一种雷达目标识别的分类器模型训练方法与流程
本发明涉及雷达目标识别技术领域,尤其是涉及一种雷达目标识别的分类器模型训练方法。
背景技术:
不同目标在战场上执行任务的不同决定了其威胁程度的差异,因此对战场目标的识别具有重要意义。目前我军装甲部队列装的某型雷达侦察车的车载雷达为脉冲多普勒雷达,对目标的识别通常采用人为判定方式,在发现目标后,侦察员通过头戴式侦听耳机监听目标的回波音频信号,对目标进行识别。这种方式对侦察员的专业素质要求较高,尤其对未经过长时间专门培训的侦察员来说,更是容易出现误判或错判的情况,目标的正确识别率极低,并且整个过程耗时比较长,因此我军装甲部队需要更加智能的车载雷达运动目标识别方法。
雷达目标识别方法的本质是将机器学习及模式识别的相应知识应用到雷达目标探测中,其思路是从目标的雷达回波中提取出能够反应目标特性的信息,使用机器学习的思想构建分类器,将提取的特征带入训练好的分类器,从而对目标的类别做出判定,其流程如图1所示,整个过程可分为两个阶段:①特征的训练学习阶段,首先对已知类别信息的训练数据集进行预处理,接着选择出对不同类别数据具有区分度的特征,进而利用这些特征确定分类器的相关参数,完成对分类器的设计;②未知目标的识别阶段,对于未知类别信息的测试数据集,首先使用与训练阶段相同方法进行预处理,接着对该数据进行特征提取,特征类型应该与训练阶段相同,最后将这些特征输入至训练好的分类器进行识别决策,从而得出未知目标的识别结果。
分析图1可以得出,雷达目标识别的关键在于特征的选择和分类器的设计,也就是分类算法的性能。需要选择的特征主要是目标的雷达回波信号特征,可分为以下3类:①高分辨距离像特征,这类特征对不同目标具有较好的区分度,但存在不稳定的问题,且该特征大多被用于飞机目标的识别,使用该特征进行地面目标识别的研究很少;②多普勒特征,对于不同地面目标而言,由于其表面材料的不同导致了目标对雷达发射电磁波散射情况的差异,再加上目标旋转和振动等的复合调制,使得回波信号的多普勒频移具有一定的差异,可以基于此特征进行目标识别,但随着目标特征控制技术的发展,利用该类方法进行分类识别也变得比较困难;③微多普勒特征,微多普勒特征是目标微运动引起的独特特征,微运动是指目标及其组成部件的振动、转动等小幅度的运动,是由目标的独特部件在特定受力下发生的,如车轮、履带及炮塔的转动,行人手臂的摆动等,这些微运动可控性低,不易被模仿,所以其微多普勒特征往往是“独一无二”的,可以作为运动目标识别的重要依据,所以基于微多普勒特征的目标识别技术为地面目标的识别提供了新思路,具有很大潜力,本发明也是基于此方法展开研究。关于分类算法,主要有以下3类:①模板匹配算法,该类算法计算量小,易于移植,但对模板库的依赖性较高,模板越精细,匹配越好,但是计算效能又会降低;②核机器学习算法,是以统计学习理论与核函数为基础的方法,如支持向量机(Support Vector Machine,SVM)等,实现简单且识别稳定;③人工神经网络算法,这类方法具有自适应和自学习的优点,但经常会出现过拟合从而使结果呈现局部最优的情况,而且模型建立较为困难。同时上述几类方法使用模型都是浅层结构,对复杂问题的建模能力有限。
目前现有技术采用的手段分为两种:目标微多普勒特征提取和基于微多普勒特征的目标识别,其中,微多普勒特征提取是从微运动引起的雷达回波信号中获得微多普勒频移的过程。ChenV C等人提出使用时频分析法可以实现微多普勒特征的提取,并使用Gabor变换法提取了圆柱体目标旋转运动、自旋陀螺进动产生的微多普勒特征;Ghaleb A等人提出了使用短时傅里叶变换(Short-Time Fourier Transform,STFT)进行目标微多普勒特征提取的方法;Sparr T等人提出使用自适应最优核时频分析(Adaptive Optimal Kernel Time Frequency Analysis,AOK-TFA)进行微多普勒特征提取的方法;孙忠胜等人使用广义S变换进行了多人微多普勒特征提取的试验;李秋生等人提出利用高阶时频分布分析雷达目标微多普勒效应的方法。