯性权重以及学习因子c1,c2等参数;
b、混沌粒子位置和速度,随机产生各粒子的初始速度vi=(v1,v2,.....,vm);
c、将每个粒子的个体极值位置设置为当前位置,计算出每个粒子的适应度,采用均方误差作为粒子适应值的评价函数,取适应度最好的粒子所对应的个体极值作为最初的全局极值;
d、按照下面公式进行迭代计算,然后更新粒子的位置,速度;
vid=wwid+c1r(pid-xid)+c2r(gd-xid)
xid=xid+αvid
其中vid表示粒子的速度,r,r表示均匀分布在(0,1)区间的随机数,α控制速权重的约束因子,ω表示惯性权重,c1,c2表示学习因子,iter为当前迭代次数,itermax为总的迭代次数,vmax表示粒子的最大速度,wmax,wmin分别为最大、最小权重因子。
e、对所有最优位置进行混沌优化,将pgi,i=1,2,...,d映射到logistic方程的定义域内,然后通过logistic方程的迭代,产生混沌变量序列
f、用p*取代当前群体中任意一个粒子的位置;
g、当达到最大迭代次数或解不再变化时停止搜索,否则返回到步骤c。
(5)用剩余的特征向量进行分类识别,得出分类的正确率。
- 还没有人留言评论。精彩留言会获得点赞!