一种对三七及其伪品的快速鉴别方法与流程
本发明属于中药鉴别技术领域,特别涉及一种对三七及其伪品的快速鉴别方法。
背景技术:
三七是最早的药食同源植物中的一种五加科人参属植物,因其具有止血、活血化瘀、降血脂、降血压、消肿定痛、的功效而广泛用于冠心病、心绞痛、脑溢血、高血脂症、肺结核略血、术后止痛等。(张延莹,张金巍,刘岩,赵国庆,张培,三七的近红外光谱鉴别方法,中国发明专利,2009,cn200910069866)由于三七市场需求巨大而资源紧缺,导致三七价格极为昂贵。市场上常出现有混伪品(陈士林,韩建萍,王晓玥,宋经元,一种三七分子身份证及鉴定方法,中国发明专利,2015,cn201510117020)如高良姜、姜黄、莪术、藤三七等,由于形貌、颜色与三七非常接近,很难分辨,常被充当三七收售、使用。但是他们的药性及功能相差甚远这严重威胁了三七的临床用药安全。因此探讨三七及其伪品的鉴别方法,对保证临床用药安全具有重要意义。
气相色谱和液相色谱已被广泛用于三七鉴别,但是这两种方法主要通过分析每种中药的活性成分,从而对不同中药加以区分。虽然准确率高,但是需要选用合适的溶剂进行成分提取,样品的预处理时间长且复杂。近年来,近红外光谱分析技术因其具有快速、无损、操作简单和易于在线等优势,已广泛应用于医药、化工、农产品、食品等复杂样品的分析检测。
但是,复杂样品光谱存在谱带重叠、背景和噪声干扰等问题,需要借助化学模式识别进行鉴别分析。按照有无训练集,化学模式识别分为无监督模式识别方法和有监督模式识别方法,前者主要有系统聚类分析,后者主要有偏最小二乘判别分析、人工神经网络、支持向量机、极限学习机。已有研究将化学模式识别结合近红外用于相似中药的鉴别(卞希慧,李露露,陈娇娇,普娅,郭玉高,一种基于化学模式识别和近红外光谱的相似药材鉴别方法,中国发明专利,2014,cn201410616144)。因此,将化学模式识别方法引入到三七及其伪品的鉴别中,将有望实现三七及其伪品的快速准确鉴别。
技术实现要素:
本发明的目的是针对上述问题,采用近红外光谱作为检测手段,利用化学模式识别建立模型,提供一种快速、准确、的三七及其伪品鉴别方法。
为实现本发明所提供的技术方案包括以下步骤:
1)购买三七及其伪品并制样
分别购买三七及其伪品若干个,将样品分别粉碎,过120目筛,分别取一定质量放入密封的塑料瓶中。
2)采集样品的近红外光谱
采用傅立叶变换-近红外光谱仪器采集样品的近红外光谱。采样波数范围12000-4000cm-1,分辨率为4cm-1,样品扫描次数64次,样品测量方式为积分球漫反射模式。仪器预热1小时后开始测样。首先将未装样品的石英瓶置于光点的中心处,作为背景保存,然后进行待测样品扫描,每个样品采集光谱三次,每采集一次,旋转石英瓶一次,最终取三次光谱数据的平均值作为每个样品的光谱。
3)优化化学模式识别方法的参数
优化系统聚类分析的类内聚类和类间距离,偏最小二乘判别分析的因子数,极限学习机的隐含层节点数和激励函数参数。