第二种为基于微多普勒特征的目标识别,Stove A G等人利用单兵便携式监测跟踪雷达采集了地面战场上3类目标(履带式车辆、轮式车辆和行人)的雷达回波信号,求得其多普勒谱,同时设计了Fisher线性分类器,对目标进行了识别。Smith G E等人采用Thales MSTAR系统对轮式车、行人和履带车进行了分类研究,利用CLEAN方法,结合主成分分析(Principal Component Analysis,PCA)对雷达回波信号的微多普勒频移进行处理,最后使用贝叶斯分类器进行目标识别。李彦兵使用了多种方法对轮式车和履带车的实测回波数据进行了识别,提取了多种微多普勒特征,如多普勒谱、能量分布特征等,之后使用SVM进行分类。总体来说,EMD分层分类法具有较高的分类正确率。Kim Y等人分别提出将人工神经网络(Artificial Neural Network,ANN)与微多普勒特征相结合、SVM与微多普勒特征相结合的行人姿态识别方法。
现有基于时频分析的微多普勒特征提取和基于微多普勒特征的目标识别方法中,还存在一些局限和不足,主要为:
(1)在使用时频分析法进行微多普勒特征提取时,线性时频分析法所得结果通常存在时频分辨率较低的问题,如STFT、Gabor变换等方法;二次型时频分析法所得结果通常存在交叉项干扰的问题,如魏格纳分布(Wigner-Ville Distribution,WVD)、伪魏格纳分布(Pseudo Wigner-Ville Distribution,PWVD)等;重排类时频分布通常存在计算复杂度太高的问题,如重排平滑伪Wigner分布(Reassigned Smoothed Pseudo Wigner-Ville Distribution,RSPWVD)等。
(2)在基于微多普勒特征的目标识别方法中,当前很多分类算法都是浅层结构,应用范围较窄,样本量较少时,无法对复杂函数进行很好地表示,因此对于较为复杂的识别问题,其处理能力有限,如Fisher线性分类器、贝叶斯分类器、SVM等,因此在提高分类器的学习能力方面有待提高。
上面论述的目标特征提取及识别方法,存在着诸多的局限性和不足。因此,要完成地面运动目标的识别,尤其是高准确率、实时的识别,有一定的难度。
技术实现要素:
本发明提出一种雷达目标识别的分类器模型训练方法,有效地解决了人工选取特征值费时费力、浅层分类算法对复杂识别问题的处理能力有限的问题,实现了快速、准确的地面目标识别。
本发明的技术方案是这样实现的:一种雷达目标识别的分类器模型训练方法,包括将已知类别信息的时频图分为训练数据集和测试数据集两类,利用原始深度学习模型进行训练,通过不断调整参数获得适用于雷达目标识别的最优深度学习模型,所述分类器模型训练阶段使用CNN模型。
作为一种优选的技术方案,所述初始CNN模型的基本网络结构由多个层组成,每一层有多个二维平面,每个平面又有多个相互独立的神经元,其处理步骤可简要归纳如下:
①将经过预处理的二维数据做为输入放入CNN;
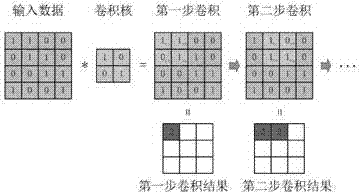
②使用3个卷积核和可加偏置对输入数据进行卷积,在C1层得到3个特征映射,卷积过程如图4所示,设输入矩阵大小为4×4,卷积核的大小为2×2,卷积的步长为1,则卷积后的矩阵大小为3×3,即对于a×b的输入数据,当卷积核大小为c×d,且步长为i时,卷积后数据的大小g×h为:
③对C1层输出的特征进行池化,即对C1层的输出中的邻域进行加权求和,加偏置再经过激励函数在S2层得到3个特征映射,其目的是对数据不同位置的特征进行聚合统计,以此来降低卷积特征向量的维度;
④重复②、③过程得C3和S4,以此类推,直到最终所得输出变为一维数组,将其输入至全连接的神经网络进行识别。
作为一种优选的技术方案,所述CNN模型训练阶段分为特征学习和模型验证两个阶段:
①在特征学习阶段,将训练数据集和对应的类别标签信息输入至CNN中,CNN开始进行训练的前向传播阶段,结束后输出预测的类别标签,将预测的标签与输入的实际标签进行对比,若不相等,则CNN开始进行误差反向传播阶段,使用梯度下降法调整CNN的各层权值和偏置参数,之后再次进行前向传播,直至预测所得标签与实际标签之间相等为止,此时保存CNN中的各项参数;
②在模型验证阶段,使用上述参数构成的CNN模型对验证数据集进行识别测试,如果所得的识别正确率达到了要求,则认为该模型就是最优模型,可以直接使用这个模型对未知类别的数据进行识别,否则需要进一步调整CNN模型的参数,直至对验证数据集的识别正确率达到要求。
采用了上述技术方案,本发明的有益效果为:
本发明有效地解决了人工选取特征值费时费力、浅层分类算法对复杂识别问题的处理能力有限的问题,实现了快速、准确的地面目标识别。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为现有技术中雷达目标识别流程图;
图2为本发明改进算法流程图;
图3为本发明基本CNN网络结构图;
图4为本发明卷积过程示意图;
图5为本发明CNN模型训练阶段原理图;
图6为本发明不同方法人体行走微多普勒特征提取效果对比图;
图7为本发明人体不同运动状态微多普勒特征提取效果图;
图8为本发明GoogLeNet网络模型参数图;
图9为本发明训练参数图;
图10为本发明训练日志图;
图11为本发明未知目标识别效果图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明主要以行人不同运动状态为例进行识别,所用的技术可以简单移植到其它类型雷达目标的识别中。整个过程可以分为两个阶段:雷达目标微多普勒特征提取、基于微多普勒特征和深度学习的目标识别。
一种雷达目标识别方法,包括新方法可分为三个阶段:
步骤一、微多普勒特征提取阶段,使用MSTFT-WVD算法获得目标的微多普勒特征时频图;
步骤二、分类器模型训练阶段,将第一阶段获得的已知类别信息的时频图分为训练数据集和测试数据集两类,利用原始深度学习模型进行训练,通过不断调整参数获得适用于雷达目标识别的最优深度学习模型;
步骤三、未知目标的识别阶段,同样利用MSTFT-WVD算法获得未知目标的微多普勒特征时频图,将其输入至第二阶段训练好的深度学习模型中,获得未知目标的类别信息。
与传统方法相比,新方法第二阶段使用的深度学习分类算法具有良好的性能,主要表现为:①能够从海量样本的训练中自行学习目标特征的变化规律,从而省去了传统方法中人工选择特征模版的过程;②与传统ML算法相比,其模型结构的深度更深,一般都具有五六个甚至十个以上的隐含层,网络层数更多,对复杂特征的表示能力更强。实验证明,使用新方法进行雷达目标识别,可以得到更高的识别正确率。
其中,目标微多普勒特征提取:微多普勒效应是微运动在雷达发射信号载频上引起的频率调制,所以微多普勒特征主要指的是微多普勒频移,则微多普勒特征提取就是从微运动引起的雷达回波信号中获得微多普勒频移的过程。目标微运动引起的微多普勒频移随时间非线性变化,即微运动引起的雷达回波信号是频谱时变信号,因此传统的傅里叶变换无法很好地描述微多普勒频移的变化规律,有效提取微多普勒特征需要其他能够处理频率时变信号的方法。
时频分析能够从频谱时变信号中很好地得到原始信号频率随时间的变化关系,是一类典型的获取时变信号频谱的方法,因此本发明使用时频分析进行雷达目标微多普勒特征提取。
常用时频分析方法主要有短时傅里叶变换(Short-Time Fourier Transform,STFT)、魏格纳分布(Wigner-Ville Distribution,WVD)等,其中前者输入线性时频分析法,后者属于二次型时频分析方法。传统微多普勒特征提取过程中单独使用这两类方法获得目标微多普勒频率随时间的变化关系,即得到时频矩阵和时频图,但所得结果都有很多缺点。因此本发明提出将两类方法相结合的思想得到一种新的时频分析方法,该方法可以有效地保留两类方法各自的优点,从而得到更真实的目标微多普勒特征。其主要过程可归纳如下:先对原始信号进行STFT得短时傅里叶变换矩阵,同时对原始信号进行WVD变换得相应时频分布矩阵,接着对二者的和矩阵设立阈值,当和矩阵的值大于该阈值时,令其值为1,否则为0,得到一个新的矩阵,最后将新的矩阵与WVD分布矩阵相乘,最终得到新的时频分布。