系统聚类分析的最佳类内聚类和类间距离的确定方法为:类内距离分别选取欧氏距离(euclidean)、标准化欧氏距离(seuclidean)、城市街区距离(cityblock)、明氏距离(minkowski)、切比雪夫距离(chebychev)、马氏距离(mahalanobis)、余弦距离(cosine)、相关距离(correlation)、皮尔逊相关系数(spearman)ward距离等9种距离,类间距离分别选取最短距离法(single)、最长距离法(complete)、类平均法(average)、加权平均距离法(weighted)、重心法(centroid)、中位距离法(median)等7种距离,依次计算各种类内和类间距离下的cophenet相关系数。cophenet相关系数最大值对应的类内聚类和类间距离为最佳距离。
偏最小二乘判别分析最佳因子数的确定方法为:因子数从1改变到25,间隔为1,计算不同因子数下的预测正确率。预测正确率最先达到最大值对应的因子数为最佳因子数。
极限学习机最佳激励函数和隐含层节点数的确定方法为:激励函数分别取s型函数、正弦函数、硬阈值函数、三角函数、径向基函数等5个函数,隐含层节点数取1-100,间隔为1,依次计算各种激励函数和隐含层节点数下极限学习机运行500次的相关系数均值与方差的比值(msr)。其中msr最大值对应的隐含层节点数及激励函数为最佳参数。
4)考察不同化学模式识别方法的鉴别效果,选取最佳化学模式识别方法
采用最佳参数分别建立系统聚类分析、偏最小二乘判别分析和极限学习机模型。根据预测正确率选择最佳化学模式识别方法。
附图说明
图1是109个中药样品的近红外光谱图
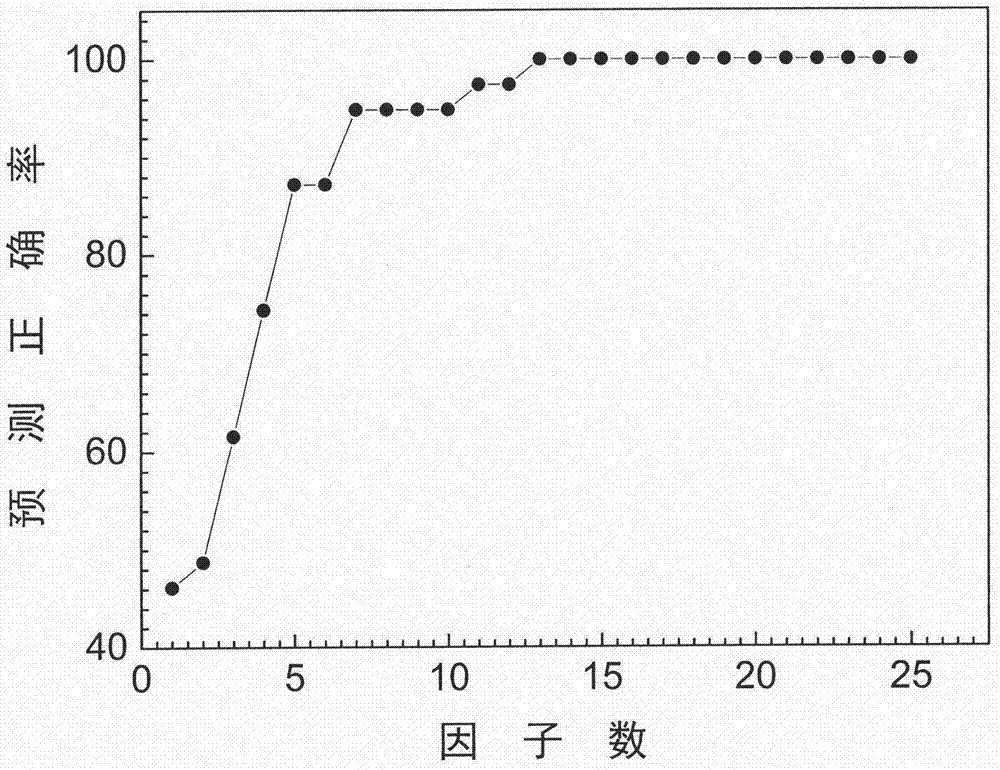
图2是三七及其伪品数据的鉴别预测正确率随着因子数的变化
图3是三七及其伪品数据中msr随着隐含层节点数及激励函数的变化图
具体实施方式
为更好理解本发明,下面结合实施例对本发明做进一步地详细说明,但是本发明要求保护的范围并不局限于实施例所表示的范围。
实施例:
1)购买三七及其伪品并制样
分别从天津14家中药店购买三七25个,莪术28个,姜黄28个,高良姜28个,共计109个样品。将样品分别粉碎,过120目筛,分别取4g放入密封的塑料瓶中。
2)采集近红外光谱
采用vertex70多波段红外/近红外光谱仪(德国布鲁克公司)采集样品的近红外光谱。采样波数范围12000-4000cm-1,分辨率为4cm-1,样品扫描次数64次,样品测量方式为积分球漫反射模式。仪器预热1小时后开始测样。首先将未装样品的石英瓶置于光点的中心处,作为背景保存,然后进行待测样品扫描,每个样品采集光谱三次,每采集一次,旋转石英瓶一次,最终取三次光谱数据的平均值作为每个样品的光谱,如图1所示。
3)优化化学模式识别方法的参数
优化系统聚类分析的类内聚类和类间距离,偏最小二乘判别分析的因子数,极限学习机的隐含层节点数和激励函数参数。
系统聚类分析的最佳类内聚类和类间距离的确定方法为:类内距离分别选取欧氏距离(euclidean)、标准化欧氏距离(seuclidean)、城市街区距离(cityblock)、明氏距离(minkowski)、切比雪夫距离(chebychev)、马氏距离(mahalanobis)、余弦距离(cosine)、相关距离(correlation)、皮尔逊相关系数(spearman)ward距离等9种距离,类间距离分别选取最短距离法(single)、最长距离法(complete)、类平均法(average)、加权平均距离法(weighted)、重心法(centroid)、中位距离法(median)等7种距离,依次计算各种类内和类间距离下的cophenet相关系数。表1显示了9种类内聚类和7种类间距离对应的cophenet相关系数。从表1中可以看出,类内聚类取皮尔逊相关系数(spearman),类间距离取平均距离法(average)对应的cophenet相关系数最大,因此spearman和average分别作为最佳的类内距离和类间距离。
表1系统聚类分析方法采用不同类内和类间距离得到的cophenet表
偏最小二乘判别分析最佳因子数的确定方法为:因子数从1改变到25,间隔为1,计算不同因子数下的预测正确率。预测正确率最先达到最大值对应的因子数为最佳因子数。让因子数从1变化到25,分别计算不同因子数下的预测准确率,得到预测正确率随着因子数的变化图,如图2所示。从图中可以看出,随着因子数的增加,预测正确率提高,当因子数大于等于13后,预测正确率都为100%。所以选定最佳因子数为13。
极限学习机最佳激励函数和隐含层节点数的确定方法为:激励函数分别取s型函数、正弦函数、硬阈值函数、三角函数、径向基函数等5个函数,隐含层节点数取1-100,间隔为1,依次计算各种激励函数和隐含层节点数下极限学习机运行500次的相关系数均值与方差的比值(msr)。其中msr最大值对应的隐含层节点数及激励函数为最佳参数。图3显示了对三七、莪术、姜黄和高良姜数据的msr随着隐含层节点数及激励函数的变化趋势,从图中可以看出,msr最大值对应的激励函数和节点数分别为三角函数和99,分别作为最佳激励函数和隐含层节点数。
4)考察不同化学模式识别方法的鉴别效果,选取最佳化学模式识别方法
采用最佳参数分别建立系统聚类分析、偏最小二乘判别分析和极限学习机模型。根据预测正确率选择最佳化学模式识别方法。将数据划分为训练集和预测集,对训练集进行建模,预测集进行鉴别。在最佳参数下对三七及其伪品进行鉴别,偏最小二乘判别分析预测准确率100%,极限学习机预测准确率为97.44%,其中系统聚类分析预测准确率为72.02%。根据预测正确率选取得最佳化学模式识别方法为偏最小二乘判别分析。
- 还没有人留言评论。精彩留言会获得点赞!