MSTFT-WVD(Modified STFT-WVD)算法,STFT的基本思想是用一个时间很短的窗函数不断的交叉平移将信号分成若干段,对每一段信号求傅里叶变换,其表达式如下所示:
式中,x(t)为要变换的信号,g*(t)为窗函数的复共轭。STFT计算简单,但所得结果具有时频分辨率无法统一的缺点,如果选择较短的窗函数则时域分辨率很高,但频域分辨率很差。反之,若窗函数较长,则时域分辨率低,频域分辨率高。
为了解决STFT结果受窗函数影响导致时频分辨率无法统一的问题,采用WVD方法不加窗的优势来获得性能上的改进,信号的WVD是其时频能量密度,表达式为:
式中,x(t)为要变换的信号。WVD不受窗函数的影响,因此具有很高的时频分辨率,但有一个很大的缺陷就是存在交叉干扰项,不利于信号的分析。信号交叉项的产生过程如下,假设信号x(t)=x1(t)+x2(t),则根据式(2)可得:
式中就是信号分量x1(t)和x2(t)产生的交叉干扰项,对于包含两个及以上分量的信号,其WVD肯定会有干扰项的存在。
为了解决WVD交叉项干扰严重的问题,采用STFT与WVD相结合的方法来获得性能上的改进,即STFT-WVD算法,其具体步骤为:对信号的STFT矩阵设立阈值,当STFT矩阵的值小于该阈值时,令该值为0,当STFT矩阵的值大于该阈值时,令其值为1,从而得到一个新的矩阵,将新矩阵与信号的WVD矩阵相乘,得到新的时频分布。此时,WVD中有交叉项的部分对应的谱值均变为0。其定义式为:
SWx(t,f)=Wx(t,f){|STFTx(t,f)|>c} (4)
式中,c为阈值。由定义可知该方法所得的时频分布分辨率较高,同时交叉项也得到了抑制。但是对于多分量信号,STFT算法由于时频分辨率差的原因,在频率重叠的地方容易形成不可分辨的区域,继而在STFT-WVD算法设立阈值进行分析时,这一区域会出现特征丢失或者改变的情况。
为了解决STFT-WVD算法分析多分量信号时出现特征丢失或改变的问题,本发明提出一种MSTFT-WVD算法,希望该算法得到的时频分布具有较高的时频分辨率高和较少的交叉项干扰,同时特征丢失或者改变较少。MSTFT-WVD算法的主要思想为:对STFT矩阵和WVD矩阵的和矩阵设立阈值来改善上述缺点,对两类矩阵求和之后,STFT中的模糊区域以及WVD中的交叉项部分保持了不变,但是信号的自项成分得到了加强,此时再设立阈值进行后续分析得到的时频分布的性能必将优于直接使用STFT-WVD所得,考虑到STFT变换为线性变换,为了与二次型变换的WVD相对应,对STFT结果进行平方运算求得其短时傅里叶变换谱Sx(t,f),之后再与WVD矩阵进行求和运算。故可将MSTFT-WVD算法的公式表述如下:
式中,SWWx(t,f)为使用MSTFT-WVD算法对信号进行时频变换所得矩阵,a为幂调节系数,c为阈值。
改进算法的流程图如图2所示。
具体的算法步骤如下:
①对微多普勒信号进行STFT变换和WVD变换分别得STFTx(t,f)和Wx(t,f),同时对STFTx(t,f)进行平方运算得原始信号的短时傅里叶变换谱Sx(t,f);
②对Sx(t,f)和Wx(t,f)进行归一化处理后求和得SW1x(t,f);
③设立阈值c,当SW1x(t,f)的值大于c时,令其值为1,当SW1x(t,f)的值小于c时,令其值为0,得到新矩阵SW2x(t,f);
④对Wx(t,f)进行指数运算得Wxa(t,f),其目的是增强Wx(t,f)中数值较大的自项部分同时减弱交叉项部分;
⑤对Wxa(t,f)和SW2x(t,f)进行乘积运算得新的时频分布SWWx(t,f)。
通过实验证实,系数a在[0.2,0.5]范围内取值为宜,阈值c在[0.3,0.7]×max|SW1x(t,f)|范围内取值为宜。
同时需要注意的是,改进算法所得的SWWx(t,f)的值只能反映信号时频变换幅度的相对大小,不是其时频分布真实幅值的绝对值。
在众多的深度学习分类算法中,卷积神经网络(Convolutional Neural Network,CNN)是第一个真正获得成功应用的深度学习算法,具有良好的性能,因此本发明在分类器模型训练阶段使用CNN模型。具体原因如下:CNN的输入是二维数据,是一种主要应用在二维数据识别中的网络,而本发明使用时频分析进行微多普勒特征提取后所得的时频图正好也是二维数据,因此可以直接以提取的微多普勒特征时频图作为CNN的输入数据,让CNN自动学习特征,避免了传统方法中对微多普勒频移再次人工进行特征值提取或者其他的数据格式转换过程。
初始CNN模型的基本网络结构如图3所示,整个网络由多个层组成,如图3中的输入层、C1层等,它的每一层又可以有多个二维平面,如图3中C1层的3个方块,每个平面又有多个相互独立的神经元,其处理步骤可简要归纳如下:
①将经过预处理的二维数据做为输入放入CNN;
②使用3个卷积核和可加偏置对输入数据进行卷积,在C1层得到3个特征映射,卷积过程如图4所示,设输入矩阵大小为4×4,卷积核的大小为2×2,卷积的步长为1,则卷积后的矩阵大小为3×3,即对于a×b的输入数据,当卷积核大小为c×d,且步长为i时,卷积后数据的大小g×h为:
③对C1层输出的特征进行池化(Pooling),即对C1层的输出中的邻域进行加权求和,加偏置再经过激励函数在S2层得到3个特征映射,其目的是对数据不同位置的特征进行聚合统计,以此来降低卷积特征向量的维度;
④重复②、③过程得C3和S4,以此类推,直到最终所得输出变为一维数组,将其输入至全连接的神经网络进行识别。
CNN模型训练阶段的原理图如5所示,主要分为特征学习和模型验证两个阶段:①在特征学习阶段,将训练数据集(微多普勒特征时频图)和对应的类别标签信息输入至CNN中,CNN开始进行训练的前向传播阶段,结束后输出预测的类别标签,将预测的标签与输入的实际标签进行对比,若不相等,则CNN开始进行误差反向传播阶段,使用梯度下降法调整CNN的各层权值和偏置参数,之后再次进行前向传播,直至预测所得标签与实际标签之间相等为止,此时保存CNN中的各项参数;②在模型验证阶段,使用上述参数构成的CNN模型对验证数据集进行识别测试,如果所得的识别正确率达到了要求,则认为该模型就是最优模型,可以直接使用这个模型对未知类别的数据进行识别,否则需要进一步调整CNN模型的参数,直至对验证数据集的识别正确率达到要求。
数据集制作:利用某型车载多普勒雷达获得人在行走、跑步、匍匐三种运动状态下的实际回波信号,之后,进行训练数据集和测试数据集的制作。因为实际测得的雷达回波信号为一段时间较长的音频信号,所以在数据集制作过程中需要将其切割为多组固定长度的短时间信号,如果长度选择太长,信号处理时非常耗时,如果长度太短,每组数据对微多普勒特征的描述不全面,例如人行走时一个摆臂的周期在2秒左右,因此本论文将每组数据的时间长度固定为3秒。同时为了增加数据量,切割时每次向后滑动一个固定长度,例如将0到3秒的信号视为第一组数据,将0.5到3.5秒的信号视为第二组数据,以此类推。最后总共获得三类目标的数据330组,各自110组。分别在各自的110组数据中随机选取90组数据做为训练数据集原始数据,剩余20组数据做为测试数据集原始数据。
微多普勒特征提取,以人行走时的雷达回波信号为例,使用三种方法在Matlab中编程对一组训练数据集原始数据进行微多普勒特征提取,可得其结果如图6所示。
分析图6可知,与STFT、WVD相比,MSTFT-WVD算法进行微多普勒特征提取效果更好,时频分辨率高于STFT所得,交叉项干扰低于WVD所得。
目标识别,目前主流的利用CNN模型进行目标识别的深度学习工具有很多,本发明主要使用Caffe搭建雷达目标识别环境。
Caffe深度学习框架搭建,Caffe(Convolutional Architecture for Fast Feature Embedding)是贾扬清博士开发的一款计算CNN相关算法的深度学习框架,具有清晰、高效的特点,同时可以支持命令行、Python及MATLAB等诸多接口,还可以在CPU和GPU之间实现无缝切换。
本发明用于搭建Caffe深度学习框架所需软件及其版本如表1所示。
表1 Caffe架构软件及版本
整个配置过程可简要归纳如下:
①安装Visual Studio 2013;
②安装CUDA 7.5.18并配置5个相应的系统变量和2个环境变量,测试是否成功安装;
③安装cuDNN 7.5;
④配置CPU Only方案,将文件CommonSettings.props.example重命名为Common-Settings.props,并启用CpuBuildOnly,关闭UseCuDNN,生成libcaffe,编译caffe.cpp直至生成caffe.exe;
⑤配置GPU方案,关闭CommonSettings.props文件中的CpuBuildOnly,并启用Use-CuDNN,重新生成libcaffe,同样编译caffe.cpp直至生成caffe.exe;
⑥安装Matlab 2014b,启用CommonSettings.props文件中的Matlab接口,并生成matcaffe,并重新编译caffe.cpp。
行人运动状态识别,本发明选用CNN模型中的GoogLeNet模型进行目标识别中训练、测试以及预测等过程,整个步骤可概括如下:
①利用改进STFT-WVD算法完成微多普勒特征提取,如图7所示,其中(a)为人行走时的雷达回波信号时频特征图,(b)为人跑步时的雷达回波信号时频特征图,(c)为人匍匐时的雷达回波信号时频特征图;
分析图7可知,人体的微运动主要是手臂和腿脚的摆动,在行走和跑步状态下手臂摆动的幅度更大,手臂的微多普勒特征更加明显,而在匍匐状态下手臂摆动的幅度与膝盖和腿脚的摆动幅度非常接近,故可明显的看到2类不同的微多普勒特征,同时在这3种状态下,跑步时产生的微多普勒频移的幅度明显大于其他两种状态下的幅度,这是由于跑步时速度明显大于其他状态所致。
②将3类不同运动状态各自的90组训练数据集放入train文件夹,并设置标签train.txt,使得数据集中数据的名称与标签一一对应,如在标签文件中,使用0代表人行走,1代表人跑步,2代表人匍匐,同理将各自的20组测试数据集放入val文件夹,并设置标签val.txt;
③将训练数据集和测试数据集分别转化为LevelDB格式,即Caffe的输入数据格式;
④分别计算出训练数据集和测试数据集的均值文件;
⑤配置GoogLeNet网络模型,即修改GoogLeNet的train_val.prototxt文件,首先修改训练及测试数据集文件、均值文件等的路径,其次根据计算机配置修改训练阶段批处理数量为10和测试阶段批处理的数量为5,最后修改目标的输出类别的数量,本发明为3类,如图8所示;
⑥配置网络训练参数,即修改GoogLeNet的solver.prototxt文件,如图9所示;
⑦开始训练,如图10所示,从图中可以看出,训练初期测试分类结果的时候,其准确率为33.33%,正好是对3类目标类别随机猜测的结果,当迭代次数达到800次时,其准确率为98.33%,所以可以利用此时生成的caffemodel模型对未知目标进行预测;
⑧对未知数据集的类别进行预测,如图11所示,对比识别为3类不同目标的概率,将该目标识别为概率最大的那一类,例如对creep90的识别结果中,为“creep”类的概率为93.10%,故可认为该运动状态是匍匐。
对于三类不同运动状态,随机选取110组数据视为未知数据进行验证,可得其结果如表2所示。
表2行人目标识别结果表
分析表2可知,基于微多普勒特征和CNN的方法可以较好地实现人体目标运动状态的识别,平均分类正确率为97.3%,高于用常规方法92.7%的识别正确率,验证了本发明提出方法识别行人目标运动状态的实际有效性。
(1)本发明提出基于MSTFT-WVD算法的微多普勒特征提取方法,在STFT和WVD特征提取的基础上,结合各自的优点,利用归一化求和的思想加强信号自项成分,有效地抑制了交叉项成分,同时一定程度上提高了时频分辨率,而且耗时较少。
(2)本发明提出将微多普勒特征与深度学习相结合的目标识别方法,将微多普勒特征时频图做为CNN的输入,让CNN自动学习特征,省去了传统方法中对微多普勒频移再次人工进行特征值提取以及其他的数据格式转换过程,减少了工作量,有效地提高了目标识别的正确率,具有其它方法不可替代的优点。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!